


AI-инструменты уже вошли в обычную разработку: локально поднять модель, проверить промпт, подключить инференс к приложению, дать агенту доступ к коду и файловой системе. В подборке собраны репозитории, которые решают такие задачи без лишней обвязки и подходят для рабочего стека.
В этой подборке инструменты распределены по назначению: от нижнего слоя, где модель запускается и отдаёт ответы, до прикладного слоя, где разработчик работает с кодом, документами, речью, изображениями и автоматизацией.
AI-инструменты удобнее разбирать по слоям стека. Сначала идёт среда, где модель запускается и отдаёт ответы. Потом фреймворки и библиотеки, через которые модель обучают, дообучают или встраивают в приложение. Выше появляются агенты, автоматизации, поиск по документам, терминальные помощники и инструменты для речи, изображений и видео.
Мы подготовили таблицу: по ней видно, какой инструмент брать под конкретную задачу и в какой раздел идти дальше.
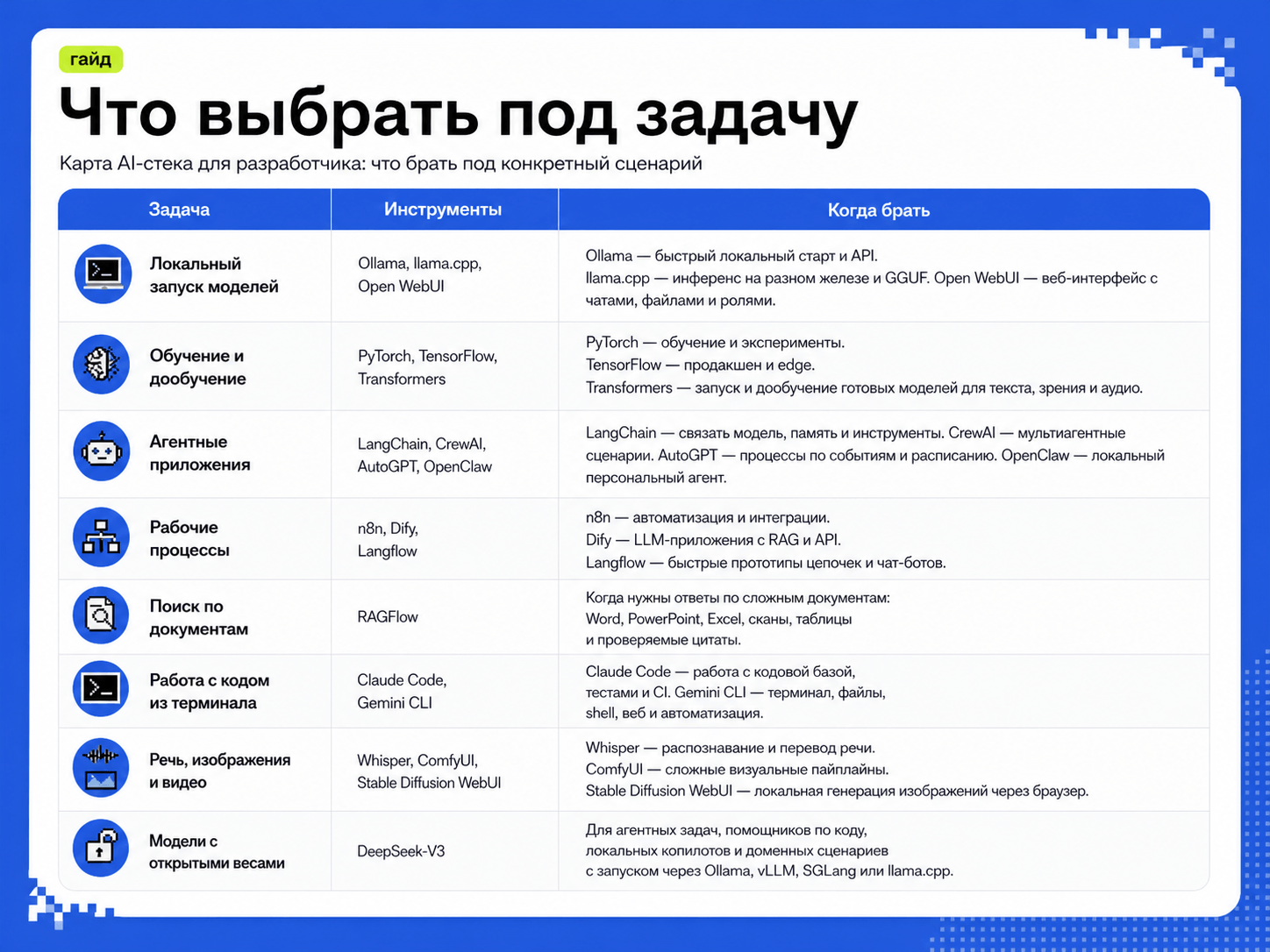
Локальный запуск моделей и интерфейс к ним
Этот блок про базовый слой: где модель живёт, как запускается и через что с ней работать. Ollama даёт быстрый локальный запуск моделей и API на localhost:11434. llama.cpp нужен для инференса на разном железе, работы с GGUF и квантизацией. Open WebUI добавляет веб-интерфейс поверх локальных и облачных моделей: чаты, файлы, поиск по документам, роли и журнал действий.
1. Ollama
https://github.com/openclaw/openclaw
Задача: Ollama нужен, когда языковую модель надо запустить локально: для проверки запросов, прототипа приложения, внутреннего помощника или сервиса, который обращается к модели с вашей машины.
Инструмент написан на Go и работает как среда запуска для моделей с открытыми весами. В списке поддерживаемых моделей указаны Llama 4, Gemma 3 и 4, Qwen 3, DeepSeek, Mistral, gpt-oss, GLM, Kimi K2.5 и MiniMax. Ollama даёт командную строку, программный интерфейс на localhost:11434, совместимые с OpenAI точки доступа и настольные приложения для macOS и Windows.
Как работает: Ollama скачивает модель, хранит её локально и поднимает сервер для обращений из приложения. Это удобно для локальной разработки LLM-приложений, приватного запуска моделей, серверов с GPU и пограничных агентов. В рабочих стеках Ollama используют как серверную часть для Open WebUI, LangChain, OpenClaw, Continue, Cline и Codex.
Команда установки:
На Windows откройте PowerShell и выполните:
irm https://ollama.com/install.ps1 | iexНа Linux и macOS выполните в терминале:
curl -fsSL https://ollama.com/install.sh | shНа некоторых Linux-дистрибутивах могут понадобиться curl и zstd. На Debian и Ubuntu их можно поставить так:
sudo apt update && sudo apt install curl zstdПроверьте, что командная строка Ollama установлена:
ollama -vСервис Ollama должен подняться в фоне на порту 11434. Если команда проверки показывает предупреждение, запустите сервис вручную:
ollama serveПосле этого можно скачать и запустить первую модель:
ollama pull <model>
ollama run <model>2. llama.cpp
https://github.com/ggml-org/llama.cpp
Задача: llama.cpp нужен, когда модель нужно запустить локально с минимальной обвязкой и нормальной скоростью на разном железе: Apple Silicon, x86, RISC-V, NVIDIA, AMD, Intel, Vulkan, OpenCL и других бэкендах. Проект написан на C и C++ и рассчитан на инференс языковых моделей с небольшим количеством зависимостей.
Как работает: llama.cpp запускает модели в формате GGUF. Модель можно скачать вручную или запустить совместимую модель прямо с Hugging Face через аргумент -hf. Для разработки есть два основных режима: llama-cli для локальных экспериментов и llama-server для HTTP-сервера с OpenAI-совместимым API.
Проект поддерживает квантизацию 1.5-bit, 2-bit, 3-bit, 4-bit, 5-bit, 6-bit и 8-bit. Это снижает потребление памяти и ускоряет инференс. Ещё есть гибридный режим CPU+GPU, когда модель больше доступной видеопамяти и часть вычислений уходит на процессор.
В проекте также есть локальный сервер llama-server на порту 8080. Этого достаточно, чтобы использовать модель как отдельный сервис в локальном окружении.
Команда установки:
llama.cpp можно поставить несколькими способами: через brew, nix или winget, запустить через Docker, скачать готовую сборку со страницы релизов или собрать из исходников. После установки нужна модель в формате GGUF. Её можно скачать вручную или запустить совместимую модель прямо с Hugging Face через аргумент -hf.
Запуск локального файла модели:
llama-cli -m my_model.ggufЗапуск модели напрямую с Hugging Face:
llama-cli -hf ggml-org/gemma-3-1b-it-GGUFЗапуск сервера с OpenAI-совместимым API:
llama-server -hf ggml-org/gemma-3-1b-it-GGUFЗапуск локального HTTP-сервера на порту 8080 с моделью из файла:
llama-server -m model.gguf --port 8080После этого веб-интерфейс будет доступен по адресу:
http://localhost:8080
Точка доступа для chat completions:
http://localhost:8080/v1/chat/completions
3. Open WebUI
https://github.com/open-webui/open-webui
Задача: Open WebUI нужен, когда локальную или облачную модель надо дать в работу через нормальный веб-интерфейс: с чатами, файлами, поиском по документам, ролями, единым входом и журналом действий.
Это самостоятельная оболочка в стиле ChatGPT для локальных и облачных языковых моделей. Проект начинался как Ollama WebUI в октябре 2023 года, а в январе 2024 года получил название Open WebUI. Он поддерживает Ollama, совместимые с OpenAI программные интерфейсы, Anthropic, Gemini, Mistral, DeepSeek и Groq. Для подключения внешних инструментов используется MCP через Streamable HTTP.
Как работает: Open WebUI ставится поверх уже выбранной модели или поставщика моделей. Внутри есть встроенный движок для поиска по документам, голосовые и видеозвонки с Whisper и синтезом речи, конструктор пользовательских агентов, вызов функций на Python, постоянное хранилище артефактов, единый вход, роли и журнал аудита.
Для команды это удобная рабочая точка поверх локального стека. Можно подключить Ollama, добавить документы, настроить доступы и получить интерфейс, с которым работают не через командную строку.
Команда установки:
Быстрее всего поднять Open WebUI через Docker. Если Ollama уже стоит на вашем компьютере, выполните:
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:mainПосле запуска интерфейс откроется в браузере:
http://localhost:3000
Флаг -v open-webui:/app/backend/data лучше не убирать: он монтирует базу данных и сохраняет данные Open WebUI между перезапусками контейнера.
Модели и фреймворки для обучения и инференса
Этот блок про модельный слой. DeepSeek-V3 — сама модель с открытыми весами, которую можно запускать через Ollama, vLLM, SGLang, llama.cpp или дообучать под задачу. PyTorch и TensorFlow нужны для обучения, экспериментов и промышленного развёртывания моделей. Hugging Face Transformers закрывает запуск и дообучение предобученных моделей для текста, зрения, аудио и мультимодальных задач.
4. DeepSeek-V3
https://github.com/deepseek-ai/deepseek-v3
Задача: DeepSeek-V3 нужен как модель с открытыми весами для агентных сценариев, помощников по коду, локальных копилотов и задач, где нужны рассуждение и генерация кода.
Как работает: DeepSeek-V3 поддерживает контекст 128K токенов. Веса лежат на Hugging Face и ModelScope. Лицензия указана как MIT с дополнительными условиями для коммерческого использования некоторых весов. Модель можно запускать локально через Ollama, vLLM, SGLang, llama.cpp или дообучать под домен.
В рабочих сценариях DeepSeek-V3 используют для агентных задач, кодинг-помощников через Cline, Continue и Aider, а также локальных копилотов для регулируемых отраслей.
Команда установки: сначала склонируйте репозиторий DeepSeek-V3:
git clone https://github.com/deepseek-ai/DeepSeek-V3.gitДля локального запуска используйте SGLang. В README DeepSeek-V3 нет одной универсальной команды установки SGLang, поэтому команду запуска нужно брать из инструкции команды SGLang для DeepSeek-V3:
https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3Если нужен демонстрационный запуск из самого репозитория DeepSeek, он работает только на Linux с Python 3.10. Перейдите в папку inference и поставьте зависимости:
cd DeepSeek-V3/inference
pip install -r requirements.txt5. PyTorch
https://github.com/pytorch/pytorch
Задача: PyTorch нужен для обучения нейросетей, экспериментов с моделями, прототипирования, исследовательских задач и перехода к продакшену через инструменты экосистемы.
Это фреймворк глубокого обучения с динамическими графами и GPU-ускорением. Он использует tape-based reverse-mode auto-differentiation. Проект находится под PyTorch Foundation в Linux Foundation, его поддерживают Meta, Nvidia, AMD, Intel и Microsoft.
Как работает: PyTorch используют для тренировки LLM и VLM, рекомендательных систем, reinforcement learning через TorchRL, научных исследований и перехода от прототипа к продакшену через TorchScript и ExecuTorch. В экосистеме также указаны Lightning, vLLM, Hugging Face и TorchTitan для распределённого предварительного обучения.
В PyTorch есть torch.compile и Inductor для ускорения вычислений на GPU, LocalTensor и LocalTensorMode для локальной симуляции distributed-вычислений, FlexAttention с CPU-backend через TorchInductor C++ template, а также проверка контрактов пользовательских операций через torch.library.opcheck.
Команда установки: PyTorch лучше ставить готовым пакетом через pip или Conda. Команду нужно выбрать в официальном селекторе под свою систему, версию Python и тип ускорения:
https://pytorch.org/get-started/locally/Если нужен запуск в Docker с GPU, в README есть готовая команда:
docker run --gpus all --rm -ti --ipc=host pytorch/pytorch:latestФлаг –ipc=host нужен из-за общей памяти: PyTorch использует её при работе с несколькими процессами, например в загрузчиках данных.
Полезный блок со скидкой
Найти репозиторий легко. Сложнее понять, что с ним делать дальше: как поднять модель локально, подключить API, собрать RAG, настроить агента, автоматизировать процесс и не превратить проект в папку с двадцатью недописанными демками.
Если хотите разбираться в ИИ-инструментах на уровне рабочих проектов, а не просто сохранять ссылки на GitHub, посмотрите курсы по нейросетям от Яндекс Практикума. Там разбирают, как работать с нейросетями в задачах, которые ближе к продакшену: от промптов и автоматизации до ботов и ИИ-сервисов.
Держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
6. TensorFlow
https://github.com/tensorflow/tensorflow
Задача: TensorFlow нужен для обучения, сборки и промышленного развёртывания нейросетевых моделей. Его используют там, где важны устойчивый продакшен-пайплайн, серверная выдача моделей, мобильный и пограничный инференс.
Это end-to-end ML-фреймворк от Google. Он работает через статический граф с режимом eager execution, даёт стабильные Python и C++ API и имеет несколько языковых привязок.
Как работает: в экосистеме TensorFlow есть TF Serving для выдачи моделей, TFX для пайплайнов, TF Lite и LiteRT для мобильных и пограничных устройств, распределённое обучение и экспорт в SavedModel. В рабочих сценариях его используют для инференса на edge и мобильных устройствах через LiteRT, рекомендательных систем через TF Recommenders, классических CV и NLP-пайплайнов, исследовательских нейросетей с TPU.
Команда установки: поставьте текущий релиз TensorFlow:
pip install tensorflowЕсли нужен меньший пакет только для CPU, используйте:
pip install tensorflow-cpuОбновить TensorFlow до последней версии можно так:
pip install --upgrade tensorflow7. Hugging Face Transformers
https://github.com/huggingface/transformers
Задача: Hugging Face Transformers нужен, когда нужно запустить, дообучить или встроить предобученную модель для текста, зрения, аудио или мультимодальных задач.
Это Python-библиотека для работы с предобученными моделями. Она даёт единое описание архитектур и интеграцию с PyTorch. В проверенных данных указаны требования: PyTorch не ниже 2.4 и Python не ниже 3.10.
Как работает: в Transformers есть Pipeline для упрощённого инференса в NLP, компьютерном зрении и аудио, Trainer для обучения с mixed precision, torch.compile, FlashAttention и распределённым режимом, а также generate для потоковой генерации и разных стратегий декодирования.
Библиотеку используют для дообучения LLM, эмбеддингов в RAG через sentence-transformers/all-MiniLM-L6-v2, продакшен-инференса через Trainer и Accelerate, локального запуска Whisper, DINOv3 и Gemma 4. В списке моделей указаны BERT, GPT-family, Llama, Qwen, Mistral, Gemma, Whisper, Vision Transformers и DETR.
Команда установки: сначала создайте виртуальное окружение:
python -m venv .my-env
source .my-env/bin/activateЕсли используете uv, окружение можно создать так:
uv venv .my-env
source .my-env/bin/activateУстановите Transformers с поддержкой PyTorch:
pip install "transformers[torch]"Для uv команда такая:
uv pip install "transformers[torch]"Агентные фреймворки и персональные агенты
Этот блок про приложения, где модель получает инструменты, память, роли, задачи и сценарии выполнения. LangChain связывает модель с поиском, памятью, инструментами и агентной логикой. CrewAI раскладывает задачу между несколькими агентами. AutoGPT подходит для непрерывных процессов с событиями и расписанием. OpenClaw работает как локальный персональный агент с каналами сообщений, браузером, файлами, cron и командной строкой.
Если нужен не список фреймворков, а сама логика агентной архитектуры, начните с пошагового разбора: как выбрать задачу, тип агента и стек.
8. LangChain
https://github.com/langchain-ai/langchain
Задача: LangChain нужен, когда приложение должно не просто отправить запрос в модель, а связать модель с инструментами, памятью, поиском, извлечением данных и агентной логикой.
Это Python-фреймворк для LLM-приложений и агентов. Он даёт модульные компоненты: цепочки, агенты, память, извлекатели, работу с инструментами и мультиагентную оркестрацию. В экосистему также входят LangGraph для графов состояний, LangSmith для наблюдаемости, оценки и развёртывания, Deep Agents для планирования и подагентов.
Как работает: LangChain используют как связующий слой между моделью и приложением. Через него собирают RAG-пайплайны с цитированием, агентов с вызовом инструментов, извлечение структурированных данных и диалоговые интерфейсы. Поверх LangChain построены Langflow, Dify, AI-узлы n8n, ChatGPT-plugins и корпоративные помощники.
В 2026 году в LangChain появились create_agent с middleware, init_chat_model с метаданными для LangSmith, поддержка подключаемой песочницы в deepagents и Responses API как стандартный вариант для OpenAI в deepagents.
Команда установки: LangChain ставится как обычный Python-пакет:
pip install langchain9. CrewAI
https://github.com/crewaiinc/crewai
Задача: CrewAI нужен для мультиагентных сценариев, где задачу удобнее разложить между несколькими агентами с разными ролями, целями и инструментами.
Это Python-фреймворк для оркестрации мультиагентных систем. Он построен с нуля и не зависит от LangChain. Базовая метафора простая: агенты работают как участники команды, у каждого есть role, goal, backstory и tools. В CrewAI есть две основные абстракции: Crews для автономной совместной работы агентов и Flows для событийной оркестрации с точным управлением вызовами модели.
Как работает: CrewAI подходит для исследовательских цепочек, анализа, контентных пайплайнов, lead-scoring с участием человека, автоответов на письма и сценариев с несколькими специализированными агентами. В проекте есть поддержка e2b и Daytona sandbox tools, AWS Bedrock V4, checkpoint forking с lineage tracking, учёт reasoning tokens и cache creation tokens, а также нативная поддержка MCP и A2A communication.
В обычной разработке CrewAI закрывает задачи, где один агент быстро превращается в слишком большой комбайн: один собирает данные, второй проверяет, третий оформляет результат или вызывает нужный инструмент.
Команда установки: перед установкой проверьте Python: CrewAI требует версию от 3.10 до 3.14.
Базовая установка:
uv pip install crewaiЕсли нужны дополнительные инструменты для агентов, ставьте расширенный вариант:
uv pip install 'crewai[tools]'Создать новый проект можно командой:
crewai create crew <project_name>CrewAI создаст папку проекта с pyproject.toml, .env, main.py, crew.py, agents.yaml и tasks.yaml. В этих файлах описываются агенты, задачи, инструменты и точка входа проекта.
Перед запуском нужно добавить ключи в .env: ключ модели, например OPENAI_API_KEY, и ключ Serper.dev, если в проекте используется SerperDevTool.
Запуск из корня проекта:
crewai run
10. AutoGPT
https://github.com/significant-gravitas/autogpt
Задача: AutoGPT нужен для непрерывных агентных процессов: когда агент должен реагировать на события, запускаться по расписанию, выполнять цепочку действий и работать как сервис. Проект вырос из экспериментального автономного агента, который запускал языковые модели по циклу мысль, действие, наблюдение. В 2024–2026 годах его полностью переписали в платформу для построения и эксплуатации ИИ-агентов.
В AutoGPT есть визуальный конструктор, маркетплейс, кредитная система биллинга и более 30 интеграций. Его используют для бизнес-автоматизации, где не хочется писать отдельный бэкенд под каждую связку действий.
Как работает: серверная часть написана на Python и FastAPI. Граф агента хранится в FalkorDB. Основная единица работы называется блоком: это составная функция с типизированными входами и выходами. Блоки могут публиковаться как инструменты MCP.
AutoGPT умеет запускаться от событий и расписания. В подготовленных данных указаны webhook-триггеры для GitHub push, Slack message и HTTP POST, а также cron-планировщик. За счёт этого агент можно использовать как долгоживущий процесс для цепочек вроде автотранскрипции видео, поиска трендов, агентных ETL-пайплайнов и контентных процессов.
Команда запуска: для локального запуска AutoGPT нужен Docker, Git, npm и редактор кода. В README указаны минимальные требования: Docker Engine 20.10.0+, Docker Compose 2.0.0+, Git 2.30+, Node.js 16.x+, npm 8.x+. Поддерживаются Linux, macOS и Windows 10/11 через WSL2.
На macOS и Linux выполните:
curl -fsSL https://setup.agpt.co/install.sh -o install.sh && bash install.shНа Windows откройте PowerShell и выполните:
powershell -c "iwr https://setup.agpt.co/install.bat -o install.bat; ./install.bat"Скрипт установит зависимости, настроит Docker и запустит локальный экземпляр AutoGPT.
11. OpenClaw
https://github.com/openclaw/openclaw
Задача: OpenClaw нужен для локального персонального агента, который работает с сообщениями, файлами, браузером, командной строкой и задачами по расписанию. Его можно использовать как рабочий инструмент для автоматизации почты, счетов, задач GitHub, веб-скрейпинга и DevOps-скриптов на своей машине.
Как работает: архитектура делится на три слоя. Первый отвечает за каналы: WhatsApp, Telegram, Slack, Discord, Signal, BlueBubbles iMessage, Microsoft Teams, Matrix, Feishu, LINE, Mattermost, WeChat, QQ и другие. Второй слой работает с моделями: Claude, GPT-5.x, Gemini и локальными моделями через Ollama. Третий слой отвечает за инструменты: автоматизацию браузера, canvas, узлы, cron, действия в Discord и Slack, файловую систему и командную строку.
Gateway работает как локальный сервис: через systemd на Linux и LaunchAgent на macOS. По умолчанию он слушает ws://127.0.0.1:18789. Конфигурация и память хранятся в обычных файлах на диске, поэтому состояние агента можно проверять и переносить между окружениями.
Команда установки: OpenClaw требует Node 24 или Node 22.14+. Рекомендуемый вариант установки:
npm install -g openclaw@latestПосле установки запустите мастер настройки:
openclaw onboard --install-daemonЭта команда настраивает OpenClaw и устанавливает Gateway daemon: на macOS через launchd, на Linux через пользовательский systemd-сервис. На Windows рекомендуемый путь — через WSL2.
Визуальная сборка приложений и автоматизация процессов
Этот блок про инструменты, где приложение или процесс собираются через визуальную схему. n8n связывает сервисы, кодовые вставки, расписания и модели. Dify помогает собрать LLM-приложение с RAG, агентной логикой, управлением моделями и API. Langflow подходит для прототипов RAG-чатботов, цепочек и агентных схем на базе LangChain.
12. n8n
Задача: n8n нужен для автоматизации рабочих процессов: связать сервисы, добавить ветвление, вызвать модель, обработать данные, отправить результат дальше. Его удобно держать в стеке, когда задача уже выросла из одного скрипта, но отдельный сервис под неё писать рано.
Платформа распространяется по fair-code модели под Sustainable Use License. Внутри есть визуальный редактор узлов, возможность вставлять JavaScript и Python-код, поддержка 400+/500+ интеграций и ИИ-узлы на базе LangChain. Проект написан на TypeScript.
Как работает: в n8n рабочий процесс собирается из узлов. Часть действий можно настроить в интерфейсе, часть дописать кодом. В ИИ-сценариях доступны более 70 встроенных ИИ-узлов, интеграция с LangChain, агенты с памятью и инструментами, RAG, поддержка MCP и возможность отдать рабочий процесс наружу как MCP-сервер.
Для рабочих окружений важны вещи вокруг выполнения: защита от SSRF, внешние секреты через 1Password и Vault, события аудита при раскрытии данных выполнения, самовосстановление Schedule node, OIDC через переменные окружения и сервис управления ключами для шифрования.
Команда установки: для запуска через Docker сначала создайте volume для данных n8n:
docker volume create n8n_dataЗатем запустите контейнер:
docker run -it --rm --name n8n \
-p 5678:5678 \
-v n8n_data:/home/node/.n8n \
docker.n8n.io/n8nio/n8nПосле запуска редактор будет доступен в браузере:
http://localhost:5678Если нужно просто быстро посмотреть интерфейс без отдельной настройки Docker, можно запустить через npx:
npx n8n13. Dify
https://github.com/langgenius/dify
Задача: Dify нужен, когда нужно собрать LLM-приложение с визуальной схемой, поиском по базе знаний, агентной логикой, управлением моделями и программным интерфейсом для подключения к существующему сервису.
Платформа написана на TypeScript и Python. Она работает с OpenAI, Anthropic, Gemini, Llama, Ollama и другими поставщиками моделей. Внутри есть визуальный конструктор рабочих процессов, RAG-пайплайн, агентные стратегии Function Calling и ReAct, редактор промптов, управление моделями, наблюдаемость и Backend-as-a-Service API.
Как работает: Dify разворачивается как набор сервисов: PostgreSQL, Redis, Qdrant или Weaviate для векторного хранилища и оркестратор рабочих процессов. В оркестраторе есть больше 14 типов узлов: LLM, Knowledge Retrieval, Code, Conditional, Iteration, Variable Aggregator, HTTP Request, Template Transform, Question Classifier, Tool, Parameter Extractor и другие. Узел с кодом работает в песочнице на Python или JavaScript.
На практике Dify закрывает задачи вроде корпоративных QA-ботов, поддержки клиентов, внутренних помощников, генерации контента, работы с несколькими моделями и подключения LLM-функций к уже существующему приложению.
Команда установки: склонируйте репозиторий Dify и перейдите в папку с Docker-конфигурацией:
git clone https://github.com/langgenius/dify.git
cd dify/dockerСкопируйте пример переменных окружения:
cp .env.example .envЗапустите Dify:
docker compose up -dПосле запуска откройте панель Dify в браузере:
14. Langflow
https://github.com/langflow-ai/langflow
Задача: Langflow нужен для быстрой сборки RAG-чатботов, цепочек с LLM и агентных сценариев через визуальный интерфейс. Его удобно брать для прототипа, когда нужно быстро проверить схему до переноса в код или до развёртывания как отдельного сервиса.
Это визуальный конструктор LLM-пайплайнов и агентов на базе LangChain. У него есть веб-интерфейс на 127.0.0.1:7860, настольный клиент для macOS и Windows и Helm-чарт для Kubernetes. Проект принадлежит DataStax и IBM после поглощения.
Как работает: в Langflow схема собирается из узлов, которые соответствуют компонентам LangChain. Поток можно превратить в REST API. В рабочих сценариях его используют для RAG-чатботов, мультиагентной оркестрации, пользовательских чатботов и интеграционных пайплайнов для BPM.
В Langflow есть AI-assistant для автогенерации компонентов, CLI и V2 endpoints для управления потоками за пределами визуального конструктора, совместимость с MCP как клиентом и сервером, а также страница развёртывания с интеграцией IBM watsonx Orchestrate.
Команда установки: для локального запуска нужны Python 3.10–3.13 и uv. Из новой папки установите Langflow:
uv pip install langflow -UЗапустите Langflow:
uv run langflow runПосле запуска интерфейс откроется по адресу:
http://127.0.0.1:7860
Если нужен быстрый запуск в контейнере, можно использовать Docker:
docker run -p 7860:7860 langflowai/langflow:latestRAG и работа с документами
RAGFlow умеет работать с Word, PowerPoint, Excel, изображениями, сканами, структурированными данными и веб-страницами. Внутри есть DeepDoc, GraphRAG, parent-child chunking, multi-recall, fused re-ranking и цитируемые ответы.
15. RAGFlow
https://github.com/infiniflow/ragflow
Задача: RAGFlow нужен для поиска и ответов по документам, где важно видеть, откуда взят каждый фрагмент ответа. Его берут для корпоративных баз знаний, исследовательских помощников, анализа данных из нескольких источников, юридических, медицинских и финансовых сценариев.
Проект объединяет RAG-движок, глубокое понимание документов через DeepDoc, агентные возможности и базу Infinity. В Infinity совмещены плотные векторы, разреженные векторы, tensor multi-vector и полнотекстовый гибридный поиск.
Как работает: RAGFlow умеет разбирать Word, PowerPoint, Excel, TXT, изображения, сканы, структурированные данные и веб-страницы. Внутри есть извлечение по шаблонам, визуализация нарезки текста с ручной правкой, цитируемые ответы, GraphRAG, parent-child chunking, Iteration agent component, шаблон генератора исследовательских отчётов, настраиваемые LLM и embeddings, multi-recall и fused re-ranking.
DeepDoc поддерживает ускорение на GPU через docker-compose-gpu.yml. В рабочих системах это полезно там, где документы сложнее обычного Markdown: таблицы, сканы, презентации, иерархия разделов, вложенные фрагменты и требования к аудиту.
Команда установки: cклонируйте репозиторий и перейдите в папку Docker:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/dockerЗапустите полный стек:
docker compose -f docker-compose.yml up -dПроверить сервер можно через логи:
docker logs -f ragflow-serverЕсли нужен режим разработки, сначала поднимают базовые сервисы:
docker compose -f docker/docker-compose-base.yml up -dЗатем запускают бэкенд из корня проекта:
uv sync --python 3.12 --all-extras
uv run python3 download_deps.py
pre-commit install
source .venv/bin/activate
export PYTHONPATH=$(pwd)
bash docker/launch_backend_service.shRAGFlow закрывает уже прикладной слой. Если нужно сначала понять механику RAG — как документы превращаются в базу знаний и почему модель отвечает по найденным фрагментам, есть отдельный разбор.
Работа с кодом из терминала
Claude Code читает кодовую базу, пишет тесты, чинит CI и работает с git-цепочкой. Gemini CLI подключает Gemini к терминалу, файловым операциям, shell, веб-загрузке, MCP и сценариям автоматизации.
16. Claude Code
https://github.com/anthropics/claude-code
Задача: Claude Code нужен для работы с кодовой базой из терминала. Он читает проект, выполняет задачи через git-цепочку, пишет тесты, чинит CI и помогает разбирать код без перехода в отдельную среду разработки.
Инструмент запускается командой claude в директории проекта. Он работает в командной строке, среде разработки и через @claude в GitHub PR и issues.
Задача: Claude Code умеет планировать многошаговую переработку кода, выполнять изменения с контролем через систему разрешений, читать падающие тесты, исправлять код, следить за CI и коммитить правки. Для командных сценариев есть хуки после использования инструментов, повторное подключение MCP-серверов, режим полного экрана /tui, мобильные уведомления через Remote Control и голосовой ввод на 20 языках, включая русский.
Для установки npm-метод указан как устаревший. Рекомендуется native installer: brew install, WinGet или пакеты дистрибутива.
Команда установки: на macOS и Linux выполните:
curl -fsSL https://claude.ai/install.sh | bashНа Windows откройте PowerShell и выполните:
irm https://claude.ai/install.ps1 | iexПосле установки перейдите в папку проекта и запустите Claude Code:
cd <project>
claude17. Gemini CLI
https://github.com/google-gemini/gemini-cli
Задача: Gemini CLI нужен для работы с проектом из терминала: прочитать кодовую базу, выполнить файловые операции, обратиться к командной оболочке, получить данные из веба и использовать модель в привычном окружении разработчика.
Это открытый терминальный ИИ-агент от Google под лицензией Apache 2.0. Он интегрирует Gemini в командную оболочку и устанавливается через npm. Для личного Google-аккаунта есть бесплатный тариф: 60 запросов в минуту и 1000 запросов в день, доступ к Gemini 3 Pro с контекстом 1 млн токенов.
Как работает: В Gemini CLI уже встроены Google Search grounding, операции с файлами, команды оболочки, загрузка данных из веба и поддержка MCP для пользовательских интеграций. Инструмент можно использовать интерактивно, запускать в скриптах и подключать к рабочим процессам на GitHub.
Для кода это означает обычный сценарий: открыть терминал в папке проекта, запустить gemini и дать задачу. Например, попросить объяснить архитектуру, проверить изменения, подготовить правки или запустить команду. Для автоматизации есть неинтерактивный режим через gemini -p, а для структурированного вывода — –output-format json и –output-format stream-json.
Команда установки:
Быстрее всего поставить Gemini CLI через npm:
npm install -g @google/gemini-cliПосле установки запустите инструмент в директории проекта:
geminiПри первом запуске Gemini CLI предложит авторизоваться. Для личного аккаунта можно выбрать вход через Google. В официальной инструкции для этого варианта указан бесплатный лимит: 60 запросов в минуту и 1000 запросов в день.
Если ставить инструмент не хочется, можно запустить его через npx:
npx @google/gemini-cliНа macOS и Linux есть установка через Homebrew:
brew install gemini-cliПосле запуска можно работать с текущей директорией, подключать дополнительные папки и вызывать Gemini CLI из скриптов:
gemini --include-directories ../lib,../docs
gemini -p "Explain the architecture of this codebase"Если Claude Code или Gemini CLI уже стоят, следующий шаг — настроить скиллы: они помогают агенту не объяснять одни и те же правила каждый раз.
Речь, изображения и видео
Этот блок про мультимодальные задачи. Whisper превращает речь в текст, определяет язык и умеет переводить речь. ComfyUI нужен для сложных схем генерации изображений и видео через узлы. Stable Diffusion WebUI закрывает локальную генерацию изображений через браузерный интерфейс, работу с LoRA, чекпойнтами и быстрыми прогонами.
18. Whisper
https://github.com/openai/whisper
Задача: Whisper нужен для распознавания и перевода речи: расшифровки подкастов, субтитров, голосовых интерфейсов, речевых помощников и потокового перевода аудио в текст.
Это открытая модель OpenAI для ASR и speech translation. В основе архитектуры Transformer encoder-decoder. Модель обучена на 680 000 часов аудио: 438 000 часов английского, 126 000 часов неанглийской речи с переводом в английский текст и 117 000 часов неанглийской речи с расшифровкой на исходном языке.
Как работает: Whisper поддерживает multilingual ASR, speech translation, language ID и voice activity detection в одной архитектуре через токены задач. В модельной линейке указаны tiny, base, small, medium, large-v1, large-v2, large-v3 и large-v3-turbo.
В рабочих стеках часто используют не только официальный репозиторий, а порты для инференса: whisper.cpp на C и C++ с GGML, Apple Metal, OpenVINO, CoreML и CUDA; faster-whisper на CTranslate2; WhisperX с временными метками по словам и diarization; whisper-jax для ускорения на TPU. Whisper также используется в OpenClaw и Open WebUI для голосовых интерфейсов.
Команда установки:
Сначала поставьте Whisper:
pip install -U openai-whisperЗатем установите ffmpeg. На Ubuntu и Debian:
sudo apt update && sudo apt install ffmpegНа macOS через Homebrew:
brew install ffmpegНа Windows через Chocolatey:
choco install ffmpegИли через Scoop:
scoop install ffmpegПосле установки можно расшифровать аудио через командную строку:
whisper audio.flac audio.mp3 audio.wav --model turboЕсли нужно перевести речь на английский, используйте мультиязычную модель, например medium:
whisper japanese.wav --model medium --language Japanese --task translate19. ComfyUI
https://github.com/comfy-org/ComfyUI
Задача: ComfyUI нужен для сложных пайплайнов генерации изображений и видео. Его используют, когда генерация собирается из нескольких шагов: загрузка модели, работа с CLIP, сэмплер, VAE, сохранение результата, апскейл, интерполяция кадров и дополнительные узлы. Это графический интерфейс, программный интерфейс и бэкенд для diffusion-моделей.
Как работает: ComfyUI строит процесс генерации как схему из узлов. Такой подход подходит для пайплайнов с ControlNet, IPAdapter, апскейлером и интерполяцией кадров. Готовый процесс можно вынести наружу через программный интерфейс.
Новые diffusion-модели часто выходят с готовыми рабочими схемами для ComfyUI. В подготовленных данных указаны Flux, SD 3.5, Wan 2.1, HunyuanVideo и Seedance. Инструмент применяют в VFX, рекламе, геймдеве, LoRA-тренировке, пакетной генерации и связках с Photoshop или Blender через MCP и коннектор.
Команда установки: cамый простой способ поставить ComfyUI — скачать декстопное приложение с официального сайта: https://www.comfy.org/download
Этот вариант подходит для Windows и macOS. После установки можно запускать ComfyUI как обычное приложение и собирать генерацию через граф из узлов.
Для Windows есть переносимая сборка. Она подходит для запуска на Nvidia GPU или только на CPU:
После скачивания архив нужно распаковать через 7-Zip или проводник Windows. Модели в формате ckpt и safetensors обычно кладутся в папку:
ComfyUI\models\checkpoints
ComfyUI хорош там, где визуальный пайплайн нужно контролировать через узлы. В параллельной ветке ИИ уже встраивают прямо в профессиональные инструменты: Claude появился в Blender, Adobe, Autodesk и Ableton.
20. Stable Diffusion WebUI
https://github.com/automatic1111/stable-diffusion-webui
Задача: Stable Diffusion WebUI нужен для локальной генерации изображений через браузерный интерфейс. Его берут для быстрых прогонов LoRA, тестов промптов, работы с Civitai, локальных артов, пользовательских чекпойнтов и прототипирования без кода.
Как работает: Stable Diffusion WebUI запускает модели семейства Stable Diffusion локально и даёт браузерную панель управления. Внутри есть txt2img, img2img, inpainting, outpainting, prompt editing, batch processing, hires fix, отдельный интерфейс для embeddings, LoRA и hypernetworks, выбор VAE, поддержка SD 2.0 и SDXL, расширения и программный интерфейс.
Ядро собрано вокруг классического однопоточного процесса генерации. Это делает инструмент понятным для быстрых задач: выбрать модель, настроить параметры, прогнать варианты, сохранить результат.
Команда установки: на Windows сначала установите Python 3.10.6 и отметьте пункт Add Python to PATH. Более новые версии Python в инструкции не рекомендуются из-за поддержки torch. Затем установите Git.
Склонируйте репозиторий:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitОткройте папку stable-diffusion-webui и запустите файл:
webui-user.bat
Запускайте его обычным пользователем, без прав администратора. После первого старта WebUI сам подтянет нужные зависимости.
Советуем дополнительно почитать по теме:
- n8n автоматизация без кода: учимся делать парсер Telegram за выходные — как он работает, запустим его прямо на своём компьютере и за пять минут соберём автоматического бота, который будет парсить новости.
- 15 скиллов для AI-агентов: установка и как работает в 2026 — как настроить агента правильно и больше не объяснять одно и то же каждый раз.
- Как создать AI-агента: пошаговое руководство — GLM-5.1 и Kimi — это агентные модели, в статье научитесь строить агентные пайплайны поверх LLM.
- Как стать ML-инженером в 2026 году: от Python до первого оффера — путь из семи этапов с нуля до первого оффера: от математики и Python до деплоя модели в продакшн.
Бонус для читателей
Если хотите работать с нейронками профессионально и зарабатывать больше, — держите промокод Практикума на любой платный курс: KOD (можно просто нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям. Начать можно в любой момент, карту привязывать не нужно.











