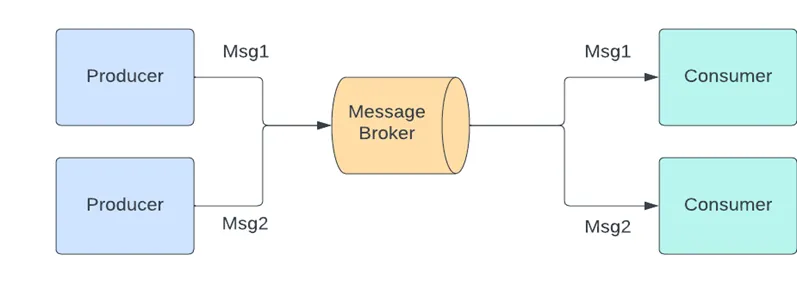
Сегодня рассказываем об очередях (или брокерах) сообщений — инструменте, который позволяет современным приложениям не ломаться под высокой нагрузкой и делает всю архитектуру более устойчивой к ошибкам. Мы разберём, что это вообще за технология, и посмотрим на два популярных варианта очередей: RabbitMQ и Kafka.
Что за сообщения в очередях
Сообщения в сегодняшней статье — фрагменты данных, которые один сервис в системе программ хочет передать другому.
Сервисы обмениваются такими сообщениями асинхронно. Асинхронные операции используют время потенциального простоя. Например, когда сервис ждёт ответа от другого сервиса, он может выполнять другие операции. Тогда машина максимально использует возможное время для работы.
Как это выглядит применительно к очередям: когда один сервис в системе создаёт сообщение, он просто отправляет его в брокер и убеждается, что очередь приняла это сообщение. После этого он может продолжать создавать сообщения или вообще заниматься другой полезной работой. Создавший данные сервис не ждёт, пока с этим сообщением что-то произойдёт — в этом и заключается асинхронность.

Ключевые термины
Чтобы было удобнее разбираться, вот несколько понятий, которые используются в нашей и других профессиональных статьях на тему очередей и сообщений.
- Производитель (producer) — сервис, который создаёт сообщения.
- Потребитель (consumer) — сервис, получающий сообщения.
- Очередь (queue) получает и хранит сообщения от производителей.
- Соединение (connection) — канал связи между приложением и брокером, обычно по протоколу TCP.
- Обменник (exchange) получает сообщения от производителей и отправляет их в очереди в зависимости от установленных правил. Очередь должна быть привязана как минимум к одному обменнику для получения сообщений.
- Привязка (binding) — правила, которые обменники используют для маршрутизации сообщений в очереди.
- Ключ маршрутизации (routing key) — ключ, который обменник использует для определения адреса доставки сообщения из очереди.
Что такое очереди сообщений и зачем они нужны
Брокеры сообщений выступают посредниками между сервисами.
Например, producer-сервис железнодорожной станции создаёт сообщения-сигналы о прибытии поезда. Он отправляет это сообщение в брокер и продолжает заниматься своими делами. Такой producer может дальше отслеживать прибытие поездов, а может выполнять другие функции. Главное, что ему не нужно следить за созданными им сигналами.
При этом в системе есть consumer-сервис, который берёт этот сигнал, открывает ворота на станции, фиксирует время на табло и выполняет остальные необходимые команды. Иногда брокер сам доставляет сообщение consumer-сервису, а иногда просто хранит его, пока сообщение не заберут.
Благодаря очередям сервисы не связаны напрямую — это снижает связанность компонентов и система становится устойчивее.
Очереди особенно полезны при неравномерной нагрузке. Например, днём поступает 100 сообщений в минуту, а ночью — 2. Очередь сглаживает пики, потому что consumer-сервис обрабатывает сообщения с приемлемой для себя скоростью, а не с той, с которой они приходят в реальной жизни.
У разных брокеров разные модели работы, но в общем виде это выглядит просто: одни сервисы публикуют сообщения в очереди, другие — получают.
Обзор RabbitMQ
Классический брокер сообщений, который реализует протокол AMQP. Этот протокол устанавливает правила направления, хранения и доставки сообщений.
RabbitMQ давно существует, хорошо документирован и часто становится первым инструментом разработчика для работы с очередями.
Принципы работы RabbitMQ
RabbitMQ ориентирован на надёжную доставку сообщений между сервисами. Он хорошо подходит для сценариев, где важно, чтобы каждое сообщение было обработано.
В основе RabbitMQ лежит идея обменников и очередей. Отправитель публикует сообщение в обменник, а обменник решает, в какие очереди это сообщение попадёт. Это удобно для гибкого управления сообщениями.
Обратите внимание, что здесь очередью может называться как брокер сообщений в целом, так и отдельное хранилище внутри него. Получается, что это может быть внутренняя очередь внутри глобальной.
Архитектура RabbitMQ
Схема работы выглядит так:
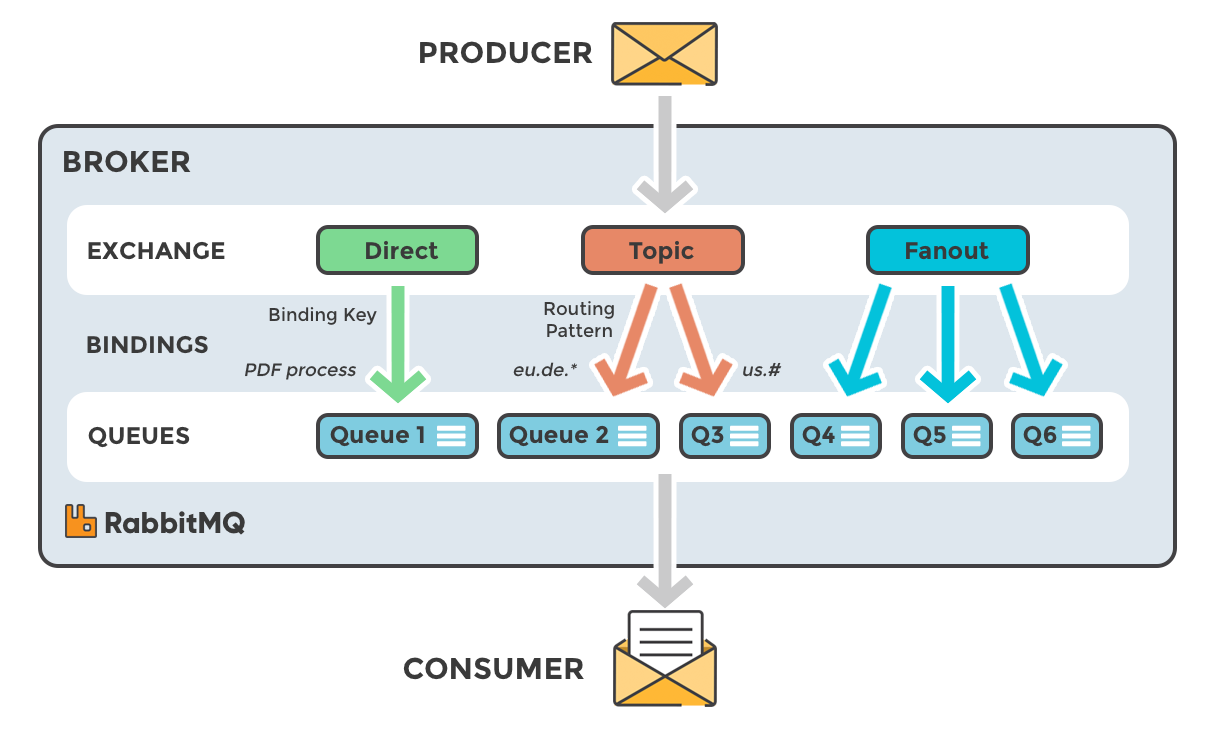
Производитель публикует сообщение, которое уходит в обменник.
Обменник решает, чему сообщение соответствует. Direct — точное совпадение, topic — совпадение с заданным правилом, fanout — разослать всем.
Binding — правила связи между обменником и очередями.
В зависимости от условий сообщения уходят в разные очереди внутри брокера сообщений. Можно настроить обменник так, чтобы сообщения с типом order.created шли в одну очередь, а order.canceled — в другую. Получатели связываются с конкретными очередями и получают только нужные сообщения.
RabbitMQ работает по модели push и сам доставляет сообщения потребителю. Но чтобы не перегрузить потребителя, количество сообщений можно ограничить.
Плюсы и минусы RabbitMQ
Главный плюс RabbitMQ — простота и предсказуемость. Он хорошо подходит для большинства прикладных задач и легко интегрируется с популярными языками и фреймворками.
Ещё этот брокер можно настроить для сложной бизнес-логики.
С другой стороны, для больших объёмов данных RabbitMQ имеет ограничения и не предназначен для долгого хранения сообщений.
Сценарии использования RabbitMQ
RabbitMQ — безопасный и понятный выбор для небольших и средних проектов.
Этот брокер хорошо подходит для асинхронных задач внутри бизнес-приложений: отправка имейл-уведомлений, обработка фоновых задач, интеграция с платёжными системами. Его часто используют там, где важна точная доставка. Тогда сообщение будет либо доставлено, либо отправлено заново.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Обзор Apache Kafka
Apache Kafka — распределённая платформа для обработки потоков данных. Этот инструмент мощнее RabbitMQ, но сложнее в использовании.
Принципы работы Apache Kafka
Kafka изначально проектировался как система для работы с большими объёмами событий, поэтому справляется там, где RabbitMQ не хватает возможностей.
Kafka часто называют не очередью, а журналом событий. Он хранит сообщения долгое время и позволяет перечитывать их.
Архитектура Kafka
Kafka — распределённая система, которая состоит из нескольких брокеров. Брокеры хранят данные и копируют их между собой. Сообщения хранятся на диске и могут оставаться там долгое время. Это позволяет обрабатывать события повторно.
В Kafka сообщения записываются в топики (topic). Выше мы разбирали topic в архитектуре RabbitMQ, но это два разных понятия:
- В RabbitMQ — правило маршрутизации сообщений.
- В Kafka — место хранения данных.
Топики разбиваются на партиции — упорядоченные логи, в которые последовательно добавляются события. Это не очередь, а запись того, в каком порядке произошли события.
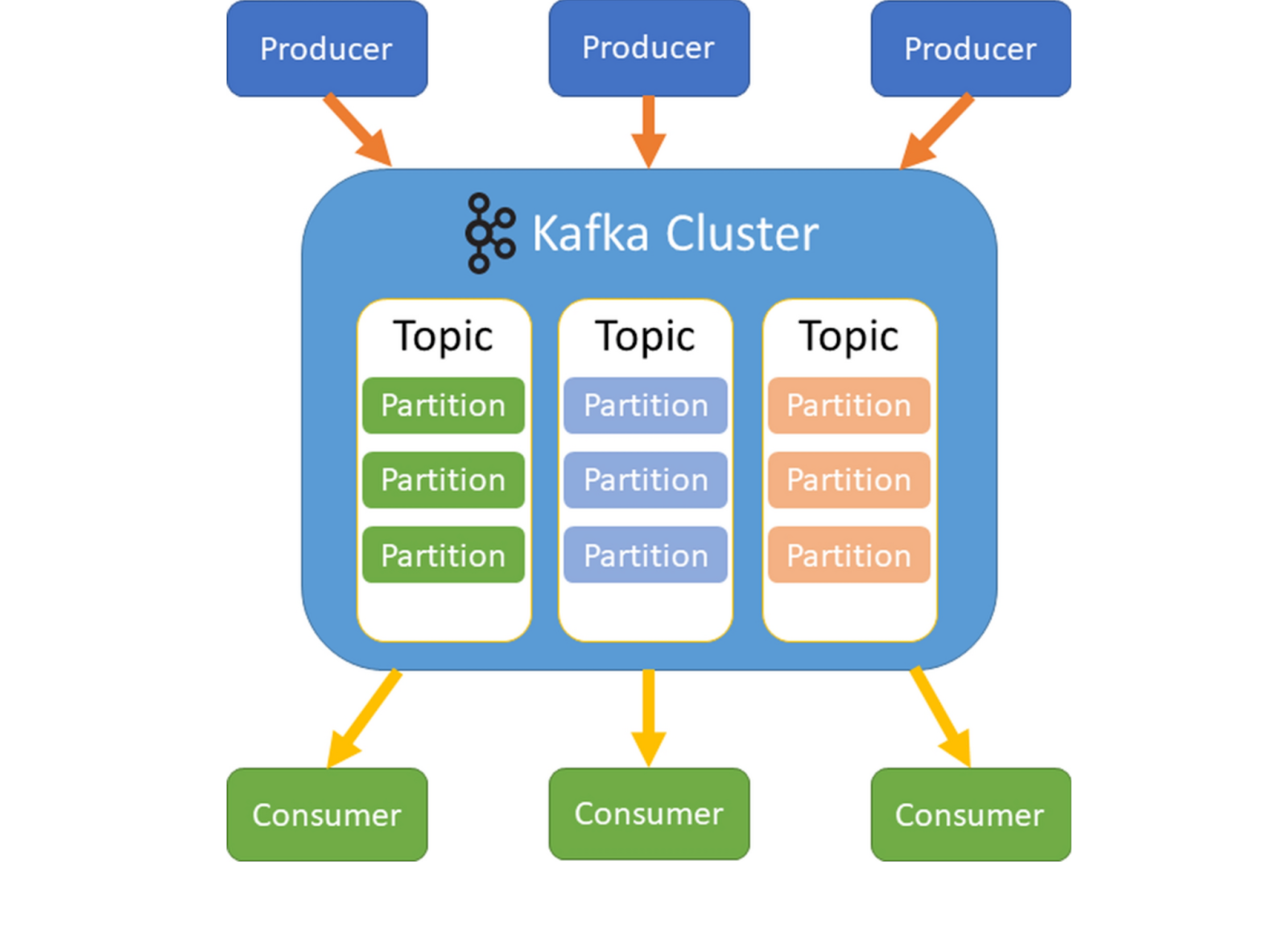
Производители записывают события в топики, а потребители сами читают их. Kafka не доставляет сообщения, как это делает RabbitMQ, — потребитель сам решает, когда и что читать. Это снижает нагрузку на Kafka и упрощает масштабирование.
Несколько сервисов могут читать один и тот же поток событий независимо друг от друга и выполнять разные задачи одновременно.
Плюсы и минусы Kafka
Главный плюс — высокая пропускная способность и масштабируемость. Kafka легко справляется с миллионами сообщений в секунду. Ещё одно преимущество — сохранение истории изменений и возможность работать с сообщениями несколько раз.
Минус в сложности — порог входа у технологии довольно высокий, а ошибки конфигурации могут быть болезненными.
Сценарии использования Kafka
Широко используется в аналитике, логировании, стриминге данных и построении событийно-ориентированных архитектур. Kafka идеально подходит для систем, где важна история изменений и возможность повторной обработки данных.
Для простых фоновых задач возможности и настройки Kafka просто избыточны, поэтому в этом случае лучше выбрать что-то попроще.
Сравнение RabbitMQ и Kafka
RabbitMQ и Kafka решают схожие задачи, но делают это разными способами. Поэтому сказать, что какая-то из этих технологий лучше, неправильно.
Дальше разберём несколько сравнений по разным критериям.
Сравнение по производительности
Если в системе тысячи сообщений в секунду — разница может быть незаметна. Если миллионы — Kafka почти всегда выигрывает.
RabbitMQ быстрее на старте для небольших нагрузок. Но хуже поддерживает горизонтальное масштабирование, если нужно настроить его на нескольких машинах.
Kafka выигрывает в сценариях с большим потоком однотипных сообщений. Ещё он оптимизирован под последовательную запись и чтение с диска. А RabbitMQ оптимизирован под доставку сообщений, а не запись.
При этом высокая производительность Kafka добавляет ему сложности.
Гарантии доставки и упорядоченности
RabbitMQ гарантирует доставку. Он поддерживает подтверждения, повторные попытки, специальные очереди для сообщений, которые не удалось обработать или доставить. Kafka хранит сообщения на диске, но он не направлен именно на доставку сообщений. Вместо этого Kafka гарантирует сохранность событий в логе, откуда любой пользователь с правом доступа может их прочесть.
В RabbitMQ проще добиться поведения, когда система защищена от повторных доставок сообщения. Даже если сообщение будет доставлено несколько раз, система поймёт, что конкретное событие уже обработано. Например, это важно в сервисах платежей, чтобы у клиентов не списывались деньги несколько раз из-за проблем в сети. В Kafka такая же работа требует аккуратной архитектуры.
Kafka гарантирует порядок сообщений внутри партиции, но не между ними. RabbitMQ гарантирует упорядоченность только в простом случае: один производитель, одна очередь, один потребитель. В более сложных случаях потребуется создание необходимой бизнес-логики приложения.
Модели доставки: push и pull
RabbitMQ использует push-модель: брокер отправляет сообщения потребителю. Это удобно, но требует контроля нагрузки, чтобы потребитель успевал всё обрабатывать.
Kafka использует pull-модель: потребитель сам забирает данные. Это даёт больше гибкости и контроля.
Что и когда используют:
- Push-модель проще и хорошо подходит в небольших системах.
- Pull-модель нужна для потоковой обработки и масштабирования.
Сравнение по простоте интеграции
RabbitMQ проще. Его легко настроить локально и быстро встроить в проект. Kafka потребует больше инфраструктуры и времени на изучение.
Для pet-проектов и небольших сервисов чаще всего лучше RabbitMQ. Kafka раскрывается в масштабе и сложных архитектурах.
Когда использовать RabbitMQ, а когда Kafka
RabbitMQ выбирают для небольших и надёжных очередей в бизнес-задачах, фоновых процессах и интеграции сервисов.
Kafka подходит для более сложной событийной системы, больших потоков данных и точного хранения истории событий.
Начинать лучше с RabbitMQ и переходить на Kafka позже — с ростом навыков или при появлении реальной необходимости.
Главное — понимать, какую проблему вы решаете.
Гибридные подходы: использование RabbitMQ и Kafka вместе
На практике RabbitMQ и Kafka часто используют вместе. Kafka — как центральный источник событий, RabbitMQ — для небольших прикладных задач. Такой подход позволяет разделить поток данных и бизнес-логику, не перегружая одну систему всем подряд.
Гибридная архитектура сложнее, но даёт максимальную гибкость и масштабируемость.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.