Нередко события в мире происходят одновременно. Мы замечаем, что чем больше оперативной памяти на сервере, тем быстрее загружается интернет-магазин. Или наоборот: чем сильнее дождь, тем меньше людей заходит в офлайн-магазины. Наш мозг инстинктивно пытается связать эти явления друг с другом, чтобы найти закономерность.
Сегодня поговорим о корреляции — числовом выражении силы таких связей. Из статьи вы узнаете, что такое корреляция в статистике, как рассчитать коэффициент корреляции и не прийти к ложным выводам.
Говорят, что есть прямая корреляция между объёмом выпитого чая во время чтения и пользой от этого чтения (но это неточно). Так что наливайте чашечку — и начнём.
Что такое корреляция
Корреляция — это сила связи между двумя или более величинами. Само слово происходит от латинского correlatio, что переводится как «соотношение» или «взаимосвязь». Когда мы говорим, что переменные коррелируют, это значит: при изменении одной величины каким-то образом меняется и другая.
Важно сразу запомнить: наличие связи между событиями не означает, что одно порождает другое. Корреляция — это просто наблюдение за тем, что данные двигаются синхронно. А вот почему — уже совсем другая история. Зависимость может быть случайной, а может объясняться каким-то третьим, скрытым фактором, который мы просто не учли.
Дальше будет много цифр, поэтому сразу посмотрим на корреляцию глазами математика. С этой точки зрения корреляция — мера совместной изменчивости двух переменных.
Представьте, что у нас есть два столбца со значениями. Первый — количество часов, которое джуниор-разработчик потратил на чтение документации. Второй — количество багов, которое он наворотил.
Математический смысл в том, чтобы взять эти два ряда чисел и посмотреть, как их отклонения от средних значений ведут себя синхронно. Если разработчик читал документацию дольше среднего значения и при этом допустил меньше багов, чем в среднем по команде, — математика зафиксирует эту совместную динамику. И так для каждого человека в выборке. По сути, мы пытаемся понять: можно ли, зная поведение одной переменной, предсказать поведение другой?
Виды корреляции
В мире данных не всё так однозначно. Связи бывают очень разными, и чтобы проводить грамотный корреляционный анализ, нужно уметь различать их виды. В основном связи делят по направлению и по форме.
Направления корреляции
Первое, на что мы всегда смотрим, — это куда двигаются наши графики. Тут есть три варианта: вверх, вниз или хаотично. Эти направления соответствуют положительной, отрицательной и нулевой корреляции.
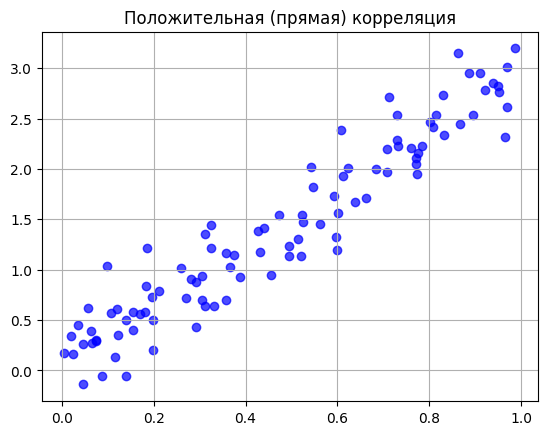
Положительная (прямая) корреляция. Обе переменные растут или падают одновременно. Простой пример: чем больше оперативной памяти в ноутбуке, тем шустрее он работает. Увеличивается один признак — увеличивается и другой. На графике это выглядит как рой точек, который ползёт из левого нижнего угла в правый верхний.
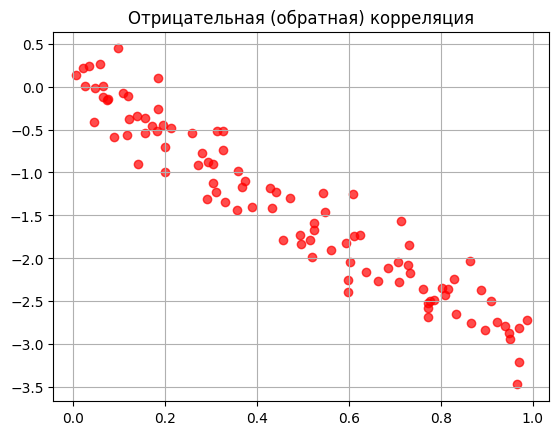
Отрицательная (обратная) корреляция. Здесь всё работает в противовес: когда одно значение растёт, другое падает. Например, чем быстрее едет электричка, тем меньше времени займёт поездка. Один показатель идёт вверх, другой — вниз.
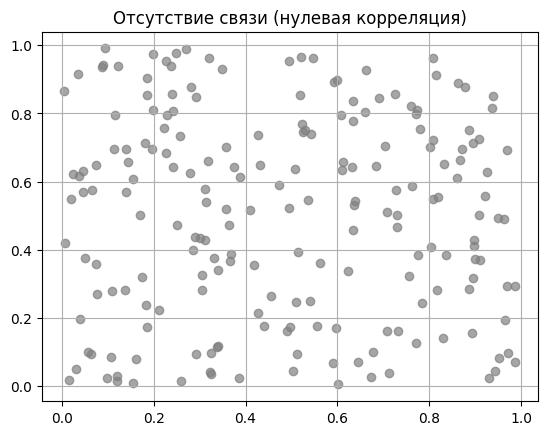
Нулевая корреляция. Это когда мы пытаемся найти логику там, где её нет. Например, если связать цвет корпуса ноутбука и скорость компиляции кода. Данные будут разбросаны по графику хаотичным облаком — никакую линию сквозь них провести не получится.
Форма корреляции
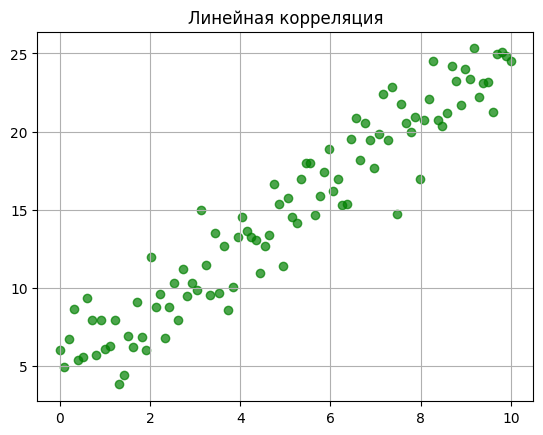
Второе важное свойство — по какой траектории двигаются данные. Здесь два варианта: по прямой и не по прямой. Это линейная и нелинейная корреляция соответственно.
Линейная корреляция. Самый простой и приятный для аналитика случай. Если нарисовать точки на графике, они выстроятся вдоль ровной прямой. Изменение одной переменной на единицу всегда приводит к предсказуемому изменению другой на определённый шаг.
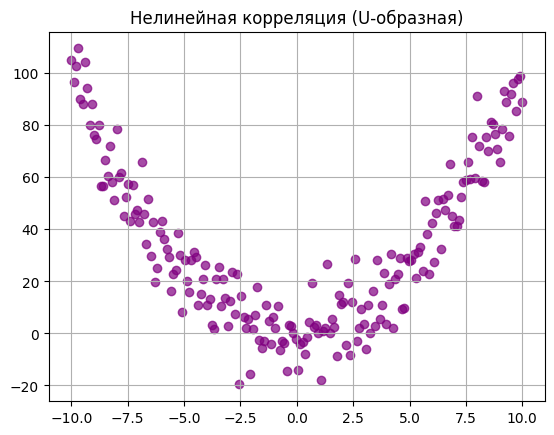
Нелинейная корреляция. Жизнь сложнее прямых линий. Бывает так, что связь есть, но она описывается кривой. Представьте зависимость уровня стресса разработчика от его продуктивности. Стресса нет совсем — программист расслаблен и работает медленно. Появляется лёгкий стресс — продуктивность взлетает. Стресс становится невыносимым — наступает выгорание, и продуктивность падает до нуля. График будет похож на дугу. Расчёт нелинейной корреляции требует особых математических подходов: стандартные формулы для прямых линий здесь покажут, что связи якобы нет.



Коэффициент корреляции — основной показатель взаимосвязи
Разглядывать графики — это здорово, но нам нужен конкретный измеримый показатель, который можно вставить в отчёт или использовать в коде. Этим показателем выступает коэффициент корреляции.
Это статистический индекс, который переводит визуальную картинку с точками в конкретное число. Благодаря ему мы можем не просто сказать, что зависимость есть, а выразить силу связи коэффициентом.
Что показывает коэффициент корреляции и как его понимать
В классической статистике этот коэффициент всегда измеряется по шкале от -1 до +1. Запомнить, как его интерпретировать, очень просто:
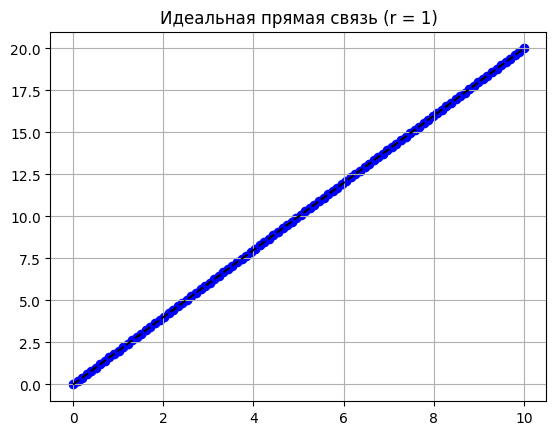
1 — идеальная прямая связь. Точки выстроились в ровную линию, идущую вверх. Зная X, мы можем со стопроцентной точностью назвать Y.
-1 — идеальная обратная связь. Точки выстроились в ровную линию, идущую вниз.
0 — линейной связи нет вообще. Такой график мы уже видели.
А как быть с промежуточными значениями? В статистике принято опираться на условные пороги (хотя в разных научных школах они могут немного отличаться):
от 0 до 0,3 (или от 0 до −0,3) — связь очень слабая, ею можно пренебречь.
От 0,3 до 0,7 (или от -0,3 до -0,7) — связь средняя (умеренная).
От 0,7 до 1 (или от -0,7 до -1) — связь сильная. Если вы получили такое значение, значит, переменные связаны очень тесно.
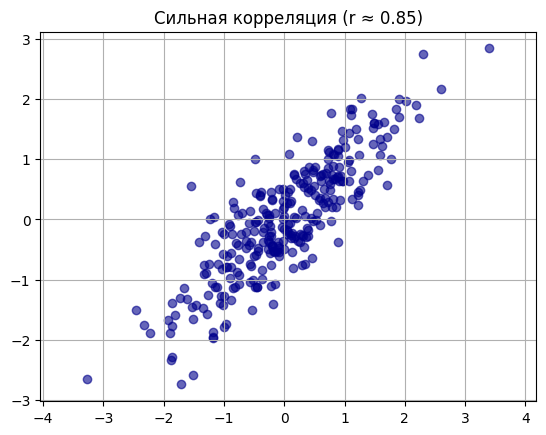
Время разобраться, как вычислить этот коэффициент.
Самый популярный метод оценки линейной связи — коэффициент Пирсона. Его придумал Карл Пирсон, один из отцов-основателей современной статистики.
Формула Пирсона пригодится, если вы работаете с непрерывными количественными данными: рост, вес, возраст, зарплата, время отклика сервера.
Важное условие: метод параметрический. Это значит, что он требователен к данным. Чтобы результат был достоверным, данные должны быть распределены нормально и без сильных аномалий. Если в выборке сто человек с зарплатой 70 тысяч рублей и один миллиардер — богатей сломает всю математику, и результат будет искажён.
Полезный блок со скидкой
Если вам интересно работать с данными и вы хотите научиться находить в них закономерности, строить модели и делать выводы — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Как вычислить коэффициент Пирсона вручную
Сейчас всё считают компьютеры, но чтобы стать хорошим аналитиком, полезно понимать математику под капотом. Вот как выглядит классическая формула Пирсона (r):
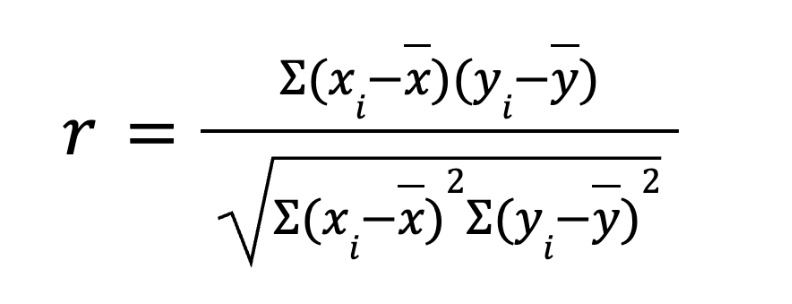
На первый взгляд, выглядит пугающе. Но на деле всё логично:
- Мы берем каждое значение первой переменной (xi) и вычитаем из него среднее значение всех иксов (x). Мы смотрим, насколько конкретная точка отклонилась от нормы.
- Делаем то же самое для второй переменной (y), вычитая среднее (ȳ).
- Умножаем эти отклонения друг на друга и складываем результаты для всех пар. Если обе переменные отклонились в одну сторону (обе больше среднего или обе меньше), умножение даст плюс. Это и есть числитель (он показывает совместную вариацию).
- А в знаменателе мы просто делим это всё на стандартные отклонения, чтобы масштабировать наш огромный результат в удобный интервал от -1 до 1.
Если ваши данные точны и распределены нормально — зовите на помощь старину Пирсона.
Коэффициент корреляции Спирмена
В ситуации, когда данные неточные, а выборка перекошена, Пирсон нам не товарищ. Если в них есть аномальные выбросы, или если мы работаем с местами в рейтинге, а не с точными числами, то мы обращаемся к методу Чарльза Спирмена.
Ранговая корреляция Спирмена — это непараметрический метод. Ему абсолютно всё равно, насколько нормально распределены ваши данные. Он ищет не строгую линейную зависимость, а монотонную. Монотонность — это когда одна величина просто растет вслед за другой, и неважно, по прямой линии или скачками.
Главная фишка Спирмена в том, что он работает не с самими числами, а с их рангами (местами). Представьте, что мы измеряем связь между местом в поисковой выдаче Яндекса и количеством кликов. Мы не можем использовать Пирсона, потому что места (1-е, 2-е, 3-е) — это порядковые данные. А вот Спирмена — можем.
Как вычислить коэффициент Спирмена вручную
Чтобы посчитать этот коэффициент, мы сначала ранжируем наши данные. Самому маленькому числу даем ранг 1, следующему — ранг 2 и так далее. Затем считаем разницу между рангами двух переменных для каждого объекта (обозначим как d). Дальше берем формулу:
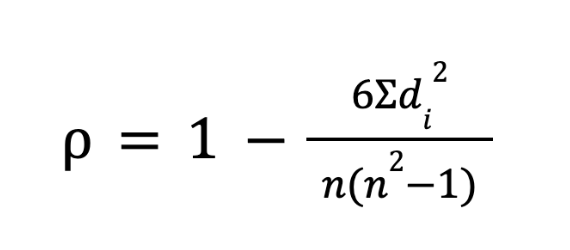
Здесь di2 — это квадрат разницы рангов, а n — количество объектов в выборке. Поскольку мы возводим разницу в квадрат, нам неважно, положительная она или отрицательная. Чем меньше эта сумма разностей, тем ближе наша дробь будет к нулю, и тем ближе итоговый коэффициент (читается «ро») будет к единице (то есть связь сильная). Выбросы этот метод не ломают, потому что миллиардер из нашего прошлого примера просто получит ранг «1», и его миллиарды не утянут за собой всю формулу.
Другие методы оценки связи
Конечно, Пирсон и Спирмен — это отцы, а их методы — база. Но наука на них не заканчивается. Для особых случаев есть другие инструменты.
Коэффициент корреляции Кендалла
Коэффициент Кендалла (обозначается греческой буквой — тау) — это ещё один метод, который работает с рангами. Но логика здесь другая: мы берем все возможные пары объектов и смотрим, совпадает ли их логика (согласованность) по двум признакам.
Представьте, что мы ищем связь между ценой смартфонов и качеством их камер. Наши объекты — сами телефоны, а признаки — их места в рейтингах стоимости и качества фото.
Если флагман А стоит дороже бюджетника Б и при этом снимает лучше него, логика сохраняется: пара считается согласованной. Но если мы берем неоправданно дорогой дизайнерский телефон В со слабой камерой и сравниваем с тем же бюджетником Б, правило ломается: по деньгам побеждает один, а по камере — другой. Это несогласованная пара.
Алгоритм попарно сравнивает все телефоны в выборке и подводит баланс по формуле:
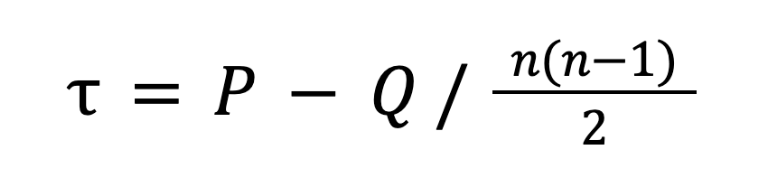
Где:
P — количество согласованных пар;
Q— количество несогласованных пар;
n — общее количество исследуемых объектов.
Выражение
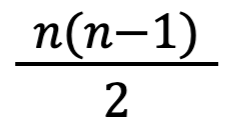
в знаменателе — это просто математический способ посчитать общее количество всех возможных пар в нашей выборке. Его можно обозначить N, чтобы формула стала проще:
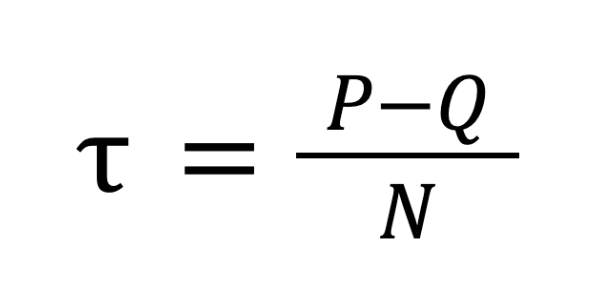
Если перевес плюсов огромный — связь прямая. Если сплошные минусы — обратная. Этот метод требует больше вычислительных ресурсов, если считать на компьютере. Зато он лучше справляется с небольшими выборками и данными, где очень много одинаковых значений.
Коэффициент корреляции Фехнера
Самый простой метод оценки связи, который можно посчитать буквально на коленке. Он вообще не учитывает, насколько сильно отклонились данные, а смотрит только на их направление относительно нормы.
Сначала мы высчитываем среднее значение для обоих признаков. Затем смотрим на каждый объект: если его значение больше среднего, присваиваем ему плюс. Если меньше — минус. Дальше мы просто считаем, совпали ли знаки у двух переменных одного объекта.
Формула коэффициента Фехнера:
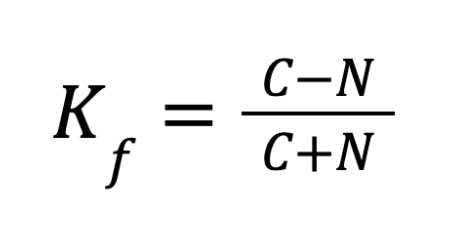
Где:
C — количество совпадений (плюс-плюс или минус-минус);
N — количество несовпадений (плюс-минус).
Знаменатель C+N — это просто общее число наших объектов.
Метод Фехнера легко может показать и отсутствие связи. Если количество совпадений окажется в точности равно количеству несовпадений, то при вычитании в числителе мы получим ноль. А ноль, поделенный на любое число, дает строгий 0. Это означает, что переменные ведут себя хаотично и закономерности нет.
Метод Фехнера очень грубый, но если вам нужно за пять секунд оценить направление связи в небольшой таблице — он отлично подойдет.

Расчет корреляции на компьютере
Понимать формулы нужно, но руками их никто не считает. В ИТ для этого используют специальный софт и языки программирования. Для наглядности, всё будем разбирать на примере.
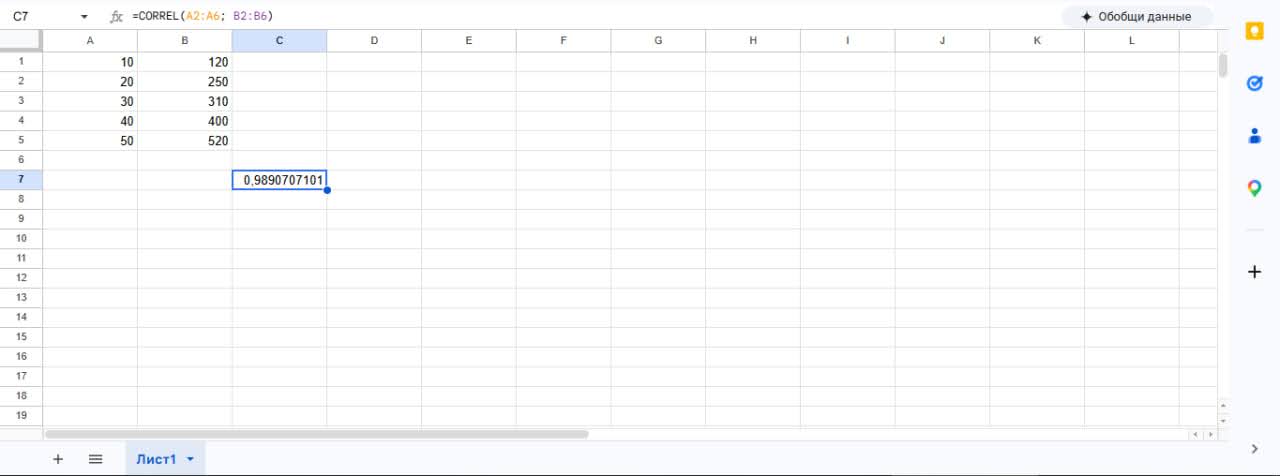
Представим, что у нас есть небольшая таблица маркетингового отдела. В одном столбце записан рекламный бюджет (в тысячах рублей), а в другом — количество новых регистраций на сайте за этот же период. У нас есть данные за пять месяцев:
| Бюджет | Новые пользователи |
|---|---|
| 10 | 120 |
| 20 | 250 |
| 30 | 310 |
| 40 | 400 |
| 50 | 520 |
Посмотрим, как рассчитать корреляцию между этими числами в разных средах.
Расчет корреляции на R
Язык R создавался статистиками для статистиков, поэтому здесь всё работает без подключения дополнительных библиотек.
Сначала заносим данные в переменные, а потом вызываем встроенную функцию:
# задаем вектор с данными по бюджету
budget <- c(10, 20, 30, 40, 50)
# задаем вектор с регистрациями
registrations <- c(120, 250, 310, 400, 520)
# запускаем тест для корреляции Пирсона
cor.test(budget, registrations, method = "pearson")
# делаем то же самое для Спирмена (указываем другой метод)
cor.test(budget, registrations, method = "spearman")По Пирсону скрипт выдаст:
Pearson’s product-moment correlation
data: budget and registrations
t = 15.344, df = 3, p-value = 0.0006013
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9036599 0.9996041
sample estimates:
cor
0.9936891
Для Спирмана вывод получится таким:
Spearman’s rank correlation rho
data: budget and registrations
S = 4.4409e-15, p-value = 0.01667
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
1
Если вам нужны только коэффициенты, вместо cor.test() используйте просто cor():
# создаем массив (вектор) с данными по бюджету
budget <- c(10, 20, 30, 40, 50)
# создаем массив с данными по регистрациям
registrations <- c(120, 250, 310, 400, 520)
# считаем Пирсона для этих двух массивов
cor(budget, registrations, method = "pearson")
# считаем Спирмена для этих же данных
cor(budget, registrations, method = "spearman")Тогда в выводе будут только 0.9936891 и 1.
Python
Python — стандарт индустрии для аналитиков. Чтобы сделать расчёт, обычно используют библиотеку pandas для создания удобных таблиц и scipy для более сложных статистических тестов.
# импортируем библиотеку pandas для работы с таблицами
import pandas as pd
# импортируем модуль stats из библиотеки scipy для статистических расчетов
import scipy.stats as stats
# создаем словарь с нашими данными по бюджету и регистрациям
data = {
'Бюджет': [10, 20, 30, 40, 50],
'Регистрации': [120, 250, 310, 400, 520]
}
# превращаем словарь в датафрейм
df = pd.DataFrame(data)
# вычисляем Пирсона и p-value с помощью pearsonr
pearson_coef, pearson_p = stats.pearsonr(df['Бюджет'], df['Регистрации'])
# вычисляем Спирмена и p-value с помощью spearmanr
spearman_coef, spearman_p = stats.spearmanr(df['Бюджет'], df['Регистрации'])
# выводим результаты Пирсона с округлением до четырех знаков
print(f"Коэффициент Пирсона: {pearson_coef:.4f}")
print(f"p-value (Пирсон): {pearson_p:.4f}\n")
# выводим результаты Спирмена с таким же округлением
print(f"Коэффициент Спирмена: {spearman_coef:.4f}")
print(f"p-value (Спирмен): {spearman_p:.4f}")Получим вывод:
Коэффициент Пирсона: 0.9937
p-value (Пирсон): 0.0006
Коэффициент Спирмена: 1.0000
p-value (Спирмен): 0.0000
Excel
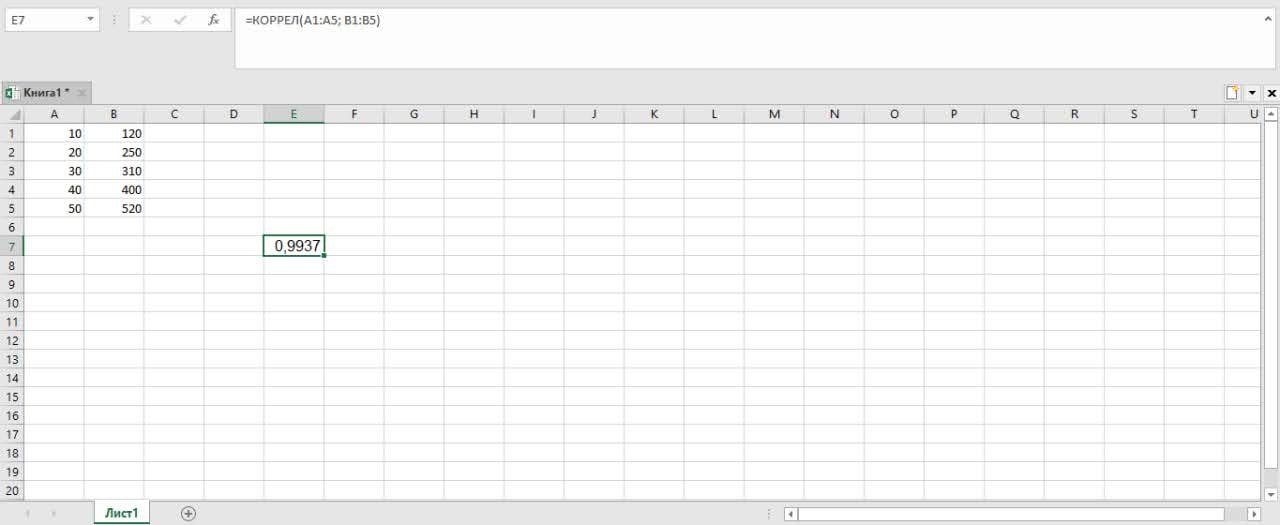
Если вы анализируете небольшую таблицу в Excel, открывать Python не обязательно. Представим, что вы перенесли наши данные в таблицу: значения бюджета лежат в ячейках от A1 до A5, а регистрации — от B1 до B5.
В табличном процессоре есть встроенная формула. Поставьте курсор в любую пустую ячейку и напишите:
=КОРРЕЛ(A1:A5; B1:B5)
Программа моментально выдаст коэффициент Пирсона для этой выборки.
Google Sheets
В облачных Google Таблицах логика ровно такая же, разница только в языке интерфейса (если установлена английская версия). Данные лежат в тех же ячейках.
Вводим функцию:
=CORREL(A1:A5; B1:B5)
И получаем искомое значение. Если у вас русская версия Google Таблиц, то формула =КОРРЕЛ(A1:A5; B1:B5) сработает точно так же, как и в десктопном Excel.
Корреляционный анализ как метод исследования
Нажать кнопку и получить цифру 0,8 — это расчёт, но в отрыве от остального он мало о чём говорит. А вот комплексная работа, в которой проверяют гипотезы, чистят данные и делают выводы, — полноценный корреляционный анализ.
Этапы проведения корреляционного анализа
Чтобы исследование было научным и достоверным, оно должно проходить по определённому пайплайну из семи шагов:
- Сбор данных: собираем наблюдения. Важно, чтобы данных было достаточно — обычно статистика начинает нормально работать от 30 наблюдений.
- Очистка и предобработка: удаляем пустые значения, исправляем опечатки, обрабатываем выбросы.
- Визуализация: обязательно рисуем график. Глаза — эволюционно одобренный инструмент для поиска аномалий. Если график показывает U-образную кривую, сразу понятно, что стандартные линейные методы здесь не сработают.
- Проверка распределения: проводим тесты (например, тест Шапиро-Уилка), чтобы понять, нормально ли распределены данные.
- Выбор коэффициента: нормальное распределение и непрерывные числа? Берём Пирсона. Данные с выбросами или ранговые? Берём Спирмена.
- Вычисление и интерпретация: получаем значение, смотрим на знак и силу.
- Оценка статистической значимости: нужно доказать, что цифра не получилась случайно. Для этого смотрят на p-value. Если p-value меньше 0.05 — результат статистически значим.
Матрица корреляций
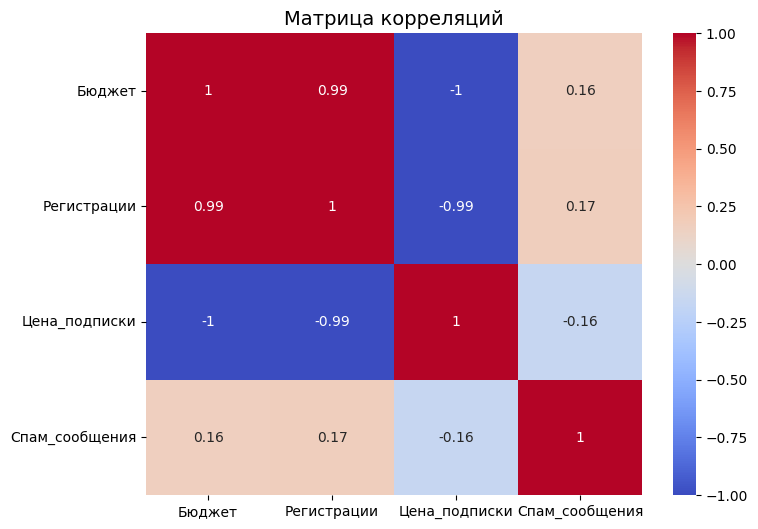
Обычно анализируют не два признака, а целые базы данных. Например, у дата-саентиста есть таблица с параметрами квартир: ценой, площадью, этажом и т. д. Считать связи парами — это долго.
Для этого строят матрицу корреляций. Это сводная таблица, где по вертикали и горизонтали написаны все переменные, а на пересечениях стоят коэффициенты. По диагонали такой матрицы всегда стоят единицы — переменная идеально коррелирует сама с собой.
В Python такую матрицу часто визуализируют в виде тепловой карты. Библиотека раскрашивает сильные положительные связи в ярко-красный цвет, а сильные отрицательные — в ярко-синий. Аналитику достаточно одного взгляда на такую тепловую карту, чтобы понять всю структуру взаимосвязей в данных.
Где применяется корреляционный анализ
Этот статистический метод — базовый инструмент в арсенале любого специалиста, работающего с цифрами.
В Data Science и машинном обучении. Алгоритмы плохо работают, если им на вход подать дублирующие друг друга данные. С помощью матрицы корреляций дата-саентисты находят и удаляют лишние параметры перед обучением нейросетей.
В финансах и инвестициях. Трейдеры собирают портфели из активов, отрицательно коррелирующих друг с другом. Если рынок упадёт, одни акции подешевеют, а другие вырастут — и инвестор останется при своих деньгах. Это основа риск-менеджмента.
В веб-аналитике и маркетинге. Анализ помогает понять, какие действия пользователя на сайте сильнее всего связаны с итоговой покупкой — например, количество просмотренных страниц или время, проведённое в каталоге.
В медицине. Для поиска неочевидных связей между симптомами, образом жизни пациента и реакцией на новые препараты.
Ложная корреляция — главная ошибка при интерпретации
Это ситуация, когда математика показывает железную связь 0,99, но в реальности эти переменные никак друг на друга не влияют. Знаменитый пример из учебников: в США график продаж мороженого идеально совпадает с графиком нападений акул на людей. Растет одно — растет и другое. Значит ли это, что мороженое делает людей вкуснее для акул? Нет. Просто есть скрытый третий фактор — жара. Летом люди и мороженое едят, и в океане купаются.
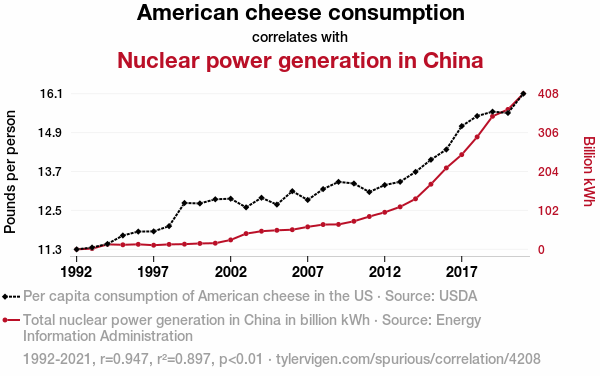
Другой пример: потребление сыра на душу населения в США идеально (r = 0,95) коррелирует с суммарной мощностью атомных реакторов в Китае. Это может быть случайностью, ошибкой малой выборки или совпадением трендов. Всегда включайте здравый смысл.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите скидку 16% на все курсы Практикума. Ей можно воспользоваться до 31 марта.