Привет!
В браузере Google Chrome есть игра с динозавриком. Когда нет интернета, браузер показывает такое:
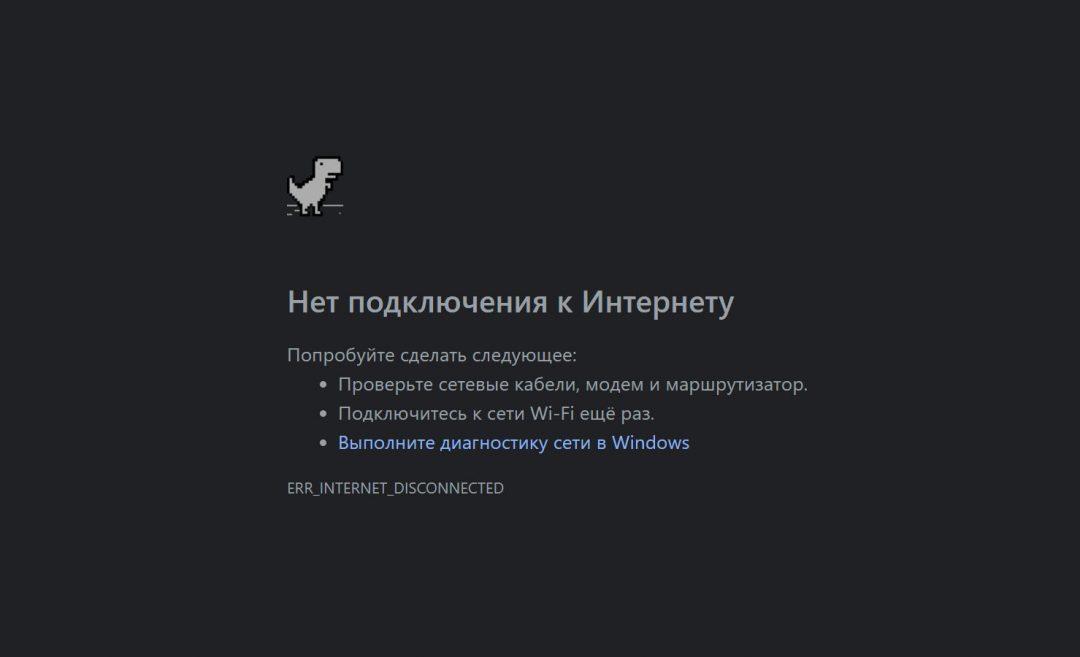
Недавно в Chrome добавили возможность поиграть в эту игру даже с интернетом: вбейте в адрес chrome://dino
Программист из Австралии по имени Эван (на Ютубе — CodeBullet) написал нейросеть, которая сама играет в эту игру, и выложил об этом видео:
Спойлер: в конце ИИ просто рвёт игру на части.
Давайте по шагам разберём, что он сделал и что у него получилось в итоге. Сам ролик на английском, поэтому, если вы не знаете английского, считайте эту статью смысловым переводом происходящего.
Создание игры
Можно научить ИИ играть в игру, просто глядя на экран и анализируя всё, что там происходит. Но тогда быстродействие ИИ будет ограничено скоростью работы экрана, то есть на каких-то сверхскоростях ИИ играть уже не сможет. А мы хотим играть на сверхскоростях, поэтому эффективнее будет встроить ИИ прямо в игру.
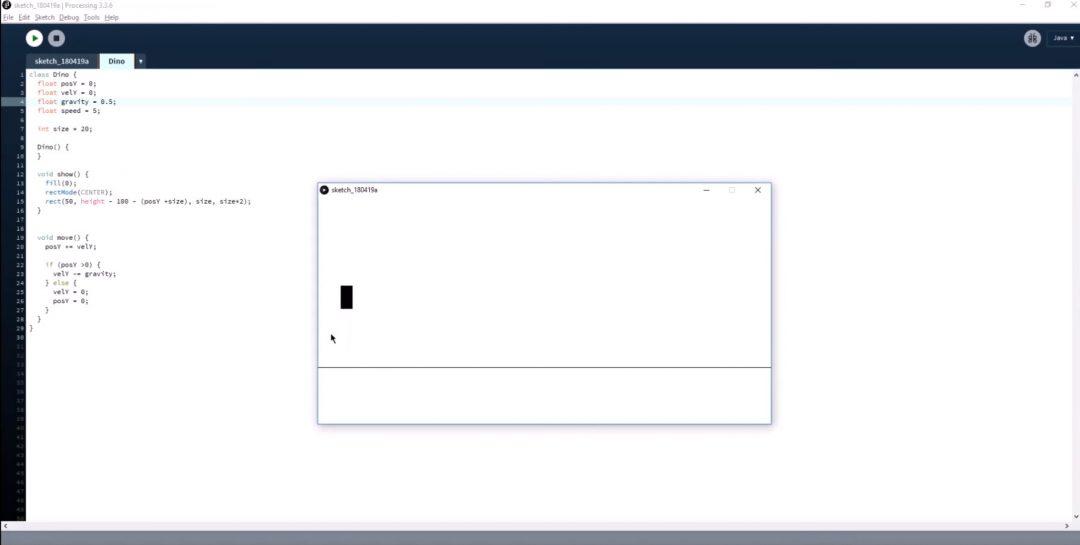
Пол и прыгучий персонаж. Чтобы попробовать первую версию игры как можно быстрее, Эван не рисует динозавра, а делает вместо него прыгающий прямоугольник. С поверхностью то же самое: простая линия вместо дороги с перспективой и песком в случайных местах. Единственное, что пока можно в игре — прыгать прямоугольником на месте:
Кстати, если вы обратите внимание на игру в Chrome, то заметите, что хотя динозаврик (по ощущениям) бежит по земле, на самом деле его координата X на экране не меняется. Можно представить, что это не динозаврик бежит, а кактусы летят на него со всё более высокой скоростью. Иллюзия!
Движение и препятствия. На следующем шаге Эван делает так, чтобы на динозаврика двигались кактусы. Но кактусы тоже рисовать долго, поэтому снова берём прямоугольники. Сначала делаем их маленькими и смотрим, что происходит:
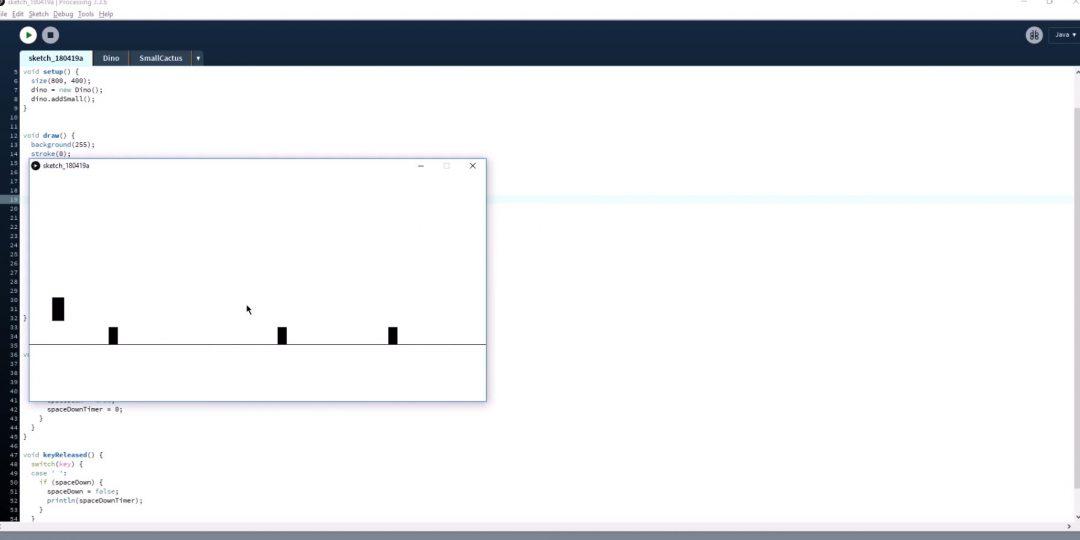
Пока всё хорошо: персонаж прыгает, прямоугольники двигаются. Можно сделать следующий шаг — добавить кактусы разной высоты и ширины, как в оригинальной игре. И снова это всё ещё прямоугольники:
Смерть от кактусов. Последнее, что делает Эван — добавляет в игру условие, что как только персонаж коснулся кактуса, то умирает. Это делается просто проверкой пересечения границ одного и второго объекта. Коснулся кактуса — всё исчезло:
Эван не начал программировать сразу всю игру с динозаврами, графикой и красивыми кактусами. Вместо этого он сделал макет игры и физику; потом убедился, что всё работает; и только после этого заменил прямоугольники на динозавра и кактусы, а линию на полу — на дорогу с песком. Всё это он просто вырезал из игры и вставил в свой проект:
За кадром осталось то, как Эван делал птиц: они могут летать низко, повыше или совсем высоко. Но мы уже понимаем, что сначала это был прямоугольник выше линии, а потом его заменили на картинку с птицей.
Динозаврику тоже пришлось научиться пригибаться — прямоугольник, который уменьшал свою высоту, превратился в пригибающегося динозаврика:
Нейросеть
Когда игра готова, можно к ней прикручивать искусственный интеллект. Для этого Эван пишет простую самообучающуюся нейросеть, которая работает по принципу обучения с подкреплением. Это значит, что ИИ сначала ничего не знает о мире, в который его поместили, и его задача — определить для себя правила, которые помогут играть в игру как можно дольше.
Если очень коротко, то это работает так:
- делают первое поколение сети;
- запускают её в игру и смотрят результат;
- те версии первого поколения, которые показали наилучшие результаты или дольше всех играли, остаются, а остальные убираются;
- эти удачные версии снова запускают в игру и тоже смотрят, какие из них покажут наилучший результат;
- новых везунчиков оставляют, остальных убирают, и всё повторяется до тех пор, пока ИИ не научится полностью проходить игру.
Первая версия ИИ, которую сделал Эван, просто прыгала случайным образом, и, если повезёт, то перепрыгивала кактусы:
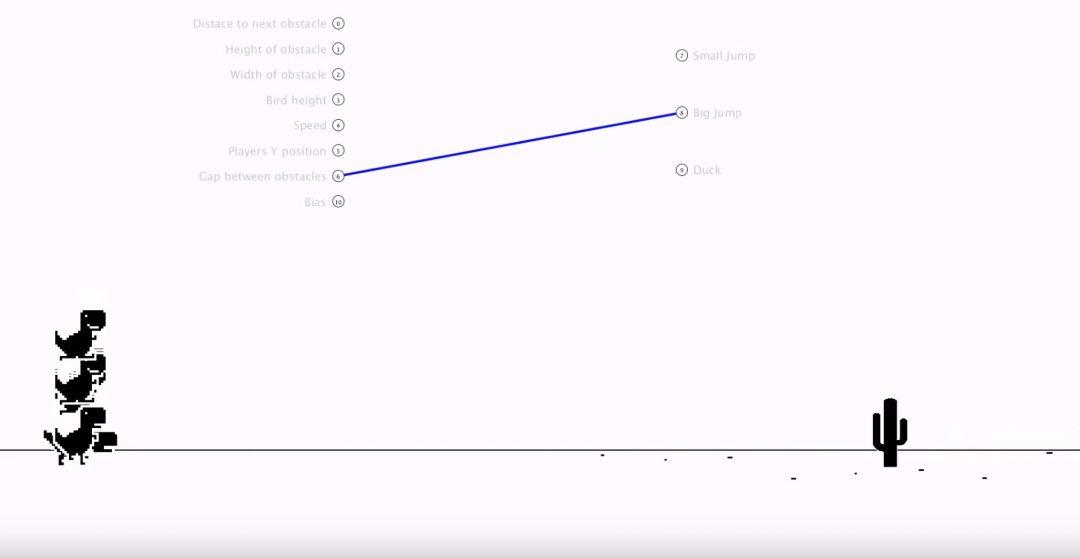
У первых нескольких поколений ИИ была примитивная тактика: просто прыгаешь и надеешься, что интервал прыжков совпадёт с расстояниями между кактусами. Это не сработало, поэтому к седьмому поколению нейросеть нашла взаимосвязь между расстоянием до препятствия, расстоянием между препятствием и моментом, когда надо подпрыгивать:
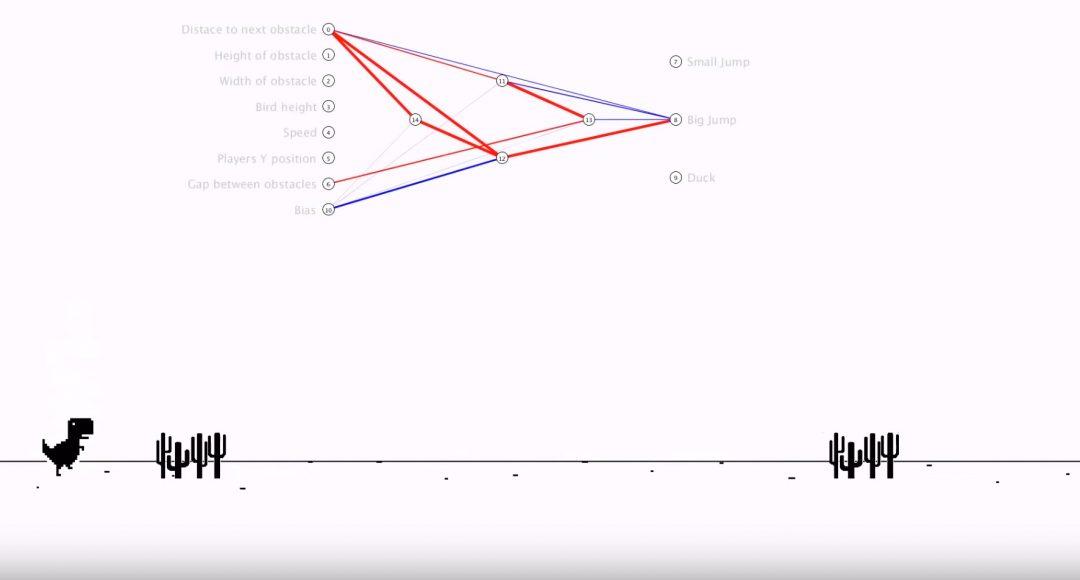
Теперь ИИ умеет дожидаться, пока кактусы не окажутся достаточно близко для прыжка, вместо того чтобы перепрыгивать их случайным образом.
Интересный момент: так как Эван использует самообучающуюся нейросеть, то мы можем заметить, как в некоторых моментах динозаврик раздваивается или распадается на множество частей.

Это связано с тем, что ИИ постоянно проверяет, что лучше: прыгнуть чуть раньше или чуть позже. И если какая-то стратегия даёт результат лучше, чем у остальных вариантов — ИИ делает эту стратегию базовой и в следующем поколении опирается уже на неё.
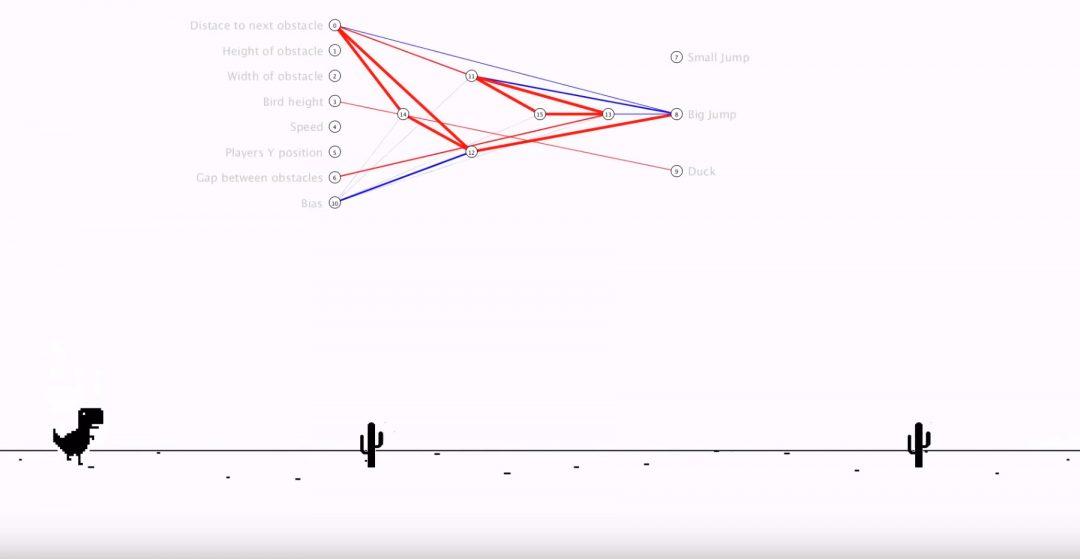

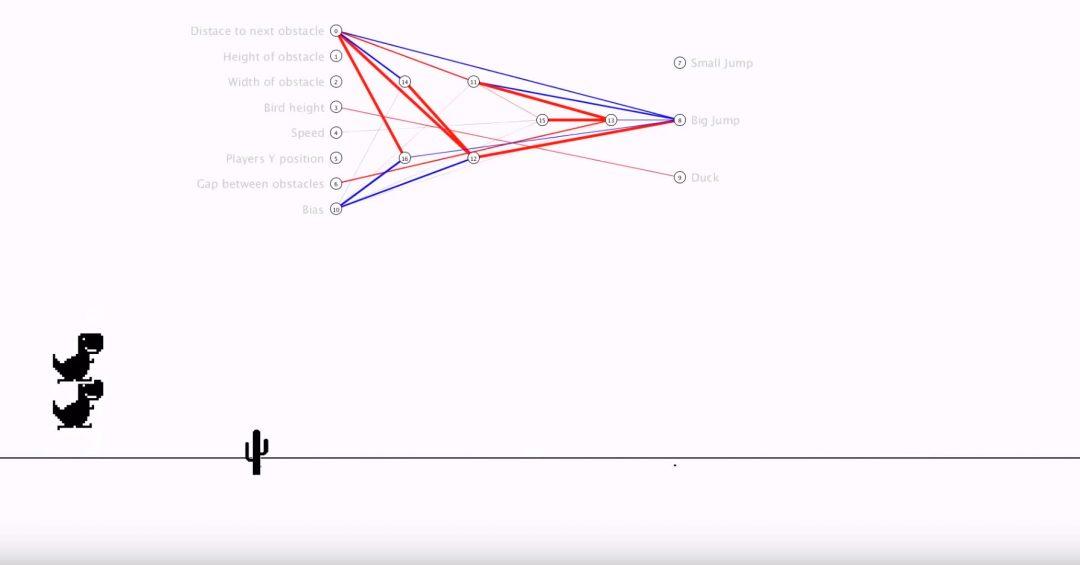
Финал
К сорок третьему поколению нейросеть Эвана научилась играть в динозаврика с такой скоростью, которая выходит за пределы человеческих возможностей. Именно для этого и используют ИИ — чтобы помочь человеку справляться с задачами ещё лучше, чем он это делает сейчас.
Есть и другие
На Ютубе много примеров, как нейросети учатся играть в эту игру. Подходы существуют разные, но чаще всего вы увидите какие-то эволюционные или генетические алгоритмы, смысл которых в одном: случайным образом мутируешь много исходных персонажей, проверяешь их, отбираешь лучшего, потом делаешь ему копии и случайным образом мутируешь их. И так шаг за шагом, поколение за поколением удачные мутации укрепляются, а ненужные пропадают.
Так как машины могут прогонять поколения очень быстро, буквально за секунды, за несколько часов можно обучить нейронку какой-нибудь несложной игре, даже если она не знает её правил. А за дни, недели и месяцы можно обучить и более сложным играм. Об этом — в следующих частях.