


В нашем прошлом проекте мы генерировали текст на цепях Маркова вручную — сами составляли пары, выбирали нужные слова и следили за предложениями. Так было нужно для понимания того, как работают цепи в принципе. Но это плохая практика для продуктового разработчика: такой алгоритм сложно поддерживать и мы не знаем, насколько хорошо мы его реализовали. Могли реализовать плохо.
Сегодня сделаем то же самое, но как настоящие программисты — используем готовую библиотеку markovify, вместо того чтобы писать код самим и с нуля.
Некоторые работодатели ожидают именно такого подхода от своих сотрудников.
Что делаем
Мы повторим наш прошлый проект на готовой библиотеке — посмотрим, станет ли код проще и проверим, что она умеет. Логика такая:
- Устанавливаем библиотеку.
- Подключаем её к нашей программе.
- Пишем код, используя новые возможности.
- Смотрим на результат и сравниваем с тем, что было раньше.
Установка markovify
Для установки запускаем терминал и пишем такую команду:
pip install markovify
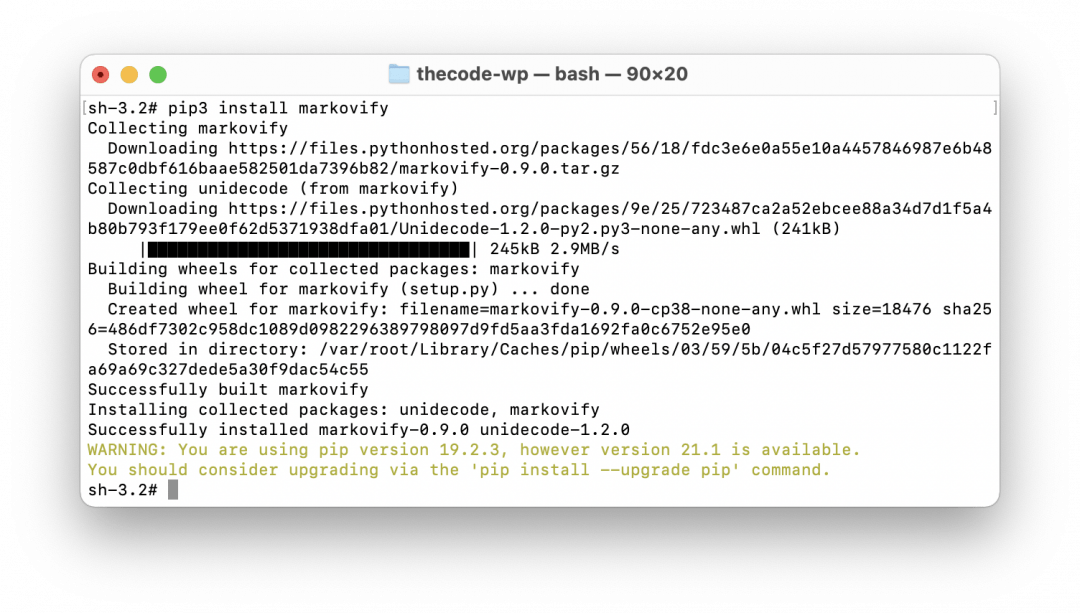
Теперь мы можем использовать эту библиотеку в наших проектах.




Подключение библиотеки
Подключаем библиотеку, как это обычно делается в питоне — командой import прямо в коде программы:
import markovify
С этого момента мы можем дальше в коде использовать все команды оттуда — программа сама найдёт библиотеку у нас на компьютере, возьмёт нужные функции и выполнит, что в них написано.
Переписываем код
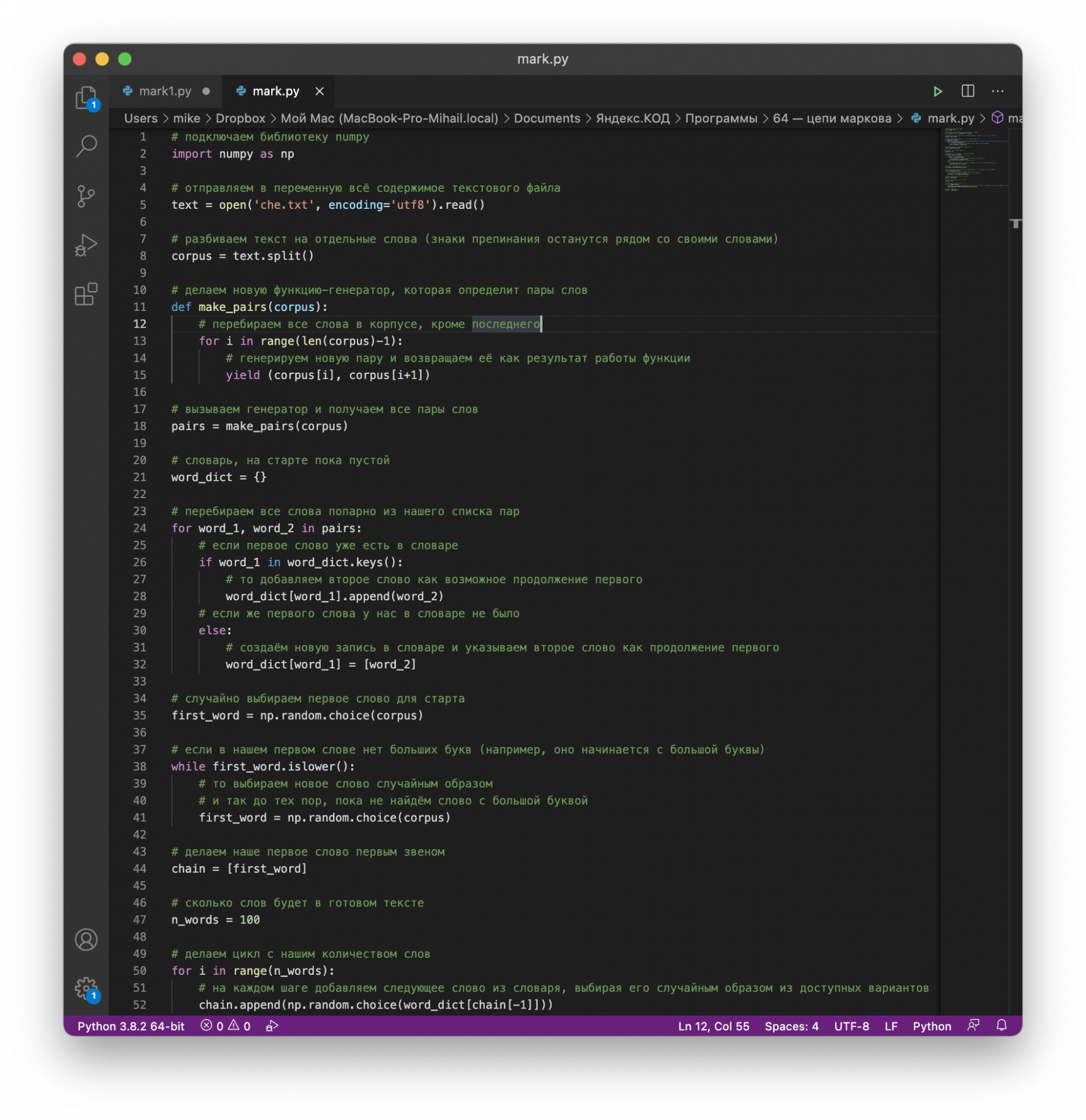
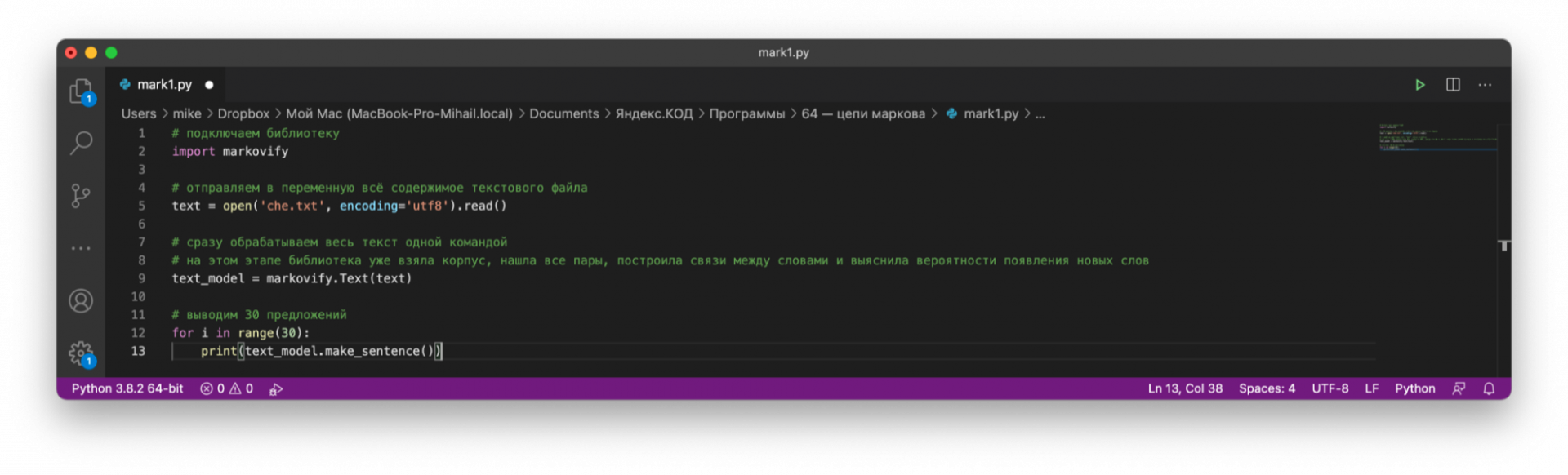
Чтобы получить то же самое, что и в прошлом проекте, нам понадобится всего 5 строк кода, не считая комментариев:
# подключаем библиотеку
import markovify
# отправляем в переменную всё содержимое текстового файла
text = open('che.txt', encoding='utf8').read()
# сразу обрабатываем весь текст одной командой
# на этом этапе библиотека уже взяла корпус, нашла все пары, построила связи между словами и выяснила вероятности появления новых слов
text_model = markovify.Text(text)
# выводим 30 предложений
for i in range(30):
print(text_model.make_sentence())Всё дело в том, что мы одной командой markovify.Text() получаем сразу многое:
- отфильтрованный корпус;
- цепочки пар слов с вероятностями появления того или иного слова;
- связи между парами.
В общем, одна команда позволяет нам сразу построить все связи между словами, чтобы потом на их основе строить предложения с помощью метода .make_sentence(). Этот метод берёт всю цепочку и строит на её основе одно предложение. Библиотека знает, что предложение должно начинаться с большой буквы и заканчиваться точкой — нам не нужно прописывать это отдельно. Всё, что нам нужно, — указать, сколько предложений надо придумать.
Было — стало
Сравните код из первого проекта с ручной обработкой цепи и код с этой библиотекой, который делает то же самое. Итоговый код раза в четыре короче (если не в пять). А умеет он гораздо больше, потому что библиотека markovify умеет не только строить цепочки, но и считать вероятности, а также многие другие вещи.
В этом — вся сила библиотек: они экономят время и силы на разработку, а результат может получиться даже лучше.
Было:
Стало:
Проверяем результат
Запускаем программу и ставим вывод 5 предложений. Результат такой:
🤖 И что значит самый рассказ?
— Сегодня едва ли это удобно, — сказал Орлов. — Я хочу мира, тишины, хочу тепла, вот этого моря, вашей близости.
— А, может, хотите конституции?
— Это все пустяки! — говорил он. — Когда же мне, наконец, сказать! — говорила Маша с письмами и визитными карточками на подносе.
Осмотрев больницу, Андрей Ефимыч всё понял.
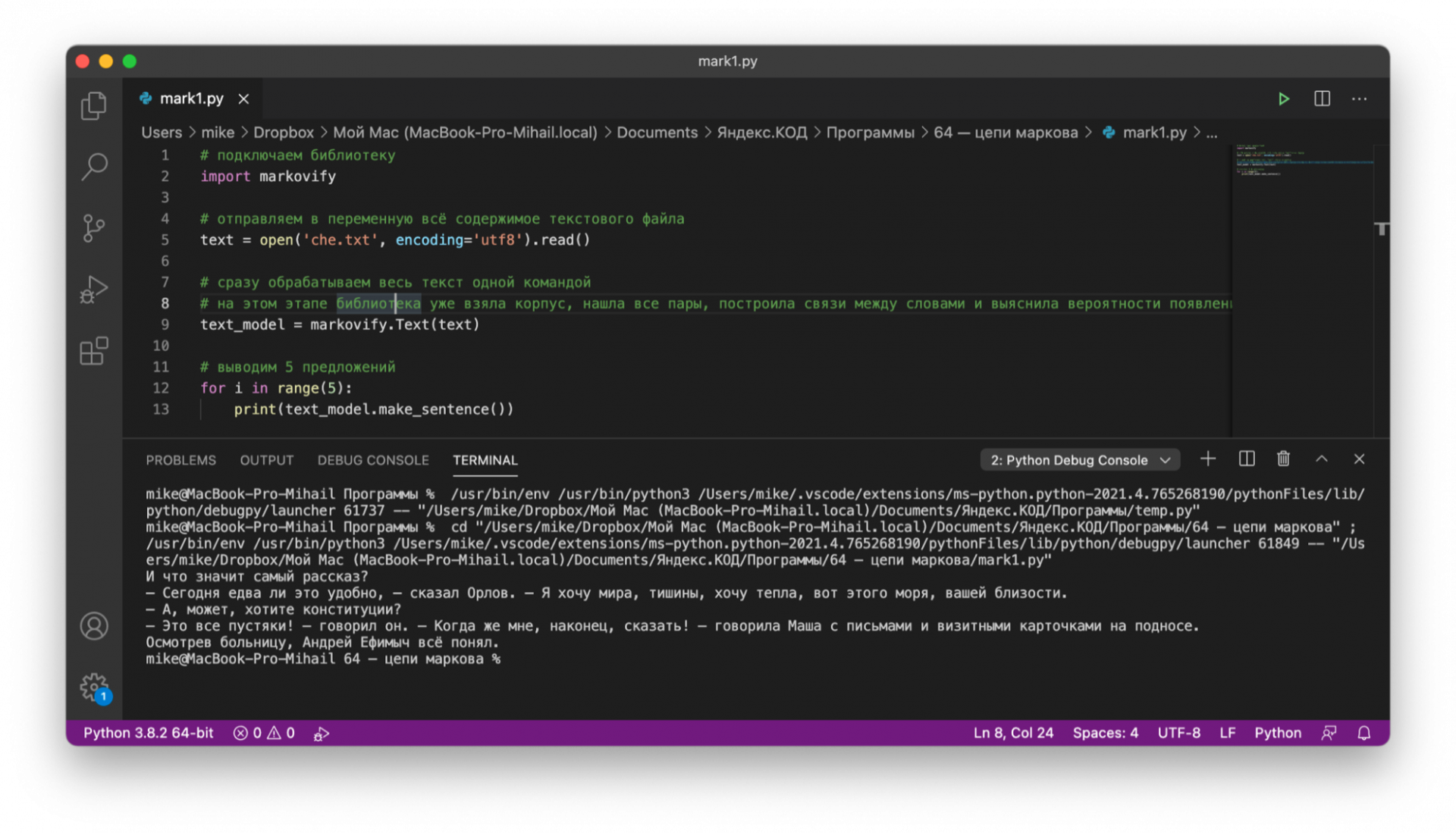
Получилось гораздо лучше, чем в первом проекте. Это связано с тем, что внутри библиотеки есть много связей и настроек, которые позволяют создавать стройный текст. Конечно, до результатов GPT3 нашей программе ещё далеко, но мы уже можем получать более-менее привычный и понятный текст, используя всего 5 строк кода.
Что дальше
Сделаем программу, которая будет создавать заголовки к нашим статьям. Когда сделаем — перенастроим её так, чтобы она сама ещё и статьи писала. Без шуток, так и сделаем.















