Компьютеры Apple с процессорами серии M запускают нейросети без танцев с бубном. В этой статье показываем, как это сделать с минимальными техническими знаниями.
К чему идём
Мы запустим большую языковую модель локально: вы сможете задавать ей текстовые вопросы и получать текстовые ответы.
Дальше можно будет загружать в эту модель свои знания — например, учебники, рабочие регламенты и справочники. Тогда можно будет попросить нейронку дать вам ответ на основании ваших знаний.
Это работает не так круто, как платный ChatGPT, но зато всё будет происходить локально на вашем компьютере.

Общий вид решения
- Скачиваем приложение Ollama, в котором будут исполняться запросы в языковую модель.
- Через Ollama скачиваем модель под наш компьютер.
- Тестируем, что моделька работает в командной строке.
- Устанавливаем Docker, чтобы крутить в нём удобный визуальный интерфейс, а не общаться с нейронкой через командную строку.
- Ставим Open WebUI.
- Тестируем работу через интерфейс.
- Добавляем базу знаний.
- Тестируем.





Что понадобится
Конкретно для этой статьи понадобится компьютер Apple с операционной системой Mac OS и любым процессором серии M. Оптимально, если у вас будет не менее 16 ГБ оперативной памяти (мы тестировали на 32 и 64 ГБ).
Также может заработать на ПК с большой видеокартой, например на 8 ГБ видеопамяти. Но это может быть дорого.
Из последних разработок для ПК нужную нам архитектуру поддерживают новые процессоры AMD Ryzen Al Max+ 395. Там применяется та же архитектура, что и в Apple M, когда процессор и видеокарта используют один и тот же пул памяти. Чтобы проверить работу технологии, мы заказали в Китае мини-ПК с этим процессором, но он ещё не приехал. Как приедет — расскажем.
Шаг 1: Ollama
Нам понадобится приложение, которое будет отвечать за взаимодействие с большой языковой моделью, как бы посредник между пользователем и нейросетью. В рамках этого эксперимента это будет Ollama.
Пошагово:
- Заходите на ollama.com.
- Скачиваете приложение.
- Устанавливаете стандартным способом — перетаскиванием в папку. Принимаете условия, если вас о чём-то спросят.

Теперь проверяем, что программа установлена:
- Открываем приложение «Терминал» (Terminal), можно найти его через поиск.
- В терминале пишем
ollama --version - Нажимаем Enter.
Должна появиться надпись ollama version is 0.9.6 или подобная — это значит, что программа установилась и готова к работе.
Шаг 2. Качаем языковую модель
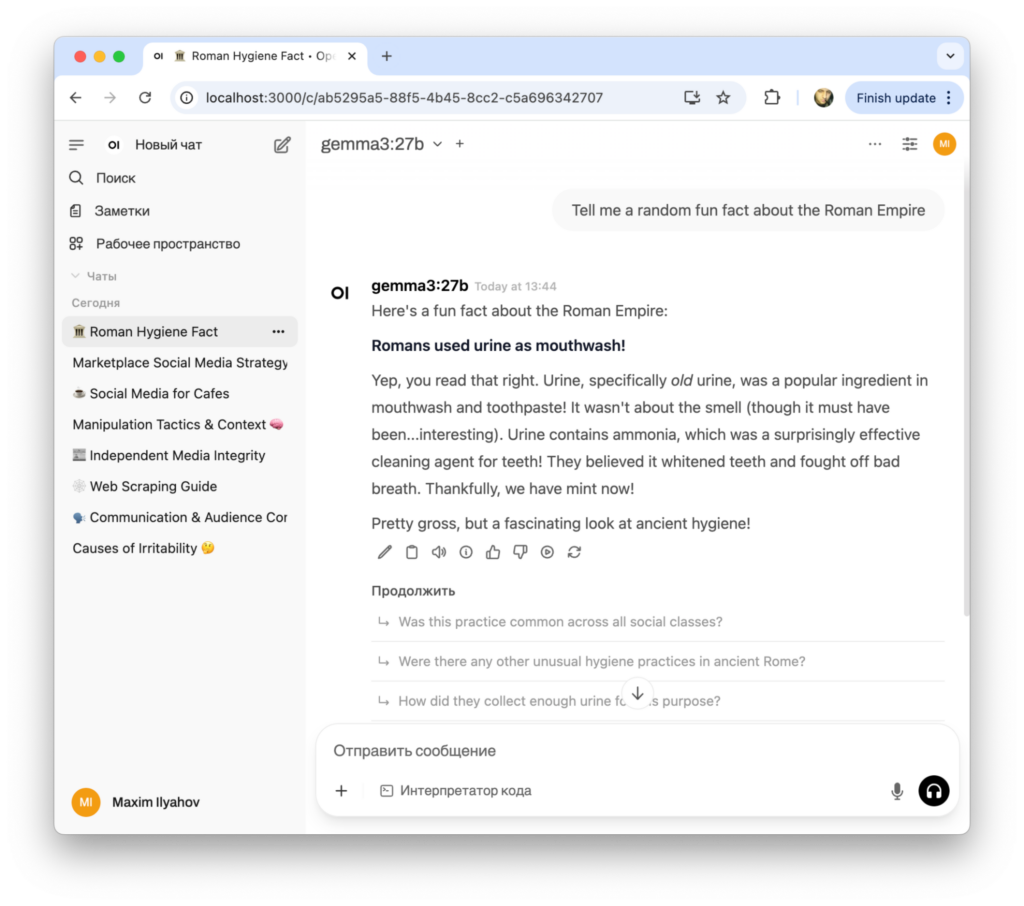
Мы будем работать с открытой языковой моделью от Google под названием Gemma 3 — это самое свежее, что есть на момент написания статьи. В будущем можно будет попробовать что-то другое. Как пишут разработчики, точка отсечения знания модели — август 2024 года.
Модель Gemma 3 есть в нескольких вариантах для разных объёмов памяти вашего компьютера. Чем модель больше, тем она теоретически умнее, но как будет на практике — предсказать сложно. Выбирайте, что вам больше подходит.
| Модель | Сколько параметров (чем больше — тем умнее) | Рекомендованная память компьютера |
| gemma3:1b (работает только с текстом) | 1 миллиард | 8 ГБ |
| gemma3:4b | 4 миллиарда | 8 ГБ |
| gemma3:12b | 12 миллиардов | 16 ГБ |
| gemma3:27b | 27 миллиардов | 32 ГБ и больше |
В том же терминале, где мы только что протестировали работу Ollama, пишем:
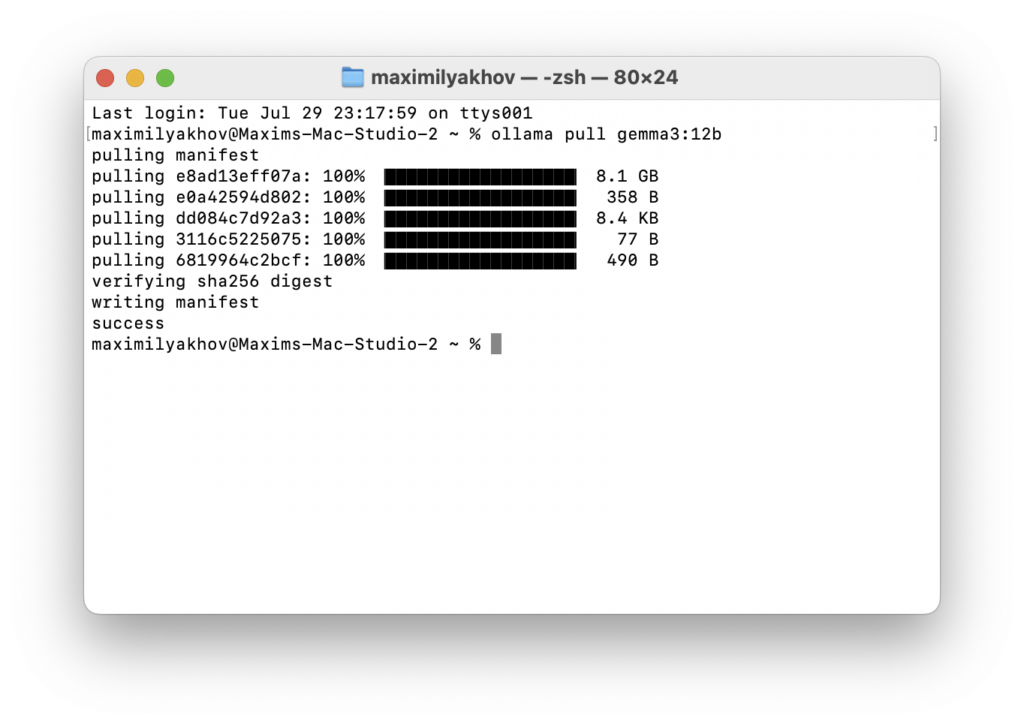
ollama pull gemma3:12b
Вместо последнего аргумента (размера модели) пишите тот, что вам нужен. Если хотите просто попробовать, можно начать с 4b — она поместится в большинстве компьютеров Apple.
Нажимайте Enter, Ollama начнёт шуршать и выкачивать нужную модель. В конце будет строчка success, что означает, что моделька скачалась и ждёт ваших приказов.

Шаг 3. Тестируем в командной строке
Теперь нужно проверить, что моделька жива и реагирует на наши запросы. Там же в терминале вводите команду и жмите Enter:
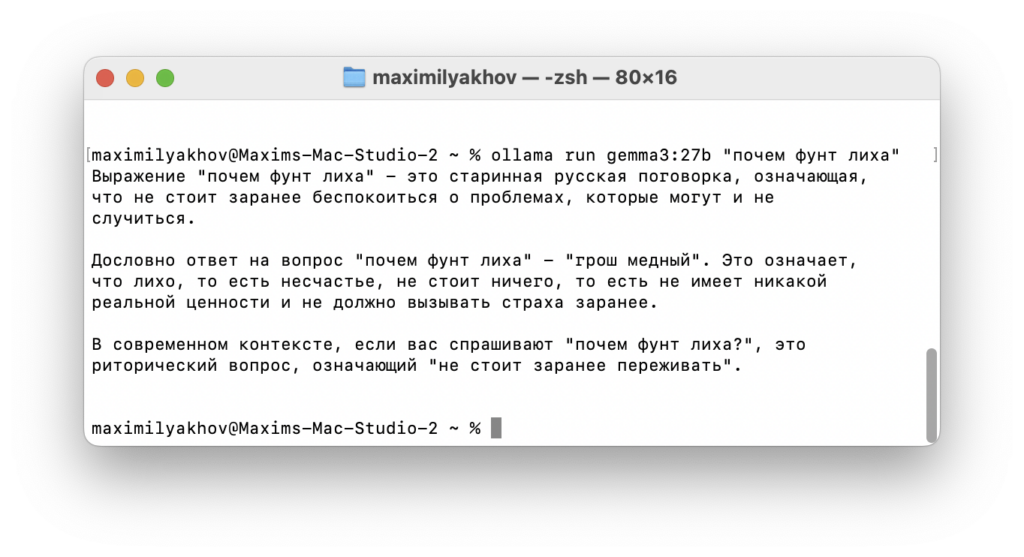
ollama run gemma3:12b "почём фунт лиха"
Вместо 12b впишите размер своей свежескачанной модели.
Если написать просто ollama run gemma3 "почём фунт лиха", то Ollama постарается выполнить эту инструкцию на модели 4b, и, если она у вас не установлена, она её постарается сначала скачать. Это не страшно, просто дополнительное место на диске займёт.
Если всё работает, вы увидите примерно такой ответ:


Теперь нажмите стрелку вверх, предыдущая команда повторится. Нажмите enter и посмотрите, что теперь сгенерирует нейронка на тот же вопрос. Так вы увидите, что нейронка не очень соображает, о чём говорит, а просто генерирует статистически одобряемые фразы. Выглядит как связный текст, но по смыслу — такое...

Справедливости ради, OpenAI тоже не в курсе:

Дальше можно попробовать любые другие запросы, используя такой синтаксис:
ollama run ваша_модель "ваш_запрос"
Например:
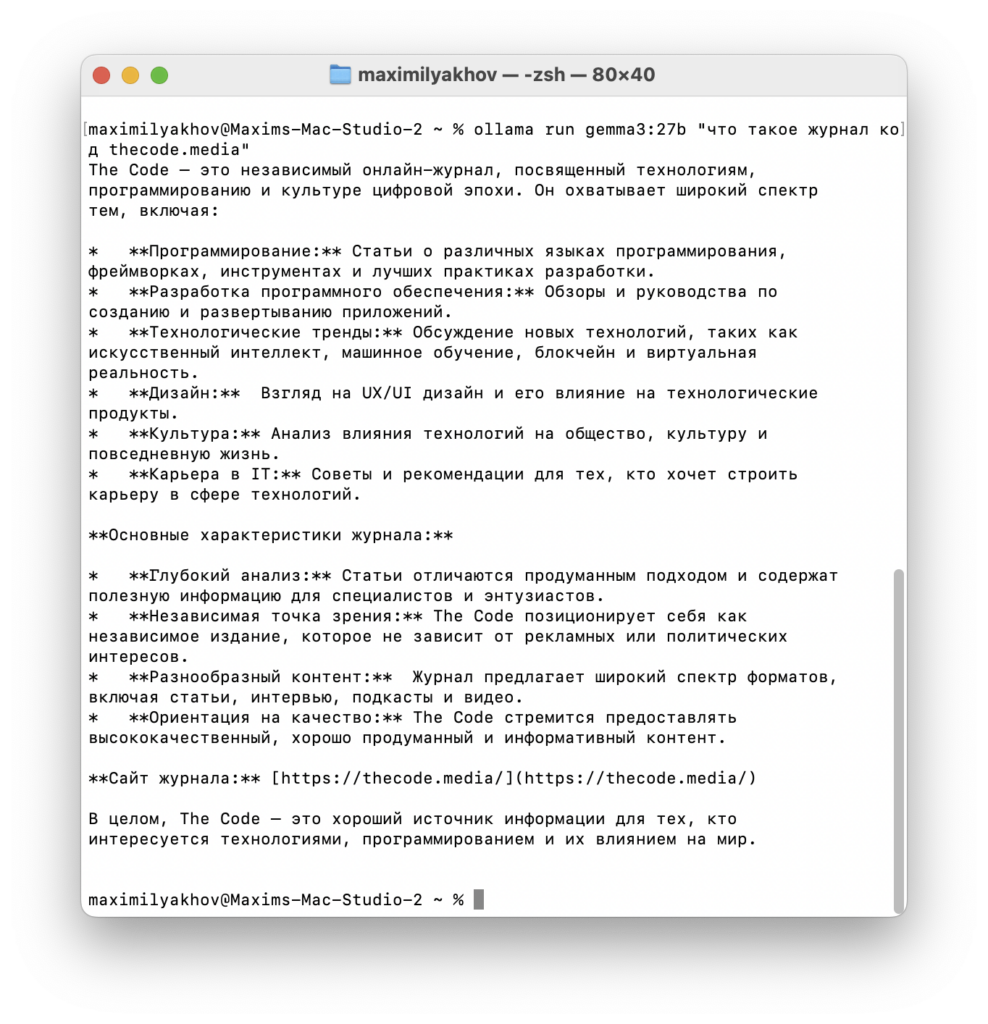
ollama run ollama run gemma3:27b "что такое журнал код thecode.media"

Шаг 4. Готовимся запустить нормальный интерфейс через Docker
Командная строка — это хорошо, но как насчёт нормального удобного интерфейса? Чтобы хранил диалоги, помнил контекст и управлял знаниями. Для этого нам потребуется приложение Open WebUI — оно бесплатное и живёт на GitHub. Но его нельзя просто так скачать, для него нужна среда исполнения Docker. Вот с неё и начнём.
- Скачиваем с официального сайта релиз Docker Desktop для Mac OS with Apple Silicon (прямая ссылка: https://desktop.docker.com/mac/main/arm64/Docker.dmg).
- Устанавливаем, со всем соглашаемся.
- Запускаем приложение и пропускаем регистрацию.

Шаг 5. Ставим интерфейс Open WebUI
Возвращаемся в терминал и копипастим вот эту команду:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Если что, это команда со страницы разработчика: https://github.com/open-webui/open-webui.
Команда означает, что нужно скачать приложение open-webui, установить его и запустить по адресу localhost:3000, где localhost — это ваш компьютер, а 3000 — это порт, по которому вы будете звонить в приложение.
После запуска этой команды Docker пойдёт колдовать, качать и устанавливать, это дело минуты на три. Могут потребоваться подтверждения установки каких-то библиотек — нажимайте Enter и со всем соглашайтесь. В итоге у вас в дашборде Docker появится приложение open-webui, как на скриншоте выше.
Шаг 6. Тестируем интерфейс
В веб-браузере заходите на адрес localhost:3000 — это адрес, по которому отвечает приложение open-webui в Docker. Он вас попросит придумать логин-пароль от рабочего пространства, после чего пригласит в чат. В меню слева ваши чаты будут храниться и архивироваться, чтобы можно было потом к ним вернуться и не генерировать одни и те же ответы по десять раз.

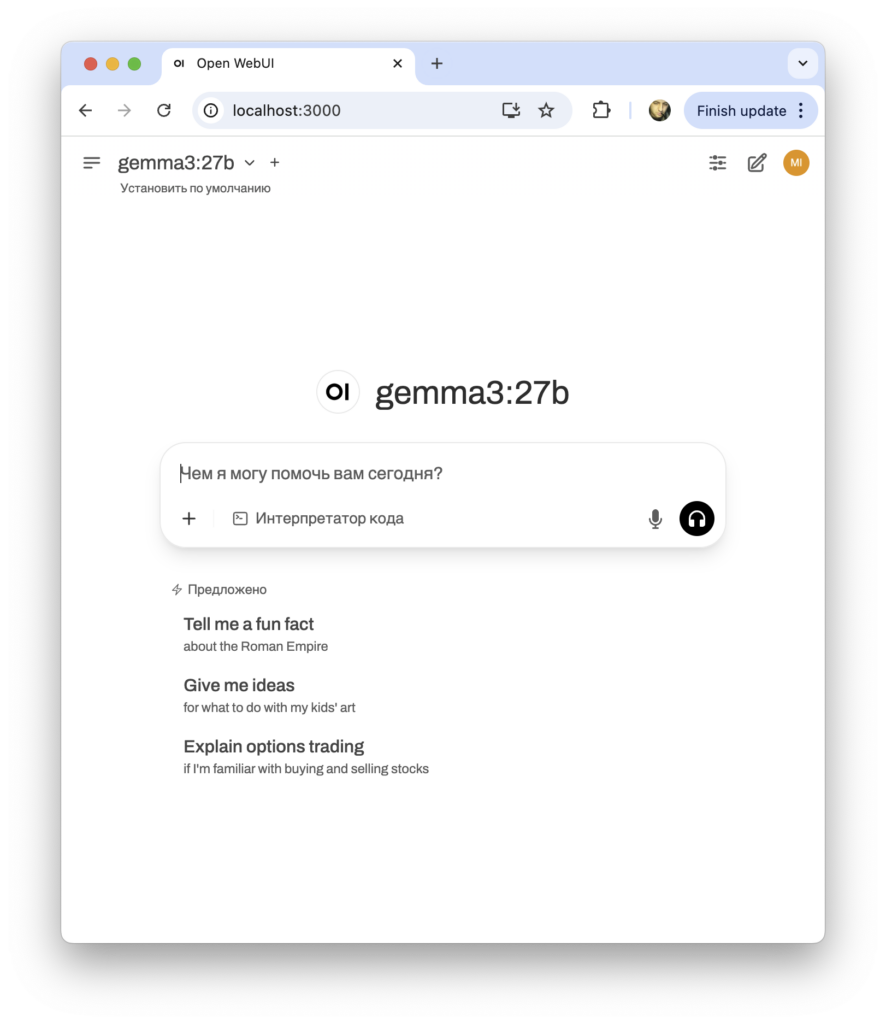
Шаг 7. Создаём базу знаний
Вы заметите, что Gemma 3 не сказать что очень умна. Польза от неё как от справочника сомнительная. Но это свойство генеративных нейросетей как таковых, поэтому удивляться нечему.
Другое дело — когда вы даёте ей работать с вашей собственной базой знаний. Вот тут нейронка может развернуться в полный рост (при определённых условиях).
Что нужно сделать, чтобы нейронка начала отвечать по вашим знаниям:
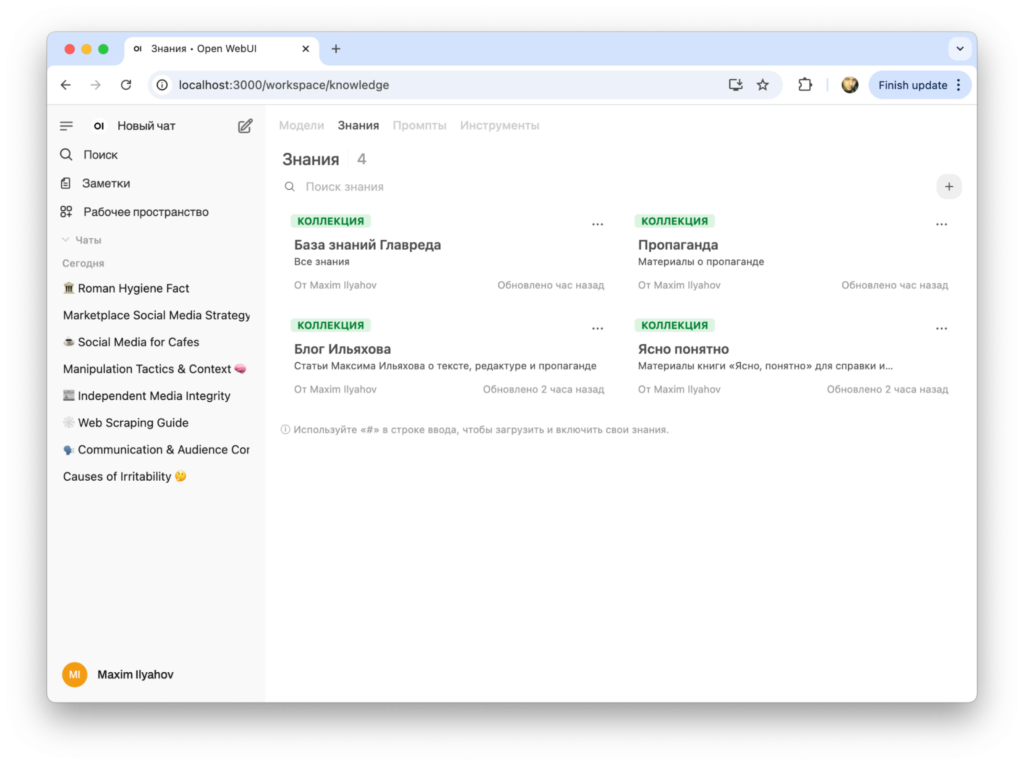
- В меню слева заходите в «Рабочее пространство».
- В верхнем меню найдите серенькую вкладку «Знания».
- Справа найдите плюсик и создайте новую базу знаний. Назовите её так, чтобы потом было удобно к ней обращаться.
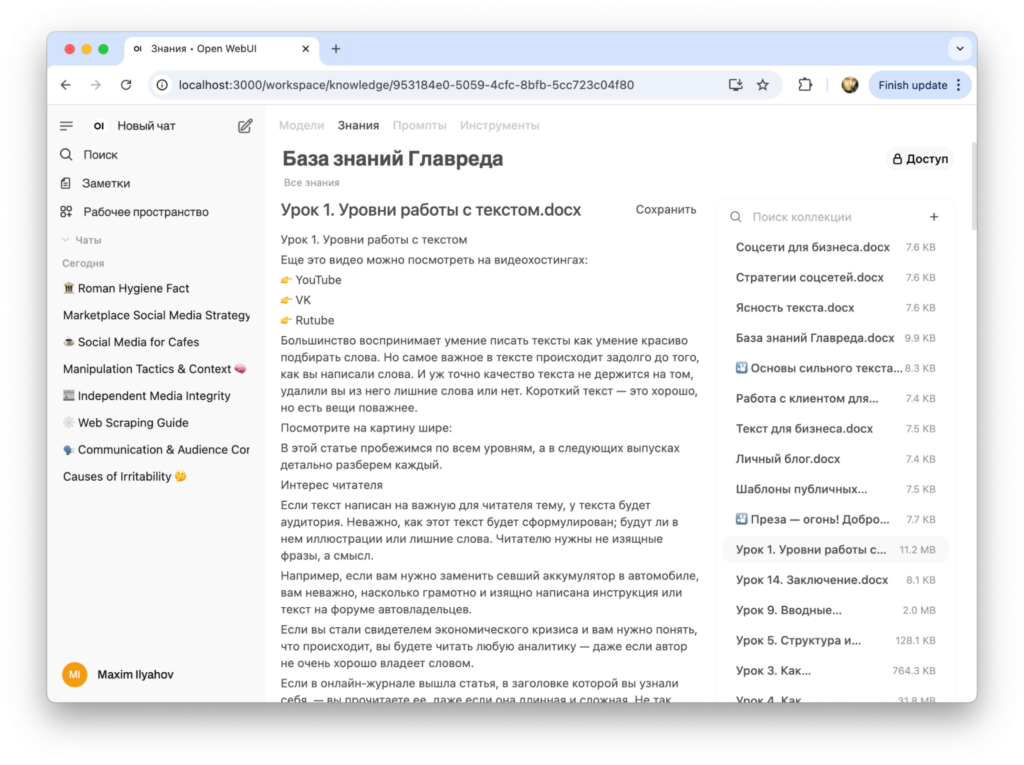
- Создав базу, добавьте в неё материалы. Оптимально разбить их на документы в формате Word или Markdown, чтобы нейронка могла их спокойно прочитать. В теории можно и загрузить PDF, но результаты работы пока что неубедительные.
В результате получится база знаний с каким-то количеством текстовых документов:

Шаг 8. Обращаемся к базе знаний
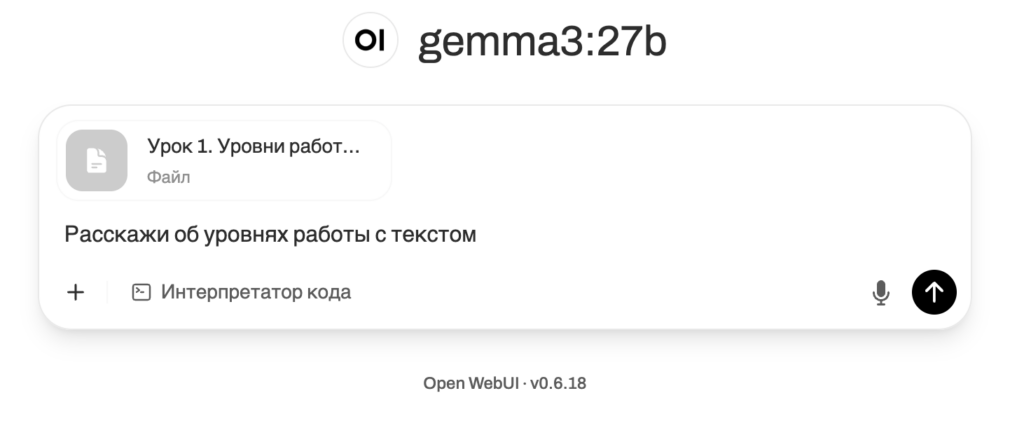
Когда в базу будут загружены нужные документы, переходите в новый чат и в поле поиска пишите знак решётки: #
Вам будет предложено выбрать, по какой базе знаний искать. Выбирайте ту, что вы только что создали. Можно выбрать отдельный документ из неё. Нейронка даст ответ, используя знания из базы и расставляя ссылки на источники.

Известные проблемы
Поиск по базе знаний работает через раз и непредсказуемо. Нейронка вроде что-то лепечет, но либо это общие слова, либо информация невпопад. Качество ответа прямо связано с качеством исходного запроса и читаемости базы знаний.
Например, я попросил нейронку дать резюме по конкретному документу из базы знаний. В документе приводится пять уровней работы с текстом, из которых нейронка поняла только три. Два других — «Сформулированная мысль» и «Слова» — она как уровни не восприняла. Хотя ответ явно дан на основе знаний из этого документа, он пока что неполный:


Во время испытаний стало понятно, что наладить работу полноценного ассистента по базе знаний — это прямо задача, а не «загрузил и забыл». В частности, что пошло не так:
- Нужно было тщательно почистить исходные документы базы знаний от мусора в оформлении и содержании. Просто взять архив с документами — не получилось.
- В базе знаний должны быть прямо качественные и хорошо структурированные знания. При попытке загрузить в нее 700 статей моего блога моделька начала давать мусорные результаты, потому что многие статьи были служебными, временными и откровенно саркастическими. Модель этого ничего не понимала и пыталась их притянуть к результатам поиска, из-за чего захлебывалась и тупила.
- Есть десятки моделей, структурирующих исходный текст базы знаний, и они дают разные результаты на разной скорости. Нужно искать ту, которая будет лучше всего работать именно для вашего материала.
- Нужно тщательно настраивать поиск и экспериментировать с разными вариантами выдачи: например, какой кусочек текста считать за единицу смысла, сколько релевантных ответов приводить в ответе нейронки.
- Текст технического характера с четкими фактами и инструкциями обрабатывается лучше, чем текст гуманитарного характера.
Но есть и хорошие новости: когда вы задаёте нейронке вопросы по своей базе знаний, а она не находит там нужной информации, она вам об этом прямо скажет. Так гораздо легче диагностировать проблемы в её знаниях.
В общем, наладка нормальной базы знаний — это тема для будущих исследований.
Пример, когда нейронка справилась неплохо: в базе была конкретная статья на эту тему, она ее нашла, плюс обнаружила пару связанных статей и тоже их привела. Здесь поиск заставляет модель находить 9 статей по запросу, что приводит к тому, что она может найти что-то лишнее:


А тут из-за настройки поиска нейронка находила только три документа, один из которых был мусорным документом «Теги». И хотя в базе знаний была нужная статья, она до нее не добиралась и не выдавала результаты. Вопрос в настройке и чистке базы знаний:


Особенности собственных знаний Gemma 3
Собственные знания нейросети — это уровень «студент-первокурсник пишет с похмелья курсач за полчаса до дедлайна». На примере в начале статьи нейронка красочно рассказывает, что римляне использовали мочу как ополаскиватель для рта. Об этом много пишут в интернете, но также можно найти источники, которые опровергают это как миф. Найти это опровержение займёт у вас примерно минуту, но для этого нужно захотеть это сделать. А когда нейронка так бодро снабжает вас информацией, бдительность может быть усыплена.
Особенно фрустрирует, когда ты спрашиваешь нейронку о чем-то, в чем сам не разбираешься. Она дает убедительный и красочный ответ. Ты начинаешь действовать по инструкции. Выясняется, что ответ бредовый, по сути неверный и даже опасный — но когда ты это поймешь, ты уже потратил время на реализацию. Куда надежнее почитать материалы, написанные людьми.
Вердикт
Запустить нейронку на компьютерах Apple с процессорами M уже довольно легко. Пара приложений и пара команд в терминале, и всё просто работает.
Польза от нейросетей сильно зависит от сферы применения. Если вложиться в создание хорошо структурированной базы знаний, то может сработать.
Помните, что генеративные нейросети — это машины по созданию среднестатистического бреда. Они проанализировали всё написанное человечеством и выдают нечто среднее. На чём модель обучена — то она и выдаст. А обучена она, при всём уважении, на мусоре.
Нельзя перекладывать на нейронки ответственность за ваши решения. А вот запускать их на своём компьютере — можно и нужно. Наслаждайтесь.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.