


Сегодня разбираем простые форматы для работы с текстовой информацией — JSON и XML. Посмотрим, как вообще работать с таким текстом, где это нужно, какие ещё есть похожие форматы и как работать с JSON в языке программирования Python.
Что такое JSON, XML и YAML
JSON, XML и YAML — это три похожих формата для работы с текстом. С их помощью в программах можно хранить и обмениваться информацией между собой.
Чтобы не запутаться, кратко разберём каждый — как выглядят, как в общем работают и когда используются.
JSON
Текстовый формат для обмена данными. Расшифровывается как JavaScript Object Notation.
Чаще всего используется:
- В веб-разработке для передачи данных между сервером и клиентом — например, для обмена списком товаров и их характеристик в интернет-магазине.
- При работе с API, когда программа запрашивает или отправляет данные в API.
- Для настройки приложений. Примеры таких файлов — settings.json и extensions.json в редакторе кода Visual Studio Code. Чтобы добавить какое-то расширение или настройку, их можно вписать в нужный файл.
JSON быстро работает при обмене данными и поддерживается почти во всех языках программирования. Отчасти это благодаря тому, что он поддерживает всего несколько основных типов данных, которые распознаются автоматически.
XML
Тоже текстовый формат. Используется реже JSON из-за своей сложности.
У XML нет предопределённых типов, как в JSON, вместо этого всё нужно задавать самостоятельно. Это убирает ограничения на количество типов, но замедляет работу программ и читаемость для человека.
Где может применяться:
- В сложных программах, где нужно задавать свои типы данных и их проверку.
- В компаниях с легаси-кодом, которым сложно, дорого или просто невыгодно переезжать на другие технологии.
YAML
Формат, который чаще применяется для хранения настроек в виде текста.
Примеры использования:
- В файлах-манифестах Kubernetes.
- Для настройки серверов и развёртывания приложений в файлах Docker.
- При создании автотестов, например для автоматического деплоя в GitHub Actions.
Что удобнее и как это выглядит
Для примера возьмём профиль человека и посмотрим, как он будет выглядеть в трёх разных форматах. Эта информация может отправиться на сервер с клиента — или наоборот.
JSON поддерживает всего несколько типов данных. Но их достаточно в большинстве случаев, а программа работает быстрее. Получается хорошо читаемый формат, с которым удобно работать и человеку, и машине:
{
"name": "Alice",
"age": 30,
"is_active": true,
"skills": ["Python", "SQL", "Docker"],
"address": {
"city": "Moscow",
"country": "Russia"
}
}XML разрешает работать с любыми типами данных, если их предварительно настроить. Это может быть полезно в сложных структурах, но скорость работы с таким файлом снижается, и человеку читать XML тоже сложнее:
<user>
<name>Alice</name>
<age>30</age>
<is_active>true</is_active>
<skills>
<skill>Python</skill>
<skill>SQL</skill>
<skill>Docker</skill>
</skills>
<address>
<city>Moscow</city>
<country>Russia</country>
</address>
</user>YAML — самый удобный формат для чтения человеком, но одновременно самый сложный для компьютера. Например, машине нужно следить за отступами, а в JSON программа сразу понимает структуру благодаря фигурным скобкам.
Выглядит YAML так:
name: Alice
age: 30
is_active: true
skills:
- Python
- SQL
- Docker
address:
city: Moscow
country: RussiaБиблиотеки Python для работы с JSON и XML
Python — универсальный и самый популярный язык сегодня, который применяется в разных сферах. Во многих из них нужен обмен текстовыми данными, и в Python JSON и XML поддерживаются по умолчанию.
Встроенные библиотеки ограничены в своих возможностях, поэтому для разных задач уже написано много внешних технологий, которые можно добавить в программу и пользоваться готовыми возможностями.
Чтобы дальше было проще, вот основные команды для работы с обоими форматами в стандартных модулях. Основные операции и синтаксис в остальных библиотеках будут похожими или вообще такими же.
Команды для работы с JSON:
- Чтение JSON-данных в Python-программе, если сами данные в виде строки:
json.loads(json_str). В скобках передаём JSON-строку, которую надо прочитать. - Чтение JSON-данных в Python-программе, если данные в виде файла:
json.load(file). В скобках передаём JSON-файл, который надо прочитать. - Запись Python-данных в JSON-строку для отправки или чтения программой:
json.dumps(data). В скобках передаём Python-объекты, которые переводим в JSON-формат. - Запись Python-данных в JSON-файл:
json.dump(data, file). В скобках передаём Python-объекты для записи и JSON-файл, в который они будут записаны.
Команды для работы с XML:
- Чтение XML-данных в Python-программе, если сами данные в виде строки:
ET.fromstring(xml_str). В скобках передаём XML-строку, которую будем читать. - Чтение XML-данных в Python-программе, если данные в виде файла:
ET.parse(“file.xml”). В скобках передаём JSON-файл, который надо прочитать. - Запись Python-данных в XML-строку:
ET.tostring(xml_tree). В скобках — XML-строка, куда будут записаны созданные в Python данные. - Запись Python-данных в XML-файл:
tree.write(“file.xml”). В скобках передаём название файла, куда будет записана предварительно созданная XML-структура.
Ещё три термина, которые нам понадобятся.
Сериализация — запись данных нашей программы в JSON-строку или файл.
Десериализация — обратный процесс, когда мы считываем JSON-данные.
Парсинг — обработка любой структуры, чтобы найти в ней полезную информацию. В контексте работы с JSON и XML это разбор файлов и строк, чтобы достать оттуда то, что нужно для работы программы.







Как устанавливаются библиотеки
Для работы с XML и JSON Python по умолчанию умеет работать со стандартными библиотеками xml.etree.ElementTree и json. Чтобы подключить эти модули, их достаточно просто добавить в начало скрипта командой import:
import json
import xml.etree.ElementTree as ET
Остальные сначала нужно установить командой pip install в терминале среды разработки IDE или терминале командной строки — в зависимости от того, где вы работаете.
В терминале командной строки это выглядит так:
А в терминале на вкладке IDE — так:
Библиотеки для работы с JSON
К описанию библиотек мы добавили примеры в коде, чтобы было понятно, как происходит:
- извлечение JSON-данных;
- извлечение XML-данных;
- генерация JSON;
- генерация XML.
json
Встроенная библиотека для работы с JSON-форматом. Подходит для большинства несложных задач. Но она не самая быстрая, потому что написана тоже на Python, а он может работать медленнее по сравнению с некоторыми другими языками.
Подходит для чтения API-запросов или сохранения настроек программы в файл.
Пример с генерацией JSON:
# импортируем библиотеку
import json
# создаём словарь с данными
data = {
"name": "Анна",
"age": 28,
"courses": ["Python to json", "Data Science"],
"objects": ["module", "convert"],
}
# преобразуем в JSON-строку с отступами
# и возможностью чтения кириллицы
json_str = json.dumps(data, indent=4, ensure_ascii=False)
# выводим на экран
print(json_str)Результат:
{
“name”: “Анна”,
“age”: 28,
“courses”: [
“Python to json”,
“Data Science”
],
“objects”: [
“module”,
“convert”
]
}
Пример с чтением JSON:
# импортируем библиотеку
import json
# создаём JSON-строку для примера
json_data = '''
{
"name": "Анна",
"age": 28,
"courses": ["JSON to Python", "Data Science"]
}
'''
# преобразуем JSON-строку в словарь
data = json.loads(json_data)
# выводим на экран
print(data["name"])Запускаем код:
Анна
Это просто пример для демонстрации работы, в реальной жизни словарь можно записывать в JSON-файл без создания промежуточной строки.
SimpleJSON
Поддерживает дополнительные возможности, например работу с точным числовым форматом decimal. Этот вариант будет полезен в работе с финансами и другими сферами, где важна точность.
Сначала библиотеку нужно установить командой pip install simplejson.
Пример c генерацией JSON:
# импортируем библиотеку
import simplejson as json
from decimal import Decimal
# cоздаём данные с decimal
data = {"price": Decimal("19.99")}
# сериализуем с поддержкой decimal
json_str = json.dumps(data, use_decimal=True)
# выводим на экран
print(json_str)Что получаем в консоли:
{“price”: 19.99}
Пример с чтением JSON, в котором мы проверим, удалось ли получить нужный тип данных:
# импортируем библиотеку
import simplejson as json
# создаём decimal-строку в JSON
json_data = '{"price": 19.99}'
# загрузка и преобразование чисел в decimal
data = json.loads(json_data, use_decimal=True)
# выводим на экран
print(type(data["price"]))Запускаем код и проверяем результат:
<class ‘decimal.Decimal’>
ujson
Быстрая библиотека для работы с JSON, оптимизированная для обработки больших файлов. Например, логов или таблиц баз данных.
В нашем примере скорости не видно, но на больших проектах эффект будет ощутимый.
Пример c генерацией JSON:
# импортируем библиотеку
import ujson
# создаём словарь
data = {"users": [{"id": 1}, {"id": 2}]}
# быстрая сериализация
json_bytes = ujson.dumps(data)
# выводим на экран
print(json_bytes)Проверяем, что получилось:
{“users”:[{“id”:1},{“id”:2}]}
Пример с чтением:
# импортируем библиотеку
import ujson
# создаём JSON-данные
json_data = '{"users": [{"id": 1}, {"id": 2}]}'
# быстрое чтение
data = ujson.loads(json_data)
# выводим на экран
print(data["users"][0]["id"])Запускаем код:
1
ijson
Позволяет обрабатывать большие JSON-файлы по частям, не загружая весь файл в память. Удобно, чтобы программа не загружала оперативную память большими файлами по несколько гигабайтов.
Сначала создадим JSON-файл для наглядного примера:
# импортируем библиотеку
import json
# создаём большой JSON-файл для демонстрации
big_data = {"users": [{"id": i, "name": f"User_{i}"} for i in range(1000)]}
# записываем данные в файл
with open('big_data.json', 'w') as f:
json.dump(big_data, f)Теперь откроем его и выведем на экран только первых трёх пользователей:
# импортируем библиотеку
import ijson
# открываем файл для чтения в бинарном режиме
with open('big_data.json', 'rb') as f:
# итеративно обрабатываем элементы массива users
for i, user in enumerate(ijson.items(f, 'users.item')):
# выводим каждого пользователя по отдельности
print(f"Обработка пользователя: {user['name']}")
# выводим только первых трёх пользователей
if i >= 2:
breakПосмотрим, что получилось:
Обработка пользователя: User_0
Обработка пользователя: User_1
Обработка пользователя: User_2
jsonschema
Даёт возможность задавать правила для валидации данных. Пригодится, когда структура информации должна соответствовать шаблону.
Создадим тестовые JSON-данные:
# импортируем библиотеку
import json
# данные, которые должны соответствовать схеме
valid_data = {
"name": "Иван",
"age": 30,
"email": "ivan@example.com"
}
# сохраняем данные в файл
with open('user.json', 'w') as f:
json.dump(valid_data, f)Теперь прочтём этот же файл, но перед этим создадим правила проверки. Имя должно быть строкой, возраст — числом, а электронная почта — строкой, к тому же должна соответствовать другим правилам, которые уточняют, что это действительно электронная почта.
# импортируем библиотеки
from jsonschema import validate, ValidationError
import json
# задаём схему валидации с проверками типов
schema = {
"type": "object",
"properties": {
"name": {"type": "string"},
"age": {"type": "number"},
"email": {"type": "string", "format": "email"}
},
"required": ["name", "email"]
}
# открываем файл
with open('user.json') as f:
# пытаемся проверить содержимое на
# соответствие заданной выше схеме
try:
# если всё правильно, говорим, что данные прошли проверку
validate(instance:=json.load(f), schema)
print(f"✅ Валидно! Имя: {instance['name']}")
# если проверка не удалась, выносим это в исключение...
except Exception as e:
# ...и выдаём сообщение об ошибке
print(f"❌ Ошибка: {type(e).__name__}: {e}")Запускаем проверку:
✅ Валидно! Имя: Иван

Библиотеки для работы с XML
Обе технологии имеют похожие операции для работы: чтение, запись и валидация. Но при этом XML более сложный, и при работе с библиотеками это тоже проявляется.
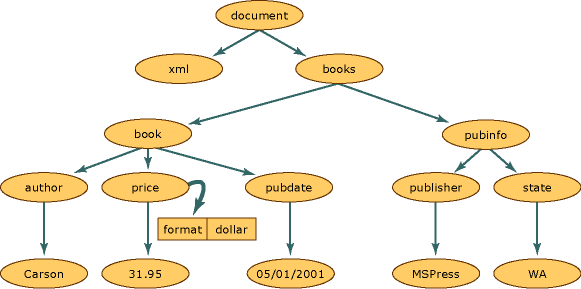
Для работы с XML нужно разобрать понятие DOM-дерева и его узлов. DOM расшифровывается как Document Object Model. Это модель представления XML-файла, где каждый узел — один из элементов:
xml.etree.ElementTree
Стандартная встроенная в Python библиотека, подходит для всех простых базовых операций.
Пример создания XML-файла:
# импортируем библиотеки
import xml.etree.ElementTree as ET
# создаём корневой элемент
root = ET.Element("catalog")
# добавляем дочерние элементы
book = ET.SubElement(root, "book", attrib={"id": "1"})
title = ET.SubElement(book, "title")
title.text = "Питон для тех, что читает КОД"
# создаём дерево и записываем в файл
tree = ET.ElementTree(root)
tree.write("catalog.xml", encoding="utf-8", xml_declaration=True)Теперь прочтём созданный файл и выведем на экран элемент-узел title.
# импортируем библиотеки
import xml.etree.ElementTree as ET
# загружаем XML из файла
tree = ET.parse("catalog.xml")
root = tree.getroot()
# находим все элементы title
for book in root.findall("book"):
# выводим результат на экран
print(book.find("title").text)Запускаем код и выводим результат:
Питон для тех, что читает КОД
lxml
Быстрая и мощная библиотека с поддержкой технологий запросов быстрого поиска и преобразования XML в другие форматы. Полезна для сложной обработки XML и просто для хорошей производительности.
Пример генерации XML:
# импортируем библиотеку
from lxml import etree
# создаём корневой элемент с пространством имён
root = etree.Element("{http://example.com}root")
# добавляем дочерние элементы
child = etree.SubElement(root, "child")
child.text = "Пятый элемент"
# записываем в файл с форматированием
tree = etree.ElementTree(root)
tree.write("lxml_output.xml", pretty_print=True, encoding="utf-8")Теперь найдём созданный элемент child.text с помощью технологии быстрых запросов XPath. Для этого нужно задать путь до нужного узла с использованием метода .xpath:
# импортируем библиотеку
from lxml import etree
# загружаем созданный XML
parser = etree.XMLParser(remove_blank_text=True)
tree = etree.parse("lxml_output.xml", parser)
# используем XPath для поиска
results = tree.xpath("//child/text()")
# выводим на экран
print(results)Смотрим, что выводится на экран:
[‘Пятый элемент’]
xmltodict
Простая библиотека для работы с XML-данными как со словарями Python. Подойдёт, если XML достаточно простой или если в программе нужно быстро преобразовывать формат XML в объект Python.
Для примера генерации файла создадим словарь и переведём его в XML:
# импортируем библиотеку
import xmltodict
# создаём словарь с данными
data = {
"catalog": {
"book": {
"@id": "1",
"title": "Python",
"price": "999"
}
}
}
# преобразуем словарь в XML
xml_str = xmltodict.unparse(data, pretty=True)
# создаём файл для записи
with open("xmltodict_output.xml", "w") as f:
f.write(xml_str)При запуске кода в корневом каталоге проекта появится файл xmltodict_output.xml.
Теперь прочтём этот XML и выведем на экран одно из значений:
# импортируем библиотеку
import xmltodict
# читаем XML и преобразуем в словарь
with open("xmltodict_output.xml") as f:
data = xmltodict.parse(f.read())
# выводим на экран значение по ключу title
print(data["catalog"]["book"]["title"])В консоли получаем результат:
Python
BeautifulSoup
Популярный инструмент, когда нужно использовать универсальный и гибкий парсинг форматов XML и HTML.
Создать файл можно так:
# импортируем библиотеку
from bs4 import BeautifulSoup
# создаём XML документ
soup = BeautifulSoup(features="xml")
catalog = soup.new_tag("catalog")
book = soup.new_tag("book", id="1")
title = soup.new_tag("title")
title.string = "Парсинг, XML и всё остальное"
book.append(title)
catalog.append(book)
# записываем в файл
with open("bs4_output.xml", "w") as f:
f.write(str(catalog))Теперь загрузим этот файл и найдём номер элемента и текст по тегу title:
# импортируем библиотеку
from bs4 import BeautifulSoup
# загружаем и парсим XML
with open("bs4_output.xml") as f:
soup = BeautifulSoup(f, "xml")
# находим элементы
for book in soup.find_all("book"):
print(book["id"], book.title.text) # 1 PythonРезультат в консоли:
1 Парсинг, XML и всё остальное
Примеры валидации данных в JSON и XML
Для дополнительной надёжности в программы добавляют функцию валидации данных — когда информацию перед использованием проверяют на соответствие правилам.
Когда мы говорили про JSON-библиотеки, то разобрали пример с jsonschema с проверкой типа данных: возраст должен быть числом, имя — строкой, а адрес электронной почты должен соответствовать шаблону проверки.
Вот ещё два примера валидации данных для JSON и XML. Это две библиотеки, которые делают практически одно и то же, но для разных форматов файлов — проверяют их на соответствие правилам, которые установят программисты при работе.
Примеры валидации JSON в Cerberus
Cerberus — библиотека для установки правил проверки JSON.
Правила могут быть любыми, которые понадобятся в работе приложения. Например, первая переменная должна содержать число, вторая — должна находиться в границах от 0 до 255, а третья вообще зависит от сложного правила и может существовать, только если результат работы одной из функций возвращает значение True.
Для примера установим такую проверку: тип данных для значения по ключу name должен быть строкой и иметь минимальную длину в два символа:
# импортируем библиотеку
from cerberus import Validator
# устанавливаем правила валидации
using = {'name': {'type': 'string', 'minlength': 2}}
# создаём данные для проверки
dictionary = {'name': 'Alex'}
# загружаем схему в переменную
v = Validator(using)
# проверяем данные на соответствие правилам
if v.validate(dictionary):
print("✓ Данные валидны")
else:
print("✗ Ошибки:", v.errors)Проверяем результат:
✓ Данные валидны
Примеры валидации XML в xmlschema
xmlschema — библиотека для валидации XML по XSD-схемам.
XSD — структура в коде, которая описывает допустимые правила и границы данных программы. То есть даёт возможность разработчикам настраивать такие же проверки, как Cerberus в JSON, но для XML.
Создание такой схемы выглядит так:
# импортируем библиотеку
from xmlschema import XMLSchema
# создаём схему XSD
xsd_schema = """<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="note">
<xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>"""
# сохраняем схему в файл
with open("note_schema.xsd", "w") as f:
f.write(xsd_schema)В этой части кода мы ещё не используем библиотеку, только создаём схему, которая сейчас фактически является обычной строкой. Но в следующей части мы присвоим эту строку в переменную, которая будет иметь специальный тип таблицы:
# создаём тестовый XML файл для проверки
with open("note.xml", "w") as f:
f.write("""<?xml version="1.0"?>
<note>
<to>Alice</to>
<from>Bob</from>
</note>""")
# загружаем схему
schema = XMLSchema("note_schema.xsd")
# проверяем XML файл
if schema.is_valid("note.xml"):
print("XML соответствует схеме")
else:
print("Ошибки валидации:", list(schema.iter_errors("note.xml")))Попробуем запустить код:
XML соответствует схеме
Часто задаваемые вопросы:
Как преобразовать Python объект в JSON строку?
Используйте json.dumps(data), где data — Python-объект (словарь, список). Пример:
json_str = json.dumps(data, indent=4, ensure_ascii=False)Как читать JSON файл в Python?
Откройте файл и примените json.load(file). Пример:
with open('file.json') as f:
data = json.load(f)Как записать данные в JSON файл?
Используйте json.dump(data, file). Пример:
with open('file.json', 'w') as f:
json.dump(data, f)Какие типы данных преобразуются между JSON и Python?
JSON поддерживает строки, числа, булевы значения (true/false), массивы (списки), объекты (словари), null. Python-аналоги: str, int/float, bool, list, dict, None.
Что такое ensure_ascii=False в json.dumps()?
Параметр ensure_ascii=False позволяет записывать не-ASCII символы (кириллицу) в оригинальном виде, а не экранировать их как \uXXXX. Без него кириллица превращается в Unicode-последовательности.
Как обработать ошибки при парсинге JSON?
Используйте конструкцию try-except для перехвата исключения json.JSONDecodeError (или ValueError в старых версиях Python):
import json
json_str = '{"invalid": }' # Некорректный JSON
try:
data = json.loads(json_str)
print(data)
except json.JSONDecodeError as e:
print(f"Ошибка парсинга JSON: {e}")Вывод:
Ошибка парсинга JSON: Expecting ‘,’ delimiter: line 1 column 12 (char 11)
Для файлов:
try:
with open('data.json') as f:
data = json.load(f)
except json.JSONDecodeError as e:
print(f"Ошибка в файле: {e}")
except FileNotFoundError:
print("Файл не найден")Ключевые исключения:
json.JSONDecodeError— синтаксическая ошибка в JSONFileNotFoundError— файл не существуетPermissionError— нет прав доступа











