








Продолжаем огромную сагу о платном курсе Практикума — «Python-разработчик». В ней мы разбираем, что проходят студенты этого курса на каждом этапе, что внутри и как этому учат. Вот полная карта путешествия:
- Как всё устроено и основы Python
- Бэкенд на Django ← вы здесь
- API: интерфейс взаимодействия программ
- Алгоритмы и структуры данных
- Управление проектом на удалённом сервере
- Посмотрим, что нужно для дипломного проекта
- Поговорим о подготовке к трудоустройству
- Алгоритмы и структуры данных Ver. 2.0
- Бэкенд на Django Ver. 2.0
- Управление проектом на удалённом сервере Ver. 2.0
Сегодня будем разбирать блок про Django — фреймворк для быстрой разработки сайтов и приложений на Python. Это значит, что с ним можно будет собрать готовый сайт или веб-приложение быстрее, проще и аккуратнее, чем писать весь код самому с нуля.
Присаживайтесь поудобнее, наливайте чай, разбор будет долгим.
Немного про то, как идёт учёба
Весь курс состоит из нескольких тематических блоков, а каждый блок делится на двухнедельные отрезки. Такой отрезок называют спринтом — и по ним строится обучение в Практикуме.

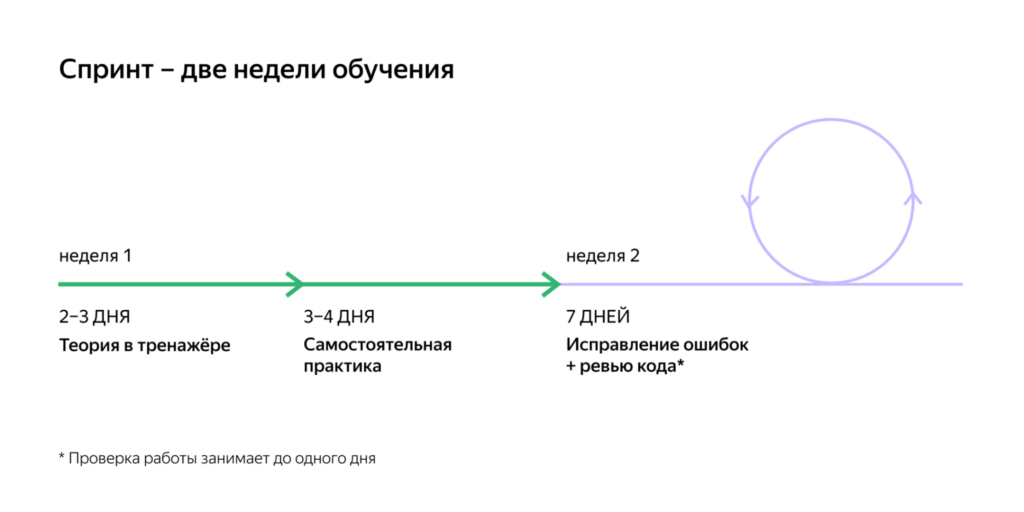
Также в спринты входят проекты — это задачи, с которыми в жизни могут сталкиваться разработчики. Перед выполнением каждого проекта вы получаете всю теорию и практику, которая понадобится для выполнения задачи. Тут уже код проверяют не автоматические тренажёры, а ревьюеры — разработчики Практикума, которые будут смотреть все файлы, логику и конечный результат. Если будут ошибки или замечания — их тоже нужно исправить за спринт.
Переход в другую когорту
Иногда бывает так, что уложиться в срок выполнения задачи не получается по разным серьёзным обстоятельствам: личным, семейным или другим. В этом случае студент может перенести дедлайн сдачи заданий, но при этом перейти в другую когорту студентов (и продолжить обучение с того же места, где остановился). Проще говоря — в новый коллектив. Когда продолжается обучение (сразу или через пару недель) — это согласовывается с куратором. Так можно сделать всего два раза за всё время обучения.
❗️ Если ваше обучение оплачивает работодатель или вы участвуете в программе государственного софинансирования, переход в другую когорту может быть недоступен или может работать по другим правилам.
Наставники, поддержка и другие роли на курсе
Во время обучения вы будете работать и общаться в чатах с командой Практикума. Вот ключевые роли, чтобы было понятнее, кто есть кто.
Куратор — хранитель организационной стороны программы и её атмосферы. Он знает, когда будут каникулы, где отвечают на вопросы наставники, что делать, если возникли проблемы со входом в личный кабинет. В программировании куратор обычно не разбирается, но все организационные вопросы можно решить через него.
Наставники — опытные разработчики, которые выполняют роль старших коллег на реальной работе. Главная задача наставника — научить студента системному мышлению, умению решать нетривиальные задачи в программировании. Они знают всё про программирование в своей области, поэтому вопросы по коду — это к ним.Код-ревьюер — это разработчик, который будет проверять проекты и играть роль тимлида. Ведёт он себя иногда при этом тоже как настоящий тимлид, поэтому погружение в профессию при общении с ним будет максимальным :-)
Команда поддержки — поможет с любыми вопросами по тренажёру или техническим вопросам курса и личного кабинета. Если что-то не работает на сайте — это к ним.
Базы данных
Одна из основных задач бэкенд-разработчика — организовать передачу данных между приложением и базой. Без умения работать с базами данных в этой профессии никуда, да и на собеседовании вас, скорее всего, попросят что-нибудь написать на SQL. Поэтому про базы данных на курсе будет много и плотно.
Раздел начинается с описания баз данных: какие они бывают, как устроены, что в них может храниться и как это всё работает. С картинками и схемами, как обычно:

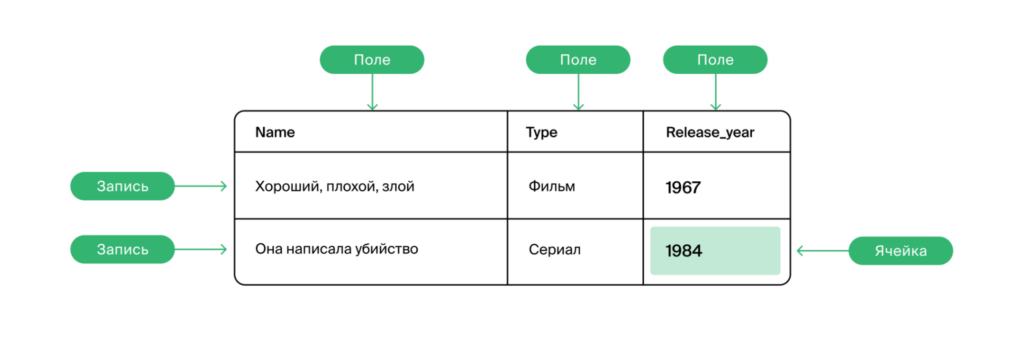
Дальше нам рассказывают про техническую часть, и тут уже начинается полноценное погружение в БД: связи, ключи, идентификаторы, уникальные значения и отношения между таблицами. Программисту про это тоже нужно знать, потому что сейчас почти нет бэкенда, который не работает с базой данных.
В конце разделов — тесты на то, как усвоился материал. Оценки за них не ставят, и на учёбу они не влияют, но показывают, как вы реально поняли эту тему. Отвечать наобум смысла нет — тесту всё равно, а вы потеряете возможность лишний раз проверить себя и увидеть, что нужно ещё подтянуть.

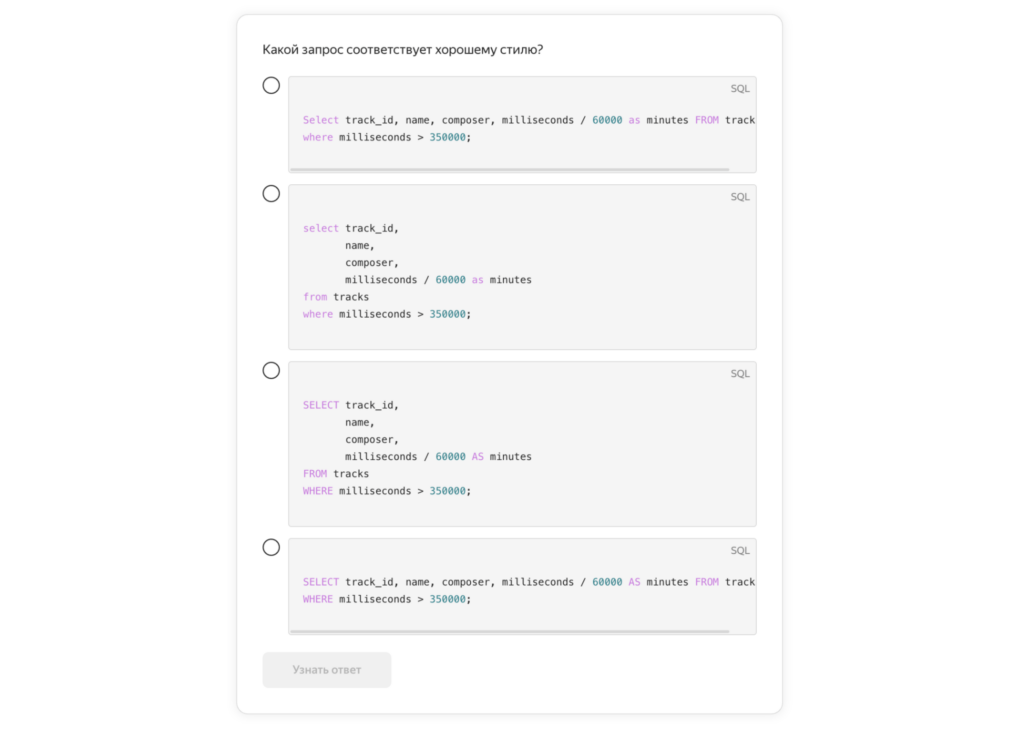
Дальше плавно начинается практика: запросы и знакомство с языком SQL. Всё идёт от простого к сложному: сначала разбирается, что такое запрос в принципе, как он устроен, что там можно писать. Потом идёт часть посложнее: нюансы синтаксиса, разные форматы запросов и правила оформления SQL-кода.


В блоке с теорией много тестов уже с примерами и конкретными запросами. Это хороший способ проверить свой уровень понимания темы (и повод перечитать какую-то часть теории, если ответил неправильно):

После этого раздел потихоньку переходит от теории к практике — к работе с SQLite (встроенной БД в Python) и написанию несложного кода. Выглядит и воспринимается довольно органично:
- сначала рассказали, что такое БД;
- показали, какие бывают запросы и как они выглядят;
- потренировались с запросами;
- теперь делаем то же самое (и уже знакомое), но в коде на Python.


База данных — это как большой склад с кучей полок. Когда приложению что-то нужно, оно отправляет запрос, как записка кладовщику:
- SELECT — какие именно вещи нам нужны (например, только имена пользователей);
- FROM — с какой полки/таблицы их взять;
- WHERE — особые условия («только красные», «только купленные вчера»);
- DISTINCT — «убери дубликаты, одинаковое мне не нужно».
Это как если бы мы попросили друга: «Дай мне (SELECT) список фильмов (FROM) из своей коллекции (WHERE) которые я ещё не смотрел, и (DISTINCT) без повторов!». Так что теперь нас знакомят с тем, как доставать информацию из БД по разным параметрам:

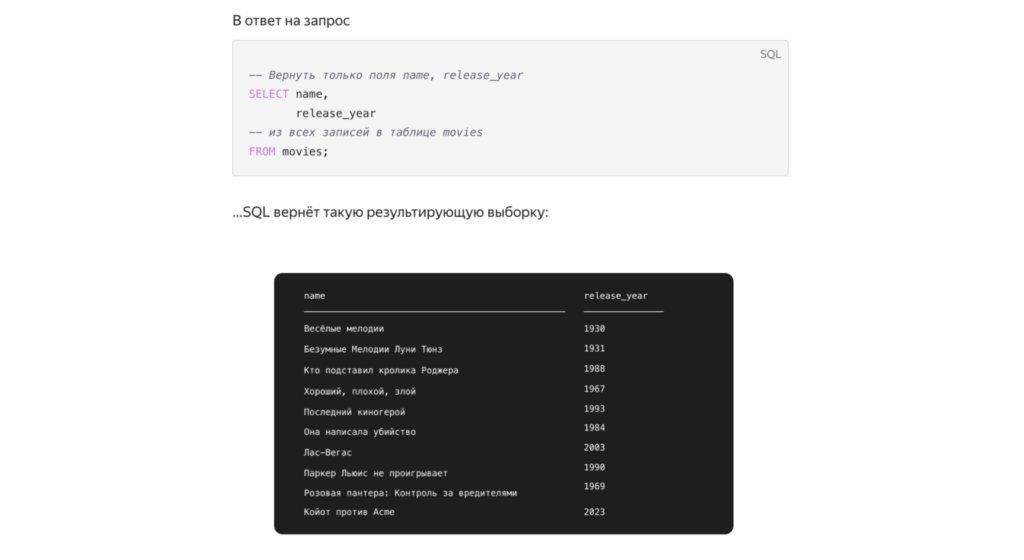
В бэкенде получение данных из базы — одна из основных операций, поэтому ей уделяется много времени и разбираются все нюансы. Периодически встречаются тесты — и простые, и заковыристые:


Практика в тренажёрах тоже появляется почти сразу, причём работа идёт сразу по двум направлениям:
- Мы продолжаем учиться работать с кодом на Python.
- Параллельно с этим отрабатываем задания с SQL-запросами, изучая новый материал.
Количество попыток решений в тренажёре не ограничено, если что — всегда можно взять подсказки или посмотреть решение:

Двигаемся дальше: ORDER BY, LIMIT и OFFSET. Представьте, что база данных — это библиотека, а SQL-запрос — просьба библиотекарю. В итоге это будет работать как-то так:
ORDER BY — «Разложи книги не как попало, а в определённом порядке». Тут можно попросить:
- По алфавиту (ORDER BY name);
- От новых к старым (ORDER BY date DESC);
- По рейтингу (ORDER BY rating DESC);
LIMIT — «Дай мне только 5 книг, а не все сразу». Так можно защитить приложение от перегрузки (типа, «не грузи 100500 записей, хватит 10») и ускорить его работу («не ищи всё, остановись на первых результатах»).OFFSET — «Пропусти первые 10 книг, покажи следующие». Это основа пагинации, когда материал разбит на пронумерованные страницы. Такое можно увидеть в поисковой выдаче, когда показывается по 10 результатов, или в интернет-магазинах (показывать по 20 товаров).
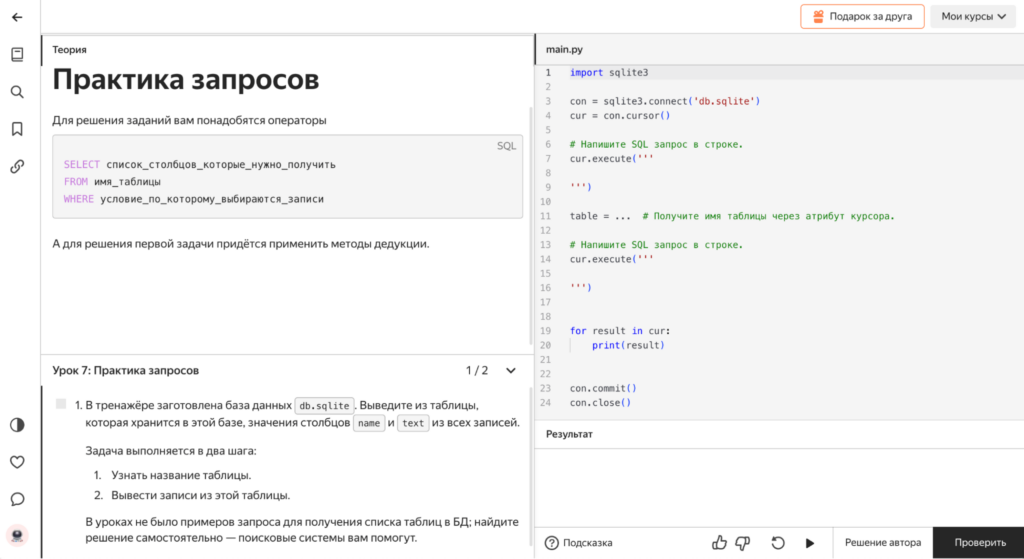
Без этих команд приложение бы либо грузило всё подряд и работало бы медленно, либо показывало данные в хаотичном порядке. А так — получаем аккуратные порции данных. И вот тому, как с этим работать, тут тоже учат. Например, как сделать так, чтобы из базы данных для каждой страницы выбиралось только по два фильма:


Как обычно, весь новый материал сразу закрепляется практикой. На этот раз вместо базы данных с фильмами — база с мороженым:
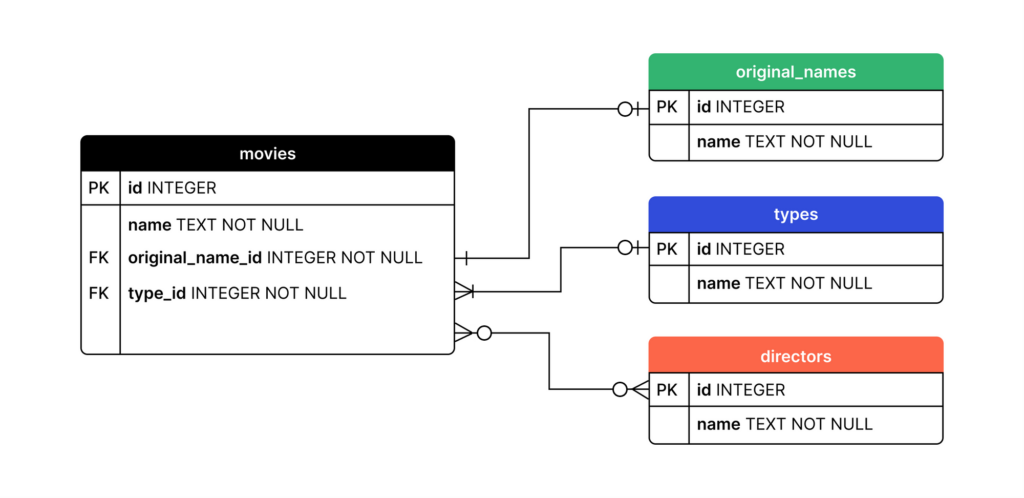
Дальше — отношения между таблицами, связи и диаграммы. Проще говоря, дают всё, что надо знать про базы данных на уровне программиста. Причём дают и с точки зрения обывателя, чтобы было понятнее, и с точки зрения программиста.
Например, вот «простая» схема связей в БД:

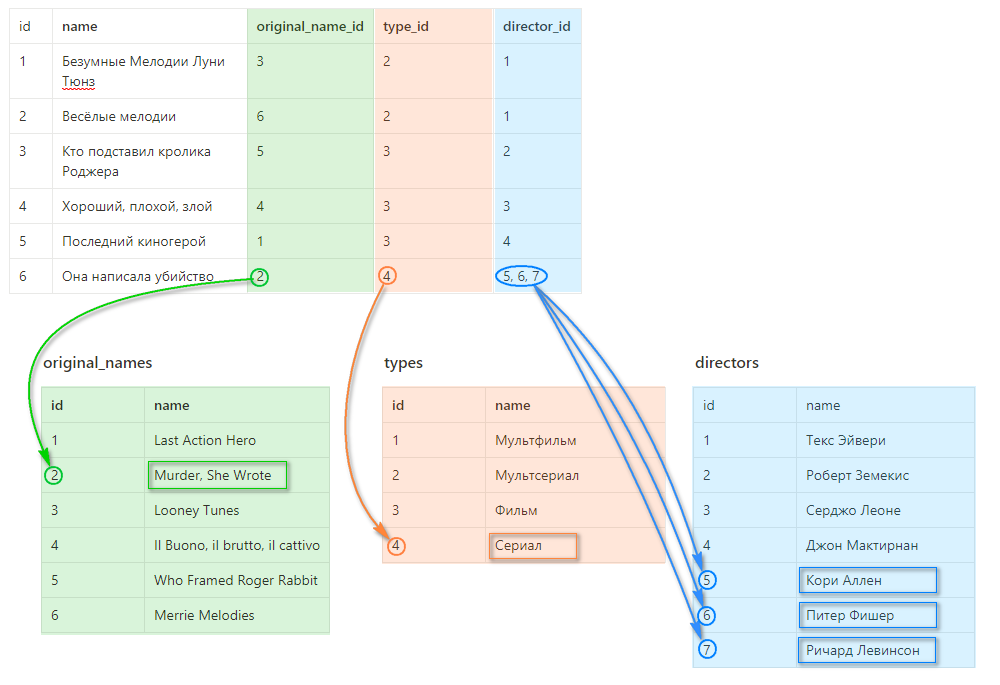
А вот программистская:

Везде, где есть возможность, тесты, причём интерактивные, где надо перетащить карточки в нужные стопки:

Ну и практика. Если в самом начале в задании много кода было уже написано за нас, то теперь надо почти всё писать самим, причём под конец раздела мы доходим до уровня полноценного администрирования баз данных:






Настройка окружения: Python, IDE, venv
В этом разделе нам дают теоретические материалы и инструкции для установки Python, показывают, как работать в терминале и создавать виртуальные окружения, а также говорят о том, как выбрать редактор кода. Полученные тут знания и опыт понадобятся и для прохождения курса, и в реальной работе.
Всё начинается с того, как установить Python. С одной стороны — логично, потому что переходим к написанию локального кода, а не в тренажёре. С другой стороны — почему бы не дать любознательным ученикам это заранее, всё равно была практика на тренажёре с кодом на Python.


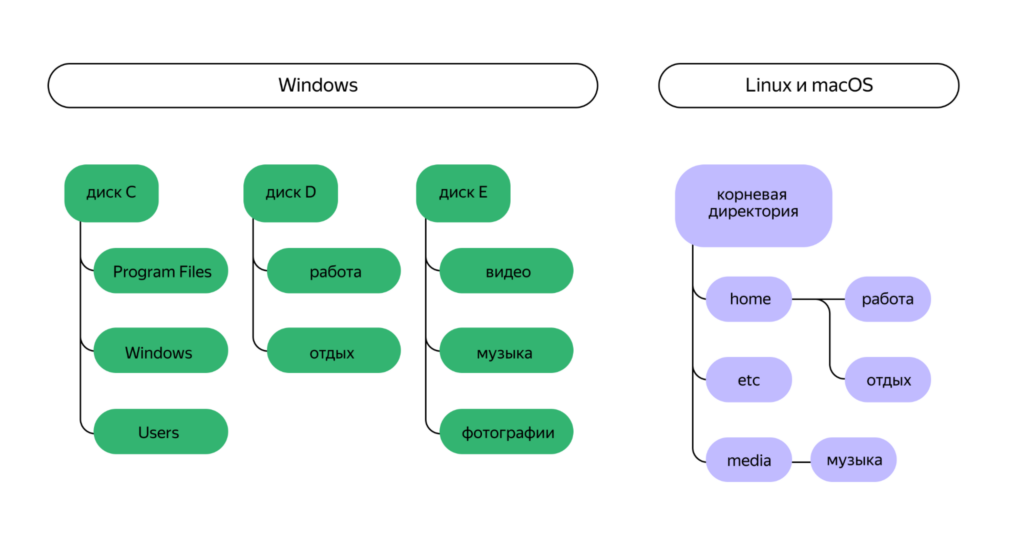
Дальше нам рассказывают про терминал и работу в командной строке, причём сразу говорят о различиях в написании пути и организации хранения файлов в разных операционных системах (и это хорошо):

Ну и тесты, само собой, чтобы знания точно остались в голове:

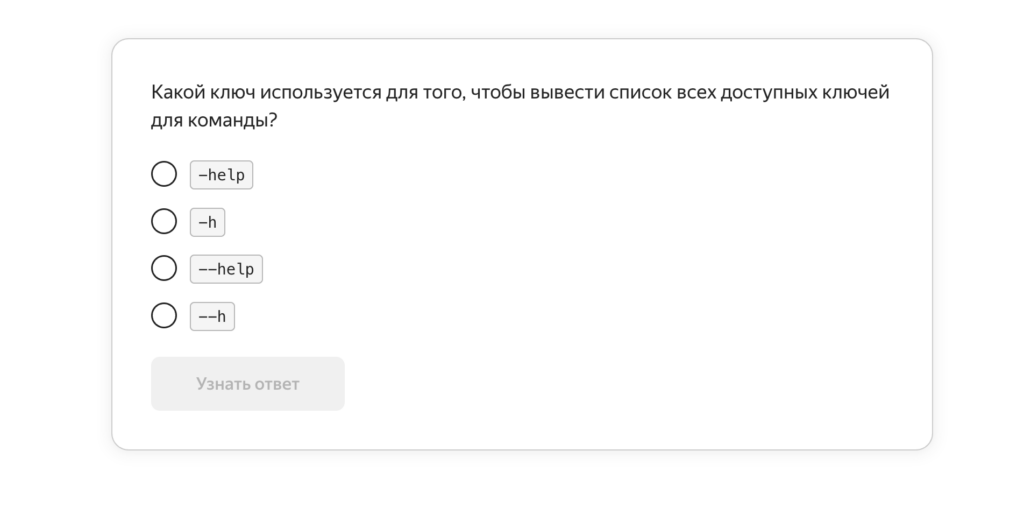
А ещё тут используется интересный подход к начальной практике: вместо того чтобы сразу переходить к настоящему терминалу, Практикум использует промежуточные тесты. Так он эмулирует работу с командной строкой и готовит студентов к тому, что там и как:

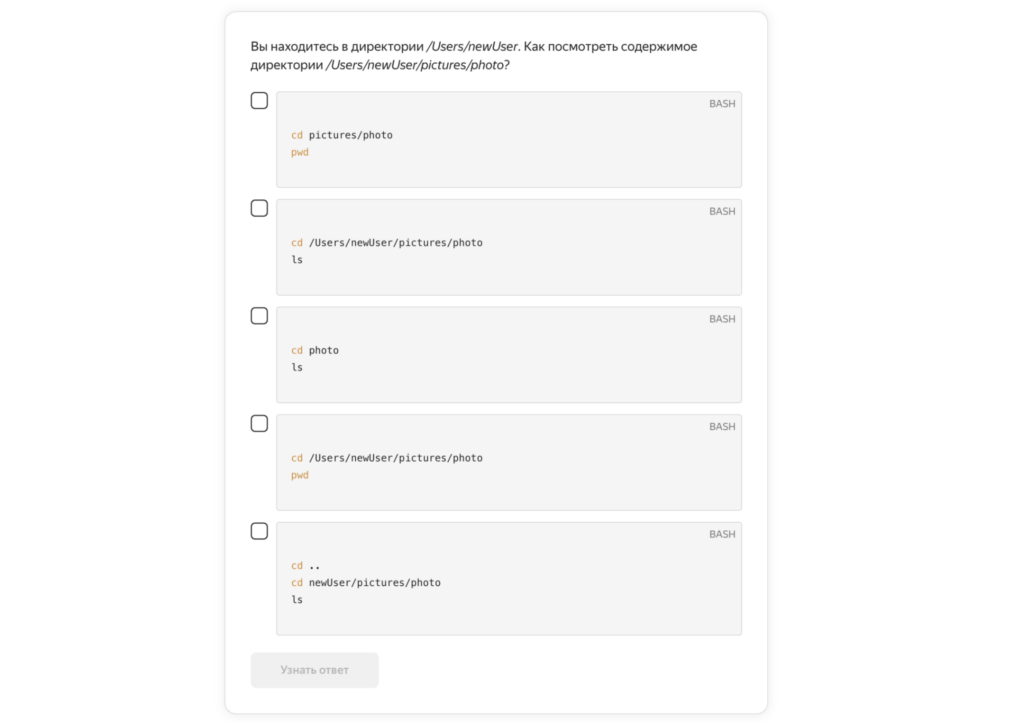
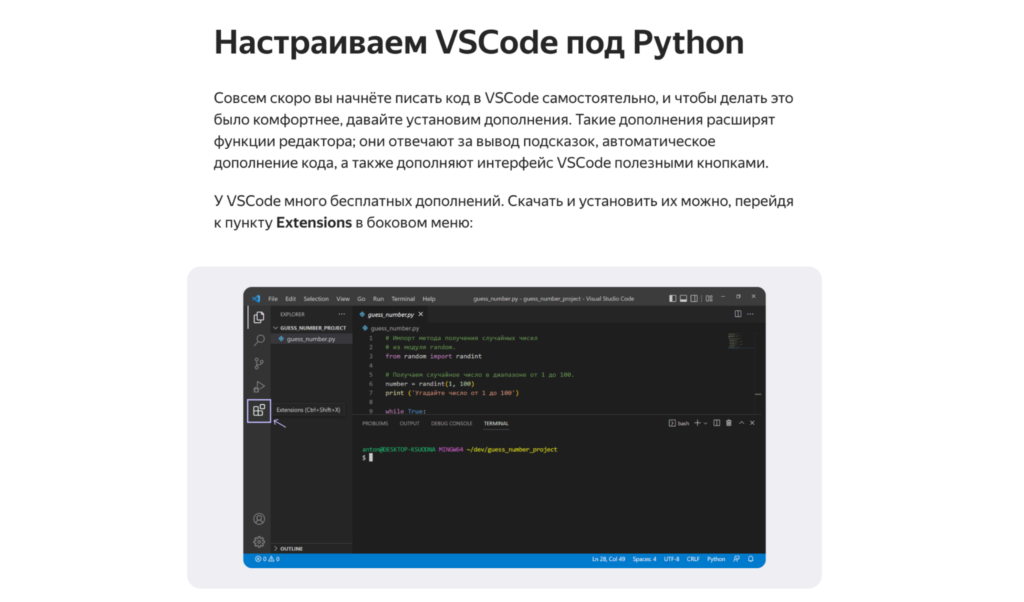
Чтобы студентам было проще писать код (и они сразу это делали как полноценные разработчики), в разделе объясняется, как выбрать и установить редактор кода (на примере VS Code), а после этого — заточить его под работу с Python:

После — теория о том, что такое виртуальное окружение и как с ним работать. Полезная штука на старте, которая позволяет разграничить учебные проекты и исключить их влияние друг на друга. Да и на работе многие программисты ведут проекты в виртуальном окружении. А ещё ребята сразу дают лайфхаки по ускорению работы с виртуалкой в терминале:

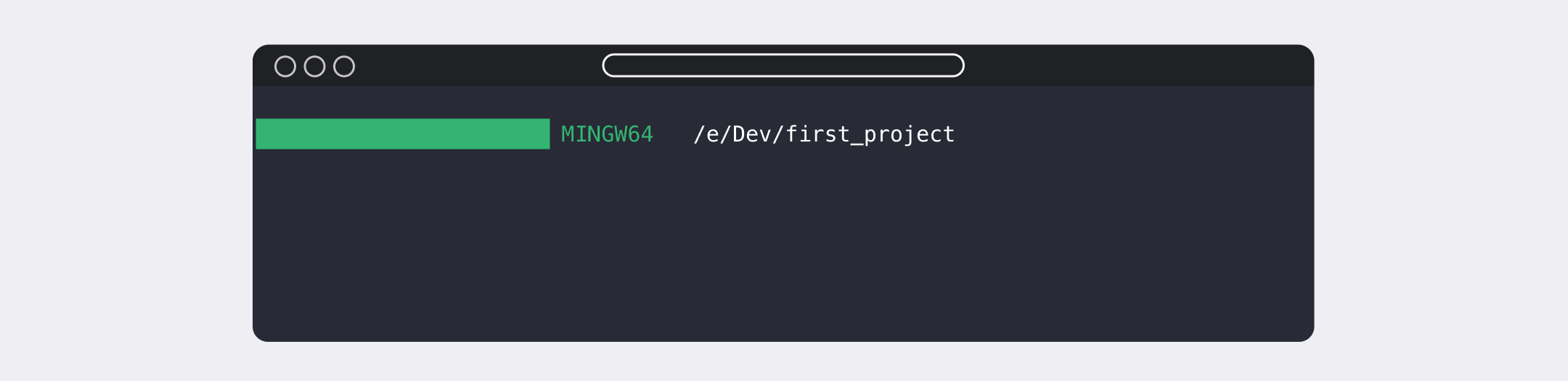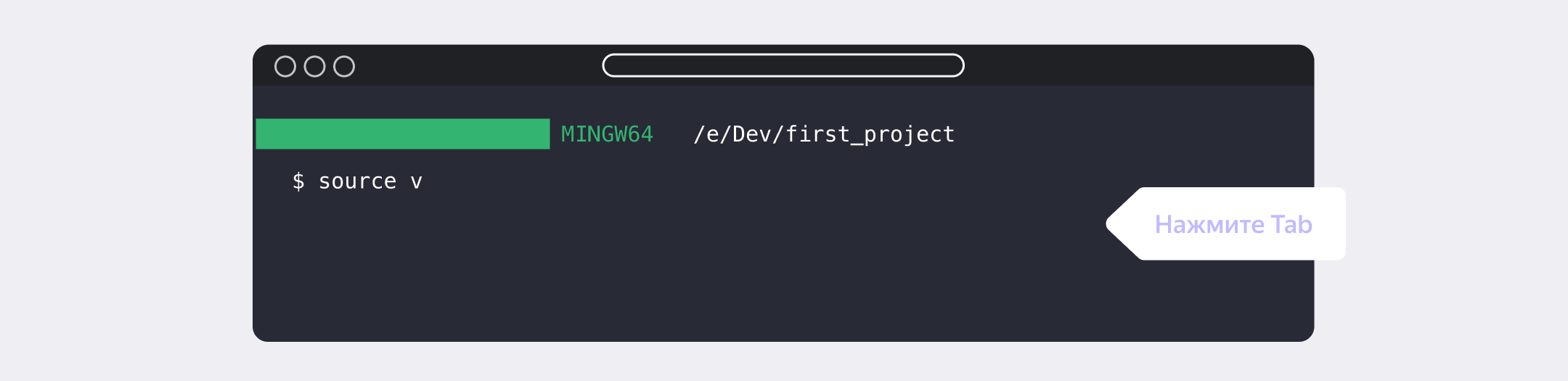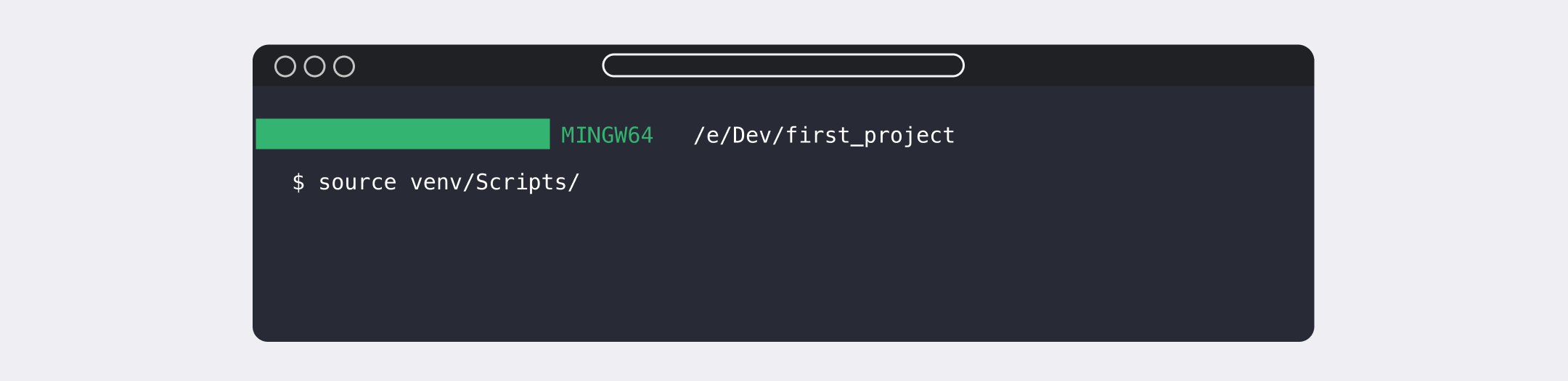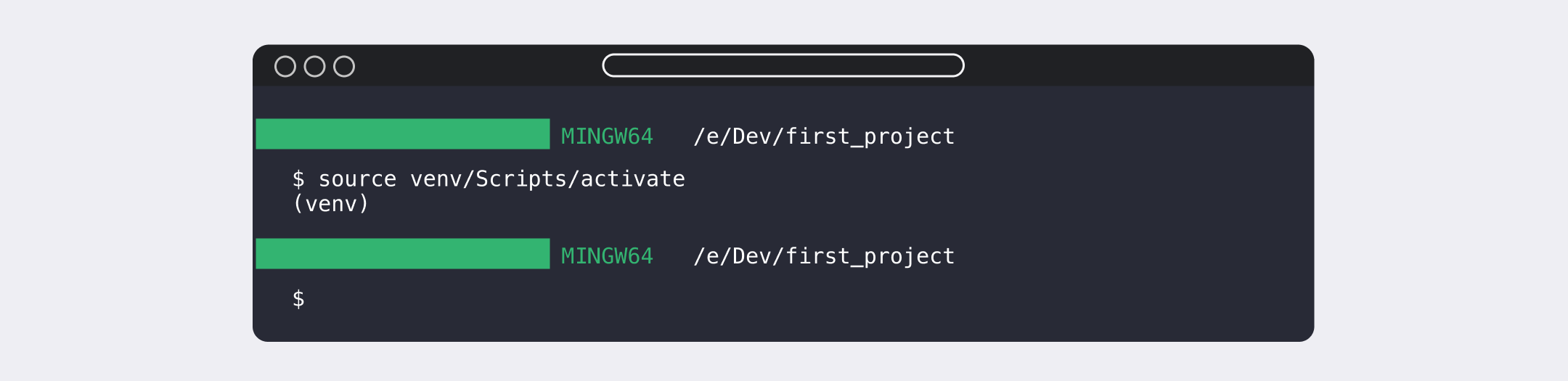
Настройка окружения: Git и Pytest
Здесь нас учат базовым принципам работы с Git, потому что, кроме написания кода, разработчик должен уметь хранить и версионировать код, используя системы контроля версий. Как правило, современная разработка — это групповая разработка, поэтому важно уметь пользоваться специальными веб-сервисами. Опыт, который появится при выполнении заданий, пригодится как в личных проектах, так и в командной работе.
Также мы поработаем с пакетом Pytest — инструментом для написания и запуска автоматических тестов, написанных на Python. Этот пакет будет использоваться в каждом финальном задании спринта, поэтому надо вникать сразу.
Так как это Практикум, то сразу уроки переходят к делу:
- регистрация на Гитхабе;
- аутентификация;
- создание ключей доступа.
Всё — с примерами, кодом и скриншотами, что должно быть:


После этого нам рассказывают всё, что нужно знать джуниор-разработчику про Гит и работу с ним:
- как создавать, удалять и клонировать репозитории;
- как в них что-то добавлять или изменять;
- как объединять код;
- что делать в случае ошибок;
- как всё откатить назад, если что-то сломалось.
И всё это — с постоянной проверкой знаний по ходу дела:

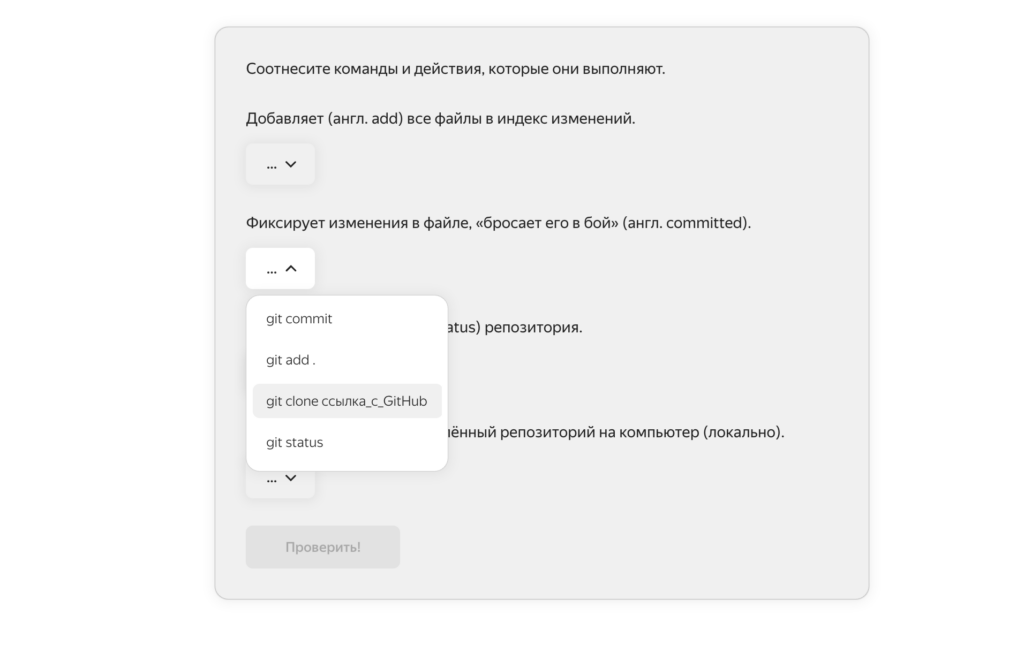
Раздаток с методическими материалами в курсе много — их можно скачивать, распечатывать и пользоваться в любое время. Секретных знаний там нет, но всё собрано в удобном и структурированном виде.
Если в процессе настройки или работы с программами могут появиться какие-то проблемы, то в курсе об этом говорится сразу. И сразу же о том, как это исправить.
Проект на Django
Тема большая, поэтому её разделили на шесть частей. Здесь начинается знакомство с фреймворком Django — одним из наиболее востребованных фреймворков для веб-разработки на Python.
Что будем делать:
- устанавливать и настраивать Django;
- создавать адреса, доступные в проекте;
- поработаем с HTML и наладим взаимодействие Django с базой данных;
- научимся управлять проектом через админ-зону;
- настроим эту зону так, чтобы администратору проекта было удобно и приятно работать.
Нас сразу погружают в суровый мир реальной заказной разработки:




Все исходные файлы и компоненты для проекта скачиваем с Гитхаба. Всё как в жизни:

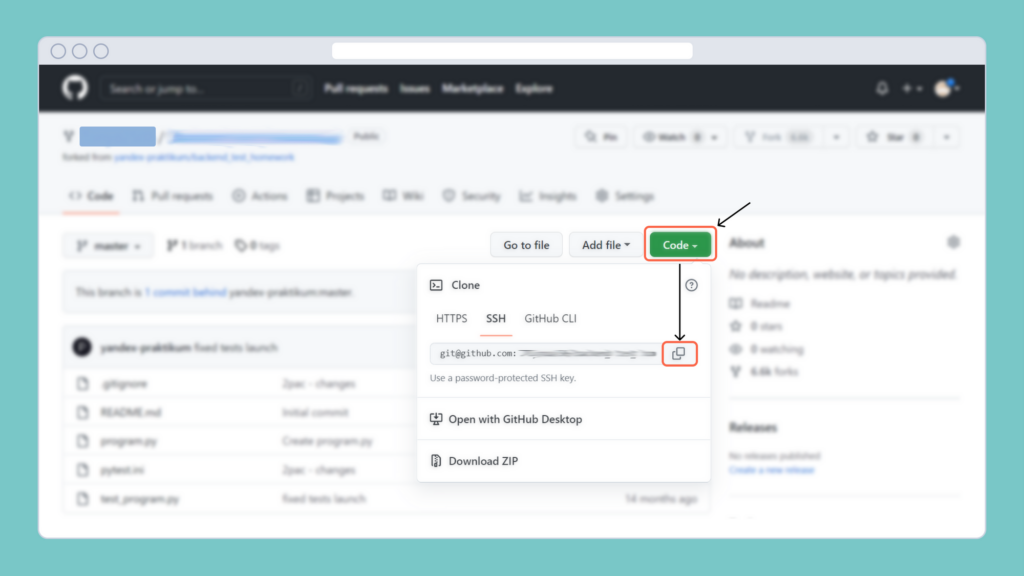
Дальше вспоминаем, как настраивать виртуальное окружение, ставим туда Django, настраиваем зависимости и приводим структуру к нужному виду. Вот так начинает пригождаться теория, которую мы изучали в прошлых спринтах.


Когда всё готово — нам рассказывают, куда разложить какие файлы, какие есть тонкости настройки проекта и какие ошибки тут можно совершить (чтобы посмотреть и их не совершать :-)
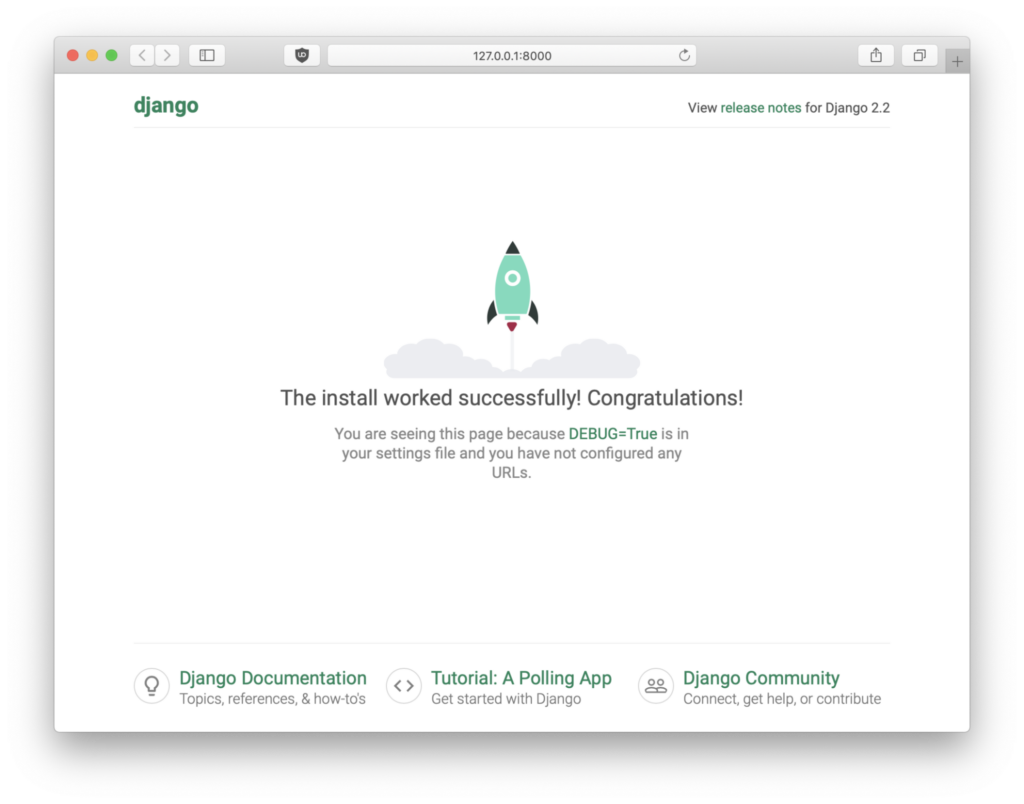
После этого учимся запускать свой Django-сервер и связывать его с виртуальным окружением, чтобы в конце увидеть страницу с картинкой успешного запуска:

Тесты по всей теории и практике, что мы делаем, тоже на месте:

Так как мы делаем полноценное приложение, то и регистрировать его тоже будем по-настоящему:


Дальше — теория (и море практики) про роутинг запросов, их обработку и адреса в Django. Всё начинается с милой и простой картинки, которую мы бы не смогли полностью понять, если бы не знали всей предыдущей теории. А так — всё понятно:

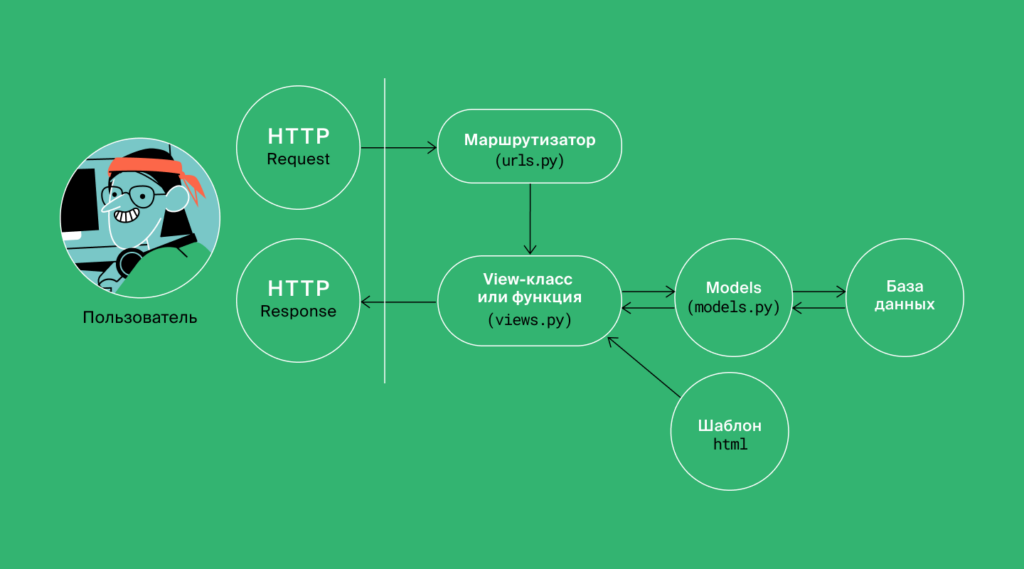
Если что, мы уже изучили разное и попрактиковались настолько, что теперь такой текст не вызывает сложностей (а раньше казался сложным шаманством разработчиков):


Базы данных, HTML и Django
Django-проект должен хранить массу данных: посты пользователей, информацию о самих пользователях, большое количество технической информации. И со всем этим бэкенд-программист должен уметь работать. Но сначала — про объекты классов и объекты в базе данных.
Классы описывают новые типы объектов и позволяют создавать экземпляры таких объектов. Записи в базах данных тоже описывают объекты — наборы свойств, которыми можно управлять.
👉 Есть способ связать данные объектов с записями в БД, упростить и автоматизировать стандартные операции и при этом обойтись без запросов на SQL. Всё это делает Django ORM — это инструмент для работы с данными реляционной БД с помощью классов, которые создаёт сам программист. Реализаций ORM много, работать будем с ORM, встроенной в Django.
После объяснения теории сразу попадаем в тренажёр. Тут уже серьёзнее, чем было: появляется дерево с файлами проекта, редактор кода и браузер. Пишешь код, проверяешь и сразу видишь результат работы Django в браузере (как бы увидел это пользователь):
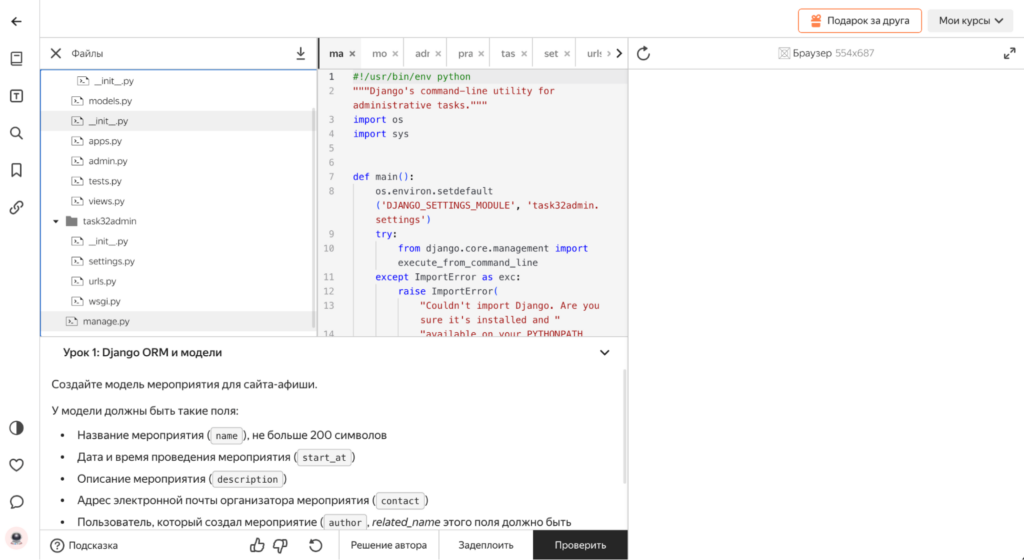
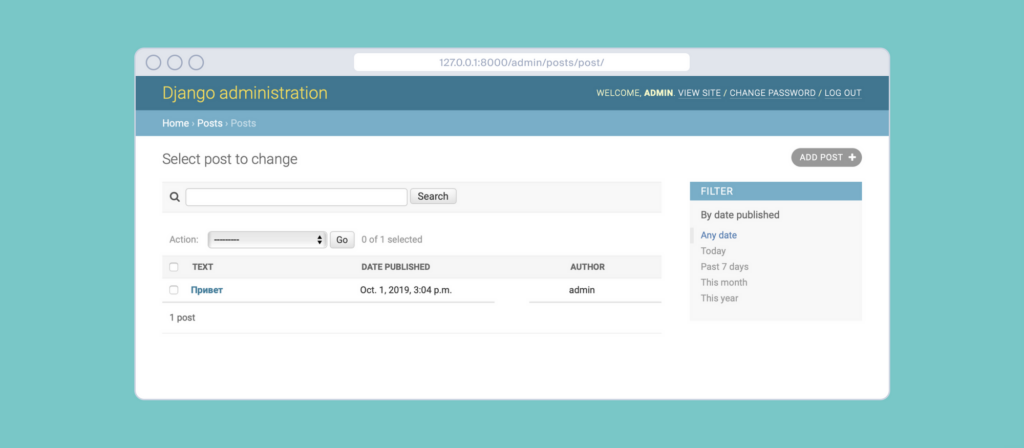
Здесь же нас сразу учат работать с админкой и регистрировать там новые компоненты (а после этого снова переносимся в тренажёр, где будем настраивать интерфейсы и логику работы некоторых элементов админки):

Чтобы результат работы с базой данных был виден на странице, нас учат формировать контент для этой страницы. Например, это можно сделать в виде списка (если что, это не чистый HTML, а шаблон на Django):
{% for post in posts %}
<ul>
<li>
Автор: {{ post.author.get_full_name }}
</li>
<li>
Дата публикации: {{ post.pub_date|date:"d E Y" }}
</li>
</ul>
<p>{{ post.text }}</p>
<a href="">все записи группы</a>
{% if not forloop.last %}<hr>{% endif %}
{% endfor %}
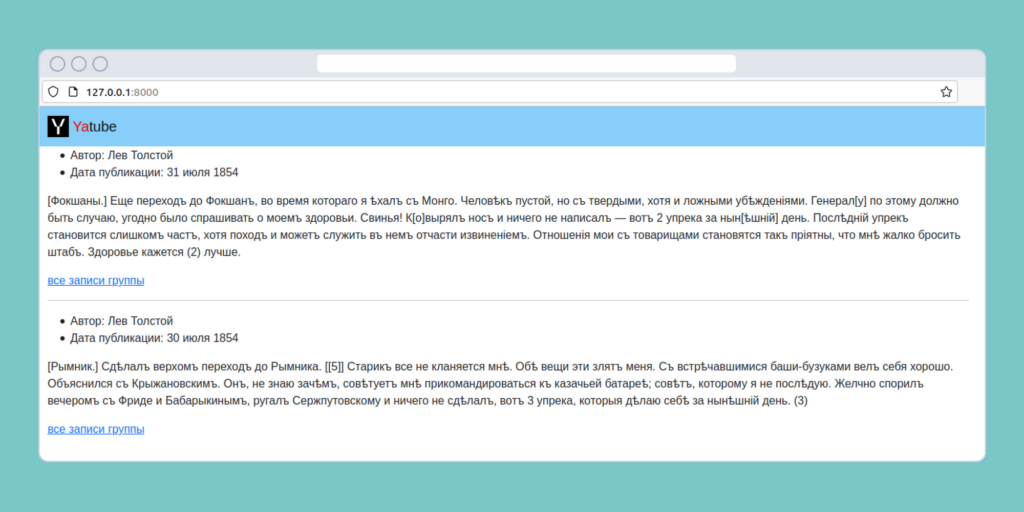
В результате выполнения этого кода получим классический интерфейс форумов (который жив и работает до сих пор):
Django ORM
Сделали проект — и продолжаем изучать фреймворк Django:
- попрактикуемся составлять сложные запросы к базе данных и выводить на страницы проекта информацию, полученную из БД;
- познакомимся с декораторами — востребованным в Python паттерном, который призван упростить разработку;
- поработаем со встроенной в Django моделью пользователя;
- настроим постраничный вывод информации;
- познакомимся с контекст-процессором.
ORM (Object-Relational Mapping) — это «переводчик» между Python и базой данных. Вместо SQL-запросов мы пишем код на Python, а ORM сам превращает его в запросы к БД.
Примеры фильтрации:
Простой поиск (filter): «Дай мне всех пользователей, у которых имя 'Вася'»:
User.objects.filter(name="Вася") # → [Вася1, Вася2, Вася3...]
Сложные условия (Q, exclude): «Найди всех, кроме Васи, но старше 18»:
User.objects.exclude(name="Вася").filter(age__gt=18) # → [Петя, Маша...]
Сортировка (order_by): «Отсортируй пользователей по возрасту (от младшего к старшему)»:
User.objects.all().order_by("age") # → [Саша (5), Маша (20), Дед (99)]
Ограничение ([:5] или .first()): «Дай только первых 5 пользователей»:
User.objects.all()[:5] # → [Вася, Петя, Маша, Саша, Глаша]
✅ Зачем это нужно?
- Не надо писать SQL вручную — ORM сам сгенерирует правильный запрос.
- Безопасность — ORM защищает от SQL-инъекций (взломов через запросы).
- Удобно — код выглядит как обычный Python, а не как страшные SQL-строки.
После всей теории (а её сильно больше, чем мы тут рассказали, раз примерно в 50), нам дают такую задачу:
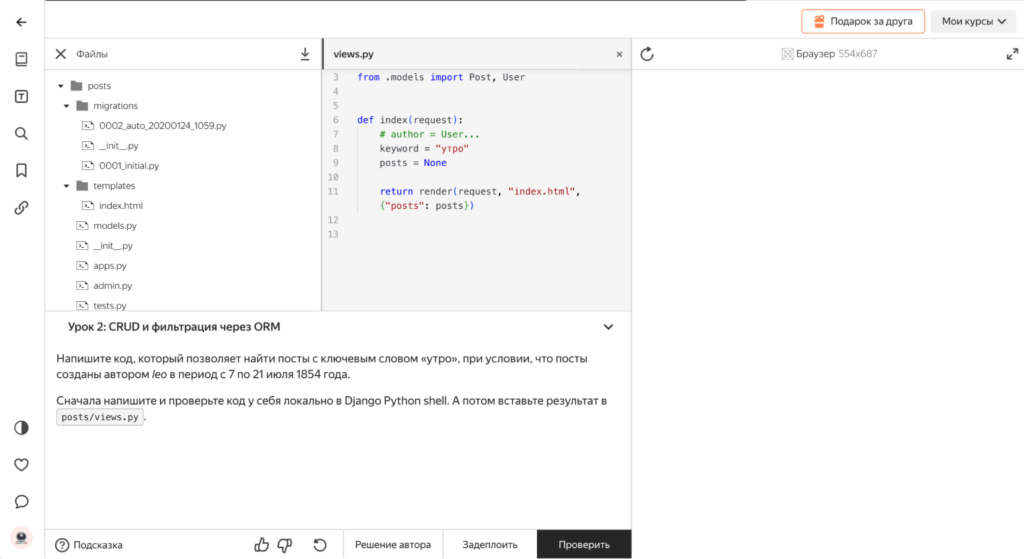
Напишите код, который позволяет найти посты с ключевым словом «утро», при условии, что посты созданы автором leo в период с 7 по 21 июля 1854 года.
Решаем, как обычно, в тренажёре:
Тесты по разным аспектам теории тоже никуда не делись :-)

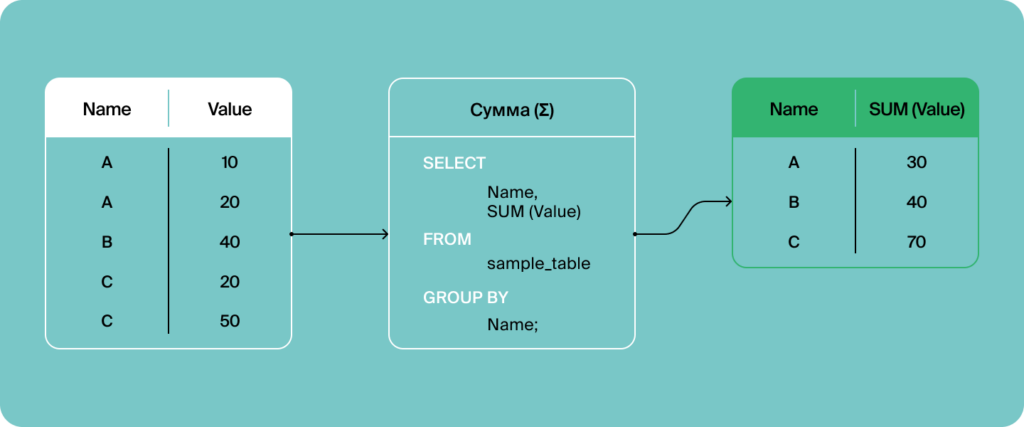
Также разбираемся с агрегирующими функциями — они позволяют находить суммарные значения по определённому полю в базе данных или по какой-то заданной выборке. Например, так можно найти самый результативный день по лайкам или комментариям в соцсети.
Вот как это работает концептуально:

А вот как в реальных задачах в разных частях проекта:
>>> from django.db.models import Max, Count
# найти максимальное значение id для объектов Post
>>> Post.objects.aggregate(Max("id"))
(0.000) SELECT MAX("posts_post"."id") AS "id__max" FROM "posts_post"; args=()
{'id__max': 43}
# пересчитать объекты id в модели Post
>>> Post.objects.aggregate(Count("id"))
(0.000) SELECT COUNT("posts_post"."id") AS "id__count" FROM "posts_post"; args=()
{'id__count': 37}
37
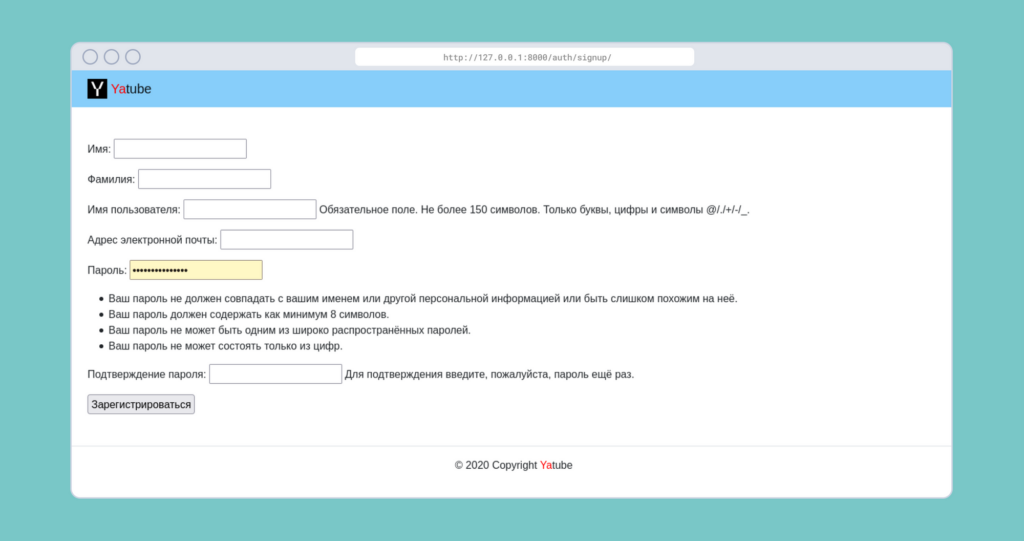
Ещё из интересного можно отметить создание своей формы регистрации для проекта. Это полноценная страница, где дизайн, логику фронтенда и сервера мы настроили с нуля. При этом это не просто страница: она работает, пользователи регистрируются, записи попадают в БД — всё по правде.
Вот шаблон страницы:
<!-- templates/users/signup.html -->
{% extends "base.html" %}
{% block title %}Зарегистрироваться{% endblock %}
{% block content %}
<form method="post" action="{% url 'users:signup' %}">
{% csrf_token %}
{{ form.as_p }}
<input type="submit" value="Зарегистрироваться">
</form>
{% endblock %}
А вот как это выглядит в браузере (на нашем локальном Django-сервере):

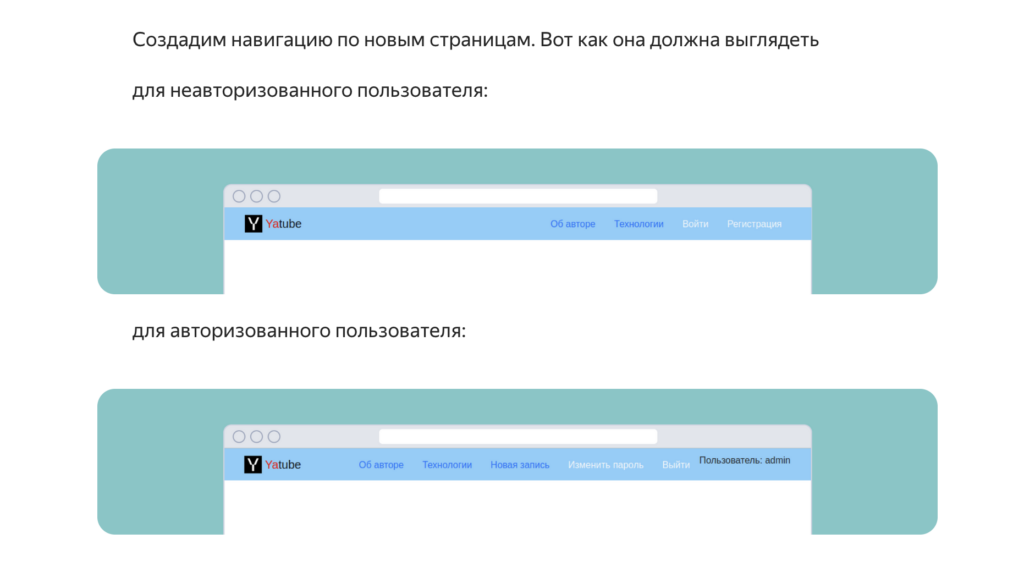
Анонимные посетители должны видеть сайт иначе, чем авторизованные пользователи. Авторизованным пользователям должны быть доступны ссылки на выход и смены пароля, а анонимным — ссылки на регистрацию и авторизацию.
В Django есть механизм, с помощью которого прямо в шаблоне можно определить, авторизован пользователь или нет. В зависимости от статуса посетителя можно показывать или скрывать определённые фрагменты страницы. Это мы про контекст-процессоры. Про них рассказывается (и показывается) тоже много, тренажёры есть и для этого.
Например, можно сделать разную шапку сайта для тех, кто авторизован и кто нет (смотрим на правый верхний угол):

Что дальше
Вот эта вся махина с Джанго, тестами и всем остальным — всего третий блок из одиннадцати в курсе «Python-разработчик». Зацените масштаб всего курса в целом (и количество знаний и навыков, которые там даются).
В следующей серии будем разбирать API: интерфейс взаимодействия программ. Будет не менее интересно, подпишитесь, чтобы не пропустить.






















