Главный инструмент для работы с сервисами искусственного интеллекта — это промпт, запрос к машине. В промпте пользователь объясняет, что нужно сгенерировать: текст, изображение, музыку, видео.
Сегодня посмотрим на то, как компьютеры понимают такие запросы и как создаётся ощущение, что они всё понимают.
В этой статье мы будем рассматривать в основном нейросети, которые работают с текстовыми запросами и ответами. На принципе работы таких систем можно объяснить основное ядро всех современных программ на основе искусственного интеллекта.
Что именно делают нейросети, принимающие промпты
Задача любой нейросети сводится к одному: преобразовать входную последовательность (наш промпт) в выходную (то, что сделает ИИ-приложение).
Этот процесс так и называется — преобразование последовательности, или sequence transduction.
Читать текст от пользователя можно по-разному. Первые версии ИИ читали текст по одному слову, а современные смотрят на весь запрос сразу. Дальше мы расскажем подробнее о различиях между этими версиями.
В отличие от чтения входной последовательности, ответ машина генерирует всегда по одному слову: написала одно, подумала, написала следующее. Так проще: можно следить за ответом на лету и просчитывать только следующее слово, а не весь текст сразу. Главная задача ИИ при работе — сохранить смысл текста и выдать адекватный ответ.
Рекуррентные нейросети — recurrent neural network, или RNN
Первые версии механизмов для обработки текстовых запросов от человека были рекуррентными. Они обрабатывали сначала одно слово, потом следующее и так до конца.
Если сравнить с программированием, то это похоже на цикл for: обработка строки по одному слову. Получается, что машина просто читает слова человека строго по порядку. При этом между словами не появляется каких-то связей по смыслу и значению, как это есть в настоящем тексте.




Проблема долгосрочных зависимостей
RNN плохо справлялись с правильной интерпретацией слов человека, потому что не могли определить важность отдельных слов и фраз в тексте.
В настоящих речи и тексте между словами есть сложные связи, которые связывают одни слова с другими. Человеку эти связи интуитивно понятны, но объяснить эти нюансы машине может быть сложно:


Чем дальше нейросеть типа RNN уходит от первого слова, тем сложнее ей вспомнить, какая может быть связь между началом текста и концом. Это называется проблемой долгосрочных зависимостей, или problem of long-term dependencies.
Модификация LSTM
Первым решением была модификация для рекуррентных сетей, которая называлась LSTM, или Long Short-Term Memory.
Улучшенная версия помогала машине определять, какие слова нужно запомнить. Как именно это делать и как разделить слова по важности, модель училась сама. Получалось что-то вроде набора условий-«ворот»: если определённое условие срабатывало, ворота их пропускали. Система запоминала слово и маркировала его по собственной шкале.
Стало гораздо лучше, но нейросеть всё равно работала пошагово. Если текст был длинный или зависимости были сложные, машина часто ошибалась. Ещё такие модели сложнее обучать, чем системы, которые работают параллельно.
Свёрточные нейронные сети — convolutional neural networks, или CNN
Следующей моделью были свёрточные сети. Они смотрели на текст уже не по одному слову, а по несколько, как бы сворачивая из соседних слов один понятный для себя смысл. На следующем слое эти смыслы тоже склеивали и так далее:


В основном эти сети использовались именно для чтения. Минусы решения перевешивали плюсы: CNN всё равно работали пошагово и тоже ошибались на больших текстах.
Что такое внимание и вектор
Когда говорят о понимании слов нейросетями, часто встречаются термины «токен» и «вектор». Чтобы дальше было проще, разберём простыми словами, что это такое.
Токеном называют каждое отдельное слово в запросе и ответе при работе с нейросетью. Модель разбивает тексты на токены и анализирует каждый из них. Первые модели анализировали токены последовательно, а сегодняшние делают это параллельно.
Вектор — упорядоченный набор чисел. Этот набор чисел есть у каждого токена, и он помогает нейросетям понять, насколько слова связаны между собой по смыслу и контексту.
Вот пример, где слова-токены и их векторы показаны в разных цветах:

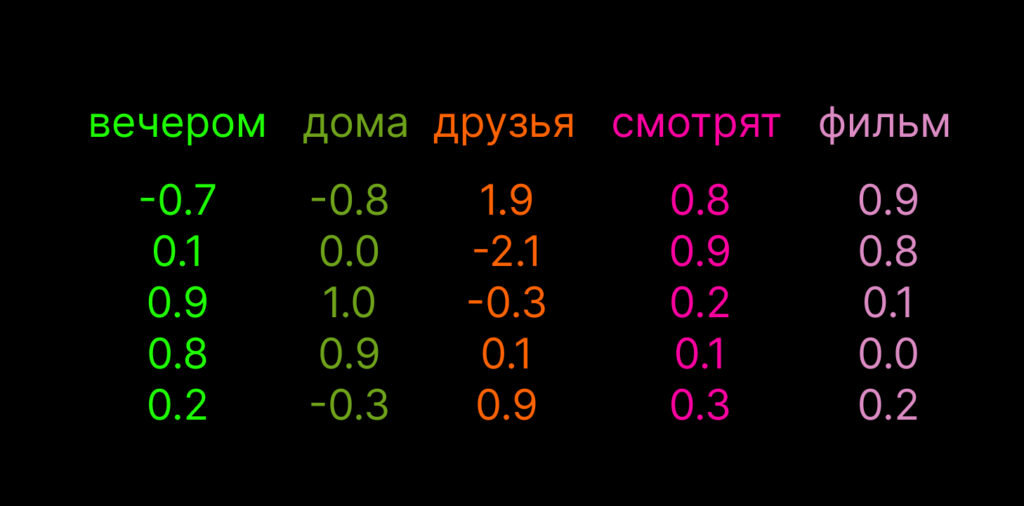
Это не настоящие векторы, но принцип тот же. Здесь видно, что слова «вечером» и «дома» и «смотрят» и «фильм» по смыслу и значению стоят ближе друг к другу, чем к остальным словам. «Вечером» и «дома» оба относятся к описанию времени и общей ситуации, а «смотрят» и «фильм» связаны как действие и объект.
Примерно так современные нейросети определяют связи между словами и смысл текста. Технически это выглядит гораздо сложнее, потому что компьютеры используют миллиарды формул и правил для таких проверок. Но в итоге машина понимает важное и запоминает смысл.
Это «внимание», или attention: машина рассчитывает значение каждого слова и связь этого слова с другими. При ответе нейросеть подбирает слова по одному, проверяя близость значений. Например, при переводе, когда нужно подобрать правильные слова под оригинальный запрос:

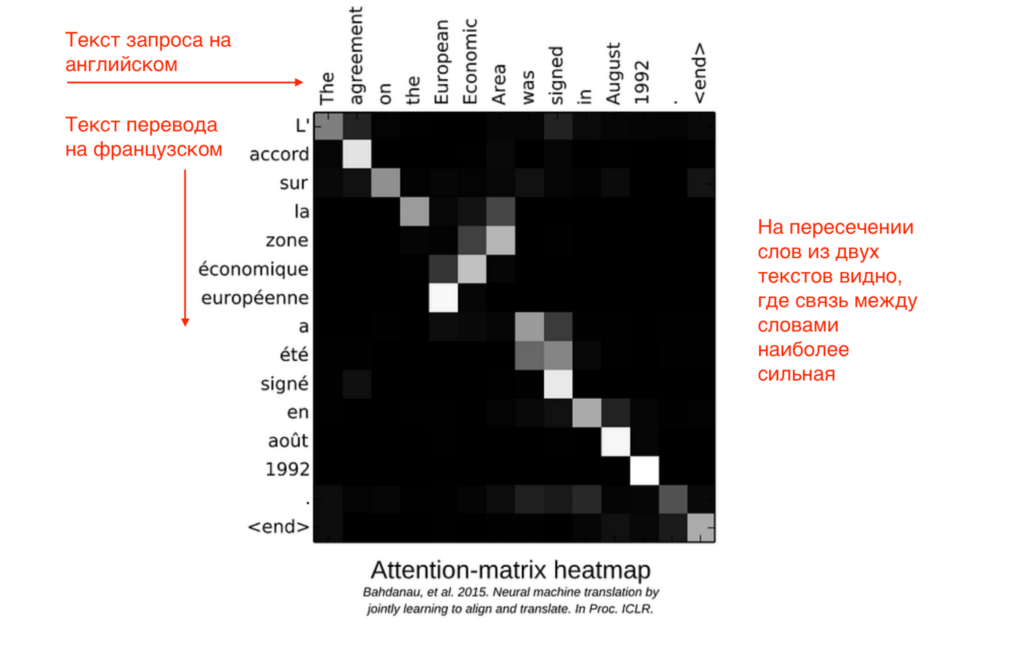
Получается тепловая карта, на которой видна связь слов ответа и запроса.
Трансформеры
Это архитектура, где главный механизм — внимание.
Все слова там проверяются одновременно. Например, текст из 1000 слов потребует построить матрицу из миллиона значений, чтобы увидеть связь каждого слова с каждым. Но современные процессоры способны обрабатывать такие объёмы данных без проблем.
Получается многопоточная система, которая умеет быстро понимать текст и строить подходящий ответ. Но ресурсов она ест при этом, конечно, уйму.
Self-attention
Это внимание, но именно внутри одного текста — например, только запроса и ответа.
Для каждого слова модель проверяет три состояния:
- Запрос — query. Это то, что нужно найти.
- Ключ — key. Это вектор, набор значений.
- Значение — value. Реальная значимость токена-слова для остального текста.
Сравнивая эти значения между токенами, модель строит связи внутри одного текста.
Multi-head attention
Современные нейросети сканируют текст сразу на несколько закономерностей, используя механизм внимания. Например, один процесс сканирует запрос на синтаксис — как слова связаны друг с другом. Другие будут проверять текст на смысловые группы, важность ключевых слов, их порядок и зависимость, эмоциональную окраску.
Сила трансформеров в том, что эти сканирования на разных слоях тоже происходят параллельно. Получается, что запрос анализируется очень быстро и очень точно.
Какие модели реализованы в разных сервисах
Во всех современных нейросетевых приложениях ядром будут трансформеры.
Но для разных задач их часто комбинируют с другими механизмами.
- Для текста — чистый трансформер.
- Для кода — трансформер, обученный на коде.
- Для изображений — трансформер и диффузионная модель.
- Для аудио — трансформер и вокодер.
- Для видео — комбинация 2D- и 3D-трансформеров, диффузионных моделей и дополнительных механизмов, таких как учёт времени.
При этом обученный на большом количестве текста трансформер часто гораздо лучше умеет писать код или переводить, чем модель, которая училась только на коде или переводах. Благодаря большому количеству данных система выводит скрытые закономерности и в итоге получает новые навыки.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.