








Продолжаем проект с распознаванием лиц и компьютерным зрением. Сегодня мы научим скрипт распознавать возраст и пол человека по фотографии.
Вот что мы уже сделали к этому моменту:
Короткая версия для быстрого погружения:
- Для распознавания лица компьютер должен получить изображение — через камеру или готовый файл.
- Компьютер использует особый алгоритм, который разбивает изображение на прямоугольники.
- С помощью этих прямоугольников алгоритм пытается найти на картинке знакомые ему переходы между светлыми и тёмными областями.
- Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека.
- Чтобы программистам каждый раз не писать свой код распознавания с нуля, сделали специальную библиотеку компьютерного зрения — cv2. Если в неё загрузить заранее подготовленные параметры лиц, она сможет распознавать их намного точнее.
- С помощью этой библиотеки можно находить на картинке не только лица, но и другие предметы — для этого нужно использовать дополнительные библиотеки либо обучать систему самому.
- Если то, что нейросеть распознала как лицо, отправить в другую нейросеть в этом же скрипте, то можно сразу получить её оценку. Например, что она думает про пол и возраст человека в кадре.
Вот текущий код скрипта — с ним мы будем сегодня работать.
# подключаем библиотеку компьютерного зрения
import cv2
# функция определения лиц
def highlightFace(net, frame, conf_threshold=0.7):
# делаем копию текущего кадра
frameOpencvDnn=frame.copy()
# высота и ширина кадра
frameHeight=frameOpencvDnn.shape[0]
frameWidth=frameOpencvDnn.shape[1]
# преобразуем картинку в двоичный пиксельный объект
blob=cv2.dnn.blobFromImage(frameOpencvDnn, 1.0, (300, 300), [104, 117, 123], True, False)
# устанавливаем этот объект как входной параметр для нейросети
net.setInput(blob)
# выполняем прямой проход для распознавания лиц
detections=net.forward()
# переменная для рамок вокруг лица
faceBoxes=[]
# перебираем все блоки после распознавания
for i in range(detections.shape[2]):
# получаем результат вычислений для очередного элемента
confidence=detections[0,0,i,2]
# если результат превышает порог срабатывания — это лицо
if confidence>conf_threshold:
# формируем координаты рамки
x1=int(detections[0,0,i,3]*frameWidth)
y1=int(detections[0,0,i,4]*frameHeight)
x2=int(detections[0,0,i,5]*frameWidth)
y2=int(detections[0,0,i,6]*frameHeight)
# добавляем их в общую переменную
faceBoxes.append([x1,y1,x2,y2])
# рисуем рамку на кадре
cv2.rectangle(frameOpencvDnn, (x1,y1), (x2,y2), (0,255,0), int(round(frameHeight/150)), 8)
# возвращаем кадр с рамками
return frameOpencvDnn,faceBoxes
# загружаем веса для распознавания лиц
faceProto="opencv_face_detector.pbtxt"
# и конфигурацию самой нейросети — слои и связи нейронов
faceModel="opencv_face_detector_uint8.pb"
# точно так же загружаем модели для определения пола и возраста
genderProto="gender_deploy.prototxt"
genderModel="gender_net.caffemodel"
ageProto="age_deploy.prototxt"
ageModel="age_net.caffemodel"
# настраиваем свет
MODEL_MEAN_VALUES=(78.4263377603, 87.7689143744, 114.895847746)
# итоговые результаты работы нейросетей для пола и возраста
genderList=['Male ','Female']
ageList=['(0-2)', '(4-6)', '(8-12)', '(15-20)', '(25-32)', '(38-43)', '(48-53)', '(60-100)']
# запускаем нейросеть по распознаванию лиц
faceNet=cv2.dnn.readNet(faceModel,faceProto)
# и запускаем нейросети по определению пола и возраста
genderNet=cv2.dnn.readNet(genderModel,genderProto)
ageNet=cv2.dnn.readNet(ageModel,ageProto)
# получаем видео с камеры
video=cv2.VideoCapture(0)
# пока не нажата любая клавиша — выполняем цикл
while cv2.waitKey(1)<0:
# получаем очередной кадр с камеры
hasFrame,frame=video.read()
# если кадра нет
if not hasFrame:
# останавливаемся и выходим из цикла
cv2.waitKey()
break
# определяем лица в кадре
resultImg,faceBoxes=highlightFace(faceNet,frame)
# перебираем все найденные лица в кадре
for faceBox in faceBoxes:
# получаем изображение лица на основе рамки
face=frame[max(0,faceBox[1]):
min(faceBox[3],frame.shape[0]-1),max(0,faceBox[0])
:min(faceBox[2], frame.shape[1]-1)]
# получаем на этой основе новый бинарный пиксельный объект
blob=cv2.dnn.blobFromImage(face, 1.0, (227,227), MODEL_MEAN_VALUES, swapRB=False)
# отправляем его в нейросеть для определения пола
genderNet.setInput(blob)
# получаем результат работы нейросети
genderPreds=genderNet.forward()
# выбираем пол на основе этого результата
gender=genderList[genderPreds[0].argmax()]
# отправляем результат в переменную с полом
print(f'Gender: {gender}')
# делаем то же самое для возраста
ageNet.setInput(blob)
agePreds=ageNet.forward()
age=ageList[agePreds[0].argmax()]
print(f'Age: {age[1:-1]} years')
# добавляем текст возле каждой рамки в кадре
cv2.putText(resultImg, f'{gender}, {age}', (faceBox[0], faceBox[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0,255,255), 2, cv2.LINE_AA)
# выводим итоговую картинку
cv2.imshow("Detecting age and gender", resultImg)
Что делаем
Учим скрипт определять возраст и пол на изображениях, а не на видео с камеры. Для этого нам понадобятся аргументы при вызове — с их помощью мы скажем скрипту, где именно нужно искать лица.
После этого мы сможем скормить скрипту фотографию Моны Лизы и получить неожиданный результат:


Можно представить, что аргументы — это текстовая настройка программы. Когда мы работаем в программе с графическим интерфейсом, эта настройка делается кнопками и ползунками, а когда работаем с командной строкой — текстовыми аргументами. Задача аргументов — передать программе дополнительные параметры, которые ей нужно учесть в работе.
Например, если мы в командной строке просто напишем python или python3, то попадём в режим выполнения python-команд. А если мы укажем аргумент при вызове, например имя скрипта, то Python поймёт, что мы хотим не вводить команды вручную, а выполнить этот файл:
python3 script.py ← здесь script.py — это аргумент для программы python3Ещё мы сталкивались с аргументами, когда вручную генерировали картинки с помощью Stable Diffusion:
python scripts/txt2img.py --prompt "photo of a programmer at a desktop in the style of the game cyberpunk 2077" --ckpt v2-1_512-ema-pruned.ckpt --config configs/stable-diffusion/v2-inference-v.yaml --H 512 --W 512
Переведём это в более читаемый вид:
python scripts/txt2img.py
--prompt "photo of a programmer at a desktop in the style of the game cyberpunk 2077"
--ckpt v2-1_512-ema-pruned.ckpt
--config configs/stable-diffusion/v2-inference-v.yaml
--H 512
--W 512
Всё, что выделено жирным, — это аргументы, которые говорят нейросети:
- что мы от неё хотим (prompt);
- где лежат веса (ckpt);
- настройку сети (config);
- какого размера должны быть итоговые картинки (h и w).
Добавляем парсер аргументов в python-скрипт
Чтобы программа умела работать с аргументами при вызове, её нужно этому научить: добавить специальный парсер аргументов и привязать разные аргументы к нужным действиям внутри программы. Чаще всего для этого используется стандартный модуль argparse, который подключается так:
# подключаем модуль для работы с аргументами при вызове
import argparse
Так как мы хотим научить скрипт работать с фотографиями, сделаем отдельный параметр --image, чтобы после него можно было указать название файла с картинкой:
# подключаем парсер аргументов командной строки
parser=argparse.ArgumentParser()
# добавляем аргумент для работы с изображениями
parser.add_argument('--image')
# сохраняем аргументы в отдельную переменную
args=parser.parse_args()Мы больше не указываем никаких параметров, потому что это необязательный аргумент — если программу запустить без него, то она выполнится как обычно.







Обрабатываем параметры в коде
Логика новой версии проекта такая:
- если при запуске мы ничего дополнительно не указывали, то берём картинку с камеры и распознаём всё там;
- если указан параметр --image, то вместо камеры берём файл и находим лица там.
Чтобы такое сделать, нужно заменить строчку:
# получаем видео с камеры
video=cv2.VideoCapture(0)
на такую:
# если был указан аргумент с картинкой — берём картинку как источник
video=cv2.VideoCapture(args.image if args.image else 0)
Если перевести новую строчку на понятный язык, она будет звучать так:
«Посмотри, указан ли параметр --image при запуске программы. Если указан — проверь, есть ли после него имя файла. Если есть — используй его в качестве основы для распознавания лиц».
Когда мы просто запустим скрипт из среды разработки, он будет работать как и раньше — брать картинку с камеры и искать лица там. Но если мы запустим скрипт из командной строки и попросим его обработать картинку, то вместо камеры мы получим разметку с лицами на фотографии. Найдём в интернете фотографию портрета Моны Лизы, положим в ту же папку, что и исходный код, и отдадим её скрипту такой командой:
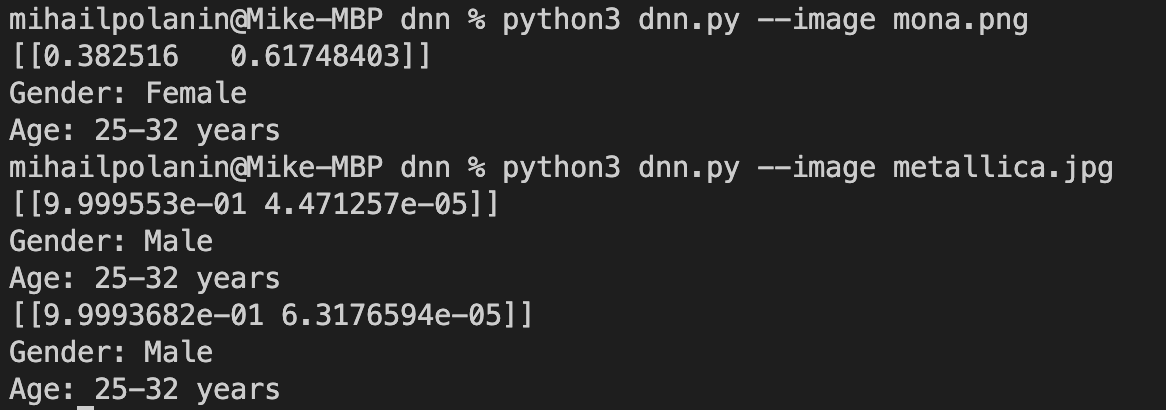
python3 dnn.py --image mona.png

Любопытно, что в этот раз модель распознала Мону Лизу как женщину — получается, в этот раз связи в узлах нейросети совпали так, что победил ответ «женщина».
Если мы добавим вывод результатов определения пола, то увидим такое:


Получается, сейчас нейросеть на 0,38 единицы уверена, что перед ней мужчина и на 0,62 — что женщина. Что это значит:
У нашей нейросети есть два выходных узла «Мужчина» и «Женщина». В результате обработки картинки на каждом узле появляется число от 0 до 1. Если в узле «Мужчина» число большое, мы предполагаем, что нейросеть увидела на этой фотографии мужчину. И наоборот.
Само по себе число нам не так важно, сколько разница между этими двумя числами. Например, если в первом узле уверенность 0,7, а во втором — 0,00001 — очевидно, что активировался первый узел, то есть нейронка решила, что перед ней мужчина.
Что мы видим здесь: нейронка на 38% уверена, что перед ней мужчина и на 61% — что женщина. Разница даже не в два раза. Уверенности особо нет.
Короче: нейронка не может ничего достоверно сказать про Мону Лизу. Перед ней вроде женщина, но вроде и мужчина. Чтобы быть уверенной, нейросеть должна увидеть разницу между узлами хотя бы в 10 раз. А здесь разница в полтора раза всего.
Так как алгоритм не настроен отвечать «Не уверен», он просто берёт самое большое значение узла и выводит его. И получается, что один раз на одной картинке нейросеть видит в Моне Лизе женщину, а на другой — мужчину. Хотя на самом деле она ничего не понимает.
Ещё одно подтверждение, что нейронки — это просто математика.
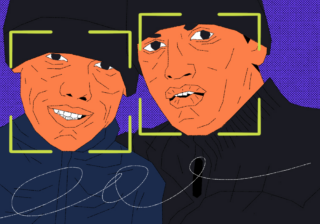
Теперь усложним задачу и попросим обработать фото группы «Металлика». Видно, что закрытые глаза и сложное освещение сбивают простые алгоритмы с толку и половина лиц просто не нашлась:


При этом в тех, кого нейросеть распознала, она уверена абсолютно: перевес значений пола более чем в 1000 раз. Про возраст вообще не спрашивайте, точность здесь просто никуда не годится.

# подключаем библиотеку компьютерного зрения
import cv2
# подключаем модуль для работы с аргументами при вызове
import argparse
# подключаем парсер аргументов командной строки
parser=argparse.ArgumentParser()
# добавляем аргумент для работы с изображениями
parser.add_argument('--image')
# сохраняем аргумент в отдельную переменную
args=parser.parse_args()
# прописываем цвет по умолчанию
color = (0,255,0)
# функция определения лиц
def highlightFace(net, frame, conf_threshold=0.7):
# делаем копию текущего кадра
frameOpencvDnn=frame.copy()
# высота и ширина кадра
frameHeight=frameOpencvDnn.shape[0]
frameWidth=frameOpencvDnn.shape[1]
# преобразуем картинку в двоичный пиксельный объект
blob=cv2.dnn.blobFromImage(frameOpencvDnn, 1.0, (300, 300), [104, 117, 123], True, False)
# устанавливаем этот объект как входной параметр для нейросети
net.setInput(blob)
# выполняем прямой проход для распознавания лиц
detections=net.forward()
# переменная для рамок вокруг лица
faceBoxes=[]
# перебираем все блоки после распознавания
for i in range(detections.shape[2]):
# получаем результат вычислений для очередного элемента
confidence=detections[0,0,i,2]
# если результат превышает порог срабатывания — это лицо
if confidence>conf_threshold:
# формируем координаты рамки
x1=int(detections[0,0,i,3]*frameWidth)
y1=int(detections[0,0,i,4]*frameHeight)
x2=int(detections[0,0,i,5]*frameWidth)
y2=int(detections[0,0,i,6]*frameHeight)
# добавляем их в общую переменную
faceBoxes.append([x1,y1,x2,y2])
# рисуем рамку на кадре
cv2.rectangle(frameOpencvDnn, (x1,y1), (x2,y2), color, int(round(frameHeight/150)), 8)
# возвращаем кадр с рамками
return frameOpencvDnn,faceBoxes
# загружаем веса для распознавания лиц
faceProto="opencv_face_detector.pbtxt"
# и конфигурацию самой нейросети — слои и связи нейронов
faceModel="opencv_face_detector_uint8.pb"
# точно так же загружаем модели для определения пола и возраста
genderProto="gender_deploy.prototxt"
genderModel="gender_net.caffemodel"
ageProto="age_deploy.prototxt"
ageModel="age_net.caffemodel"
# настраиваем свет
MODEL_MEAN_VALUES=(78.4263377603, 87.7689143744, 114.895847746)
# итоговые результаты работы нейросетей для пола и возраста
genderList=['Male ','Female']
ageList=['(0-2)', '(4-6)', '(8-12)', '(15-20)', '(25-32)', '(38-43)', '(48-53)', '(60-100)']
# запускаем нейросеть по распознаванию лиц
faceNet=cv2.dnn.readNet(faceModel,faceProto)
# и запускаем нейросети по определению пола и возраста
genderNet=cv2.dnn.readNet(genderModel,genderProto)
ageNet=cv2.dnn.readNet(ageModel,ageProto)
# если был указан аргумент с картинкой — берём картинку как источник
video=cv2.VideoCapture(args.image if args.image else 0)
# пока не нажата любая клавиша — выполняем цикл
while cv2.waitKey(1)<0:
# получаем очередной кадр с камеры
hasFrame,frame=video.read()
# если кадра нет
if not hasFrame:
# останавливаемся и выходим из цикла
cv2.waitKey()
break
# определяем лица в кадре
resultImg,faceBoxes=highlightFace(faceNet,frame)
# перебираем все найденные лица в кадре
for faceBox in faceBoxes:
# получаем изображение лица на основе рамки
face=frame[max(0,faceBox[1]):
min(faceBox[3],frame.shape[0]-1),max(0,faceBox[0])
:min(faceBox[2], frame.shape[1]-1)]
# получаем на этой основе новый бинарный пиксельный объект
blob=cv2.dnn.blobFromImage(face, 1.0, (227,227), MODEL_MEAN_VALUES, swapRB=False)
# отправляем его в нейросеть для определения пола
genderNet.setInput(blob)
# получаем результат работы нейросети
genderPreds=genderNet.forward()
# выбираем пол на основе этого результата
gender=genderList[genderPreds[0].argmax()]
# отправляем результат в переменную с полом
print(f'Gender: {gender}')
# делаем то же самое для возраста
ageNet.setInput(blob)
agePreds=ageNet.forward()
age=ageList[agePreds[0].argmax()]
print(f'Age: {age[1:-1]} years')
# добавляем текст возле каждой рамки в кадре
cv2.putText(resultImg, f'{gender}, {age}', (faceBox[0], faceBox[1]-10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0,255,255), 2, cv2.LINE_AA)
# выводим итоговую картинку
cv2.imshow("Detecting age and gender", resultImg)Что дальше
А дальше будем учить нейросеть запоминать наше лицо — посмотрим, как проходит процесс обучения и что для этого нужно.






















