Сегодня поговорим о дата-аналитике в бизнесе и разберём, как работают компании с большими объёмами информации. Главная тема статьи — OLAP-кубы, сложные системы для построения аналитических отчётов из Big Data.
Это — жёсткая и хардовая теория, которая нужна далеко не всем в ИТ. Её можно не знать — и быть отличным разработчиком всю свою карьеру. Но если вы смотрите в сторону аналитики, то это точно пригодится, чтобы вырасти в профи.
Какая информация используется в аналитике данных
Чтобы развиваться, бизнесу нужны данные про себя: какие идеи работают, что продаётся, какие пользователи регистрируются.
Видов информации может быть очень много, и приходит она из разных источников: метрики сайта, базы данных, CRM-системы. Пока информация просто собирается в одном месте, она не имеет структуры и может быть в любом виде: строки, числа, изображения. Такая информация называется сырой.
Чтобы информацию можно было использовать для аналитики, её нужно обработать: исправить ошибки в записях, привести к одному виду, собрать вместе данные разных типов. Такая информация будет обработанной.
В аналитике используют оба типа данных, и дальше мы расскажем, как именно.


Как с ней работают
После обработки данных их можно загружать в хранилища. Этот процесс называют сокращённо ETL, от английского Extract-Transform-Load, или, в переводе, извлечение — обработка — загрузка.
В начале развития компании информацию можно просто копировать и сохранять в разных Excel-таблицах вручную, но с ростом бизнеса успевать следить за этим становится невозможно. Процесс сбора всей информации автоматизируют через ETL-инструменты.
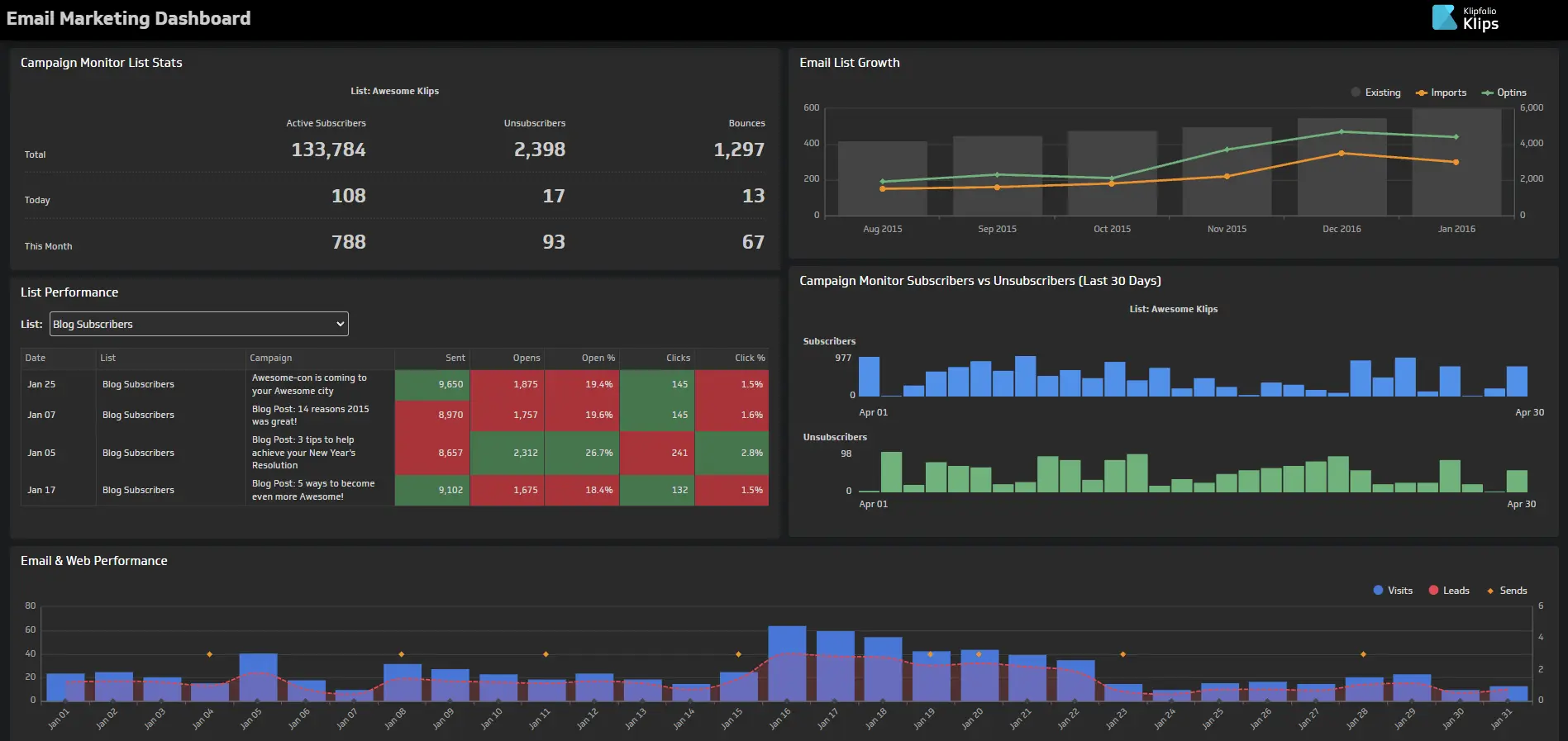
Обработанные сохранённые данные можно подключить к системе Business Intelligence (BI-системе). Это удобный визуальный интерфейс, средство для быстрого построения наглядных графиков, просмотра показателей и в целом работы с аналитикой.
Пример одной из таких систем — Klipfolio:




Почему данные отправляют в разные хранилища
Способ использования данных может быть различным, а в зависимости от использования будут различаться и способы хранения этих данных.
Обычные базы данных хорошо подходят для быстрых небольших операций, которые изменяют информацию в базах. Это может быть регистрация нового пользователя, смена пароля или внесение изменений в список товаров на складе.
Такие операции ещё называют транзакциями, а сами базы данных — транзакционными. MySQL, PostgreSQL и SQLite — примеры транзакционных баз данных. Они хранят информацию и позволяют динамически изменять её.
Но аналитики работают по-другому. Им не нужно часто вносить много точечных изменений, вместо этого они обрабатывают биг-дату — большие сложные объёмы информации. Например, нужно использовать отчёты и данные из нескольких источников для построения одной сводной таблицы или графика для наглядного представления данных.
Сводная таблица собирает данные из обычных таблиц, суммирует и группирует по блокам.


Аналитикам нужно проверить много гипотез и найти правильный вопрос, ответ на который поможет бизнесу вырасти. Такими вопросами могут быть:
- Как распределятся продажи товаров по разным регионам в разное время года?
- На какую часть сервиса чаще всего поступают жалобы от пользователей?
- Сколько денег компания тратила на каждое из своих подразделений в последний год? А последние 3 года? А последние 10 лет?
Для ответов на такие вопросы могут понадобиться данные разного формата и из разных отчётов: продажи, географическое распределение, демографические отчёты.
Всё это называется многомерным анализом. Обычные таблицы могут показать только средние числа или только одно измерение. Это даёт общее понимание, но без подробностей. Например, на примере ниже мы видим, что средние показатели продаж газировки равны по всем регионам продаж, продуктам и сезонам:
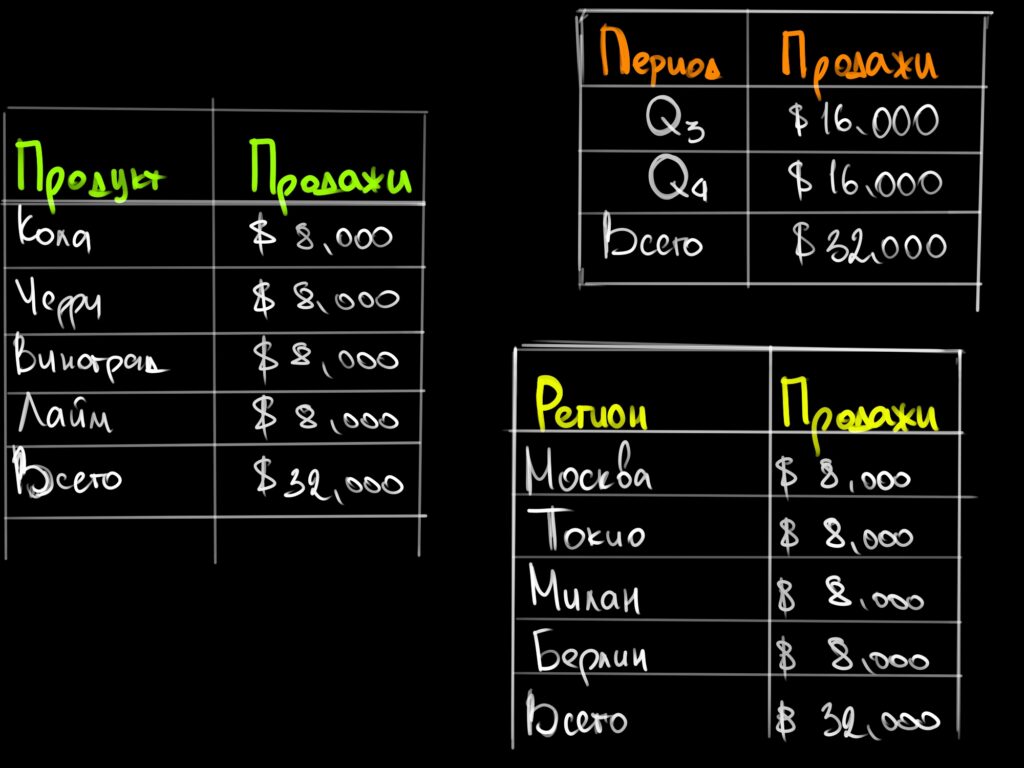
Многомерная таблица позволяет сделать срез состояния сразу в нескольких областях и найти важные подробности. Например, увидеть, что какой-то из продуктов не продаётся в определённые сезоны в определённых регионах:

Для таких задач можно использовать и транзакционные базы данных, но они предназначены для другого, аналитическая работа будет идти очень медленно. Поэтому вместо обычных баз данных используют хранилища данных (data warehouse).
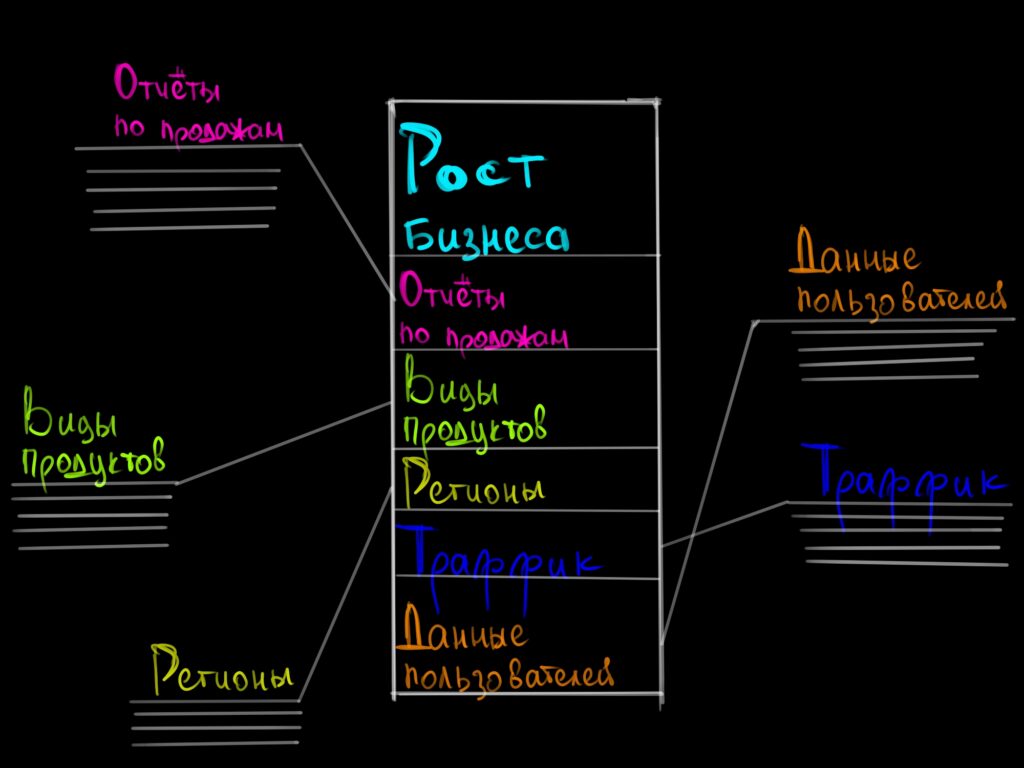
Хранилища оптимизированы для структурирования и работы с данными разного формата. Эти данные попадают в таблицы, между которыми устанавливаются связи. Теперь, если аналитику нужно достать информацию из нескольких разных таблиц, он сможет сделать это быстро. Примеры хранилищ данных: Google BigQuery, Amazon Redshift, Snowflake.
Обычно в хранилищах есть центральная таблица, которая хранит всю основную информацию, и аналитики работают с ней. Такие схемы устройства называются «Звезда» или «Снежинка»:
Ещё есть озёра данных. Это хранилища, куда помещают ещё не отфильтрованную информацию. Иногда аналитикам данных и специалистам Data Scientist нужно посмотреть на все данные, с которыми можно работать, и хранилищ данных для этого может быть недостаточно, потому что туда попадают уже обработанные материалы.
Что такое OLAP и OLTP
В аналитике при работе с данными есть два похожих понятия, сначала разберём их.
OLTP — сокращение от Online Transaction Processing, или обработка онлайн-транзакций. OLTP-системы работают с короткими транзакциями. Налаженная система обработки платежей, заказов, создания собственных продуктов или отслеживания состояния своего аккаунта в интернет-магазине или банке — это OLTP-система.
Для OLTP-систем подходят транзакционные базы данных.
OLAP-система — сокращение от Online Analytical Processing, онлайн-аналитическая обработка. Это набор комплексных инструментов для аналитики сводных таблиц. OLAP нужна для сложных комплексных запросов, которые требуют работы с большим количеством данных.
Для OLAP-систем чаще всего используются хранилища данных.
Будет неправильно сказать, что базы данных совсем не подходят для аналитики. Есть специализированные аналитические БД, которые спроектированы с учётом потребностей обеих систем, и их можно использовать для обеих целей. Но специализированные инструменты — лучше.
Из чего состоит OLAP-система
Для онлайн-аналитической обработки нужно подготовить и настроить несколько компонентов.
- Хранилище данных, в которое попадает и где структурируется обработанная очищенная информация.
- Сервер, на котором хранится программное обеспечение и хранилища данных.
- ETL — настроенные процессы извлечения, обработки и загрузки данных в хранилища данных. Эти процессы могут потребовать разных инструментов, например для сбора потоковых данных или интеграции всех инструментов между собой.
- Инструменты аналитики для взаимодействия пользователей с хранилищем данных.
Если собрать всё вместе, получится OLAP-система.
Что такое OLAP-куб
В списке элементов OLAP-системы нет OLAP-куба, потому что куб — это просто абстракция для лучшего понимания всей технологии. В реальности никакого куба нет, есть просто сложно выстроенная взаимосвязанная между собой сеть данных.
Обычная таблица для аналитики состоит из двух измерений, например из продаж и региона. Это похоже на плоский квадрат:

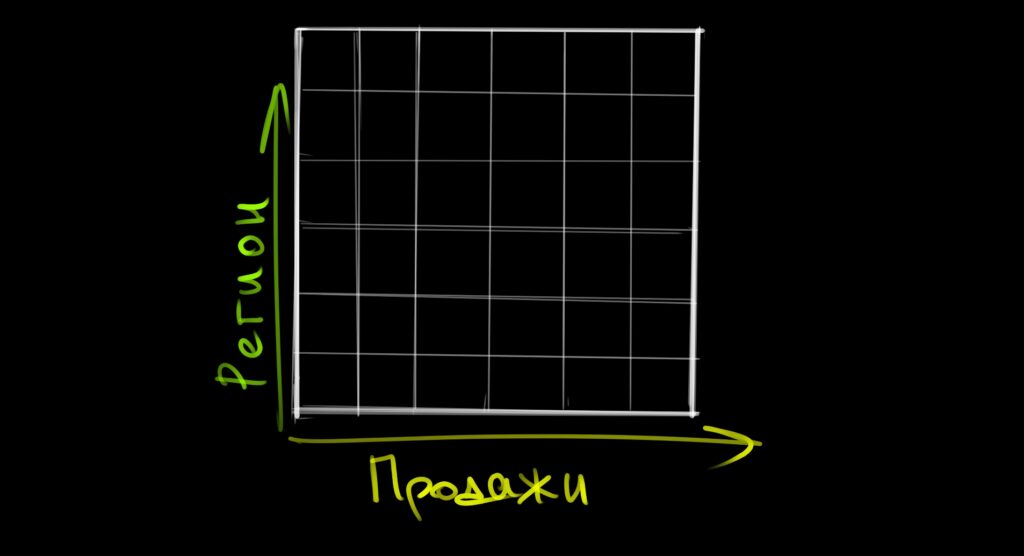
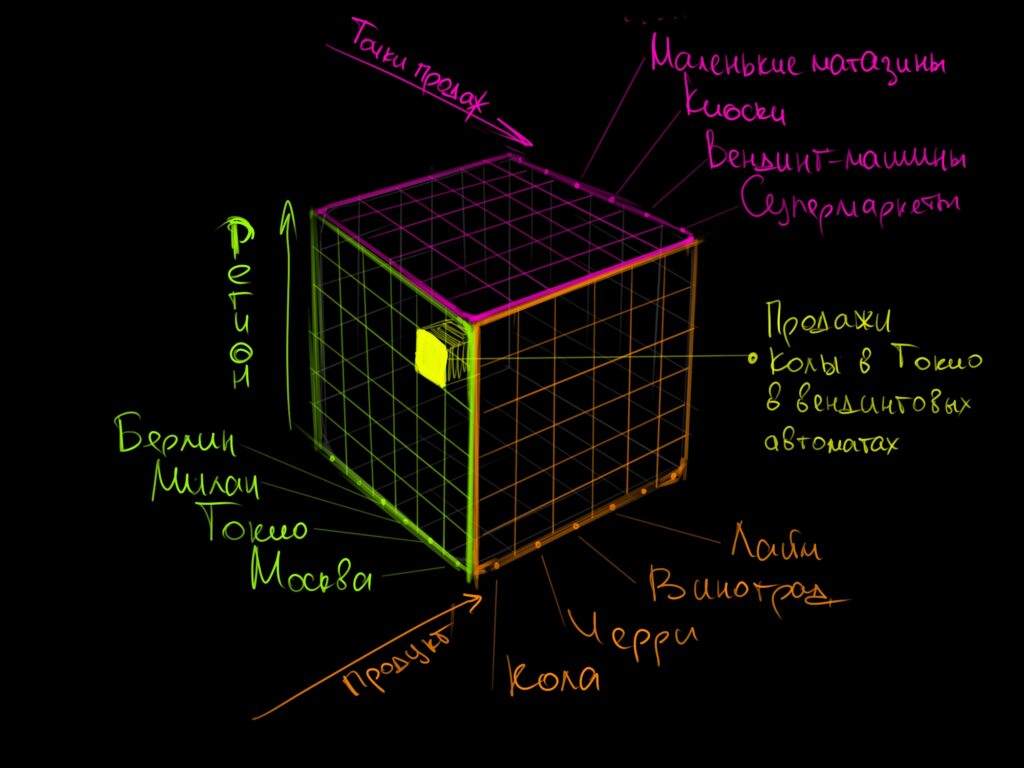
OLAP-таблица на основе информации из хранилища данных может включать любое количество измерений, которые можно связать между собой. Если использовать три измерения, это будет похоже на трёхмерный куб — но правильнее сказать, что в OLAP-кубе может быть любое количество граней, а внутри него находится ядро, которое понимает связи между всеми этими гранями:
Какие типы OLAP существуют
Есть несколько моделей OLAP-систем.
MOLAP. Сокращение от Multi-dimensional Online Analytical Processing (многомерная онлайн-аналитическая обработка). В этом варианте для хранения и анализа данных используются многомерные базы данных MDDB.
MOLAP-куб статичный, он состоит из данных, которые вычисляются и готовятся заранее. Это увеличивает скорость работы данных и позволяет быстро получить срез по нескольким таблицам или провести сложные вычисления. Но объём данных в MOLAP ограничен, а ещё возможности анализа зависят от заранее установленных требований.
ROLAP. Означает Relational Online Analytical Processing (реляционная онлайн-аналитическая обработка). Данные хранятся в обычной реляционной базе данных, но выдаются конечным пользователям в многомерной форме.
Инструменты аналитики динамически создают ROLAP-куб, поэтому объём данных для него не ограничен — но динамическая работа идёт медленнее, а из-за работы с реляционными базами данных вместо хранилищ ROLAP-система может быть очень медленной, особенно при работе со сложными вычислениями и большим объёмом данных.
HOLAP. Hybrid Online Analytical Processing, гибридная онлайн-аналитическая обработка.
HOLAP объединяет преимущества двух первых способов и устраняет их недостатки. Данные хранятся в двух местах сразу: хранилище данных и базе данных. Этот вариант требует сложной архитектуры, сервера с поддержкой ROLAP и MOLAP и частого обслуживания. Зато HOLAP-куб может хранить огромные объёмы данных, масштабироваться и работать быстрее реляционных баз данных.
Преимущества OLAP
Строить OLAP-системы может быть сложно и дорого, но иногда такие затраты многократно окупаются из-за большого количества преимуществ.
- Пользователи системы могут просматривать все собранные данные в одном месте и работать с ними через один комплексный инструмент.
- MOLAP-часть материалов неизменна, обработана заранее и доступна для быстрого анализа, а это могут быть огромные массивы данных.
- OLAP-кубом могут пользоваться не только аналитики, но и вообще все, кому нужно поработать со статистикой и хранящимися в системе показателями.
- Правильная организация системы позволит увидеть неочевидные скрытые зависимости одних рабочих процессов от других.
- Информация в OLAP-кубе может быть детализирована для быстрого понимания зависимостей разных показателей между собой.
Где используется OLAP
OLAP-куб отлично подходит для задач аналитиков данных, которым нужно смотреть на данные под разными углами. Чем больше удаётся собрать информации и настроить правильные взаимосвязи между разными типами данных, тем больше вероятность увидеть что-то полезное и неочевидное.
Кроме аналитики, OLAP идеально подходит для функций бизнес-отчётности, например финансового анализа, бюджетирования или прогнозирования продаж.
Чем больше данных разного типа присутствует в задаче — тем лучше для неё подходят OLAP-системы. Например, для финансовой модели небольшого бизнеса OLAP-куб можно построить в обычном Excel, используя систему формул и связав ячейки из разных листов документа. После этого можно по-разному изменять данные и смотреть, что будет, если:
- увеличить или снизить цены на товары;
- сократить сроки кредиторской или дебиторской задолженности;
- убрать одну из линеек товаров или заменить другой;
- сменить поставщика;
- изменить сроки доставки.
OLAP-система может быть полезна не только для чистых финансовых бизнес-целей. Любая крупная организация с большим количеством показателей разного характера может использовать онлайн-аналитическую обработку и лучше узнать себя.
Например, вуз может создать и поддерживать OLAP-куб с большим количеством пересекающейся между собой информации:
- списки студентов за разные года;
- успеваемость каждого;
- показатели успеваемости по преподавателям;
- количество отчисленных и взявших академический отпуск за разные периоды;
- проходные баллы по специальностям и количество поступивших на бюджетную и коммерческую формы обучения.
Если взять крупный вуз и его данные за 10–15 лет, количество информации будет огромным, так что ни одна транзакционная база данных не справится с задачами аналитики. С OLAP-системой у аналитиков будет пространство для проверки и тестирования гипотез и удобный работающий инструмент.
Кто всем этим занимается
Аналитики выявляют закономерности и ищут ответы на вопросы компаний, для которых строят OLAP-кубы. Но они работают чаще всего с уже готовыми выстроенными системами.
А вот свести все данные так, чтобы они имели правильные связи и одни таблицы правильно реагировали на изменения в других таблицах, — это другая задача, которой занимаются бэкенд-разработчики и инженеры данных.
Инженеры данных совмещают работу аналитиков и технологов, пишут код и работают с базами и другими хранилищами данных. Они настраивают автоматический сбор и обработку данных и следят, чтобы аналитики и специалисты Data Scientist имели доступ ко всей нужной информации.
Если тоже хотите понять такие крутые сложные штуки и научиться строить их, посмотрите на программу «Инженер данных» в Практикуме и на остальные курсы. Можно почитать, что входит в обучение, и попробовать бесплатную часть на любом треке. Так можно лучше понять, что это такое и чем предстоит заниматься на обучении и на будущем месте работы.