


Пока фронтенд и часть бэкенда переживают волну сокращений, data science в России находится в другой ситуации. Крупные компании рассматривают ML-системы как прямой источник прибыли: модели рекомендаций, детекция фрода, динамическое ценообразование — всё это приносит деньги здесь и сейчас. Поэтому найм не останавливается. А поскольку в России специалистов традиционно меньше, чем нужно рынку, конкуренция за сильных кандидатов идёт в вашу пользу.
В статье собрали путь из семи этапов с нуля до первого оффера: от математики и Python до деплоя модели в продакшн. Каждый этап — конкретные темы, критерий перехода и сколько времени реально уйдёт на обучение.
У НАС ЕСТЬ КАРЬЕРНЫЙ БОТ
Внутри бота актуальные дорожные карты по профессиям, разборы карьерных треков и истории тех, кто уже прошёл этот путь. Иногда там же лежит промокод на курсы Практикума.
Откройте бота (можно просто кликнуть) и узнайте как расти в IT, если вы джун, мидл или сеньор!
Средний оффер у людей, которые прошли полный цикл подготовки по этому ML-стеку, составляет 250 тысяч рублей. Верхняя планка для тех, кто выходит на валютную удалёнку, — 7–10 тысяч долларов в месяц.
Теперь главное: кому этот роадмап подходит, а кому — нет.
Почему именно ML-инженер, а не просто data scientist
Data science — широкая область. Внутри неё четыре основных роли: аналитик данных, инженер данных, исследователь и ML-инженер. Этот роадмап — про последнего.
ML-инженер проектирует и запускает модели в продакшн. Если аналитик помогает бизнесу принимать решения на основе данных, а инженер данных строит инфраструктуру под эти данные, то ML-инженер — тот, кто берёт всё это и делает из этого работающий сервис.
В российских реалиях ML-инженер редко делает что-то одно. Ему нужно и понимать данные как аналитик, и уметь задеплоить модель как разработчик, и объяснить бизнесу, зачем вообще это нужно. Швейцарский нож, если коротко.
Именно под этот профиль выстроены все этапы ниже — Python, SQL, Classic ML, Deep Learning, ML System Design и деплой.
Роадмап рассчитан на два типа читателей.
- Человек без IT-опыта, который хочет войти в data science с нуля. Реалистичный срок до первого оффера: 6–12 месяцев при системном подходе. Без структуры те же темы растягиваются на 12–18 месяцев, а иногда заканчиваются третьим пересмотром курса по питону без единого собеседования.
- Разработчик или аналитик, который хочет переехать в DS. Свитчер из разработки уже понимает, что такое продакшн и кодовая база. Свитчер из аналитики понимает метрики и умеет объяснять бизнесу ценность данных. Оба стартуют с форой — реальный срок сокращается примерно на треть.

Главная ошибка: учить слишком много одного
Есть типичный кейс, который повторяется регулярно: человек полгода учит Python и вроде бы знает его хорошо: декораторы, генераторы, асинхронность. На технический вопрос по Python отвечает уверенно, но гораздо хуже про SQL и ML System Design. Проблема не в том, что Python лишний, а в том, что те два-три месяца, которые ушли на его шлифовку сверх нужного уровня, можно было потратить на SQL и базовый MLSD — и уже получить оффер.
Это и есть концепция красной линии. Для найма важен не максимум знаний в одной теме, а достаточный уровень по всем одновременно.
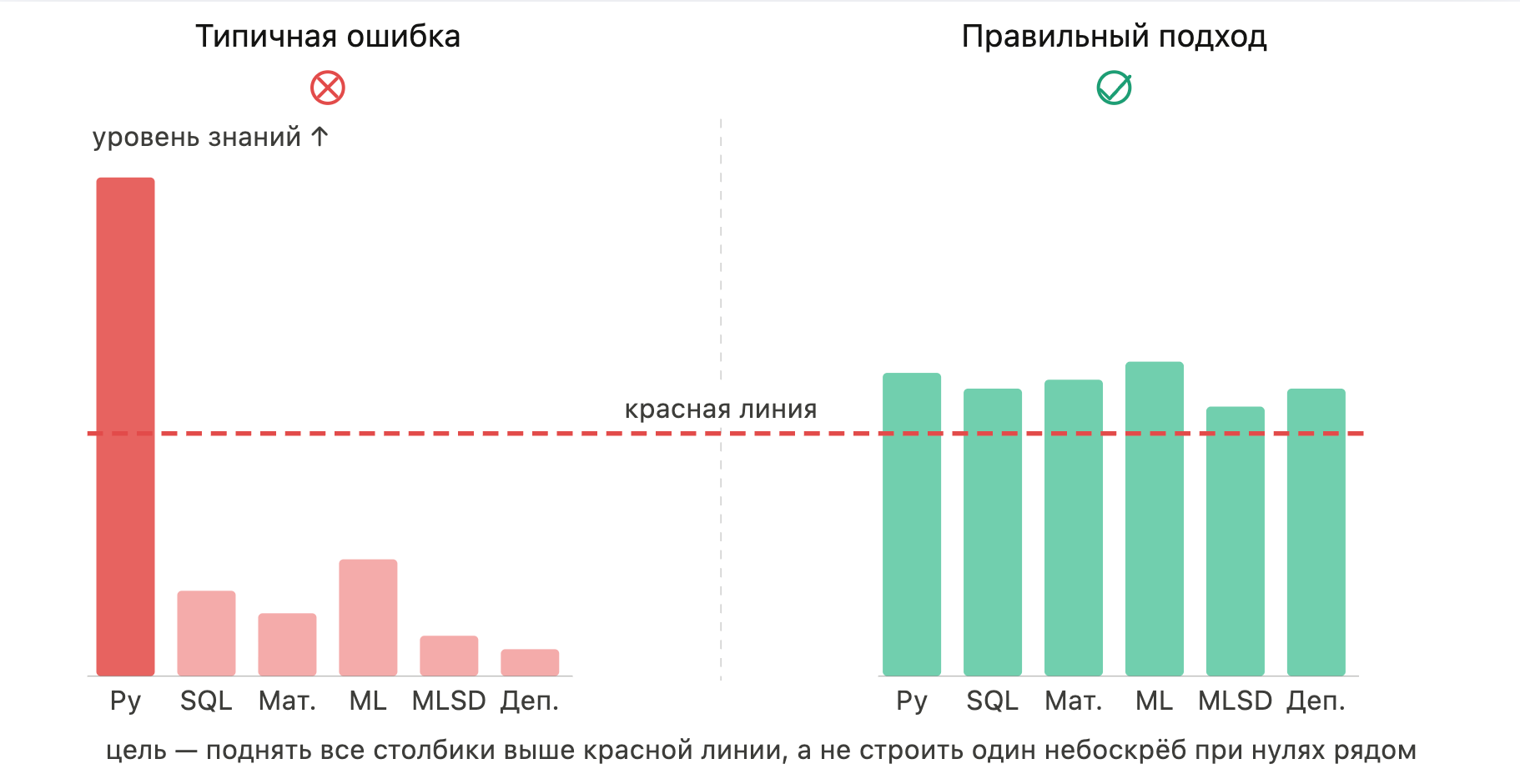
Посмотрите на график выше: по вертикали — уровень знаний, по горизонтали — дисциплины. Красная линия — это минимальный порог по каждой из них, после которого вас возьмут на работу.
Если хотите быстро проверить свои знания и постоянно тренироваться — используйте ChatGPT и аналогичные инструменты, они позволяют буквально промоделировать собеседование после каждой темы — записать транскрипт, попросить модель погонять вас по материалу и найти слабые места. Это не замена реальным собесам, но хорошая промежуточная проверка между ними.
Этап 1 — Математика: одна-две недели, не больше
Математика — главный источник страха у всех, кто смотрит на data science снаружи. Форумы, чужие LinkedIn- или тг-посты и некоторые преподаватели формируют ощущение, что без аспирантуры по математике в DS делать нечего. Это неправда.
Вот список того, что нужно понять для старта.
- Из математического анализа — что такое производная и что такое градиент. Это почти одно и то же понятие, только градиент обобщает производную на многомерный случай. Нужно понимать не формулы вывода, а смысл: производная показывает, как функция меняется при изменении аргумента. Именно на этом работает обучение любой модели.
- Из линейной алгебры — что такое вектор и матрица, какие над ними есть операции и что скалярное произведение двух векторов означает содержательно, а не просто как посчитать. Это нужно, чтобы понимать, как данные представляются внутри модели.
- Из теории вероятностей и математической статистики — какие бывают распределения и откуда они берутся, что такое статистическая значимость, что такое выборка. Поверхностно, на уровне одного параграфа каждая тема.
- Отдельно стоит потратить несколько дней на методы оптимизации — не поверхностно, а с пониманием. Градиентный спуск, как он работает, почему именно так. На собеседованиях это спрашивают не в разделе математики, а в разделе про модели: как обучается линейная регрессия, почему лосс ведёт себя так, что нужно сделать, чтобы модель сошлась. Без понимания оптимизации эти вопросы не закрыть.
- И ещё один момент, который стоит разобрать отдельно — метод максимального правдоподобия. Он кажется абстрактным, пока не столкнёшься с логистической регрессией. Там сразу станет понятно, откуда берётся log-loss и зачем всё это нужно.
Критерий перехода к этапу 2: вы понимаете, что такое градиентный спуск и зачем нужна производная при обучении модели.
Этап 2 — Python и алгоритмы: четыре-шесть недель
Python в data science нужен, чтобы решать задачи достаточно уверенно, пока голова занята моделями, а не синтаксисом. На собеседованиях питон проверяют на двух уровнях. Первый — теоретические вопросы про устройство языка. Второй — живое решение алгоритмических задач.
Что учить из теории Python
Вот темы, которые спрашивают:
- Типы данных и то, как Python хранит объекты в памяти — ссылочная модель, изменяемые и неизменяемые типы.
- Разница между списком и кортежем — не в том, что один менять можно, а другой нет, а почему это вообще сделано именно так.
- Хеш-таблицы: как устроены, почему словарь работает быстро.
Дальше — декораторы и генераторы. Их любят спрашивать на всех уровнях, и здесь важно именно понимание механики, а не умение написать по памяти. Асинхронность: GIL, мультипроцессинг, async/await. Не нужно знать все нюансы, но понимать разницу между потоками и процессами в Python и почему GIL это важно — обязательно.
Если идёте в исследовательский отдел или R&D, могут спросить про внутреннее устройство числа в Python — как оно хранится в памяти, что такое PyObject. Для большинства позиций это избыточно, но знать, что такое вопрос существует, полезно.
Алгоритмы: что спрашивают
Для большинства DS-позиций в средних и крупных компаниях алгоритмические задачи несложные.
- Нотация O(n) — обязательно, причём не абстрактно, а применительно к моделям: почему self-attention в трансформерах работает за O(n²), это спрашивают часто
- Хешмапы и базовые структуры данных.
- Two pointers и скользящее окно.
- Связные списки.
Задачи на собеседованиях обычно комбинируют две концепции: хешмапа плюс связный список, two pointers плюс скользящее окно. Задача уровня easy — одна концепция, medium — две в связке. Советуем решить около 50–100 таких задач, чтобы набрать насмотренность — видеть структуру и понимать, какой инструмент применить.
Как учить в 2026 году
Здесь есть конкретный рабочий подход, который сокращает время в разы. Берёте задачу на LeetCode уровня easy. Если не решается — открываете форум, берёте решение, копируете в ChatGPT и просите объяснить: почему именно так, какой алгоритм, что происходит в каждой строке. Если в объяснении встречается незнакомая конструкция — тут же спрашиваете про неё. Одна задача может дать два-три новых понятия, которые разбираете сразу по цепочке.
Критерий перехода к этапу 3: решаете задачи уровня medium на LeetCode без подсказок. Заодно вы уже готовы к алгоритмической секции на большинстве DS-собеседований — а это примерно 40% всего, что там спрашивают.
Этап 3 — SQL: одна-две недели
SQL недооценивают особенно те, кто идёт в data science через курсы по Python и сразу прыгает к моделям. Потом на собеседовании выясняется, что оконные функции — тёмный лес. Хорошая новость: SQL осваивается быстро. Нет ничего принципиально сложного, если заниматься последовательно.
Вот что нужно знать.
- Синтаксис и базовые запросы — само собой.
- JOIN-ы всех типов с пониманием, что происходит с данными при каждом из них. Фильтрация, подзапросы, агрегации.
- И оконные функции — это отдельная тема, которую нужно разобрать нормально, не по верхам.
Здесь есть одна важная развилка в зависимости от того, куда именно вы целитесь.
Если идёте в Classic ML — аналитика данных, рекомендательные системы, классификация, предсказание оттока — SQL нужен полностью. Данные надо уметь вытаскивать, джойнить, агрегировать, писать сложные запросы с окнами. На собеседованиях это проверяют отдельной секцией.
Если целитесь в NLP или работу с языковыми моделями — SQL можно брать в урезанном объёме. Достаточно понимать синтаксис и подзапросы, потому что данные всё равно приходится где-то доставать, но глубокая аналитика через SQL там нужна реже.
Критерий перехода к этапу 4: пишете оконные функции без гугла и понимаете, что происходит с данными в каждом типе JOIN.
Полезный блок со скидкой
Следующие этапы (с 4 по 7 — самые хардовые) вы можете пройти с проверкой на реальных задачах — курс ML-инженер от Яндекс Практикума за 12 месяцев закрывает полный цикл обучения: от обучения до деплоя через Docker, FastAPI и Yandex Cloud, с 18 проектами в портфолио на выходе.
Это способ получить структурированную обратную связь там, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Этап 4 — Classic ML: шесть-восемь недель
Здесь больше всего тем, здесь глубже всего копают на собеседованиях, и именно здесь большинство кандидатов либо проходят отбор, либо нет.
Начинается всё с фундамента — линейной регрессии — именно через неё понимаешь, как вообще устроено машинное обучение: есть функция с параметрами, параметры меняются в процессе обучения, качество измеряется через функцию потерь, минимизируется через градиентный спуск. Всё остальное — надстройка над этой идеей.
После регрессии идёт классификация. Логистическая регрессия, метрики классификации — и вот здесь важный момент, который стоит выделить отдельно.
Метрики нужно знать как инструмент принятия решений: что происходит с метриками при дисбалансе классов, чем отличается ROC-AUC от PR-AUC и в каком случае какую смотреть. На практике именно метрики показывают, насколько хорошо работает модель — и именно с них начинается любой разговор про ML System Design на собеседовании.
SVM — метод опорных векторов — разбирается здесь же. Не как основной рабочий инструмент, а как способ понять идею разделяющей гиперплоскости и margin. Это помогает думать про классификацию в целом.
Ансамбли
Следующий уровень — ансамблевые методы. Деревья решений как базовый строительный блок. Затем три типа ансамблей: бэггинг, бустинг, стекинг.
Из бэггинга — Random Forest, понять идею: много деревьев, каждое обучается на случайной подвыборке данных и случайном подмножестве признаков, итоговый ответ — голосование. Из бустинга — градиентный бустинг, и вот здесь нужно остановиться.
На собеседованиях очень любят спрашивать: что именно в градиентном бустинге является градиентом, а что — бустингом. Это не абстрактный вопрос — он проверяет, понимаете ли вы, что каждое следующее дерево обучается на остатках ошибки предыдущего, и что минимизация этой ошибки происходит через градиентный спуск в пространстве функций, а не параметров. Разобраться с этим стоит нормально, не по верхам.
Из фреймворков — CatBoost, XGBoost, LightGBM. Их нужно потыкать руками, понять основные гиперпараметры и чем они отличаются по устройству.
И отдельно — Bias-Variance Tradeoff. Что такое смещение и разброс, как они связаны со сложностью модели, что происходит при переобучении и недообучении. Если идёте именно в Classic ML, здесь копают глубоко.
Работа с данными
Параллельно с моделями идёт блок по работе с данными — EDA, разведочный анализ. Его не выучивают отдельно, он нарабатывается в процессе: смотришь на данные, строишь распределения, ищешь аномалии, проверяешь пропуски. Этот навык нужен на каждом этапе работы дата-сайентиста, поэтому практиковаться лучше с самого начала.
Сюда же входят методы снижения размерности — PCA как основной. Идея: из 150 признаков сделать 50, сохранив максимум информации. На собеседованиях спрашивают не часто, но понимать нужно.
И методы кластеризации — KMeans и DBSCAN. KMeans разбивает данные на K заданных кластеров, DBSCAN находит кластеры произвольной формы. Разница в том, что KMeans требует задать число кластеров заранее, DBSCAN — нет.
Критерий перехода к этапу 5: можете объяснить, в чём градиент в градиентном бустинге, назвать три метрики классификации с объяснением когда какую применять, и рассказать про Bias-Variance Tradeoff без конспекта.
Этап 5 — Deep Learning и выбор специализации
Здесь роадмап разветвляется. Дальнейший путь зависит от того, в какую сторону вы хотите двигаться: Classic ML или NLP и языковые модели. Это разные профили с разными требованиями на собеседованиях.
Но сначала — то, что нужно всем без исключения.
Что учат все: трансформеры и Attention
Трансформеры изменили область машинного обучения сильнее, чем что-либо за последние десять лет. Их спрашивают везде — даже на собеседованиях в Classic ML. Поэтому базовое понимание архитектуры обязательно для любого дата-сайентиста в 2026 году.
Что нужно понять. Как устроен механизм Attention — не формулу, а идею: каждый токен в последовательности смотрит на все остальные и взвешивает их по значимости. Почему self-attention работает за O(n²) по числу токенов — это про то, что каждый токен сравнивается с каждым, отсюда квадратичная сложность. Этот вопрос на собеседованиях встречается регулярно.
Для Classic ML этого достаточно. Дальше идёт ML System Design, и об этом — в следующем разделе.
NLP и LLM-трек: что учат дополнительно
Если выбираете направление языковых моделей, агентов и NLP — список расширяется, и здесь нужно погружаться глубже.
- Сверточные сети и их роль в обработке последовательностей. Как устроены трансформеры с пониманием каждого блока: embeddings, positional encoding, multi-head attention, feed-forward слои.
- Дообучение готовых моделей под бизнес-задачи — Supervised Fine-Tuning, SFT. Это про то, как взять открытую модель и адаптировать её под конкретную задачу с минимальным набором размеченных данных.
- RAG — Retrieval-Augmented Generation. Идея: вместо того чтобы хранить все знания в параметрах модели, при каждом запросе достаём релевантные документы из внешней базы и подаём их в контекст. Это сейчас один из основных паттернов в продакшн-системах на основе LLM.
- Векторные базы данных — как они устроены, зачем нужны, чем отличаются от обычных. Это инфраструктура под RAG и семантический поиск.
- Агенты — что такое агентная архитектура, какие паттерны существуют, как несколько агентов взаимодействуют между собой. MCP и Tool Calling — как модель вызывает внешние инструменты и почему это важно для продакшн-систем.
- Из фреймворков — LangChain и LangGraph. На них сейчас пишется большинство агентных систем в реальных проектах.
Критерий перехода для Classic ML-трека к этапу 6: можете объяснить, как работает Attention и почему self-attention квадратичный. Для NLP-трека: можете описать архитектуру RAG-системы от запроса до ответа и объяснить, зачем нужна векторная база данных.

Этап 6 — ML System Design: учить параллельно с этапом 4
MLSD — самое недооценённое и при этом самое весомое на собеседованиях в 2026 году. Его стали спрашивать везде: и в крупных компаниях, и в стартапах, и на позиции джуна, хотя глубина ожиданий там ниже. За последние несколько лет требования к дата-сайентистам изменились. Раньше от джуна ждали умения обучить модель на данных и показать метрику. Сейчас ждут понимания, зачем вообще эта модель нужна бизнесу, как её результат измерить в деньгах или бизнес-показателях, и как это всё задеплоить и проверить в продакшне.
Структура ответа всегда одна и та же, и её нужно знать до автоматизма.
- Бизнес-постановка. Что хочет бизнес, какие ограничения, что можно и что нельзя делать в рамках задачи: без этого непонятно, что вообще оптимизировать.
- Метрики. Здесь три уровня. Бизнес-метрики — выручка, конверсия, отток. Онлайн-метрики — то, что можно измерить в продакшне на живых пользователях в реальном времени. Офлайн-метрики — то, что считается на тестовой выборке до деплоя. Важный нюанс: хорошая офлайн-метрика не всегда совпадает с онлайн, и понимание этого разрыва — один из любимых вопросов интервьюеров.
- Данные. Какие данные есть, каких не хватает, как их собирать.
- Baseline. Самое простое решение, которое можно сделать быстро и запустить в продакшн за день, которое хоть как-то работает и задаёт точку отсчёта.
- Архитектура и итеративное улучшение. Как двигаться от baseline к нормальному решению шаг за шагом.
- Деплой и AB-тест. Как проверить, что новая модель действительно лучше старой на живых пользователях, а не только на тестовой выборке.
Критерий перехода к этапу 7: прошли хотя бы один mock MLSD-интервью и получили внятный фидбек. Можно через ChatGPT, можно через знакомого сеньора, можно через сообщества в Telegram. Главное — не теория в вакууме, а разбор реального кейса.
Этап 7 — Деплой: базовый уровень, но пропускать нельзя
Деплой — это то, что отделяет модель в ноутбуке от модели, которая реально работает и приносит деньги. Пять лет назад джуна это почти не спрашивали. Сейчас спрашивают, и тенденция идёт в сторону углубления требований, особенно в NLP-направлении.
Для старта не нужно знать DevOps на уровне инженера инфраструктуры. Нужно понимать, как это устроено в целом, и уметь задеплоить хотя бы один pet-проект самостоятельно.
Что учить
- Docker — первый и главный инструмент. Понять, что такое контейнер, чем он отличается от виртуальной машины, как написать Dockerfile, как собрать образ и запустить его. Это не сложно и осваивается за несколько дней практики.
- FastAPI — фреймворк для создания REST API на Python. В DS он используется как обёртка вокруг модели: принимает запрос, прогоняет через модель, возвращает предсказание. Понять базовый роутинг, как принимать данные на вход и что возвращать — этого достаточно.
- CI/CD — на уровне понимания идеи. Что такое пайплайн, как изменения в коде автоматически проходят тесты и деплоятся. Не нужно уметь настраивать GitHub Actions с нуля, но понимать, что происходит между коммитом и продакшном — обязательно.
- Kafka и Hadoop — на уровне базовой осведомлённости. Что это такое, зачем нужны, в каких задачах применяются. На собеседованиях для джунов в это редко уходят глубоко, но если встретится вопрос — не должно быть полного ступора.
Как учить
Здесь работает тот же подход, что с алгоритмами: берёте реальную задачу, задеплоиваете модель из предыдущих этапов в Docker-контейнер, оборачиваете FastAPI. Всё, что непонятно по ходу — разбираете через ChatGPT построчно. Один задеплоенный проект даёт больше понимания, чем три прочитанных туториала.
Критерий перехода к офферу: есть хотя бы один проект, который запускается в Docker и принимает запросы через API. Не идеальный, не production-ready — просто работающий.
Три сценария: как движется обучение в зависимости от старта
Роадмап один, но скорость и болевые точки у всех разные. Вот три реальных сценария.
Сценарий 1 — Новичок без IT-опыта
Это самый долгий путь, и здесь важно не питать иллюзий. Реалистичный срок при системном подходе — 6–12 месяцев. Без структуры и внешней проверки знаний те же темы растягиваются на 12–18 месяцев, а нередко заканчиваются тем, что человек застревает на имитации: обучает модель на Титанике, считает это портфолио и не понимает, почему не зовут на собеседования.
Типичная траектория без системы выглядит так. Первые недели — эйфория: Python идёт легко, всё понятно, кажется что через три месяца уже оффер. Потом наступает яма: задачи становятся сложнее, прогресс замедляется, мотивация падает. Примерно половина уходит именно здесь. Те, кто остаётся, часто попадают в ловушку имитации — делают учебные проекты, не ходят на собеседования, ждут момента когда будут готовы. Этот момент не наступает сам по себе.
Вам может помочь внешняя структура в виде ментора или группы, регулярные mock-собеседования начиная с середины пути, и главное — первый реальный собес как можно раньше. Фидбек от реального интервьюера стоит больше месяца самостоятельного обучения.
Сценарий 2 — Свитчер из разработки или аналитики
У свитчера из разработки уже есть понимание продакшна, умение читать чужой код и базовые алгоритмы. Python скорее всего знаком хотя бы поверхностно. Это сокращает первые два этапа роадмапа в разы.
Свитчер из аналитики приходит с другой форой: понимание метрик, умение разговаривать с бизнесом на его языке, опыт работы с данными. ML System Design для него будет даваться проще, чем для новичка, потому что он уже думает категориями бизнес-задач, а не просто моделей.
В обоих случаях путь примерно тот же, что у новичка, но быстрее на треть. Основные темы для доучивания — Classic ML, Deep Learning и MLSD. Деплой для бывшего разработчика скорее всего уже знаком. Матан для аналитика часто не проблема.
Есть один нюанс, который стоит отметить. Бывший тимлид в разработке, который переходит в DS джуном, поначалу может ощущать дискомфорт от смены уровня. Но техническая база и опыт работы в команде дают очень быстрый рост — быстрее, чем у классического новичка без опыта вообще.
Сценарий 3 — NLP и LLM-трек
Если цель — работать с языковыми моделями и агентами, базовый роадмап проходится полностью, плюс добавляется блок из этапа 5: трансформеры глубоко, fine-tuning, RAG, агенты, LangChain. Это плюс два-три месяца к общему сроку.
Зато этот трек сейчас один из самых востребованных. Компании активно ищут людей, которые умеют не просто вызвать API языковой модели, а выстроить вокруг неё нормальную систему: с retrieval, инструментами, оценкой качества и деплоем.
Матрица выбора по сценарию:
| Кто вы | Срок до оффера | Где будет сложнее всего |
| Новичок без IT | 6–12 месяцев | Алгоритмы, не потерять темп в яме |
| Свитчер из разработки | 4–8 месяцев | Classic ML и MLSD |
| Свитчер из аналитики | 4–8 месяцев | Алгоритмы и деплой |
| Новичок, NLP-трек | 9–14 месяцев | Deep Learning, RAG-архитектуры |
Итого: что получите на выходе
Пройдя все этапы этого роадмапа, вы получаете конкретный стек, с которым реально выходить на рынок.
Python на уровне уверенного использования, понимание алгоритмов для прохождения технических секций. SQL для работы с данными. Classic ML с пониманием того, что и когда применять, и как объяснить выбор модели. Базовое понимание Deep Learning и трансформеров. MLSD как навык структурированного ответа на любой бизнес-кейс. Деплой на уровне Docker и FastAPI.
Data science в России сейчас в редкой ситуации: спрос растёт, специалистов не хватает, и направление защищено от волны IT-сокращений, потому что бизнес видит в нём прямую прибыль, а не просто расходы на инфраструктуру. Это не навсегда — рынок насытится, требования вырастут. Но сейчас окно открыто.
Последний практический совет: не ждите момента, когда будете готовы. Начинайте ходить на собеседования после SQL и базового Python. Получайте фидбек, доучивайте конкретные пробелы, повторяйте.
Советуем дополнительно почитать по теме:
- Кто такой Data Scientist: что он делает и сколько зарабатывает — разбираем все четыре DS-роли изнутри: чем ML-инженер отличается от аналитика, исследователя и дата-инженера, и где у каждого потолок по зарплате.
- Data Engineer: кто это, чем занимается и как стать — если после роадмапа поймёте, что хочется строить инфраструктуру под данные, а не модели — вот смежная профессия с таким же спросом на рынке.
- 12 библиотек Python, которые стоит попробовать в 2026 году — актуальный обзор инструментов для агентного стека: Smolagents, Pydantic-AI, FastMCP — всё то, что упоминается в NLP-треке этого роадмапа.
- Основные модели машинного обучения: виды и применение — теоретическая база к этапу Classic ML: какие модели вообще бывают, как выбирать под задачу и что от вас ждут на собеседовании.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.











