







Сегодня — заключительная часть цикла про распознавание лиц на Python и про библиотеку компьютерного зрения cv2. Мы напишем код, который научит нейросеть определять, кто именно находится перед ней:

Вот как мы к этому пришли, если нужны подробности:
А вот теория, чтобы сразу можно было понять, о чём пойдёт речь дальше:
- Для распознавания лица компьютер должен получить изображение — через камеру или готовый файл.
- Компьютер использует особый алгоритм, который разбивает изображение на прямоугольники и по ним определяет, где в кадре лицо.
- Чтобы программистам каждый раз не писать свой код распознавания с нуля, сделали библиотеку компьютерного зрения — cv2. Если в неё загрузить заранее подготовленные параметры лиц, она сможет распознавать их намного точнее.
- Чтобы нейросеть могла понять, какой именно человек перед ней, её тоже нужно этому обучить отдельно.
- Для обучения нужен датасет — набор фотографий, по которым нейросеть построит математическую модель лица. Его можно собрать по разным источникам или сгенерировать самому с помощью камеры.
Что делаем
У нас есть новая модель распознавания лиц, которую мы натренировали на фотографиях лица нашего автора Миши Полянина. Используем её для того, чтобы нейросеть подписывала Мишу, если он в кадре.
Нам понадобятся файлы из предыдущего проекта — обученная модель и файл с примитивами Хаара, по которым нейронка определяет лица. Обученную модель нужно сделать самим, чтобы скрипт мог вас узнавать.
Чтобы всё это сделать, нам понадобится Python — на нём пишут почти всё, что связано с машинным обучением и компьютерным зрением:
Как установить Python на компьютер и начать на нём писать
Настраиваем скрипт
Создаём новый файл face_detect.py и сразу подключаем две нужные нам библиотеки: компьютерного зрения и работы с системными функциями. Последняя нужна для того, чтобы можно было найти, где лежит скрипт, и сориентироваться, как получить доступ к папке с моделью:
# подключаем библиотеку компьютерного зрения
import cv2
# библиотека для вызова системных функций
import os
Теперь создаём новый распознаватель лиц — это встроенная функция библиотеки cv2. В него мы загружаем свою модель и отдельно подключаем фильтр Хаара — он будет нужен для поиска лиц на видео:
# получаем путь к этому скрипту
path = os.path.dirname(os.path.abspath(__file__))
# создаём новый распознаватель лиц
recognizer = cv2.face.LBPHFaceRecognizer_create()
# добавляем в него модель, которую мы обучили на прошлых этапах
recognizer.read(path+r'/trainer/trainer.yml')
# указываем, что мы будем искать лица по примитивам Хаара
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")Последнее, что осталось сделать на этом шаге, — получить доступ к камере и настроить шрифт для вывода подписей к лицам:
# получаем доступ к камере
cam = cv2.VideoCapture(0)
# настраиваем шрифт для вывода подписей
font = cv2.FONT_HERSHEY_SIMPLEX








Запускаем распознавание с камеры
Чтобы ускорить процесс, возьмём код основного цикла из файла face_gen.py из предыдущей статьи и немного поменяем его под нашу задачу. Логика будет такая:
- Получаем видеопоток.
- Определяем все лица на видео.
- Каждое лицо отправляем в нейросеть с нашей моделью — она будет искать там знакомых её людей.
- Если есть совпадение по id с тем, кого мы знаем, — меняем в подписи номер id на имя этого человека.
- Добавляем рамку и подпись.
- Выводим картинку с камеры и повторяем всё заново.
Единственный неочевидный момент здесь — это подстановка имени пользователя вместо id. Сейчас мы сделали это простой проверкой, но, если пользователей будет много, можно использовать базу данных и обрабатывать всё через неё.
Читайте комментарии, чтобы разобраться в том, что происходит в основном цикле программы:
# запускаем цикл
while True:
# получаем видеопоток
ret, im =cam.read()
# переводим его в ч/б
gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# определяем лица на видео
faces=faceCascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100), flags=cv2.CASCADE_SCALE_IMAGE)
# перебираем все найденные лица
for(x,y,w,h) in faces:
# получаем id пользователя
nbr_predicted,coord = recognizer.predict(gray[y:y+h,x:x+w])
# рисуем прямоугольник вокруг лица
cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2)
# если мы знаем id пользователя
if(nbr_predicted==1):
# подставляем вместо него имя человека
nbr_predicted='Mike Polyanin'
# добавляем текст к рамке
cv2.putText(im,str(nbr_predicted), (x,y+h),font, 1.1, (0,255,0))
# выводим окно с изображением с камеры
cv2.imshow('Face recognition',im)
# делаем паузу
cv2.waitKey(10)# подключаем библиотеку компьютерного зрения
import cv2
# библиотека для вызова системных функций
import os
# получаем путь к этому скрипту
path = os.path.dirname(os.path.abspath(__file__))
# создаём новый распознаватель лиц
recognizer = cv2.face.LBPHFaceRecognizer_create()
# добавляем в него модель, которую мы обучили на прошлых этапах
recognizer.read(path+r'/trainer/trainer.yml')
# указываем, что мы будем искать лица по примитивам Хаара
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
# получаем доступ к камере
cam = cv2.VideoCapture(0)
# настраиваем шрифт для вывода подписей
font = cv2.FONT_HERSHEY_SIMPLEX
# запускаем цикл
while True:
# получаем видеопоток
ret, im =cam.read()
# переводим его в ч/б
gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# определяем лица на видео
faces=faceCascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100), flags=cv2.CASCADE_SCALE_IMAGE)
# перебираем все найденные лица
for(x,y,w,h) in faces:
# получаем id пользователя
nbr_predicted,coord = recognizer.predict(gray[y:y+h,x:x+w])
# рисуем прямоугольник вокруг л≈ица
cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2)
# если мы знаем id пользователя
if(nbr_predicted==1):
# подставляем вместо него имя человека
nbr_predicted='Mike Polyanin'
# добавляем текст к рамке
cv2.putText(im,str(nbr_predicted), (x,y+h),font, 1.1, (0,255,0))
# выводим окно с изображением с камеры
cv2.imshow('Face recognition',im)
# делаем паузу
cv2.waitKey(10)Результат работы
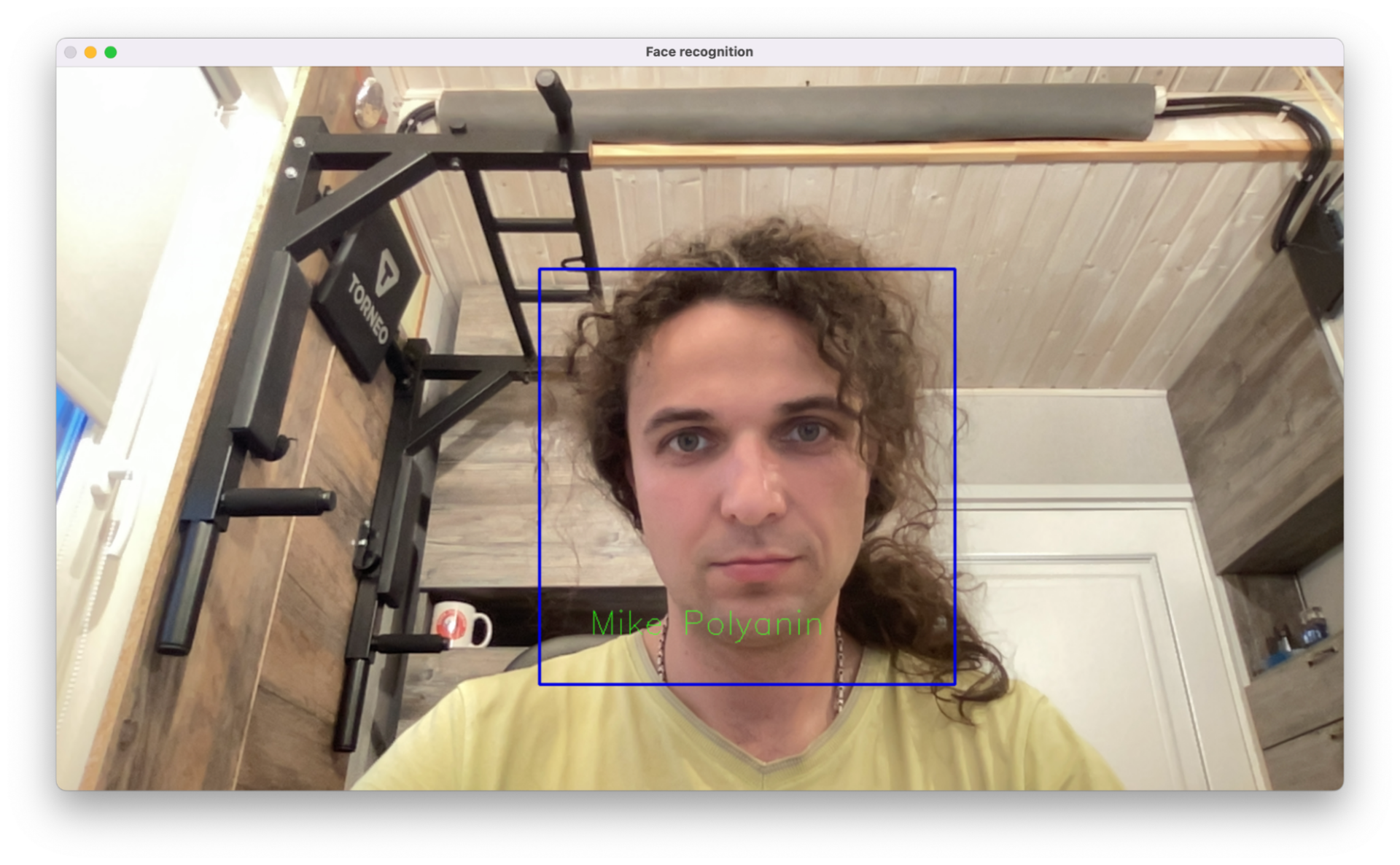
После запуска скрипта у нас будут работать две нейросети: одна будет искать все лица в кадре, а вторая — искать среди них те, которые ей известны. Если есть совпадение и мы знаем, как зовут человека под определённым id, то скрипт подставит его имя и мы увидим примерно такое:
А можно так запомнить несколько человек?
Конечно. Всё, что для этого нужно сделать, — запустить скрипт face_gen.py из прошлой статьи и ввести новый id. После этого программа сделает нужное количество снимков с камеры и добавит их в датасет. Так можно сделать сколько угодно раз — нейросети всё равно, сколько людей запоминать и распознавать.
Когда добавляется новый пользователь, модель нужно переобучить. Для этого достаточно удалить старый файл trainer.yml и запустить заново скрипт face_train.py — он заново пройдёт по всем фотографиям и построит новую модель.
Где это можно применить
Сейчас подобные алгоритмы применяются в пропускных системах в офисных зданиях — когда нужно повысить общий уровень безопасности. Для этого при оформлении пропуска сотрудников просят посмотреть в камеру и покрутить головой — в это время нейросеть делает много снимков и добавляет их в датасет, а потом переобучается с ними.
Когда сотрудник после оформления пропуска прикладывает его к турникету, камера находит лицо этого сотрудника в кадре и пробует распознать его с помощью новой модели. После распознавания система смотрит, какой у него уровень доступа и можно ли пускать этого сотрудника через этот турникет.























