








Представьте, что вы работаете в банке. К вам приходит клиент и просит кредит на миллион рублей. У вас есть его данные: возраст, зарплата, стаж работы и кредитная история. Вам нужно принять решение: выдавать деньги или нет.
Лучше доверить такое решение алгоритму, а не интуиции. В машинном обучении для таких задач есть классический надежный инструмент — логистическая регрессия.
Сегодня мы разберем, что такое логистическая регрессия, как она работает и почему аналитики данных до сих пор ее обожают.
Что такое логистическая регрессия
Логистическая регрессия — это алгоритм машинного обучения, который используется для предсказания вероятности того, что объект принадлежит к определенному классу. Например, алгоритм анализирует текст входящего письма и выдаёт: «Вероятность того, что это спам — 98%». Опираясь на эту цифру, почтовый сервис понимает, что сообщение нужно автоматически перенести в папку «Спам».
Это базовая, но невероятно мощная модель, которая лежит в основе многих современных рекомендательных систем и классификаторов. Главная задача, которую решает этот метод — классификация. Нам нужно посмотреть на данные и сказать, произойдет какое-то событие или нет. Клиент вернет долг или просрочит платеж? Письмо — это спам или важное сообщение от коллеги? Пациент болен или здоров? Во всех этих случаях зависимый переменный признак (наш ответ) принимает одно из двух значений. Либо да, либо нет. Либо 1, либо 0.
Чаще всего алгоритму задают вопросы с двумя вариантами исхода: произойдет событие или нет. Клиент вернет долг или просрочит платеж? Письмо — это спам или важное сообщение от коллеги? Пациент болен или абсолютно здоров? В этих случаях зависимый переменный признак (наш ответ) принимает одно из двух значений: либо 1, либо 0.

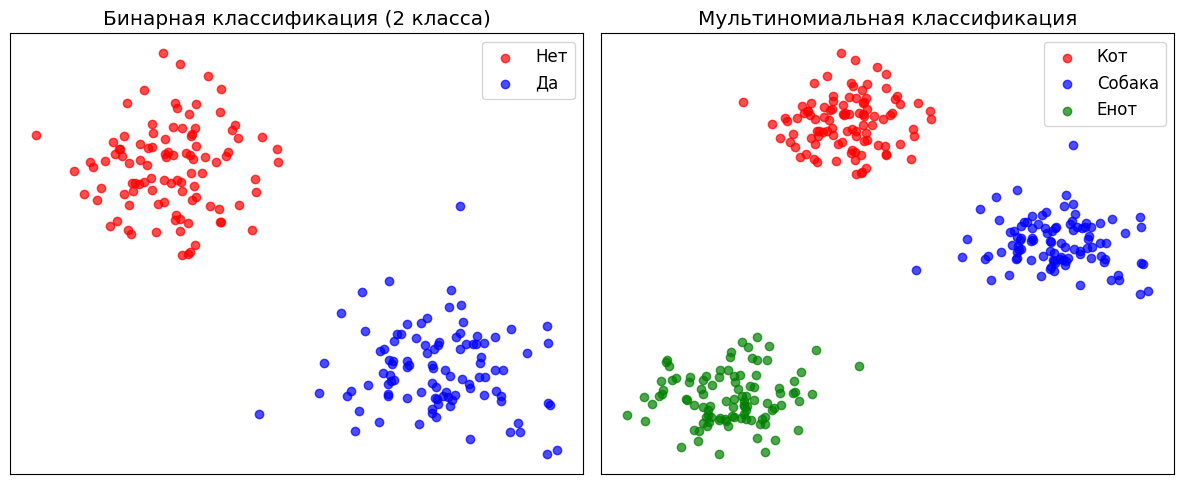
Слева — бинарная классификация (два варианта), справа — мультиномиальная (несколько вариантов).
Но логистическая регрессия отлично справляется и с задачами, где классов больше двух. Например, алгоритм может проанализировать фотографию животного и определить: это кот, собака или енот? Или прочитать отзыв на фильм и понять его тональность: позитивная, нейтральная или негативная? В таком случае модель просто рассчитает вероятность для каждого возможного варианта и выберет тот, где процент выше всего.
Чем логистическая регрессия отличается от линейной
В классической статистике линейная регрессия используется для того, чтобы предсказать какое-то непрерывное число. Например, зная площадь квартиры и расстояние до метро, линейная модель предскажет её стоимость: 5, 10 или 20 миллионов рублей.
Но что будет, если мы попытаемся натравить линейную регрессию на задачу классификации? Допустим, мы пытаемся предсказать выдачу кредита, где 0 — это отказ, а 1 — одобрение.
Линейный алгоритм построит прямую линию. Проблема в том, что прямая линия уходит в бесконечность. Для клиента с огромной зарплатой она может предсказать значение +15, а для безработного студента выдать -42.

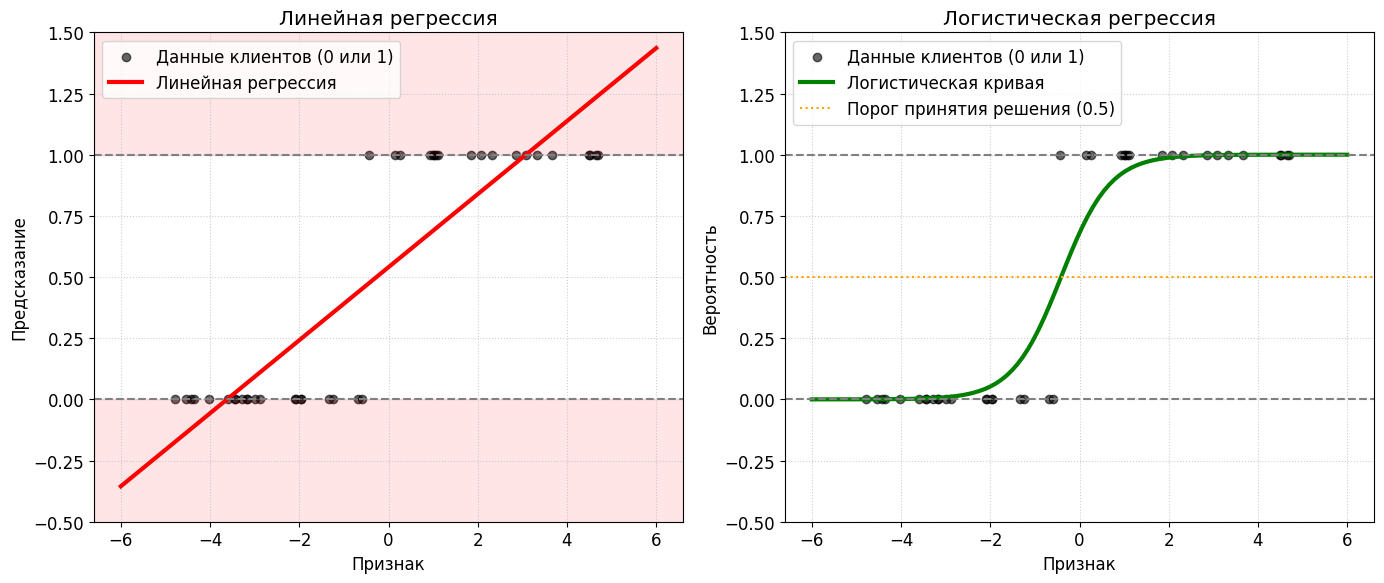
На графике слева линейная прямая уходит вверх и вниз, выдавая бессмысленные для нашей задачи числа. Справа — логистическая кривая (S-образная), которая аккуратно прижимает все предсказания к диапазону от 0 до 1.
Как нам интерпретировать значение -42, если мы ждем ответ «да» или «нет»? Никак. Именно поэтому математики придумали другой подход. Логистический алгоритм предсказывает не саму метку, а вероятность того, что событие произойдет. А вероятность всегда находится в строгих рамках от 0 до 1.
Полезный блок со скидкой
Если хотите разбираться в данных и понимать, как их использовать в реальных проектах, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Как работает логистическая регрессия
Модель превращает данные в вероятность в три шага — суммирует признаки умноженные на коэффициент важности, вычисляет на основе полученного логита вероятность и сравнивает эту вероятность с порогом принятия решения.
Скалярное произведение и логиты
На первом этапе алгоритм работает точно так же, как и линейная модель. У нас есть признаки клиента: возраст, зарплата, стаж. Модель присваивает каждому признаку свой коэффициент важности, или вес. Например, размер зарплаты для выдачи кредита важнее, чем возраст, поэтому вес у зарплаты будет больше.
Модель берет значение каждого признака, умножает на его вес и складывает всё вместе. К этой сумме прибавляется некоторое базовое значение — константный сдвиг. В результате мы получаем какое-то число от минус бесконечности до плюс бесконечности. В математике машинного обучения это число называют логитом или отступом.
Сигмоида — логистическая функция
Теперь нам нужно превратить этот сырой логит в понятную вероятность от 0 до 1. Для этого используется специальная математическая функция — сигмоида. Вот её формула:

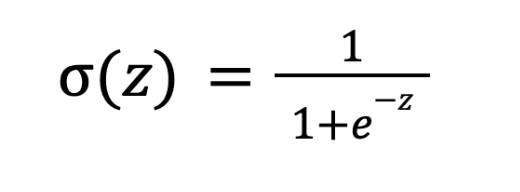
Где:
z — логит,
e — константа, примерно равная 2,71828.

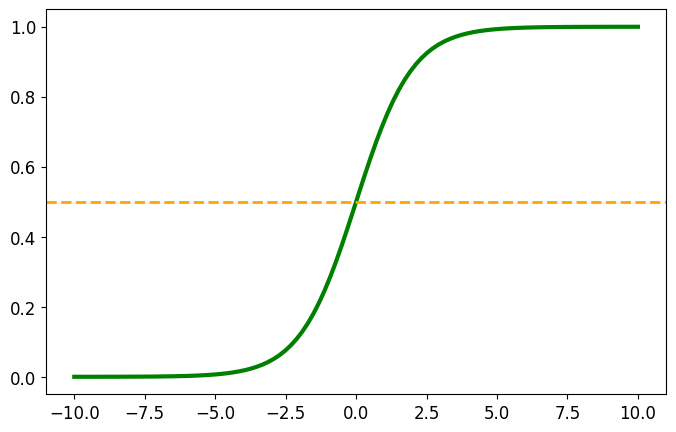
Функция плавно переводит любое число на горизонтальной оси в диапазон от 0 до 1 на вертикальной оси.
Если логит равен нулю, функция выдает ровно 0.5 (вероятность 50%). Если число большое и положительное (например, +10), сигмоида выдаст значение, очень близкое к 1. Если число сильно отрицательное (-50), мы получим почти 0.
Классификация
Модель поработала и сказала: вероятность того, что этот клиент вернет кредит, равна 0.85 (85%). Что нам делать с этой информацией?
Чтобы алгоритм выдал финальный класс — 0 или 1, устанавливается порог принятия решения. По умолчанию он равен 0.5. Если предсказанная вероятность 0.5 — алгоритм говорит «Да» (класс 1).
Если вероятность < 0.5 — алгоритм говорит «Нет» (класс 0).
В реальном бизнесе этот порог можно двигать. Например, если в стране кризис и банк хочет выдавать кредиты только самым надежным клиентам, порог можно поднять до 0.8 или даже 0.9.




Как модель машинного обучения учится на ошибках
Любая модель машинного обучения не знает правильных весов с самого начала. Она расставляет их случайным образом, а затем учится на исторических данных. Но как она понимает, что ошибается?
Метод максимального правдоподобия
В основе обучения лежит статистический метод максимального правдоподобия. Проще говоря — мы подгоняем данные: ищем такие веса для наших признаков, при которых вероятность получить именно те данные, которые мы реально видим перед собой, будет максимальной.
Функция потерь Log Loss
Чтобы корректировать веса, алгоритму нужна функция потерь — инструмент, который будет штрафовать модель за ошибки. Обычный подсчет доли неправильных ответов здесь не работает, потому что он слишком грубый и его невозможно дифференцировать (а это нужно для математики).
Для логистической регрессии используется функция потерь Log Loss — логистический функционал потерь.

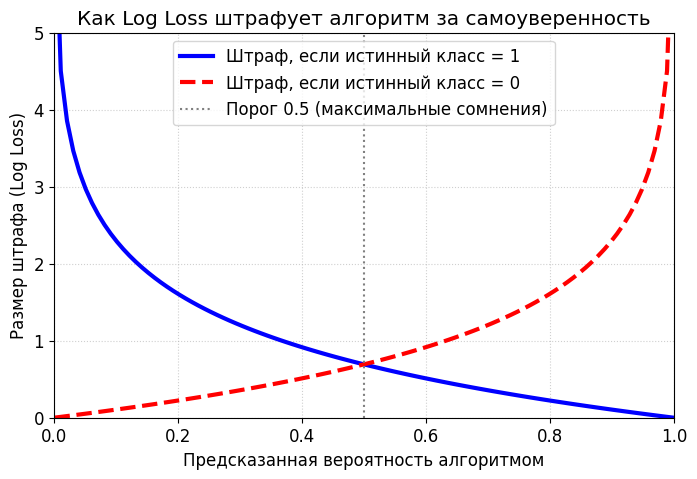
График функции Log Loss. Штраф улетает в бесконечность, если модель уверенно предсказывает абсолютно неправильный ответ.
Её смысл в том, что она использует логарифмы, чтобы наказывать алгоритм за чрезмерную самоуверенность. Если пациент здоров (класс 0), а модель предсказывает, что он здоров с вероятностью 10%, она получит небольшой штраф — ошиблась, бывает. Но если пациент здоров, а модель настаивает «Он болен с вероятностью 99%!», штраф будет гигантским. Модель должна быть не только точной, но и адекватно оценивать свою уверенность.
Градиентный спуск
Чтобы свести нашу ошибку к минимуму, используется метод градиентного спуска.
Представьте человека с завязанными глазами на вершине горы, которому нужно спуститься в самую низкую точку долины. Он нащупывает землю ногой, определяет, где самый крутой уклон вниз (это и есть антиградиент), и делает шаг в эту сторону.
Алгоритм делает то же самое: вычисляет производные функции потерь, немного меняет веса признаков и делает шаг вниз. И так повторяется сотни раз, пока ошибка не перестанет падать.

Типы моделей классификации
Логистическая регрессия бывает разной, всё зависит от того, сколько классов нам нужно предсказать.
Бинарная
Это классический вариант, о котором мы говорили выше. У нас есть два варианта исхода. Да или нет. Черное или белое. Выдаём кредит или отказываем.
Мультиномиальная
Что делать, если нам нужно предсказать не два класса, а десять? Например, мы анализируем фотографию животного, и алгоритм должен понять: это кот, собака или енот?
Для этого создаются отдельные наборы весов для каждого класса. Мы получаем сразу несколько сырых логитов. А вместо классической сигмоиды мы пропускаем их через функцию Softmax. Эта функция возводит логиты в степень экспоненты и нормирует их так, чтобы сумма вероятностей всех классов равнялась ровно единице, или 100%. Модель может выдать: кот — 70%, собака — 20%, енот — 10%. Значит, на фото скорее всего кот.
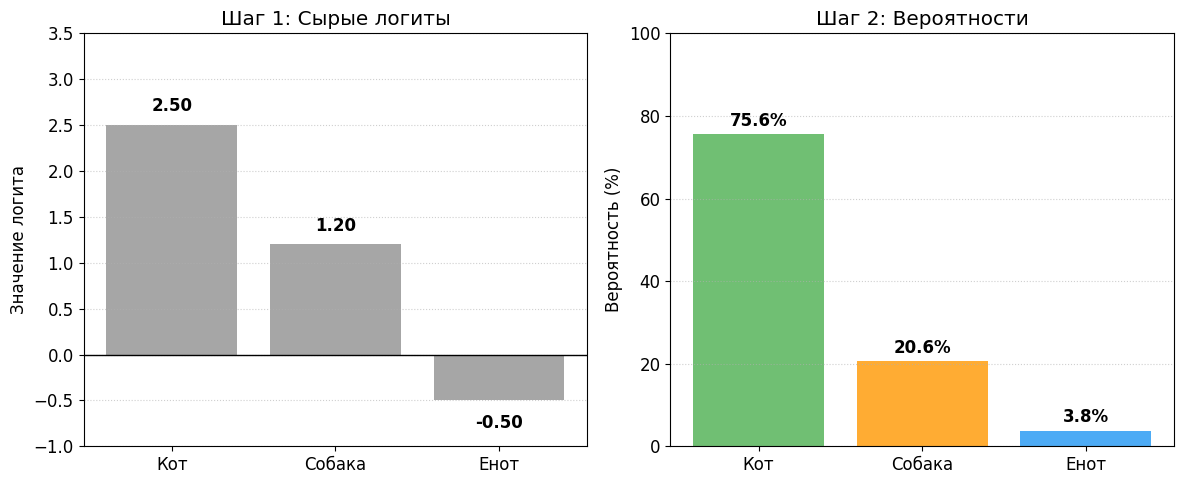
Softmax переводит абстрактные логиты в понятные вероятности.
Альтернатива: пробит-модель
В литературе по анализу данных иногда можно встретить термин пробит-модель. По сути, это близкий родственник логистической регрессии. Вся разница кроется в функции, которая переводит сырые логиты в вероятности. Если логистическая регрессия использует сигмоиду, то пробит-модель использует функцию распределения стандартного нормального распределения. На практике результаты этих двух моделей почти не отличаются, но исторически так сложилось, что социологи и экономисты предпочитают пробит, а программисты — логит.

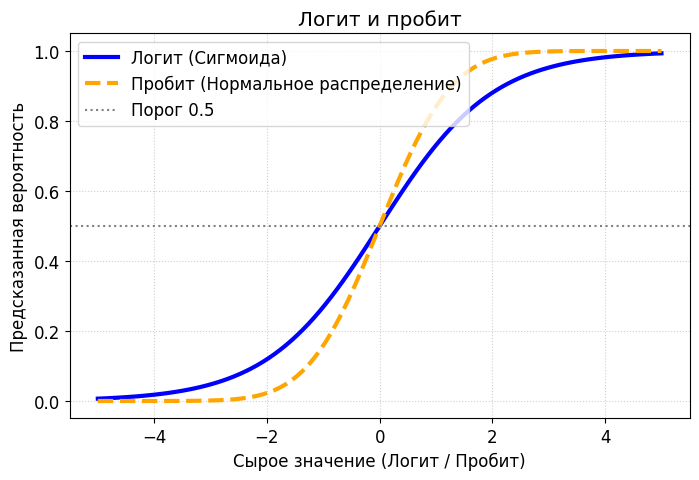
Где сигмоида, а где половина гауссова «колокольчика»? Сходу и не скажешь.
Как логистическую регрессию спасают от переобучения
Иногда алгоритм так сильно пытается подстроиться под обучающие данные, что начинает находить ложные, несуществующие закономерности. Он идеально решает тренировочную задачу, но полностью проваливается на новых данных. Это называется переобучением. Чтобы с этим бороться, применяется регуляризация.
L1 и L2 регуляризация: что выбрать
Регуляризация — это искусственный штраф за слишком большие значения весов.
L1 умеет обнулять веса неважных признаков. Если вы загрузили в модель 1000 параметров пользователя, L1 сама поймет, какие из них мусорные, и оставит только 50 самых важных, умножив веса остальных на ноль.
L2 работает иначе: она не обнуляет веса полностью, но делает их маленькими и равномерными. Она защищает модель от ситуации, когда один-единственный признак перетягивает на себя всё внимание алгоритма.
Как работать с логистической регрессией на Python
Аналитики данных редко пишут математические формулы и алгоритмы градиентного спуска с нуля. Для этого есть готовые библиотеки, самая популярная из которых — scikit-learn. В ней логистическая регрессия уже упакована в один удобный класс, и всё обучение сводится к паре строчек кода.
Давайте посмотрим, как обучить модель предсказывать выдачу кредита на практике. Для демонстрации мы создадим крошечную базу данных из семи клиентов банка, обучим на них алгоритм, а затем попросим его принять решение по новому человеку.
# импортируем библиотеку pandas для работы с таблицами
import pandas as pd
# импортируем готовую модель логистической регрессии из scikit-learn
from sklearn.linear_model import LogisticRegression
# 1. ГЕНЕРИРУЕМ ДАННЫЕ
# Зарплата (тыс. руб.), Возраст (лет) и Возврат кредита (1 -- вернул, 0 -- не вернул)
bank_data = pd.DataFrame({
'salary': [50, 20, 120, 80, 30, 200, 15],
'age': [25, 20, 45, 35, 22, 50, 18],
'returned': [0, 0, 1, 1, 0, 1, 0]
})
# 2. ПОДГОТАВЛИВАЕМ ПРИЗНАКИ И ОТВЕТЫ
# X_train -- это таблица только с признаками клиентов (зарплата и возраст)
X_train = bank_data[['salary', 'age']]
# y_train -- это правильные ответы из прошлого (вернул или нет)
y_train = bank_data['returned']
# 3. ОБУЧАЕМ МОДЕЛЬ
# создаем пустую модель
model = LogisticRegression()
# обучаем её командой fit (она сама подберет идеальные веса для зарплаты и возраста)
model.fit(X_train, y_train)
# 4. ПРИНИМАЕМ РЕШЕНИЕ ПО НОВОМУ КЛИЕНТУ
# к нам пришел новый клиент: зарплата 90 тыс. руб., возраст 30 лет
new_client = pd.DataFrame({'salary': [90], 'age': [30]})
# просим обученную модель предсказать, выдавать ли ему кредит (получим 0 или 1)
prediction = model.predict(new_client)
# а если мы хотим узнать точную вероятность в процентах:
probability = model.predict_proba(new_client)
# выводим результат на экран
print(f"Решение алгоритма (класс): {prediction[0]}")
print(f"Вероятность невозврата (класс 0): {probability[0][0]:.2f}")
print(f"Вероятность возврата (класс 1): {probability[0][1]:.2f}")Вывод получится таким:
Решение алгоритма (класс): 1
Вероятность невозврата (класс 0): 0.00
Вероятность возврата (класс 1): 1.00
Как видите, всё просто. Команда fit под капотом запускает всю ту сложную математику с поиском минимальной ошибки, о которой мы говорили раньше. А команда predict выдает готовый результат.


Как работать с логистической регрессией на R
В R логистическая регрессия чувствует себя как дома — она работает прямо «из коробки», без установки тяжелых дополнительных библиотек.
Чтобы обучить модель в R, используется базовая функция glm(). Сгенерим демонстрационные данные и запустим её.
# 1. ГЕНЕРИМ ДАННЫЕ
bank_data <- data.frame(
salary = c(50, 20, 120, 80, 30, 200, 15, 100, 40, 70, 60, 150),
age = c(25, 20, 45, 35, 22, 50, 18, 35, 40, 45, 28, 30),
returned=c(0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 1, 1)
)
# 2. ОБУЧАЕМ МОДЕЛЬ
model <- glm(returned ~ age + salary, data = bank_data, family = "binomial")
# 3. ИЗУЧАЕМ СТАТИСТИКУ
# Теперь математика сойдется идеально, и мы увидим реальный вклад каждого фактора
summary(model)
# 4. ПРИНИМАЕМ РЕШЕНИЕ ПО НОВОМУ КЛИЕНТУ
new_client <- data.frame(salary = 90, age = 30)
probability <- predict(model, newdata = new_client, type = "response")
# выводим результат
print(probability)Скрипт выдаст:
Call:
glm(formula = returned ~ age + salary, family = "binomial", data = bank_data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -3.88033 2.95326 -1.314 0.189
age 0.06250 0.09660 0.647 0.518
salary 0.02508 0.02223 1.128 0.259
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 16.636 on 11 degrees of freedom
Residual deviance: 11.487 on 9 degrees of freedom
AIC: 17.487
Number of Fisher Scoring iterations: 5
А вывод последней команды получится таким:
1
0.5625509
Главная фишка R кроется в функции summary(). Если в Python для получения детального научного отчета пришлось бы тянуть отдельную библиотеку, то в R эта короткая команда сразу покажет вам всё. Она выведет на экран значения коэффициентов, их стандартные ошибки и уровни значимости. Аналитик с первого взгляда понимает, какие признаки реально влияют на выдачу кредита, а какие — просто информационный шум, который нужно выкинуть из модели.
Где применяется логистическая регрессия
Этот алгоритм окружает нас повсюду, управляя механикой привычных сервисов.
Банки: кредитный скоринг
Самый популярный пример. Банки собирают о вас сотни параметров и пропускают через логистическую регрессию. Модель выдает вероятность дефолта. Если вероятность невозврата долга выше заданного порога — вам автоматически приходит отказ.
Маркетинг: прогнозирование оттока клиентов
Операторы связи не любят терять абонентов. Они используют логистическую модель для предсказания оттока. Алгоритм анализирует: как часто вы звоните в техподдержку, как давно меняли тариф, падает ли ваш трафик. Если вероятность вашего ухода высока, система заботливо пришлет вам SMS со скидкой на абонентскую плату.
Медицина: диагностика заболеваний
Врачи используют классификацию для помощи в постановке диагнозов. Загрузив результаты анализов крови, данные МРТ, давление и возраст пациента, модель может с высокой точностью оценить вероятность развития сердечно-сосудистых заболеваний или диабета.
В итоге, логистическая регрессия нужна везде, где нужно предсказать ситуацию так, чтобы решение укладывалось в ограниченное количество вариантов.
Частые ошибки при работе с логистической регрессией
Даже идеальную математику можно сломать, если использовать её неправильно. Вот главные грабли, на которые наступают дата-саентисты.
Игнорирование качества данных
В англоязычной среде работы с данными говорят: «мусор на входе — мусор на выходе». Если в вашей обучающей таблице есть задвоенные строки, пустые ячейки или возраст клиента указан как 250 лет, модель обучится на этом мусоре. Вычищение выбросов и подготовка датасета — это 80% успеха всего проекта.
Слепая вера в алгоритм без бизнес-логики
Математика стерпит всё. Вы можете загрузить в алгоритм количество кроликов в Австралии и попытаться предсказать курс биткоина. Машина посчитает вам веса и выдаст формулу. Но в этом нет никакого смысла. Всегда нужно понимать предметную область и оценивать, есть ли реальная логическая связь между признаком и ответом.
Переусложнение модели
Неопытные дата-специалисты часто пытаются выбить стопроцентную точность, забрасывая в модель сотни новых параметров. Золотое правило опытных аналитиков гласит: чем проще регрессия, тем стабильнее она работает. Слишком сложная модель выучит данные наизусть, но сломается при столкновении с реальным миром.
Путаница в метриках оценки
Самая грубая ошибка — проверять качество алгоритма на тех же данных, на которых он обучался. Это как дать школьнику ответы на экзамен, а потом восхищаться его знаниями. Данные всегда нужно делить на тренировочную и тестовую выборки.
Если вам интересно писать код и вы хотите разобраться, какой язык программирования выбрать для старта, — держите скидку 16% на все курсы Практикума. Она действует с 10 по 31 марта.
Вам слово
Приходите к нам в соцсети поделиться своим мнением о статье и почитать, что пишут другие. А ещё там выходит дополнительный контент, которого нет на сайте — шпаргалки, опросы и разная дурка. В общем, вот тележка, вот ВК — велком!























