


Начиная с обновления ES6 в 2015-м, каждый год выходит новая версия языка. И практически все изменения в JavaScript — это заимствования из других языков.
Сегодня посмотрим, что вышло интересного в 2023 и 2024 году. Паттерн-матчинга всё ещё нет, но есть кое-что другое не менее полезное.
Новые методы Set
Set в JavaScript — это такая структура данных, которая хранит только уникальные значения. Set используют для фильтрации повторяющихся элементов в массиве, проверки наличия определённого значения или сравнения списков.
Раньше методы Set позволяли добавлять, удалять и проверять наличие элементов, а теперь можно производить ещё и операции со множествами: пересечение (intersection), объединение (union) и разность (difference).
Метод intersection возвращает новый Set, который содержит только те элементы, что есть в обоих множествах.
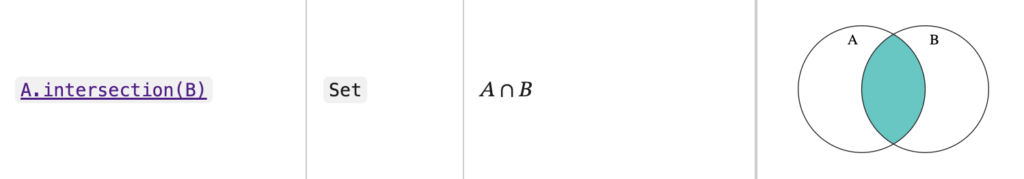
Например, у нас есть два списка: setA — товары в магазине, а setB — то, что уже купили. Нужно узнать, что из списка купленных товаров ещё в наличии:
const setA = new Set([1, 2, 3, 4]);
const setB = new Set([3, 4, 5, 6]);
const commonItems = setA.intersection(setB);
console.log(commonItems); // Set { 3, 4 }
Результат — Set с элементами 3 и 4, которые есть и там, и там.
Следующий метод — difference. Он возвращает новый Set, содержащий элементы, которые есть в одном множестве, но отсутствуют в другом. Это удобно, когда нужно понять, что уникально в одном наборе данных по сравнению с другим.

Допустим, есть два списка: список статей, которые уже опубликованы в журнале, и список новых предложений от авторов. С помощью метода difference можно сразу увидеть, какие из новых статей ещё не были напечатаны.
const publishedArticles = new Set([
"Обзор новых фреймворков",
"Советы для DevOps-инженеров",
"Лучшие практики безопасности"
]);
const proposedArticles = new Set([
"Советы для DevOps-инженеров",
"Лучшие практики безопасности",
"Какие IDE будут модны в 2025",
"Новое в CSS"
]);
const newArticles = proposedArticles.difference(publishedArticles);
console.log(newArticles);
// Set { "Какие IDE будут модны в 2025", "Новое в CSS" }
И последний метод — union (объединение). Он позволяет объединить два множества, собрав в новый Set все уникальные элементы из обоих. То есть мы берём два списка, убираем повторы и получаем полный набор данных. Это удобно, когда, например, нужно объединить списки пользователей, зарегистрированных через сайт и мобильное приложение, чтобы получить общий список всех клиентов.

Например, есть два поставщика кабачков и всего такого: местный фермер и импортный производитель. Завскладом хочет получить полный список всех наименований. С помощью union можно объединить эти списки, убрав дубликаты, и получить полный список уникальных видов кабачков, тыкв и патиссонов:
const localZucchinis = new Set(["Кабачок белый", "Кабачок цукини", "Кабачок жёлтый"]);
const importedZucchinis = new Set(["Кабачок жёлтый", "Кабачок цукини", "Кабачок патиссон"]);
const allZucchinis = localZucchinis.union(importedZucchinis);
console.log(allZucchinis);
// Set {
// "Кабачок белый",
// "Кабачок цукини",
// "Кабачок жёлтый",
// "Кабачок патиссон"
// }
Группировка элементов массива
Новый метод Object.groupBy() умеет разделять элементы массива на группы. Мы говорим методу, по какому правилу разделить элементы (передаём функцию-колбэк), а он возвращает объект, где названия групп — это строки, а значения — массивы элементов, которые подходят под каждую группу.
Если нужно, чтобы группы назывались не строками, а чем-то другим (числами или объектами), то используем Map.groupBy().
Всё это нужно, чтобы быстро и удобно сортировать или разделять данные по категориям. Раньше для этого использовали ручную итерацию по массиву с помощью циклов или метод reduce.
Посмотрим на примере. У нас есть список товаров на складе, где каждый товар имеет название, тип (категорию) и количество:
const inventory = [
{ name: "спаржа", type: "овощи", quantity: 5 },
{ name: "бананы", type: "фрукты", quantity: 0 },
{ name: "коза", type: "мясо", quantity: 23 },
{ name: "вишня", type: "фрукты", quantity: 5 },
{ name: "рыба", type: "мясо", quantity: 22 },
];Мы хотим сгруппировать товары по их категории: овощи, фрукты, мясо и так далее. Для этого используем метод Object.groupBy():
const groupedByType = Object.groupBy(inventory, (item) => item.type);
console.log(groupedByType);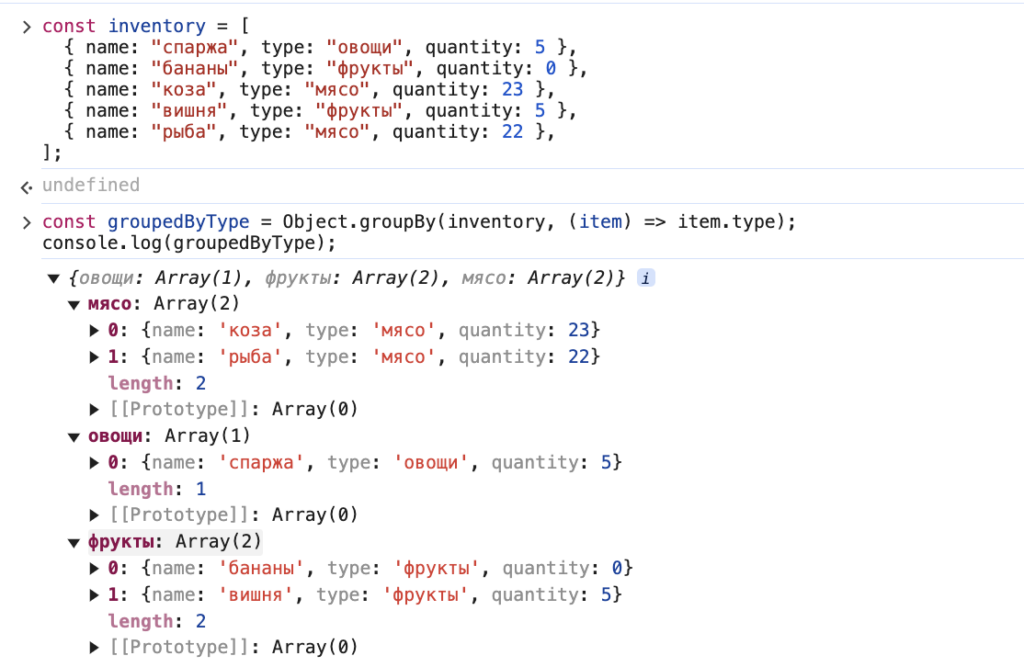
Что здесь произошло:
- Метод
Object.groupBy()берёт массивinventoryи для каждого элемента вызывает функцию (item) =>item.type. Далее эта функция возвращает тип товара («овощи», «фрукты» или «мясо»). - Элементы с одинаковым значением
typeсобираются в массивы и становятся значениями в итоговом объекте. - Ключи объекта (овощи, фрукты, мясо) соответствуют возвращаемым значениям функции.
Метод может пригодиться при группировке товаров по категориям или для работы с пользовательскими данными (разделение по возрастным группам, ролям или регионам). Также полезен для анализа данных — чтобы быстро увидеть, сколько элементов относится к каждой группе, или выделить определённые категории для дальнейшей обработки.

await без async
Одна из новых долгожданных возможностей — это использование await без async.
👉 async — это синтаксический сахар над промисами. Чтобы вручную не писать цепочки .then и .catch, используют ключевые слова async и await для более читабельного и понятного кода. Ключевое слово async делает функцию асинхронной, то есть она возвращает промис. А await позволяет заморозить выполнение функции до тех пор, пока промис не будет выполнен.
Раньше, чтобы выполнить асинхронный код с await, нужно было обязательно оборачивать его в async-функцию, даже если в этом не было особой необходимости. А в последних версиях JavaScript можно просто написать await на верхнем уровне:
// Выполняем HTTP-запрос по указанному URL и ожидаем ответа от сервера
const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
// Преобразуем ответ в JSON-объект
const data = await response.json();
// Выводим полученные данные в консоль
console.log(data);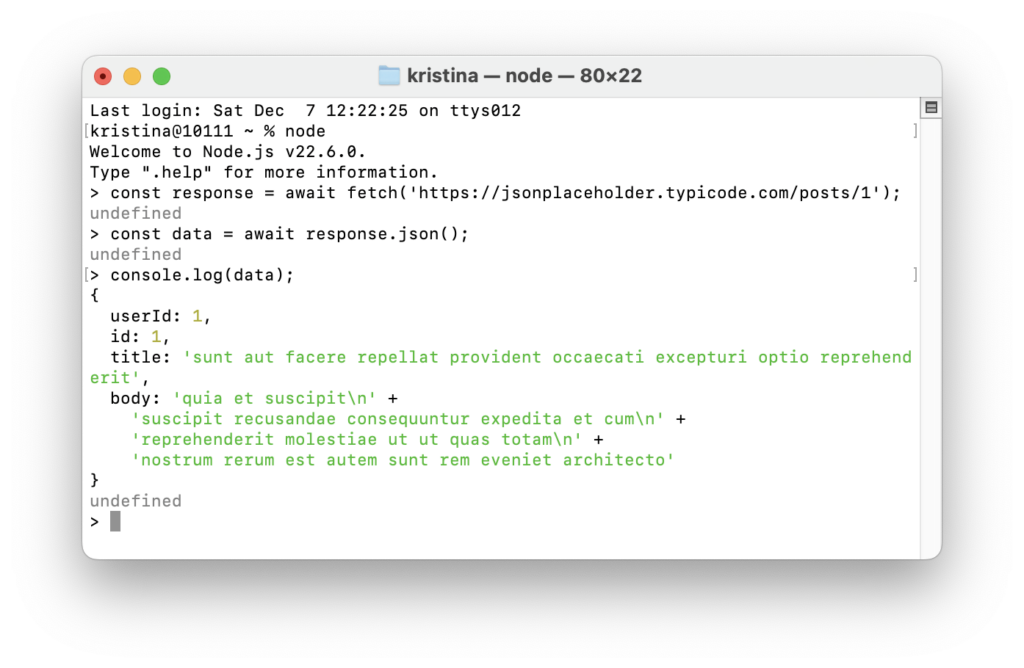
Здесь мы используем await без async-функции — код возвращает данные и не выдаёт ошибку, как это было бы раньше. Мы работаем с асинхронными операциями, не создавая лишних обёрток. Код становится проще и удобнее, особенно в случаях, когда нужно выполнить что-то быстро или протестировать небольшой кусок логики.
Работа с промисами вне тела конструктора
Другое нововведение, связанное с промисами, метод Promise.withResolvers.
Он позволяет отдельно получить функции resolve и reject, которые можно вызвать в любой момент, чтобы завершить промис успешно или с ошибкой. Это полезно в сложных сценариях, когда завершение промиса зависит от разных условий или событий, например при работе с устаревшими API на основе колбэков или когда нужно динамически создавать промисы.
Вот как это работает. Раньше, чтобы создать промис, нужно было использовать конструктор new Promise() и внутри прописывать логику вызова resolve и reject. С помощью же нового метода Promise.withResolvers мы создаём промис, и метод возвращает сразу три объекта:
promise— сам промис, с которым можно работать;resolve— функцию, позволяющую успешно завершить промис;reject— функцию для завершения промиса с ошибкой.
То есть функции resolve и reject доступны сами по себе, и мы можем управлять выполнением асинхронного кода. Выглядит это так:
async function* readableToAsyncIterable(stream) {
// Создаём промис для ожидания события "readable"
let { promise, resolve } = Promise.withResolvers();
// Когда поток становится читаемым, разрешаем промис
stream.on("readable", () => resolve());
// Пока поток доступен для чтения
while (stream.readable) {
// Ждём, пока поток сообщит, что данные готовы
await promise;
let chunk;
// Читаем все доступные куски данных
while ((chunk = stream.read())) {
yield chunk; // Возвращаем кусок данных
}
// Создаём новый промис для следующего ожидания
({ promise, resolve } = Promise.withResolvers());
}
}Что произошло:
- С помощью
Promise.withResolvers()мы создали новый промис и функцииresolve/reject, которые управляют его завершением. - Когда поток становится читаемым (
stream.on("readable")), мы вызываемresolve, завершая текущий промис. Это позволяет двигаться дальше по циклу. - После обработки данных создаём новый промис для следующей итерации, чтобы снова ждать события
readable.
Если бы здесь не было Promise.withResolvers(), пришлось бы вручную оборачивать весь код в new Promise() каждый раз, когда нужно создать новый промис. Это сделало бы код более громоздким и сложным для чтения. Кроме того, логика управления промисами была бы заперта внутри конструктора, и функции resolve/reject нельзя было бы использовать так гибко.
Флаг /v для регулярных выражений
Флаг /v — это нововведение для работы с регулярными выражениями, особенно полезное для работы с Юникодом. Он не только расширяет возможности, но и решает некоторые проблемы, которые были у флага /u, например некорректную обработку регистра.
Вот что умеет флаг /v:
Позволяет использовать свойства символов Юникода (\p{...}) для проверки категорий символов — эмодзи, буквы определённого языка, пробелы и так далее:
// Проверяем, является ли символ эмодзи
const isEmoji = /^\p{RGI_Emoji}$/v;
console.log(isEmoji.test("💚")); // true
console.log(isEmoji.test("A")); // false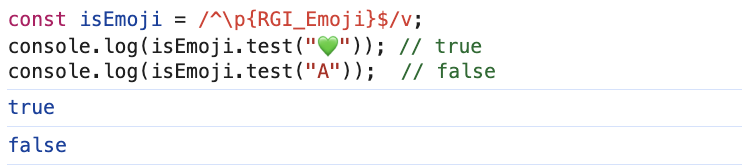
Позволяет находить символы, которые принадлежат сразу нескольким категориям, то есть использовать пересечения (&&):
// Ищем буквы греческого алфавита
const greekLetters = /[\p{Script_Extensions=Greek}&&\p{Letter}]/v;
console.log(greekLetters.test("π")); // true
console.log(greekLetters.test("1")); // false
Может исключать определённые символы из общего набора через исключение (--):
const noHearts = /^[\p{RGI_Emoji}--[💚❤️]]$/v;
console.log(noHearts.test("💚")); // false, т.к. 💚 исключён
console.log(noHearts.test("🐨")); // true, т.к. 🐨 входит в набор RGI_EmojiЭто регулярное выражение создаёт набор, затем включает все эмодзи (\p{RGI_Emoji}), а затем исключает: символы 💚 и ❤️ (--[💚❤️]).

Пайплайн-оператор
И напоследок посмотрим на конвейерный, или пайплайн-оператор |>. Он ещё не вошёл в основную спецификацию, но, скорее всего, это произойдёт уже скоро, так что поговорим про него. Основная идея — сделать код чище в тех случаях, когда функции или операции применяются последовательно.
Пайплайн-оператор — это стандартная функция функциональных языков, позволяющая «передавать» значение из одной функции в другую, при этом результат предыдущей функции используется в качестве параметра для следующей (примерно как Fetch API передаёт любые возвращаемые данные из одного промиса в другой).
Вот как такая логика выглядит в стандартном JS:
// Функция, добавляющая восклицательные знаки в конец строки
const exclaim = (str) => str + "!!!";
// Функция, добавляющая фразу "Listen up! " в начало строки
const listen = (str) => "Listen up! " + str;
// Функция, преобразующая строку в верхний регистр
const uppercase = (str) => str.toUpperCase();
// Исходная строка для преобразования
const text = "Hello World";
// Последовательное применение функций:
// 1. listen добавляет "Listen up! " к строке,
// 2. exclaim добавляет "!!!" в конец,
// 3. uppercase преобразует строку в верхний регистр.
const result = uppercase(exclaim(listen(text)));
// Вывод результата в консоль: "LISTEN UP! HELLO WORLD!!!"
console.log(result);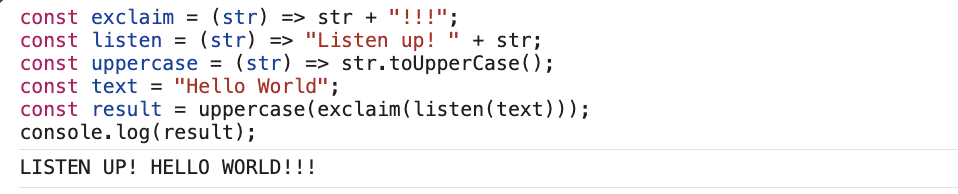
Проблема такого подхода — сильная вложенность. Чтобы понять, что происходит, нужно разбирать выполнение функций, начиная с самой вложенной.
А вот как эту задачу решил бы пайплайн-оператор:
const result = "Hello World"
|> listen(%)
|> exclaim(%)
|> uppercase(%);
console.log(result); // "LISTEN UP! HELLO WORLD!!!"С пайплайн-оператором каждая операция записывается линейно, слева направо, что делает код гораздо понятнее. Значение "Hello World" последовательно передаётся через функции listen, exclaim и uppercase, а % служит токеном-заполнителем, представляющим результат предыдущего шага.
Поскольку пайплайн-оператор ещё не вошёл в основную спецификацию, протестировать его можно с помощью Babel REPL. Для этого в настройках слева нужно включить плагин Pipeline Operator:
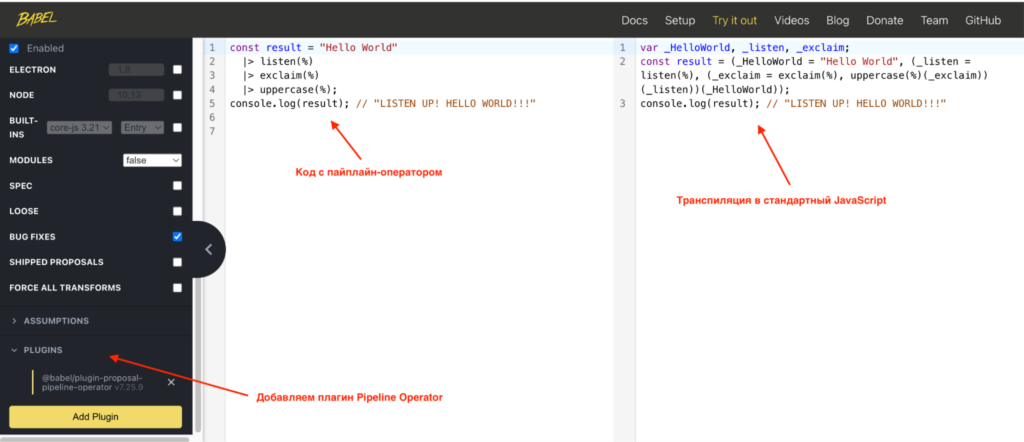
Как понять, что уже можно использовать
Пока эти возможности поддерживаются не всеми браузерами. Прежде чем использовать что-то в своём проекте, проверьте поддержку фичи на сайте Can I Use.
Также поддержку функций в окружении Node.js проверяют с помощью Node.green. Если функция ещё не поддерживается, можно использовать транспилятор Babel для преобразования кода в более старый, совместимый синтаксис.











