Представим вполне реальную ситуацию: мы сидим дома, у соседей ремонт, в комнате рядом работает телевизор, кто-то разговаривает, в умной колонке с Алисой играет музыка, и в этот момент мы просим её рассказать о Древнем Риме. Напомним, что вокруг довольно шумно, плюс сама колонка играет какую-то музыку. Как она вообще нас услышит и распознает в этом шуме, что мы от неё хотим?
А вот так ↓
Как было раньше
Раньше было так: если нужно распознать голосовую команду посреди шума, использовались два алгоритма:
- эхоподавление;
- и шумоподавление (ANC, Active Noise Canselling).
Первый помогает отделить речь от музыкального фона, а второй подавляет постоянные звуки вроде шума улицы или гула бытовой техники.
Главная проблема такого логичного решения в том, что это работает не во всех условиях. Например, шумоподавление часто ослабляло и распознавание самой голосовой команды — вы что-то сказали, а шумодав решил, что это чей-то случайный разговор, и попытался его заглушить. Также эффективность эхоподавления зависит от положения колонки: если микрофон стоит сзади, а говорящий — спереди от колонки, то микрофону будет сложнее уловить чистую речь.
А ещё раньше не было единого решения, которое одинаково хорошо показывало бы себя в лабораторных тестах и при реальной эксплуатации устройств. Например, во время тестов всё было прекрасно, но стоило поставить колонку в обычный офис, и процент распознавания речи сразу падал до критических значений.
Что придумал Яндекс
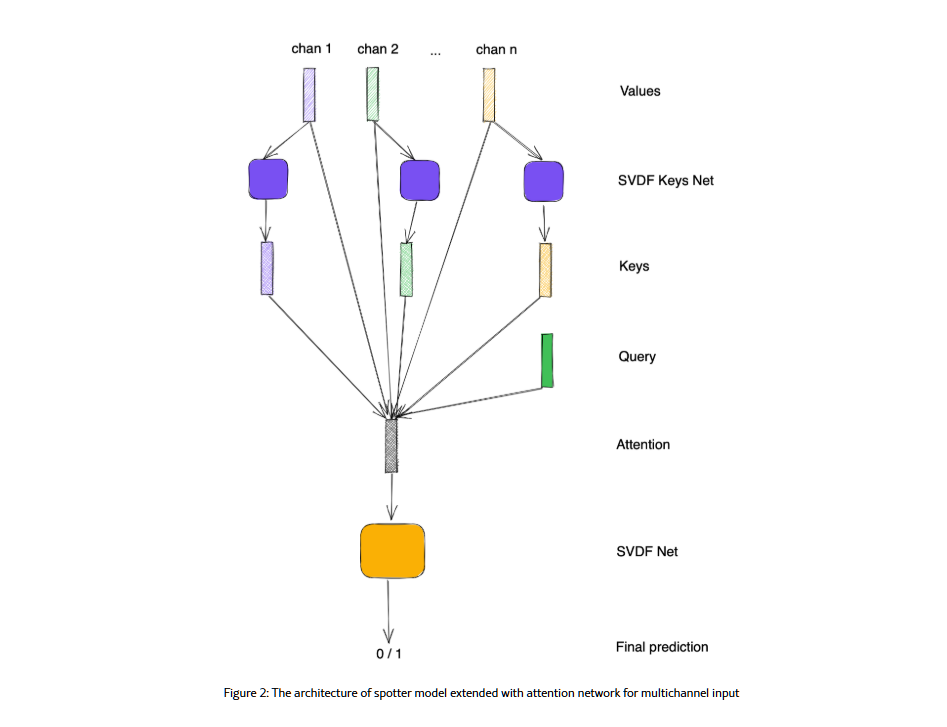
Исследователи голосовых технологий Яндекса предложили новый способ — использовать нейросеть с attention-механизмом, которая смешивает два сигнала в наиболее информативный вариант. Например если шум есть только на отдельных частотах, то на них может быть взят звук с шумоподавлением, а на остальных с эхоподавлением. В качестве источников используются одновременно каналы с эхоподавлением, шумоподавлением, а также «чистый» омни-канал — сигнал с микрофона без обработки.
Теперь переведём на русский:
- под капотом — нейросеть, которая постоянно анализирует разные звуковые каналы и ищет среди них в каждый момент самый адекватный для распознавания;
- таких каналов как минимум два: звуковая дорожка с эхоподавлением и с шумодавом;
- каждую секунду нейросеть выбирает дорожку с максимально понятным сигналом, собирает речь в реальном времени и распознаёт её.
Такой подход позволяет системе гибко адаптироваться к внешним условиям и фокусироваться на том канале, где голос пользователя слышен лучше всего. В итоге колонка слышит разборчивую речь даже в условиях неоднородного шума.


Как это работает технически
В основе технологии — нейросеть, построенная по принципам архитектуры SVDF, которая хорошо подходит для работы на устройствах с ограниченными ресурсами.
Что такое SVDF
Архитектура SVDF (Singular Value Decomposition Filter) — это особый способ организации работы маленькой нейросети для обработки последовательностей, например звука или текста. Её главная цель — уметь улавливать важные закономерности во времени, но при этом быть очень простой и требовать мало вычислительной мощности. Это делает её идеальной для работы в часах, телефонах или микрофонах с голосовыми помощниками, где важно быстро реагировать.
Принцип работы в том, что такая нейросеть разделяет задачу на две части. Одна часть («пространственные» фильтры) ищет закономерности в самих данных, например том, какие частоты есть в звуке прямо сейчас. Другая часть («временные» фильтры) специально обучена помнить, какие закономерности уже встречались совсем недавно, и сочетать их с новыми данными. Это разделение позволяет нейронке понимать не только что происходит, но и в каком порядке это происходит, а это очень важно для распознавания речи.
Короче, SVDF — это умный и экономный дизайн нейросети. Вместо того чтобы заставлять ИИ помнить всё сразу, архитектура назначает им разные роли: одни смотрят на текущий момент, а другие — на контекст из недавнего прошлого. Благодаря такому подходу даже маленькая нейросеть может достаточно хорошо распознавать команды типа «Алиса» или «Окей, Google», не нагружая процессор устройства.
Сначала исследователи обучили модель на одноканальном сигнале, а затем адаптировали её к шумной многоканальной среде: добавили attention-механизм, который помогает выбирать наилучший сигнал из нескольких микрофонов. Такая модель была дообучена на полумиллионе многоканальных примеров, чтобы повысить точность распознавания.
В отличие от других подходов, где для каждого микрофона требуется отдельная работающая копия нейросети, сделали обработку в рамках одного вычислительного цикла — это снижает нагрузку на устройство и ускоряет работу.
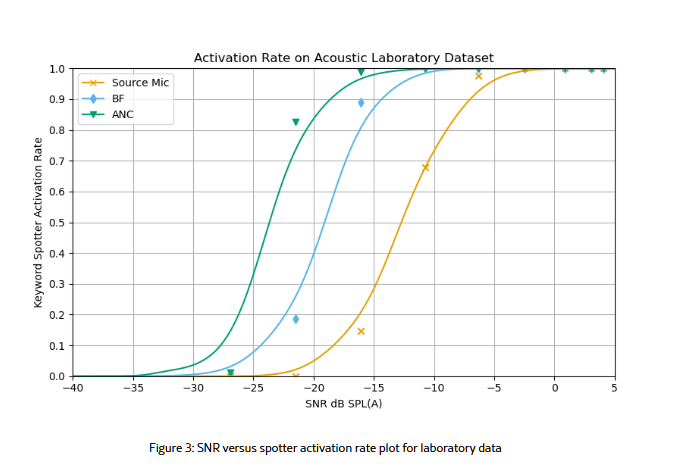
Надёжность модели проверяли в специальной акустической лаборатории, где воспроизводили разные типы шума — уличный, кухонный, шум пылесоса, телевизора, белый и розовый шум — и меняли уровень громкости голосовой команды. Даже в ситуациях, когда голос почти полностью заглушался, система сохраняла способность распознавать речь.
Лучший результат показала модель с тем самым attention-механизмом: она уверенно справлялась с задачей и в особенно шумных условиях, оставаясь при этом менее ресурсоёмкой, чем другие решения.
Статью с описанием нового подхода приняли на крупнейшую международную конференцию по речевым технологиям Interspeech, которая прошла в этом году в Нидерландах. На конференции также представили работы Microsoft, Google DeepMind, Google AR и других бигтехов.
Что дальше
В перспективе этот же механизм можно использовать для выбора наилучшего звукового канала при передаче аудио в облако — например, в системе автоматического распознавания речи (ASR). Это позволит повысить точность без увеличения нагрузки на сеть, поддерживая экономичность ресурсов при передаче данных. Проще говоря, даже с медленным интернетом получится распознавать голос почти в реальном времени.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.