








Redis (REmote DIctionary Service) — это база данных с открытым исходным кодом, которая помогает очень быстро читать и записывать информацию. В отличие от других баз данных, Redis хранит данные в оперативной памяти, а не на диске. Именно это и делает её очень быстрой.
Redis часто используют для того, чтобы хранить временные данные, которые нужно быстро получать, например кэшированные страницы сайта, результаты поиска или сессии пользователей. Короче, Redis используют для любых операций в реальном времени, где важна скорость.
Сегодня разберёмся, как работает Redis, для чего он нужен, как установить и пользоваться.
Преимущества и недостатки разных СУБД
Для начала вспомним, как вообще устроены базы данных.
База данных (БД) — это хранилище информации, структурированной и не очень. Обычно так называют множество связанных таблиц, хотя на практике данные могут представляться в разном виде. Основная задача БД — упорядочить информацию так, чтобы компьютер мог с ней легко работать, а человек мог пользоваться этими данными как ему удобно.
В зависимости от того, какие данные нужно в ней хранить и как с ними работать, БД делятся на реляционные и нереляционные.
- Реляционные базы данных (SQL) — организуют информацию в виде таблиц, где данные связываются друг с другом с помощью специальных ключей. Такой подход удобен для сложных запросов и анализа данных, поскольку можно легко комбинировать информацию из разных таблиц. Такие базы часто используются в банковских системах или для учёта товаров на складах.
- Нереляционные базы данных (NoSQL) — нужны для хранения данных в более гибком формате, например в виде документов, графов или пар «ключ-значение». Вместо таблиц и жёстких связей такие базы работают с более динамичными структурами данных, что позволяет быстрее обрабатывать информацию в реальном времени.

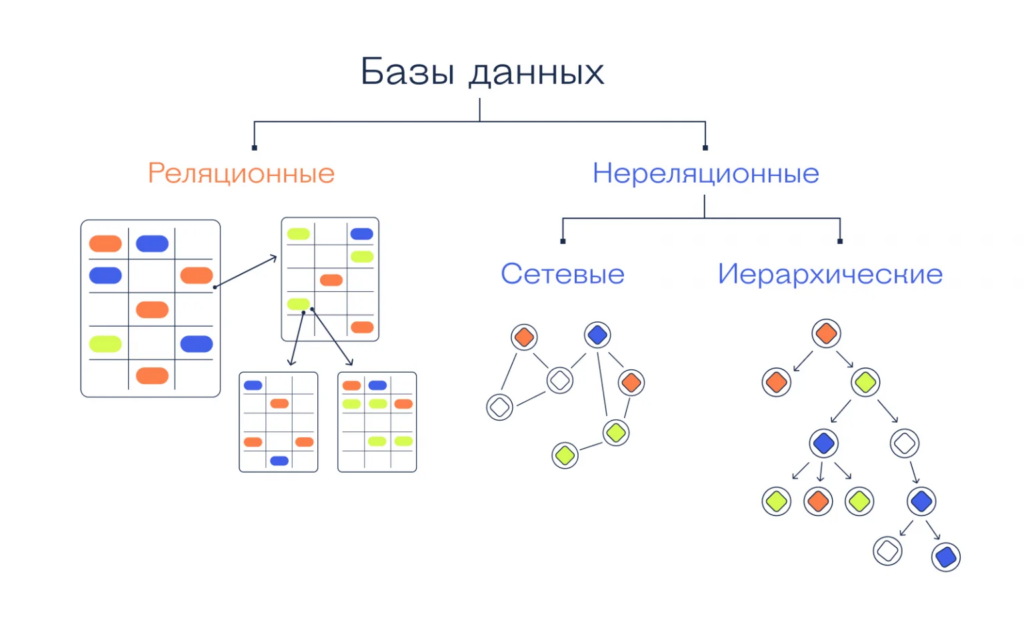
Реляционные базы данных подходят для работы с чётко упорядоченными данными и надёжны при выполнении важных операций. Например, если пользователь делает электронный платёж, то система или завершит перевод полностью, или отменит его, не оставляя всё в подвешенном состоянии. Это защищает от ошибок и потери данных.
Но поскольку данные в таких БД хранятся на жёстких дисках, то каждый запрос занимает время. Когда объём данных растёт, становится сложнее масштабировать такие базы и поддерживать их. Кроме того, реляционные базы плохо работают с неструктурированными данными — с JSON-документами или графами. И для современных приложений, где данные быстро меняются, это уже не так удобно.
Поэтому в современных приложениях часто используют нереляционные БД, к которым и относится Redis.
Redis использует модель «ключ-значение» и хранит данные в оперативной памяти, а не на диске. Redis может напрямую обращаться к данным по уникальному ключу, без сложных запросов, как в реляционных базах данных.







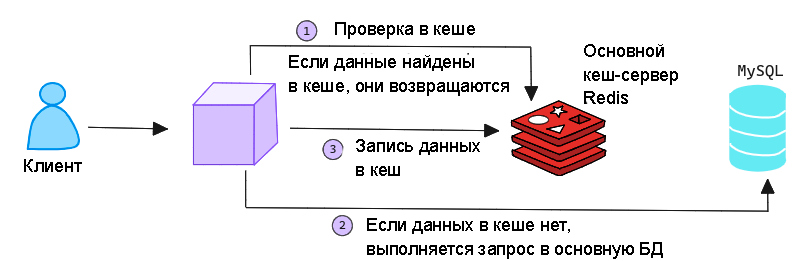
Как работает Redis
Когда клиент делает запрос к приложению, данные сначала ищутся в кэше Redis. Если данные найдены, то сразу возвращаются клиенту, поскольку Redis хранит их в оперативной памяти. Если данных в кэше нет, запрос отправляется в основную базу данных. После получения данных из базы они возвращаются клиенту и одновременно записываются в кэш Redis, чтобы при следующем запросе можно было бы быстро извлечь информацию без обращения к основной базе данных.
Схематично это выглядит так:

Redis поддерживает различные структуры данных (строки, списки, множества), он более гибкий, чем классические базы, и удобен для работы с динамическими данными. Но если данных слишком много, оперативной памяти может не хватить, поэтому Redis лучше подходит для временных данных, которые быстро обновляются.





Для чего используют Redis
Redis используют для решения задач, связанных с быстрой обработкой данных. Всё это достигается за счёт хранения данных в оперативной памяти, использования модели «ключ-значение» и работы с гибкими структурами данных.
Кэширование. Redis помогает организовать кэширование, сохраняя часто запрашиваемые данные в памяти. Это снижает нагрузку на основной сервер и ускоряет доступ к информации. За счёт того, что данные доступны через уникальный ключ, их можно быстро извлечь, не обращаясь к дисковой памяти.
Управление сессиями. В веб-приложениях Redis используется для хранения данных о сессиях пользователей. Сервер быстро получает информацию о том, что пользователь авторизован, и это ускоряет работу с приложением. Данные сессий сохраняются в виде пар «ключ-значение», что делает доступ к ним мгновенным, даже если приложение работает с удалёнными серверами.
Очереди задач. Это полезно для фоновых операций — обработки заказов или отправки уведомлений. Каждая задача помещается в очередь с использованием соответствующего типа данных, что помогает распределить нагрузку на сервер.
Обработка сообщений в реальном времени. Redis поддерживает механизм «подписка/публикация», который позволяет приложениям отправлять и получать сообщения в режиме реального времени. Это особенно важно для чатов, уведомлений или других систем с мгновенной передачей данных.
Работа с временными данными. Для задач, где данные быстро меняются, например при подсчёте лайков или просмотров. Пары «ключ-значение» используются для хранения этих данных, что позволяет мгновенно их обновлять.
Геоданные. Redis поддерживает работу с географическими данными. Это полезно для приложений, которые ищут объекты на основе текущего местоположения пользователя.
Дальше поговорим про типы данных, с которыми работает Redis.
Какие типы данных поддерживает Redis
Redis поддерживает 10 типов данных: строки, списки, множества, упорядоченные множества, хэши, битовые карты, битовые поля, HyperLogLog, потоки и геопространственные индексы.
Строки (Strings) — основная структура данных в Redis, представляющая собой пары «ключ-значение», где значением может быть строка, число или двоичные данные. Строки можно сохранять, обновлять, получать и удалять.Чтобы установить пару «ключ-значение», нужно ввести команду SET и указать данные:
SET username "kristina"
Чтобы получить эти данные, используют команду GET:
GET username
Списки (Lists) — упорядоченные коллекции строк.
Множества (Sets) — уникальные неупорядоченные строки.
Сортированные множества (Sorted Sets) — похожи на множества, но каждому элементу присваивается вес (score), который определяет его порядок. Часто используются для создания рейтингов или таблиц лидеров.
Хэш-таблицы (Hashes) — ассоциативные массивы, состоящие из пар «поле-значение», где поле — это строка, а значение может быть любым типом данных. Удобны для представления объектов — профилей пользователей или данных корзины покупок.
Остальные типы данных используются не так часто, но помогают решать разные специфические задачи. Битовые карты позволяют отслеживать состояния на уровне битов, битовые поля помогают экономно хранить целые числа, HyperLogLog используется для оценки числа уникальных элементов, потоки предназначены для работы с упорядоченными записями, а геопространственные индексы позволяют обрабатывать координаты и выполнять поиск на основе расстояний.
Если упорядочить типы данных по уровню сложности, иерархия будет выглядеть примерно так:


Дальше мы установим Redis, изучим основные команды и поработаем с типами данных.
Как начать работать с Redis
Для начала нужно установить Redis на свой компьютер. Делается это через командную строку, и установка зависит от операционной системы. На Windows посложнее, на Mac и Linux — попроще.
Windows
Официально Redis не поддерживается на Windows, но его можно установить через подсистему Windows для Linux (WSL2). То есть мы сначала ставим на Windows что-то похожее на Линукс, а потом на неё устанавливаем Redis.
Ещё Redis можно установить с помощью Docker, но такой простой путь не для нас, поэтому используем WSL2.
Открываем PowerShell и вводим команду:
wsl --install
По умолчанию эта команда устанавливает дистрибутив Ubuntu. Дальше следуем инструкциям и ждём конца установки:

После завершения установки перезагружаем компьютер. Чтобы проверить, что всё установилось корректно, вводим в PowerShell команду:
wsl --status
Иногда может понадобиться установка дополнительных пакетов.
Теперь нужно открыть приложение Ubuntu, чтобы в нём установить Redis. Вся дальнейшая работа с Redis будет происходить в терминале Ubuntu.
Нажимаем кнопку «Пуск» и вводим «Ubuntu» в строку поиска:


Жмём на иконку, чтобы запустить терминал Ubuntu. Система попросит придумать логин и пароль для создания нового UNIX-аккаунта. После этого терминал будет готов к работе.
Для установки Redis выполняем в терминале команду:
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get update
sudo apt-get install redis
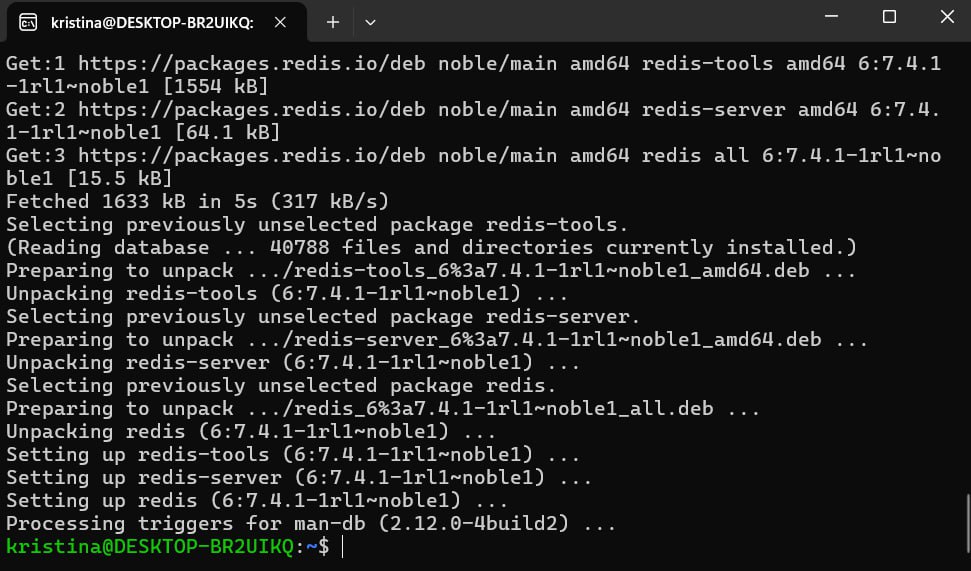
После завершения установки запускаем Redis. Для этого вводим команду:
sudo service redis-server start
Чтобы проверить, что Redis работает, выполняем команду:
redis-cli pingЕсли всё правильно, то Redis ответит PONG:

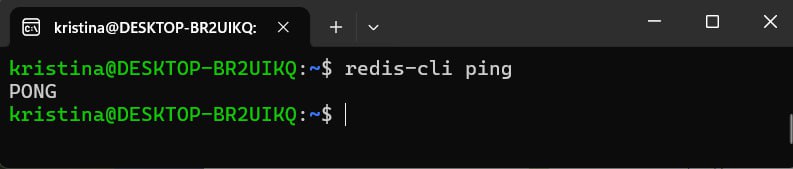
MacOS
На Mac Redis устанавливается через менеджер пакетов Homebrew. Если он ещё не установлен, то открываем терминал и вводим команду:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
После установки Homebrew устанавливаем Redis командой:
brew install redis
Затем запускаем Redis:
brew services start redis

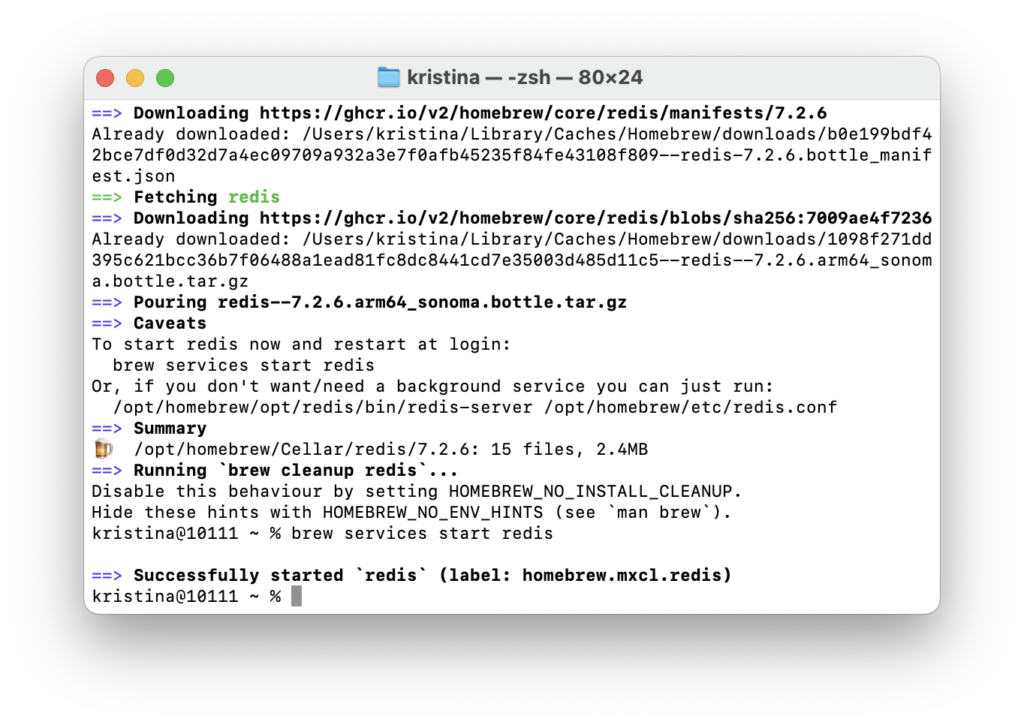
Чтобы проверить, что Redis успешно запущен, выполняем команду:
redis-cli ping
Если всё правильно, то получим ответ PONG:

Как подключать Redis к своему проекту и использовать в качестве БД — расскажем в следующей статье. А сейчас посмотрим, как в Redis работать с данными.
Основные команды
Все команды Redis выполняются в командной строке redis-cli. Когда мы заново заходим в терминал, то сначала нужно запустить командную строку:
redis-cli
После этого можно вводить команды Redis напрямую.
Допустим, мы хотим добавить какие-то данные в БД журнала «Код». Добавляем хэш-таблицу, где будут храниться данные о статье в формате «поле-значение».
Вводим такую команду:
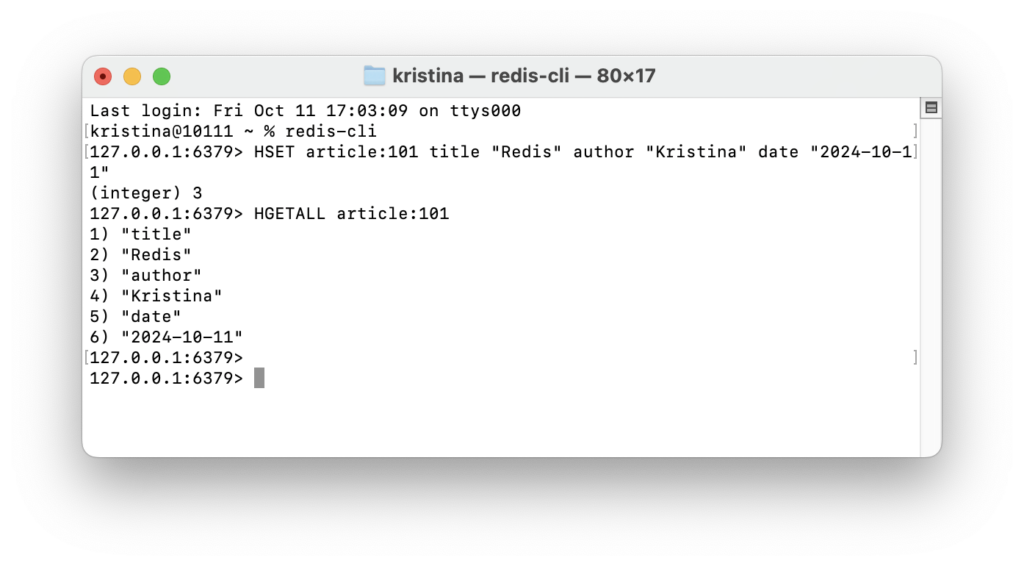
HSET article:101 title "Redis" author "Kristina" date "2024-10-11"
Что это значит:
- Команда
SETзаписывает данные в память, префиксHобозначает тип данных, с которыми мы работаем, — хэш-таблица. article:101— уникальный ключ для статьи, который позволяет легко идентифицировать её в базе данных.title— поле с заголовком статьи.author— поле с автором статьи.date— дата публикации.
Redis создал хэш-таблицу для статьи с идентификатором article:101, и эту информацию можно извлекать по ключу. Чтобы получить все данные о статье, используем команду:
HGETALL article:101

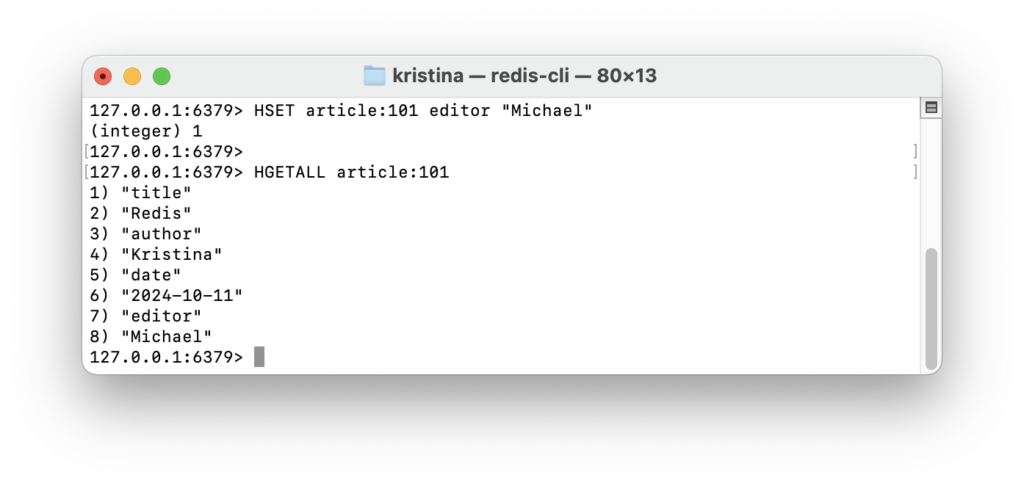
Можно добавлять новые поля и значения:
HSET article:101 editor "Michael"

Чтобы удалить данные, используем команду DEL:
DEL article:101
Все команды в Redis организованы по типам данных и функциональности. В таблице приведены некоторые основные команды.
| Функциональность | Команда | Описание |
| Управление ключами | SET | Устанавливает значение для указанного ключа |
| GET | Получает значение, связанное с указанным ключом | |
| DEl | Удаляет ключ и его значение из базы данных | |
| EXISTS | Проверяет, существует ли указанный ключ | |
| Работа со строками | APPEND | Добавляет значение к строке |
| STRLEN | Возвращает длину строки | |
| Работа со списками | LPUSH | Добавляет один или несколько элементов в начало списка |
| RPUSH | Добавляет один или несколько элементов в конец списка | |
| LRANGE | Получает подмассив элементов из списка по диапазону индексов | |
| LPOP | Удаляет и возвращает первый элемент списка | |
| Работа со множествами | SADD | Добавляет один или несколько элементов в множество |
| SMEMBERS | Возвращает все уникальные элементы из множества | |
| SREM | Удаляет один или несколько элементов из множества |


Конфигурации Redis
Redis — очень гибкий инструмент, который можно настраивать под свои конкретные задачи. Если у вас небольшой проект, то подойдёт простой вариант с одним сервером. Если же требуется обрабатывать много пользователей, то можно настроить репликацию или кластеризацию. Это значит, что в конфигурации будут резервные серверы, которые могут автоматически подключаться, если основной выйдет из строя.
Все основные настройки задаются через файл конфигурации redis.conf. Там можно указать, как инструмент будет работать: от параметров подключения до настройки памяти и безопасности.
Вот пример параметров, которые можно настроить.
- Порт подключения: по умолчанию работает на порте 6379. Можно изменить порт с помощью параметра
port. - Установка пароля: Redis можно защитить паролем, чтобы никто не мог получить доступ без разрешения. Для этого используется параметр
requirepass. - Настройка памяти: Redis хранит данные в оперативной памяти, можно задать лимит памяти через параметр
maxmemory, чтобы Redis не использовал слишком много ресурсов. - Персистентность: хотя Redis хранит данные в памяти, можно настроить сохранение данных на диск, чтобы при перезапуске сервера данные не терялись. Для этого используется опция
appendonly, которая включает запись операций на диск.
Чтобы получить все текущие настройки, вводим команду:
CONFIG GET *

Мы получим длинный список текущих параметров. Например, maxmemory-clients означает ограничение на количество клиентов, которые могут подключаться к Redis, когда установлен лимит памяти. Если установлен 0, то ограничений на количество клиентов нет.
Допустим, мы хотим изменить лимит памяти и включить персистентность данных, чтобы Redis не использовал слишком много оперативной памяти и при этом сохранял данные на диск. Чтобы установить какой-либо параметр, используем команду SET.
Вводим эти команды в командную строку:
CONFIG SET maxmemory 256mb
CONFIG SET appendonly yes
Получаем ответ OK:
Чтобы проверить, применились ли настройки, снова используем команду GET вместе с параметрами:
CONFIG GET maxmemory
CONFIG GET appendonly
И видим, что настройки применились:
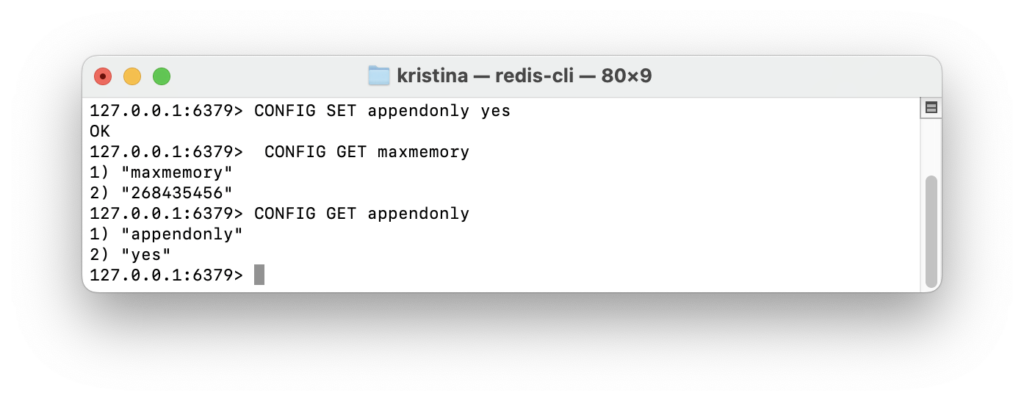
В этом примере мы ограничили использование оперативной памяти до 256 МБ и включили режим персистентности, чтобы не терять данные при перезапуске сервера.
Другая важная функция — Redis Sentinel. Она позволяет настроить механизм отказоустойчивости, чтобы приложение работало более надёжно и стабильно. Redis Sentinel следит за состоянием Redis-серверов и автоматически переключает работу на резервные серверы, если что-то пойдёт не так. Для Sentinel обычно создаётся отдельный файл (sentinel.conf), в котором указываются параметры, связанные с его работой.
Где применяют Redis
Redis — распространённый инструмент в современной разработке.

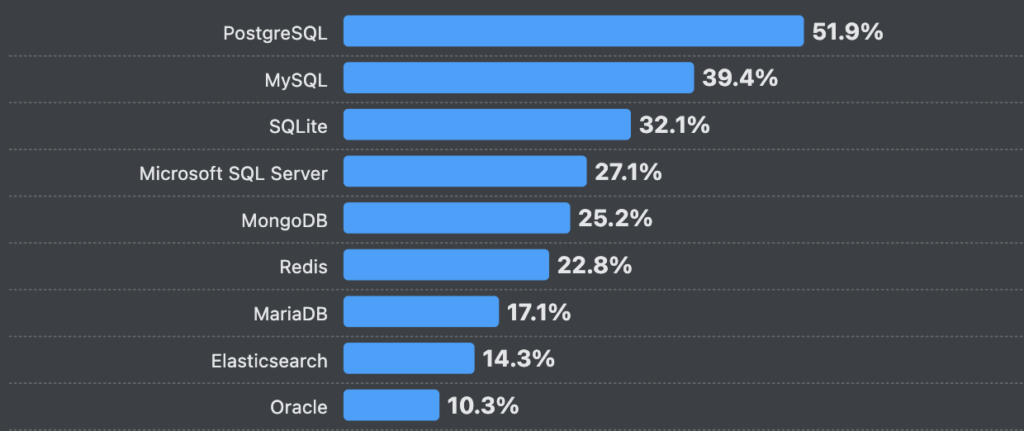
Данные опроса StackOverflow 2024: Redis используют 22,8% профессиональных разработчиков
В веб-приложениях его используют как кэш для ускорения доступа к часто запрашиваемым данным. Это помогает снизить нагрузку на основной сервер базы данных и ускорить отклик системы.
В соцсетях Redis используют для хранения числа лайков, комментариев, просмотров и других метрик. Например, в твиттере Redis используется для кэширования временных данных и работы с очередями задач. Так система может быстро обрабатывать огромное количество запросов от миллионов пользователей.
В интернет-магазинах Redis управляет корзинами покупателей. Когда пользователь добавляет товар в корзину, Redis сохраняет эту информацию в памяти, ассоциируя данные с уникальным ключом — идентификатором покупателя. Это ускоряет процесс обработки заказа.
В игровых приложениях, особенно в многопользовательских играх, где нужно постоянно обмениваться данными между сервером и игроками, Redis работает как брокер сообщений. Когда один игрок совершает действие (передвигается, атакует или отправляет сообщение в чате), это действие должно быть мгновенно передано другим игрокам. Здесь Redis используется для передачи сообщений между разными частями системы или между игроками через механизмы «публикация/подписка».















