


Вы написали алгоритм: в теории он идеален, а вот на практике тормозит. И часто дело тут не в сложности «О-большое», а в физике. Процессор работает на гигагерцах, а память — в разы медленнее, и, если данные лежат «далеко», мощнейший CPU просто сидит без дела и ждёт.
Сегодня разберём, что такое кеш-френдли-код. Узнаем, как хранятся данные в памяти, что такое «промахи кеша» и как низкоуровневая физика процессора влияет на работу огромных баз данных.
Что такое кеширование
Если максимально упростить, кеширование — это способ держать важные данные ближе к тому, кто их использует. Чтобы при каждом обращении не бежать в дальнее хранилище, будь то оперативная память, диск или база данных.
Представьте, что вы собираете мебель.
- Без кеша: чтобы закрутить шуруп, вы идёте в соседнюю комнату, берёте один шуруп, возвращаетесь, закручиваете, потом идёте за вторым. Это долго и неэффективно.
- С кешем: вы берёте горсть шурупов и кладёте их в карман — теперь они доступны вам в любой момент. Карман — это и есть ваш кеш.
В компьютере всё то же самое. Процессор — это мастер, который работает с бешеной скоростью, а его оперативная память — это склад в соседнем здании. Чтобы CPU не простаивал, между ним и памятью есть сеть быстрых буферов, куда процессор заранее подгружает данные, которые ему, скорее всего, понадобятся.
Если ваш код написан так, что процессор легко угадывает следующие данные, то это быстрый код. Если нет — процессор постоянно промахивается и ждёт доставку со «склада».
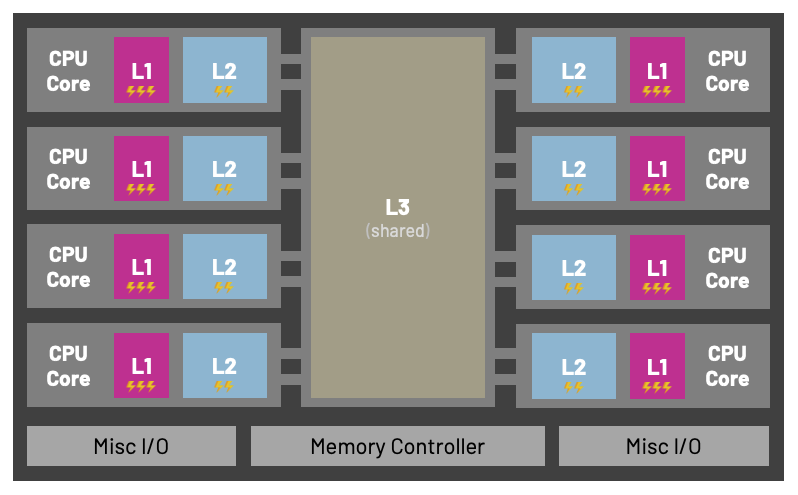
Типы кеш-памяти
Кеш устроен как многоуровневая иерархия: чем память быстрее, тем она меньше и дороже. Процессор постоянно балансирует между скоростью и объёмом, пытаясь получить данные как можно ближе к себе.
1. Кеш процессора (L1, L2, L3). Это «карманы» самого процессора, самая быстрая память во Вселенной, процессор складывает туда данные, которые, скорее всего, ему понадобятся в ближайшие такты:
- L1 — крошечный, но максимально быстрый. Доступ занимает единицы наносекунд.
- L2 — больше по объёму, медленнее L1, но всё ещё крайне быстрый.
- L3 — общий для нескольких ядер, самый «дальний» среди уровней кеша, но гораздо быстрее RAM.
Мы не можем управлять этим кешем напрямую командами типа «положи переменную в L1», но мы можем писать код так, чтобы процессор сам догадался это сделать. Это и есть суть кеш-френдли-подхода.
2. Оперативная память (RAM). Сюда загружаются программы и переменные, доступ быстрый, но по сравнению с L1 — медленнее на порядок. Если процессор не нашёл данные в L1/L2, он лезет сюда, теряя драгоценные такты. Это называется «промахом кеша».
3. Программный кеш и базы данных. Это уже кеш на уровне архитектуры приложения, а не железа. Мы вручную создаём быстрый слой, чтобы лишний раз не дёргать тяжёлую базу данных (например, PostgreSQL).
Например, Redis и Memcached — это специальные in-memory-системы, которые позволяют хранить частые результаты запросов в формате «ключ → значение». Они возвращают данные за миллисекунды, не нагружая PostgreSQL или другой тяжёлый источник, умеют автоматически очищать старые данные по времени жизни (TTL) и дают удобные структуры данных, чтобы кешировать не только строки, но и целые подготовленные модели данных.
Задача этого уровня кеша такая же, как у L1 и L2 в процессоре: не ходить глубоко, когда можно ответить быстро. Только здесь «глубина» — это уже сетевой запрос в базу, а «быстро» — оперативка сервера.
Если убрать Redis из нагруженного проекта, база данных сразу начинает задыхаться. Если, наоборот, правильно его внедрить, вы резко снижаете нагрузку и ускоряете приложение без изменения основного кода.
Кстати, про Redis у нас была отдельная статья, почитайте, если планируете использовать его для API, очередей или кеширования.

Преимущества и недостатки кеширования
Кеширование — это обмен: вы тратите память, которой всегда мало, чтобы выиграть скорость, которой всегда не хватает. Та же логика работает и в железе (L1 — L3), и на уровне приложений (Redis, Memcached, браузерный кеш).
Преимущества кеширования
Скорость (Latency): данные из кеша (L1 или Redis) прилетают в сотни раз быстрее, чем из основного источника (RAM или жёсткого диска). Процессор не простаивает, пользователь не ждёт загрузки.
Например, вы открываете соцсеть. Старые фотки лента показывает сразу же — это кеш, а новые грузятся дольше — это «поход» на сервер. То же самое внутри CPU: попадание в L1 — это «фото уже в телефоне», а промах в RAM — это «скачать заново».
Снижение нагрузки (Throughput): кеш экономит ресурсы там, где взлетает нагрузка. Если 1000 пользователей просят одну и ту же главную страницу, зачем собирать её 1000 раз? Мы собираем один раз, кладём в кеш, и остальные 999 раз отдаём готовую копию. База данных говорит вам спасибо и не падает.
Экономия денег: в облаках (AWS, Google Cloud) вы платите за время работы процессора и операции чтения диска. Кеш позволяет делать меньше лишних движений, а значит, экономит бюджет компании.
Недостатки кеширования
Инвалидация (протухание данных): это самая сложная проблема в IT. Как понять, что данные в кеше устарели? Вы поменяли аватарку, а на сайте висит старая. Всё потому, что она застряла в кеше на одном из уровней: браузер, CDN, сервер.
Настроить правильное время жизни (TTL) и условия очистки — это важный этап разработки. И даже при правильных настройках изменения «доезжают» не сразу.
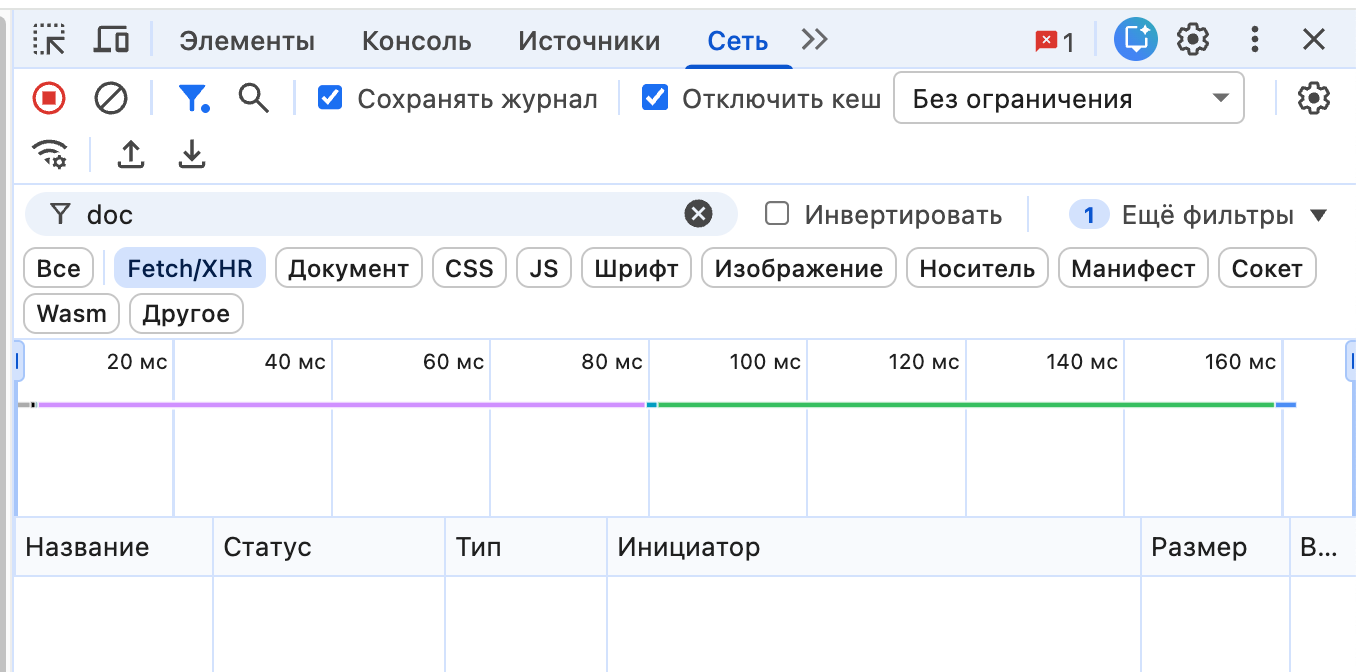
👉 Если кажется, что что-то работает не так, откройте DevTools → вкладка «Сеть» → поставьте галочку «Отключить кеш» и обновите страницу. Это даёт команду браузеру игнорировать локальный кеш и брать всё заново с сервера. Часто помогает понять, проблема в коде или просто где-то застрял старый файл.
Непредсказуемость: это следствие того, что кеш живёт своей жизнью. Код может быть идеальным, но если одна из копий данных устарела, система начинает вести себя странно: то работает, то ломается, то внезапно чинится после обновления страницы.
Типичная ситуация: «У меня на компе не работает!» — «А ты кеш чистил?» — «О, заработало!»
Здесь проблема не в том, что данные устарели, а в том, что приложение неявно зависит от того, попадёте вы в свежий кеш или в старый. Один и тот же запрос возвращает разные версии ответа, потому что цепочка доставки (браузер → CDN → прокси → сервер) не синхронизирована.
Расход памяти: кеш должен быть быстрым, поэтому он живёт в дорогой памяти (SRAM в процессоре или RAM на сервере). Если кешировать всё подряд, сервер превращается в мусорное ведро: память забита вчерашними результатами, а системе некуда складывать актуальные данные.
Как на самом деле хранятся данные
Прежде чем оптимизировать код, нужно понять, как компьютер видит вашу оперативную память. Многие представляют память как бесконечную ленту из нулей и единиц, но на практике удобнее представлять её как огромную таблицу или склад с ячейками. Данные хранятся в виде последовательных блоков, и у каждого есть адрес.
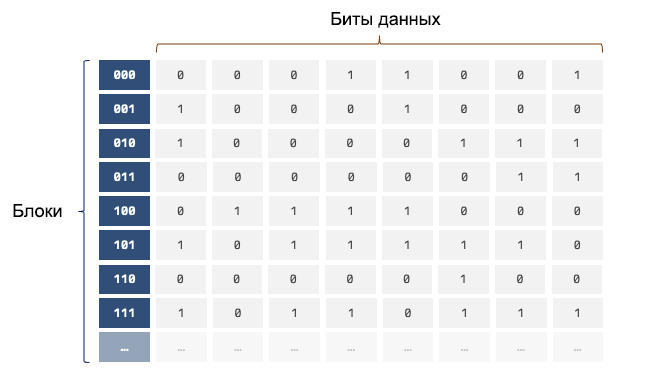
Кеш-линия: процессор работает оптом
Главный секрет скорости в том, что процессор никогда не читает память по одному байту, это слишком дорого и долго. Если вы попросите его: «Дай мне переменную a», он пойдёт в память и захватит не только эту переменную, но и кусок данных, лежащих рядом с ней. Этот кусок называется кеш-линией (Cache Line), и размер одной линии обычно 64 байта.
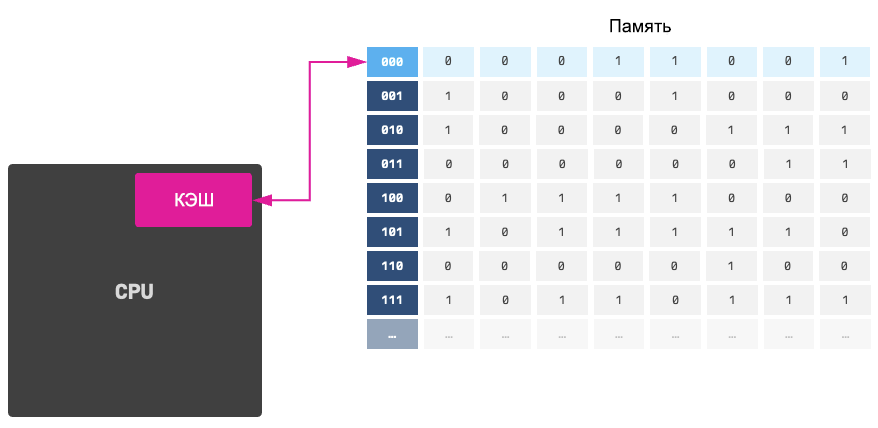
Hit и miss: попадания и промахи
Когда процессору нужны данные, то сначала происходит проверка карманов (L1): «У меня уже есть этот кусок данных?»
Если да — это cache hit (попадание). Данные доступны мгновенно, и процессор счастлив.
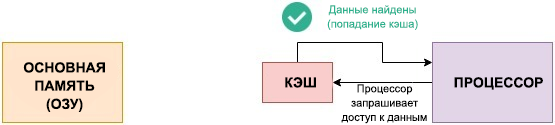
Если нет — это cache miss (промах). Процессору приходится ставить работу на паузу и лезть в медленную оперативную память или диск, чтобы загрузить новую кеш-линию.
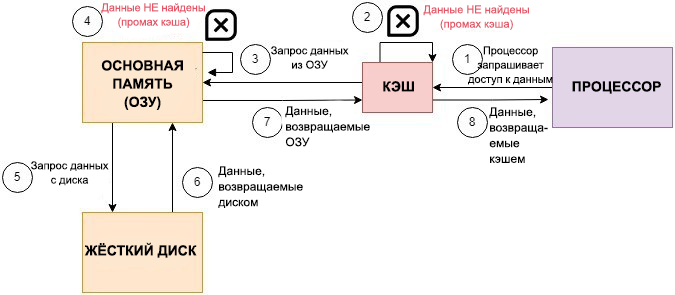
Задача программиста — организовать данные так, чтобы процессор загружал линию один раз и обрабатывал её целиком, а не бегал на склад за каждым байтом.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Кеш-дружественный код
Теперь, когда мы понимаем, по какому принципу работает процессор, разберёмся с кеш-дружественным кодом. Это не какой-то отдельный стиль программирования, а стиль мышления, когда вы подстраиваете структуры данных так, чтобы было удобно процессору.
Характеристики кеш-дружественного кода
Кеш-дружественный код обычно выглядит так:
- работает с данными последовательно, а не прыгает по памяти;
- использует структуры данных, лежащие в RAM одним блоком (массивы, слайсы), а не разбросанные по куче мелкие узлы;
- повторно использует данные, которые недавно были прочитаны (временная локальность);
- минимизирует сложные вложенные условия, которые ломают предсказание ветвлений.
Эти базовые принципы для разных языков программирования: язык не меняет физику процессора. Но эффект от кеш-френдли-стиля в разных языках будет разный, и это важно понимать, чтобы не ждать от Python или JS чудес.
Почему языки ведут себя по-разному?
Всё дело в формате хранения данных. Например, в компилируемых языках (C++ / Rust), когда вы создаёте массив
int arr[3] = {1, 2, 3};
то в памяти действительно будет лежать три числа подряд — голые байты без лишней обвязки. Процессор читает одну кеш-линию и получает сразу несколько элементов бесплатно.
А вот в интерпретируемых (Python / JS) тот же массив arr = [1, 2, 3] представляет собой список указателей, каждый из которых ведёт в совершенно разные места памяти. Каждый элемент здесь — это объект с метаданными, заголовком, счётчиком ссылок, типом и сервисной информацией. Память фрагментирована, данные разнесены — как результат, процессор буксует, а кеш «промахивается».
Стратегии написания кеш-дружественного кода
В реальности очень много структур данных внутри программ эквивалентны матрице: это те же таблицы, картинки, гриды, CSV-данные, любые двумерные массивы чисел. И у них есть одна особенность: в памяти они лежат не «квадратом», а сплющенной строкой.
Строка 1 → сразу за ней строка 2 → дальше строка 3… Компьютер не знает, что у тебя «таблица», — для него это линейный массив.
И исходя из этого возникает два способа читать эту таблицу:
- Быстро (row-major): читать строку за строкой (
matrix[i][j]). Вы идёте по памяти последовательно. Процессор загружает кеш-линию, и следующие элементы уже в ней — практически бесплатны. - Медленно (column-major): читать по колонкам (
matrix[j][i]). Вы берёте один элемент, потом прыгаете через километр памяти за следующим. Процессор постоянно промахивается мимо кеша. И из-за таких мелочей два одинаковых алгоритма могут различаться по скорости в разы.
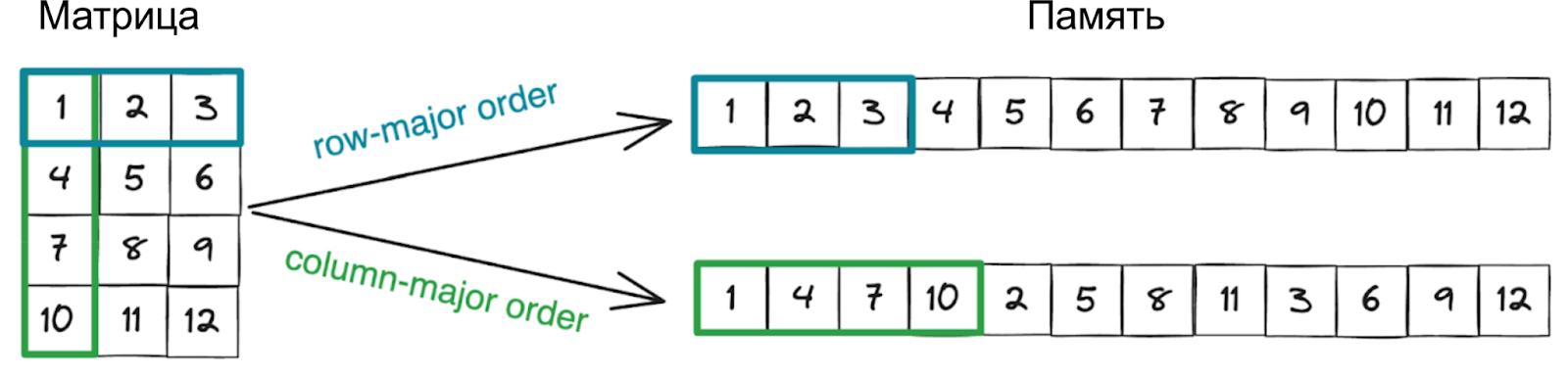
То, как мы обходим данные, важнее, чем сам алгоритм. Если процессор не может предсказать ваши шаги, он простаивает. Поэтому кеш-дружественные стратегии выглядят так:
- Минимизировать случайные прыжки по памяти. Чем линейнее структура, тем выше скорость.
- Группировать связанные данные рядом. Структура массивов > массив структур — типичная оптимизация в играх и high-performance-коде.
- Переставлять циклы так, чтобы внутренний проход шёл по последовательным адресам. Это особенно критично в матрицах, изображениях, CSV.
- Не вставлять тяжёлых условий в самый вложенный цикл.
Современные процессоры любят предсказуемость. Чем меньше случайности вы создаёте, тем больше шансов, что кеш и предсказатель ветвлений будет работать на вас.
А что насчёт компиляторов и «ПЗУ»?
Если вы пишете на C++/Rust/Go, компилятор действительно может оптимизировать часть ваших действий: например, поднимать часто используемые данные в регистры, объединять операции или менять порядок вычислений, если результат не меняется.
Но в языках вроде Python или JavaScript вы не управляете компилятором напрямую. Там оптимизация идёт через другой слой: интерпретатор или JIT-движок. Они тоже используют те же принципы кеша, просто без участия программиста.
Поэтому ваша задача — не «вручную засунуть переменную в L1», а писать код, который движку легко анализировать и оптимизировать: линейные структуры данных, предсказуемые циклы, минимум случайных прыжков.
Оптимизация кода на уровне алгоритмов
Теперь поговорим о том, как обрабатывать данные. Процессор — это не просто калькулятор, это конвейер: пока он выполняет одну инструкцию, то уже подгружает следующую. И самое страшное для него — это неопределённость.
Упрощение условий
В любом коде есть конструкции if / else. Для нас это просто логика, а для процессора — развилка на дороге. Чтобы не тормозить на каждой развилке, в процессоре есть блок Branch Prediction (предсказатель ветвлений), который пытается угадать: «Скорее всего, условие будет true, поэтому я заранее начну выполнять код из блока if».
Например, вы обрабатываете массив чисел: если число > 128, то прибавить к сумме:
- Если массив отсортирован (0, 5, 10… 130, 150), условия идут предсказуемо: сначала куча
false, потом кучаtrue. Процессор доволен, скорость максимальная. - Если массив перемешан (150, 0, 130, 5), условие скачет случайным образом и процессор постоянно ошибается в прогнозах.
Поэтому желательно писать код так, чтобы ветвления были предсказуемыми. Либо, если это критичный участок кода, переформулировать логику так, чтобы вообще избавиться от ветвления.
Частотность характеристик
В программировании, особенно в ООП, мы любим создавать объекты «всё в одном». Например, класс User, где лежит всё: id, login, hp (здоровье), avatar_blob (огромная картинка) и biography (текст на пять страниц). Но в игре или высоконагруженном цикле вы, скорее всего, каждый кадр обновляете только hp и position.
Возникает проблема: когда процессор загружает User в кеш-линию, то захватывает не только нужные hp, но и кусок ненужной biography. Кеш забивается «холодными данными», а полезные «горячие» данные не влезают.
Решением будет разделять данные по частоте использования. Например, горячие данные (id, hp, coords) мы храним в одном массиве/структуре. А «холодные» (avatar, bio, history) — храним отдельно и подгружаем, только когда открывается профиль игрока.
Так вы повышаете плотность полезной информации в кеше.
Техники оптимизации
Сразу оговоримся: это следующий уровень. Если вы пишете сайт-визитку или стандартный API на Python, вам вряд ли придётся спускаться на этот уровень вручную. Этими техниками пользуются разработчики компиляторов, игровых движков, высокочастотного трейдинга и библиотек для машинного обучения.
Для экспериментов и сравнения «быстро/медленно» есть полезные веб-инструменты типа Compiler Explorer и QuickBench: они позволяют увидеть ассемблер, проверить влияние оптимизаций и сравнить производительность разных подходов. Но важно помнить: реальные промахи кеша и ошибки предсказания ветвлений можно измерить только на локальной машине профилировщиками вроде perf или Intel VTune.
Реассоциация
Процессор умеет делать несколько дел одновременно, но он не может начать следующее действие, пока не готов результат предыдущего.
- Плохо:
sum = (a + b) + c. Чтобы прибавитьc, процессор должен сначала дождаться результатаa + b. Это простой процессора. - Хорошо:
sum = (a + b) + (c + d). Процессор может сложитьa+bи [/tags]c+d[/tags] одновременно на двух разных блоках, а потом сложить результаты.
Поэтому пишите код так, чтобы вычисления были независимы друг от друга. Это позволяет процессору загрузить все свои мощности, а не ждать одного медленного вычисления.
Условная передача данных
Мы уже говорили, что процессор ненавидит ветвления, поскольку они могут сбросить его конвейер. Поэтому суровые оптимизаторы переписывают логику так, чтобы избавиться от if. Это называется branchless-программированием — «кодом без ветвлений».
Например, если написать так:
if (a > b) { max = a; } else { max = b; }
то велик риск промаха предсказания.
Поэтому для оптимизации пишут такой код без if:
max = a – ((a – b) & ((a – b) >> 31));
Здесь нет условий: процессор просто молотит побитовые операции поток за потоком, не останавливаясь ни на наносекунду.
Векторизация
Ну и самое интересное: обычный код — это SISD (Single Instruction, Single Data): «Возьми одно число, сложи с другим». А векторизация — это SIMD (Single Instruction, Multiple Data): «Возьми пачку из 4 (или 8) чисел и сложи их с другой пачкой за один такт». Такое хорошо работает в обработке картинок, видео, звука, нейросети.
Когда на Python вы пишете c = a + b в библиотеке NumPy, то под капотом срабатывает именно SIMD на C/C++. Именно поэтому циклы в чистом Питоне медленные, а матричные операции — молниеносные.
Что в итоге
Если вы пишете на JS, PHP или Python, ваш интерпретатор и JIT-компилятор сами пытаются применить эти трюки, и ваша задача просто не мешать им:
- Пишите предсказуемый код.
- Используйте типизированные массивы (TypedArrays в JS), если работаете с бинарными данными.
- Для тяжёлых вычислений берите готовые библиотеки (NumPy, Tensorflow), написанные профи, которые уже использовали SIMD и кеш-оптимизации за вас.
Мыслить категориями «кеш-линий» и «векторизации» — значит понимать, почему ваша программа потребляет ресурсы, именно это и отличает инженера.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.











