


Сегодня — первая часть статей из серии «Как сделать свой ChatGPT». Посмотрим на разные виды LLM — больших языковых моделей, которые разговаривают с пользователем и могут решать задачи, писать код, переводить или играть роль определённого персонажа.
Для статьи мы выбрали open-source-модели, которые можно бесплатно установить себе на компьютер и сделать локальный аналог ChatGPT. Мы расскажем про устройство таких программ и их показатели: результаты тестов, которые позволяют инженерам и простым пользователям понять, что умеет модель и насколько хорошо.
Что такое LLM и почему они важны
Большая языковая модель (large language model, или LLM) — программа машинного обучения, которая проанализировала большое количество текста и на основе этих данных научилась общаться с человеком и решать разные задачи.
За время обучения модель выстраивает нейронную сеть, похожую по принципам работы на нейроны человеческого мозга: связи между нейронами программы помогают ей понять запрос от пользователя и сформировать подходящий ответ.
Из-за объёма обработанной информации программа выводит сразу несколько направлений для разных закономерностей. Поэтому в результате может давать адекватные решения на запросы, которым напрямую не училась: по программированию, математике, ремонту, готовке, туристическим достопримечательностям. Вы можете спросить у такой модели, в каких разделах японских супермаркетов продают рис в упаковках и красную рыбу, и она даст подробные инструкции и расскажет, как задать вопрос сотрудникам магазина.
Кто такие AI-помощники
AI-помощники используют в своей работе LLM. Получается так:
- LLM — языковая модель, которая умеет генерировать текст на основе изученных данных и контекста предыдущего диалога.
- AI-помощник — система, в которой LLM является главным из компонентов. Но ещё в ней есть интерфейс, память, инструменты и логика управления.
LLM отвечает на запросы, а AI-помощник решает задачи пользователя целиком: помнит контекст, вызывает инструменты, соблюдает правила и действует по сценарию.
Ищете работу в IT?
Карьерный навигатор Практикума разберёт ваше резюме, проложит маршрут к первому работодателю, подготовит к собеседованиям в 2026 году, а с января начнёт подбирать вакансии именно под вас.
Выбор подходящей модели LLM
Если хотите посмотреть, сколько нейромоделей сегодня лежит сейчас в открытом доступе, зайдите на платформу huggingface.co. Можно выбрать LLM по задачам, языкам, лицензиям, целям:
Большинство моделей можно использовать почти без ограничений. Даже крупные компании вроде OpenAI и Google выкладывают здесь свои продукты практически без ограничений на использование, в том числе коммерческое.
Выбор модели под конкретную задачу важен, потому что нужно учитывать цели и возможности. Программы небольшого объёма проще установить и запустить, и работают они быстрее. Более тяжёлые сложные LLM рассуждают глубже и дают более стабильные и точные ответы, но для их работы нужны мощные ресурсы.
Размер модели
Обычно размер модели измеряется количеством параметров, которые обозначаются числом и буквой В (от слова billion — миллиард): 5В, 8В, 70В, 400В.
Основной объём параметров в искусственном интеллекте составляют веса (weights). Это показатели, которые определяют важность отдельных частей запроса. Например, если модель будет делать расчёт стоимости дома, то поставит высокий вес показателям «размер дома» и «месторасположение».
Ещё один важный параметр — смещения (biases). Это корректировки, которые помогают машинам лучше обучаться. Смещения влияют на выходные данные и часто работают с нулевым показателем. Например, благодаря смещениям программа выявит, что нулевой размер дома не всегда означает нулевую стоимость — например, из-за цены на землю.
Веса и смещения компьютер выводит сам. Когда модель пропускает через себя данные и анализирует их, одновременно она выстраивает взаимосвязи. Работающий с моделью человек может повлиять на эти параметры только косвенно, добавив специально обработанные данные для обучения.
Нейросеть состоит из нескольких слоёв. Входящий запрос проходит их все, пока не дойдёт до последнего и не отдаст ответ. Как примерно это работает на каждом слое:
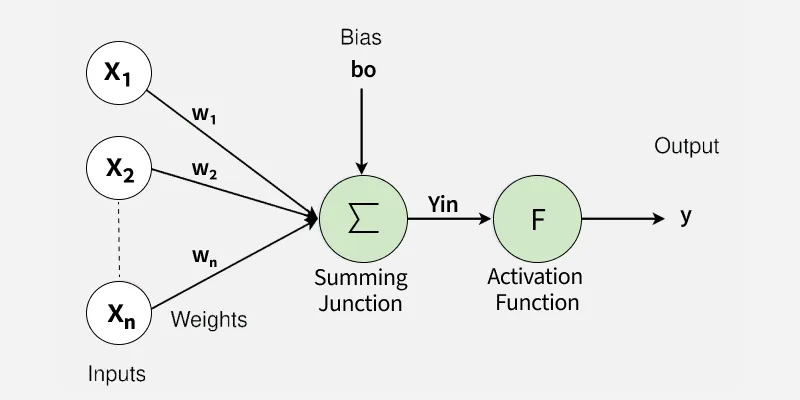
Что здесь происходит, если упрощённо:
Inputs (входные данные, запрос). Процесс начинается с поступления данных. Данные могут быть любыми: пиксели, числа, файлы музыкальной записи.
Weights (веса). Каждый нейрон модели вычисляет сумму весов входных данных. Все части входного запроса умножаются на свой вес, который показывает важность этой части.
Bias (смещение). Добавляется смещение, которое помогает сместить выходное значение.
Activation function (функция активации). Сумма взвешенных входных данных и смещения проходит через функцию активации, которая определяет, передавать ли отдельные нейроны дальше или оставить их неактивными и не учитывать.
Output (выходные данные, ответ). Весь процесс повторяется несколько раз — в зависимости от того, из скольких слоёв состоит нейросеть.
Кроме весов и смещений, есть ещё гиперпараметры. Это настройки, которые задаются человеком: особенности и количество шагов обучения, некоторые показатели внутреннего устройства модели другие технические ограничения. Модели с разными гиперпараметрами будут обучаться и в итоге работать по-разному даже с одинаковыми наборами данных, которые обработают.
Настройка модели для чата
Большинство LLM изначально обучены как базовые языковые модели — они умеют понимать запросы, но требуют дополнительной настройки для диалогов с живыми людьми. Чат-версии моделей проходят специальное дообучение, которое учит их отвечать в правильном формате и следовать системным инструкциям.
При локальном использовании в личных целях важно правильно задать все настройки и ограничения роли модели, потому что это напрямую повлияет на качество общения. Грамотно настроенная чат-модель может выглядеть как полноценный AI-помощник даже при небольшом размере.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Обзор open-source-LLM-моделей
Дальше посмотрим на несколько моделей, которые можно скачать и использовать в своих проектах, в том числе коммерческих.
Все варианты ниже — модели общего назначения, которым можно написать с любым вопросом. Но качество ответа всегда будет немного разным, в зависимости от пройденного обучения LLM.
Hermes 3 — Llama-3.1 8B
Ссылка на модель: huggingface.co
Созданная компанией Nous Research языковая модель для локальных систем с небольшими ресурсами. Хорошо работает как диалоговый ассистент и чат-бот, активно участвует в разговоре, стабильно генерирует чёткие ответы.
Hermes и Llama — две разные модели, потому что Hermes является доработанной версией от Llama. Поэтому финальная модель носит двойное название.
Вот сравнение обеих моделей при разных вариантах параметров и испытании на разных тестах. Например, AGIEval (0-shot) проверяет способность модели решать задачи уровня экзаменов, а BoolQ — вопросы из тестов с ответами «да» или «нет».
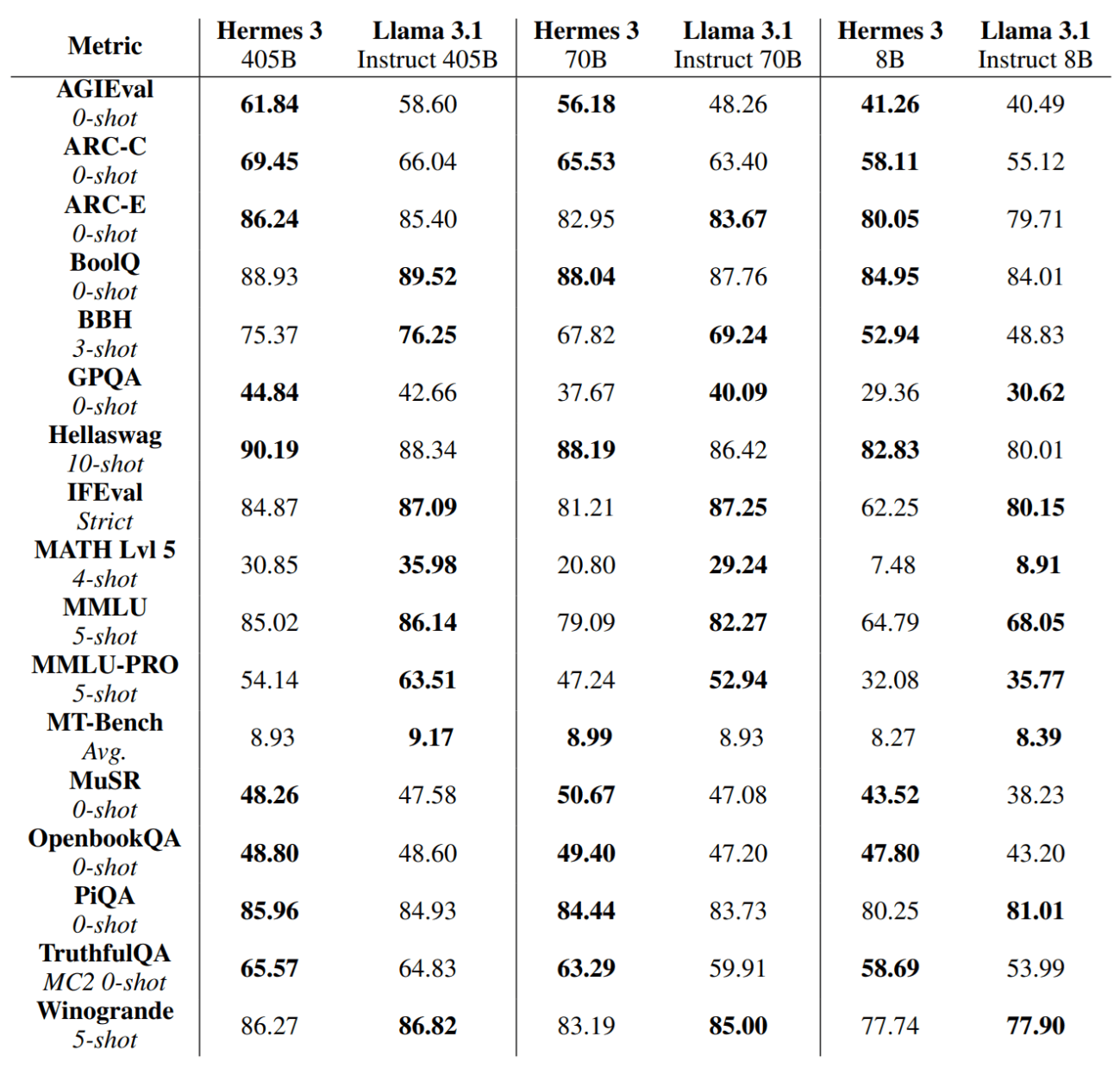
По таблице можно сделать выводы, что у модели получается хорошо, а что не очень.
Hermes 3 — Llama-3.1 8B довольно чётко понимает причинно-следственные связи, умеет рассуждать без подсказок и хорошо справляется с человеческой логикой. Модель можно использовать там, где важно живое общение.
При этом Hermes слабее других моделей в математике, строгом следовании указаниям и работе с академическими экзаменами.
Yi-1.5-9B-Chat
Ссылка на модель: huggingface.co
Оптимизированная языковая модель, специально обученная работать с кодом, диалогами и рассуждениями.
При этом она лёгкая и одна из самых умных моделей в классе 9B. У неё нет перекоса в отдельные области, например только код или только чат. Если разбирать отдельные показатели-бенчмарки, то можно сделать несколько выводов.
Диалоги и чат — самая сильная сторона.
Математика и логика развиты очень хорошо, модель подходит для сложных объяснений, обучения и задач «почему так».
Код стабильный, но не настолько высокого уровня, как у топовых кодерских моделей. Для сложной математики и программирования не подходит.
InternLM2 5-7B Chat
Ссылка на модель: huggingface.co
Чат-ориентированная LLM на 7B параметров от Shanghai AI Lab, сделанная как практичный рабочий ассистент. Её ключевая идея в максимуме пользы при умеренном размере.
Если смотреть по результатам тестов, получается так.
Логика у InternLM2 5-7B Chat развита лучше всего. Модель умеет думать, погружаться в контекст разговора, решать сложные логические задачи и думать по шагам, делать выводы на основе известных фактов.
Математика для такой небольшой модели развита очень сильно, она хорошо умеет объяснять решения и обучать.
Анализ больших документов — ещё одно сильное преимущество, InternLM2 5-7B Chat может найти нужный факт в огромном объёме информации.
Ещё модель хорошо работает с мультиязычными документами и хорошо понимает китайский контекст: административные структуры, образовательную систему, научные источники. Это потому, что программа обучалась на большом количестве китайских данных. Если вам нужен анализ учебных и научных китайских текстов или ассистент по азиатскому рынку, обязательно попробуйте InternLM2 5-7B Chat.
Где уступает другим моделям: живой диалог и код.
Humanish-Roleplay-Llama-3.1-8B
Ссылка на модель: huggingface.co
Разговорная модель для креативных задач, которая умеет:
- отвечать за реплики персонажей в играх, визуальных новеллах, интерактивных историях;
- участвовать в ролевом чате, импровизации сцен;
- разговаривать в чатах в качестве развлекательных ассистентов.
Хуже подходит для кода, математики, работы с документами и других вещей, где требуется строгое выполнение задач. У модели другая цель — исполнять роль разных персонажей. Поэтому она обучена на большом количестве диалогов с естественной разговорной манерой, и это отражается в её работе.
OpenChat-3.5-1210
Ориентирована на чат, код, математику и логическое мышление. Главная идея проекта — сделать open-source-модель, которая ведёт себя как ChatGPT, но при этом доступна локально и без ограничений по лицензии.
Теперь — что говорят тесты.
Код действительно сильный, это одно из главных преимуществ модели. OpenChat-3.5-1210 не специализированная программа для кода, но хороший инженерный чат с объяснением скриптов, алгоритмов и поиском ошибок.
Логика хорошо развита, но не так хорошо, как, например, у InternLM2 5-7B.
Диалоги и чаты стабильного уровня выше среднего.
Получается, что это самая удобная модель для повседневного использования с бесплатной лицензией. Другое преимущество для разработчиков — OpenAI-совместимый API. Если у вас уже есть код OpenAI-модели, подключить и настроить OpenChat-3.5-1210 становится намного проще.
Для узкоспециализированных вещей модель работает уже не так хорошо: сложная математика, длинный контекст диалога, ролевые персонажи, китайские источники — для этих задач лучше подойдут модели, обученные специально под эти задачи.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.
Как устанавливать и запускать open-source-модели с Hugging Face
Пока что рассказываем упрощённый план, чтобы не перегружать сложностями.
То, что лежит по ссылкам в открытых источниках, например Hermes и OpenChat, — не готовые модели для использования. Это наборы параметров: архитектура, веса, смещения. Чтобы сделать свой ChatGPT, программисту нужно взять эти настройки и аккуратно переложить на подготовленное окружение.
Необходимое окружение чаще всего включает Python, Git, платформу для использования графического процессора и несколько дополнительных библиотек, которые используются в коде. Ещё для большинства моделей 7–9 В нужен графический процессор с 16–24 гигабайтами видеопамяти.
Чтобы модель из Hugging Face или другого источника стала настоящим чатом, а пользователи могли разговаривать с моделью, нужно настроить формат сообщений, движок для обработки запросов и интерфейс. Многие проекты предлагают инструменты, чтобы пройти этот этап быстрее. Например, готовый сервер с OpenAI-совместимым API.
Когда разработчик запускает код, модель скачивает параметры и перекладывает их на движок. Модель и движок должны иметь одинаковые настройки: количество слоёв, устройство вычислений и логику генерации ответов.
Под движком часто объединяют всё, что нужно для запуска модели. Вот упрощённая общая схема:
- Для запуска модели нужно установить и настроить движок, который будет поддерживать устройство модели: архитектуру, формат весов, токенизацию.
- Устройство движка и модели должны совпадать. Представьте, что модель — это набор деталей разных форматов, которые нужно положить в заготовленные пазы. Движок — это платформа с такими пазами.
- После скачивания модели она переносит в движок все настройки-веса, которые позволяют итоговой LLM работать.
- Для физически осязаемой работы с моделью понадобится интерфейс общения.
- Чтобы всё это было проще сделать, для некоторых проектов можно использовать готовые движки с работающими серверами, где всё уже настроено.
В следующий раз разберём подробнее процесс установки и запуска модели и то, что из этого может получиться.











