








Инженер данных — ещё одна интересная специальность из мира аналитики, которая даёт возможность поработать с кодом, Big Data и интересными технологиями для получения и обработки информации. Сегодня разбираем, чем именно занимается Data Engineer, сколько может заработать и как не запутаться во всех специальностях по анализу данных.
Что делает Data Engineer
Чтобы ответить на этот вопрос, сначала надо разобраться, зачем нужна аналитика в целом.
Финальная цель любой аналитической работы — получить ответ на сформулированный вопрос. Иногда данные собираются до того, как задача поставлена, иногда после. Крупные компании работают сразу в обоих направлениях: собирают всю информацию, которую могут достать, и придумывают алгоритмы для сбора ответов на нужные им вопросы.
Аналитики данных и дата-сайентисты разбираются в деталях бизнеса, много общаются с заказчиками, владельцами и другими участниками всего процесса. В какой-то момент они приходят к выводу вроде: «Есть гипотеза: чтобы повысить продажи на 5%, нужно увеличить прибыль от продажи годовых подписок. Но часть пользователей не продлевают подписку. Значит, нужно выяснить, почему пользователи прекращают пользоваться нашим продуктом на постоянной основе. Сделаем выборку по самым популярным причинам из опросов и возьмём ещё информацию отсюда и отсюда».
Данные для аналитики берут из разных мест: баз данных, хранилищ и озёр данных (про озёра будет ниже). Поступать данные могут из CRM-систем, Google-форм, аналитических метрик и других источников. При этом первоначальные данные будут сырыми, необработанными: в них будет лишняя и повторяющаяся информация или они могут быть разного формата.
Основная работа инженера данных начинается в месте сбора информации и заканчивается точками, откуда их будут забирать аналитики и дата-сайентисты.
Отличия Data Engineer от Data Scientist
Этих специалистов иногда путают — возможно, потому, что они выполняют две разные части одной работы.
Изначальную сборку данных настраивают разные специалисты:
- фронтенд-разработчики настраивают формы в веб-приложениях;
- маркетологи подключают получение информации из маркетинговых инструментов;
- аналитики добавляют записи данных в метрики;
- администраторы CRM налаживают сбор данных в CRM-системах;
- Data Engineer тоже может участвовать в этом процессе, например если нужно собирать потоковые данные в реальном времени.
Инженер данных следит за тем, чтобы все эти данные вовремя собирались, обрабатывались и были доступны для аналитиков и специалистов Data Science.
Data Scientist возьмёт эти данные и будет изучать под разными углами или обучать на них модели машинного обучения. Итогом его работы должны быть прогнозы и полезные для бизнеса выводы, основанные на большом количестве данных. Дата-сайентист может найти нужный алгоритм для анализа информации и обучить модель машинного обучения для построения точных прогнозов.
Если у дата-сайентистов возникнут сложности при работе с материалами или ему понадобятся новые данные, он обратится к дата-инженеру, и инженер решит эту проблему. Поэтому эти две специальности — просто два этапа одного большого процесса по работе с данными.







Data Engineer: кто это и почему все эти профессии так похожи?
Информации в современном бизнесе так много, что вся работа просто не умещается в одну специальность. При этом все профессии работают с биг-датой, а значит, пересекаются.
Набор навыков у специалистов тоже похожий — просто для каждой работы они должны быть развиты на разных уровнях. Например, аналитику данных нужны математика и программирование, но не на таком уровне, как они нужны дата-сайентисту. А инженеру данных программирование нужно больше, чем дата-сайентисту, но меньше, чем инженеру машинного обучения.
Задачи и функции Data Engineer
Data Engineer должен сделать данные доступными для анализа.
Для подготовки данных инженер настраивает процессы ETL — extract, transform and load (извлечение, преобразование и загрузка). Это продвинутый уровень работы с Big Data. Чтобы понять, когда нужен конвейер ETL и как он устроен, надо коротко разобрать уровни развития бизнеса. Это упрощённое понимание — в реальности эти уровни тоже могут перемешиваться друг с другом.
На первом уровне развития компании этих процессов чаще всего нет — в первые недели или месяцы. Дата-инженеров и дата-сайентистов в компании, скорее всего, тоже нет — или их функции выполняет кто-то один. Ответственный за аналитику специалист может выгружать данные из метрик вручную и сохранять в Excel-таблице. Пока клиентов и сотрудников немного, этого хватает.
На втором уровне человеческих возможностей по обработке информации уже недостаточно. Разработчики могут подключить базы данных, и информация о пользователях и внутренних процессах компании начинает сохраняться туда. Теперь данные из всех источников будут структурироваться, очищаться и загружаться в базы данных. К базам данных можно подключить системы business intelligence и визуализировать информацию на графиках и дашбордах.
На третьем уровне количество данных поднимается до уровня Big Data, когда информации накапливается действительно очень много. Теперь для работы с ней нужны аналитики и специалисты Data Science, которые будут изучать все показатели, строить прогнозные модели и визуализировать их.
Проблема в том, что обычные базы данных подходят для большого количества коротких операций, но неэффективны для аналитики и сложных запросов. Поэтому на этом этапе инженеру данных нужны другие технологии — хранилища и озёра данных.
Что такое хранилища и озёра данных
Хранилища и озёра данных — два источника материалов для работы дата-сайентиста, которые готовит к использованию дата-инженер.
Простая база данных быстро заполняется данными и изменяет их. Но данные для аналитики могут быть разного формата: отчёты продаж, метрики разных форматов, фото, видео, таблицы. В точках сбора данных эта информация сырая и неподготовленная. В ней могут быть дубли, ошибки, неправильно заполненные поля, нерелевантная информация. Базы данных плохо справляются с обработкой таких данных и будут сильно тормозить процесс.
В хранилище данных эта информация попадает очищенная и распределяется по разным директориям-таблицам соответственно своему формату. Все эти разные таблицы связаны между собой, чаще всего одной сводной центральной таблицей:

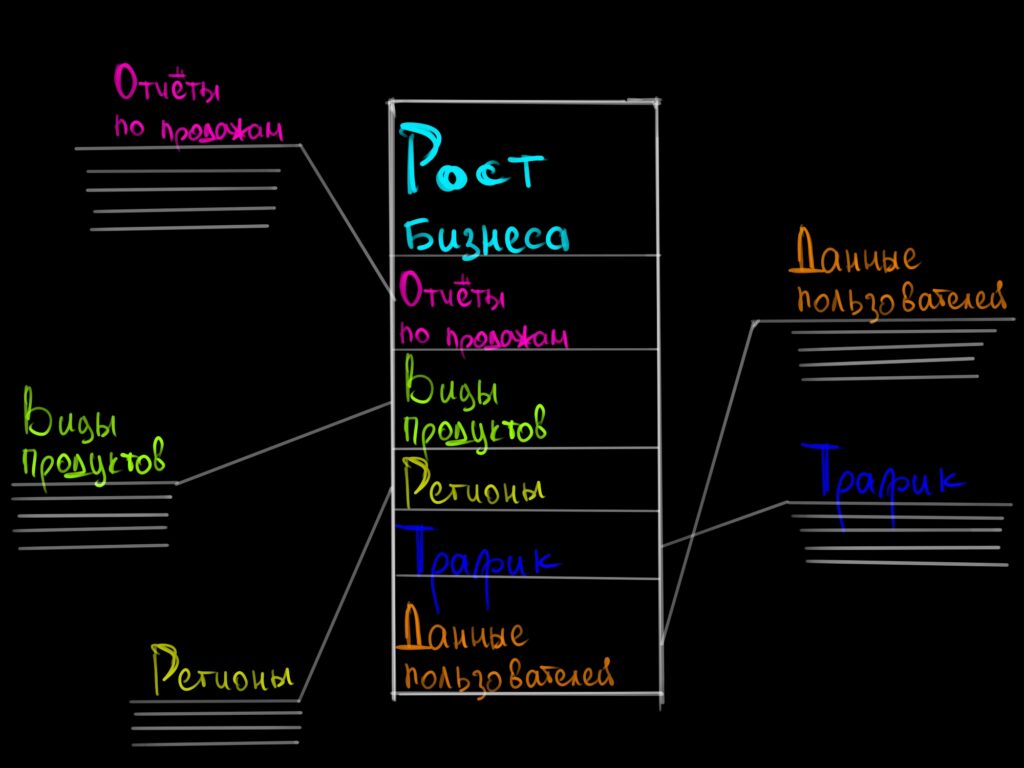
Преобразование перед добавлением информации в хранилище данных приводит данные в порядок и очищает их. Но может получиться так, что дата-сайентистам нужна вся информация, а не только очищенная.
Для таких случаев инженеры данных настраивают озёра данных, в которых хранятся все сырые данные, которые сняли через разные источники.
Хранилища и озёра данных оптимизированы для работы с аналитикой. Они быстро обрабатывают сложные запросы и отдают информацию для обучения моделей или визуализации. При этом с ними не работают как с базами данных — то есть не используют для множества частых коротких операций.


Как выглядят процессы ETL
ETL — настроенный конвейер, который автоматически извлекает записи из всех доступных компании источников и помещает в нужные хранилища или озёра данных. У этого процесса есть три основных этапа.
Первый этап — настройка извлечения данных из разных источников. Для этого понадобится настроить технологии в каждой точке. Вот что это может быть, если взять как пример работу с интернет-магазином:
- Яндекс Метрика или Google Analytics для анализа и записи поведения пользователей на веб-сайте.
- API CRM-системы и интеграционные инструменты для автоматической выгрузки данных клиентов и истории покупок.
- SQL-базы с остальной информацией и их интеграция через API.
Второй этап — перевод данных на должный уровень, то есть очистка данных и подготовка к загрузке. Вот несколько примеров того, что нужно сделать:
- Очистить записи от дублей.
- Отформатировать и привести всё к одному виду.
- Добавить дополнительные метрики, например рассчитать средний чек.
- Сопоставить данные из разных источников для проверки ошибок.
- Объединить данные в таблицы.
Третий этап — подготовленные данные загружаются в хранилище. На этом этапе биг-дата уже извлечена и подготовлена, осталось собрать её в одном месте. Теперь ей можно пользоваться для аналитики и построения прогнозных моделей.
А вот основные преимущества, которые даёт конвейер ETL:
- Упорядоченные и точные логи обо всех событиях с момента настройки ETL.
- Единый портал, где можно получить данные для аналитики.
- Увеличение продуктивности за счёт того, что ни один из процессов не нужно делать вручную — кроме первоначальной настройки.
Что нужно знать и уметь
В разных компаниях инструменты для настройки ETL различаются, но есть несколько самых популярных технологий, знание которых пригодится всегда.
Python для автоматизации и для работы с данными на всех этапах. Python-скрипты и библиотеки — универсальные инструменты, которые используются для извлечения и трансформации, потоковой обработки и визуализации. Два других популярных языка для инженеров данных — Java и Scala.
Язык запросов SQL для работы с базами данных. Хотя по большей части задачи инженера данных относятся к хранилищам и озёрам данных, базы данных тоже остаются важной частью их обязанностей.
Apache Kafka для работы с потоковыми данными в реальном времени. Это хранилище, которое позволяет хранить данные, получать и сохранять новую информацию в потоковом режиме и обмениваться ими между источниками.
Hadoop — фреймворк с открытым исходным кодом на основе языка программирования Java для управления хранением и обработкой больших объёмов данных. Hadoop включает в себя несколько составных модулей и много других инструментов и приложений для работы с данными.
Насколько сложно выучить технологии для всего этого?
Чем интереснее вам эти темы, тем проще будет выучить.
Если вы уже знаете основы программирования и понимаете, как в целом работает код, выучить остальные технологии будет относительно несложно. Хотя не все ИТ-инструменты похожи на написание программ, но сами инструменты — программы, поэтому разобраться в принципах их работы уже проще.
Главное, учить системно, постоянно и структурированно, даже небольшими объёмами. Постепенно вы привыкнете к миру дата-инженерии, начнёте мыслить в нужном направлении и поймёте, чем будете заниматься.
Востребованность профессии
Инженер данных — профессия для больших компаний. Но большим компаниям нужно много инженеров данных, потому что Big Data означает не только много информации, но и определённые правила для работы с ней.
Настоящая big data характеризуется четырьмя тезисами, начинающимися с буквы V:
- Volume (объём) — большой объём информации.
- Variety (разнообразие) — данные могут быть различного вида.
- Veracity (достоверность) — информация должна быть правдивой, чтобы основанные на ней прогнозы аналитиков тоже были правдивыми.
- Velocity (скорость) — новые данные появляются постоянно в режиме реального времени.
Записи в Big Data появляются миллионами каждую секунду, и возможности для их использования увеличиваются постоянно. Сами компании тоже растут, поэтому в ближайшие годы количество вакансий инженеров данных будет увеличиваться.
Сколько получает Data Engineer
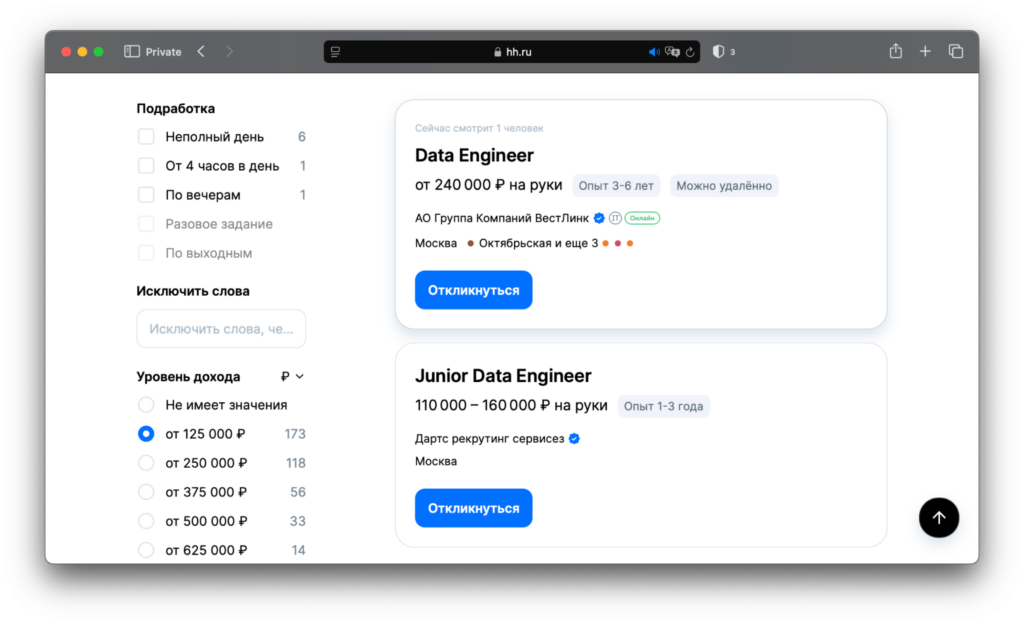
Сайт hh.ru показывает, что сейчас в России открыты 1 500 вакансий инженера по данным, при этом в 173 вакансиях предлагают оплату выше 125 000 рублей:

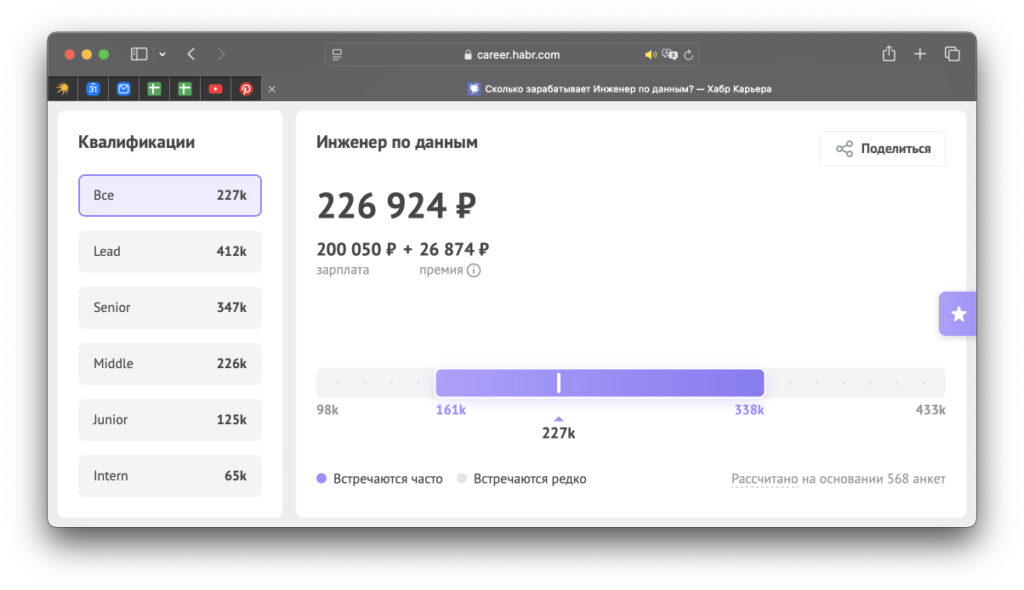
Хабр Карьера показывает среднюю зарплату дата-инженера в 226 924 рубля. Если разбить по грейдам, 125 000 получают специалисты уровня джуниор, 226 000 — уровня мидл, сеньоры зарабатывают 347 000 рублей:

Плюсы и минусы профессии Data Engineer
Хорошие зарплаты. Это сравнительно новая профессия, которая напрямую влияет на доходность бизнеса и приносит деньги компаниям. Поэтому владельцы бизнеса готовы много платить хорошим специалистам.
Разнообразная работа. Инженеру данных часто нужно решать разнообразные задачи и знакомиться с новыми технологиями. Это помогает сохранять интерес и развиваться.
Возможности для развития. Data Engineer может развиваться как в своей профессии, так и перейти в другую, если захочет сменить основное направление. Можно изучить недостающие знания и стать DevOps или MLOps-инженером, бэкенд-разработчиком и архитектором ПО или Data Scientist, если интересует математика.
Порог входа высокий и абстрактный. Инженер данных должен уметь много всего, но при этом чётких требований к профессии нет. Необходимые навыки могут зависеть от конкретной компании, поэтому при подготовке к собеседованиям полезно немного изучить возможное будущее место работы и понять, что предстоит там делать.
Если хотите подготовить себя к новой профессии или прокачать знания и пополнить портфолио, попробуйте курсы Практикума «Инженер данных» и «Инженер данных с нуля». В непонятных моментах подскажут опытные специалисты и наставники, а в конце курса карьерный центр поможет подготовиться к поиску работы.
















