Стандарт HTML5 принят в 2014 году, и тогда же в HTML добавилось много новых тегов, про которые многие не знают до сих пор. Мы решили исправить это и рассказать о семи полезных HTML-тегах, которые можно использовать почти в любом проекте. Многие из них решают SEO-задачи, но есть и те, которые меняют внешний вид страницы.
<header> и <footer>
Видимый эффект: нет.
Задача этих тегов — разметить на странице блоки с шапкой и подвалом сайта (то есть верхней и нижней частью). Они не влияют на внешний вид сайта, но помогают поисковым системам разобраться в структуре страницы. Например, поисковик может взять из подвала время работы компании для карточки быстрого ответа или найти в шапке общую информацию о сервисе:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Новые теги</title>
<style>
body {
font-family: arial;
font-size: 18px;
line-height: 1.3;
}
</style>
</head>
<body>
<header>
<h1>
Журнал «Код»
</h1>
<p>
«Код» — журнал «Яндекс Практикума» о технологиях и программировании.
</p>
<p>
Мы помогаем преодолеть барьер на входе в информационные технологии
</p>
<hr>
</header>
<!-- тут — основное содержимое страницы -->
<footer>
<h3>
Кто пишет «Код»
</h3>
<p>
Статьи — Миша Полянин
<br>
Редактор новостей — Инна Долога
<br>
Корректор — Ира Михеева
<br>
Главред — Максим Ильяхов
</p>
</footer>
</body>
</html>
<article>
Видимый эффект: нет.
Второй тег для помощи поисковикам. Его задача — сообщить роботу, что здесь начинается основное содержимое, ради которого пользователь и пришёл на сайт. Например, мы написали статью про анализ слов и хотим логически отделить её от остального текста на странице. Для этого мы оборачиваем всю статью в тег <article> — так поисковик будет знать, что основное лежит здесь.
Если на странице несколько материалов, например новостей или коротких подборок, то можно обернуть каждую таким тегом — в стандарте нет ограничений на количество таких разделов.
Для наглядности добавим тег с началом статьи к предыдущему коду:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Новые теги</title>
<style>
body {
font-family: arial;
font-size: 18px;
line-height: 1.3;
}
</style>
</head>
<body>
<header>
<h1>
Журнал «Код»
</h1>
<p>
«Код» — журнал «Яндекс Практикума» о технологиях и программировании.
</p>
<p>
Мы помогаем преодолеть барьер на входе в информационные технологии
</p>
<hr>
</header>
<article>
<p>
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь подойдём к этому серьёзно и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое облако самых частых слов — это из первого тома «Войны и мира».
</p>
<p> <strong> Что делаем </strong> </p>
<p>
Сегодня мы проанализируем текст всех томов «Войны и мира» и посмотрим, изменятся ли самые частые слова, как это будет выглядеть в облаке. Интересно, можно ли по таким облакам хотя бы примерно понять общее настроение или содержание текста.
</p>
</article>
<footer>
<h3>
Кто пишет «Код»
</h3>
<p>
Статьи — Миша Полянин
<br>
Редактор новостей — Инна Долога
<br>
Корректор — Ира Михеева
<br>
Главред — Максим Ильяхов
</p>
</footer>
</body>
</html>





<aside>
Видимый эффект: нужно настроить через стили.
Иногда бывает полезно к основному материалу добавить что-то на поля: мысль, комментарий или примечание. Для этого в HTML5 используется тег <aside> — он размещает на странице дополнительный контент, который не относится к основному материалу.
Чтобы визуально это выглядело опрятно, к этому тегу и тегу статьи добавляют стили — они помогают сопоставить абзац основного текста и комментарий к нему:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Новые теги</title>
<style>
body {
font-family: arial;
font-size: 18px;
line-height: 1.3;
}
aside {
/* фон */
background: yellow;
/* поля */
padding: 10px;
/* ширина */
width: 200px;
/* основной текст будет слева */
float: right;
/* фон */
font-size: 13px;
}
.main {
/* отступ справа */
margin-right: 240px;
/* указываем, что это блок */
display: block;
}
</style>
</head>
<body>
<aside>
<p>Как мы делали раньше</p>
</aside>
<div class="main">
<p>
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь подойдём к этому серьёзно и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое облако самых частых слов — это из первого тома «Войны и мира».
</p>
</div>
<p> <strong> Что делаем </strong> </p>
<aside>
<p>Что сделаем сегодня и зачем</p>
</aside>
<div class="main">
<p>
Сегодня мы проанализируем текст всех томов «Войны и мира» и посмотрим, изменятся ли самые частые слова, как это будет выглядеть в облаке. Интересно, можно ли по таким облакам хотя бы примерно понять общее настроение или содержание текста.
</p>
<hr>
</div>
</body>
</html>
<section>
Видимый эффект: нет.
Ещё один способ логически объединить данные на странице в один блок. Это бывает полезно при вёрстке, чтобы было видно, где заканчивается один раздел и начинается другой. Внешне никак не проявляется, но верстать становится проще.
<section id = "part1">
<aside>
<p>Как мы делали раньше</p>
</aside>
<div class="main">
<p>
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь подойдём к этому серьёзно и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое облако самых частых слов — это из первого тома «Войны и мира».
</p>
</div>
</section>
<section id = "part2">
<p> <strong> Что делаем </strong> </p>
<aside>
<p>Что сделаем сегодня и зачем</p>
</aside>
<div class="main">
<p>
Сегодня мы проанализируем текст всех томов «Войны и мира» и посмотрим, изменятся ли самые частые слова, как это будет выглядеть в облаке. Интересно, можно ли по таким облакам хотя бы примерно понять общее настроение или содержание текста.
</p>
<hr>
</div>
</section><mark>
Видимый эффект: слова выделятся просто так и особенно на поиске. С помощью этого тега можно выделить на странице ключевые слова или результаты поиска. Раньше для этого использовали <span> со стилями, теперь сделали отдельный тег. По умолчанию всё выделяется жёлтым, как будто мы выделяем слова маркером на бумаге — отсюда и название тега:
<p>
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь <mark>подойдём к этому серьёзно</mark> и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое <mark>облако самых частых слов</mark> — это из первого тома «Войны и мира».
</p>
<details>
Видимый эффект: появится интерактивный элемент — раскрывашка.
Это такой аналог ката, когда информация прячется за клик — например, чтобы не спойлерить или не засорять страницу лишними деталями, которые нужны только экспертам.
<details>
<summary>Внимание, спойлер!</summary>
<p>Минус такого решения в том, что поиск работает только с одинаковыми словами. Например, «исследователь», «исследовательский» и «исследование» — это три разных слова, за которыми стоит один смысл. Но они у нас будут на разных строках, и мы не сможем их сразу учесть все вместе.</p>
</details>
<meter>
Видимый эффект: графический индикатор.
Когда нам нужно вывести на странице значения счётчиков или показать текущие параметры какого-то прибора, можно не делать кастомный индикатор, а использовать уже готовый — <meter>. Его плюс в том, что он сам следит за тем, насколько текущие значения укладываются в допустимые границы, и подсвечивает всё разными цветами. Например, если прибор работает штатно и показатели в норме, то он будет зелёным, а если выходят за границы диапазонов — то жёлтым.
Допустим, у нас есть датчик, который показывает давление воды в трубах. Минимально допустимое давление — 2 атмосферы, максимальное — 5. Вот как это может выглядеть на странице:
<p>Индикатор давления</p>
<p>Низкое <meter value="1" max="10" low="2" high="5"></meter> </p>
<p>Нормальное <meter value="3" max="10" low="2" high="5"></meter> </p>
<p>Высокое <meter value="7" max="10" low="2" high="5"></meter> </p>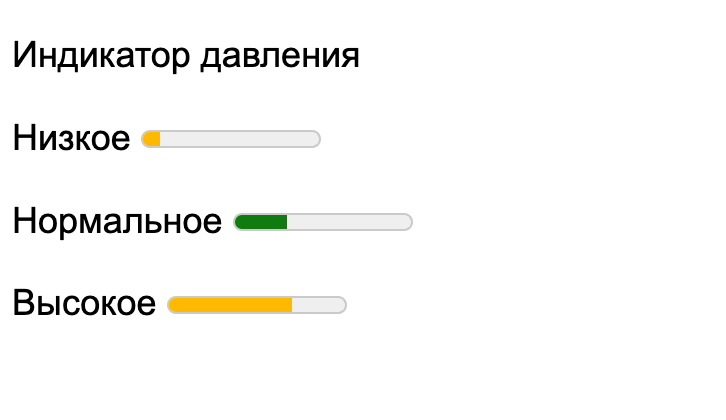
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Новые теги</title>
<style>
body {
font-family: arial;
font-size: 18px;
line-height: 1.3;
}
aside {
/* фон */
background: yellow;
/* поля */
padding: 10px;
/* ширина */
width: 200px;
/* основной текст будет слева */
float: right;
/* фон */
font-size: 13px;
}
.main {
/* отступ справа */
margin-right: 240px;
/* указываем, что это блок */
display: block;
}
</style>
</head>
<body>
<header>
<h1>
Журнал «Код»
</h1>
<p>
«Код» — журнал «Яндекс Практикума» о технологиях и программировании.
</p>
<p>
Мы помогаем преодолеть барьер на входе в информационные технологии
</p>
<hr>
</header>
<section id = "part1">
<aside>
<p>Как мы делали раньше</p>
</aside>
<div class="main">
<p>
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь подойдём к этому серьёзно и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое облако самых частых слов — это из первого тома «Войны и мира».
</p>
</div>
</section>
<section id = "part2">
<p> <strong> Что делаем </strong> </p>
<aside>
<p>Что сделаем сегодня и зачем</p>
</aside>
<div class="main">
<p>
Сегодня мы проанализируем текст всех томов «Войны и мира» и посмотрим, изменятся ли самые частые слова, как это будет выглядеть в облаке. Интересно, можно ли по таким облакам хотя бы примерно понять общее настроение или содержание текста.
</p>
<hr>
</div>
</section>
<p>
Мы уже анализировали самые частые слова в тексте, но делали это быстро, на коленке и с помощью Экселя. Теперь <mark>подойдём к этому серьёзно</mark> и используем дата-сайенс и Python — с ним такой анализ будет проще, быстрее и эффективнее. Заодно научимся делать такое красивое <mark>облако самых частых слов</mark> — это из первого тома «Войны и мира».
</p>
<details>
<summary>Внимание, спойлер!</summary>
<p>Минус такого решения в том, что поиск работает только с одинаковыми словами. Например, «исследователь», «исследовательский» и «исследование» — это три разных слова, за которыми стоит один смысл. Но они у нас будут на разных строках, и мы не сможем их сразу учесть все вместе.</p>
</details>
<p>Индикатор давления</p>
<p>Низкое <meter value="1" max="10" low="2" high="5"></meter> </p>
<p>Нормальное <meter value="3" max="10" low="2" high="5"></meter> </p>
<p>Высокое <meter value="7" max="10" low="2" high="5"></meter> </p>
<footer>
<h3>
Кто пишет «Код»
</h3>
<p>
Статьи — Миша Полянин
<br>
Редактор новостей — Инна Долога
<br>
Корректор — Ира Михеева
<br>
Главред — Максим Ильяхов
</p>
</footer>
</body>
</html>