LLM, или Large Language Model, — это большие языковые модели, такие как ChatGPT, DeepSeek или Grok. Они выглядят умными: уверенно отвечают, приводят аргументы, пишут код и разбираются в других вещах. Но рано или поздно модель начинает галлюцинировать: говорить неправду, которая похожа на правду. Чем ответственнее область использования ответов искусственного интеллекта, тем опаснее последствия.
Чтобы ответы были надёжнее, можно использовать дебагинг — исправление ошибок.
Сегодня разбираем механизм галлюцинаций LLM, типы ошибок и узнаём, можно ли как-то от этого защититься или надёжно исправить неверные ответы.
Что такое галлюцинации ИИ
Вот определение:
Галлюцинация ИИ — уверенный, но вымышленный ответ машины, не соответствующий реальности или доступным источникам.
Получается, что галлюцинация — правдоподобно выглядящий, но фактически неверный ответ. Модель может подавать информацию логично и даже сопровождать её вымышленными фактами, ссылками и терминами. Для пользователя это выглядит как полностью придуманный ответ.
Причины появления галлюцинаций у нейросетей
Правда в том, что модель не проверяет факты и не знает, где правда, а где ложь. Модели предсказывают каждое слово-токен на основе вероятностей, а не сверяются с реальностью. Если какие-то конструкции встречались в наборах данных при обучении, машина будет использовать их.
Чтобы понять, почему модель может галлюцинировать, нужно понять, как вообще появляются эти ответы. Архитектура обработки ответа может выглядеть как такая цепочка:

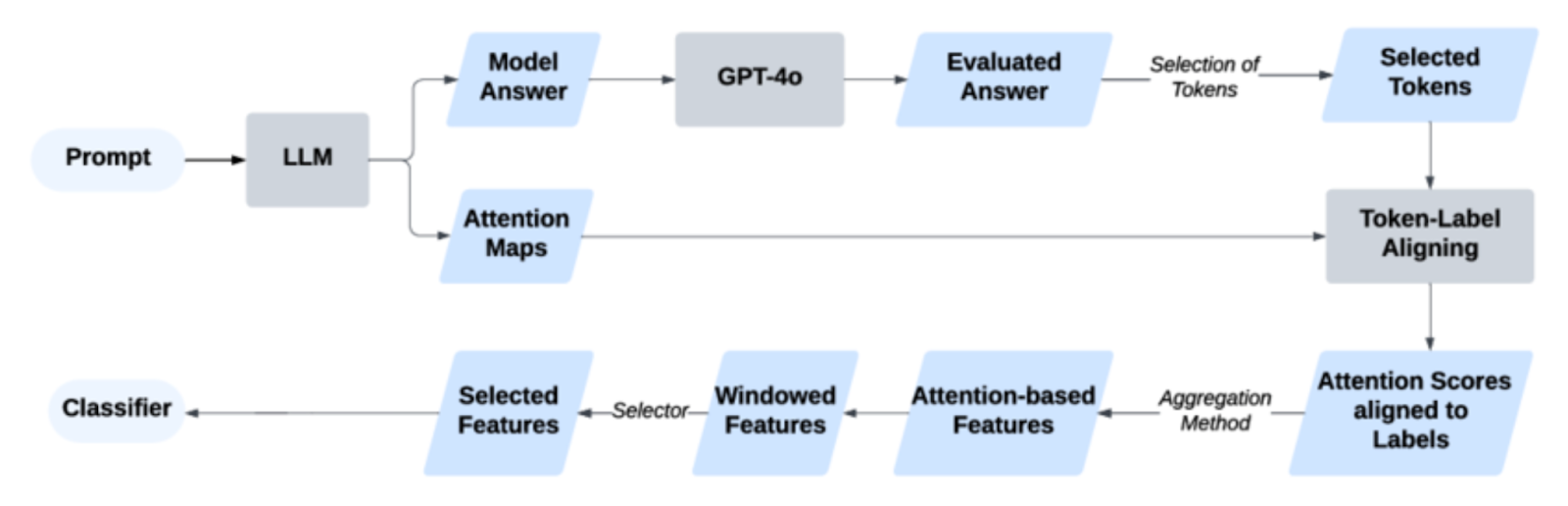
1. Prompt — запрос пользователя. Модель не понимает точный смысл и намерения человека, она воспринимает это просто как набор значений-токенов.
2. LLM — место, где языковая модель принимает запрос. Здесь машина начинает вычислять вероятности следующих токенов.
3. Model Answer — черновой ответ модели. Первичный, внутренний вариант ответа, который компьютер сгенерировал до проверок, фильтров и оценок.
4. GPT-4o. Отдельная модель или этап, который оценивает качество чернового ответа: полезность, соответствие инструкциям, безопасность.
5. Evaluated Answer — оценённый ответ. На этом этапе уже ясно, какие части хорошие, слабые или потенциально опасные. Финальный текст ещё не выбран, но уже понятно, что можно оставить.
6. Selection of Tokens — выбор слов-токенов из подходящих. Модель проверяет, какие токены проходят по вероятностям и ограничениям. Тут решается, какие слова реально попадут в финальный ответ.
7. Selected Tokens — составляется финальный набор токенов для ответа. Это почти финальный ответ.
Attention Maps. Процесс, который идёт параллельно с предыдущими с момента попадания запроса в нейросеть. Включает части запроса, на которые модель обращала внимание при генерации. Это параллельный предыдущим шагам процесс, один из ключевых механизмов ИИ-моделей для выделения важной информации.
8. Token-Label Aligning — сопоставление конкретных слов из ответа и меток. Например, «релевантно», «полезно», «опасно». Модель должна понимать, какие слова за какой эффект ответственны.
9. Attention Scores aligned to Labels. Рассчитывается, какие части текста сильнее всего повлияли на оценки.
10. Attention-based Features. Шаг, когда из карт внимания извлекаются числовые характеристики. Эти числа упрощённо представляют поведение модели и не используются для ответа, только для анализа.
11. Windowed Features — оконные признаки. Окна — это оценённые куски текста, а признаки — числовые характеристики текста, по которым алгоритм принимает решение. Как могут выглядеть эти признаки:
- уверенность ответа: 0,92;
- длина предложения: 37;
- количество утверждений без источника: 3.
12. Selected Features — машина оставляет только самые важные признаки, которые влияют на решение.
13. Classifier — классификатор. Отдельная модель или алгоритм, который на основе признаков решает: «Ответ нормальный? Опасный? Неточный?»
Галлюцинация появляется в первой половине схемы — на пути между пунктом LLM до Selected Tokens. В этой части нет фрагмента «проверить ответ на правдивость», есть только несколько этапов подбора подходящих слов.
Иногда галлюцинацию может заметить классификатор как внешний компонент системы. Но он тоже не понимает наверняка, если модель, которую он анализирует, врёт. Классификатор только подсчитывает соответствие шаблонам, согласованность, соответствие контексту. В итоге он может сказать: «Похоже на галлюцинацию, но не факт».
Получается, на всём пути генерации ответа нет ни одного места с жёсткой проверкой: «Это правда или ложь?»
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Знания и уверенность
На тему галлюцинаций ИИ часто можно встретить график расхождения. На одной оси — уверенность модели, на другой — точность ответа:

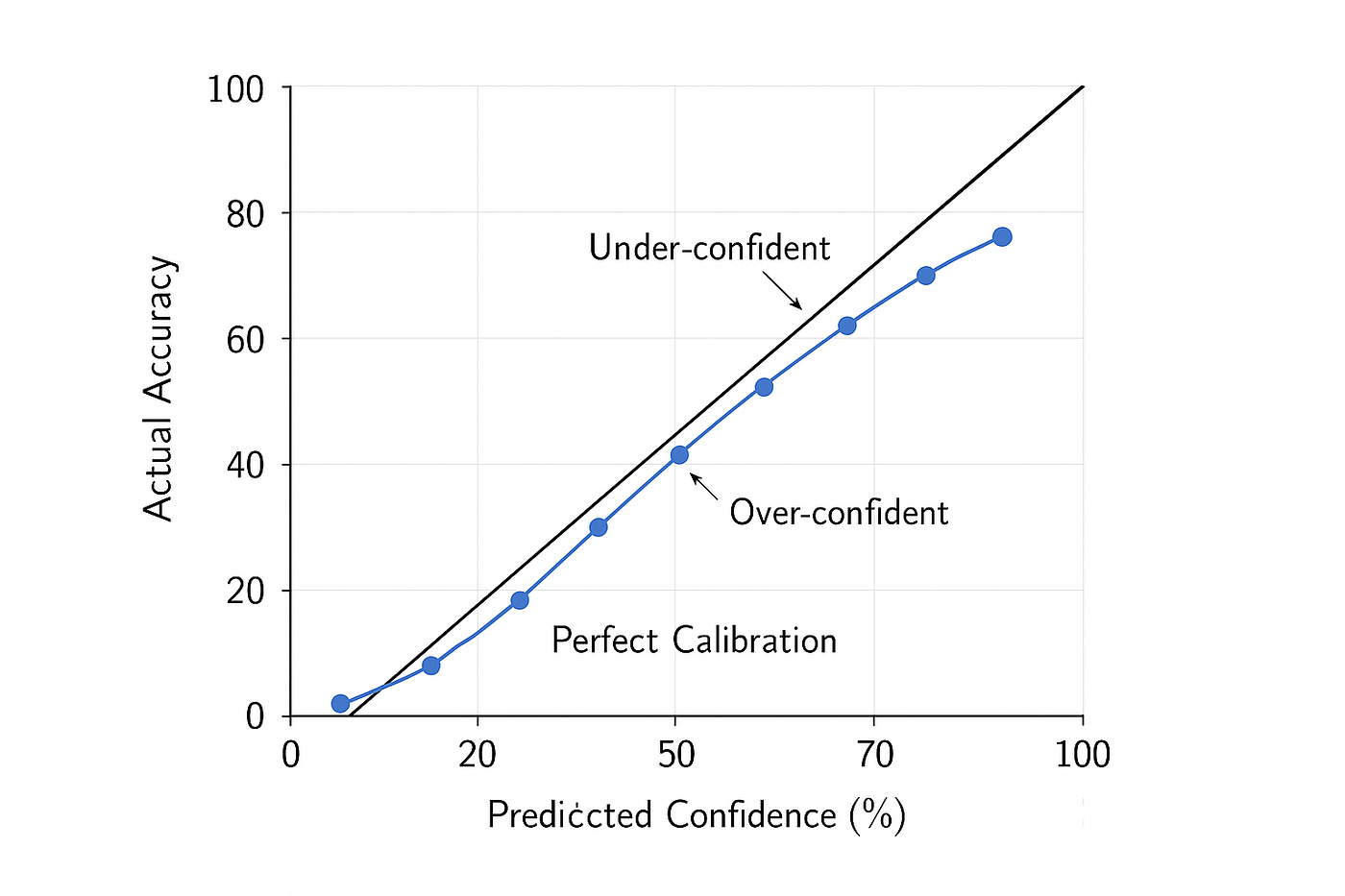
Смысл в том, что LLM может отвечать уверенно, но при этом неточно. В этом и есть опасность галлюцинаций: фактические ошибки компьютер подаёт как точную правду.
Ошибки, допускаемые нейронными сетями с примерами
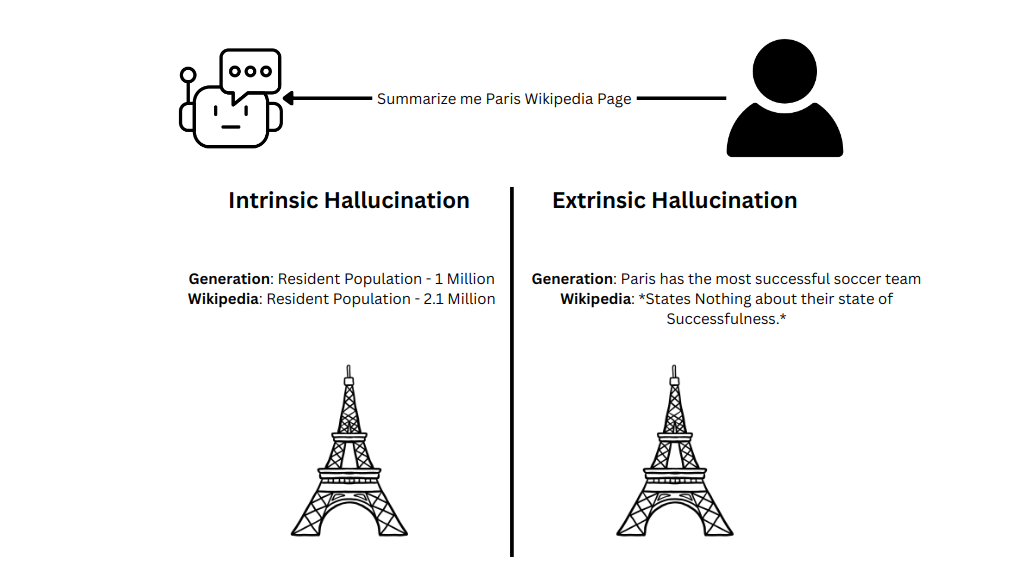
Часто отдельно выделяют два вида галлюцинаций: внутренние (intrinsic) и внешние (extrinsic).
При внутренних галлюцинациях модель противоречит контексту, который ей выдал пользователь, и путает факты внутри входных данных. При внешних — добавляет факты, которых вообще не было, выдумывает источники, события, API и другие вещи.
Например, пользователь попросил краткую выжимку фактов о Париже из Википедии. Тогда:
- Внутренней галлюцинацией будет назвать население в один миллион вместо реальных двух. Модель неправильно передаёт факты внутри переданного контекста. Данные о населении есть, но не те.
- Внешней — сказать, что в Париже самая успешная в мире команда по футболу, когда в Википедии нет вообще такой информации.

Отсутствие критического мышления и понимания контекста
Это ошибка рассуждения. Модель не проверяет логические противоречия, не замечает, что данные неполные, не говорит: «Я не знаю». Вместо этого она уверенно отвечает на вопрос, даже если задачу нельзя решить на основе той информации, что дал пользователь.
Это может случиться, если пользователь задаёт неполный вопрос, например просит посчитать прибыль без точных исходных данных или продолжить логику без ключевых шагов. В таких запросах нельзя сделать однозначный вывод, но машина вместо запроса уточняющей информации начинает рассуждать и берёт самые вероятные сценарии для генерации уверенного ответа. Главное, что она не фиксирует, что вывод сделать нельзя.
Неполнота и предвзятость обучающих данных
Модели обучались на данных, которые для неё собрали программисты. А значит, у среднестатистической модели есть такие недостатки:
- плохо знает редкие темы, потому что по ним мало информации — или, наоборот, слишком много и факты смешиваются;
- уверенно обобщает запросы, про которые мало данных;
- воспроизводит неверные, но популярные заблуждения;
- заполняет недостаток точной информации цепью умозаключений и догадками.
Это ошибка источников, а не логики.
Если попробовать задать вопрос на тему, по которой много разных данных, модель может придумать ответ — просто потому, что слова из запроса слишком часто встречаются в разных областях данных. Это может выглядеть так:


Способы борьбы с галлюцинациями ИИ
Вот несколько советов, как дебажить ответы. Их можно использовать для снижения вероятности галлюцинаций искусственного интеллекта или чтобы исправить замеченные ошибки в существующих ответах.

Установление чётких целей для модели
Основное требование, которое лучше всегда держать в уме: чем точнее цели и критерии ожидаемого от модели результата, тем лучше итог.
Слишком общий запрос:
«Расскажи, как лучше хранить данные в backend-приложении»
После этого модель начинает отвечать общими словами, смешивать разные типы баз данных и архитектуры и давать советы в зависимости от проекта. Чтобы получить конкретное решение, дайте машине столько информации, сколько можно:
«Предложи один вариант хранения данных для pet-проекта на FastAPI с PostgreSQL. Не перечисляй альтернативы. Объясни почему».
Тогда модель начинает работать в узком контексте.
Повышение качества обучающих данных
Этот совет больше относится к RAG-системам для внутренних баз знаний, которые используют сотрудники в компаниях. Эти системы используют предварительно подготовленные данные для ответа: документацию, статьи, таблицы.
Пример проблемы, которая может возникнуть: модель уверенно описывает несуществующий API, потому что в базе знаний лежит устаревший файл двухлетней давности. Для пользователя это выглядит как ложь в ответе, хотя ИИ просто опирается на плохие данные.
Чтобы починить модель, нужно помогать RAG-системе: удалить устаревшие документы из базы знаний, добавить даты актуальности, передавать в ответы пользователям только релевантные фрагменты. Для пользователей будет лучше оставить пять свежих файлов, чем пятьдесят старых.
Создание и использование шаблонов данных
Без чётких указаний модель может отвечать в разных форматах: списком, сплошным абзацем текста, кодом. Из-за разного формата сложнее понять, где факт, а где — рассуждения модели.
Можно снизить эту неопределённость, заставив компьютер отвечать по шаблону:
«Ответь строго в формате:
1. Краткий ответ (1–2 предложения)
2. Причина
3. Ограничения
Если чего-то не знаешь — напиши „нет данных“».
Рамки упрощают понимание ответа и снижают галлюцинации за счёт того, что структура ответа снижает вероятность свободной интерпретации фактов.
Ограничение диапазона ответов
Открытый общий вопрос увеличивает возможность галлюцинаций, например:
«Почему заказ не прошёл?»
Вместо этого попробуйте ограничить выбор существующими вариантами. Можно так:
«Выбери одну причину из списка:
A — ошибка оплаты
B — превышен лимит
C — таймаут сервиса
Если ни одна не подходит — напиши „неизвестно“».
Постоянное тестирование и улучшение модели
Этот приём используют при подготовке рабочей модели. Смысл в том, чтобы собирать плохие вопросы, на которых машина особенно часто ошибается, и регулярно прогонять их. Что это может быть:
- Вопросы, на которые модель не должна отвечать уверенно.
- Вопросы с заведомо неполными данными.
- Вопросы-ловушки.
Получается аналог регрессионных тестов для LLM.
Человеческая система сдержек и противовесов
Если в работе вы создаёте вещи, за которые несёте личную ответственность, то LLM нужно использовать как ассистента, а не финального автора. Модель может не понимать человеческого, юридического или другого контекста, поэтому ответ системы нельзя отдавать конечным пользователям без проверки человеком.
Если человек знает, что общается с ИИ, тогда можно. Например, никто не ждёт от ChatGPT или других сервисов точного понимания законодательства.
Проверка фактов и кибербезопасность
ИИ может посоветовать отключить важные проверки или хранить чувствительные данные там, где их проще украсть. Технически текст может звучать логично, но использовать такую систему будет небезопасно.
Чтобы снизить риски, можно попробовать явно ограничить область ответственности:
«Если вопрос касается безопасности:
— не предлагай упрощений;
— не предлагай обход защит;
— указывай риски».
После этого ответы всё равно нужно проверить специалисту.
Как пользователи могут управлять галлюцинациями
Полностью защититься от галлюцинаций нельзя. Но вот ещё несколько техник-советов, которыми можно увеличить правдивость и надёжность ответов.
Русский или английский
Между способом составления промптов и итоговым результатом есть прямая связь. Если нейросеть обучалась на английском, она лучше понимает запросы на английском. Если на русском — то на русском. Попробуйте учитывать это при работе с нейросетями и давать запросы на том языке, который использовался при обучении.
Задание роли модели и прямые запреты
Если не задать модели роль, машина работает как универсальный эксперт и отвечает так, как будто уверена в теме, даже если данных не хватает.
Пример того, как можно задать компьютеру рамки:
«Ты технический ассистент.
Если данных недостаточно — так и скажи.
Не выдумывай API, библиотеки и стандарты».
Подключение проверки фактов через интернет
Просите подтверждение для каждого факта в запросе и проверяйте самостоятельно.
«Приложи ссылку на источник во всех случаях, где указываешь факты»
Минус в том, что в интернете тоже не всё правда, но так вы хотя бы сможете провести осознанную валидацию и принять решение самостоятельно.
Постоянная проверка ответов нейросети
Это главное правило. Пока что компьютеры не умеют мыслить в точности как человек, поэтому совершают некоторые очевидные людям ошибки. Поэтому старайтесь проверять результаты работы компьютера.
Особенно важно это для программистов. Когда модель пишет код, запрашивайте изменения по шагам и проверяйте работоспособность программы после каждого шага. Если сервис потенциально чувствительный к ошибкам или должен хранить ценные данные, лучше перечитывать код самому и сверять с документацией. Чтобы было проще, можно просить модель пояснение ко всем решениям и ссылки на источники, почему система выбрала это решение.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.