Однажды мы рассказывали, как утащить что угодно с любого сайта, — написали свой парсер и забрали с чужого сайта заголовки статей. Теперь сделаем круче — покажем на примере нашего сайта, как можно спарсить вообще весь текст всех статей.
Парсинг — это когда вы забираете какую-то конкретную информацию с сайта в автоматическом режиме. Для этого пишется софт (скрипт или отдельная программа), софт настраивается под конкретный сайт, и дальше он ходит по нужным страницам и всё оттуда забирает.
После парсинга полученный текст можно передать в другие программы — например подстроить свои цены под цены конкурентов, обновить информацию на своём сайте, проанализировать текст постов или собрать бигдату для тренировки нейросетей.
Что делаем
Сегодня мы спарсим все статьи «Кода» кроме новостей и задач, причём сделаем всё так:
- Научимся обрабатывать одну страницу.
- Сделаем из этого удобную функцию для обработки.
- Найдём все адреса всех нужных страниц.
- Выберем нужные нам рубрики.
- Для каждой рубрики создадим отдельный файл, в который добавим всё текстовое содержимое всех статей в этой рубрике.
Чтобы потом можно было нормально работать с текстом, мы не будем парсить вставки с примерами кода, а ещё постараемся избавиться от титров, рекламных баннеров и плашек.
Будем работать поэтапно: сначала научимся разбирать контент на одной странице, а потом подгрузим в скрипт все остальные статьи.
Выбираем страницу для отладки
Технически самый простой парсинг делается двумя командами в Python, одна из которых — подключение сторонней библиотеки. Но этот код не слишком полезен для нашей задачи, сейчас объясним.
from urllib.request import urlopen
inner_html_code = str(urlopen('АДРЕС СТРАНИЦЫ').read(),'utf-8')Когда мы заберём таким образом страницу, мы получим сырой код, в котором будет всё: метаданные, шапка, подвал и т. д. А нам нужно не только достать информацию из самой статьи (а не всей страницы), а ещё и очистить её от ненужной информации.
Чтобы скрипт научился отбрасывать ненужное, придётся ему прописать, что именно отбрасывать. А для этого нужно знать, что нам не нужно. А значит, нам нужно взять какую-то старую статью, в которой будут все ненужные элементы, и на этой одной странице всё объяснить.
Для настройки скрипта мы возьмём нашу старую статью. В ней есть всё нужное для отладки:
- текст статьи,
- подзаголовки,
- боковые ссылки,
- кат с кодом,
- просто вставки кода в текст,
- титры,
- рекламный баннер.


Получаем сырой текст
Вот что мы сейчас сделаем:
- Подключим библиотеку urlopen для обработки адресов страниц.
- Подключим библиотеку BeautifulSoup для разбора исходного кода страницы на теги.
- Получим исходный код страницы по её адресу.
- Распарсим его по тегам.
- Выведем текстовое содержимое распарсенной страницы.
На языке Python это выглядит так:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSoup
from bs4 import BeautifulSoup
# получаем исходный код страницы
inner_html_code = str(urlopen('https://thecode.media/parsing/').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# выводим содержимое страницы
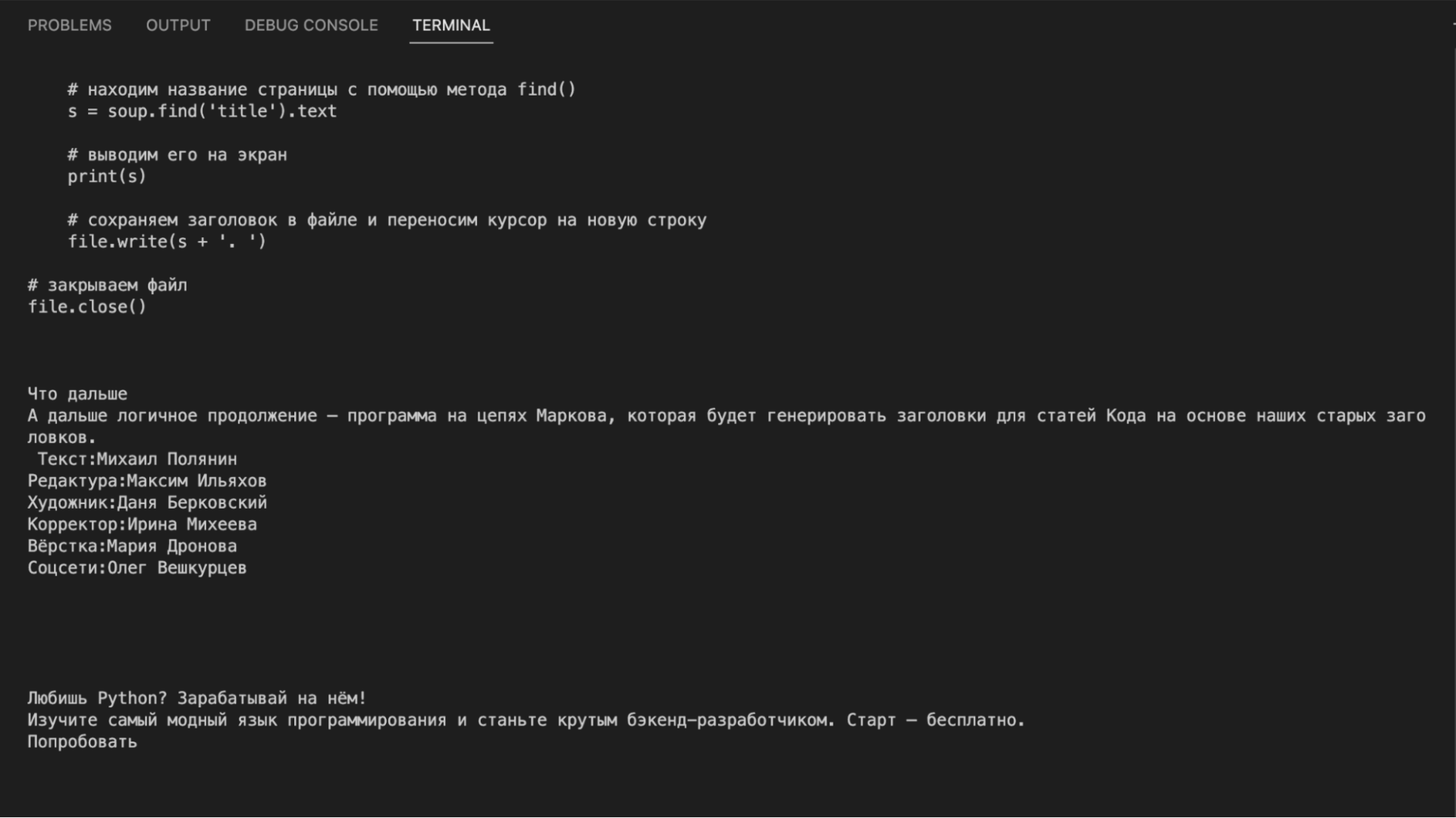
print(inner_soup.get_text())Если посмотреть на результат, то видно, что в вывод пошло всё: и программный код из примеров, и текст статьи, и служебные плашки, и баннер, и ссылки с рекомендациями. Такой мусорный текст не годится для дальнейшего анализа:
Чистим текст
Так как нам требуется только сама статья, найдём раздел, в котором она лежит. Для этого посмотрим исходный код страницы, нажав Ctrl+U или ⌘+⌥+U. Видно, что содержимое статьи лежит в блоке <div class=”article-content line-numbers”>, причём такой блок на странице один.

Чтобы из всего исходного кода оставить только этот блок, используем команду find() с параметром ‘div’, {“class”: ‘article-content’} — она найдёт нужный нам блок, у которого есть характерный признак класса.
Добавим эту команду перед выводом текста на экран:
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find(‘div’, {“class”: ‘article-content’})
Стало лучше: нет мусора до и после статьи, но в тексте всё ещё много лишнего — содержимое ката с кодом, преформатированный код (вот такой), вставки с кодом, титры и рекламный баннер.
Чтобы избавиться и от этого, нам нужно знать, в каких тегах или блоках это лежит. Для этого нам снова понадобится заглянуть в исходный код страницы. Логика будет такая: находим фрагмент текста → смотрим код, который за него отвечает, → удаляем этот код из нашей переменной.Например, если мы хотим убрать титры, то находим блок, где они лежат, а потом в цикле удаляем его командой decompose().

Сделаем функцию, которая очистит наш код от любых разделов и тегов, которые мы укажем в качестве параметра:
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()А теперь добавим такой код перед выводом содержимого:
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
Точно так же проанализируем исходный код и добавим циклы для удаления остального мусора:
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры, перебирая все их возможные индексы в цикле (потому что баннеры в коде имеют номера от 1 до 99)
for i in range(99):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')Теперь всё в порядке: у нас есть только текст статьи, без внешнего обвеса, лишнего кода и ссылок. Можно переходить к массовой обработке.
Собираем функцию
У нас есть скрипт, который берёт одну конкретную ссылку, идёт по ней, чистит контент и получает очищенный текст. Сделаем из этого функцию — на вход она будет получать адрес страницы, а на выходе будет давать обработанный и очищенный текст. Это нам пригодится на следующем шаге, когда будем обрабатывать сразу много ссылок.
Если запустить этот скрипт, получим тот же результат, что и в предыдущем разделе.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
print(clear_text('https://thecode.media/parsing/'))Получаем адреса всех страниц
Одна из самых сложных вещей в парсинге — получить список адресов всех нужных страниц. Для этого можно использовать:
- карту сайта,
- внутренние рубрикаторы,
- разделы на сайте,
- готовые страницы со всеми ссылками.
В нашем случае мы воспользуемся готовой страницей — там собраны все статьи с разбивкой по рубрикам: https://thecode.media/all/. Но даже в этом случае нам нужно написать код, который обработает эту страницу и заберёт оттуда только адреса статей. Ещё нужно предусмотреть, что нам не нужны ссылки из новостей и задач.
Идём в исходный код общей страницы и видим, что все ссылки лежат внутри списка:

При этом каждая категория статей лежит в своём разделе — именно это мы и будем использовать, чтобы обработать только нужные нам категории. Например, вот как рубрика «Ахах» выглядит на странице:
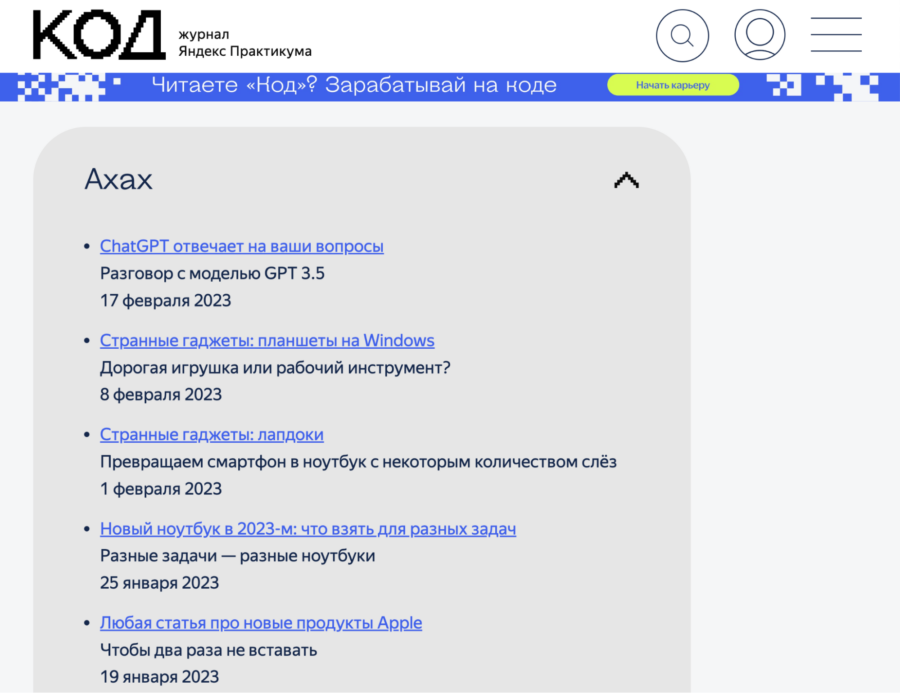
А вот она же — но в исходном коде. По названию легко понять, какой блок за неё отвечает:
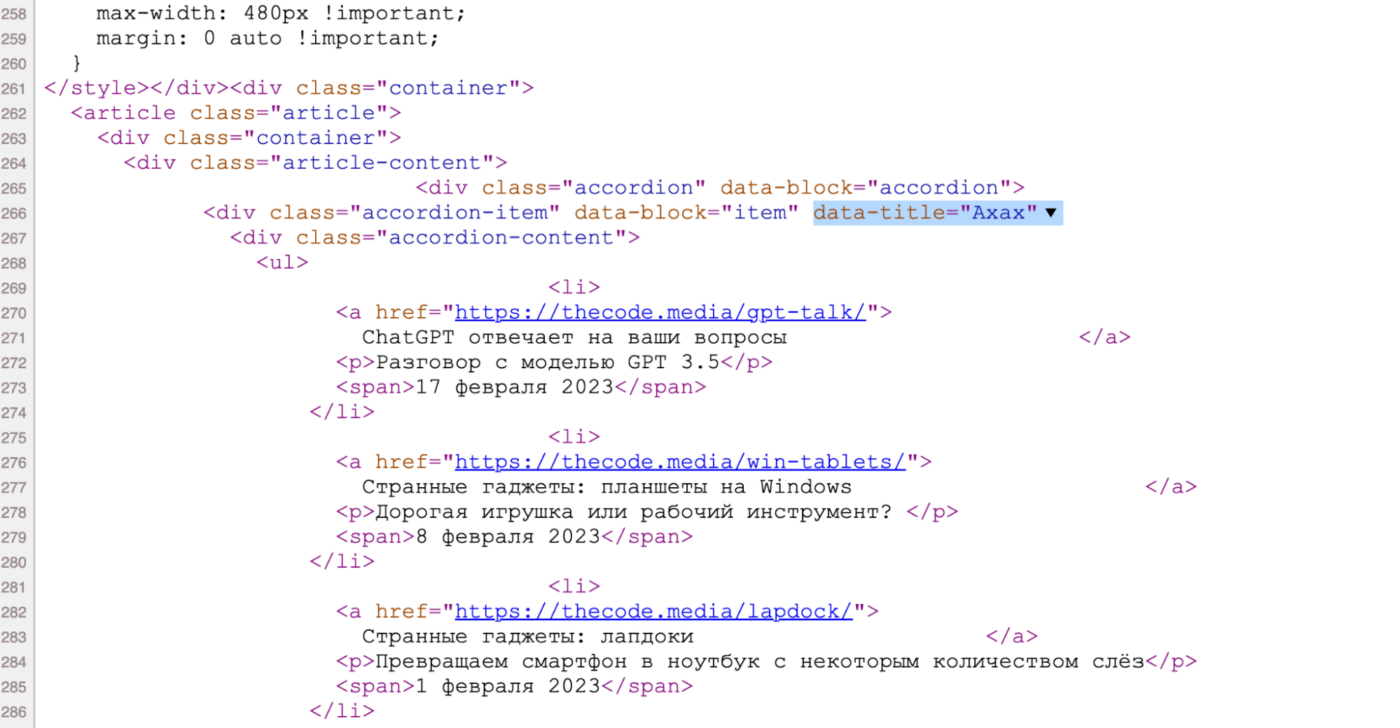
Чтобы найти раздел в коде по атрибуту, используем команду find() с параметром attrs — в нём мы укажем название рубрики. А чтобы найти адрес в ссылке — используем команду select(), в которой укажем, что ссылка должна лежать внутри элемента списка.
Теперь логика будет такая:
- Создаём список с названиями нужных нам рубрик.
- Делаем функцию, куда будем передавать эти названия.
- Внутри функции находим рубрику по атрибуту.
- Перебираем все элементы списка со ссылками.
- Находим там адреса и записываем в переменную.
- Для проверки — выводим переменную с адресами на экран.
def get_all_url(data_title):
html_code = str(urlopen('https://thecode.media/all/').read(),'utf-8')
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# выводим найденные адреса
print(url)
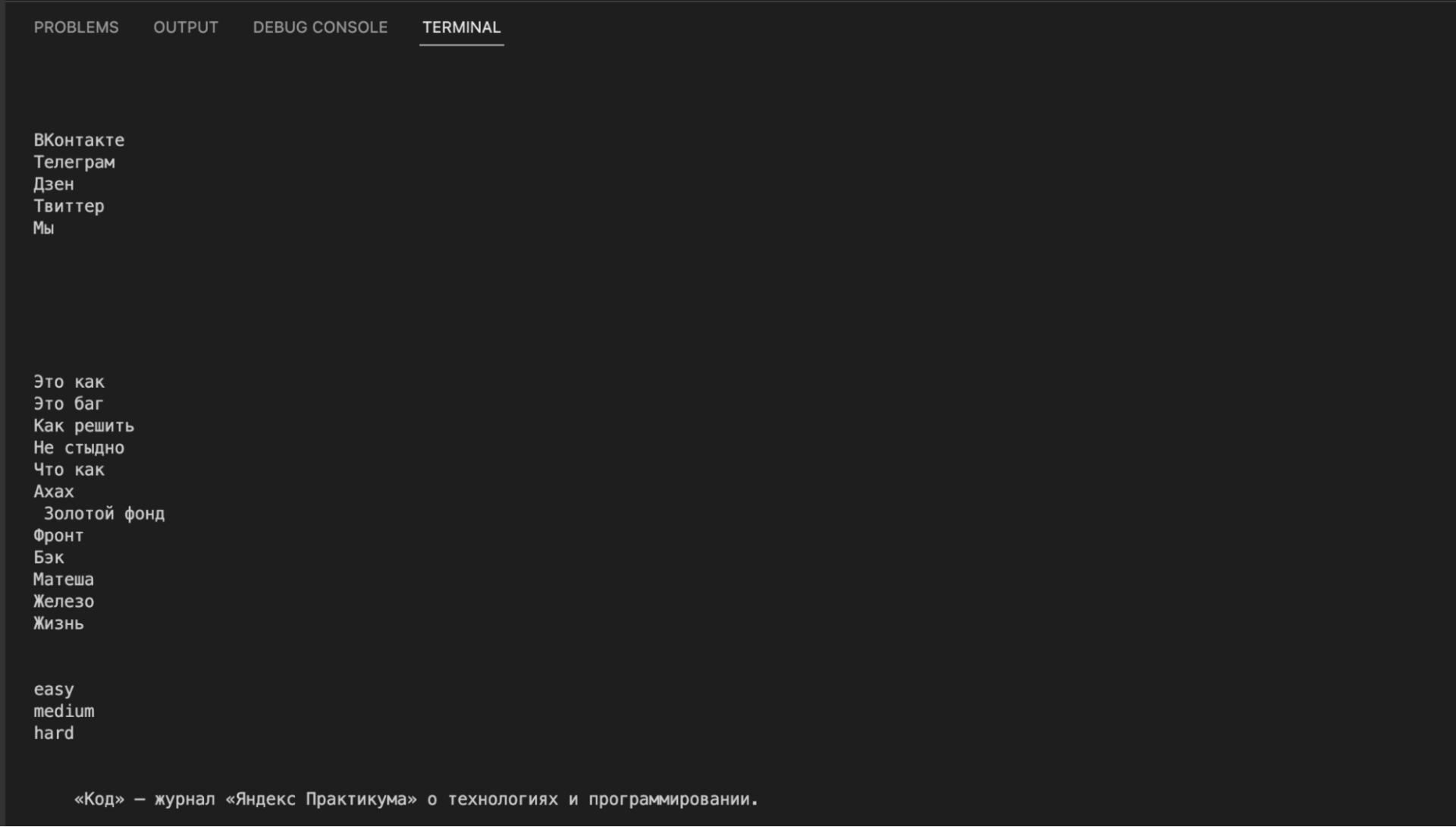
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)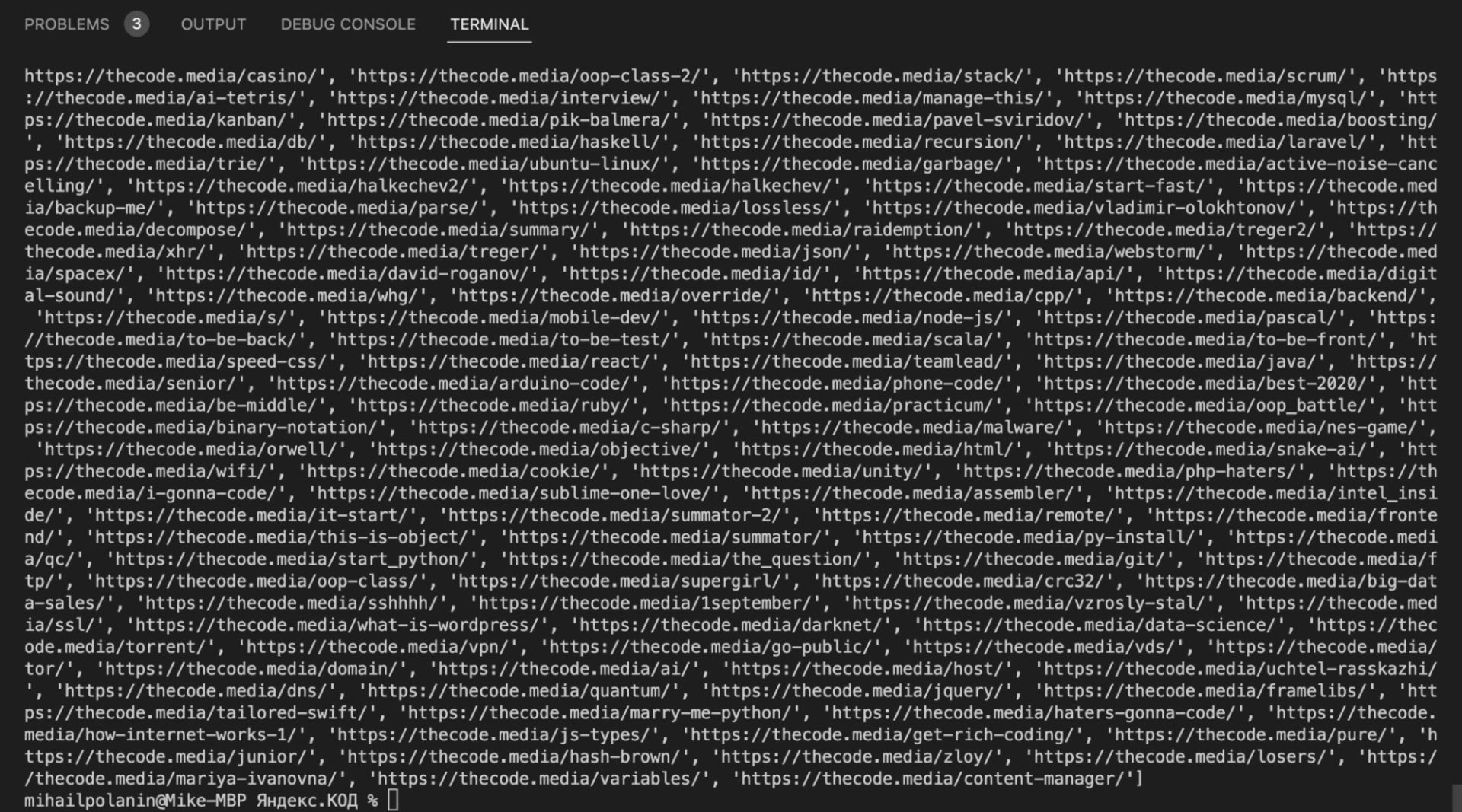
На выходе у нас все адреса страниц из нужных рубрик. Теперь объединим обе функции и научим их сохранять текст в файл.

Сохраняем текст в файл
Единственное, чего нам сейчас не хватает, — это сохранения в файл. Чтобы каждая рубрика хранилась в своём файле, привяжем имя файла к названию рубрики. Дальше логика будет такая:
- Берём функцию get_all_url(), которая формирует список всех адресов для каждой рубрики.
- В конец этой функции добавляем команду создания файла с нужным названием.
- Открываем файл для записи.
- Перебираем в цикле все найденные адреса и тут же отправляем каждый адрес в функцию clear_text().
- Результат работы этой функции — готовый контент — записываем в файл и переходим к следующему.
Так у нас за один прогон сформируются адреса, и мы получим содержимое страницы, которые сразу запишем в файл. Читайте комментарии, чтобы разобраться в коде:
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# очищаем код от выбранных элементов
def delete_div(code,tag,arg):
# находим все указанные теги с параметрами
for div in code.find_all(tag, arg):
# и удаляем их из кода
div.decompose()
# очищаем текст по указанному адресу
def clear_text(url):
# получаем исходный код страницы
inner_html_code = str(urlopen(url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
inner_soup = BeautifulSoup(inner_html_code, "html.parser")
# оставляем только блок с содержимым статьи
inner_soup = inner_soup.find('div', {"class": 'article-content'})
# удаляем титры
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-titry'})
# удаляем боковые ссылки
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-link-aside'})
# удаляем баннеры
for i in range(11):
delete_div(inner_soup, "div", {'class':'wp-block-lazyblock-banner'+str(i)})
# удаляем кат
delete_div(inner_soup, "div", {'class':'accordion'})
# удаляем преформатированный код
delete_div(inner_soup, 'pre','')
# удаляем вставки с кодом
delete_div(inner_soup,'code','')
# возвращаем содержимое страницы
return(inner_soup.get_text())
# формируем список адресов для указанной рубрики
def get_all_url(data_title):
# считываем страницу со всеми адресами
html_code = str(urlopen('https://thecode.media/all/').read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим рубрику по атрибуту
s = soup.find(attrs={"data-title": data_title})
# тут будут все найденные адреса
url = []
# перебираем все теги ссылок, которые есть в списке
for tag in s.select("li:has(a)"):
# добавляем адрес ссылки в нашу общую переменную
url.append(tag.find("a")["href"])
# имя файла для содержимого каждой рубрики
content_file_name = data_title + '_content.txt'
# открываем файл и стираем всё, что там было
file = open(content_file_name, "w")
# перебираем все адреса из списка
for x in url:
# сохраняем обработанный текст в файле и переносим курсор на новую строку
file.write(clear_text(x) + '\n')
# закрываем файл
file.close()
# названия рубрик, которые нам нужны
division = ['Ахах','Не стыдно','Это баг','Это как']
# перебираем все рубрики
for el in division:
# и обрабатываем каждую рубрику отдельно
get_all_url(el)
Что дальше
Теперь у нас есть все тексты всех статей. Как-нибудь проанализируем частотность слов в них (как в проекте с текстами Льва Толстого) или научим нейросеть писать новые статьи на основе старых.