Представьте: вы аналитик данных в интернет-магазине. Маркетологи поменяли экран оформления заказа и хотят узнать, приносит ли он больше денег. Вы запускаете A/B-тест: делите пользователей на две группы, собираете данные — и видите странную картину. В первой группе большинство покупает на 1000 рублей, но один залётный богатей купил на миллион. Во второй — все стабильно покупают на 1500 рублей, но не больше.
Если примерно посчитать среднее значение, первая группа победит из-за одного крупного покупателя. Но по факту вторая группа стабильно приносит больше денег. Как математически доказать, что вторая группа лучше и проигнорировать случайного богатея из первой?
Спойлер: нам поможет U-критерий Манна-Уитни. Разберёмся, что это за зверь, в чём его логика и как применять этот статистический тест на практике.
Что такое критерий Манна-Уитни
U-критерий Манна-Уитни — это непараметрический статистический тест, который помогает сравнить две независимые выборки и понять, есть ли между ними статистически значимые различия.
Слово «непараметрический» здесь самое главное. Это значит, что тесту неважно, как распределены ваши данные. Ему не нужна идеальная колоколообразная кривая, и не страшны безумные выбросы вроде покупки на миллион среди чеков по тысяче.
Тест работает по простому принципу: он сравнивает не сами значения, а их ранги, места в общем рейтинге. Тут как в гонке: важно не то, с каким временем пришёл каждый спортсмен, а то, кто финишировал первым, вторым, третьим. Манна-Уитни делает то же самое с данными.
Для чего нужен U-критерий Манна-Уитни
Главная задача теста — математически подтвердить или опровергнуть гипотезу, что две группы данных взяты из одной совокупности. Грубо говоря, мы хотим ответить на вопрос, отличаются ли две группы реально или разница между ними — это воля случая.
Типичные задачи U-теста — сравнивать:
- Бизнес-метрики в A/B-тестах, когда данные сильно скошены: время на сайте, сумма покупок;
- Медицинские данные — сравнить состояния пациентов до и после применения разных лекарств в двух независимых группах;
- Результаты опросов — сравнить уровень тревожности у двух разных групп респондентов.
В общем, если у вас есть две независимые группы с целевым показателем, U-тест поможет.
Зачем критерий Манна-Уитни, если есть t-критерий Стьюдента
Так уж повелось, что когда говорим о сравнении двух групп, сразу думаем о t-критерии Стьюдента. Это неспроста: t-тест мощный и классный. Но есть минус: он весьма капризный. Чтобы «тэшка» сработала правильно, нужно нормально распределить данные без сильных выбросов.
Если эти условия нарушаются, t-критерий начинает врать. Выбросы сильно смещают среднее арифметическое значение, и результаты теста становятся неадекватными.
Критерий Манна-Уитни — это ваша палочка-выручалочка. Мы применяем его вместо t-критерия Стьюдента, когда:
- Наши данные распределены ненормально — например, имеют длинный «хвост» в одну сторону;
- В данных есть очевидные аномалии и выбросы, которые мы не можем или не хотим удалять;
- Мы работаем с порядковыми данными по типу оценок, где нельзя сказать, что 4 ровно в два раза лучше 2;
- Выборки очень маленькие.
Не стоит думать, что критерий Манна-Уитни универсален — и у него есть свои требования.
Критерий Манна-Уитни и Вилкоксона: в чем разница
Новички часто путают эти два теста, потому что они оба непараметрические и оба работают с рангами. Разница фундаментальная — в типе данных:
- Критерий Манна-Уитни используется для двух независимых выборок (разные люди в разных группах).
- Т-критерий Вилкоксона (Wilcoxon signed-rank test) используется для зависимых выборок (одни и те же люди до и после какого-то события).
Если вы перепутаете тесты, вы получите совершенно неправильную оценку статистической значимости. Запомнить просто:
- Манн-Уитни — это про соревнование двух разных команд.
- Вилкоксон — это про прогресс одной команды во времени.



Условия применения критерия Манна-Уитни
Хотя этот статистический тест менее требователен, чем параметрические аналоги, у него всё же есть свои правила. Если их нарушить, результат может получиться бессмысленным.
Требования к выборкам
Для выборок правил всего два — независимость и число наблюдений от трёх.
Независимость выборок значит, что одна выборка не должна никак влиять на другую. Если вы тестируете мужскую и женскую реакцию на дизайн сайта — это независимые группы. Но если вы замеряете пульс у одних и тех же людей до чашки кофе и после — это зависимые выборки. Тут U-тест не пройдет.
В каждой группе должно быть хотя бы по три наблюдения. Если взять меньше, тест физически не сможет показать статистически значимое различие, даже если данные в группах кардинально отличаются. Максимального предела нет, но если у вас Big Data, то тест может работать долго, и там часто применяют другие инструменты — тот же t-тест подойдет лучше.
Требования к данным
У данных есть требования — ранжируемость и похожесть распределения.
Для U-критерия не имеет значения, анализируете ли вы объективные зарплаты или субъективные звездочки в отзывах. Главное условие — этим значениям в принципе можно присвоить ранги от самого малого к самому большому.
Что касается распределения: хоть тест и не требует нормального распределения, он работает лучше всего, когда форма распределения у двух групп примерно одинаковая. Если одна группа имеет форму скошенного колокола, а другая форму равномерного «кирпича», тест может показать различие не в медианах, а просто зафиксировать факт того, что формы распределения разные.
Полезный блок со скидкой
Если хотите разбираться в данных и понимать, как их использовать в реальных проектах, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Как работает критерий Манна-Уитни
Прежде чем мы закопаемся в математику и начнем сортировать числа, давайте посмотрим на алгоритм работы теста с высоты птичьего полёта.
Мы не можем просто посмотреть на средние значения и сделать выводы — нам нужно доказать, что разница не случайна. Весь процесс — от стартовой идеи до финального вывода — укладывается в пять логичных шагов:
- Формулируем гипотезы. Мы всегда начинаем с презумпции невиновности — нулевой гипотезы. Она гласит: «Между нашими выборками нет статистически значимой разницы, они пришли из одного распределения». Альтернативная гипотеза ей возражает: «Разница есть, значения одной группы явно сдвинуты относительно другой».
- Ранжируем данные. Мы берем наблюдения из обеих групп, собираем их в один ряд и выстраиваем по порядку от меньшего к большему, раздавая каждому значению его номер.
- Считаем U-статистику. Мы оцениваем, насколько сильно перемешались представители двух групп в нашей общей очереди. Для этого используем математические формулы или статистические библиотеки, чтобы получить эмпирическое значение критерия.
- Сравниваем с критическим порогом. Мы обращаемся к готовым статистическим таблицам, чтобы узнать допустимую границу случайности — критическое значение. В случае компьютерных расчетов мы смотрим на показатель p-value.
- Интерпретируем результат. Сравниваем наши расчеты с порогом отсечения. Если перемешивание слабое (представители одной группы явно вытеснили другую в конец очереди), мы отвергаем нулевую гипотезу и подтверждаем наличие различий.
Формулы скоро будут, обещаем. Но сначала скажем еще пару слов о ранжировании.
Бывает так, что два или более значений в наших группах совпадают. Например, два пользователя купили ровно на 500 рублей. Кому из них дать ранг выше?
В таких случаях используется правило связанных рангов. Мы берем позиции, которые должны были занять эти значения, и считаем их среднее арифметическое.
Например, у нас есть числа: 10, 20, 20, 30. Алгоритм следующий:
- Числу 10 присваиваем ранг 1.
- Два числа 20 претендуют на ранги 2 и 3. Мы считаем среднее: (2 + 3) / 2 = 2,5. Обоим числам 20 присваиваем ранг 2,5.
- Числу 30 присваиваем следующий ранг — 4.
Филлеры закончились, переходим к формулам.
U-критерий Манна-Уитни: формула расчета
Гуманитарии, не пугайтесь — формулы здесь требуют только умения складывать и умножать.
Расчет сумм рангов R1 и R2
Будем считать, что мы уже выстроили все наблюдения в одну общую очередь и раздали ранги. Теперь подсчитаем сумму рангов для каждой группы отдельно. Обозначим суммы рангов как R1 и R2:
R1 — это сумма всех рангов элементов, которые пришли из первой выборки.
R2 — это сумма всех рангов элементов, которые пришли из второй выборки.
Формулы для U1 и U2 и проверка правильности вычислений
Теперь нам нужно посчитать два промежуточных значения U. Формулы выглядят так:
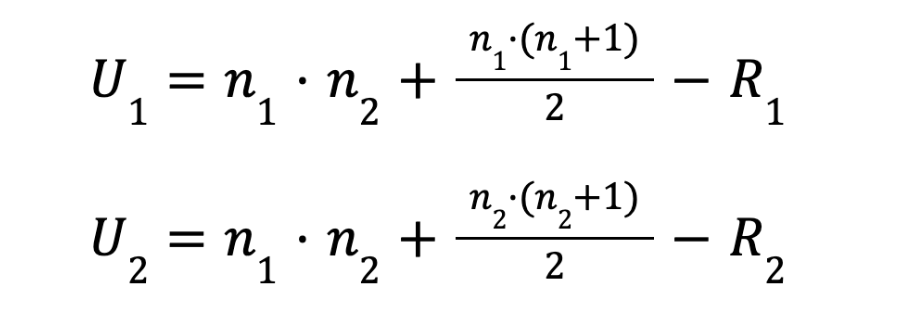
Где:
n1 и n2 — количество элементов в первой и второй выборках.
R1 и R2 — суммы рангов, которые мы посчитали шагом ранее.
Лайфхак для самопроверки: чтобы убедиться, что вы нигде не ошиблись в расчетах, сложите получившиеся U1 и U2. Их сумма всегда должна быть равна произведению размеров выборок:
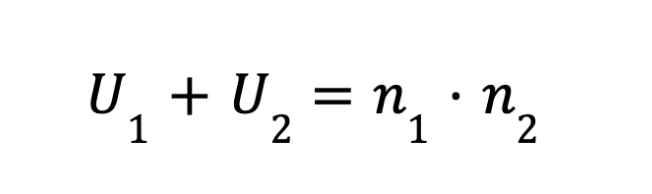
Итоговое значение U
Чтобы получить итоговую эмпирическую величину U-критерия, нам нужно просто выбрать наименьшее из двух полученных значений.
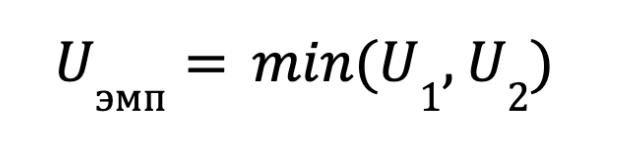
Это значение мы будем сравнивать с критическим для заданного уровня значимости α и размеров выборок n₁ и n₂ — Uкрит. Эти значения есть в специальных статистических таблицах. Вот пример такой таблицы:
| n1 / n2 | 3 | 4 | 5 |
| 3 | — | 0 | 1 |
| 4 | 0 | 0 | 1 |
| 5 | 1 | 1 | 2 |
| 6 | 2 | 2 | 3 |
| 7 | 2 | 3 | 5 |
Так, например, если в обеих выборках по 5 наблюдений, то Uкрит = 2.
Как интерпретировать результат
Вот здесь нужно быть очень внимательным, потому что логика критерия Манна-Уитни работает «наоборот» по сравнению со многими другими тестами.
Если Uэмп ≤ Uкрит (различия статистически значимы)
Чем меньше значение Uэмп, тем сильнее различаются наши выборки. Если наше эмпирическое значение попало в зону от нуля до табличного критического значения, значит, мы признаём, что различия статистически значимы.
Если Uэмп > Uкрит (различий нет)
Если рассчитанное нами значение больше табличного, мы признаём, что статистически значимых различий нет.
Пример расчета U-критерия Манна-Уитни
Давайте решим задачку руками. Допустим, мы проверяем, влияет ли цвет кнопки «Купить» на сумму заказа.
Группа 1 (Красная кнопка): 150, 400, 450, 600 рублей. n₁ = 4.
Группа 2 (Зеленая кнопка): 200, 250, 300, 800 рублей. n₂ = 4.
Сформулируем гипотезы.
Нулевая гипотеза (H0). Статистически значимых различий между группами нет. Цвет кнопки никак не влияет на сумму заказа, а разброс в наших цифрах — это просто случайное совпадение.
Альтернативная гипотеза (H1). Различия между выборками статистически значимы. Цвет кнопки действительно влияет на то, с каким чеком уходят пользователи.
Шаг 1. Объединяем и ранжируем
Выстраиваем все числа по порядку и раздаем ранги:
150 (группа 1) — ранг 1
200 (группа 2) — ранг 2
250 (группа 2) — ранг 3
300 (группа 2) — ранг 4
400 (группа 1) — ранг 5
450 (группа 1) — ранг 6
600 (группа 1) — ранг 7
800 (группа 2) — ранг 8
Шаг 2. Считаем суммы рангов
R1 (красная кнопка) = 1 + 5 + 6 + 7 = 19
R2 (зелёная кнопка) = 2 + 3 + 4 + 8 = 17
Шаг 3. Считаем U-статистику
Подставляем значения в формулы:
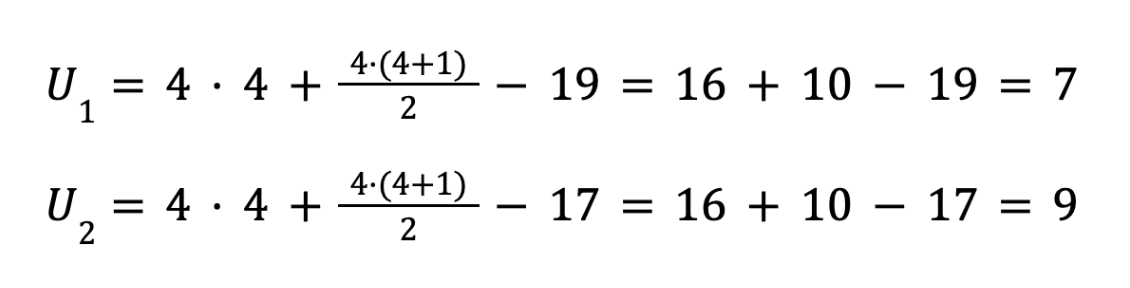
Проверяем:
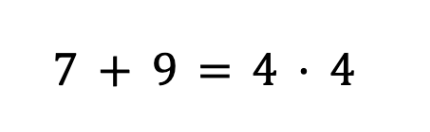
Сходится!
Для эмпирического критерия выбираем меньшее значение:
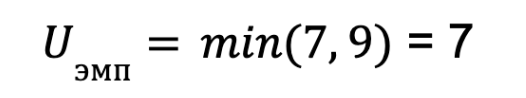
Шаг 4. Сравниваем значение с таблицей
Теперь нам нужно понять, семерка — это много или мало?
Смотрим в таблицу для стандартного уровня значимости 0.05 (это значит, что мы допускаем лишь 5% вероятности случайного совпадения):
| n1 / n2 | 3 | 4 | 5 |
| 3 | — | 0 | 1 |
| 4 | 0 | 0 | 1 |
| 5 | 1 | 1 | 2 |
| 6 | 2 | 2 | 3 |
| 7 | 2 | 3 | 5 |
Наш Uкрит= 0, а значит Uэмп > Uкрит
Шаг 5. Интерпретируем результаты
В нашем примере выше Uэмп = 7, а Uкрит = 0. Семерка больше нуля. Значит, статистически значимых различий в чеках из-за цвета кнопки мы не обнаружили. Данные перемешаны слишком сильно, чтобы говорить о победе одной из групп.

Расчет критерия Манна-Уитни в статистических пакетах
В реальной жизни руками, конечно, никто ничего не считает. Давайте посмотрим, как делегировать эту работу компьютеру.
Python
Проанализируем те самые чеки с красной и зеленой кнопок. Напишем для этого простой скрипт с NumPy и SciPy:
# импортируем библиотеку для математики и работы с массивами
import numpy as np
# импортируем функцию mannwhitneyu из модуля статистики библиотеки scipy
from scipy.stats import mannwhitneyu
# создаем массив с покупками первой группы (красная кнопка)
group_red = np.array([150, 400, 450, 600])
# создаем массив с покупками второй группы (зеленая кнопка)
group_green = np.array([200, 250, 300, 800])
# вызываем функцию для теста Манна-Уитни и сохраняем результаты
# параметр alternative='two-sided' означает, что мы ищем различия в любую сторону
stat, p_value = mannwhitneyu(group_red, group_green, alternative='two-sided')
# выводим полученную U-статистику в консоль
print(f"Статистика U: {stat}")
# выводим полученное значение p-value в консоль
print(f"P-значение: {p_value:.3f}")Скрипт отработает и выдаст:
Статистика U: 9.0
P-значение: 0.886
Если p-value в результате выполнения этого кода был бы меньше 0.05, мы бы уверенно заявили, что различие есть. Но в нашем случае цвет кнопки не сыграл роли.
Почему скрипт выдал U = 9, а не U = 7? Дело в том, что функция mannwhitneyu(x, y) по умолчанию всегда возвращает U-статистику строго для первого переданного ей массива (в нашем коде это group_red).
Если вы поменяете переменные местами и вызовете функцию вот так: mannwhitneyu(group_green, group_red), то Python посчитает статистику для зеленой кнопки и выдаст 7.
R
В R есть встроенная функция wilcox.test. Не дайте названию сбить вас с толку: если передать ей независимые выборки, она считает именно Манна-Уитни. Скрипт получится таким:
# создаем первую группу
group1 <- c(150, 400, 450, 600)
# создаем вторую группу
group2 <- c(200, 250, 300, 800)
# запускаем статистический тест для независимых выборок
wilcox.test(group1, group2, paired = FALSE)Вывод:
Wilcoxon rank sum exact test
data: group1 and group2
W = 9, p-value = 0.8857
alternative hypothesis: true location shift is not equal to 0
Смотрим на p-value, делаем выводы. Хотя последней строчкой R даже любезно делает вывод за нас :)
Частые ошибки при расчете критерия Манна-Уитни
Напоследок разберем грабли, на которые часто наступают начинающие аналитики:
- Слепая вера в то, что тест проверяет только медианы. Как мы обсуждали выше, если форма распределения в двух группах кардинально разная, тест Манна-Уитни покажет статистически значимое различие, даже если медианы у групп абсолютно одинаковые. Он проверяет общее «доминирование» одной выборки над другой, а не просто сдвиг центра.
- Игнорирование связанных рангов при ручном расчете. Если у вас в данных много повторяющихся нулей (например, количество лайков у постов) и вы не усредняете их ранги, статистика получится сильно искаженной. Благо, софт делает эту поправку под капотом автоматически.
- Применение для зависимых выборок. Об этом уже говорили: для данных «до/после» нужен тест Вилкоксона. Манн-Уитни покажет здесь чепуху.
- Слишком маленькие выборки при ожидании малого эффекта. Непараметрические тесты менее мощные, чем параметрические. Если разница между группами крошечная, а данных мало (например, по 5 человек), тест её просто не заметит.
Статистика — это не магия, а просто набор логичных инструментов. Если ваши данные шалят и выбрасывают фортеля, не пытайтесь натянуть на них классический t-тест. Доставайте из арсенала непараметрический U-критерий Манна-Уитни, и пусть ваши А/В-тесты всегда показывают объективную реальность!
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.