Сегодня рассказываем про искусственный интеллект и машинное обучение: что делают ML-модели, какие бывают, как подбирают тип модели в зависимости от задач.
❗️ С непривычки будет сложно, но такова суровая реальность нейросетей.
Определение машинного обучения
Машинное обучение (Machine Learning) — это одно из направлений искусственного интеллекта. ИИ объединяет вообще все технические исследования и практики, которые направлены на создание глобального технического разума. И всё, что включает или подразумевает решения, сделанные машиной, относится к искусственному интеллекту.
В сфере искусственного интеллекта есть три главных термина — они нам понадобятся для понимания того, что происходит в машинном обучении в целом.
Искусственный интеллект (AI) включает все дисциплины для разработки копии человеческого разума в цифровом варианте. Точная копия — это когда машина может думать, чувствовать и принимать решения, или по крайней мере притворяться, что умеет. До этого пока далеко, для достижения этой цели нужно развивать и объединять разные направления. Роботостроение, компьютерное зрение, нечёткая логика, машинное и глубинное обучение — это всё одна большая дисциплина.
Машинное обучение (ML, или Machine Learning) занимается созданием и настройкой «думающих» программ без явного программирования.
Модель машинного обучения — это программа, которая ищет ответ на вопрос, который её научили решать. Системе можно дать строгие правила, как нужно реагировать в каждом конкретном случае, а можно дать большие наборы данных — Big Data. Машина проанализирует эти данные и научится находить решения на задачи такого же типа сама. Рекомендации по фильмам и музыке — это работа модели машинного обучения, которая проанализировала ваши предпочтения. ML-модели чаще всего доводятся до ума вручную инженерами данных.
Глубинное обучение (DL, или Deep Learning) — усложнённый вариант машинного обучения, при котором модели могут корректировать себя сами и обучаются на гораздо большем объёме данных, чем при машинном обучении.
С чего начинается разработка модели
Чтобы научить машину думать как человек, нужна начальная модель-заготовка. Эта модель появляется в несколько этапов, чаще всего это происходит так.
- Сначала исследователи машинного обучения (ML-researchers) выводят новые алгоритмы и методы для решения задач. На этом этапе модель ещё не сформирована в виде кода — есть только концепции и правила.
- После этого разработчики библиотек и фреймворков переводят эти математические алгоритмы в удобные структуры. Эти структуры — шаблоны будущих готовых моделей, которые будут использовать ML-инженеры.
- Инженер машинного обучения вызывает готовый алгоритм из библиотеки, настраивает и оптимизирует его для решения конкретных задач. Созданием модели с нуля ML-инженеры занимаются редко.
Получается, что инженерам машинного обучения не нужно знать математику так хорошо, как исследователям. Но хорошие математические навыки всё равно нужны: для выбора правильной модели, настройки, диагностики и коррекции.





Типы машинного обучения
Новую чистую модель нужно научить работать с теми данными, которые нужны вам. В зависимости от способа обучения есть разные виды машинного обучения.
Обучение с учителем (supervised learning). Настраивающий модель специалист даёт программе наборы данных и маркирует их, чтобы программа поняла, к чему они относятся и что означают. После изучения таких размеченных данных машина может определять похожие данных в массивах новой информации или находить связи между несколькими параметрами в датасете.
Обучение без учителя (unsupervised learning). Модель получает наборы данных и должна сама вывести какие-то закономерности. Например, установить для себя какие-то параметры в информации и распределить всё по группам в соответствии с этими параметрами.
Обучение с частичным участием учителя (semi-supervised learning). Это совмещённый вариант обучения с учителем и без. На старте специалист по работе с моделью даёт ей набор данных, часть из которых размечена. Программа выводит для себя базовые основные закономерности и дальше работает с ними. Это ускоряет и упрощает процесс обучения. Например, при большом количестве перемешанных неразмеченных данных у модели сразу будет понимание, на что ориентироваться.
Обучение с подкреплением (reinforcement learning). Подкрепление в данном случае — обратная связь на действия модели. Программа получает описание задачи и общие правила, по которым ей нужно выполнять эту задачу. В этих правилах заложены положительные и отрицательные воздействия на модель в зависимости от того, насколько правильным было её поведение.
Например, при поиске кратчайшего маршрута модель может получать виртуальный штраф за каждый километр выше нормы — и поощрение за каждые сэкономленные 10 километров. С каждым шагом программа становится умнее и ищет более быстрое решение. В конце концов машина находит оптимальный маршрут.
Глубинное обучение (deep learning). Здесь нейросети анализируют большое количество данных и выводят из них для себя правила, которые потом раскладывают по нескольким слоям. Эти слои используются потом для анализа данных. Подробно обучать нейросеть не нужно.
Пример глубинного обучения — анализ записей для голосового помощника. На первом слое программа может анализировать первые одну-две секунды, после которых запись попадёт в одну из категорий: «жалоба», «консультация» или «не опознано». На следующем слое модель проверит ещё несколько секунд, определит слова и добавит новую информацию к записи. После последнего слоя программа определит категорию и содержание обращения от пользователя.
Классические задачи, решаемые с помощью машинного обучения
В зависимости от цели модели машинного обучения разделяются на разные типы решаемых задач. Вот три самых известных типа.
Классификация. Модель разбивает входные данные по разным категориям. Она может проходить по каждому экземпляру данных, например фото или таблице, и проверять: есть ли у этого объекта признаки А, Б, В, Г? После ответа на все вопросы программа примет финальное решение: к какой категории относятся те материалы, которые ей выдал пользователь? Например, модель может регистрировать тип текстового или голосового сообщения от клиента для передачи нужному специалисту.
В итоге — данные при классификации промаркированы, и модель знает, что к чему относится.
Регрессия — термин из теории вероятностей и статистики. Это связь одной математической величины с другой. Выявленная зависимость будет позволять предсказывать, как изменится одно число после изменения в других. Например, так можно строить прогноз по росту или падению цен на акции или недвижимость в зависимости от изменения связанных факторов.
Кластеризация. Процесс разделения данных по группам, когда информация не промаркирована. Модель должна сама вывести закономерности и группы, на которые она разложит входные данные.
В этом отличие кластеризации от классификации — программа сама ищет скрытые паттерны в данных.
Типы входных данных при обучении
Передаваемые в модель исходные данные напрямую связаны с тем, какую задачу будет решать эта модель. Типы могут быть при этом практически любыми.
- Числа: возраст, температура, доход.
- Категории: пол, цвет, тип изделия.
- Текст: отзывы, письма, заголовки.
- Фото: рентген, фото продукта, снимки с камер наблюдения.
- Временные ряды: курс акций, история продаж, колебания давления.
- Пространственные данные: координаты, карты, снимки со спутника.
- Аудиоданные: речь, музыка, запись звуков живой природы.
Короче, ограничений по входным данным у нейросетей нет. Что нам нужно — то они и будут анализировать.


Типы функционалов качества
Функционал качества — общие свойства продукта, которые влияют на то, как хорошо он выполняет свои задачи. Можно сказать, что это коэффициент полезного действия для ML-моделей. В машинном обучении функционалы качества считаются по-разному в зависимости от типа обучения модели.
Для обучения с учителем функционал качества может быть средней ошибкой в ответах и прогнозах, например точность предсказаний.
При самостоятельном обучении нет какого-то одного правила для подсчёта и количественного выражения. Можно определить и установить основной показатель для каждого случая, например насколько хорошо модель выявила скрытые паттерны или подобрала подходящие данные для каждой категории при кластеризации.
В обучении с подкреплением функционал качества посчитать проще всего, потому что модель получает штрафы и награды за каждое действие. Можно найти общее и среднее количество всех наград и штрафов, минимальное время для решения задачи или отношение наград и штрафов.
Алгоритмы моделей машинного обучения
Алгоритмы и математические зависимости — это та часть, которой чаще всего занимаются ML-исследователи. Они находят сложные паттерны и занимаются математикой профессионально, часто эти люди работают в академической сфере.
Сегодня есть много разных видов алгоритмов для моделей машинного обучения — как и разделов математики. Мы расскажем упрощённо о нескольких, а подробно разберём некоторые алгоритмы в отдельной статье.
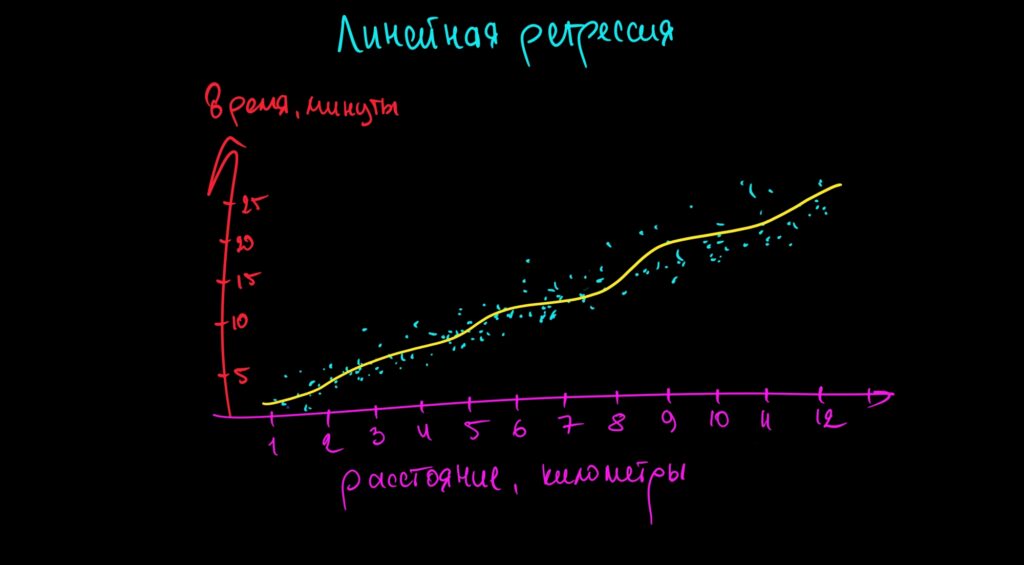
Линейная регрессия
Алгоритм, который находит зависимость в уже существующих размеченных данных и прогнозирует будущий результат.
Визуально это можно представить как расположение всех данных на графике. Например, нужно спрогнозировать время доставки товара от склада до заказчика. Модель расставит на графике расстояния между складами и заказчиками и время, за которое удавалось закончить доставку в предыдущие случаи.


Это хорошо работает, если зависимость действительно линейная.
Но в нашем примере на данные может влиять много чего: район доставки, загруженность дорог, ремонтные работы, сам курьер, который может водить слишком аккуратно или периодически нарушать скоростной режим.
Для таких вариантов в линейной регрессии есть возможность построить не прямую линию зависимости, а полиномиальную — то есть функцию, которая зависит от нескольких параметров. Тогда на выходе мы получим кривую, которая будет колебаться в зависимости от меняющихся параметров и выдавать более точные прогнозы.
Технически это будет уже полиномиальная регрессия, но зависимость всё равно линейная:

Дерево решений
Набор вопросов, ответы на которые ведут к следующим вопросам, пока не будет получен окончательный ответ. Получается структура, где вопросы будут узлами, а ветки, отходящие от узла, — ответами.
По такому алгоритму может вычисляться риск сердечных заболеваний, одобрение кредита в банке или определение вида животного на фотографии:


Ещё один пример — веб-приложение Akinator, которое угадывает, какого персонажа или животное вы загадали. Приложение задаёт простые вопросы с несколькими вариантами ответов и постепенно сужает круг поиска:


Случайный лес
Этот метод объединяет несколько деревьев для лучшей точности анализа.
Каждое из деревьев случайного леса может анализировать свою часть. Например, при попытке взять кредит одно дерево анализирует доход и возраст, второе — кредитную историю, третье — коэффициенты между доходами и уже существующими долгами. Один алгоритм может дать ответ «Отклонить кредит», а два других — «Одобрить». Случайный лес примет то решение, за которое голосует большинство отдельных деревьев.

Нейронная сеть
Алгоритм без учителя, который выводит для себя несколько уровней проверки.
Это похоже на дерево решений, потому что информация проходит через несколько слоёв, которые можно сравнить с узлами-вопросами. Разница в том, что основа технологии — нейросеть — может обучаться сама. Она выводит проверки, через которые пропускает данные, и мы не можем точно знать, что именно она проверяет. Поэтому эти уровни называются скрытыми слоями.
Например, в теории возможно, что нейросеть проверяет на одном из слоёв количество пикселей красного и оранжевого оттенка на фото, чтобы ответить на вопрос, является ли изображение фотографией осеннего леса. Но наверняка знать нельзя, потому что связи между слоями получаются очень сложными для понимания человеком.

Примеры использования машинного обучения
Вот несколько примеров реальной пользы, которую уже сейчас приносят ML-модели:
- В кибербезопасности есть авторизация и аутентификация по фото и голосу, распознавание вредоносных программ и хакерских атак.
- Здравоохранение использует компьютерное зрение для анализа рентгеновских снимков и выявления заболеваний. Ещё современные модели умеют изучать истории болезни пациентов для составления плана будущих осмотров и возможного лечения.
- Беспилотные автомобили собирают данные с камер и датчиков вокруг себя благодаря ML и тоже используют компьютерное зрение.
- Для продаж прогнозные модели могут дать примерное понимание, чего ожидать при увеличении одного из элементов бизнеса. Например, что даст открытие ещё одной торговой точки? А двух? А десятка или сотни?
Практические сферы применения
Сегодня машинное обучение используется хотя бы в небольшой степени уже во многих областях жизни человека, смотрите сами:
- Перевод речи в текст.
- Распознавание жестов.
- Чтение рукописного текста.
- Разные виды технической диагностики.
- Медицинские обследования.
- Прогнозы погоды на основе предыдущих наблюдений.
- Выявление мошенничества.
- Своевременное распознавание хакерских атак на сайты компаний.
- Кредитная проверка.
- Обнаружение спама.
В целом, правило здесь такое: если что-то из несложных решений можно передать машине и объяснить ей правила принятия таких решений — этим занимаются нейросети, а человек смотрит, как они с этим справляются.