








Разбираем ещё одну тему про искусственный интеллект: как сделать так, чтобы машина работала с заранее отобранными данными и отвечала на основе них. Такой инструмент называется RAG-системой, от слов Retrieval-Augmented Generation — «поисковая дополненная генерация».
RAG-системы работают как ChatGPT, YandexGPT и другие языковые модели, но с дополнительными библиотеками. Например, используя набор инструкций одной конкретной бухгалтерии в одной конкретной компании. Если бухгалтерам понадобится составить сложный отчёт, они могут отправить запрос в базу, а она выдаст набор инструкций со ссылками на существующие документы.
Как это работает и чем отличается от обычных языковых AI, рассказываем дальше.
Что такое база знаний ИИ
База знаний с нейросетевой моделью — это структурированное хранилище информации, которое ИИ использует для анализа, ответов и рекомендаций. В отличие от обычной базы данных, здесь важно не просто хранить факты, но и уметь их правильно выдавать пользователям. Поэтому модель не отправляет в качестве ответа документы целиком, а извлекает нужные фрагменты под конкретный запрос.
Для пользователя всё выглядит так, что база знаний, с которой он общается, — это мост между человеком и библиотеками данных. С инженерной точки зрения всё немного сложнее:
- Пользователь пишет запрос в диалоге с базой знаний.
- Модель на входе разбирает и оцифровывает запрос, чтобы найти всю нужную информацию в библиотеках данных.
- Подходящие статьи, шаблоны и другие материалы отправляются в другую часть модели — большую языковую модель или LLM.
- LLM обрабатывает все эти материалы и готовит подходящий ответ для пользователя.
По сути, такая база знаний позволяет нейросети опираться на внутренние знания компании или проекта. Именно так ИИ начинает отвечать на конкретные специализированные запросы.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Традиционные базы знаний в сравнении с базами знаний ИИ
В базах знаний хранятся статьи, FAQ и другие документы, которые читает человек. Чтобы найти ответ в обычной базе, нужно правильно сформулировать запрос: слова из него должны точно совпасть с тем, что написано в данных. Потом нужно проверить результаты выдачи и отобрать подходящие материалы. Машина работает просто как поиск по словам.
В базе знаний с ИИ всё по-другому: запрос можно формулировать на естественном человеческом языке, а система сама найдёт подходящие фрагменты. ИИ не просто ищет совпадения, а пытается понять смысл вопроса и контекста. Это делает доступ к знаниям быстрее и удобнее, особенно для сложных или неточных запросов.
Основные компоненты базы знаний ИИ
Чтобы было проще понимать механику работы, вот два важных понятия.
Embedding — перевод текста с человеческого языка в числовой «язык смыслов», понятный машине. Каждое слово машина переводит в набор чисел-векторов, через которые понимает важность каждого и связь друг с другом. Иногда такой процесс ещё называют индексацией или индексированием.
На иллюстрации ниже похожие слова отмечены похожими цветами, но на самом деле модель переводит слова в векторы — наборы чисел, которые понятны машинам:

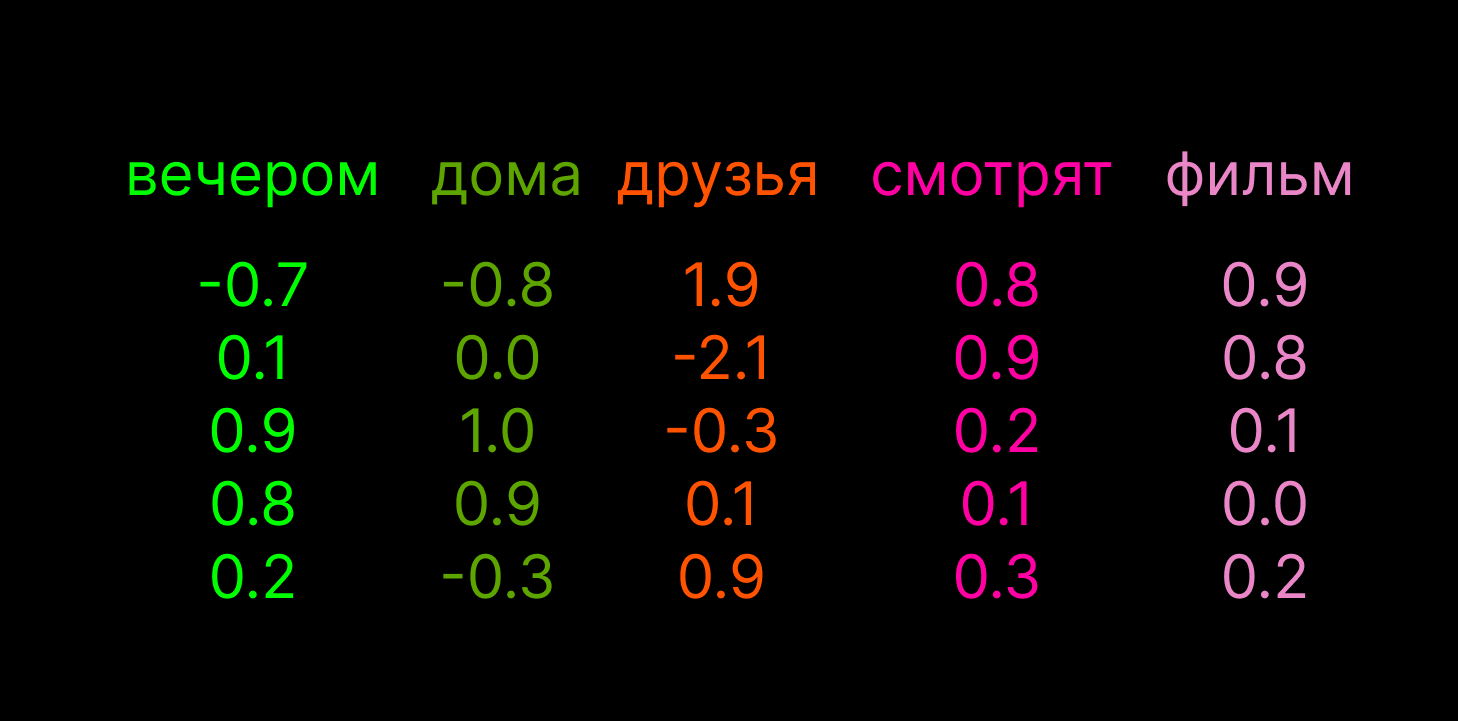
Embedding понимает, где находится слово в пространстве смыслов.
Retrieval — поиск ближайших смыслов. Этот механизм важен для нахождения самых подходящих материалов в библиотеках данных, которые нужны для ответа пользователю. Именно поэтому RAG-система понимает запрос, написанный в свободной форме.
Теперь — компоненты.
Чаще всего база знаний с ИИ состоит из данных, embedding-модели для поиска и LLM-модели, которая формирует ответ. Данные хранятся в виде текстов, разбитых на небольшие фрагменты. Поиск чаще всего реализован через векторное embedding-сравнение смыслов.
Генеративная языковая модель объединяет найденные фрагменты в связный ответ. Без неё база знаний даже с embedding-моделью остаётся просто умным поиском. Вместе они образуют систему, которая может объяснять, пересказывать и адаптировать информацию под пользователя.
RAG (Retrieval-Augmented Generation)
Теперь можно сделать итоговое определение.
RAG — подход, при котором нейросеть сначала ищет информацию во внешней базе знаний, которую подготовили инженеры, редакторы и другие специалисты. После этого генерируется ответ на основе найденных материалов.
Модель не хранит все факты в себе, а каждый раз обращается к данным. Это важное отличие от стандартной схемы языковых моделей, которые обучаются на большом количестве данных и при общении с человеком опираются только на то, что хранится внутри них.
Работа с внешними библиотеками материалов снижает количество ошибок и галлюцинаций, когда система придумывает ответ. Но не на 100%, поэтому к ответам базы знаний всё равно нужно относиться критически и проверять перед использованием.
Главное преимущество RAG — актуальность. Вы можете обновлять документы, и ИИ сразу начнёт использовать новую информацию без переобучения. Такой подход особенно полезен для внутренних инструкций, документации и бизнес-процессов.
Интеллектуальные помощники ИИ
Это модели, которые понимают запросы пользователя и возвращают понятные ответы.
Благодаря внешним библиотекам данных интеллектуальные помощники становятся удобным гибким поиском по всей информации библиотек. Это могут быть инструкции и регламенты коммерческих компаний, обучающие документы разработчиков программного обеспечения и вообще любая информация, которой кто-то пользуется.
Возможности самообучения
Обычная ИИ-модель не может быстро обучиться новым знаниям. Для этого нужно собрать и подготовить данные, запустить процесс дообучения, скорректировать работу системы. Это дорогой и долгий процесс:

С RAG-системой всё проще: достаточно добавить новые данные во внешние библиотеки, и модель почти сразу готова их использовать.
Это не значит, что нейромодели RAG-систем вообще не нужно дополнительно обучать. Но такое обучение нужно делать реже и для другой цели: чтобы модель научилась лучше мыслить и обрабатывать информацию из базы.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.
Преимущества баз знаний с поддержкой ИИ
Главное преимущество при хорошо обученных моделях — скорость получения ответов. Пользователь задаёт вопрос в любой форме и сразу получает компактный понятный результат. Это экономит время и нагрузку поддержки и экспертов.
Второе преимущество — масштабируемость. Одна база знаний может работать с тысячами пользователей, и по-разному заданные вопросы с одинаковым смыслом получат стабильный одинаковый ответ.
Примеры использования баз знаний с ИИ
Такие базы могут применяться везде, где нужно часто обращаться к большому количеству собранных данных.
Один из примеров — внутренние порталы компаний. Сотрудники спрашивают про процессы, регламенты и инструменты, не открывая большое количество документов. Это особенно полезно для адаптации новых специалистов.
Ещё один сценарий — поддержка клиентов. ИИ-ассистент отвечает на типовые вопросы, а сложные передаёт человеку. Так повышается скорость ответа и общее качество сервиса.
Основные возможности баз знаний на основе ИИ
RAG-системы ищут по смыслу, а не по словам. Это значит, что вопрос можно задать неточно и система всё равно найдёт нужный фрагмент. Такая возможность особенно ценна для неструктурированных данных.
ИИ может пересказывать информацию, упрощать сложные тексты и адаптировать стиль. Если модель хорошо обучить, то одна и та же база знаний подойдёт и для новичков, и для опытных специалистов.
При этом ни одна база знаний не поможет, если требуются действия живого человека. Например, чат-бот может пообещать отменить заказ на доставку цветов или еды, но в реальности система уже внесла данные заказа. Если реальный оператор не увидит сообщения или не отреагирует вовремя, запрос клиента останется невыполненным. Иногда в этом нет вины ИИ или человека — например, если запрос отправлен слишком поздно:

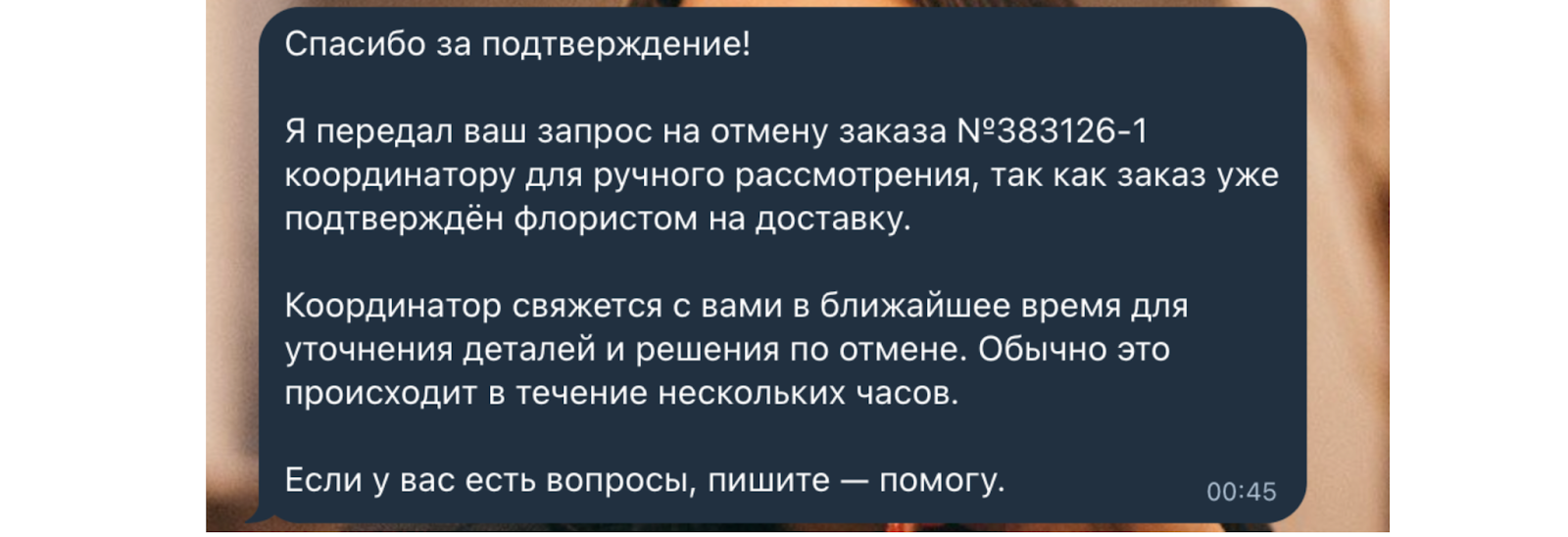
Как выстраивают RAG-систему
Для созданий базы знаний с ИИ есть несколько основных шагов.
Сначала нужно собрать и привести в порядок данные: документы, инструкции, статьи. Это основа того, с чем будет работать и что будет использовать для ответов машина.
Все материалы разбивают на небольшие фрагменты и преобразуют в векторную базу данных. Для этого текст отправляют в эмбеддинг-модель, и она возвращает массив чисел. Тогда начинает работать семантический поиск, то есть по смыслу.
После этого можно настраивать связку: embedding-поиск и генеративная LLM.
На последнем этапе систему тестируют и дорабатывают, улучшая качество ответов. Обычно это итеративный процесс проверок и корректировок.
Где RAG уже работает
RAG часто используется во внутренних чат-ботах IT-команд. Они помогают разработчикам быстро находить информацию по коду, инфраструктуре и процессам. Это снижает количество отвлекающих вопросов в чатах.
Ещё ИИ может отвечать на вопросы по корпоративным отчётам, документации и исследованиям. Пользователю не нужно быть экспертом, чтобы разобраться в регламентах и шаблонах или получить полезный вывод.
Как превратить базу знаний в топливо для ИИ
ИИ-модель будет хорошо работать только с понятными и структурированными знаниями. Если база состоит из набора разрозненных документов, результат будет слабым.
Важно подготовить данные так, чтобы машине было легко работать. Для этого база должна быть актуальной, логичной и ориентированной на вопросы пользователей. Тогда ИИ сможет извлечь из неё максимум пользы.
ИИ нужны чёткие формулировки и минимальный шум. Чем меньше лишнего текста и дублирования, тем лучше ответы.
Ещё важно, чтобы каждый фрагмент имел ясный смысл сам по себе. Контекст важнее объёма: лучше иметь короткие точные описания, чем длинные, но абстрактные документы. Это упрощает поиск и генерацию ответов.
Разбиваем знания на фрагменты
Фрагмент — это минимальный кусок информации, который можно понять без остального документа. Обычно это абзац или небольшой логический блок. Слишком большие фрагменты ухудшают поиск.
Хорошее правило — один фрагмент отвечает на один вопрос. Такой подход делает базу знаний гибкой и удобной для RAG: так ИИ легче комбинирует атомарные знания в ответ.
Вот как это правило описано в статье о составлении технической документации от Google:
«Сфокусируйте каждый абзац на одной теме.
Абзац должен представлять собой самостоятельную логическую единицу. Ограничивайте каждый абзац одной текущей темой. Не описывайте, что произойдёт в следующем абзаце и что было в прошлом. При редактировании удаляйте (или переносите в другой абзац) любые предложения, которые не имеют прямого отношения к теме абзаца».
В примере к этому есть два абзаца: в первом есть предложения из другой темы. Во втором эти предложения вычеркнуты:


Связываем: как строится граф знаний (Knowledge Graph)
Граф знаний — это связи между понятиями, терминами и документами. Он помогает понимать, как разные части информации относятся друг к другу. Даже простой граф улучшает навигацию и поиск:

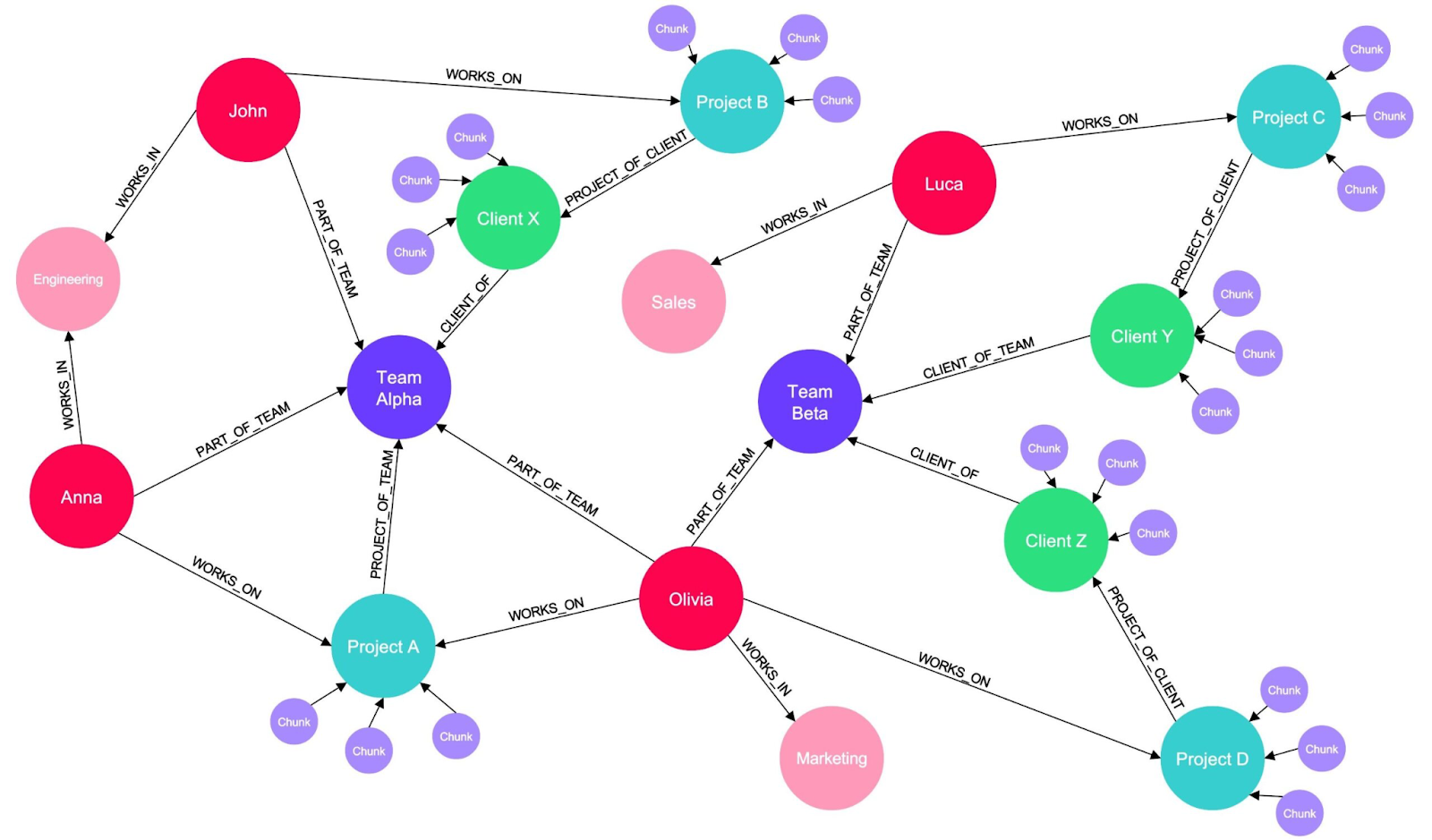
Необязательно рисовать диаграмму или график. Важнее, чтобы этот граф существовал в виде данных и использовался для поиска. Например, чтобы уточнить термины или показать связанные темы. Это делает ответы более точными и осмысленными.
Обновления, ревизия, приоритеты
Чаще всего базу знаний не получится собрать один раз и навсегда, потому что данные будут устаревать. Регулярные обновления критически важны для качества ответов. Неактуальные данные могут нанести вред и быстро подрывают доверие пользователей.
В процессе обновлений полезно расставлять приоритеты: какие документы важнее, какие используются чаще. Это помогает машине опираться на ключевые источники. В результате ответы становятся стабильнее и надёжнее.
Ищете работу в IT?
Карьерный навигатор Практикума разберёт ваше резюме, проложит маршрут к первому работодателю, подготовит к собеседованиям в 2026 году, а с января начнёт подбирать вакансии именно под вас.
Чек-лист: готова ли ваша база знаний к работе с ИИ
Если большинство этих пунктов выполнено, база знаний готова к подключению нейромоделей и апдейту до полноценной RAG-системы:
- Документы актуальны и не противоречат друг другу.
- Информация разбита на компактные понятные фрагменты.
- Нет лишних дубликатов и абстрактной информации без пользы.
- Есть структура и логика связей между темами.
- База регулярно обновляется.






















