Ещё пару лет назад синтез речи годился разве что для смешных донатов на стримах — слушать это всерьез было невозможно из-за механических неестественных интонаций. Сегодня же нейросети научились не просто читать текст, а отыгрывать интонации, делать паузы и даже копировать конкретные голоса. И теперь для озвучки видеоинструкции, пет-проекта или контента не нужно арендовать студию и мучить микрофон.
Мы протестировали актуальные сервисы 2025 года и отобрали те, которые выдают чистый звук, понимают контекст и адекватно работают с русским языком.
Как работает нейросетевая озвучка текста?
В основе любой современной «говорилки» лежит технология TTS (Text-to-Speech). Глобально это пайплайн, который принимает на вход строку символов — текст, а на выходе отдаёт WAV-файл — аудио. Раньше это была жёсткая алгоритмическая задача, а сейчас — чистое поле для Deep Learning.
Технология преобразования текста в речь (TTS)
Современный процесс генерации речи обычно состоит из шести ключевых этапов:
1. Анализ и препроцессинг. Сначала система чистит входные данные. Она должна понять контекст: расшифровать «г. Москва» как «город Москва», перевести число «2025» в слова «две тысячи двадцать пять» и определить, где заканчивается предложение.
2. Фонетическая конвертация. Текст превращается в транскрипцию. Нейросеть разбивает слова на фонемы — мельчайшие единицы звучания. Здесь решается, как прочитать слово «замóк» или «зáмок» в зависимости от соседних слов.
3. Генерация просодии. Самый важный этап для создания «человечности». ИИ рассчитывает ритм, расставляет ударения, определяет длительность пауз и интонационный контур (вверх или вниз), чтобы речь не звучала монотонно.
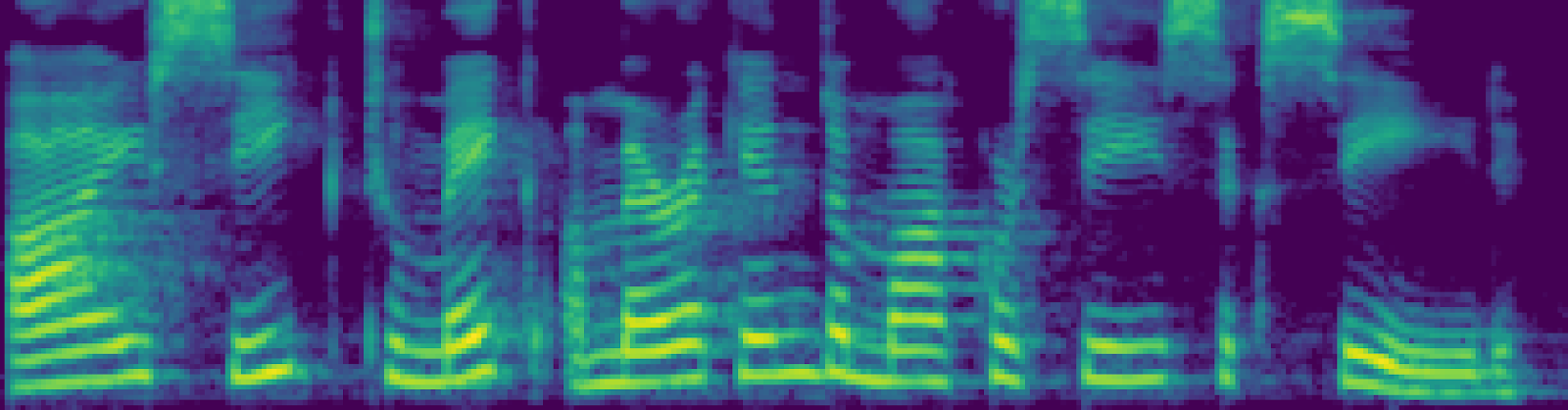
4. Синтез речи. На основе фонем и просодии акустическая модель (например, Tacotron) строит мел-спектрограмму. Это пока ещё не звук, а его визуальный «чертёж» — график частот во времени:
5. Генерация аудио. Вокодер — устройство синтеза речи — берёт этот чертёж и превращает его в реальную звуковую волну. Именно здесь убирается «металлическая» интонация робота.
6. Постобработка. Финальный штрих: нормализация громкости, удаление артефактов дыхания или щелчков, чтобы на выходе получился чистый WAV-файл.
И всё это происходит за те секунды, пока вы ждёте результат.
Чем ИИ-озвучка отличается от традиционных методов
Раньше (в эпоху Windows XP и ранних навигаторов) использовался конкатенативный синтез. Принцип был простым: живого диктора записывали часами, нарезали его речь на крошечные фрагменты (дифоны и трифоны), сохраняли в базу, а алгоритм просто склеивал эти куски в нужном порядке.
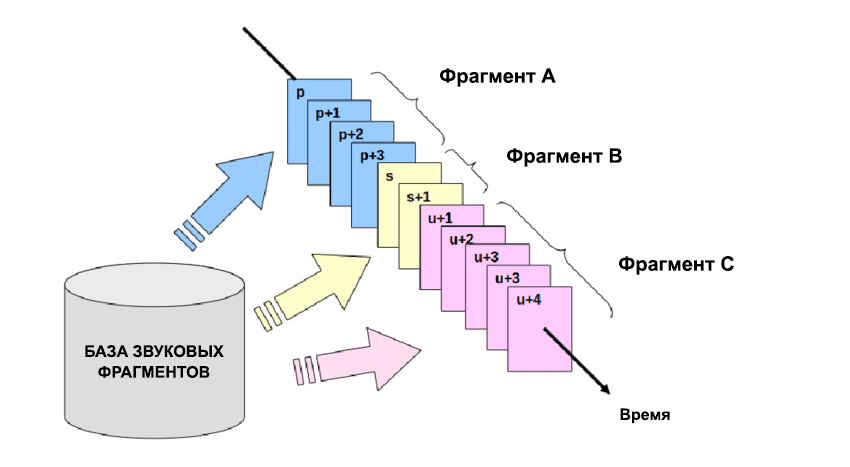
Минусы старого подхода в том, что речь звучала рваной, интонация всегда была одинаковой, «роботизированной», изменить голос или эмоцию было невозможно без новой многочасовой записи диктора.
Нейросетевой (параметрический) синтез работает иначе. ИИ не хранит в памяти кусочки звука. Он хранит закономерности человеческой речи. Нейросеть обучалась на тысячах часов аудио и теперь генерирует звук с нуля, семпл за семплом.
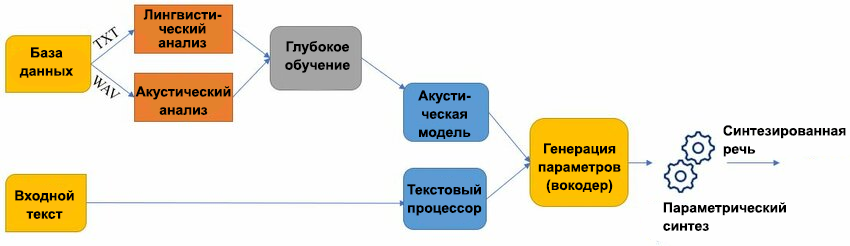
Такой подход даёт свои плюсы: плавность переходов, умение соблюдать контекст — вопросительная интонация в конце вопроса появится автоматически, возможность клонировать любой голос по короткому семплу и менять эмоции на лету.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Топ-5 нейросетей для озвучки текста
С теорией разобрались, теперь перейдём к практике и рассмотрим пять самых популярных нейросетей.
ElevenLabs: лидер в реалистичной озвучке
Если вы ищете качество, при котором слушатель в слепом тесте не отличит робота от живого актёра, — вам сюда. На 2025 год ElevenLabs задаёт планку для всей индустрии: именно их движки используют для дубляжа кино и озвучки AAA-игр.
- Для кого: видеоблогеры, разработчики игр, те, кому нужно клонировать свой (или чужой) голос.
- Киллер-фича: Voice Cloning. Вы загружаете 1 минуту своего голоса, и нейросеть начинает говорить вашим тембром на любом языке. Причём сохраняются даже микровздохи и интонационные привычки.
- Русский язык: работает отлично, без «акцента робота», понимает контекст (вопрос, сарказм, агрессия).
- Цена: есть бесплатный тариф (10 000 символов в месяц ≈10 минут аудио), но лицензия требует указывать авторство. Платные тарифы начинаются от 5 $/мес.
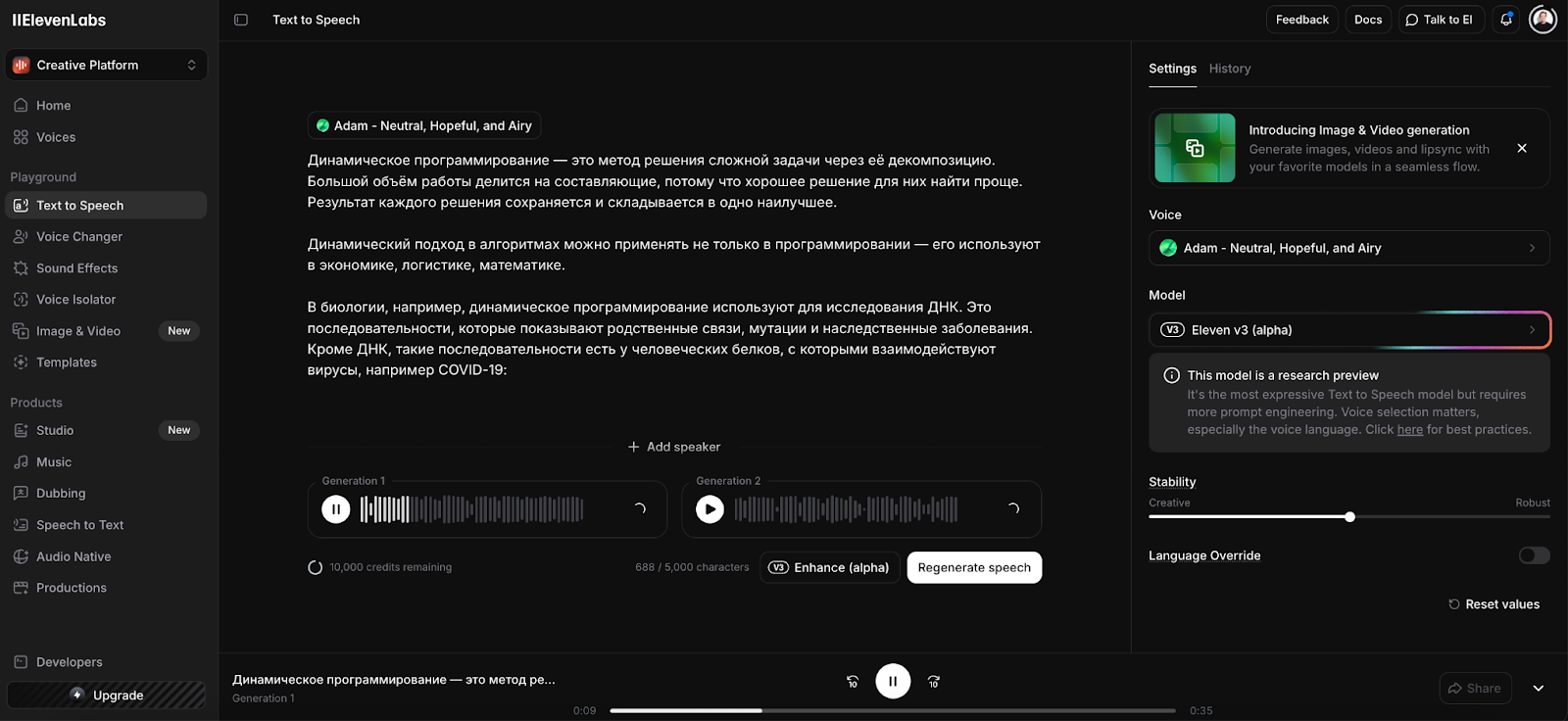
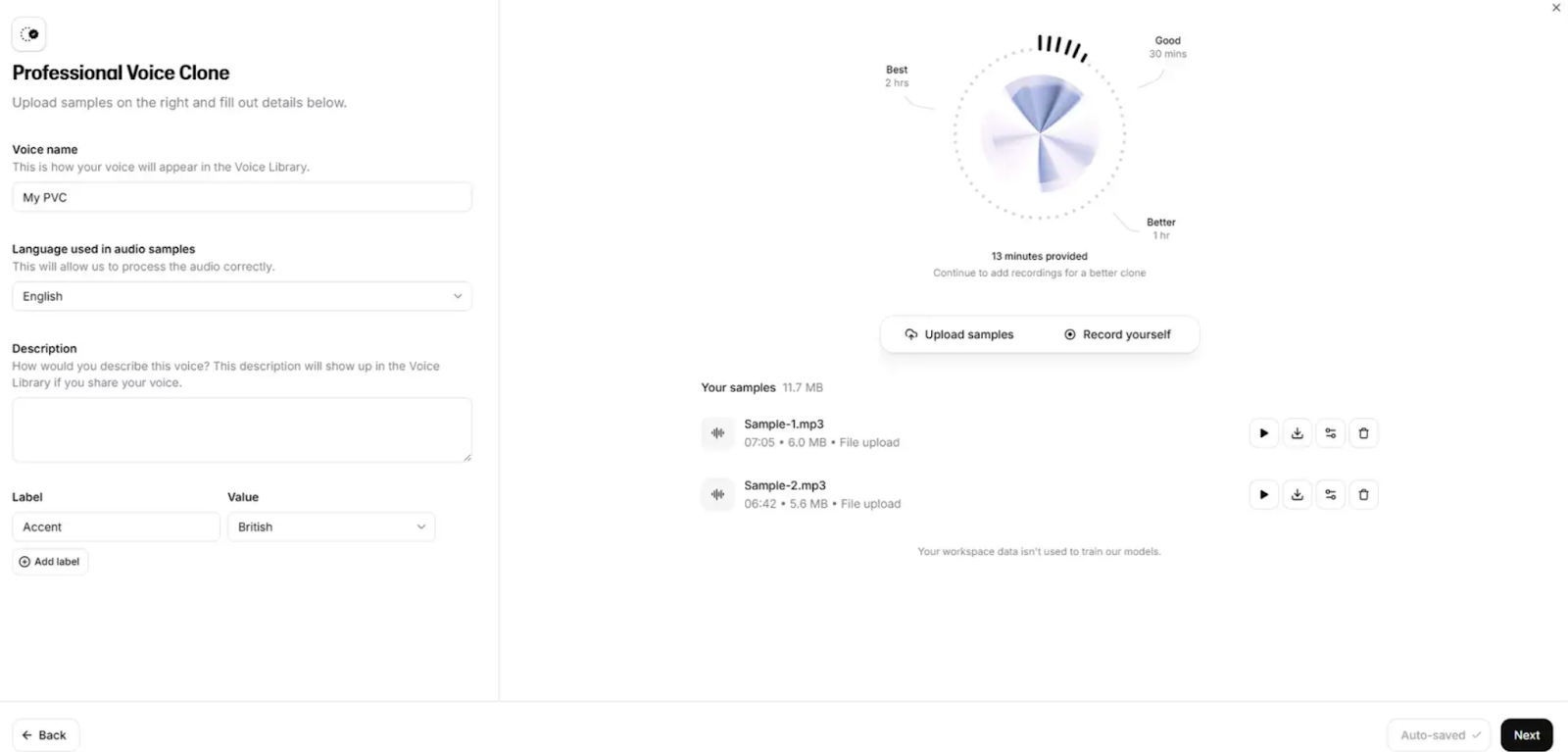
Murf.ai: профессиональное решение для контентмейкеров
Это не просто «читалка», а полноценная студия. Murf позиционирует себя как «Canva для звука».
- Для кого: для создателей презентаций, специалистов, занимающихся обучением сотрудников, рекламщиков.
- Фишки: вы можете загрузить видеоряд или слайды прямо в редактор и таймить озвучку под конкретные кадры. Есть библиотека музыки и видеостоков.
- Русский язык: есть, качество хорошее, но интонации чуть более «дикторские» и официальные, чем у ElevenLabs. Иногда проскальзывают роботизированные артефакты.
- Цена: бесплатная версия — чисто «попробовать» (скачать файл нельзя). Рабочие тарифы — от 19 $/мес.
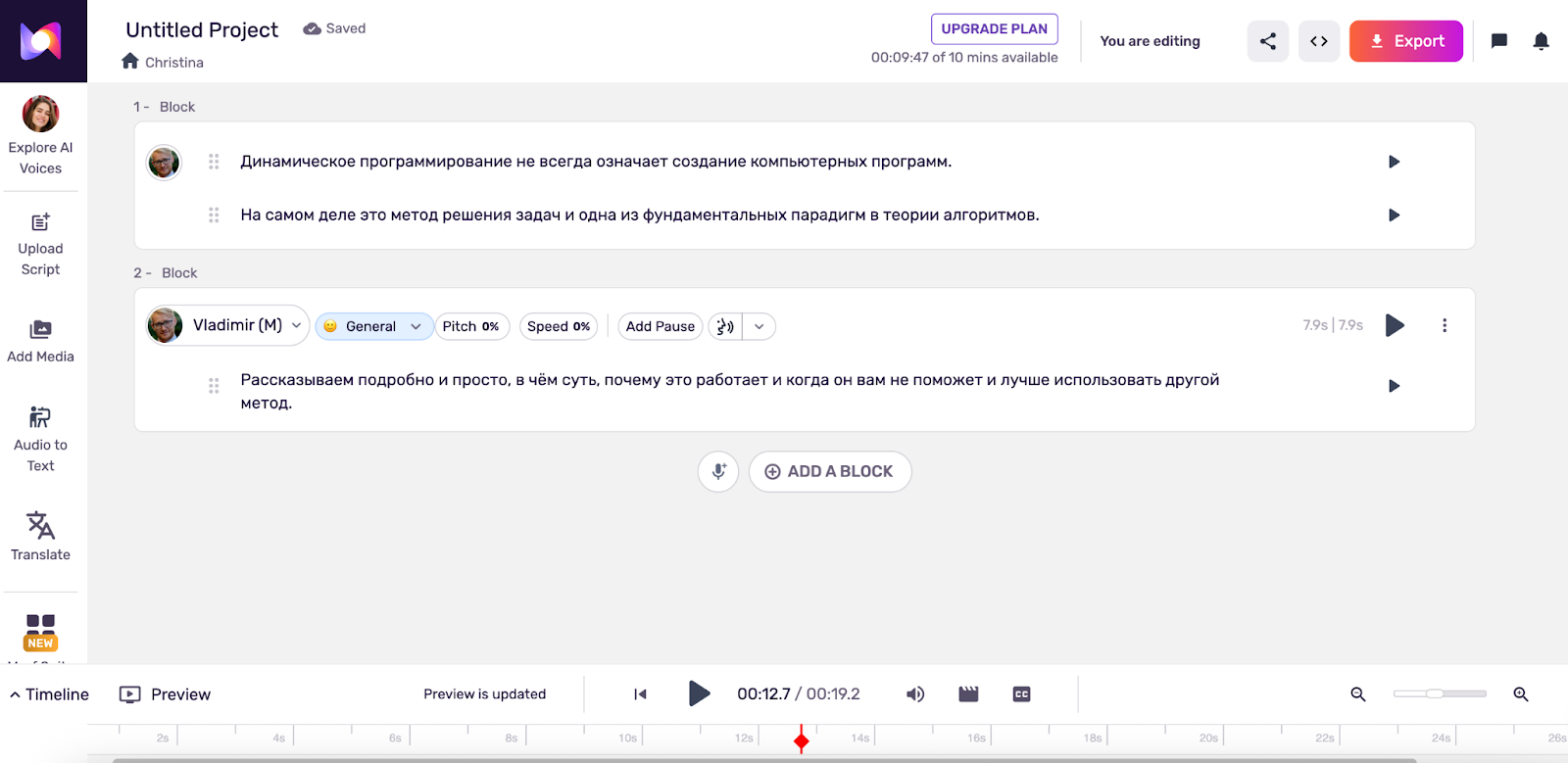
Lovo.ai: поддержка более чем ста языков и голосов
Мощный комбайн, который вырос в полноценный видеоредактор под названием Genny.
- Для кого: для тех, кому нужно много разнообразных голосов и эмоций (более 30 вариантов эмоциональной окраски — от «пьяного» до «рыдающего»).
- Фишки: огромный выбор персонажей. Можно озвучить диалог, где один голос будет скрипучим стариком, а второй — весёлой девочкой. Также есть встроенный AI-генератор картинок и скриптов.
- Русский язык: поддерживается, база голосов обширная.
- Цена: триал на 14 дней, дальше — от 24 $/мес. Бесплатный тариф сильно урезан.
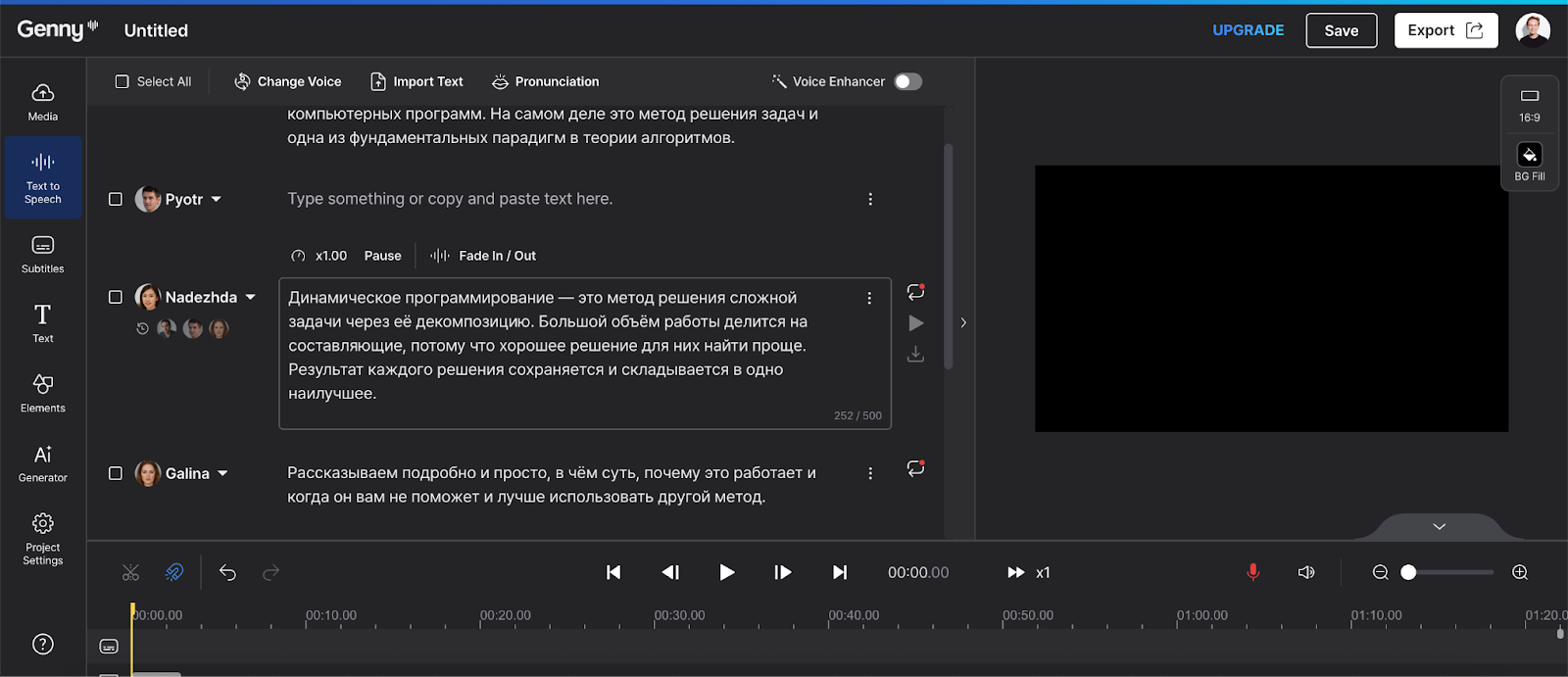
Google Text-to-Speech: облачное решение
Тяжёлая артиллерия от Google Cloud. Здесь будет не красивый сайт с кнопками, а мощный API для разработчиков, но его качество (особенно модели WaveNet и Neural2) — топовое.
- Для кого: для разработчиков приложений, автоответчиков (IVR), тех, кто умеет пользоваться консолью или сторонними оболочками.
- Фишки: максимальная стабильность и поддержка SSML (язык разметки синтеза речи). Вы можете кодом указать: «сделай паузу 2 секунды, а это слово скажи шёпотом».
- Цена: самый щедрый Free Tier. Google даёт бесплатно озвучивать до 4 миллионов символов в месяц (для стандартных голосов) и 1 млн для WaveNet. Для личных нужд этого хватит на годы.
Как этим пользоваться?
У Гугла есть удобная демозона прямо в консоли (как на скрине ниже). Вы просто вбиваете текст, выбираете язык и тип голоса — обязательно ищите пометку Neural2 или Studio, это те самые голоса нового поколения, которые звучат неотличимо от человека.
Терминал снизу (Cloud Shell) и вкладка Get Code пригодятся позже, когда вы захотите автоматизировать процесс. А пока можно просто поиграться с настройками в визуальном редакторе, тестировать скорость и интонацию, не написав ни строчки кода. Вы настраиваете звук бесплатно здесь, а потом просто копируете конфиг в свой проект.
IBM Watson Text to Speech: корпоративный уровень
Это часть огромной экосистемы IBM Cloud. Сразу предупредим: это инструмент не для того, чтобы по-быстрому озвучить тикток. У него нет привычного веб-интерфейса с кнопкой «Сгенерировать», и всё взаимодействие происходит через API.
- Для кого: для разработчиков энтерпрайз-софта, банков, интеграторов. Обычному пользователю тут будет сложно и душно.
- Порог входа высокий. Чтобы просто «потыкать» сервис, нужно создать аккаунт в IBM Cloud и обязательно привязать банковскую карту (даже для бесплатного тарифа).
- Фишки: главная сила Watson — кастомизация. Его можно натренировать правильно произносить специфические термины (медицинские диагнозы, юридические формулировки), где другие нейронки ломают язык.
- Цена: есть Lite-план (10 000 символов в месяц бесплатно), но проходить мучения с регистрацией и настройкой API стоит, только если вам нужны специфические сервисы IBM.
Бесплатные нейросети для озвучки
Не всегда есть бюджет на подписки по 20 $, особенно если вы пилите пет-проект или просто хотите послушать длинную статью в дороге.
Balabolka + RHVoice: локальное решение
Balabolka — это программа-оболочка для Windows (выглядит как привет из 2000-х, но функциональность мощнейшая), а RHVoice — это бесплатный движок с открытым кодом, который к ней подключается.
- Как это работает: вы скачиваете программу, ставите голосовой движок RHVoice, и всё работает офлайн. Интернет не нужен вообще.
- Качество: голоса (особенно «Александр» и «Елена») звучат разборчиво, но не ждите от них актёрской игры ElevenLabs. Это рабочие лошадки для чтения книг или озвучки технических инструкций.
- Главный плюс: полная приватность и ноль затрат. Вы можете сгенерировать хоть 100 часов аудио, и всё это бесплатно и локально.
- Для Mac/Linux: увы, Balabolka работает только на Windows. Пользователям macOS проще использовать встроенную функцию «Проговаривание» (Spoken Content) в настройках системы — там доступны отличные голоса Siri, которые звучат даже лучше.
Яндекс SpeechKit: 1 млн символов бесплатно
Если вам нужен «тот самый голос Алисы» и идеальное понимание русского языка — лучше Яндекса пока ничего нет.
- Для кого: для тех, кто не боится консоли или готов написать простенький скрипт на Python.
- Качество: топовое. Расставляет ударения правильно даже в сложных словах, понимает ёфикацию.
- Нюанс с ценой: формально это платный облачный сервис. НО! Яндекс даёт грант или Free Tier для новых пользователей, которого хватает примерно на 1 миллион символов. Для личных проектов этого объёма хватит надолго.
Кнопок «скачать» тут нет, потому работаем через код:
- Регистрируемся в Yandex Cloud, создаём Billing Account и привязываем карту — спишут и вернут рубль.
- Создаём в облаке каталог — папку.
- Заводим Service Account (сервисный аккаунт) — это виртуальный пользователь для ваших скриптов. Важно: при создании выдайте ему роль editor или ai.speechkit-user, иначе у него не будет прав говорить.
- Генерируем для этого аккаунта API Key.
Всё! Этот ключ — ваш пропуск. Затем берёте любой пример кода с GitHub (официальная документация Яндекса полна примеров на Python и Bash), вставляете туда свой ключ и текст — и получаете аудиофайл студийного качества.
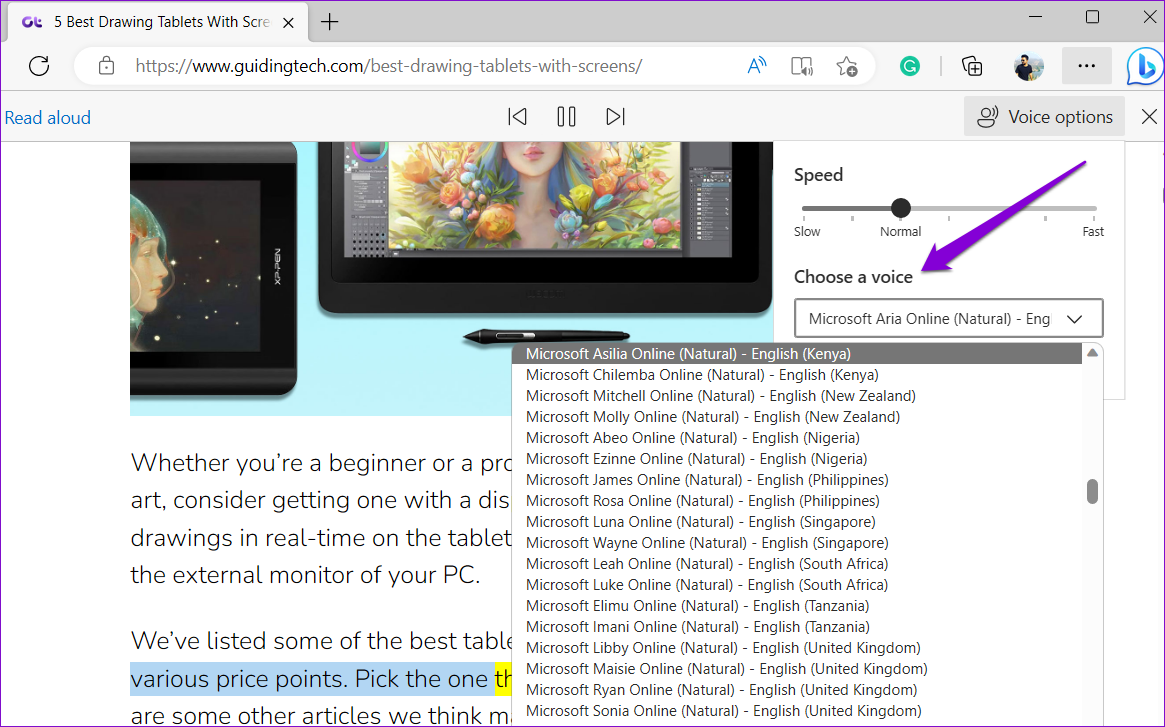
Edge Read Aloud: встроенный в браузер инструмент
Это самый недооцененный читерский метод. В браузере Microsoft Edge встроена функция «Прочесть вслух» (Read aloud), которая использует дорогущие нейросетевые голоса Azure TTS абсолютно бесплатно.
- Как это работает: открываете PDF или сайт в Edge, жмёте кнопку с буквой «A» в адресной строке — и браузер читает текст голосом, который у конкурентов стоит денег.
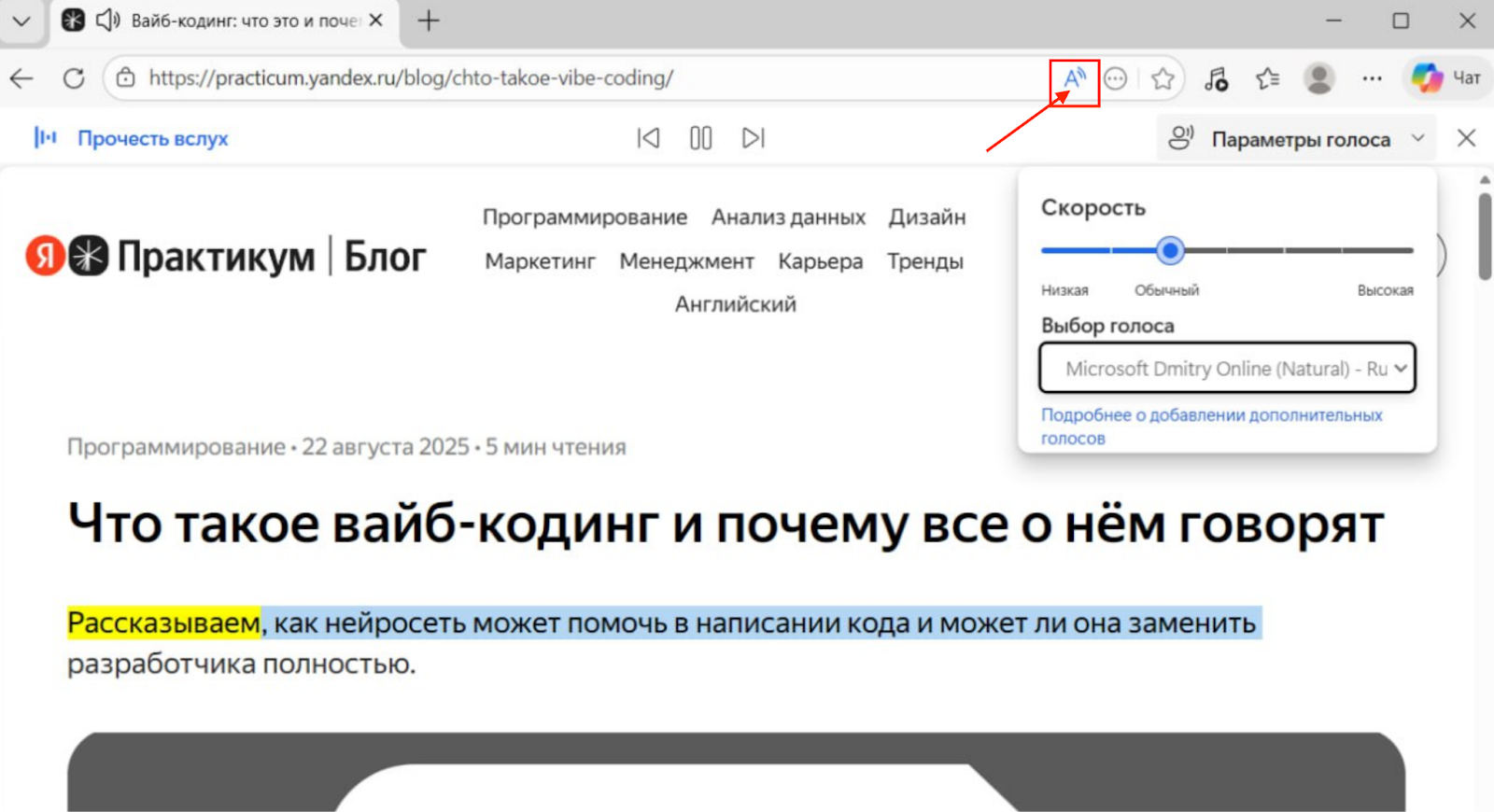
- Качество: потрясающее. Есть «Светлана» и «Дмитрий», которые звучат очень натурально, делают паузы на запятых и меняют интонацию.
- В чём подвох: кнопки «Скачать MP3» там нет. Это инструмент для прослушивания. Чтобы забрать аудио себе в видеоролик, придётся использовать «костыль»: включить запись звука с экрана (или Virtual Audio Cable) и записать поток в реальном времени. Неудобно, зато бесплатно и качественно.
Как озвучить текст нейросетью: пошаговая инструкция
На первый взгляд всё несложно, но, если просто скопировать сырой текст из ворда, на выходе получится унылый бубнёж с ошибками. Чтобы получить звук студийного качества, нужно пройти четыре этапа.
Шаг 1. Выбор подходящего сервиса
Как и везде в разработке, всё начинается с цели. Если вам нужно озвучить короткий мем или тикток на 15 секунд, нет смысла регистрироваться в сложных облачных платформах — хватит браузерного расширения или простого телеграм-бота. Но если вы делаете дубляж фильма или озвучиваете аудиокнигу, то смотрите в сторону ElevenLabs или Murf, где есть управление эмоциями и огромный выбор голосов.
Также оцените бюджет: для длинных текстов сервисы с оплатой «за каждый символ» могут разорить вас за полчаса. В таких случаях лучше искать безлимитные тарифы или локальные решения вроде Balabolka.
Шаг 2. Подготовка текста для озвучки
Нейросеть читает ровно то, что написано. Поэтому текст нужно превратить в «сценарий для робота». Сначала избавьтесь от неоднозначностей: сокращение «г.» нейросеть может прочитать как «грамм», а не «город», поэтому пишите слова целиком.
Особое внимание уделите цифрам и датам — лучше прописать их словами, чтобы «42» не прозвучало как «четыре два». И конечно, расставьте «режиссёрские» знаки препинания. Даже если по правилам русского языка запятая там не нужна, но вы хотите, чтобы диктор сделал паузу для дыхания, — смело ставьте её. Точка создаёт длинную паузу, многоточие добавляет задумчивости.
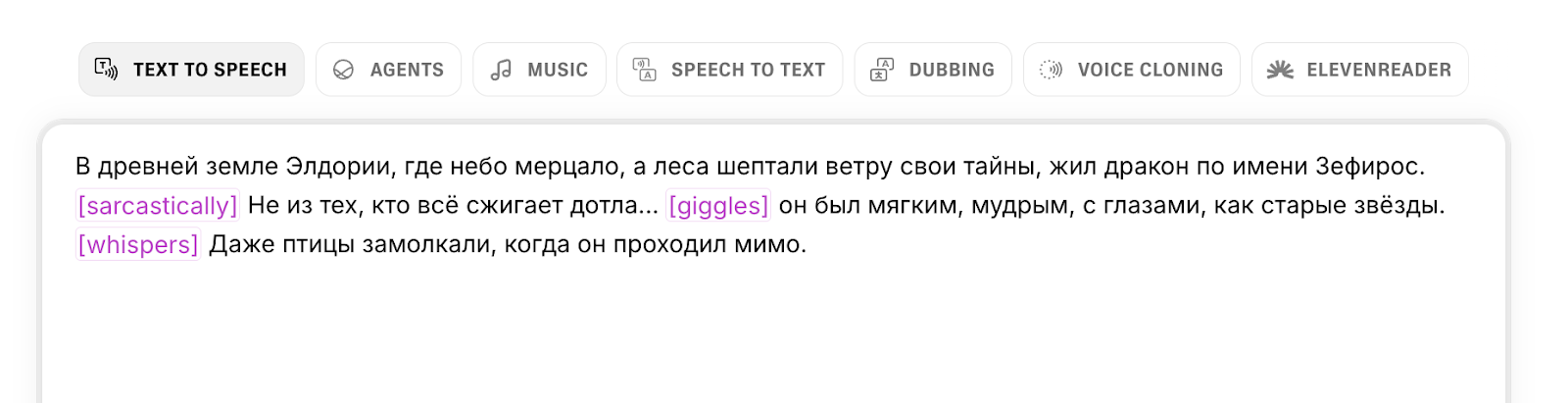
Но высший пилотаж — это эмоциональные подсказки.
Продвинутые сервисы понимают команды в квадратных скобках, как в пьесе. Хотите добавить драмы? Напишите [whispers], и нейросеть перейдёт на шёпот. Нужно разрядить обстановку? Вставьте [giggles] или [laughs]. А тег [sarcastically] заставит ИИ изменить интонацию на язвительную.
В более сложных системах разметка делается через SSML-теги в XML. Например, вот так можно объяснить роботу, что «СПб» — это город, а после важной фразы нужно выразительно помолчать:
<speak>
Привет! Это пример <sub alias="разметки синтеза речи">SSML</sub>.
<p>Я умею расшифровывать аббревиатуры. Например, <sub alias="Санкт-Петербург">СПб</sub> — это город на Неве.</p>
А сейчас я сделаю драматическую паузу... <break time="2s"/>
И продолжу говорить с новой строки.
Могу даже продиктовать ваш номер по цифрам: <say-as interpret-as="digits">12345</say-as>.
</speak>Что здесь происходит:
<speak>— обязательная обёртка для всего текста.<sub alias="...">— заставляет читать не то, что написано (СПб), а то, что в кавычках (Санкт-Петербург).<break time="2s"/>— жёсткая пауза на 2 секунды. Точнее, чем просто точка.<say-as>— подсказка, как читать число: как год, как сумму денег или просто по цифрам.
Так вы не просто скармливаете текст, а управляете актёрской игрой. Без этих меток даже самый крутой голос может звучать плоско.
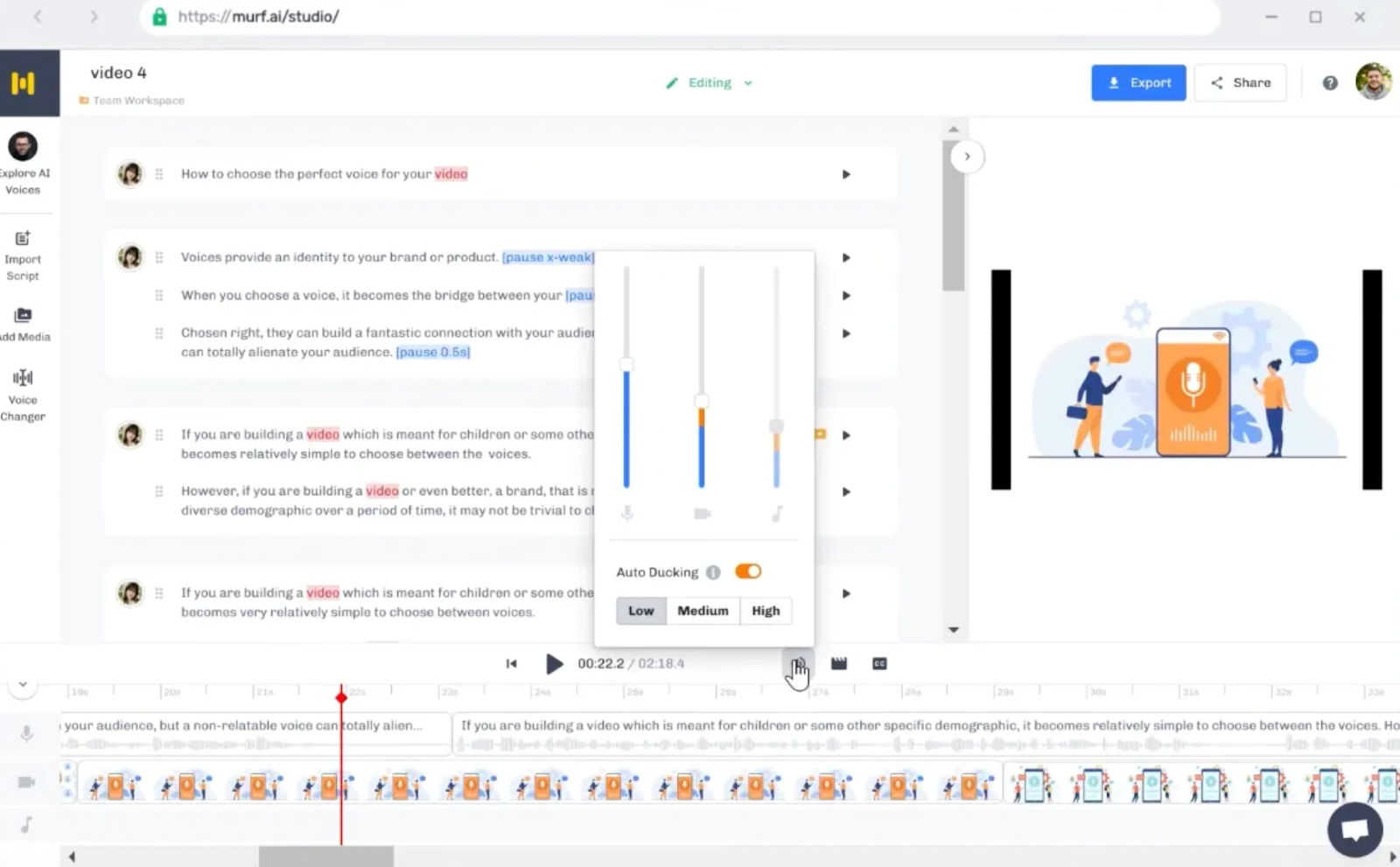
Шаг 3. Настройка параметров голоса
Дефолтные настройки — это безопасный, но скучный вариант. Чтобы голос зазвучал живо, нужно поэкспериментировать. Посмотрим на примере murf.ai:

На верхней панели есть несколько ползунков:
- Pitch (высота тона): если хотите сделать голос моложе или напряжённее — повышайте питч. Хотите добавить авторитета, басовитости или спокойствия — уводите в минус.
- Speed (скорость): для динамичных роликов в TikTok смело ставьте +10 или +15%. Для обучающих лекций лучше чуть замедлить (−5%), чтобы слушатель успевал переваривать информацию.
- Add Pause (паузы): нейросеть иногда тараторит, поэтому вставляйте микропаузы (0,5 с) между мыслями, это добавляет речи естественный ритм, как будто диктор набирает воздух в лёгкие.
- Style (стиль): на скрине стоит General (обычный), но у многих премиум-голосов здесь прячутся режимы Promo (для рекламы), Sad (грустный) или Newscast (новости). Обязательно проверяйте этот список — смена стиля меняет подачу сильнее, чем любые другие настройки.
Шаг 4. Экспорт и сохранение результата
Перед тем как нажать заветную кнопку Download и списать кредиты, прослушайте превью от начала до конца. Нейросети любят идеально прочитать три абзаца, а в последнем слове сглотнуть окончание или перейти на металлический скрежет.
Когда результат вас устроит, выбирайте формат. Если планируете монтировать звук в видеоредакторе, накладывать музыку и эффекты — всегда качайте в WAV. MP3 уже сжат, и при повторной обработке качество звука может заметно просесть.
Особенности ИИ-озвучки на русском языке
Русский язык считается одним из самых сложных для TTS-моделей. Если в английском нейросети уже достигли почти 100%-го реализма, то в русском они всё ещё могут споткнуться на ровном месте. Потому что в русском языке свободный порядок слов, плавающее ударение и буква «Ё», которую все игнорируют, а роботы из-за этого страдают.
Проблемы с интонацией и ударениями
Главная боль — это омографы. Нейросеть не всегда понимает, что вы имели в виду:
- «На двери висит замóк» или «Принц построил зáмок»?
- «Я плачý налоги» или «Я плáчу от налогов»?
- «Бе́лки» (животные) или «Белки́» (протеины)?
Без подсказок ИИ часто выбирает самый популярный вариант, и он не всегда верный.
Вторая проблема — буква «Ё». В обычной переписке мы её не ставим, но для нейросети «все» (everyone) и «всё» (everything) — это два разных слова. Если вы напишете «Все пропало», робот прочитает это как «Все (люди) пропало», что звучит как бред сумасшедшего.
Третья боль — IT-сленг и англицизмы. Слова вроде «C#», «SQL», «Backend» нейросети часто пытаются читать транслитом или по буквам («Сэ-решетка», «Эс-Ку-Эль», «Бацкенд»). А слово «Java» в исполнении некоторых моделей звучит как «Ява», что сразу выдаёт искусственность.
Как добиться естественного звучания
Чтобы ИИ заговорил как живой человек, текст придётся «причесать» специально под него:
- Тотальная ёфикация. Везде, где слышится «Ё», она должна быть написана, без вариантов. «Ёлка», «передохнём», «узнаёт» — всё это должно быть с точками, иначе получите смысловые галлюцинации.
- Знак «плюс» для ударений. Большинство движков (Яндекс, Google, Edge) понимают знак + перед ударной гласной. Если робот тупит, прописывайте явно: «Это стóит б+ольших денег».
- Фонетическая запись. Сложные иностранные бренды и термины лучше писать кириллицей так, как они слышатся. Вместо «Renault» пишите «Рено». Вместо «C++» — «Си-плюс-плюс». ИИ не на экзамене по английскому, его задача — звучать, а не читать правописание.
- Дробление предложений. Если у вас предложение на три строки с пятью деепричастными оборотами, ИИ «задохнётся» и потеряет интонацию к концу. Разбейте его на три коротких фразы — звук станет динамичнее.
Лучшие голоса для русского языка
Не все модели одинаково полезны, но есть проверенные варианты, которые звучат максимально «по-нашему»:
- «Ермил» и «Филипп» (Яндекс SpeechKit): звучат как профессиональные дикторы радио. Низкий тембр, отличная дикция, идеально подходят для новостей и подкастов.
- «Dmitry» и «Svetlana» (Microsoft Azure): голоса из браузера Edge. Дмитрий звучит уверенно и доверительно, Светлана построже. Они прекрасно справляются с длинными текстами.
- «Adam» (ElevenLabs): хоть это и изначально английская модель, она пугающе хорошо выучила русский. У него есть лёгкий, едва уловимый акцент, но этот минус перекрывает эмоциональный диапазон.
- «Алёна» (из Алисы): хороша для лёгкого, развлекательного контента, но может звучать слишком узнаваемо — сразу понятно, что с вами говорит колонка.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.
Практическое применение нейросетевой озвучки
Для видеороликов и подкастов
Боль любого блогера — это не монтаж, а звук. Чтобы записать чистый голос, нужно выгнать кота из комнаты, закрыть окна и надеяться, что сосед с перфоратором уехал в отпуск. Нейросети решают эту проблему радикально: у вас всегда есть «студийный диктор», который не кашляет и готов работать в три часа ночи.
Но настоящий прорыв 2025 года — это локализация. Представьте, что вы сняли гайд по настройке сервера. С помощью функции Voice Cloning вы можете перевести этот ролик на испанский, китайский или хинди, причём говорить на этих языках будете вы сами (точнее, ваш цифровой клон). Это открывает двери на глобальный рынок без необходимости учить языки или нанимать дорогих актёров дубляжа.
В образовательных проектах
Любой, кто хоть раз делал онлайн-курс или корпоративную инструкцию, знает такую проблему: продукт обновился, кнопка «Купить» переехала в другой угол, и теперь нужно перезаписывать весь урок. Если вы работали с живым диктором, вам придётся искать его, платить за студию и пытаться попасть в ту же интонацию, что и полгода назад.
С ИИ-озвучкой такой проблемы нет. Вы просто открываете сохранённый проект, меняете одно предложение в тексте и нажимаете «Сгенерировать». Через минуту готов обновлённый урок с тем же самым голосом и тембром. Это сэкономит сотни часов на актуализации контента.
Для озвучки книг и статей
Раньше выпуск аудиокниги был привилегией топовых писателей, за которыми стояли издательства с бюджетами. Инди-авторам оставалось либо читать самим, что редко получается хорошо, либо платить дикторам по ставке за каждый час готового материала.
Нейросети демократизировали этот процесс. Теперь любой лонгрид, техническую документацию или фантастический рассказ можно превратить в аудиоформат за пару вечеров.
Конечно, для сложной художественной литературы с десятью персонажами ИИ пока может не хватить актёрского мастерства (хотя ElevenLabs уже очень близок), но для бизнес-литературы, новостей и нон-фикшена это идеальное решение. Читатели скажут вам спасибо за возможность послушать статью в машине или на пробежке, а не ломать глаза с экрана телефона.
Частые вопросы (FAQ)
Какая нейросеть лучше всего озвучивает текст бесплатно?
Если мы говорим о качестве звука, то безусловный лидер бесплатного сегмента в 2025 году — это, как ни странно, браузер Microsoft Edge. Его встроенный движок Read Aloud выдаёт результат уровня платных студийных сервисов. Как мы уже сказали, скачать аудиофайл нельзя, придётся записывать звук с экрана.
Если же вам нужно «честное» бесплатное решение, которое работает без интернета и позволяет сохранять файлы в mp3 без танцев с бубном, то лучшая связка — это старая добрая Balabolka с движком RHVoice. Да, голос будет попроще, но зато без лимитов.
Как сделать озвучку более естественной?
Естественность умирает на длинных, сложных предложениях без знаков препинания. Секрет прост: дробите текст на короткие фразы, не ленитесь проставлять букву «ё» (это критично для интонации) и используйте знаки препинания как режиссёрские ремарки.
В продвинутых сервисах вроде ElevenLabs не бойтесь использовать теги эмоций — одна пометка [sighs] (вздыхает) перед предложением может сделать фразу живой.
Есть ли ограничения по длине текста?
Да, и они бывают двух типов.
Первый — это лимит «за один раз» (input limit). Большинство нейросетей не могут «проглотить» больше 2–5 тысяч символов за один заход, иначе они начинают терять контекст и интонацию. Поэтому «Войну и мир» придётся скармливать по главам.
Второй лимит — финансовый. В облачных сервисах вы тратите кредиты на каждый сгенерированный символ. Например, на стартовом тарифе ElevenLabs у вас есть 30 тыс. кредитов на месяц. Если вы ошиблись в тексте и перегенерировали абзац — вы заплатили дважды. Полный безлимит по длине и попыткам дают только локальные программы, установленные на ваше железо.
Ищете работу в IT?
Карьерный навигатор Практикума разберёт ваше резюме, проложит маршрут к первому работодателю, подготовит к собеседованиям в 2026 году, а с января начнёт подбирать вакансии именно под вас.