Подключить API от любого ИИ-провайдера — дело пяти минут. Но между скриптом, который просто «болтает» в консоли, и надёжным продуктом, который решает реальные задачи, — пропасть. Без правильной архитектуры ваша модель будет галлюцинировать, забывать контекст и выдавать красивые, но бесполезные ответы.
Чтобы ИИ перестал быть игрушкой и стал частью именно вашего продукта, нужен AI-стек. Это не просто набор модных библиотек, а новая философия разработки, где к привычным базам данных и API добавляются векторы, стриминг и RAG. Сегодня разберём, каким должен быть AI-стек в зависимости от задачи.
Что такое AI-стек и зачем он нужен
Ещё пару лет назад стандартом для веб-разработчика был MERN (Mongo, Express, React, Node) или его аналоги. Все жили в парадигме CRUD: создать запись, прочитать, обновить, удалить, — и всё было детерминировано: если ты запросил пользователя с ID=1, база всегда вернёт одного и того же Ивана Ивановича.
С появлением больших языковых моделей всё поменялось. Современный AI-стек — это уже не просто сервер, база данных и фронтенд, а инфраструктура, которая умеет работать с вероятностями, смысловыми расстояниями и гибким контекстом. Теперь разработчику недостаточно «принять JSON → вернуть JSON». Нужно уметь:
- организовать потоковую передачу, чтобы ответ печатался по буквам, а не висел в загрузке 10 секунд;
- настроить векторный поиск, чтобы искать не по ключевым словам, а по смыслу;
- управлять контекстом, потому что память модели ограничена и стоит денег.
И главная беда «голой» нейросети в том, что она живёт в своём изолированном пузыре. GPT-5 знает историю Римской империи, но понятия не имеет, какой остаток товара на вашем складе в Самаре. Если просто подключить API к сайту, модель начнёт либо выдумывать факты, либо отвечать общими фразами.
Здесь AI-стек напрямую пересекается с концепцией RAG (Retrieval-Augmented Generation), про которую мы подробно писали в нашей статье. Кратко напомним идею: RAG учит модель отвечать, опираясь на факты из вашей документации или базы знаний, а не на свои фантазии.
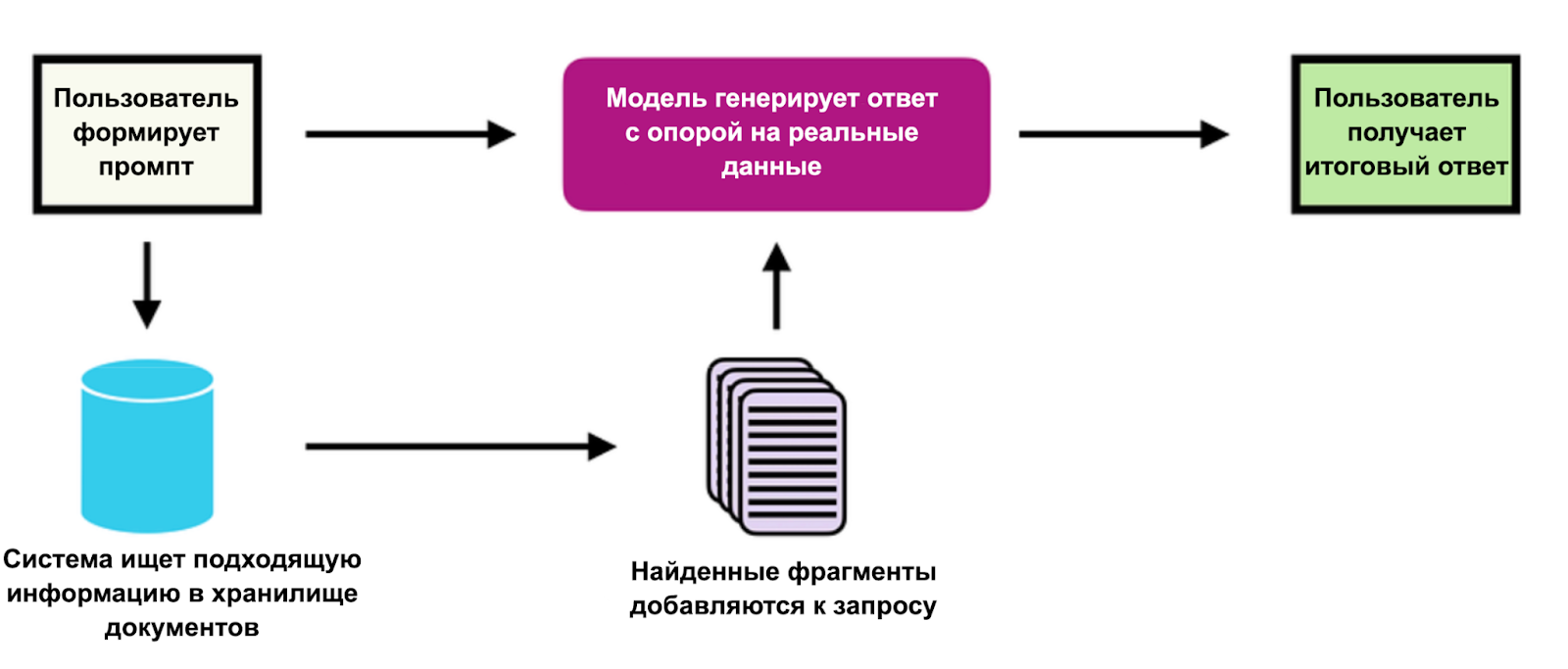
Так вот, AI-стек — это инженерное воплощение RAG.
- RAG — это методика: подсунь модели факты.
- AI-стек — это инструменты, которые позволяют это сделать быстро и надёжно.
По сути, задача современного AI-стека — вытащить сферическую нейросеть из вакуума и встроить её в ваш конкретный проект, с вашими реальными данными и ограничениями. Чтобы модель отвечала не так, как ей «кажется», а в контексте вашего приложения.
Выбор базовых компонентов стека (фронт/бэк/БД)
В обычных веб-проектах технологии часто выбирают по принципу «что знаю, то и использую». Но в AI-приложениях действуют иначе: здесь важнее не привычность инструмента, а то, насколько он справляется с задачами стриминга, длинного контекста и интеграции с ML-библиотеками.
Frontend: Next.js vs React
React сам по себе не плохой выбор — это всё те же компоненты, состояние и JSX. Но при работе с LLM у интерфейса появляется новая обязанность: показывать ответ модели по мере генерации, а не ждать, пока она «придумает» весь текст целиком.
Причина простая: LLM не отвечает одним большим JSON-объектом, а шлёт текст по частям, токен за токеном. Чтобы интерфейс выглядел «как ChatGPT», фронтенд должен этот поток принимать и сразу рисовать — без лагов и перерендеров.
В React начинается много ручной работы, где приходится самому решать, как открыть SSE/WebSocket-соединение, как считывать поток и постепенно добавлять текст, как не блокировать интерфейс, когда приходит длинный ответ и как синхронизировать это с состоянием компонентов.
А вот Next.js упрощает жизнь за счёт встроенной инфраструктуры:
- Серверные компоненты позволяют выполнять часть кода прямо на сервере, рядом с источником данных, в том числе рядом с LLM или RAG-пайплайном. Это означает, что запрос к модели, векторный поиск, сбор контекста и форматирование не прогоняются через браузер. Всё это происходит на сервере, быстро и безопасно, а на клиент уходит только результат.
- Route Handlers (обработчики маршрутов) из коробки умеют стримить данные на клиент без сложностей с Server-Sent Events.
- Vercel AI SDK уже содержит готовые хуки и функции, которые принимают поток токенов и «печатают» текст так же плавно, как ChatGPT.
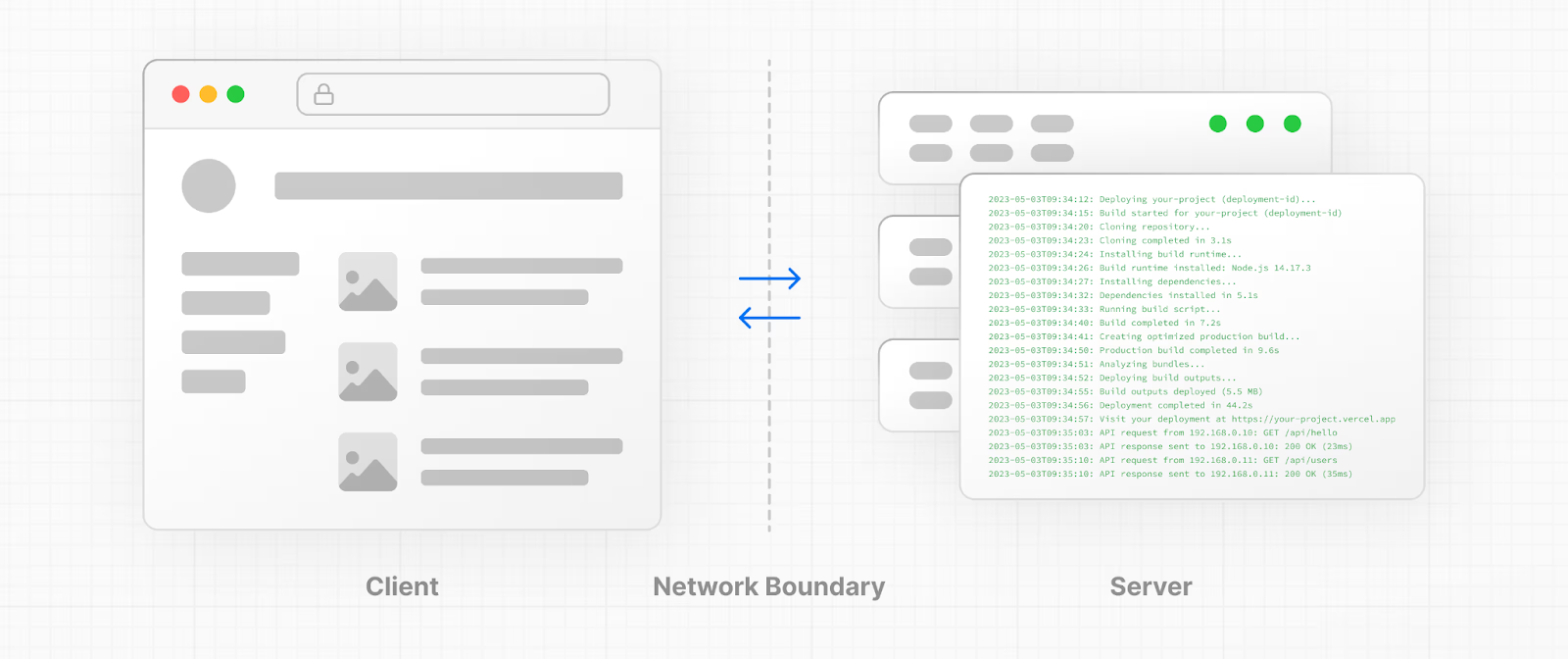
Смысл такой: если вы делаете интерфейс поверх LLM, React требует много ручной обвязки, а Next.js решает типовые задачи заранее. Для джуна это просто способ не провалиться в дебри инфраструктуры на старте.
Backend: Python (FastAPI) — без вариантов
В обычной веб-разработке бэкенд можно собрать на чём угодно: Go, Java, Rust и т. д. Но вот экосистема библиотек для машинного обучения выросла вокруг Python, и других полноценных альтернатив почти нет.
Практически всё, что связано с LLM, RAG и обработкой данных, существует именно там:
- PyTorch и TensorFlow;
- NumPy, Pandas, scikit-learn;
- LangChain, LlamaIndex;
- миллионы готовых решений, пайплайнов, примеров и моделей.
Технически можно писать бэкенд для AI и на Java, и на Go, и на Node.js, но вы моментально упрётесь в то, что ключевых библиотек нет, обёртки устарели, а многие функции нужно собирать вручную. И проект всё равно превратится в гибрид, где «реальная логика» работает в Python, а бэкенд только проксирует запросы.
И поэтому лучше остановится на FastAPI — современном фреймворке для Python, который решает две важные задачи:
- отлично работает с асинхронностью (а запросы к LLM всегда медленные);
- позволяет быстро обернуть любую ML-логику в быстрый API-сервис.
По сути, FastAPI — это мост между вашим AI-кодом и фронтендом. Он достаточно простой, чтобы джун поднял MVP за вечер, и достаточно мощный, чтобы выдержать настоящую продовую нагрузку.

Сама же модель чаще всего берётся из API провайдера:
- OpenAI / Azure OpenAI: стабильные модели, предсказуемые ответы, хороший инструментарий.
- Anthropic — модели с более строгими гарантиями безопасности и поведения.
- HuggingFace — огромный супермаркет моделей: от лёгких mini-LLM до гигантов, заточенных под код, чат, поиск или мультимодальность. Если вам нужна модель для RAG, модель для классификации или модель, обученная на медицинских документах, она, вероятно, она уже там.
А FastAPI обычно становится тем местом, где вся эта история сходится: вы подключаете нужный API, обрабатываете запросы, готовите контекст для RAG, управляете эмбеддингами, а затем отдаёте результат на фронтенд.
Если вы строите систему, где есть генерация текста, эмбеддинги, поиск, разбор документов или RAG, то Python даёт доступ к экосистеме, а FastAPI делает так, чтобы вся эта логика жила на удобном бэкенде.
База данных: PostgreSQL вместо зоопарка решений
Прежде чем выбирать инструмент, разберёмся, что вообще такое векторная база и зачем она нужна в AI-проектах. Когда мы преобразуем текст в эмбеддинг, то получаем длинный список чисел — вектор, который описывает смысл этого текста.
Например, «телефон» и «смартфон» будут лежать близко друг к другу в векторном пространстве. «Телефон» и «банан» будут далеко друг от друга, а запрос «как вернуть товар» будет находиться рядом с инструкциями по возврату.
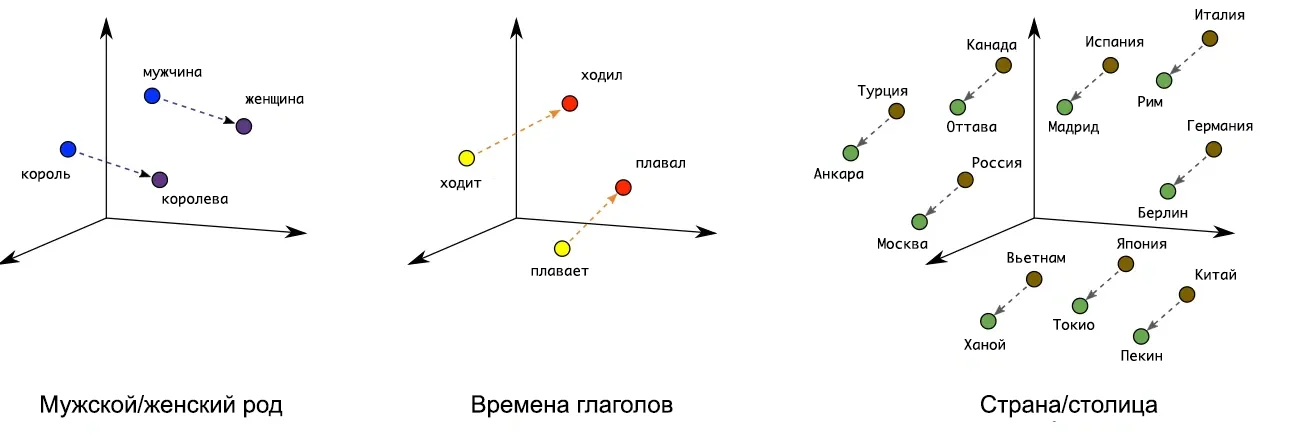
Векторная база данных нужна для двух задач:
- Хранить эмбеддинги документов, сообщений или любых текстов, с которыми работает ваш AI-агент.
- Быстро находить векторы, семантически похожие на запрос пользователя.
Это фундамент RAG: модель отвечает на основе найденных документов, а не из своей цифровой головы.
Теперь перейдём к выбору инструмента. Сегодня популярны специализированные векторные БД — Pinecone, Weaviate, Qdrant. Они действительно быстрые, мощные, масштабируемые, но часто избыточные, особенно если вы делаете первое AI-приложение. Если у вас уже есть PostgreSQL (а он есть почти везде), то проще и дешевле включить расширение pgvector.
pgvector — это опенсорсный модуль, который учит обычный Postgres хранить векторы и сравнивать их между собой. Вектор — это и есть «смысловой отпечаток» текста, который создаёт нейросеть. С помощью pgvector Postgres получает новый тип данных vector и операции для поиска похожести.
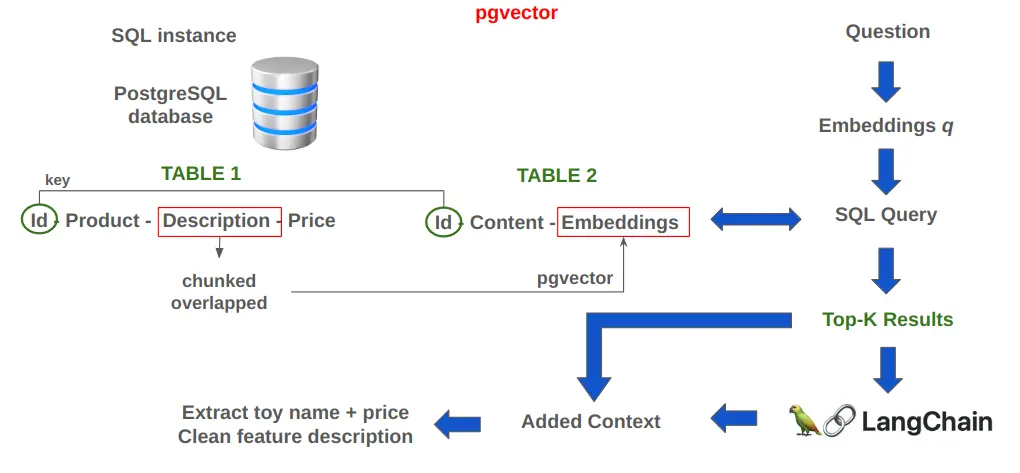
По сути, Postgres превращается в векторную базу: вы можете класть в одно и то же хранилище таблицы пользователей, документы и их эмбеддинги, а затем искать «самые похожие куски текста» стандартными SQL-запросами. Никакой рассинхронизации и выделенных сервисов, работают привычные бэкапы, индексы, мониторинг — всё, что у вас уже настроено.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Интеграция AI-инструментов (оркестрация)
Когда вы впервые отправляете запрос к API OpenAI (или другому ИИ-провайдеру), всё выглядит просто: отправили текст — получили ответ. Но как только запросов становится несколько, выясняется, что модель не хранит никаких состояний и каждый вызов для неё — новая сессия без прошлого.
В интерфейсе ChatGPT кажется, будто модель «помнит» историю, но это иллюзия. Сам сервис под капотом просто пересобирает всю переписку и отправляет её в модель заново. А вот через API такого автомата нет. Если вы хотите, чтобы модель понимала, о чём шёл разговор пять минут назад, какие документы уже искали и какие параметры заданы пользователю, то всё это приходится формировать вручную.
Вы должны собрать историю сообщений, добавить найденный контекст, удалить лишнее, уложиться в лимит токенов и отправить модели одну большую структуру данных. Это и есть основная проблема многослойных AI-приложений: память нужно конструировать самим, иначе модель будет воспринимать каждый запрос как первый.
Другая проблема — многошаговые задачи. Например:
- Найти нужные документы в базе (RAG).
- Разрезать большие файлы на фрагменты.
- Сделать эмбеддинги и выбрать подходящие.
- Сформировать промпт, вставить найденный контекст.
- Отправить модели.
- Привести её ответ к определённому формату (JSON, Markdown, список).
Да, всё это можно написать вручную, но через пару дней бэкенд превращается в кашу из условий, конкатенации строк и операций с токенами.
Именно для этого нужны оркестраторы LangChain или LlamaIndex, которые берут на себя всю грязную работу по управлению контекстом. Чтобы вручную не собирать историю чата и считать токены, вы просто пишете: «Создай цепочку: найди документы → добавь в контекст → спроси ChatGPT».
LangChain отлично подходит, когда нужно выстроить сложную логику поведения агента, например «если пользователь спросил про погоду, сходи в API погоды, а если про курс валют — на биржу».
А LlamaIndex специализируется на работе с вашими данными: он лучше всех умеет «разжёвывать» PDF-файлы, сайты и таблицы, чтобы скормить их нейросети.
Можно делать и без оркестратора — на чистом Python или Node. Но это как писать SPA без React: технически возможно, но очень муторно. Оркестраторы просто автоматизируют рутину, чтобы вы занимались логикой продукта, а не бесконечной сборкой промптов и управлением токенами.
Инструменты для разработки с AI (IDE)
После того как вы определились с ядром AI-стека — фронтендом, бэкендом, базой, векторным поиском и оркестратором, — появляется другая часть работы. Стек сам по себе ничего не делает: его нужно поддерживать, развивать, рефакторить, связывать компоненты между собой. И вот здесь важны рабочие инструменты: среда разработки и AI-ассистенты.
Это отдельный слой экосистемы. Если первый слой отвечает на вопрос «из чего построено приложение», то второй — «как быстро вы сможете это приложение разрабатывать».
Долгое время стандартом был VS Code с установленным плагином GitHub Copilot. Это отличная связка, но у неё есть фундаментальное ограничение: Copilot — это всего лишь плагин. Он видит открытый файл, может немного подглядеть в соседние вкладки, но не понимает всей картины: помогает дописать строку, но не может пересобрать архитектуру.
А вот форк VS Code Cursor с полностью встроенным ИИ-ядром решает такую проблему радикально. Он не «дополняет» редактор, а работает внутри него.
Он понимает контекст всего проекта и индексирует всю вашу кодовую базу. Вы можете спросить его: «Где в проекте используется старый метод авторизации и как его заменить на новый?», и он найдёт все файлы, предложит правки и даже сам их внесёт.
Популярные готовые стеки
За последние пару лет индустрия более-менее устаканила три подхода к тому, как собирать AI-приложения. И выбор зависит от того, кто вы и задачу какого масштаба вы решаете.
Стек «Инди-дев»: Next.js + Vercel AI SDK + Supabase
Это один из самых популярных вариантов для тех, кто хочет запустить проект быстро и в одиночку. Главная фишка здесь монолит на TypeScript. Не нужно переключать контекст между языками: и интерфейс, и логика, и работа с базой пишутся в одном синтаксисе.
В центре всего — Next.js. Как мы уже писали в предыдущем разделе, в связке с Vercel AI SDK он берёт на себя всю сложную работу по стримингу ответов, чтобы текст печатался красиво, как в чате. А Supabase закрывает сразу все вопросы по хранению данных: это и обычная база, и векторный поиск, и авторизация пользователей.
Стек «Энтерпрайз»: FastAPI + LangChain + Pinecone
Это не альтернативная архитектура, а её старший брат. В крупных компаниях требования другие: огромные объёмы документов, десятки интеграций, жёсткие SLA, нагрузка, разделение сервисов по ролям.
Поэтому здесь используют всё то же самое, только в значительно более тяжёлой конфигурации. Вместо pgvector ставят Pinecone, вместо одного сервиса — десяток, вместо одного RAG-пайплайна — цепочки агентов.
Новоиспечённый разработчик это всё поднимать, конечно, не должен, но полезно понимать, во что ваш пет-проект превращается в бою.
Практический кейс: собираем AI-стек с нуля
Представим ситуацию: допустим, вам прилетела задача сделать умного чат-бота для техподдержки. Он должен читать вашу внутреннюю документацию (PDF, Google Docs, Notion) и отвечать на вопросы сотрудников, не выдумывая факты.
Разберёмся пошагово, как собрать нужный стек.
Шаг 1. Бэкенд
Раз нам нужен RAG — то придётся работать с разбиением документов, эмбеддингами, векторным поиском и длинным контекстом. Альтернатив тут особо нет: самые зрелые библиотеки для обработки текста и взаимодействия с LLM (PyTorch, NumPy, LangChain, LlamaIndex) находятся в экосистеме Python.
Поэтому Python + FastAPI — это оптимальная связка. Python даёт доступ к LangChain или LlamaIndex, чтобы легко управлять логикой диалога, а FastAPI позволяет завернуть всё это в быстрый и асинхронный веб-сервер.
Да, теоретически можно собрать RAG на Node.js, но придётся искать чужие порты, городить обёртки и мириться с функциональностью, которая всегда появляется в экосистеме Python первой. А зачем страдать, если можно не страдать?

Шаг 2. Память
Чат-бот должен помнить две вещи:
- Обычные данные: история переписки, пользователи, настройки.
- Векторные данные: смысловые слепки вашей документации.
Самая частая ошибка — пытаться развести это в разные сервисы: MySQL под пользователей, Pinecone под эмбеддинги, потом руками поддерживать синхронизацию. Для малого и среднего проекта это оверхед.
Поэтому рациональный вариант здесь — PostgreSQL + pgvector.
Postgres остаётся вашим основным хранилищем, а pgvector добавляет ему способность выполнять поиск по смысловой близости. Эмбеддинги становятся просто ещё одной колонкой, и всё работает в единой транзакционной системе, без лишних сервисов и отдельной инфраструктуры.
Шаг 3. Фронтентд
Как мы уже писали в разделе про фронтенд-стек, Next.js выигрывает за счёт готовой инфраструктуры для стриминга. Но в рамках практического проекта это важно не из-за красивого появления текста, а потому что фронту приходится жить между двумя мирами — браузером и вашим RAG-бэкендом.
У интерфейса есть три задачи:
- Удерживать соединение со стримом без подвисаний.
- Корректно обновлять состояние, пока приходят токены.
- Не блокировать рендеринг при длинных ответах модели.
В чистом React это превращается в клубок эффектов, кастомных хуков и самописной обработки потока, а в Next.js большая часть этой инфраструктуры уже доступна из коробки.
Поэтому на этапе сборки стека выбираем Next.js, чтобы снизить число ошибок на стороне интерфейса. Он позволяет фронтенду выполнять свою роль — быть тонким клиентом, который не гоняет лишнюю логику и не пытается сам управлять потоками.
В итоге мы собрали архитектуру, которая идеально подходит для старта, но при этом легко масштабируется:
- Фронт: Next.js — нормальный UX и удобная работа со стримингом.
- Бэк: Python + FastAPI — идеальная среда для библиотек RAG.
- БД: PostgreSQL + pgvector — единое хранилище и для данных, и для эмбеддингов.
На таком фундаменте можно построить хоть пет-проект за выходные, хоть серьёзный стартап.
Частые ошибки
Собрать технологии вместе — это ещё полдела. Другая половина работы — это не попасть в ловушки, которые съедают бюджет и время.
1. Переусложнение. Вы делаете минимальный продукт, но сразу тащите туда Kubernetes, микросервисы, три вида очередей и отдельную векторную базу за сто баксов в месяц. Не надо так.
Адекватная стартовая точка — один простой сервер и одна база данных. Масштабируйтесь только тогда, когда действительно упрётесь в ограничения текущего решения.
2. Разработка на хайпе. Сфера ИИ меняется каждый день. Утром вышел новый фреймворк, в обед про него написали все кому не лень, а вечером вы переписываете под него весь проект.
Вы никогда не закончите проект, потому что будете вечно переезжать на «модные молодёжные» инструменты. Выбирайте инструменты, у которых есть документация, комьюнити и устойчивость.
3. Хранение ключей на фронтенде. Это даже не ошибка, а прямая угроза безопасности, за которую банят аккаунты и воруют деньги с карт. Какой бы API вы ни использовали — OpenAI, Azure, Anthropic, HuggingFace или свою локальную модель, — никогда не кладите секретные ключи в клиентский код.
Любой токен, который попадает в браузер, автоматически становится публичным. Его можно прочитать через DevTools, стянуть через прокси или просто подсмотреть в скомпилированном JS. Ключи должны жить только на сервере: в переменных окружения или в защищённом хранилище. Фронтенд делает запрос в ваш бэкенд, а уже бэкенд безопасно общается с AI-провайдером.
4. Garbage In, Garbage Out. Некоторые думают: «Я поставлю крутой векторный поиск, и нейросеть поумнеет».
Нет. Векторная база не превращает плохо отсканированный PDF в структурированную документацию. Качество данных — это основа, и если вы скормите базе данных кривые, неструктурированные PDF-файлы, нейросеть выдаст вам такой же кривой ответ.
80% успеха AI-стека — это не выбор базы данных, а качественная подготовка ваших данных перед тем, как положить их в эту базу. Уберите дубли, очистите текст, нарежьте документы на внятные фрагменты, а уже потом индексируйте.
Ну и напоследок: начинайте с минимального работающего набора — Python, Postgres и простой интерфейс. Посмотрите, как система ведёт себя на ваших реальных данных, и только после этого добавляйте сложность.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.