


Ассемблер — это собирательное название языков низкого уровня. «Низкий» здесь означает не примитивность, а близость к машинному коду, который компьютеры понимают без перевода (в отличие от высокоуровневых языков). Ассемблер — что-то среднее между машинным кодом и командами на естественном языке.
Нужно ли учиться писать на ассемблере в 2026 году? Да, если хотите войти в высшую лигу и делать то, что почти никто не может, например создавать программы для микроконтроллеров. А вот читать ассемблер, чтобы понимать принципы работы высокоуровневого кода, будет полезно многим программистам.
Если научитесь читать ассемблерный код, то сможете:
- разобраться, как в памяти хранятся временные данные, регистр и прочие важные вещи, позволяющие правильно работать с памятью во всех высокоуровневых языках;
- понять, какие оптимизации выполняет компилятор и как они влияют на конечную производительность и поведение программы;
- работать с низкоуровневыми API и добавлять в высокоуровневый код ассемблерные вставки для лучшей производительности.
Сегодня потренируемся разбираться в ассемблерном коде. Для этого преобразуем код высокоуровневой программы в ассемблер, посмотрим получившийся код и то, какие оптимизации применяет компилятор, чтобы сделать его эффективнее.
Краткий обзор
В статье про ассемблер мы уже разбирали его базовые понятия: что такое регистры, из чего состоит программа и какие бывают команды. Кратко напомним основные моменты.
В ассемблере используются мнемоники — короткие символические имена, которые представляют машинные команды (например, MOV, ADD, SUB).
После мнемоник следуют операнды — значения, над которыми выполняется операция. Они могут быть регистрами процессора, то есть специальными ячейками памяти, адресами памяти или непосредственными значениями. Например:
MOV eax, 5 ; Переместить значение 5 в регистр eax
Здесь MOV — это мнемоника команды перемещения, eax и 5 — операнды. Комментарий после ; объясняет, что делает эта строчка кода.
Инструмент Compiler Explorer
Мы будем переводить высокоуровневую программу в ассемблер через Compiler Explorer и смотреть, как она работает, обращается к памяти и что происходит на каждом этапе.
Compiler Explorer — онлайн-инструмент, созданный Мэттом Годболтом для исследования компиляторов. В Compiler Explorer можно писать код на высокоуровневом языке и сразу видеть, какой ассемблерный код генерирует для него компилятор. А если это Python или Java, можно увидеть их байт-код.
Принцип работы инструмента простой: слева выбираем нужный язык, справа — версию компилятора. Затем в окно слева вводим код, а справа видим сгенерированный ассемблер.
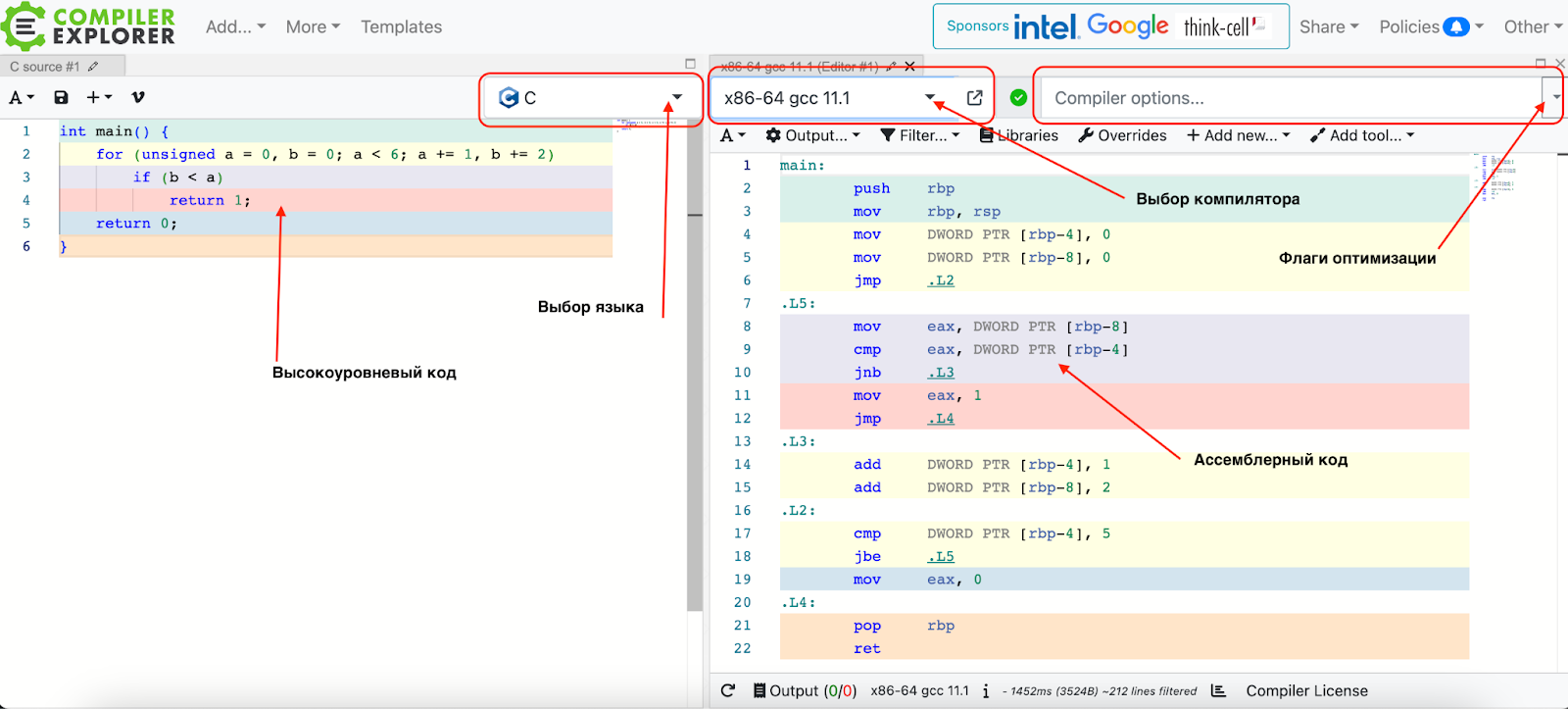
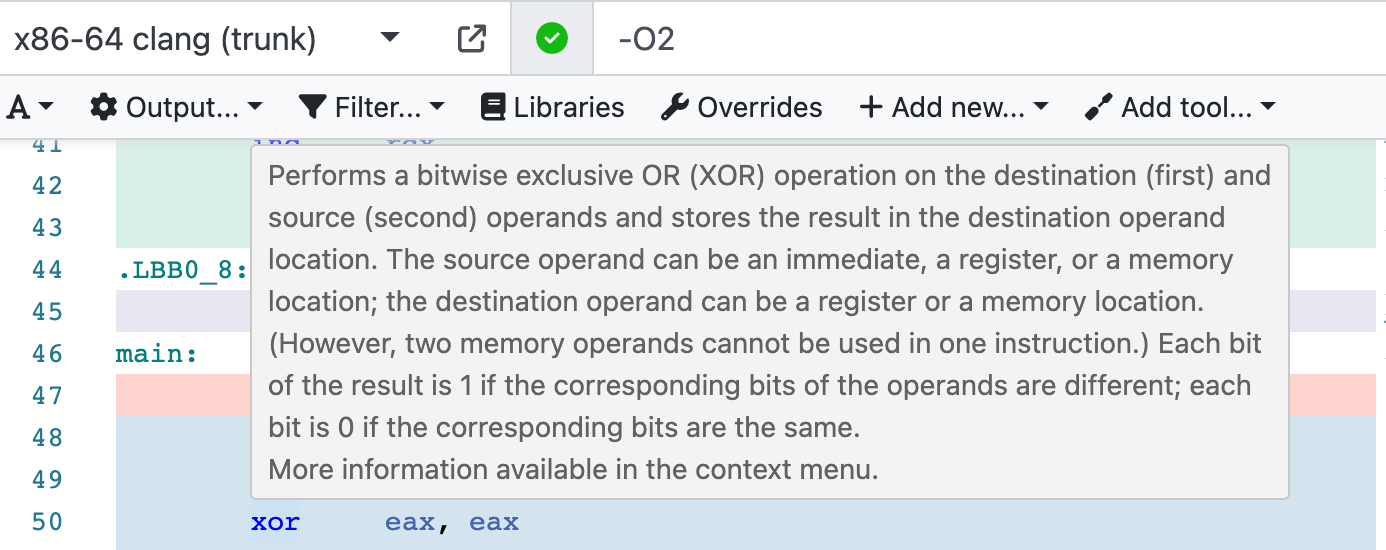
С помощью Compiler Explorer удобно изучать синтаксис ассемблера: наводим курсор на команду и сразу видим её описание. А через контекстное меню можно раскрыть полное описание и перейти на страницу документации.
Современные компиляторы очень умные. При работе с кодом они используют оптимизации для улучшения производительности и эффективности генерируемого машинного кода. Могут удалять «мёртвый» код, который никогда не используется, уменьшать число итераций цикла, предсказывать ветвления и так далее. С помощью флагов компилятора разработчик может включать разные виды оптимизаций или вообще их отключать. Например, флаг -О1 означает базовую оптимизацию.
Выбирая различные типы оптимизации, можно увидеть, как компилятор оптимизирует тот или иной кусок кода. Инструмент сам подсвечивает, какая строчка во что превратилась и как реализовались исходные решения.




Читаем высокоуровневую программу
Разберем небольшую программу на С++ и посмотрим на разные уровни оптимизации. Есть небольшой код, который определяет функцию square: она принимает один целочисленный аргумент num и возвращает его квадрат.
int square(int num) {
return num * num;
}В ассемблере без оптимизации код будет выглядеть так:
square(int):
push rbp
mov rbp, rsp
mov DWORD PTR [rbp-4], edi
mov eax, DWORD PTR [rbp-4]
imul eax, eax
pop rbp
ret
Строчки кода в обоих окнах раскрашены в разные цвета. Если наводить курсор на разные блоки кода, мы увидим соответствия ассемблерного кода. Три строки на С++ превратились в 7 строк на ассемблере. Разберёмся, что тут происходит.
Код сохраняет текущее состояние стека (push rbp), чтобы потом его можно было восстановить. Это поддерживает правильный порядок вызовов функций и возвращений из них.
Затем код готовит место в памяти для хранения входного числа (mov rbp, rsp и mov DWORD PTR [rbp-4], edi). После этого берёт это число, умножает его на само себя, чтобы получить квадрат (mov eax, DWORD PTR [rbp-4] и imul eax, eax), и сохраняет результат. Наконец, восстанавливает исходное состояние стека (pop rbp) и возвращает результат умножения обратно в вызывающую программу (ret).
Теперь включим базовую оптимизацию -O1 и посмотрим на новый сгенерированный код:
square(int):
imul edi, edi
mov eax, edi
ret
Код стал намного меньше: мы видим, что компилятор убрал все подготовительные действия по работе с памятью. В первой строке код умножает значение, хранящееся в регистре edi, само на себя. Результат умножения сохраняется в том же регистре edi. Во второй строке копируется значение из регистра edi в регистр eax. И наконец команда ret возвращает управление вызывающей функции.
Компилятор определил, что для выполнения функции не требуется сохранение состояния стека и подготовка локальных переменных, как в первом случае, и все операции можно выполнить прямо в регистрах.
Такой ассемблер уже не выглядит сложным и пугающим, и разобраться в нём намного проще. А изучая оптимизированный и неоптимизированный ассемблерный код, можно понять, как программа использует ресурсы системы.
Случай неправильной оптимизации
Редко, но бывает, что оптимизации компилятора приводят к ошибке в работе корректной программы. И вычислить это можно, только покопавшись в ассемблерном коде.
Три года назад пользователь Reddit поделился случаем, когда его код на C выдавал неправильный результат при включённой оптимизации в версии компилятора GCC 9+.
Причиной ошибки стал такой фрагмент кода:
int main() {
for (unsigned a = 0, b = 0; a < 6; a += 1, b += 2)
if (b < a)
return 1;
return 0;
}В коде выполняется цикл, в котором переменные a и b инициализируются значениями 0. На каждом шаге цикла a увеличивается на 1, а b — на 2, пока a не достигнет 6. В каждой итерации проверяется условие if (b < a). Если условие истинно, код завершает выполнение и возвращает 1[t/ags]. Если цикл завершается без прерываний, код возвращает .0
При этом условие if (b < a) никогда не будет истинным, поскольку b всегда увеличивается на 2, в то время как a увеличивается только на 1. Поэтому код всегда должен возвращать 0.
Без включенных оптимизаций код вёл себя ожидаемо, но стоило добавить любую оптимизацию, и код выдавал 1, чего не должно было происходить. При изучении проблемы выяснилось, что компилятор генерировал такой ассемблерный код:
main:
mov eax, 1
ret
Здесь мы видим, что инструкция mov перемещает значение 1 в регистр eax, который используется для возврата значения из функции. И всё. То есть, компилятор просто убирал весь цикл с условием, что и давало некорректный результат.
Реддитор сообщил о своей проблеме, и баг компилятора исправили. Оказалось, что разработчики не добавили поддержку беззнаковых (unsigned) типов данных.
Что дальше
Если всё-таки захотелось освоить программирование на ассемблере, рекомендуем почитать книгу Андрея Столярова «Программирование на языке ассемблера NASM для ОС Unix». Там на подробных примерах описана вся суть низкоуровневого программирования.
А в следующей серии поговорим про сайзкодинг — искусство делать программы в минимальное количество байтов.











