








Если идти на PostgreSQL собеседование без чёткой картины, какие темы актуальны для каждого грейда, легко потратить время на материал, до которого разговор даже не дойдёт. Реальное интервью на Junior и Middle обычно проходит по предсказуемой схеме: интервьюер сначала проверяет владение синтаксисом, затем — понимание того, как СУБД устроена изнутри, и в конце даёт пару практических задач на запросы. В этом материале собраны типовые вопросы для обоих грейдов в формате «вопрос → ответ → чего ждёт интервьюер», задачи с пояснениями, построчный разбор вывода EXPLAIN ANALYZE и список ошибок, на которых регулярно срезаются даже подготовленные кандидаты.
Для этой статьи я подготовил сгенерированный SQL-файл с таблицами, тестовыми данными и комментариями, чтобы вы могли попрактиковаться и поэкспериментировать с запросами из примеров.
У НАС ЕСТЬ КАРЬЕРНЫЙ БОТ
Внутри бота актуальные дорожные карты по профессиям, разборы карьерных треков и истории тех, кто уже прошёл этот путь. Иногда там же лежит промокод на курсы Практикума.
Откройте бота (можно просто кликнуть) и узнайте как расти в IT, если вы джун, мидл или сеньор!
Как устроено собеседование по PostgreSQL: что спрашивают и на каком уровне
Собеседование по практически любой реляционной СУБД можно разделить на 3 ступени, в случае PostgreSQL это разделение видно особенно отчётливо. От Junior ждут уверенного владения синтаксисом и базовыми конструкциями — без погружения во внутренности. У Middle-специалиста уже спросят про MVCC, логику работы планировщика и про то, почему конкретный запрос отрабатывает за две секунды вместо двадцати миллисекунд. Senior уже двигается в сторону инфраструктуры — репликация, журналирование, отказоустойчивость. Эта о первых двух ступенях, через них проходит большинство разработчиков в первые год-два в профессии.
| Уровень | Что проверяется | Типичный вопрос |
|---|---|---|
| Junior | Синтаксис SQL, базовые конструкции, типы данных | «Чем DELETE отличается от TRUNCATE?» |
| Middle | Механизмы работы БД, оптимизация, транзакции | «Как PostgreSQL выбирает план запроса?» |
| Senior (за рамками статьи) | Архитектура, репликация, WAL | «Как работает Write-Ahead Logging?» |
В живом разговоре интервьюер обычно стартует с разминочных вопросов и поднимает планку, как только видит уверенные ответы. Если кандидат вязнет на синтаксических деталях, до Middle-блока обсуждение, как правило, просто не доходит.
Основы PostgreSQL: что нужно знать до первого собеседования
PostgreSQL — это объектно-реляционная СУБД с открытым исходным кодом, которая соблюдает требования ACID, обладает развитой типовой системой и расширяется через дополнительные модули. Тем, кто раньше имел дело только с MySQL или SQLite, важно сразу зафиксировать ключевые отличия: строгая типизация, расширяемая система типов, JSONB, массивы и свои типы данных SQL.
- MVCC без блокировок на чтение — чтение никогда не встаёт в очередь за записью, а запись не ждёт читателей; это противоположность классическим блокировочным моделям.
- Расширяемая система типов — пользователь может объявлять собственные типы, операторы и функции, а не только использовать встроенные.
- Нативная поддержка массивов и JSONB — массивы и бинарный JSON ведут себя как обычные индексируемые типы, а не как сериализованный текст.
- Полнотекстовый поиск из коробки — встроенные tsvector и tsquery дают морфологию и ранжирование без подключения внешних движков.
Этих четырёх пунктов достаточно, чтобы аккуратно ответить на вопрос об отличиях PostgreSQL от MySQL, это демонстрирует понимание специфики PostgreSQL.
Вопросы уровня Junior: синтаксис, типы данных, базовые конструкции
Раздел построен по одному и тому же шаблону: формулировка от интервьюера, краткий ответ с примером кода и одна строка о том, что отделяет средний ответ от сильного. SQL-примеры даны на стандартном синтаксисе без специфических расширений. Вспомнить базовые SQL-запросы и потренироваться может помочь одна из моих предыдущих статей о SQL, которая как раз посвящена базовым конструкциям.
1. Чем PostgreSQL отличается от MySQL?
При выборе базы данных важно понимать компромисс: PostgreSQL ориентирован на соответствие стандарту SQL и расширяемость, MySQL — на простоту и быструю выборку в типовых сценариях. PostgreSQL изначально умел MVCC без блокировок, оконные функции и CTE; MySQL развивал эти возможности постепенно. Кроме того, PostgreSQL гораздо строже относится к типам и не выполняет неявных приведений в местах, где MySQL делает это «тихо».
Чего ждёт интервьюер: не зачитанного списка отличий, а понимания, что эти СУБД шли на компромиссы, выбирая между строгостью семантики и скоростью простых операций.
2. Что такое DDL, DML, DCL? Примеры команд
Это группы команд SQL, разделённые по назначению. DDL (Data Definition Language) описывает структуру: CREATE, ALTER, DROP, TRUNCATE. DML (Data Manipulation Language) работает с содержимым: SELECT, INSERT, UPDATE, DELETE. DCL (Data Control Language) управляет доступом: GRANT, REVOKE. Иногда отдельно выделяют TCL для управления транзакциями: BEGIN, COMMIT, ROLLBACK.
Чего ждёт интервьюер: что вы относите TRUNCATE именно к DDL, а не к DML — это маркер понимания, что команда работает на уровне таблиц, а не построчно.
Полезный блок со скидкой
PostgreSQL редко учится по одной статье: нужно писать запросы, разбирать ошибки, смотреть планы выполнения и понимать, почему база ведёт себя именно так.
Если хотите готовиться не по разрозненным шпаргалкам, а по программе с практикой и обратной связью, держите промокод Практикума: KOD —он даст скидку на любой платный курс.
3. Чем DELETE отличается от TRUNCATE и DROP?
DELETE убирает строки по условию, журналирует каждое удаление, активирует триггеры и поддаётся откату внутри транзакции. TRUNCATE стирает всё содержимое таблицы целиком, действует на уровне таблиц, не пишет каждую строку в WAL и обнуляет последовательности SERIAL. DROP уничтожает саму таблицу со всей её обвязкой — индексами, ограничениями, зависимостями.
DELETE FROM orders WHERE created_at < '2023-01-01'; -- удаляет строки по условию
TRUNCATE TABLE orders; -- очищает таблицу целиком
DROP TABLE orders; -- удаляет таблицу полностьюЧего ждёт интервьюер: упоминания, что TRUNCATE не сработает на таблице, на которую ссылаются внешние ключи без CASCADE, и что он сбрасывает счётчики последовательностей.
4. Что такое первичный ключ и внешний ключ? Зачем нужны?
В реляционной базе данных первичный ключ (PRIMARY KEY) уникально определяет каждую строку — его значения не повторяются и не могут быть NULL. Внешний ключ (FOREIGN KEY) — это поле, ссылающееся на первичный ключ другой таблицы; он гарантирует ссылочную целостность, не давая вставить,например, заказ с несуществующим user_id. Под первичный ключ PostgreSQL автоматически заводит индекс, а под внешний — нет, и это нужно делать руками.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL
);
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
user_id INT REFERENCES users(id) ON DELETE CASCADE,
amount NUMERIC(10, 2)
);Чего ждёт интервьюер: что вы помните про автоматический индекс на PK и его отсутствие на FK — это одна из самых распространённых причин медленных JOIN-ов в реальных проектах.
5. Чем CHAR отличается от VARCHAR?
CHAR(n) — строка фиксированной длины: значение «abc», записанное в CHAR(10), дополнится семью пробелами справа. VARCHAR(n) — переменной длины с верхним пределом. В PostgreSQL оба типа физически хранятся одинаково, поэтому на практике используют либо TEXT, либо VARCHAR без указания длины, не получая заметной разницы в производительности.
Чего ждёт интервьюер: описания разницы и фразы вроде «в PostgreSQL разница между этими типами — не та же, что в MySQL». Это показывает понимание нюансов Postgre и внимательность к деталям.
6. Что такое NULL? Почему WHERE col = NULL не работает?
NULL обозначает не значение, а его отсутствие. Любое сравнение с NULL через = или <> возвращает не TRUE/FALSE, а снова NULL, поэтому такие строки не попадают в результат фильтра. Чтобы выбрать строки с пустым полем, нужны операторы IS NULL или IS NOT NULL.
SELECT * FROM users WHERE deleted_at IS NULL; -- правильно
SELECT * FROM users WHERE deleted_at = NULL; -- неправильно, всегда вернёт 0 строкЧего ждёт интервьюер: понимания, что NULL искажает поведение и агрегатов (COUNT(col) его игнорирует, а COUNT(*) считает), и условий в JOIN.
7. Типы JOIN: INNER, LEFT, RIGHT, FULL, CROSS — разница и когда использовать
INNER JOIN оставляет только строки, для которых нашлось совпадение в обеих таблицах. LEFT JOIN берёт все строки слева и подставляет совпадения справа, заполняя пробелы значениями NULL. RIGHT JOIN действует зеркально. FULL JOIN объединяет оба варианта — и слева, и справа без отсечения. CROSS JOIN даёт декартово произведение: каждая строка с каждой.

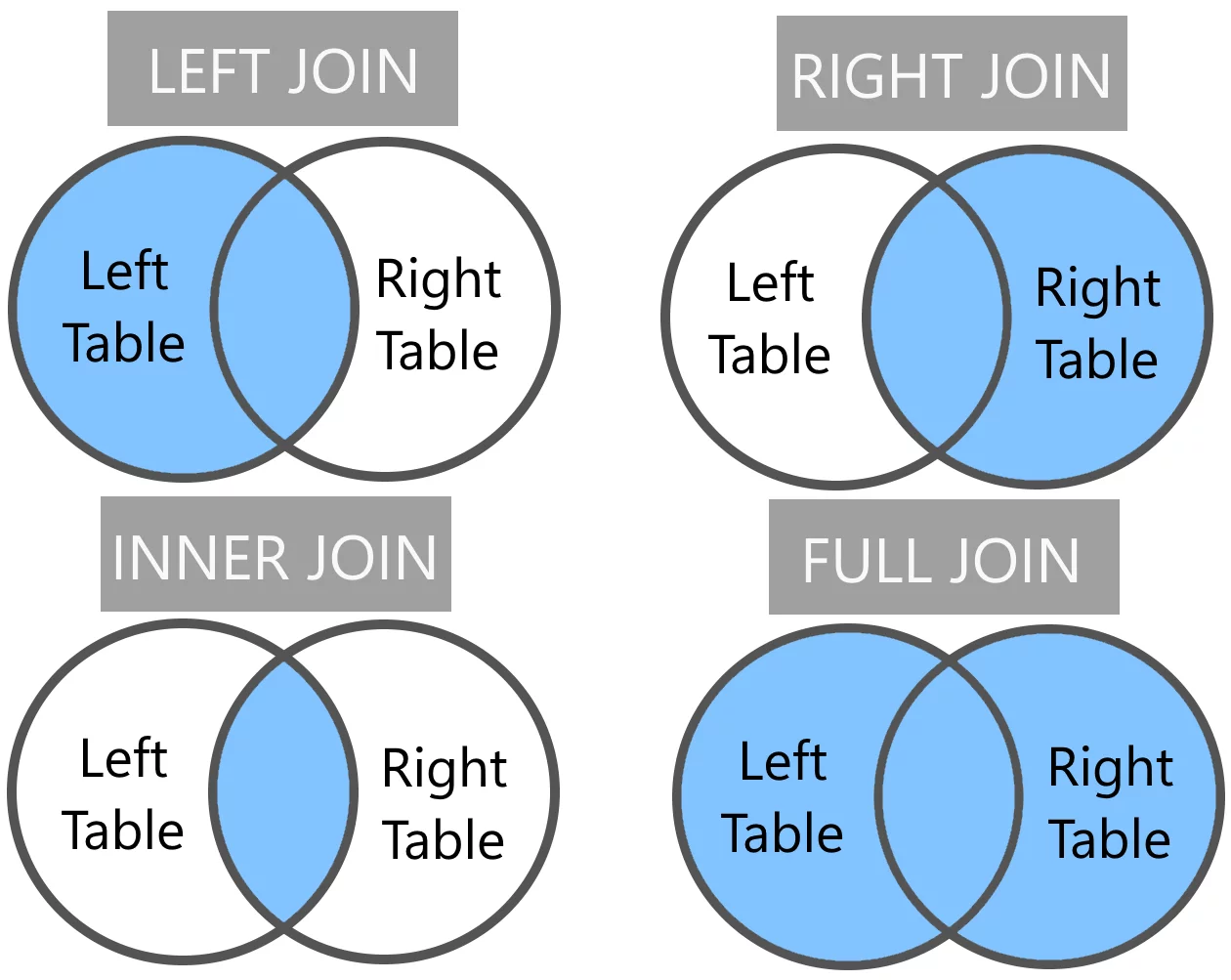
-- Все клиенты и их заказы (включая клиентов без заказов)
SELECT u.name, o.id
FROM users u
LEFT JOIN orders o ON o.user_id = u.id;Чего ждёт интервьюер: что для задачи «найти клиентов без заказов» вы выберете связку LEFT JOIN + IS NULL — это первая практическая задача почти на любом интервью.
8. Чем WHERE отличается от HAVING?
WHERE отфильтровывает строки до этапа группировки и не умеет работать с агрегатами. HAVING накладывает условие уже на готовые группы и применяется в паре с GROUP BY. Если фильтрацию можно перенести на уровень строк через WHERE, это всегда стоит делать — так в группировку попадает меньше данных.

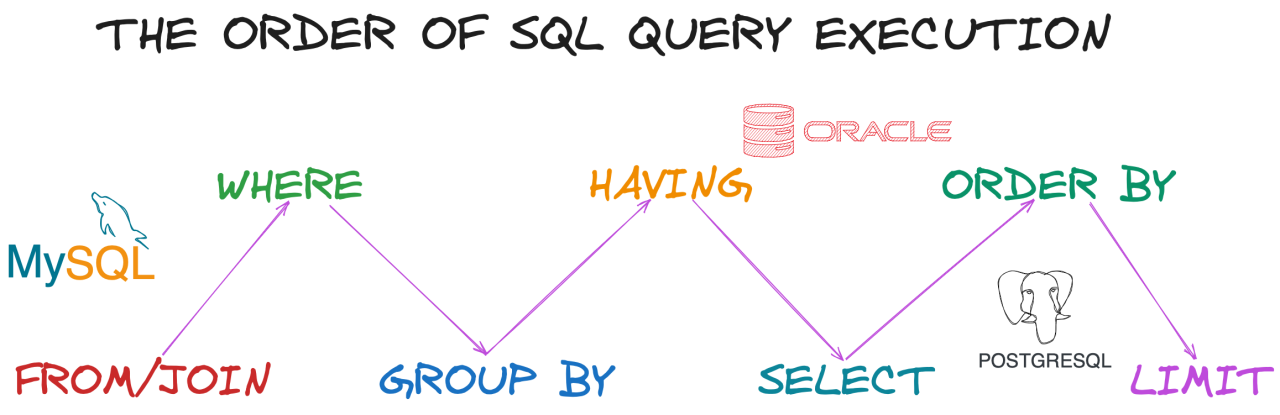
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
WHERE hired_at > '2020-01-01' -- фильтр строк до группировки
GROUP BY department_id
HAVING AVG(salary) > 100000; -- фильтр групп после группировкиЧего ждёт интервьюер: что вы держите в голове порядок выполнения SQL: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY.


9. Что такое подзапрос (subquery)? Когда использовать, когда не использовать?
Подзапрос — это SELECT, вложенный в другой запрос. Он бывает скалярным (возвращает одно значение), строчным (одну строку), табличным (множество строк) и коррелированным (опирается на колонки внешнего запроса). Подзапросы удобны для разовой логики, но коррелированные часто работают медленно — для каждой строки внешнего запроса они выполняются заново. В большинстве случаев их можно переписать через JOIN или CTE с лучшим планом.
-- Скалярный подзапрос
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);Чего ждёт интервьюер: фразы «коррелированный подзапрос обычно сводится к JOIN» — это уже мышление уровня Middle.
10. Что такое индекс? Когда индекс замедляет запрос?
Индекс — это вспомогательная структура (по умолчанию B-tree), которая хранит отсортированные значения колонки и ссылки на строки в таблице. Поиск по индексированному полю становится быстрым. Но INSERT, UPDATE, DELETE начинают работать медленнее, потому что наряду с самой строкой нужно обновить все связанные индексы. На небольших таблицах планировщик может сознательно проигнорировать индекс и пойти через Seq Scan — это нормальное поведение.
Чего ждёт интервьюер: признания, что «индексы — не бесплатный ускоритель», и понимания компромисса между скоростью чтения и скоростью записи.
Вопросы уровня Middle: механизмы, оптимизация, транзакции
С этого момента начинается реальный водораздел между Junior и Middle. До сих пор знание синтаксиса было способно вытянуть собеседование, но дальше нужно понимать, что происходит под капотом PostgreSQL.
1. Что такое ACID? Объясните каждый принцип на примере перевода денег
ACID — это четыре свойства, которым должна соответствовать транзакция. Atomicity (атомарность) гарантирует, что транзакция либо выполняется целиком, либо отменяется полностью: невозможна ситуация, когда деньги списались со счёта А, но не поступили на счёт Б. Consistency (согласованность) удерживает БД в корректном состоянии после транзакции — общая сумма средств на счетах сохраняется. Isolation (изоляция) скрывает промежуточные состояния параллельных транзакций друг от друга. Durability (долговечность) обеспечивает сохранность изменений после COMMIT даже при внезапном отключении питания — за это отвечает WAL.
Чего ждёт интервьюер: объяснения каждой буквы через единый сквозной пример, а не простой расшифровки аббревиатуры. Именно здесь чаще всего и срезаются.
2. Что такое MVCC в PostgreSQL? Как он работает без блокировок?
MVCC (Multi-Version Concurrency Control) — модель, в которой каждая транзакция работает с собственным «снимком» данных, актуальным на момент её начала. При обновлении строки PostgreSQL не перезаписывает её, а вставляет новый кортеж с пометкой, какая транзакция его создала (xmin); старая версия получает признак удаления (xmax), но физически остаётся на диске. Каждая транзакция при чтении сравнивает идентификаторы и решает, какая версия ей видна. Чисткой устаревших версий занимается процесс VACUUM.
Чего ждёт интервьюер: что вы упомянете VACUUM и проблему раздутия таблиц (table bloat) — это говорит о понимании последствий MVCC, а не только его идеи.
3. Уровни изоляции транзакций: Read Committed, Repeatable Read, Serializable
PostgreSQL практически реализует три уровня (Read Uncommitted на деле эквивалентен Read Committed). На Read Committed транзакция видит только закоммиченные данные, но при повторном чтении одной и той же строки значение может измениться. На Repeatable Read транзакция работает со снимком на момент своего старта и при повторных чтениях получает те же значения. Serializable — самый жёсткий: он гарантирует такое поведение, как если бы транзакции выполнялись строго одна за другой.
| Аномалия | Read Committed | Repeatable Read | Serializable |
|---|---|---|---|
| Грязное чтение | Не возникает | Не возникает | Не возникает |
| Неповторяющееся чтение | Возможно | Не возникает | Не возникает |
| Фантомное чтение | Возможно | В PostgreSQL не возникает | Не возникает |
| Аномалии сериализации | Возможны | Возможны | Не возникают |
Чего ждёт интервьюер: что вы упомянете особенность PostgreSQL — на Repeatable Read фантомное чтение уже не появляется, что отклоняется от формулировки в стандарте SQL.


4. Что такое «грязное чтение», «неповторяющееся чтение», «фантомное чтение»?
Грязное чтение — ситуация, когда транзакция А видит изменения транзакции Б до того, как Б их закоммитила. Неповторяющееся чтение — внутри одной транзакции А одна и та же строка прочитана дважды и значения отличаются, потому что в промежутке Б успела внести и закоммитить изменения. Фантомное чтение — повторный SELECT по одному условию возвращает другое количество строк, потому что Б добавила или удалила записи, попадающие под этот фильтр.
Чего ждёт интервьюер: конкретного сценария на каждую аномалию, а не сухого определения из учебника.
5. Как работают индексы B-tree, Hash, GIN, GiST, BRIN — когда какой использовать?
B-tree — индекс по умолчанию, закрывает операторы =, <, >, BETWEEN и LIKE ‘prefix%’. Hash работает только на равенство и в современных версиях редко обходит B-tree. GIN предназначен для составных значений — массивов, JSONB, полнотекстового поиска: внутри это инвертированный индекс, сопоставляющий каждому элементу список содержащих его строк. GiST используется для геометрии, диапазонных типов и того же полнотекстового поиска; универсален, но проигрывает GIN в задачах точного совпадения. BRIN рассчитан на огромные таблицы с естественной упорядоченностью данных (логи, метрики): хранит min/max по диапазонам блоков и отличается крайне маленьким размером.
CREATE INDEX idx_users_email ON users (email); -- B-tree по умолчанию
CREATE INDEX idx_docs_tags ON documents USING GIN (tags); -- GIN для массива
CREATE INDEX idx_logs_ts ON logs USING BRIN (created_at); -- BRIN для временных рядовЧего ждёт интервьюер: что GIN вы выбираете для JSONB, а BRIN — для больших временных рядов; такая привязка типа индекса к задаче выдаёт реальный опыт.
6. Что такое составной индекс? Правило «prefix»
Составной индекс охватывает несколько колонок в фиксированном порядке: CREATE INDEX ON orders (user_id, created_at). Правило префикса формулируется так: индекс задействуется, если фильтр запроса начинается с первой колонки индекса (либо первой и второй, либо всех по порядку — но обязательно с первой). Запрос только по created_at без user_id через такой индекс не пройдёт.
CREATE INDEX idx_orders_user_date ON orders (user_id, created_at);
SELECT * FROM orders WHERE user_id = 5; -- использует индекс
SELECT * FROM orders WHERE user_id = 5 AND created_at > '2024-01-01'; -- использует индекс
SELECT * FROM orders WHERE created_at > '2024-01-01'; -- НЕ использует индексЧего ждёт интервьюер: что порядок колонок в индексе вы определяете по селективности — самая селективная и часто используемая в фильтрах ставится первой.
7. Когда индекс не используется? Четыре причины
Первая — обёртка функцией или явное приведение типа: WHERE LOWER(email) = ? обычный индекс по email не задействует, понадобится функциональный индекс (LOWER(email)). Вторая — поиск по подстроке или суффиксу: LIKE ‘%text%’ через B-tree не пройдёт, нужен GIN с расширением pg_trgm. Третья — слишком низкая селективность: когда условие выбирает существенную долю строк, последовательное чтение оказывается дешевле, чем переход через индекс. Четвёртая — устаревшая статистика: после массовой загрузки или удаления данных нужен ANALYZE, иначе оценки планировщика будут неверными.
Чего ждёт интервьюер: конкретного решения для каждой причины — функциональный индекс, pg_trgm, ручной ANALYZE. Простой перечень причин без рецептов будет выглядеть как заученный материал.
8. Что такое EXPLAIN и EXPLAIN ANALYZE? Как читать вывод?
EXPLAIN выводит план, который планировщик собирается выполнить: какие операции, в каком порядке, с какой расчётной стоимостью. EXPLAIN ANALYZE дополнительно реально выполняет запрос и возвращает фактическое время и количество строк по каждому узлу. Главный диагностический сигнал — расхождение между ожидаемыми (rows) и фактическими (actual rows) значениями: разница в десятки раз почти всегда означает проблему. Подробный разбор плана с аннотациями вынесен в отдельный раздел ниже.
Чего ждёт интервьюер: что вы читаете план снизу вверх и держите в голове иерархию узлов.
9. Что такое CTE (Common Table Expression)? Чем отличается от подзапроса?
CTE — именованный временный результат, объявленный через ключевое слово WITH. Делает запутанные запросы читаемыми и позволяет один раз вычислить промежуточный набор и сослаться на него несколько раз. Поддерживает рекурсивный вариант (WITH RECURSIVE), без которого иерархические структуры на чистом SQL не разворачиваются. До PostgreSQL 12 CTE служили оптимизационным барьером — планировщик всегда материализовал результат. Начиная с 12-й версии простые CTE автоматически инлайнятся, и по поведению они приблизились к подзапросам.
WITH high_paid AS (
SELECT * FROM employees WHERE salary > 100000
)
SELECT department_id, COUNT(*) FROM high_paid GROUP BY department_id;Чего ждёт интервьюер: упоминания изменения в PostgreSQL 12 и понимания, в каких случаях CTE оправданы (читаемость и рекурсия), а в каких ничего не дают.
10. Оконные функции: ROW_NUMBER, RANK, DENSE_RANK, LAG, LEAD
Оконные функции считают значения по «окну» строк, при этом не схлопывают их в одну запись (в отличие от агрегатных). ROW_NUMBER() присваивает каждой строке окна уникальный порядковый номер. RANK() выдаёт ранг с разрывами при равенстве (1, 2, 2, 4). DENSE_RANK() — ранг без разрывов (1, 2, 2, 3). LAG(col, n) достаёт значение колонки из предыдущей строки, LEAD(col, n) — из следующей. Само окно описывается выражением OVER (PARTITION BY … ORDER BY …).
SELECT
department_id,
name,
salary,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rn
FROM employees;Чего ждёт интервьюер: что задачу «топ-N в каждой группе» вы решите связкой ROW_NUMBER + PARTITION BY, а не нагромождением коррелированных подзапросов. Помочь детально разобраться с оконными функциями может помочь моя статья, которая посвящена им отдельно.
11. Что такое VIEW и Materialized View?
VIEW (представление) — сохранённая формулировка запроса, которая каждый раз вычисляется заново при обращении. Удобен для абстракции и разграничения доступа. Materialized View — представление, чей результат материализован на диске и обновляется только командой REFRESH MATERIALIZED VIEW. Применяется для тяжёлых аналитических выборок, которые нет смысла пересчитывать на каждом чтении.
CREATE MATERIALIZED VIEW monthly_revenue AS
SELECT date_trunc('month', created_at) AS month, SUM(amount) AS total
FROM orders GROUP BY 1;
REFRESH MATERIALIZED VIEW monthly_revenue; -- обновить данныеЧего ждёт интервьюер: понимания, что Materialized View — это компромисс между свежестью данных и скоростью ответа, а не «view, но быстрее».
12. Что такое партиционирование? Зачем нужно? Типы: RANGE, LIST, HASH
Партиционирование — это разделение крупной таблицы на физически независимые части по значению определённой колонки. Запрос с фильтром по этой колонке читает только подходящую партицию (механизм partition pruning). RANGE использует диапазоны значений — например, заказы по месяцам. LIST — конкретные перечни значений, скажем, записи по странам. HASH распределяет строки по хешу, обеспечивая равномерность.
CREATE TABLE orders (
id SERIAL,
created_at DATE NOT NULL,
amount NUMERIC
) PARTITION BY RANGE (created_at);
CREATE TABLE orders_2024 PARTITION OF orders
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01');Чего ждёт интервьюер: что партиционирование вы применяете, когда таблица перерастает оперативную память и при этом запросы естественным образом фильтруются по одной колонке.
Разбор EXPLAIN ANALYZE: как читать план запроса на реальном примере
EXPLAIN ANALYZE PostgreSQL — основной инструмент диагностики медленных запросов, но без тренировки его вывод воспринимается как нечитаемый набор скобок и чисел. На нём мы остановимся отдельно. Разберём план на реалистичной задаче — нужно вытащить сотрудников, чья зарплата выше средней по их отделу.
EXPLAIN ANALYZE
SELECT e.name, e.salary, e.department_id
FROM employees e
WHERE e.salary > (
SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id
);
Вывод (упрощённый, как видит его кандидат на собеседовании):
Seq Scan on employees e (cost=0.00..158420.50 rows=3333 width=44)
(actual time=0.521..2847.293 rows=4821 loops=1)
Filter: (salary > (SubPlan 1))
Rows Removed by Filter: 5179
SubPlan 1
-> Aggregate (cost=158.20..158.21 rows=1 width=32)
(actual time=0.281..0.281 rows=1 loops=10000)
-> Seq Scan on employees (cost=0.00..155.00 rows=1280 width=8)
(actual time=0.012..0.234 rows=1000 loops=10000)
Filter: (department_id = e.department_id)
Rows Removed by Filter: 9000
Planning Time: 0.187 ms
Execution Time: 2848.156 msКаждая строка несёт конкретную информацию, и чтение плана сводится к разбору этих смыслов.
| Элемент вывода | Что означает | На что обратить внимание |
|---|---|---|
Seq Scan on employees | Полный последовательный проход по таблице без обращения к индексу | Плохой признак на крупных таблицах; стоит подумать про индекс |
cost=0.00..158420.50 | Расчёт планировщика: стоимость старта и итоговая стоимость в условных единицах | Эти числа имеют смысл только в сравнении планов между собой |
rows=3333 | Сколько строк планировщик рассчитывает получить | Сильное расхождение с actual rows — сигнал устаревшей статистики, нужен ANALYZE |
actual time=0.521..2847.293 | Реальное время до первой и до последней строки в миллисекундах | Большое второе число — здесь и сидит узкое место |
actual rows=4821 | Сколько строк действительно вернул узел | Сопоставлять с расчётным rows |
loops=10000 | Сколько раз был исполнен этот узел | Значение больше единицы означает узел внутри подплана или соединения |
Filter: | Условие, отсеивающее строки на этом узле | Большой процент отсеянных строк — повод для индекса |
Rows Removed by Filter: 9000 | Сколько строк прочитали и отбросили | Чем больше число, тем хуже КПД чтения |
SubPlan 1 | Внутренний подплан, вызываемый для каждой строки внешнего запроса | loops=10000 — это десять тысяч повторных вычислений, прямой кандидат на оконную функцию |
Planning Time / Execution Time | Время планирования и время выполнения | Существенный разрыв означает, что проблема в данных, а не в плане |
Главный вывод по этому плану: подплан срабатывает 10000 раз — по разу на каждую строку внешнего Seq Scan. Это классический симптом коррелированного подзапроса, и его надо переписать. Корректная альтернатива — оконная функция AVG(salary) OVER (PARTITION BY department_id), которая посчитает среднее по отделу за один проход. Кроме того, наличие Seq Scan по department_id вместо Index Scan намекает: если запрос горячий, имеет смысл создать индекс на этой колонке.
Практические задачи: SQL-запросы, которые дают на собеседовании до Middle
Практические задачи на интервью никогда не подбираются случайно. За каждой стоит конкретный навык, и сильный кандидат озвучивает этот навык вслух прежде, чем начинает писать запрос. Здесь шаблон такой же как и с теорией: задача, её решение и что хочет проверить интервьюер.
1. Найти сотрудников с зарплатой выше средней по отделу
SELECT name, salary, department_id
FROM (
SELECT
name,
salary,
department_id,
AVG(salary) OVER (PARTITION BY department_id) AS dept_avg
FROM employees
) sub
WHERE salary > dept_avg;Что проверяет интервьюер: умение применять оконные функции там, где напрашивается коррелированный подзапрос. Решение через WHERE salary > (SELECT AVG …) будет принято на Junior, но на Middle ждут именно оконного варианта.
2. Найти клиентов, у которых нет ни одного заказа
SELECT u.id, u.name
FROM users u
LEFT JOIN orders o ON o.user_id = u.id
WHERE o.id IS NULL;Что проверяет интервьюер: знакомство с шаблоном «LEFT JOIN плюс IS NULL». Альтернативный вариант через NOT EXISTS тоже корректен и нередко быстрее на крупных объёмах. Решение через NOT IN — антипаттерн: при появлении NULL в подзапросе оно ломается.
3. Найти топ-3 категории по выручке за месяц
SELECT month, category, revenue
FROM (
SELECT
date_trunc('month', o.created_at) AS month,
p.category,
SUM(o.amount) AS revenue,
ROW_NUMBER() OVER (
PARTITION BY date_trunc('month', o.created_at)
ORDER BY SUM(o.amount) DESC
) AS rn
FROM orders o
JOIN products p ON p.id = o.product_id
GROUP BY 1, 2
) ranked
WHERE rn <= 3;Что проверяет интервьюер: способность собрать GROUP BY и оконную функцию в одном запросе. Это базовый шаблон «топ-N в каждой группе» — он показывает, что вы не путаете уровни агрегации.
4. Найти дубликаты в таблице
SELECT email, COUNT(*) AS cnt
FROM users
GROUP BY email
HAVING COUNT(*) > 1;Что проверяет интервьюер: базовое владение GROUP BY + HAVING. По сути, разминка перед следующим вопросом — «а теперь удалите эти дубликаты», который встречается в задаче 7.
5. Вывести 5 последних заказов каждого клиента
WITH ranked_orders AS (
SELECT
id,
user_id,
amount,
created_at,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY created_at DESC) AS rn
FROM orders
)
SELECT id, user_id, amount, created_at
FROM ranked_orders
WHERE rn <= 5;Что проверяет интервьюер: совмещение CTE с ROW_NUMBER. Сильный кандидат сразу проговаривает, почему обычный LIMIT тут не работает: он режет общий результат, а нужно ограничивать каждую группу отдельно.
6. Написать рекурсивный CTE для иерархии (сотрудники → менеджеры)
WITH RECURSIVE hierarchy AS (
-- Базовый случай: топ-менеджеры без руководителя
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- Рекурсивный шаг: подчинённые на следующем уровне
SELECT e.id, e.name, e.manager_id, h.level + 1
FROM employees e
JOIN hierarchy h ON e.manager_id = h.id
)
SELECT * FROM hierarchy ORDER BY level, id;Что проверяет интервьюер: знакомство со структурой рекурсивного CTE — якорная часть, UNION ALL, рекурсивный шаг. Без WITH RECURSIVE подобную задачу средствами одного SQL не решить, поэтому она хорошо отделяет тех, кто читал документацию, от тех, кто ограничился туториалом.
7. Удалить дубликаты, оставив только одну запись с минимальным id
DELETE FROM users
WHERE id NOT IN (
SELECT MIN(id)
FROM users
GROUP BY email
);Альтернатива через ctid (физический адрес строки в PostgreSQL) — для случаев, когда подходящего уникального id нет:
DELETE FROM users a
USING users b
WHERE a.email = b.email AND a.ctid > b.ctid;Что проверяет интервьюер: умение строить DELETE через подзапрос или конструкцию USING. В качестве бонуса — знакомство с ctid как PostgreSQL-специфичным механизмом.
Полезный блок
На собеседовании важно не просто помнить определения, а уметь объяснить ход мысли: почему нужен индекс, как читать EXPLAIN ANALYZE, где использовать CTE и чем опасен SELECT *.
Такую базу проще собирать на практике. В Практикуме можно выбрать курс по разработке, аналитике или тестированию, пройти вводную часть и понять, подходит ли направление. Промокод KOD (можно просто нажать) даст скидку на любой платный курс.
Чего не стоит говорить на собеседовании: типичные ошибки
Это не теоретические риски, а формулировки, после которых интервьюер может поставить мысленный минус.
1. «Индексы ускоряют всё»
Почему это плохо: каждый дополнительный индекс делает INSERT, UPDATE и DELETE дороже — обновлять приходится не только саму строку, но и все индексные структуры. На таблицах с тяжёлой записью лишние индексы могут уронить производительность в разы.
Как правильно: «Индексы ускоряют чтение, но замедляют запись и занимают место на диске. Я завожу индекс, когда конкретный запрос показывает себя медленным, и проверяю эффект через EXPLAIN ANALYZE. Каждый ненужный индекс — это технический долг».
2. Путать уровни изоляции
Почему это плохо: формулировка «Read Committed — безопасный уровень по умолчанию» — типовой маркер поверхностного знания. На Read Committed возможны и неповторяющееся чтение, и фантомное.
Как правильно: называйте уровень и тут же — какие аномалии он не закрывает. «По умолчанию в PostgreSQL стоит Read Committed; для типовой веб-нагрузки этого достаточно, но если нужна согласованность отчёта, переключаюсь на Repeatable Read».
3. Отвечать на вопрос об ACID одним словом «ACID»
Почему это плохо: интервьюера интересует не формула, а понимание. Кандидат, который расшифровал аббревиатуру и замолчал, фактически расписался в том, что зубрил по карточкам.
Как правильно: разверните каждую букву через единый сквозной пример — перевод денег, бронирование номера, оформление заказа. Один пример на четыре свойства показывает, что они увязаны в систему, а не существуют по отдельности.
4. Писать SELECT * в практических задачах
Почему это плохо: SELECT * тащит с собой ненужные колонки, увеличивает объём пересылаемых данных и не даёт планировщику использовать index-only scan. На собеседовании это маркер «писал только в pet-проектах».
Как правильно: всегда явно перечисляйте поля, даже если задача синтетическая. Если в условии не указано, какие именно колонки нужны, — переспросите интервьюера.
5. Не знать EXPLAIN
Почему это плохо: Middle, который не умеет читать план запроса, не сможет диагностировать инциденты в продакшене. Это красный флаг — после такого ответа собеседование обычно сворачивают.
Как правильно: даже если не помните детали, обозначьте подход: «EXPLAIN ANALYZE запускаю на медленных запросах; первым делом смотрю расхождение между rows и actual rows, тип скана и loops у вложенных узлов».
Как готовиться: минимальный план за 2 недели
За две недели подготовиться, конечно, сложно, но можно, если составить грамотный план. Ниже пример такого плана с пояснениями.
Неделя 1 — синтаксис и базовые конструкции
- Дни 1–2: типы данных,
CREATE TABLE, ограничения, первичные и внешние ключи - День 3:
SELECT,WHERE,ORDER BY,LIMIT— на живых примерах - Дни 4–5: все типы JOIN с упражнениями на разных формах данных
- День 6:
GROUP BY,HAVING, агрегатные функции - День 7: подзапросы — скалярные, табличные, коррелированные
- Тренажёр: pgexercises.com — закрывает все темы недели
Неделя 2 — механизмы и оптимизация
- День 8: ACID, уровни изоляции, аномалии — теория с примерами
- День 9: MVCC,
VACUUM, проблема bloat - Дни 10–11: индексы (B-tree, GIN, BRIN, составные), правило префикса, функциональные индексы
- День 12:
EXPLAIN ANALYZE— поднять локальный PostgreSQL и проверить план на собственных данных - День 13: CTE (включая рекурсивный) и оконные функции
- День 14: разбор практических задач из этой статьи без подсказок
- Тренажёр: SQL-секция LeetCode — задачи на оконные функции и CTE
К концу второй недели на руках должно быть три вещи: локальный PostgreSQL с тестовыми данными, привычка прогонять EXPLAIN ANALYZE на каждом сложном запросе и решённые без подсматривания задачи из раздела «Практика». С таким набором на собеседование идти уже можно не бояться.
В статье мы разобрали распространённые вопросы, часто встречающиеся практические задачи и некоторые типичные ошибки. При подготовке не забывайте чередовать теорию с практикой и обязательно прогоняйте запросы, это критически важно для понимания и усвоения материала. Не бойтесь экспериментировать с запросами и удачи на собеседованиях!
Советуем дополнительно почитать по теме:
- 17 инструментов разработчика: базовый набор для любого стека — редактор, GitHub, Docker, Postman, Codex и другие инструменты, которые помогают писать, проверять и поддерживать код в 2026 году.
- Как выучить JavaScript с нуля: готовый план для начинающих — план изучения языка, DOM, асинхронности, npm и рабочих инструментов; подойдёт тем, кто параллельно готовится к первым техническим собеседованиям.
- Как стать ML-инженером в 2026: роадмап от Python до первого оффера — путь через Python, SQL, классический ML, Deep Learning и деплой моделей; полезно тем, кто хочет применить SQL и PostgreSQL в данных и ML.
- Что такое DevOps и как он работает — объясняем деплой, CI/CD, контейнеры, серверы и инфраструктуру; логичное продолжение для тех, кто уже разобрался с базами и хочет понимать продакшен.
- Как не бросить программирование: 5 реальных причин и выход — статья про обучение без выгорания: как не зависнуть между SQL, backend, задачами с LeetCode и бесконечной подготовкой к собеседованиям.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.























