


Иногда в Ютубе, Твитере или на любой другой крупной площадке можно заметить странное поведение счётчиков: цифры просмотров или лайков сначала увеличиваются, а потом внезапно уменьшаются — как будто кто-то развидел видео, разлайкал пост и взял свой репост обратно.
Это побочный эффект работы базы данных со множеством распределённых запросов. Это интересная штука, которую стоит разобрать, чтобы понимать устройство больших интернетных систем.
Это краткий конспект видео Тома Скотта про то, почему счётчики в интернете работают именно так. Если вы знаете английский, посмотрите оригинал, а если нет — читайте статью, все основные мысли здесь тоже есть.
Однопоточная обработка: всё просто, компьютер справляется сам
Самая простая модель обработки данных — последовательная, или однопоточная. Есть некая очередь команд, процессор их по очереди выполняет.
Чуть более сложная модель — когда в процессоре несколько ядер. Тогда некий диспетчер раздаёт разные задания разным ядрам, каждое считает свои задания, отдаёт результаты, и их потом собирают воедино. Для каждого ядра это выглядит как однопоточная обработка, а считают ядра каждое своё, не пересекаясь.
Но всё меняется, когда один компьютер начинает отвечать за обработку нескольких запросов на одни и те же данные сразу от нескольких пользователей.

Отступление про базу данных
Технически большинство популярных сервисов в интернете — это просто большие базы данных с приятным интерфейсом. Ютуб — база данных видео, комментариев и лайков. Телеграм — база данных сообщений, файлов и реакций.
Задача каждой базы данных — вовремя и правильно обработать поступивший запрос и перейти к следующему. При этом база всегда следит, чтобы выполнение запроса не сломало всю внутреннюю систему, поэтому она всегда перестраховывается и не всегда может моментально отреагировать.
Получается, что смысл всех глобальных сервисов — отреагировать на запрос пользователя и показать результат своей работы. Эта мысль нам скоро понадобится.
Многопоточная обработка: всё сложно
Как только у компьютера появляется задача из серии «обработать запросы тысяч пользователей в секунду», то всё становится гораздо сложнее. Запросов так много, что база данных не успевает их обработать, поэтому и часть запросов попросту теряется:

Очевидное решение — подключить больше компьютеров, чтобы они тоже могли брать часть запросов и отрабатывать их. Получается, что с этого момента нам нужен второй компьютер, чтобы он помог первому всё обработать. Потом появляется третий, четвёртый, и в итоге, если нашим сервисом пользуется миллиард человек, то таких компьютеров может быть несколько сотен, а то и тысяч.
Проблема в том, что база данных сайта всё равно должна быть одна, даже если за неё отвечают много компьютеров. А время обработки каждого запроса — ненулевое. Пока один компьютер выполняет свою операцию с ячейкой базы данных, другой компьютер тоже может начать работать с этой ячейкой. И тогда случится конфликт:

Что тут происходит:
- Тысяча пользователей одновременно ставят лайк. На схеме мы рассматриваем два лайка из тысячи.
- Система начинает распределять запросы между разными компьютерами, чтобы обработать их как можно быстрее.
- Один компьютер берёт из базы текущее число лайков (17), увеличивает на единицу и кладёт новое значение обратно.
- Пока первый делает свою работу, второй компьютер параллельно начинает делать свою. Он берёт старое число лайков (нового же ещё нет), тоже добавляет единицу, кладёт на место.
- В итоге в ячейке «Всего лайков» лежит 18 лайков, а не 19. Один из лайков пропал.
 Делаем свой таймер на Python
Делаем свой таймер на Python Python: как сделать многопоточную программу
Python: как сделать многопоточную программу Асинхронное программирование в Python — что это, как устроено и где применяется
Асинхронное программирование в Python — что это, как устроено и где применяется Асинхронный код на Python: синтаксис и особенности
Асинхронный код на Python: синтаксис и особенности Прокачиваем асинхронное программирование на Python: используем контекстный менеджер
Прокачиваем асинхронное программирование на Python: используем контекстный менеджер Как устроена память в Python
Как устроена память в PythonДобавляем кэширующие серверы
Видно, что в предыдущей схеме есть проблема: система хоть и обрабатывает все запросы, но делает это криво и часть данных теряется. Чтобы такого не случалось, придумали кэширующие серверы. Что это такое:
- Кэширующий сервер — это прослойка между пользователем и центральным сервером.
- Пользователи подключаются не к центральному серверу напрямую, а к одному из кэшей — а их может быть и сто, и тысяча.
- В кэше хранится какая-то версия базы данных, с которой работает пользователь. Версия в кэше не знает о других версиях базы на других кэшах.
- Раз в несколько секунд кэши резюмируют всю свою активность и отправляют отчёт на центральный сервер. Например, «За последние 2 секунды я получил столько-то лайков этому видео, столько-то — тому, столько-то — третьему».
- На центральном сервере все запросы от кэшей обрабатываются и суммируются в центральной базе данных.
- Центральный сервер отправляет кэшам свежую версию базы данных.
Получается, что центральный сервер работает не с миллиардами запросов пользователей, а с несколькими тысячами запросов от кэширующих серверов. Такие запросы обработать гораздо проще.
А у кэшей, получается, ведётся временная «двойная бухгалтерия». Они собирают свой вариант базы данных, отправляют его в главную базу, а та уже всё сопоставляет и сверяет в своём темпе.
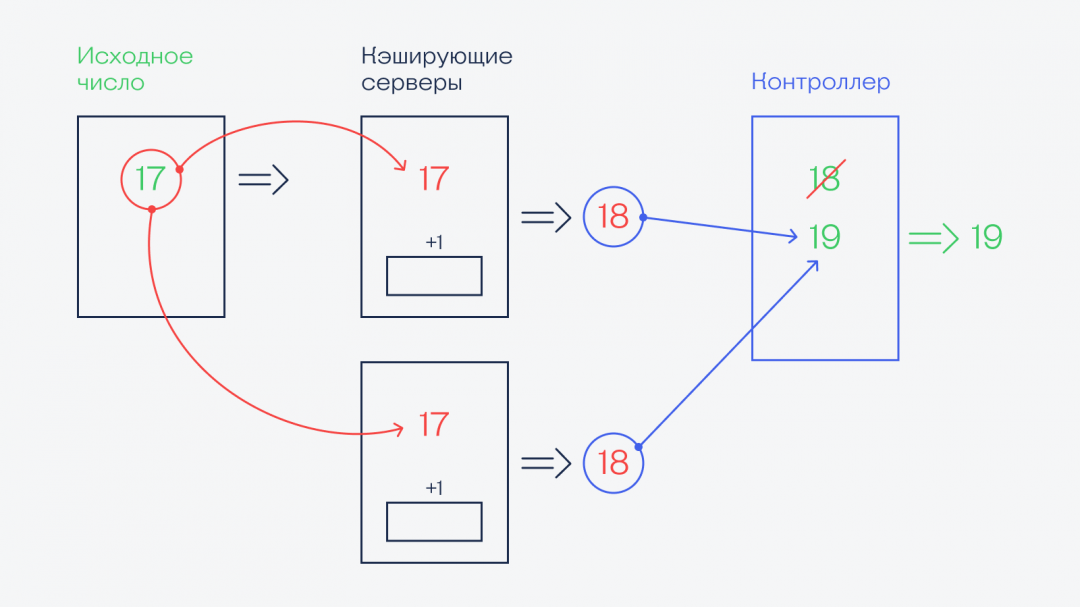
Как исчезают лайки
Это то, как цифры скачут вперёд, но как они могут откатиться обратно? Если не брать в расчёт то, что кто-то снимет свой лайк (система это легко отработает), то механизм устроен так:
- При общих нагрузках на систему компьютеры могут начать сами подстраховываться и сами добавлять единицу к числу лайков из базы, а потом прибавлять ещё одну. Это делается для ускорения обработки — если ситуацию можно предусмотреть (что в базе уже неактуальное старое число) и не делать лишнюю работу, то компьютер так и сделает.
- Некоторое время спустя система перепроверяет все запросы, которые были сделаны, и замечает внутреннюю накрутку счётчика.
- Как только очередной цикл проверки закончился, система обновляет цифры на счётчике, убирает лишние единицы (добавленные для скорости), и мы видим, как счётчик внезапно теряет несколько лайков.
Когда наступает стабильность
Если обратить внимание, то можно заметить, что такая ситуация бывает только с новыми или очень популярными прямо сейчас сообщениями (или видео). На старых роликах, твитах и сообщениях всё стабильно. Так происходит потому, что старые ролики перестают быть такими популярными, к ним поступает гораздо меньше запросов, и база может обрабатывать их в штатном режиме.
Но когда они снова вдруг становятся популярными, цифры снова начинают скакать. Зато теперь вы знаете, как это работает.











