Наш старый знакомый Эван Codebullet снова делает алгоритм, который играет в игры и ставит рекорды. На этот раз он будет играть в тетрис. Если хотите лучше понимать логику работы этого алгоритма, посмотрите, как запрограммировать тетрис на JavaScript самому, а потом возвращайтесь сюда.
Оригинальное видео Эвана (если знаете английский, смотреть будет интереснее):

Если вам лень смотреть 18 минут видео или не знаете английский, то читайте статью — мы собрали все ключевые моменты.
👉 Искусственный интеллект — это не всегда нейросети
В этом случае всё сделано на чистом JavaScript. Сила этого алгоритма в том, что он ведёт себя как нейросеть, но не обучается на ходу, а чётко следует заложенным в него правилам. Поэтому качество игры этого алгоритма не зависит от количества проходов в обучении, а только от правил, по которым он создан.
Если хотите посмотреть и оценить сам код алгоритма, зайдите в Гитхаб Эвана.
Сначала нужно сделать саму игру
Эван начинает с простого — создаёт игровое поле, по которому падает красный квадратик:


В игре пока нет никакой механики кроме падения красного квадрата, но в этом и есть суть программирования Эвана — продвигаться вперёд маленькими шагами. Так у него на каждом этапе получается что-то рабочее, что можно взять за основу для следующего шага.
Как только Эван начал рисовать фигуры и возможные варианты их вращения, то понял, что нужно найти схемы, как это делается в оригинальной игре:

Как видите, здесь всё то же самое, как в нашем проекте — каждая фигура вписана в квадрат, чтобы при вращении не вылезать за его пределы. А ещё этот рисунок помогает понять, как запрограммировать вращение и положение фигуры при повороте.
Теперь, когда мы знаем, как выглядят фигуры, можно запрограммировать и их падение. Но сразу есть проблема: они просто улетают за край игрового поля, потому что нет проверки границ.
Когда Эван это исправил и добавил автовращение каждой фигуре на старте, получилось такое:

Оказалось, что, сделав один или несколько поворотов, фигуры застывали на месте и накладывались друг на друга. Эван хотел по-быстрому решить эту проблему, но из-за нелепой ошибки в коде фигуры стали разваливаться на части.
Много итераций спустя Эван исправил все баги и смог-таки заставить блоки падать и вращаться.
Проверка на пересечения и столкновения
Теперь задача сделать так, чтобы фигуры умели определять, столкнутся ли они на следующем шаге с чем-то или нет. Если нет, значит так двигаться можно, а если будет пересечение с другой фигурой, то двигаться в эту сторону нельзя.
Всё шло отлично до тех пор, пока игровое поле не переполнилось. Новые фигуры стали появляться сверху, тут же останавливались, потому что некуда падать, и сразу же поверх них отрисовывались новые. Вывод: надо добавить проверку на достижение верхнего края поля. Если фигура остановилась на нём или за его пределами — всё, игра закончена.

Удаление целой линии
В тетрисе есть правило — когда горизонтальная линия полностью заполнена, она исчезает, а всё, что сверху, сдвигается на один ряд вниз. Первая версия алгоритма Эвана убирала ряд с экрана, но забывала сделать всё остальное. Получалась как бы невидимая линия, на которую могут опираться другие фигуры:

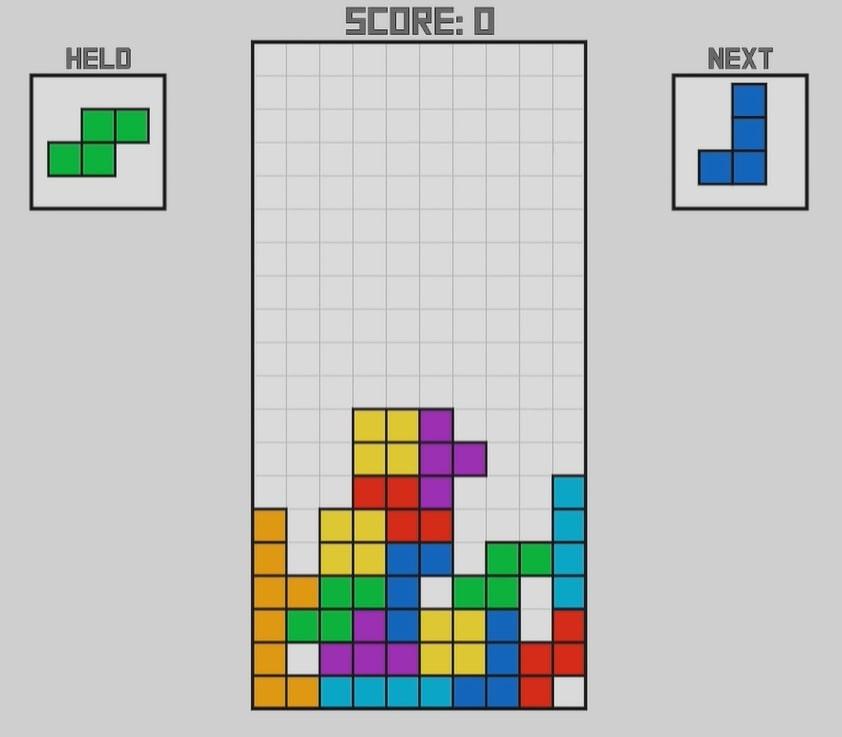
После обновления кода всё заработало как нужно. Заодно появились окошки со следующей и удерживаемой фигурами.
Удерживаемая фигура — это специальный элемент в современном тетрисе, который работает так:
- там появляется какая-то фигура из игровой последовательности;
- игрок в любой момент может заменить текущую фигуру на эту, а обратно уже не может;
- это позволяет набирать больше очков и помогает игрокам ставить больше рекордов.

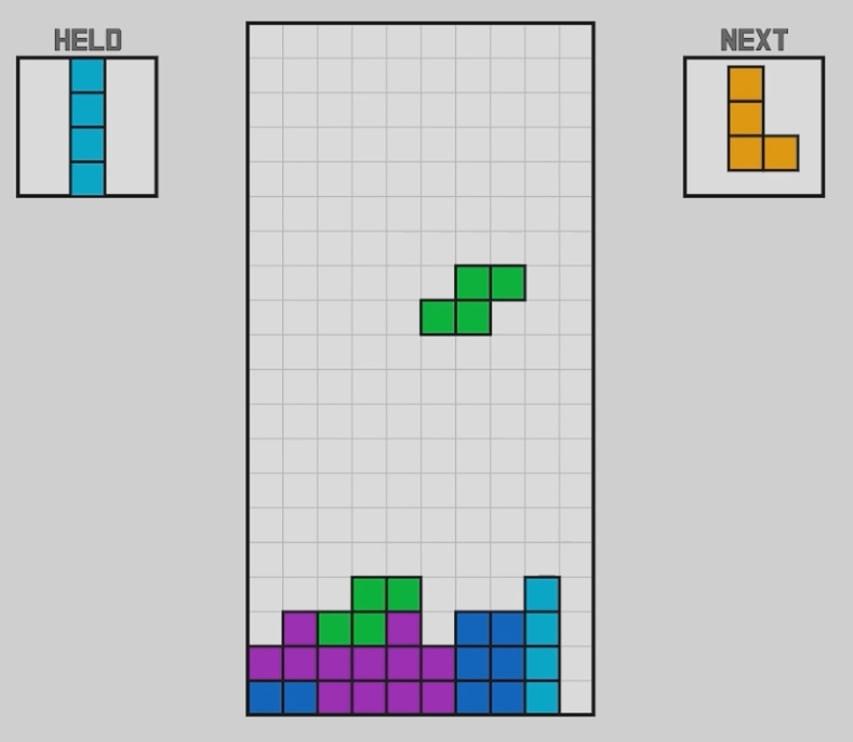
Обучаем алгоритм
Кажется, что всё готово к тому, чтобы подключить к игре игровой алгоритм и научить его круто играть в тетрис. Но нас сразу ждёт первая проблема — как научить его правильно ставить фигуры.
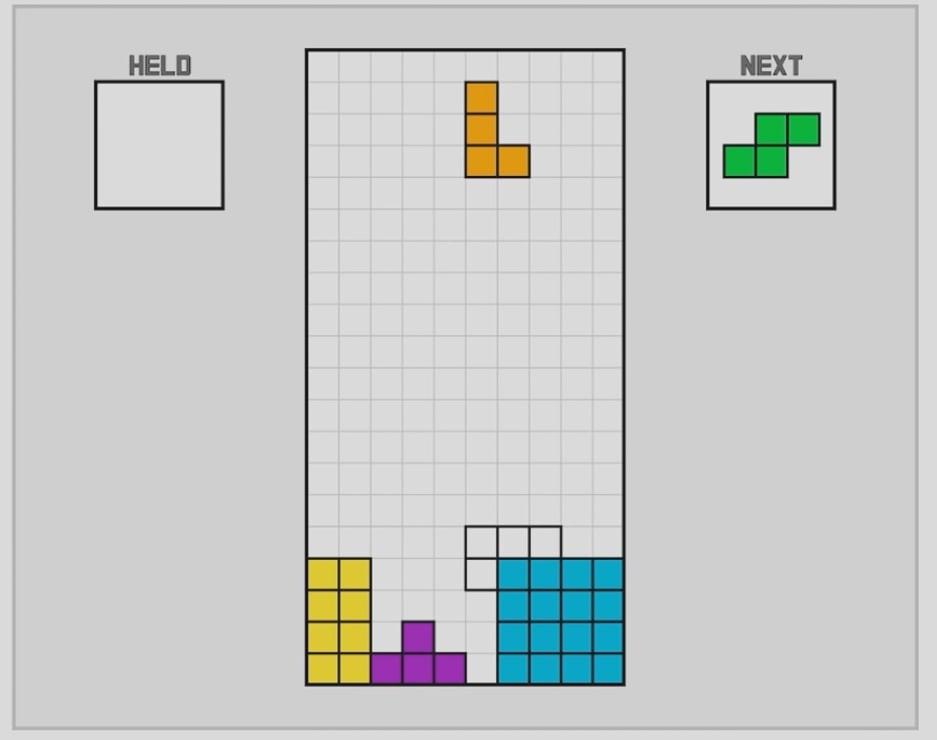
Первое, что приходит в голову, — показать ему все возможные положения среди остальных фигур, если просто опустить текущую фигуру вниз. Потом — то же самое, но повернув её один раз, затем два раза и три. Но так мы не сможем задвинуть зелёную фигуру левее, чтобы она попала в паз, как на рисунке ниже:

Решение — мы смоделируем для каждой фигуры все возможные нажатия клавиш. Это не оптимальный вариант с точки зрения использования машинных ресурсов, но он даёт нам нужный результат. Теперь компьютер может прикинуть, куда поместить очередную фигуру уже на старте. Незакрашенная фигура внизу — это Эван сделал видимым процесс «мышления» алгоритма, куда поставить новый элемент:

Выбираем оптимальное место
При выборе расположения блоков алгоритм будет отдавать предпочтение тому, которое даст наибольшее количество внутренних баллов. Для этого Эван написал правило: фигура не должна оставлять под собой пустые ячейки, недоступные для других фигур.
Чем меньше таких ячеек остаётся, тем более желаемый ход. Теперь программа лучше подгоняет фигуры друг к другу:

Но возникла другая проблема: ненужные высокие башни. Компьютер делает вроде как правильно — оставляет как можно меньше дыр, — но при этом совершенно не следит за другими параметрами. Эван добавляет в алгоритм второе правило: чем ниже общая масса блоков — тем лучше.
Стало намного лучше: теперь компьютер старается не оставлять под собой пустых блоков и стремится укладывать фигуры как можно ниже.

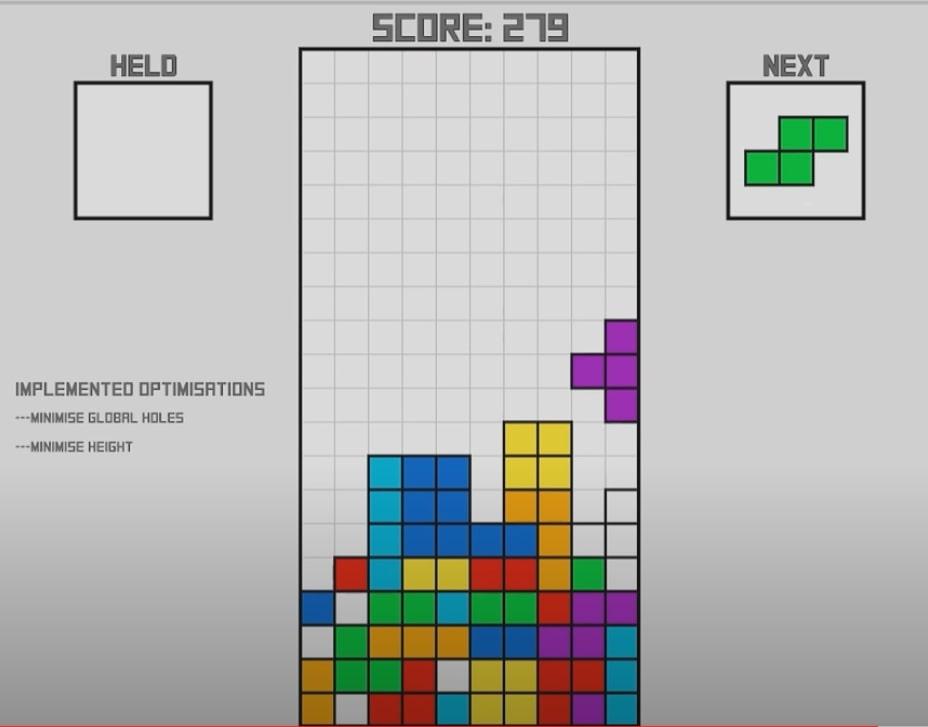
Используем удерживаемую фигуру
Следующее, чему Эван учит свой алгоритм, это использовать удерживаемую фигуру. Третье правило, которое он добавляет, такое: проверь, что будет, если заменить фигуру на удерживаемую, и если результат будет лучше — замени фигуру.
Стало ещё лучше:

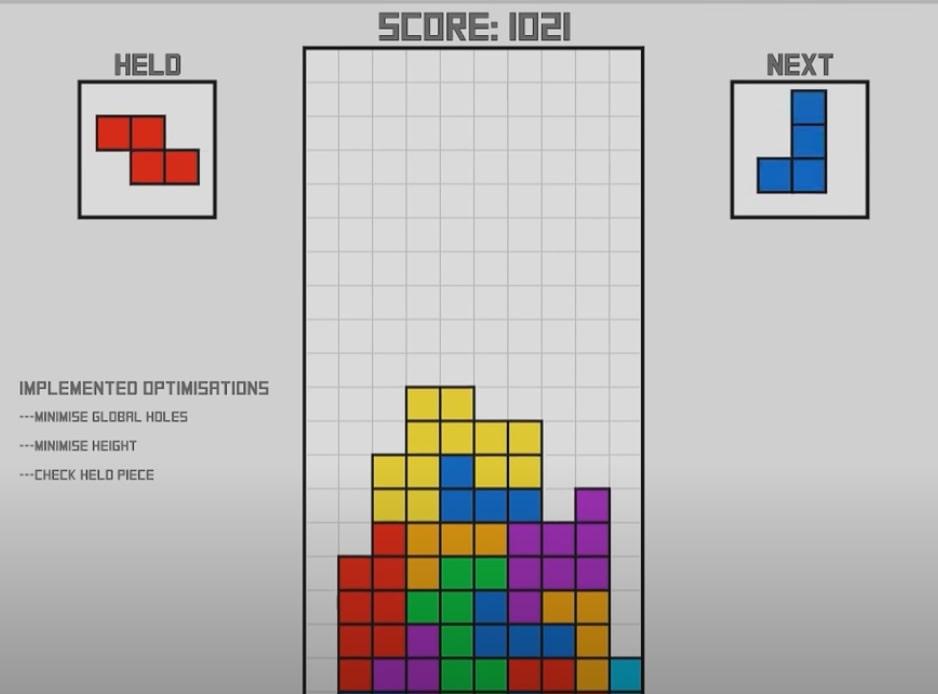
Последняя проблема — пустые одиночные столбцы
Когда компьютер ставит фигуры по этим трём правилам, то часто у него получаются пустые вертикальные столбцы, куда можно поместить только прямую фигуру:

Такое поведение мешает правильной работе всего алгоритма и не даёт ему полностью реализовать свой потенциал. Поэтому Эван вводит четвёртое, последнее правило: старайся избегать таких длинных пустых мест.
И это стало решающим моментом в работе алгоритма. До этого он с трудом собирал 1000 линий, а сейчас легко набирает 10 000 линий и не останавливается на этом.
Выводы простые:
- Искусственный интеллект — это не всегда нейронка. Иногда это просто сложный алгоритм, который работает так, как придумал его создатель. Научиться новому самостоятельно такой алгоритм не может.
- Компьютер можно научить играть во что угодно, если есть чёткие правила игры и мы понимаем, как этими правилами лучше всего пользоваться.
- Степень мастерства алгоритма зависит от правил, по которым он работает. Если мы чётко понимаем правила и знаем стратегии победы, наш алгоритм будет работать лучше.
- Если всё сделать правильно, компьютер сможет играть в игру намного лучше человека. И это нормально, потому что именно для этого и делают алгоритмы.