У нас уже есть большой цикл про компьютерное зрение и распознавание лиц. В этом цикле мы научились видеть лицо человека, определять примерный возраст и пол, работать с веб-камерой и с файлами. Если не читали, можно начать сейчас:
Пока что наш алгоритм не умеет различать разных людей в кадре. Максимум — сказать, что это «мужчина, столько-то лет», а кто конкретно — нет.
Чтобы нейронка научилась узнавать вас по лицу, нужно создать собственную модель распознавания лиц и скормить её нейросети. Тогда она сможет определять и подписывать имя человека в кадре. Сегодня мы сделаем первую часть — соберём датасет и обучим на нём нашу нейросеть. А во второй части прикрутим новую модель к алгоритмам распознавания.
- Для распознавания лица компьютер должен получить изображение — через камеру или готовый файл.
- Компьютер использует особый алгоритм, который разбивает изображение на прямоугольники.
- С помощью этих прямоугольников алгоритм пытается найти на картинке знакомые переходы между светлыми и тёмными областями.
- Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека.
- Чтобы программистам каждый раз не писать свой код распознавания с нуля, сделали библиотеку компьютерного зрения — cv2. Если в неё загрузить заранее подготовленные параметры лиц, она сможет распознавать их намного точнее.
- С помощью этой библиотеки можно находить на картинке не только лица, но и другие предметы — для этого нужно использовать дополнительные библиотеки либо обучать систему самому.
- Чтобы нейросеть могла понять, кто именно перед ней, её тоже нужно этому обучить отдельно.
Что нужно для обучения нейросети
Чтобы научить нейросеть узнавать конкретных людей в кадре, нужно:
- Собрать датасет.
- Обучить нейросеть на этом датасете и выгрузить результат обучения в отдельный файл.
Датасет в нашем случае — это набор фотографий. Фото должны быть подобраны так, чтобы лицо было в разных ракурсах или с разным освещением. Чем больше фото, тем точнее обучение. Идеально, если по имени файла сразу будет понятно, какие фото к какому человеку относятся.
Когда датасет будет собран, мы отдадим его нейросети — она распознает все лица и построит их модель, которую можно сохранить в отдельном файле. Если этот файл потом отдать другой нейросети, она сможет понять, кто именно находится перед ней в кадре.
Для проекта нам понадобится Python: как установить Python на компьютер и начать на нём писать.


Подготовка
В папке, где будет лежать скрипт, нужно создать две папки:
- dataSet,
- trainer.
В первой папке будут лежать фотографии, на которых будет учиться нейросеть, а во второй будут результаты этого обучения.
Ещё нужно скачать файл haarcascade_frontalface_default.xml и положить его туда же, где и скрипт. Это модель распознавания лиц по примитивам Хаара.







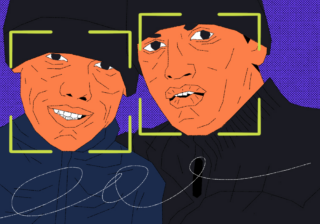
Собираем датасет
В коммерческих проектах датасет собирают долго и из разных источников, а потом вручную проверяют каждое фото, подходит оно или нет. Чтобы не тратить на это время, используем такой лайфхак: мы сгенерируем датасет из кадров с камеры. Для этого мы запустим захват видео и каждые 100 миллисекунд будем брать новый кадр и запоминать лицо оттуда.
Точно так же работает разблокировка по лицу с помощью камеры в Андроиде: телефон просит покрутить головой перед камерой, а сам в это время делает много снимков, а потом тренирует модель распознавания.
Сначала подключим все нужные библиотеки:
# подключаем библиотеку машинного зрения
import cv2
# библиотека для вызова системных функций
import os
Сразу подключим модель с примитивами Хаара к нейросети — это тот самый файл, который скачивали отдельно.
Чтобы нейросеть в процессе обучения знала, кому принадлежат эти фотографии, добавим параметр id. Это будет внутренний номер пользователя, который мы потом превратим в настоящее имя:
# получаем путь к этому скрипту
path = os.path.dirname(os.path.abspath(__file__))
# указываем, что мы будем искать лица по примитивам Хаара
detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
# счётчик изображений
i=0
# расстояния от распознанного лица до рамки
offset=50
# запрашиваем номер пользователя
name=input('Введите номер пользователя: ')
# получаем доступ к камере
video=cv2.VideoCapture(0)Последнее, что осталось, — сделать цикл, который соберёт как минимум 30 фотографий, найдёт на них лица и запишет их файл с нужными именами. Так как примитивы Хаара — это чёрно-белые прямоугольники, для простоты и ускорения работы мы тоже будем переводить кадры в ч/б. Чтобы потом в процессе тренировки нейросети было проще, мы будем сохранять не кадр с камеры целиком, а только лицо:
# запускаем цикл
while True:
# берём видеопоток
ret, im =video.read()
# переводим всё в ч/б для простоты
gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# настраиваем параметры распознавания и получаем лицо с камеры
faces=detector.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100))
# обрабатываем лица
for(x,y,w,h) in faces:
# увеличиваем счётчик кадров
i=i+1
# записываем файл на диск
cv2.imwrite("dataSet/face-"+name +'.'+ str(i) + ".jpg", gray[y-offset:y+h+offset,x-offset:x+w+offset])
# формируем размеры окна для вывода лица
cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2)
# показываем очередной кадр, который мы запомнили
cv2.imshow('im',im[y-offset:y+h+offset,x-offset:x+w+offset])
# делаем паузу
cv2.waitKey(100)
# если у нас хватает кадров
if i>30:
# освобождаем камеру
video.release()
# удалаяем все созданные окна
cv2.destroyAllWindows()
# останавливаем цикл
breakСохраняем скрипт как face_gen.py — потому что для тренировки нам понадобится отдельный код. После запуска в терминале нужно будет ввести номер пользователя — им может быть любое число. Во время работы скрипт покажет нам 30 кадров, которые он сделал, а в папке dataSet появятся новые файлы — это значит, что мы всё сделали правильно:

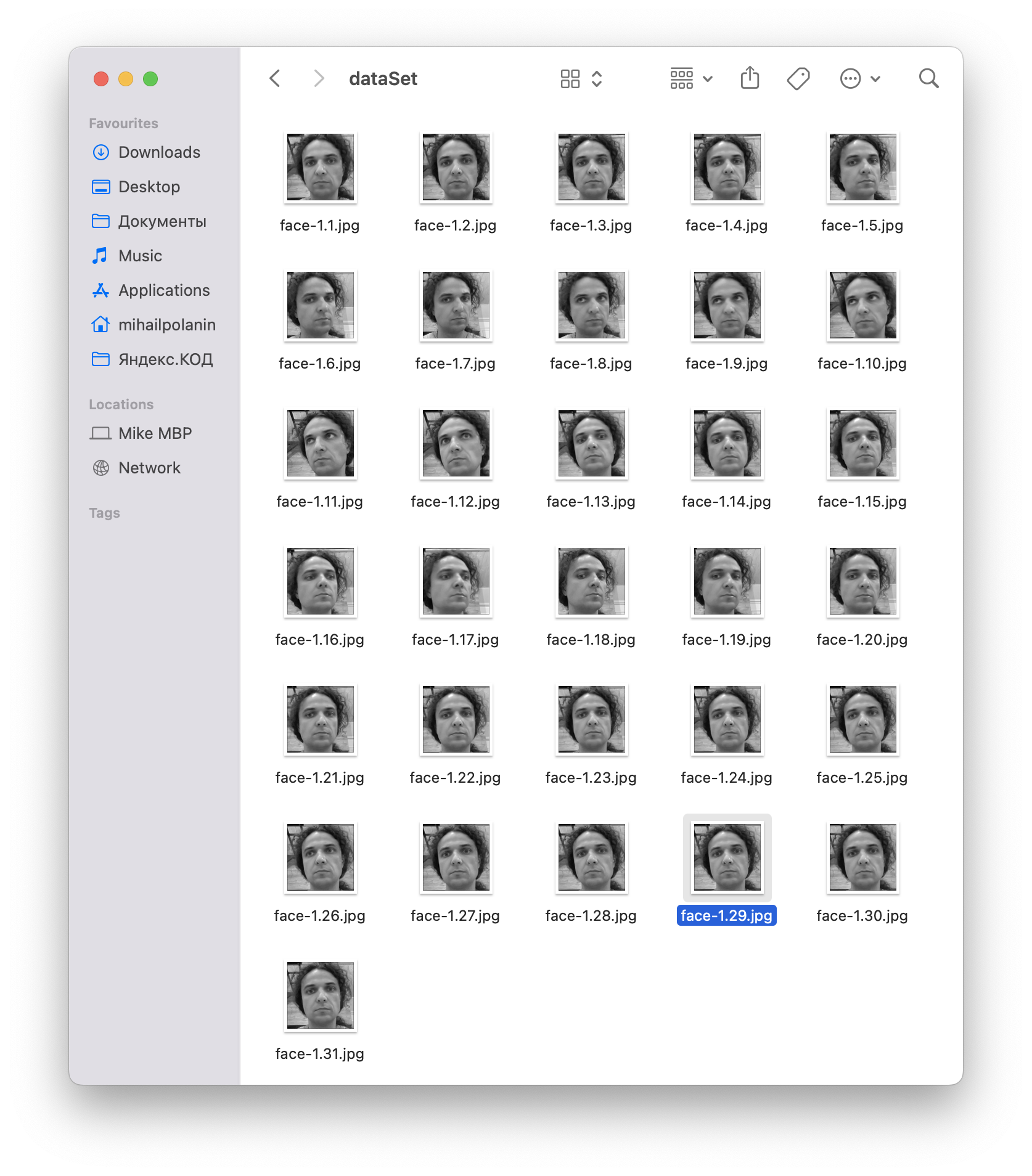
Обучаем нейросеть
Создаём новый файл face_train.py — он будет отвечать за обучение на собранном датасете. Так как мы сами придумывали формат имени файла, то это сильно упростит нам задачу: цифра, которая стоит после дефиса и до первой точки, и будет id пользователя:
face-1.29.jpg ← здесь после дефиса и до первой точки стоит число 1, значит эта фотография относится к пользователю с id = 1.
Начало скрипта будет похоже на предыдущее, добавятся только две библиотеки — для обучения нейросети и для работы с изображениями:
# подключаем библиотеку компьютерного зрения
import cv2
# библиотека для вызова системных функций
import os
# для обучения нейросетей
import numpy as np
# встроенная библиотека для работы с изображениями
from PIL import Image
# получаем путь к этому скрипту
path = os.path.dirname(os.path.abspath(__file__))
# создаём новый распознаватель лиц
recognizer = cv2.face.LBPHFaceRecognizer_create()
# указываем, что мы будем искать лица по примитивам Хаара
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
# путь к датасету с фотографиями пользователей
dataPath = path+r'/dataSet'Теперь самое интересное — собираем картинки и id пользователя из датасета. Для простоты id будем называть подписью — если у нас не будет сведений о том, что за человек на фотографиях, будем просто выводить номер пользователя как подпись.
Логика будет такая:
- Открываем папку с картинками.
- По очереди читаем каждую картинку и переводим её в специальный формат, с которым умеет работать библиотека numpy.
- Получаем id пользователя из имени файла — просто убираем всё до дефиса и после первой точки.
- Определяем лицо на картинке — это будет просто, потому что на картинках и так будут только лица.
- Добавляем лица в список лиц.
- Добавляем id пользователя в список пользователей
- Чтобы было видно, что скрипт работает, на долю секунды будем выводить на экран текущую картинку.
- На выходе получим список с лицами и идентификаторами пользователей, к которым они относятся.
Запишем это в виде кода на Python:
# получаем картинки и подписи из датасета
def get_images_and_labels(datapath):
# получаем путь к картинкам
image_paths = [os.path.join(datapath, f) for f in os.listdir(datapath)]
# списки картинок и подписей на старте пустые
images = []
labels = []
# перебираем все картинки в датасете
for image_path in image_paths:
# читаем картинку и сразу переводим в ч/б
image_pil = Image.open(image_path).convert('L')
# переводим картинку в numpy-массив
image = np.array(image_pil, 'uint8')
# получаем id пользователя из имени файла
nbr = int(os.path.split(image_path)[1].split(".")[0].replace("face-", ""))
# определяем лицо на картинке
faces = faceCascade.detectMultiScale(image)
# если лицо найдено
for (x, y, w, h) in faces:
# добавляем его к списку картинок
images.append(image[y: y + h, x: x + w])
# добавляем id пользователя в список подписей
labels.append(nbr)
# выводим текущую картинку на экран
cv2.imshow("Adding faces to traning set...", image[y: y + h, x: x + w])
# делаем паузу
cv2.waitKey(100)
# возвращаем список картинок и подписей
return images, labelsНаконец, обучаем и сохраняем модель, чтобы её можно было использовать в других проектах. При этом нейросети неважно, сколько пользователей и фотографий будет в датасете — один или тысяча. Она запомнит их все, сопоставит одно с другим и запомнит, как выглядит пользователь под каждым номером. Результат такой обработки сохраним в yml-файле — это один из стандартных форматов для таких моделей:
# получаем список картинок и подписей
images, labels = get_images_and_labels(dataPath)
# обучаем модель распознавания на наших картинках и учим сопоставлять её лица и подписи к ним
recognizer.train(images, np.array(labels))
# сохраняем модель
recognizer.save(path+r'/trainer/trainer.yml')
# удаляем из памяти все созданные окнаы
cv2.destroyAllWindows()
Если после запуска скрипта в папке trainer появился файл trainer.yml — поздравляем, вы только что обучили нейросеть распознавать лицо человека!
# подключаем библиотеку машинного зрения
import cv2
# библиотека для вызова системных функций
import os
# получаем путь к этому скрипту
path = os.path.dirname(os.path.abspath(__file__))
# указываем, что мы будем искать лица по примитивам Хаара
detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
# счётчик изображений
i=0
# расстояния от распознанного лица до рамки
offset=50
# запрашиваем номер пользователя
name=input('Введите номер пользователя: ')
# получаем доступ к камере
video=cv2.VideoCapture(0)
# запускаем цикл
while True:
# берём видеопоток
ret, im =video.read()
# переводим всё в ч/б для простоты
gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# настраиваем параметры распознавания и получаем лицо с камеры
faces=detector.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100))
# обрабатываем лица
for(x,y,w,h) in faces:
# увеличиваем счётчик кадров
i=i+1
# записываем файл на диск
cv2.imwrite("dataSet/face-"+name +'.'+ str(i) + ".jpg", gray[y-offset:y+h+offset,x-offset:x+w+offset])
# формируем размеры окна для вывода лица
cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2)
# показываем очередной кадр, который мы запомнили
cv2.imshow('im',im[y-offset:y+h+offset,x-offset:x+w+offset])
# делаем паузу
cv2.waitKey(100)
# если у нас хватает кадров
if i>30:
# освобождаем камеру
video.release()
# удаляем все созданные окна
cv2.destroyAllWindows()
# останавливаем цикл
break# подключаем библиотеку компьютерного зрения
import cv2
# библиотека для вызова системных функций
import os
# для обучения нейросетей
import numpy as np
# встроенная библиотека для работы с изображениями
from PIL import Image
# получаем путь к этому скрипту
path = os.path.dirname(os.path.abspath(__file__))
# создаём новый распознаватель лиц
recognizer = cv2.face.LBPHFaceRecognizer_create()
# указываем, что мы будем искать лица по примитивам Хаара
faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml")
# путь к датасету с фотографиями пользователей
dataPath = path+r'/dataSet'
# получаем картинки и подписи из датасета
def get_images_and_labels(datapath):
# получаем путь к картинкам
image_paths = [os.path.join(datapath, f) for f in os.listdir(datapath)]
# списки картинок и подписей на старте пустые
images = []
labels = []
# перебираем все картинки в датасете
for image_path in image_paths:
# читаем картинку и сразу переводим в ч/б
image_pil = Image.open(image_path).convert('L')
# переводим картинку в numpy-массив
image = np.array(image_pil, 'uint8')
# получаем id пользователя из имени файла
nbr = int(os.path.split(image_path)[1].split(".")[0].replace("face-", ""))
# определяем лицо на картинке
faces = faceCascade.detectMultiScale(image)
# если лицо найдено
for (x, y, w, h) in faces:
# добавляем его к списку картинок
images.append(image[y: y + h, x: x + w])
# добавляем id пользователя в список подписей
labels.append(nbr)
# выводим текущую картинку на экран
cv2.imshow("Adding faces to traning set...", image[y: y + h, x: x + w])
# делаем паузу
cv2.waitKey(100)
# возвращаем список картинок и подписей
return images, labels
# получаем список картинок и подписей
images, labels = get_images_and_labels(dataPath)
# обучаем модель распознавания на наших картинках и учим сопоставлять её лица и подписи к ним
recognizer.train(images, np.array(labels))
# сохраняем модель
recognizer.save(path+r'/trainer/trainer.yml')
# удаляем из памяти все созданные окнаы
cv2.destroyAllWindows()Что дальше
Теперь у нас всё готово для того, чтобы мы добавили новую модель в скрипт распознавания лиц. Сделаем это в следующий раз и посмотрим, как нейросеть справляется с этой задачей.