Когда сервис внезапно ломается, пользователи видят примерно такое:
Но за ошибкой 500 может стоять много разных причин: перегруженные серверы, неудачный релиз или просто переполненный диск. SRE — это попытка сделать стабильность сервиса инженерной задачей, а не результатом ручного труда. В итоге появляется система: измеряем, автоматизируем, улучшаем.
SRE находится между разработкой и эксплуатацией. Смысл в том, что разработчики хотят выкатывать новые возможности сервиса, а бизнес хочет, чтобы ничего не ломалось. SRE помогает найти баланс и сделать так, чтобы скорость не убивала стабильность.
Что такое SRE
Site Reliability Engineering — подход к управлению надёжностью через инженерные методы. Его впервые системно описали в Google, где решили, что эксплуатацию нужно строить так же строго, как разработку кода.

На схеме выше есть Dev Product Area — зона разработки продукта, а также SRE Product Area — инженеры надёжности. Каждой команде разработки соответствует своя SRE-команда, и все работают сообща.
Смысл внешнего цикла в том, что бизнес определяет приоритеты, разработка создаёт фичи, SRE обеспечивает надёжность, а лучшие практики возвращаются в систему. И так по кругу.
Задача SRE — не просто реагировать на сбои, а предотвращать их. Это значит заранее измерять доступность, производительность и ошибки, а потом улучшать систему на основе точных показателей.
Можно привести такой пример: разработчики интернет-магазина добавили новую систему рекомендаций, но после этого сервер стал отвечать дольше. Пользователи уходят, конверсия падает. SRE посмотрит на метрики, найдёт узкое место и предложит решение, чтобы сохранить технические возможности без ущерба для бизнеса.
Основная цель SRE — баланс между инновациями и стабильностью
Если дать разработчикам полную свободу, сервис может меняться каждый день. Но если запретить выпуск новых фич ради стабильности, продукт устареет. SRE ищет золотую середину.
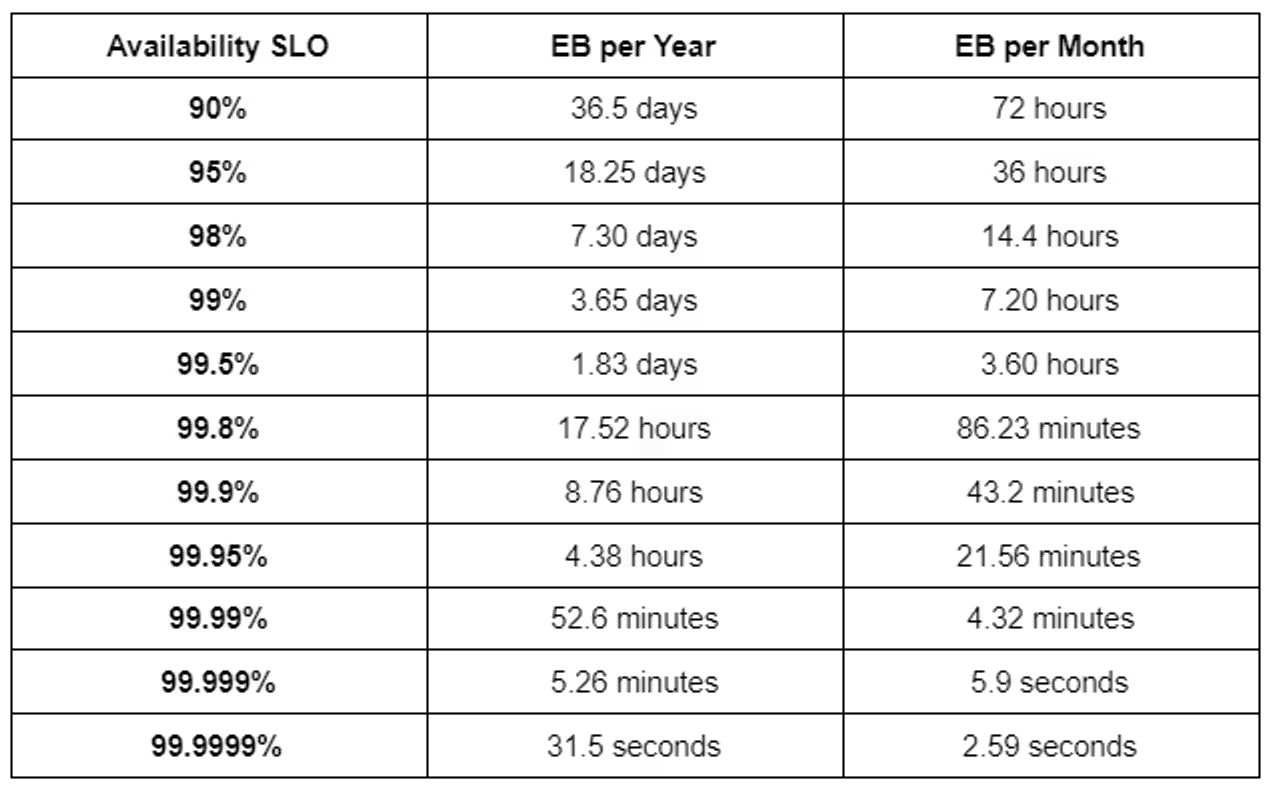
В поиске баланса помогает ввод понятия «допустимого уровня ошибок» — error budget. Например, сервис может быть доступен 99,9% времени. Это означает, что небольшой процент сбоев допустим и даже при этом бизнес будет расти.
Допустим, в месяц сервис работает 43 200 минут. При доступности 99,9% допустимо около 43 минут простоя. Это и есть пространство для экспериментов. Зная это число, команда понимает: если бюджет ошибок уже исчерпан, нужно остановить выпуск новых фич.
Какое реальное время может быть выделено на error budget в разных случаях?
- Многие облачные SaaS-сервисы декларируют доступность 99,9% или 99,95%. Это стандарт для бизнес-приложений, где час простоя неприятен, но не критичен.
- Банки и платежные системы обычно целятся в 99,99% и выше. Для них даже 40 минут простоя в месяц могут означать реальные финансовые потери.
- Для внутренних инструментов компании иногда хватает 99%.
Как выглядит error budget в зависимости от процентов:
Кто такой SRE-инженер и чем он занимается
SRE-инженер занимается смежными задачами. Это не просто администратор серверов и не просто разработчик. Он понимает и код, и инфраструктуру, и бизнес-метрики.
SRE-инженер смотрит на сервис и ищет узкие места, риски и возможные точки отказа. Его задача — сделать сбои редкими, предсказуемыми и управляемыми. Например, он анализирует нагрузку при появлении проблемы, добавляет кэширование или масштабирование и в итоге снижает вероятность сбоя.
«Инженер-универсал»: код, инфраструктура и мониторинг
Как и разработчики, SRE тоже пишет код, но обычно для автоматизации процессов: деплой, бэкапы, мониторинг. Например, простой health-check для получения ответа от сервера, который выполняется раз в определённый промежуток времени. Система мониторинга запрашивает результат выполнения такого кода каждую минуту. Если статус показывает поломку, срабатывает сигнал тревоги.
А ещё SRE понимает, как работает облако, контейнеры, CI/CD и сетевые настройки. Он соединяет всё это в единую систему.
Обязанности SRE-инженера
SRE формулирует уровни доступности и цели по качеству сервиса. Эти метрики показывают реальные договоренности между бизнесом и командой разработки.
Когда происходит инцидент, например падение базы или ошибка релиза, SRE участвует в его устранении. Но главное — он находит причину и делает так, чтобы инцидент либо не повторялся вообще, либо вероятность его повторения была минимальна. Например, если на пике нагрузки сервер упал, SRE проанализирует, почему не было автомасштабирования и как это предотвратить в будущем.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами, и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Ключевые принципы и практики SRE
SRE строится на измерениях, автоматизации и культуре ответственности без поиска виноватых. Это инженерный подход к надёжности. Если что-то можно измерить, это нужно измерить. Если процесс повторяется больше двух раз, его нужно автоматизировать. Если случился сбой, нужно разобрать его системно, найти причины и сделать так, чтобы вероятность повторного сбоя была минимальна.
Измерение всего
Сначала посмотрим такую схему:
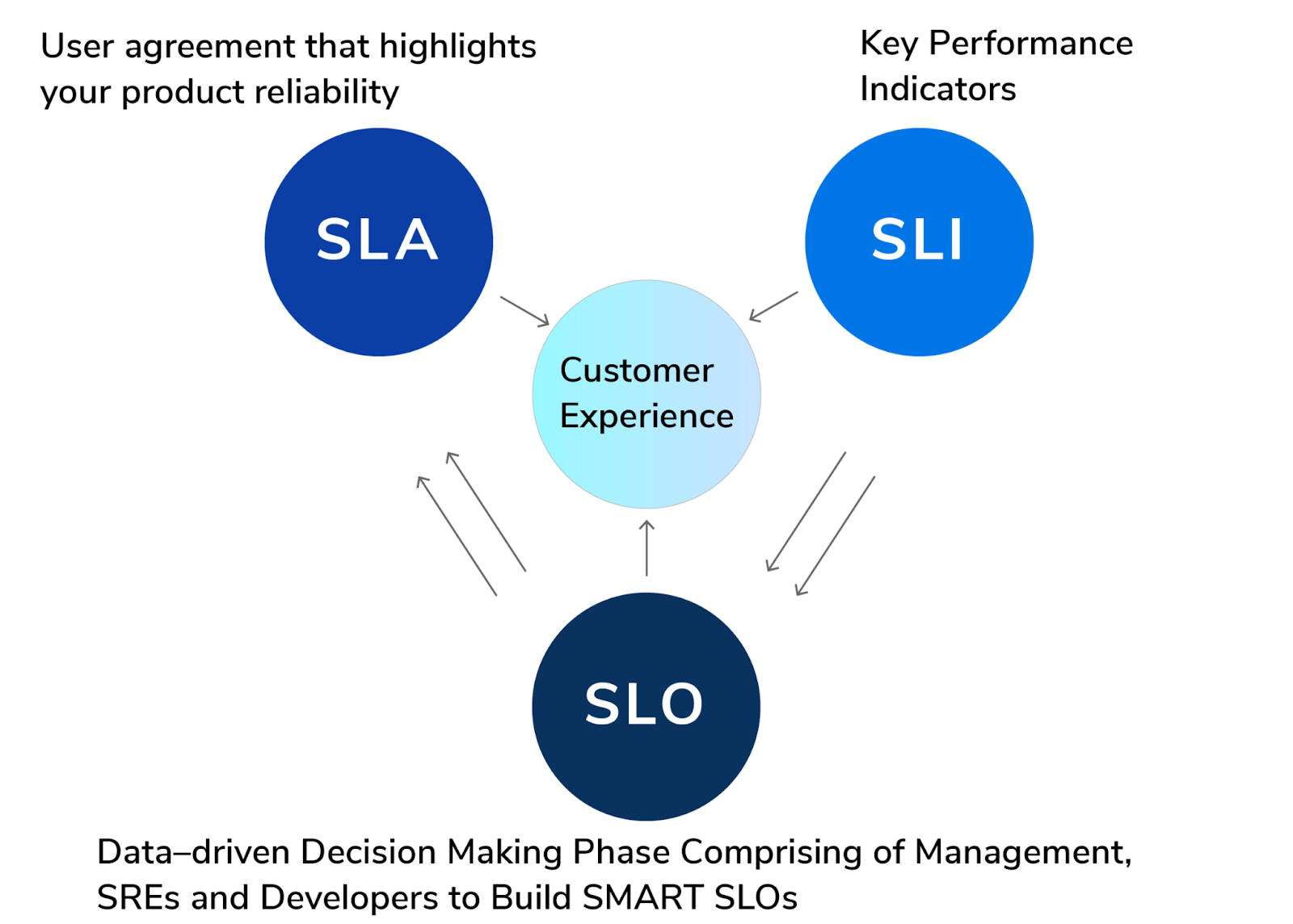
Теперь разберём, что здесь изображено.
Customer Experience — опыт клиентов. Это самое важное: как быстро работает сервис, есть ли какие-то поломки, можно ли им вообще пользоваться.
SLI (Service Level Indicator): индикатор уровня обслуживания. Ключевые метрики, которые показывают реальное состояние системы. Это процент успешных запросов, среднее время ответа, количество ошибок сервера.
SLO (Service Level Objective): целевой уровень обслуживания. Цель, которую ставит себе команда, например: «95% запросов должны обрабатываться быстрее 300 мс». Это уже не договор с клиентом, а внутренняя планка качества.
Команда строит SLO на основании SLI.
SLA (Service Level Agreement): соглашение об уровне обслуживания. Это внешний договор, официальное обещание клиенту. На схеме написано: «Пользовательское соглашение, которое фиксирует надёжность вашего продукта».
Чтобы обещать SLA, нужно понимать SLO.
Автоматизация рутинного труда
Ручное выполнение задач — это риск. Человек может забыть шаг, перепутать сервер или версию. Для повышения безопасности SRE старается автоматизировать все повторяющиеся процессы. Вот что это может быть.
Масштабирование. Когда нагрузка растёт, добавляются новые реплики сервиса. Когда падает, лишние выключаются.
Автоматическое восстановление. Если контейнер упал, он сам перезапускается. А если сервер стал недоступен, трафик переключается на другой.
Мониторинг. Не человек сидит и смотрит на графики, а система сама отправляет сигнал, если что-то пошло не так.
Постепенное внедрение изменений и постмортемы
Релизы можно публиковать постепенно — сначала на 5% пользователей, потом на 50%, затем на всех. Это снижает масштаб возможного сбоя.
Если произошёл инцидент, проводится разбор ситуации, но без поиска виноватых. Например, если релиз сломал авторизацию, анализируют, были ли тесты, мониторинг и фича-флаги.
Какие есть стратегии обновлений:
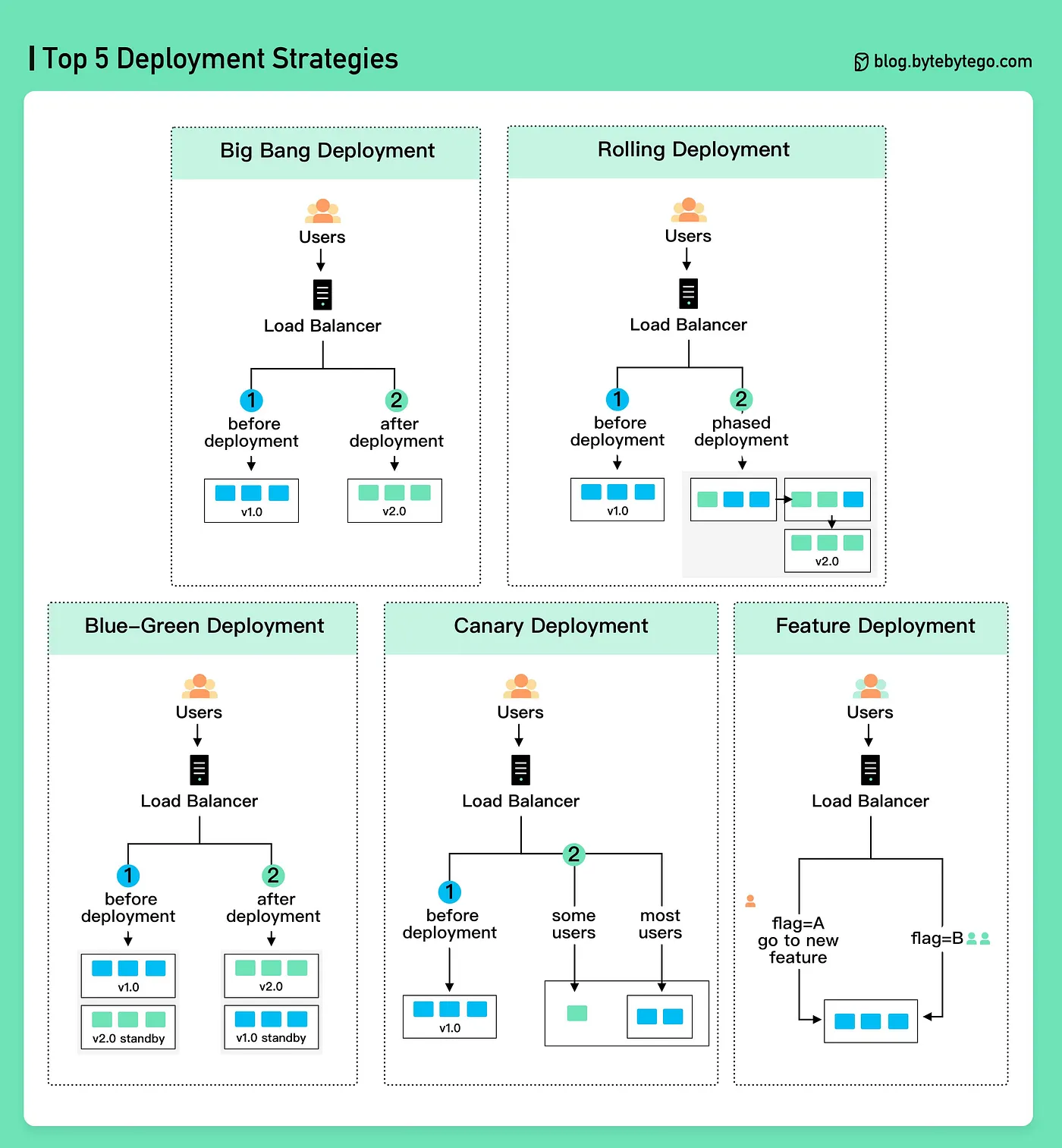
Дальше разбираем, как всё это работает. Load Balancer здесь — балансировщик нагрузки, который распределяет трафик между серверами.
Big Bang Deployment. Все пользователи сразу переходят на новую версию. Просто, но если сломалось, ломается у всех. Используется редко, обычно в маленьких проектах.
Rolling Deployment. Серверы обновляются по очереди. Часть серверов работает на старой версии v1.0, часть на новой v2.0, и постепенно на новую версию переходят все. Плюс в том, что нет полномасштабного времени простоя для обновления, но зато у разных пользователей временно работают разные версии.
Blue–Green Deployment. Идея в том, что всегда есть две готовые среды: Blue с текущей версией и Green — с новой. Трафик целиком переключается на новую среду. Это позволяет быстро выкатить обновления, но минус в стоимости: нужно содержать две среды. Такая модель часто используется в критичных системах.
Canary Deployment. Сначала новую версию получает только небольшой процент пользователей. Если метрики хорошие, обновление продолжается. Здесь минимальный риск, но эта система сложнее в настройке.
Feature Deployment. Код новой функции уже в рабочей версии, но включается выборочно: flag A включает новую версию, flag B — старую. Получается, что обновление можно включать и выключать без релиза. Минус в том, что feature deployment усложняет код.
SRE vs DevOps: в чём разница и что выбрать
DevOps — философия сотрудничества между разработкой и эксплуатацией. SRE — более конкретная инженерная реализация этой же идеи.
То есть DevOps говорит: «Убираем барьеры между командами». А SRE добавляет к этому конкретные метрики, бюджеты ошибок и правила релизов.
Популярные инструменты в арсенале SRE-инженера
SRE использует инструменты мониторинга, автоматизации и управления инфраструктурой. Они помогают видеть состояние системы в реальном времени.
Мониторинг и алертинг: Prometheus, Grafana, Datadog
Prometheus собирает метрики, Grafana визуализирует их в виде графиков, а Datadog даёт облачную платформу мониторинга.
Как работает: если количество ошибок резко растёт, система отправляет алерт, и команда узнаёт о проблеме раньше пользователей. Это как приборная панель автомобиля: если загорелся индикатор перегрева, вы остановитесь до поломки.
Управление конфигурацией и инфраструктурой: Terraform, Ansible, Kubernetes
Инструменты управления всеми компонентами системы.
Terraform позволяет описывать инфраструктуру в виде кода. Вместо ручного создания серверов есть декларативные файлы, где разработчик может задать точные инструкции.
Ansible автоматизирует настройку серверов, а Kubernetes управляет контейнерами и масштабированием.
Централизованное логирование: ELK Stack (Elasticsearch, Logstash, Kibana)
ELK Stack собирает логи со всех сервисов в одно место. Это удобно, когда микросервисов много. Если пользователь жалуется на ошибку, SRE может быстро найти соответствующую запись.
Как внедрить SRE-практики в свою компанию
SRE предполагает постепенное изменение процессов. Поэтому не нужно сразу нанимать команду инженеров и переписывать всё на Kubernetes. Лучше начать с малого.
Шаг 1: Определите ваши самые критические сервисы и установите для них SLO
Не все системы одинаково важны. Падение лендинга и падение платёжного сервиса — разные по последствиям события.
Определите ключевой сервис и задайте для него измеримую цель, например, 99,5% успешных запросов.
Шаг 2: Начните с малого — автоматизируйте одну повторяющуюся операцию
Маленькие улучшения накапливаются и формируют устойчивую систему. Если каждый день кто-то вручную перезапускает сервис — это явный сигнал о том, что нужна автоматизация: простой скрипт, автоперезапуск или CI/CD.
Шаг 3: Внедрите культуру blameless postmortem после следующего инцидента
Когда что-то сломается, не ищите виноватых. Вместо этого соберите команду и разберите: что произошло, почему и какие изменения нужны.
Так формируется зрелость инженерной культуры. Надёжность — это необязательно отсутствие ошибок, а способность системы и команды на них правильно реагировать.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.