








Представьте себя на месте аналитика данных в крупном маркетплейсе. Команда дизайнеров обновила кнопку «Купить» на сайте: раньше она была синей, теперь стала ярко-оранжевой. Через неделю появились свежие данные по продажам. Вы видите, что со старой кнопкой средний чек был 2500 рублей, а с новой — 2650 рублей.
Похоже на успех, но не спешите радоваться — в статистике всё не так просто. Разница в 150 рублей может быть простой случайностью. Вдруг на этой неделе просто выросли цены на ходовой товар или был праздник и люди решили себя побаловать?
Чтобы понять, значима ли эта разница, аналитики используют специальный статистический инструмент — t-тест, он же критерий Стьюдента. Разберёмся, как этот метод работает, зачем он нужен и как его посчитать на Python и R.
Что такое t-тест
T-тест (или t-критерий Стьюдента) — это тест, который позволяет определить, есть ли статистически значимая разница между двумя группами средних значений.
Ключевое слово здесь — «статистически значимая». То есть достаточно большая, чтобы появиться случайно.
Фан факт: t-тест разработал Уильям Госсет, который работал химиком на пивоварне Guinness в Дублине. Guinness запрещала своим сотрудникам публиковать научные статьи под своими именами, чтобы не раскрывать производственные секреты. Поэтому Госсет опубликовал свою работу под псевдонимом Стьюдент (Student).
Для чего нужен t-критерий Стьюдента
T-критерий нужен, чтобы принимать взвешенные решения на основе данных. Например, с помощью критерия Стьюдента можно проверять разные гипотезы:
- Стала ли новая рекламная кампания приносить больше лидов?
- Увеличила ли новая система рекомендаций среднее время пребывания пользователя на сайте?
- Тратят ли больше внутриигровой валюты те игроки, которые прошли обучение?
- Новое лекарство снижает артериальное давление сильнее, чем плацебо?
T-тест даёт уверенность в том, что разница — результат изменения, а не случая.




Виды t-теста и условия их применения
Есть три основных вида t-теста. Какой выбрать, зависит от того, какие именно группы данных нужно сравнить.
Одновыборочный t-тест
Подойдёт, когда нужно сравнить среднее значение одной выборки с заранее известным значением.
Пример. На заводе по производству сока автомат должен разливать ровно 1000 мл в каждый пакет. Берём 30 пакетов из партии, измеряем объём сока и решаем проверить, не отклоняется ли средний объём в этой партии от стандарта в 1000 мл.
Парный t-тест
Пригодится, чтобы сравнить средние одной и той же группы, но в разное время или в разных условиях. Иначе говоря — наблюдения в двух группах зависимы. Чаще всего это классическая схема «до — после».
Пример. Группа студентов проходит тест по математике. Затем они посещают интенсивный курс по предмету и снова проходят тест. Нужно сравнить средний балл группы «до» обучения и «после», чтобы оценить эффективность курса. В этом случае значение каждого студента «до» жёстко связано с его же значением «после».
Двухвыборочный t-тест для независимых выборок
Наш лучший друг, когда нужно сравнить средние значения двух независимых групп. Пациенты из группы А не связаны с пациентами из группы Б; пользователи мобильного приложения на Android не связаны с пользователями на iOS.
Пример. Нужно сравнить среднюю зарплату Python-разработчиков и Java-разработчиков в Москве. Это две разные группы людей, они не связаны друг с другом. Значения одной группы не влияют на значения другой. И эталона, как в одновыборочном тесте, нет.

Когда применять t-тест
Нельзя просто взять и прогнать любые выборки через t-тест. Он требует соблюдения нескольких важных условий: нормальное распределение данных, равенство дисперсий для независимых выборок и независимость наблюдений.
Нормальное распределение данных
Если вы не знаете, что за «нормальное распределение», то загляните в нашу статью и возвращайтесь. Мы подождём :)
Желательно, чтобы данные в каждой выборке соответствовали нормальному распределению. Мы говорим «желательно», потому что t-тест довольно устойчив к небольшим нарушениям нормальности, особенно если в выборке больше 50 значений.
В этой ситуации нас страхует центральная предельная теорема: распределение выборочных средних стремится к нормальному, даже если сами исходные данные распределены иначе.
Но на совсем маленькой выборке (<10 значений) с сильно скошенными данными такой фокус не пройдёт.
Равенство дисперсий для независимых выборок
Дисперсия — это мера разброса данных вокруг среднего. Например, в выборках {5, 6, 7} и {2, 5, 11} среднее равно 6, но значения распределены по-разному.
Это требование актуально только для двухвыборочного t-теста для независимых выборок. Если две группы имеют сильно разную дисперсию, классический t-тест выдаст ошибку. В этом случае используют модификацию, t-критерий Уэлча. Он умеет работать с разными дисперсиями.
Независимость наблюдений
Наблюдения внутри каждой выборки не должны быть связаны друг с другом. Также выборки должны быть независимы между собой (если это не парный t-тест). Здесь мы говорим о дизайне исследования, а не о вычислениях.
Представьте, что мы решили проверить гипотезы и узнать, кто быстрее печатает: бэкенд-разработчики или фронтендеры.
Для группы бэкендеров позвали 100 разных человек, посадили их за компьютеры и замерили скорость каждого. У нас 100 независимых наблюдений. Всё честно.
А для группы фронтендеров почему-то взяли одного стажёра Васю и заставили его пройти тест на скорость 100 раз подряд. В таблице данных у нас вроде бы всё красиво: 100 строчек для бэкенда и 100 строчек для фронтенда. Но во второй группе данные жёстко зависимы — это всё один и тот же бедолага-Вася.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами, и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
T-тест и z-тест — когда какой использовать
Часто возникает путаница между t-тестом и z-тестом. Оба сравнивают средние. В чём разница?
Z-тест работает, только когда мы знаем истинную дисперсию всей генеральной совокупности (то есть разброс данных вообще всех наблюдений в мире, а не только нашей маленькой выборки).
В реальной жизни такой сценарий встречается редко. Мы не знаем разброс зарплат всех программистов планеты и выручки всех маркетплейсов в «Чёрную пятницу». Поэтому z-тест используется крайне редко, в основном в академических задачках из учебников.
Главная фишка t-теста: он умеет отлично работать на малых выборках. Но есть одно условие, о котором мы говорили выше: если выборка маленькая, сами данные не должны содержать аномалий. Если данные в порядке — t-тест справится даже с пятью наблюдениями.
T-тест Стьюдента: формула расчёта
Заглянем под капот. Помните, что не обязательно считать всё вручную, за вас это сделает компьютер, но понимать логику полезно.
Задача любого t-теста — посчитать так называемую t-статистику — это одно число. Общий принцип расчёта t-статистики будет выглядеть как-то так:


Пока что выглядит абстрактно, поэтому определим, что для нас полезный сигнал, а что — шум. Если вспомнить, что t-тест нужен, чтобы определить, случайна ли разница между средними результатами, то получится конкретизировать:


Теперь разберём, что это значит для разных видов t-теста.
Формула одновыборочного t-теста
Вспомним пример с соконаливалкой на заводе. В этом случае разница средних — это среднее объёма из выборки пакетов минус стандартное значение (1000 мл).
Формула расчёта будет выглядеть так:

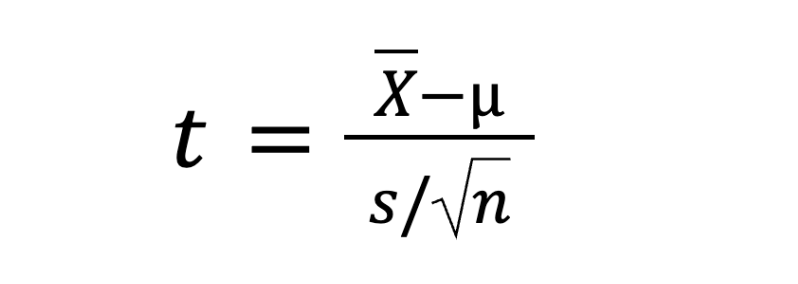
Где:
X — среднее выборки
μ — стандартное (или эталонное) значение
s — стандартное отклонение выборки
n — объём выборки
Давайте расшифруем. Допустим, мы измерили 30 пакетов, и средний объём получился 995 мл. Значит, в числителе у нас 995–1000 = –5. Автомат немного недоливает.
Но насколько эти 5 мл критичны? Всё зависит от знаменателя (шума). Если автомат наливает нестабильно: в одном пакете 950 мл, а в другом 1040 мл — это огромный разброс. Знаменатель получится большим, он «съест» нашу разницу в 5 мл, и t-статистика будет маленькой. Тест скажет: «Тут и так всё прыгает, так что ваши 5 мл — это в пределах нормы».
А вот если автомат наливает суперстабильно, по 994–996 мл, то разброс минимальный. Знаменатель будет крошечным, дробь выдаст огромное значение t-статистики, и проверка гипотезы приведёт к выводу, что автомат стабильно недоливает.
Формула для независимых выборок
Перейдём к варианту, когда у нас есть две независимые группы. Вспомним наш маркетплейс и A/B-тест кнопок. Здесь нам нужно сравнить их между собой. Формула классического теста Стьюдента (когда мы верим, что разброс чеков в обеих группах одинаковый) выглядит так:

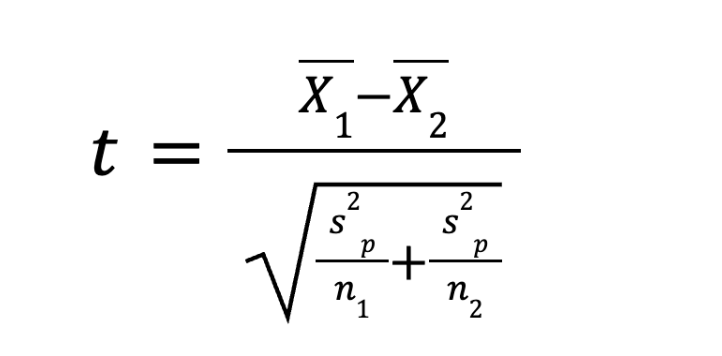
Немного потерпите, скоро расшифруем. Но сначала рассмотрим формулу критерия Уэлча, когда дисперсии разные. Формула почти такая же, но она берёт дисперсию каждой группы по отдельности:

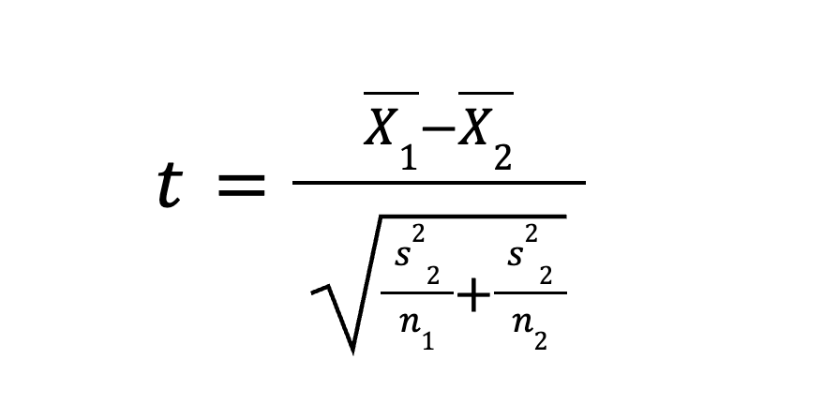
Логика всё та же: числитель против знаменателя. В числителе мы вычитаем средний чек серой кнопки из среднего чека оранжевой (например, 2650 – 2500 = 150 рублей). Это наш полезный сигнал.
А в знаменателе мы суммируем шум из обеих групп. Мы берем дисперсию первой выборки (s₁²), делим на количество покупателей в ней (n₁), прибавляем то же самое для второй группы и извлекаем корень. Обратите внимание на знаменатель: чем больше пользователей мы приведём на сайт (n₁ и n₂), тем меньше будет математический «шум», и тем легче метод сможет поймать даже микроскопическую, но реальную разницу в чеках.
Формула парного t-теста
Напомним, это тест для одной выборки в разных условиях. Допустим, мы измеряли скорость работы 15 разработчиков до того, как пересадили их на новые мощные ноутбуки, и после.
Формула парного t-теста:

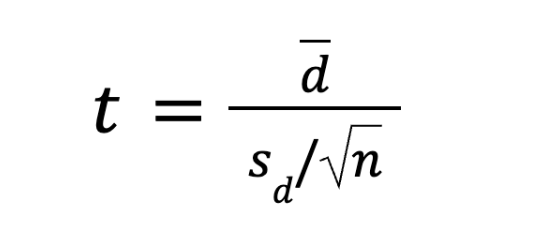
Вместо того чтобы сравнивать две огромные кучи данных, мы вычисляем разницу (дельту) для каждого конкретного человека. Вася стал писать код на 10 строк в час быстрее, Петя — на 5, а Маша отвлеклась на новый экран, и её скорость упала на 2.
Мы собираем эти персональные разницы в одну новую выборку. Буква d (от слова difference) — это как раз среднее арифметическое этих улучшений. В идеальном мире, если новые ноутбуки никак не влияют на работу, средняя разница должна болтаться возле нуля.
Поэтому мы берём эту новую выборку разниц. Если среднее улучшение сильно отличается от нуля на фоне общего разброса (sd), значит, статистический тест подтверждает: новые ноуты реально ускоряют команду.
Раз мы сравниваем выборку с нулем, то иногда встречается такая формула парного t-теста:

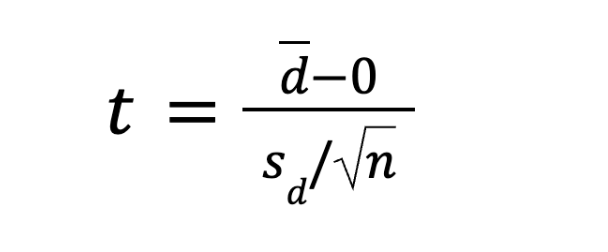
Если увидите такую формулу, то не удивляйтесь — это формальное напоминание, что среднее, как и в других t-тестах, мы с чем-то сравниваем. Просто в парном варианте мы сравниваем с 0.


Пошаговый пример расчёта t-теста для независимых выборок
На практике для t-тестов нужны гипотезы. На примере с цветом кнопки для маркетплейса сформулируем нулевую и альтернативную гипотезы:
Нулевая гипотеза (H1). Средний чек в обеих группах одинаков. Разница случайна. Дизайнеры зря старались.
Альтернативная гипотеза (H2). Средние чеки в группах А и Б отличаются. Оранжевая кнопка дала реальный эффект. Дизайнерам — бонус.
Как мы определим, насколько должен быть весомым результат t-теста, чтобы мы уверенно приняли одну из гипотез? Для этого вводят уровень значимости, который обычно обозначают . Обычно его берут равным 0.05 (или 5%). То есть, мы готовы отвергнуть нулевую гипотезу, только если вероятность её истинности меньше 5%.
Теперь перейдём к практике. Аналитики редко считают руками, ведь есть специализированный софт. Разберёмся, как провести t-тест при помощи распространённых среди аналитиков языков программирования — Python и R.
Python
Для Python существует мощная библиотека scipy, в которой есть всё необходимое. Мы сгенерируем синтетические данные для примера.
# импортируем библиотеку для работы с массивами
import numpy as np
# импортируем модуль stats из scipy для статистических тестов
from scipy import stats
# сгенерируем данные для группы А (серая кнопка)
# средний чек 2500, стандартное отклонение 500, 100 заказов
group_a = np.random.normal(loc=2500, scale=500, size=100)
# сгенерируем данные для группы Б (оранжевая кнопка)
# средний чек 2650, стандартное отклонение 550, 110 заказов
group_b = np.random.normal(loc=2650, scale=550, size=110)
# выведем средние для наглядности (они будут отличаться от заданных из-за случайности)
# print('Средний чек группы А:', np.mean(group_a))
# print('Средний чек группы Б:', np.mean(group_b))
# Проведём двухвыборочный t-тест для независимых выборок
# scipy по умолчанию использует критерий Уэлча (equal_var=False)
# это более безопасный вариант, если мы не уверены в равенстве дисперсий
t_statistic, p_value = stats.ttest_ind(group_a, group_b, equal_var=False)
# выведем результаты t_статистики
print('T-статистика:', t_statistic)
# выведем p_value
print('P-value:', p_value)Консоль выведет:
Средний чек группы А: 2507.245029926899
Средний чек группы Б: 2694.360230186777
T-статистика: -2.7116944435057015
P-value: 0.007260572053204483
Чуть позже мы расскажем, что означают эти цифры, а пока посмотрим, как сделать те же расчёты на языке R.
R
R — это язык, созданный статистиками для статистиков. Здесь двухвыборочный t-тест делается одной командой.
# Генерируем данные первой группы (средний чек 2500, стандартное отклонение 500, 100 заказов)
group_a <- rnorm(100, mean = 2500, sd = 500)
# Генерируем данные второй группы (средний чек 2650, стандартное отклонение 550, 110 заказов)
group_b <- rnorm(110, mean = 2650, sd = 550)
# Проводим t-тест Уэлча (R использует его по умолчанию, equal.var = FALSE)
# Используется синтаксис формулы: переменная_результата ~ переменная_группировки
# Для двух независимых векторов: t.test(вектор1, вектор2)
result <- t.test(group_a, group_b)# Выводим полный отчёт о результатах
print(result)Вывод в консоль следующий:
Welch Two Sample t-test
data: group_a and group_b
t = 0.010208, df = 207.95, p-value = 0.9919
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-134.4033 135.8024
sample estimates:
mean of x mean of y
2585.917 2585.218
Как интерпретировать результаты t-теста
Компьютер выдал нам результаты, но бизнесу сами по себе эти цифры ничего не скажут. Наша задача как аналитиков — перевести их на человеческий язык.
Давайте разберём выдачу наших скриптов. Вы наверняка заметили, что результаты в Python и R у нас получились совершенно разными. И это отличный повод посмотреть на оба классических сценария A/B-тестирования: когда гипотеза подтвердилась и когда с треском провалилась.
Небольшая ремарка: результаты разошлись, потому что мы генерировали случайные данные в обеих программах, не фиксируя так называемый seed (зерно случайности). Python и R создали для нас две разные виртуальные реальности, и это круто для учёбы. Но в вашей реальной работе датасет будет один, и ответ тоже будет один.
Что такое p-value
P-value — это вероятность получить такую же (или ещё большую) разницу между чеками чисто случайно, при условии, что на самом деле цвет кнопки ни на что не влияет (то есть если верна нулевая гипотеза). Главное правило аналитика: мы берём полученное p-value и сравниваем его с нашим заранее заданным уровнем значимости (, который равен 0.05).
Сценарий 1: Победа дизайна (результаты из Python)
В Питоне p-value составил 0.0072. Это примерно 0.7%. Вероятность того, что разница в чеках (2694 рубля против 2507 рублей) произошла из-за случайного наплыва щедрых покупателей — меньше одного процента. Это ничтожно мало.
Раз наше p-value меньше порога строгости (0.0072 < 0.05), мы смело отвергаем нулевую гипотезу.
Вывод: разница статистически значима. Оранжевая кнопка действительно заставляет людей покупать на бóльшие суммы. Можно выписывать дизайнерам бонус и раскатывать новый цвет на всех пользователей.
Сценарий 2: Совпадения случайны (результаты из R)
А здесь наш p-value улетел в космос и составил 0.9919 (почти 99.2%). Тест буквально кричит нам о победе рандома над дизайном.
Посмотрите на средние чеки в выдаче R: 2585.9 и 2585.2. Разница составила 70 копеек. Поскольку p-value сильно больше (0.9919 > 0.05), мы не имеем права отвергнуть нулевую гипотезу.
Вывод: разница статистически не значима. Цвет кнопки не принёс результата. Оставляем старый дизайн и идём придумывать новые фичи.
Типичные ошибки при использовании t-теста
T-тест — инструмент мощный, но не всесильный. Вот две классические ошибки, которые совершают новички (и не только они).
Применение при нарушении нормальности
Как мы уже говорили, t-тест Стьюдента не любит малые выборки, в которых данные распределены ненормально. Например, в данных присутствуют сильные выбросы.
Если в вашей группе из 10 разработчиков есть один, который зарабатывает 5 миллионов рублей в месяц, его зарплата катастрофически завысит среднее арифметическое. В этом случае t-тест выдаст неадекватный результат.
Что делать:
Если выборки большие (> 30–50), t-тест, скорее всего, всё равно сработает нормально (ЦПТ спасает).
Если выборки маленькие, вместо t-теста используйте непараметрические тесты, например, U-критерий Манна-Уитни. Он сравнивает не средние, а ранги данных, и ему до лампочки все эти формы распределения и выбросы.
Множественные сравнения без поправки
Это так называемая проблема подглядывания или p-hacking.
Представьте, что вы хотите сравнить эффективность пяти разных рекламных кампаний (А, Б, В, Г, Д). Вместо одного A/B-теста вы решаете провести кучу парных сравнений: А против Б, А против В, А против Г, ..., Г против Д. Всего 10 сравнений.
Если для каждого сравнения вы используете α = 0.05, то вероятность ложноположительного результата в каждом тесте равна 5%. Но вероятность ошибиться хотя бы в одном из 10 тестов будет намного выше: 1 - (1 - 0.05)10 0.40 (или 40%). Вы почти гарантированно найдёте значимую разницу там, где её нет, просто из-за количества попыток.
Что делать:
Поправка Бонферрони. Разделите желаемый на количество сравнений. Если вы делаете 10 тестов, то используйте α = 0.05 / 10 = 0.005. Это очень строгий критерий, но он защищает от ложных открытий.
Другие тесты. Используйте специализированные тесты для множественных сравнений или метод ANOVA.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.























