Мы уже подробно рассказывали, как работает SQL — язык запросов к базе данных. Как и в языках программирования, в SQL есть типы данных. Они делают работу с таблицами удобнее, помогают лучше структурировать информацию и предотвращают ошибки.
SQL используют аналитики, дата-сайентисты, бизнес-аналитики и разработчики — в общем, все, кто работает с данными. Сегодня разберёмся, какие типы данных есть в SQL, как выбирать нужный тип под свои задачи и как правильно преобразовывать разные типы данных.
Для чего используются типы данных в SQL
SQL — язык запросов к базе данных. Название так и расшифровывается: «язык структурированных запросов» (Structured Query Language). В SQL запросы имеют чёткую структуру, а сам язык задаёт правила, по которым данные создаются, обновляются, читаются или удаляются. Это основные операции при работе с данными, и они обозначаются аббревиатурой CRUD (create, read, update, delete — создание, чтение, обновление и удаление).
В SQL есть разные типы данных: целые числа, текст, денежные величины, даты, время, двоичные файлы и многие другие. Типы данных помогают базе данных понять, как работать с информацией: на текст БД выделяет один объём памяти, на числа — другой и так далее. Используя подходящие типы данных, мы делаем систему более эффективной и помогаем SQL:
- Поддерживать структуру и порядок — данные упорядочены, а это упрощает их обработку.
- Оптимизировать производительность — SQL быстро выполняет операции, когда данные заранее отсортированы по типам.
- Снизить расход памяти — правильно подобранный тип данных помогает сократить объём занимаемой памяти.
Выбор правильного типа данных помогает разработчикам более внимательно относиться к работе с базой данных. Например, если колонка настроена как DATE, в ней можно хранить только значения даты. Если мы попытаемся вставить текстовые данные, это вызовет ошибку — и программист увидит, что он делает что-то не то, и исправит свой код.
Типы данных в SQL также определяют, какие операции с данными можно производить. Допустим, если в колонке указаны числа, SQL может выполнять с ними математические расчёты. Если это текст, SQL может отсортировать строки по алфавиту. А если в колонке даты, их можно фильтровать по времени.
⚠️ Не все типы данных поддерживаются разными базами. У каждой версии баз данных — MySQL, PostgreSQL, Oracle или SQL Server — есть свои особенности, и некоторые типы данных могут отсутствовать.
Мы рассмотрим основные типы, которые поддерживаются почти во всех популярных базах данных.
Классификация типов данных SQL и примеры их использования
Когда мы в SQL создаём таблицу, то для каждой колонки указываем тип данных — так БД понимает, какая информация будет в колонке и как с ней работать. Выглядит это, например, так:
CREATE TABLE employees (
employee_id INT, -- Числовой тип для уникального идентификатора
name VARCHAR(50), -- Строковый тип для имени
salary DECIMAL(10, 2), -- Числовой тип для зарплаты с точностью до сотых
hire_date DATE, -- Тип даты для даты приёма на работу
is_active BOOLEAN -- Логический тип для статуса активности
);Мы создали таблицу employees, где каждой колонке задали определённый тип данных. Теперь SQL будет знать, как хранить и обрабатывать информацию в каждом поле.
Типы данных делятся на основные категории: числовые, строковые, для работы с датой и временем, а также логические. Это предопределённые типы, но в некоторых БД можно задавать ещё и пользовательские типы (User-Defined Types, UDT) под специфические задачи.
Также есть и составные типы данных — это когда несколько полей можно объединить с разными типами данных в один общий блок. Такой тип данных позволяет хранить сразу несколько связанных значений в одной колонке таблицы.
Если говорить в целом, то все типы данных в SQL можно структурировать так:
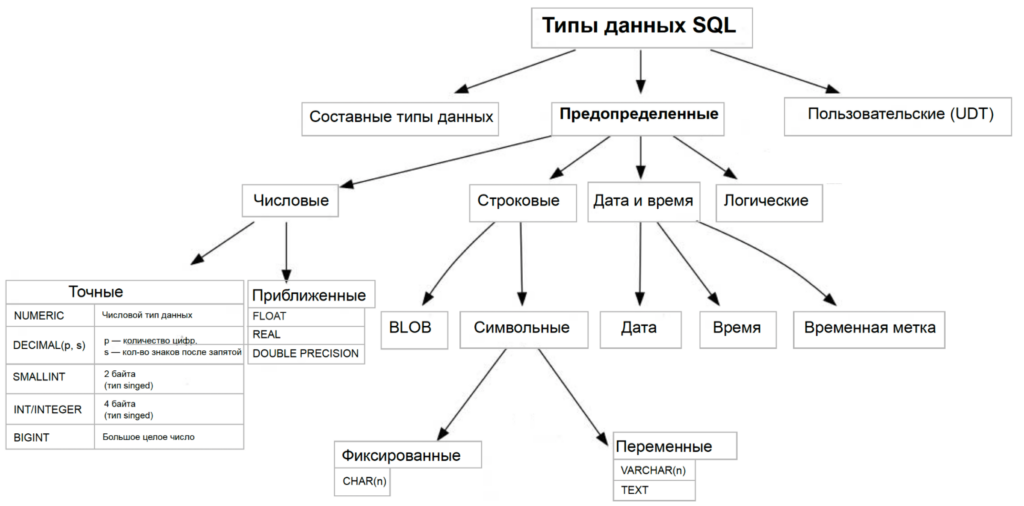
Дальше разберём подробно предопределённые типы в SQL — и начнём с числовых. Они делятся на точные и приближённые.
Точные числовые типы:
NUMERIC— для хранения чисел с фиксированной точностью, позволяет хранить числа с очень большим количеством цифр. Применяется в основном для финансовых данных, где важна точность и нельзя допустить ошибок в расчётах.DECIMALочень похож наNUMERIC, но позволяет задавать точность более гибко — можно указать, сколько цифр будет до и после запятой. Например,DECIMAL(10, 2)будет хранить точные значения с двумя знаками после запятой.TINYINTзанимает всего 1 байт и поддерживает значения от 0 до 255 (только положительные) или от –128 до 127 (положительные и отрицательные). Используется для хранения небольших чисел.SMALLINTзанимает меньше места и используется для небольших целых чисел, например для хранения статусов, категорий, возраста, количества товаров в заказе, когда числа не превышают диапазон от –32 768 до 32 767.INT/INTEGER— стандартный тип для целых чисел, используется для большинства числовых данных, например идентификаторов, счётчиков, количества чего-либо, цены в целых единицах. Подходит для значений, которые могут быть как положительными, так и отрицательными, и помещаются в диапазон от –2 147 483 648 до 2 147 483 647.BIGINTхранит очень большие целые числа, которые не помещаются вINT. Используется для хранения длинных идентификаторов — номеров транзакций или счётчиков на крупных платформах, где обычныйINTне справится.
Приближённые числовые типы хранят значения с плавающей точкой:
FLOATхранит дробные значения. Используется для научных расчётов, измерений, весов, температур, когда допустима погрешность.REALпохож наFLOAT, но более точный. Часто используется, когда нужно хранить небольшие дробные значения с чуть более высокой точностью, например данные лабораторных измерений.DOUBLE PRECISION— тип с двойной точностью, занимает больше памяти, но даёт более точное представление дробных значений. Используется, когда важна высокая точность — для расчётов в инженерии, физике и так далее.
Следующая категория — строковые типы данных. Они хранят текстовую информацию. В базе клиентов строковые типы данных будут использоваться для хранения имён и адресов, в интернет-магазинах — для описания товаров. Строковые типы делятся на символьные и бинарные.
Символьные типы данных нужны для хранения строк, состоящих из символов. Они в свою очередь делятся на фиксированные (CHAR) и переменные (VARCHAR), (TEXT):
CHARиспользуется, когда все значения в колонке имеют одинаковую длину. Например, если нужно хранить коды стран из трёх букв (RUS, KAZ),CHAR(3)будет занимать фиксированное количество места и сможет быстро обработать данные.VARCHARнужен, когда длина текста в колонке может сильно меняться. Например, для хранения имён пользователей, адресов или комментариев, где длина текста у каждого пользователя будет разной.VARCHARиспользует только необходимый объём памяти, поэтому данные не занимают лишнего, что экономит место в базе, особенно если текст короткий.TEXTиспользуется для хранения длинных текстов, у которых нет ограничения по длине, например для описаний товаров или отзывов.
Другой подвид строковых данных — бинарные типы. В SQL они нужны для хранения данных, которые представляют собой файлы — изображения, видео, аудио или зашифрованные данные. Эти типы данных похожи на текстовые, но SQL обрабатывает их как двоичные, не пытаясь интерпретировать как обычный текст.
Например, в системах документооборота для быстрого доступа часто нужно хранить файлы прямо в базе данных. Чтобы не хранить путь к файлу на сервере, файл записывается как двоичные данные в формате BLOB и прикрепляется к записям — к карточкам клиентов или заказов. Такой подход упрощает работу, поскольку не нужно создавать отдельное место для хранения файлов на сервере. Вся информация — и данные, и файлы — находится в одном месте. Становится проще делать резервные копии: достаточно создать один файл с копией базы данных, в котором сохранены все данные и файлы.
Следующая категория типов данных в SQL — типы для работы с датой и временем:
- Дата (
DATE) хранит только дату, без времени. Формат ГГГГ-ММ-ДД. Подходит для хранения дней рождения, дат регистрации и других событий, где точное время не требуется. - Время (
TIME) хранит только время без указания даты. Формат ЧЧ:ММ:СС. Используется для хранения начала времени или окончания события, рабочего времени и так далее. - Временная метка (
TIMESTAMP) хранит и дату, и время вместе. Формат ГГГГ-ММ-ДД ЧЧ:ММ:СС. Подходит для отслеживания точных временных меток — времени создания записи, времени входа пользователя или обновления данных.
И наконец, логический тип данных — BOOLEAN. Может принимать значения 1 для TRUE и 0 для FALSE. Используется для хранения значений, где возможны только два варианта: «да» или «нет». Например, BOOLEAN можно использовать, чтобы указать, подтверждён ли аккаунт пользователя или активен ли он сейчас.








Хранение типов данных SQL
Мы рассмотрели самые базовые типы — на самом деле их намного больше, и в разных БД могут быть свои уникальные типы. Дальше посмотрим, как разные типы данных хранятся в памяти и что с этим делать.
Разные типы данных занимают разное количество памяти. Чем больше данных сохраняется, тем больше места они занимают и тем медленнее работает база (но не всегда). Поэтому важно правильно подбирать типы данных для каждого столбца, чтобы всё работало быстро, а память не расходовалась зря.
Допустим, мы создаём таблицу для хранения информации о пользователях, где указываем их возраст. Возраст — это число, и в SQL можно выбрать разные числовые типы данных: TINYINT, SMALLINT, INT или BIGINT.
Что выбрать? INT — общий числовой тип данных с большим диапазоном, он занимает 4 байта. А тип TINYINT занимает всего 1 байт памяти и может хранить значения в диапазоне от 0 до 255. Возраст человека пока не может превышать 255, поэтому TINYINT будет более чем достаточно:
CREATE TABLE users (
age TINYINT -- Возраст пользователя, тип TINYINT
);В этом коде мы создали таблицу users и присвоили колонке age тип данных TINYINT. Если бы мы использовали INT, то каждая запись в таблице занимала бы лишние 3 байта. На первый взгляд немного, но в больших таблицах с миллионами пользователей это приведёт к потерям памяти. Таблица с миллионом записей будет тратить на хранение возраста 4 МБ вместо 1 МБ.
Дальше в нашей таблице создадим другую колонку, где будем хранить уникальные идентификаторы для каждой записи. Записей может быть очень много, и для идентификаторов лучше выбрать тип INT, поскольку его диапазон позволяет создать миллионы уникальных записей.
CREATE TABLE users (
user_id INT PRIMARY KEY, -- Уникальный идентификатор, тип INT
age TINYINT -- Возраст пользователя, тип TINYINT
);В реальной таблице, которая создаётся после выполнения SQL-кода, пользователь не видит типы данных напрямую. Если мы откроем таблицу, то увидим только значения в каждой ячейке — текст, числа, даты. Типы данных работают под капотом базы данных и определяют, как данные будут обрабатываться и сколько памяти займут.
Как преобразовать типы данных в SQL
В SQL можно преобразовывать данные из одного типа в другой. Это полезно, когда нужно использовать данные из разных таблиц: в одной таблице данные могут быть представлены как числа, а в другой — как текст. Чтобы нормально со всем этим работать, нужно привести их к одному типу.
Есть явное и неявное приведение типов, как и в языках программирования.
Явное приведение — это когда мы сами указываем, что хотим изменить тип данных. Для этого в SQL есть две функции: CAST() и CONVERT(). Они работают плюс-минус одинаково, но CAST() поддерживается всеми СУБД, а CONVERT() специфична для SQL Server.
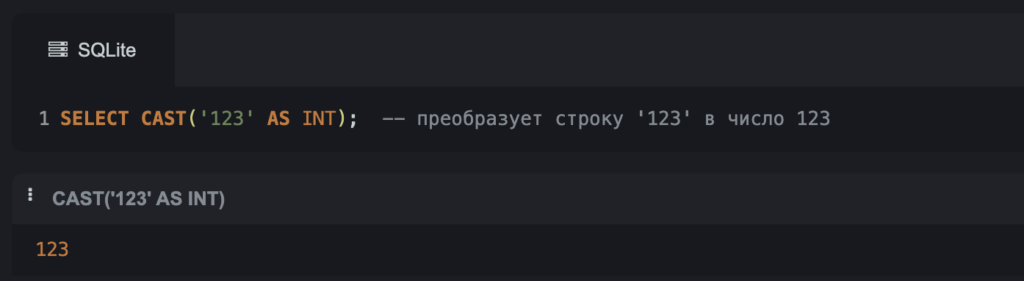
Преобразуем строку в число:
SELECT CAST('123' AS INT); -- преобразует строку '123' в число 123
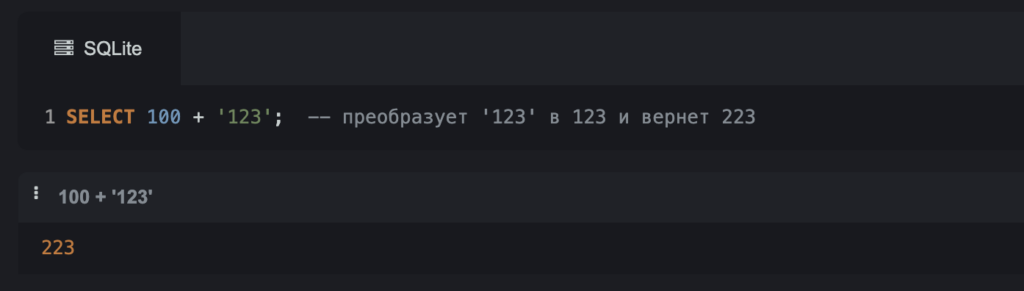
Неявное приведение — это когда SQL сам пытается преобразовать типы данных, если это возможно. Если мы складываем число и текст «123», SQL автоматически преобразует «123» в число:
SELECT 100 + '123'; -- преобразует '123' в 123 и вернёт 223
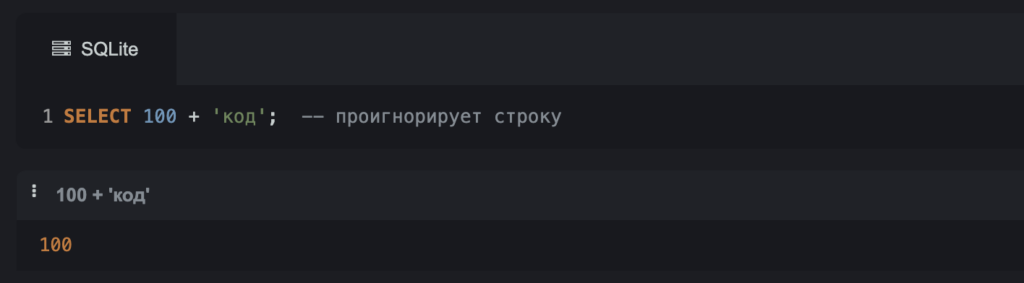
Если SQL не сможет сделать неявное приведение, то выдаст ошибку или просто проигнорирует какую-то часть данных. Если мы захотим сложить текст и число, то получим только число — строка на выходе потеряется:
SELECT 100 + 'код'; -- проигнорирует строку
Как и в других языках программирования, с преобразованием типов нужно быть осторожным. Например, при попытке преобразовать число с плавающей точкой в целое дробная часть будет отброшена. Это может повлиять на вычисления, где важна точность:
SELECT CAST(345.54 AS INT); -- вернёт 345 без дробной части

А зачем всё это знать?
Современная разработка очень редко обходится без баз данных. Если мы берём какие-то простые веб-проекты или пишем несложный код на Python, то можно и без них. Или если программируем микропроцессоры, настраиваем внешний вид сайта с помощью CSS и решаем алгоритмические задачки с собеседований — тогда да, можно обойтись без знаний SQL.
Но если взять что-то немного более сложное, то без SQL уже не получится: пользовательские данные нужно где-то хранить, и лучше это делать не в текстовом файлике, а использовать специальный инструмент для работы с данными.