








Язык программирования Python — один из самых популярных, потому что удобный и быстрый. В нём много интересных и полезных встроенных инструментов: одни из них применяются почти в каждом проекте, а другие — только при крайней необходимости.
Сегодня расскажем про один из этих инструментов — регулярные выражения в Python. Эта технология может сделать жизнь разработчика проще или, наоборот, усложнить. А результат уже зависит от мастерства программиста и ситуации.
Что такое регулярные выражения и зачем они нужны
«Регулярный» — не совсем точное слово в русском языке для описания работы этой технологии. Регулярные выражения в Python (regular expressions, regex или просто регулярки) — шаблоны для поиска нужных фрагментов текста.
Работает это так: программист составляет шаблон и отдаёт компьютеру. А машина смотрит в него и понимает, что нужно искать.
Вот пример: регулярное выражение "([А-ЯЁа-яё]+)" находит все слова в кавычках. Попробуем вставить это выражение в предварительно подготовленный текст и посмотрим, что найдётся:

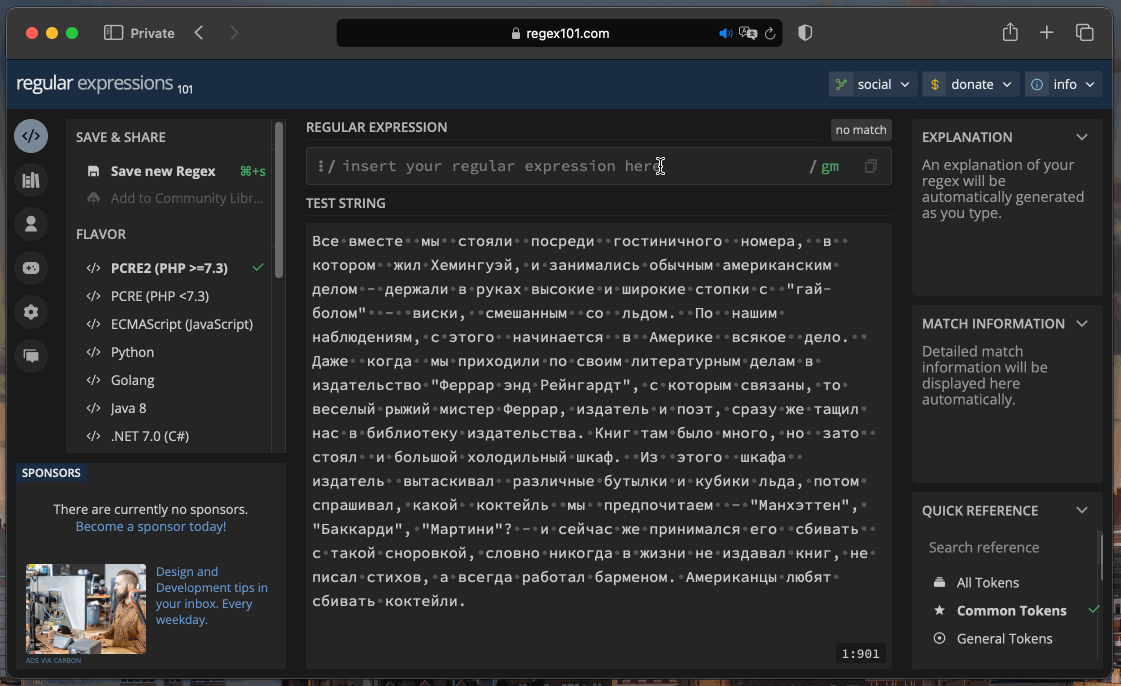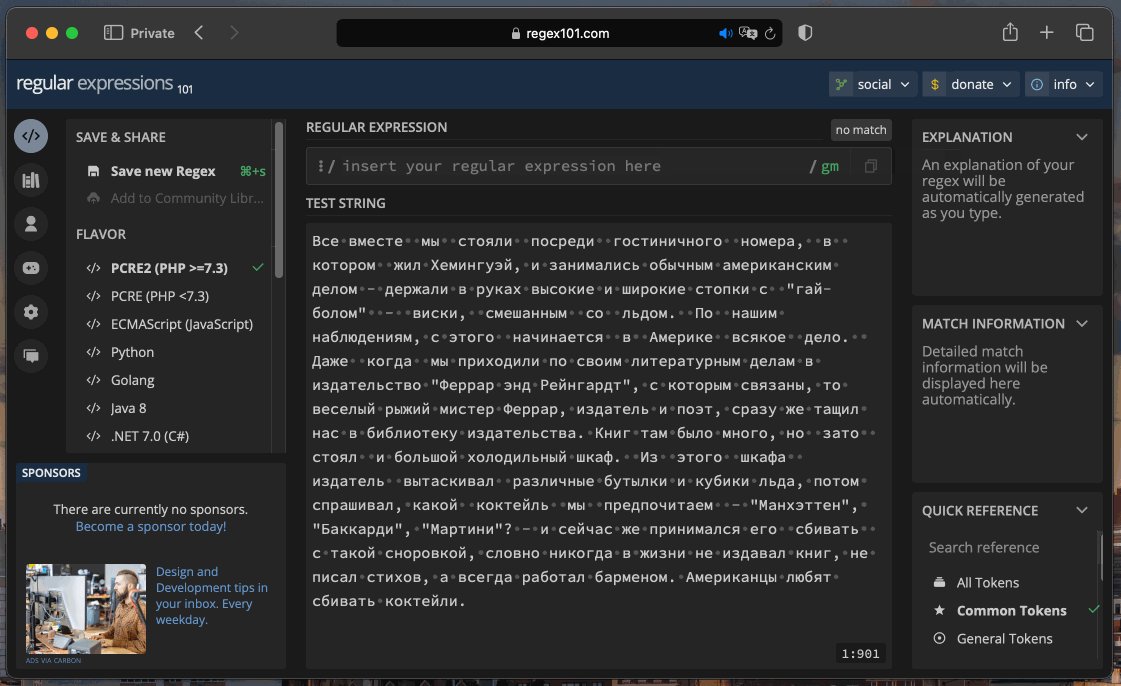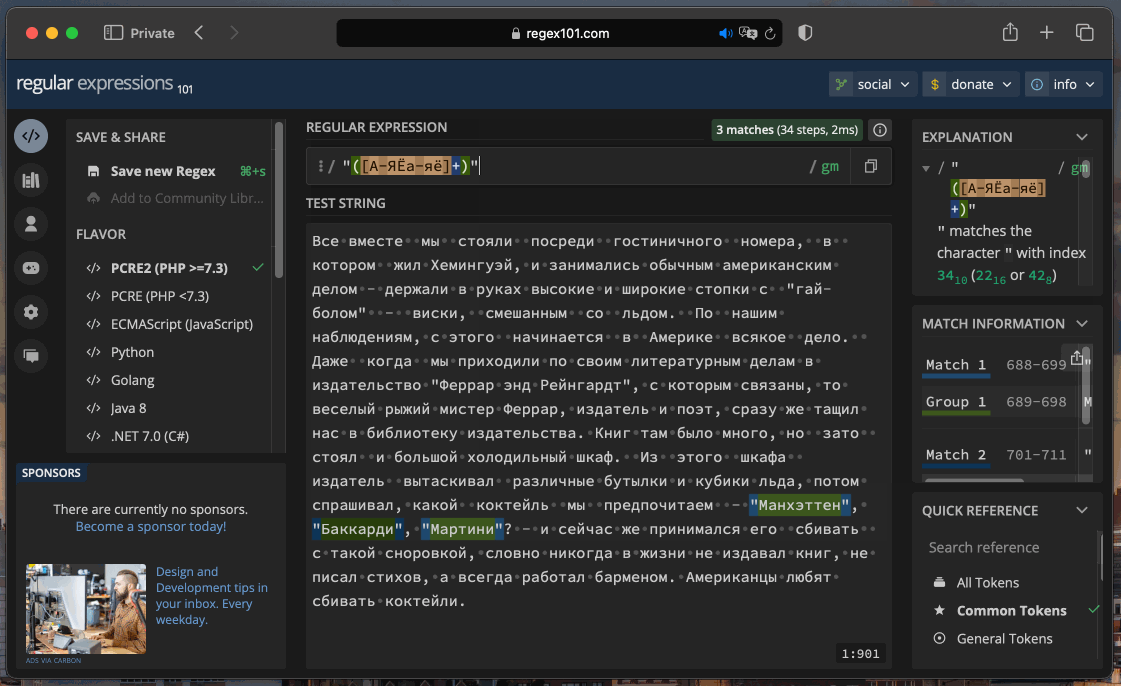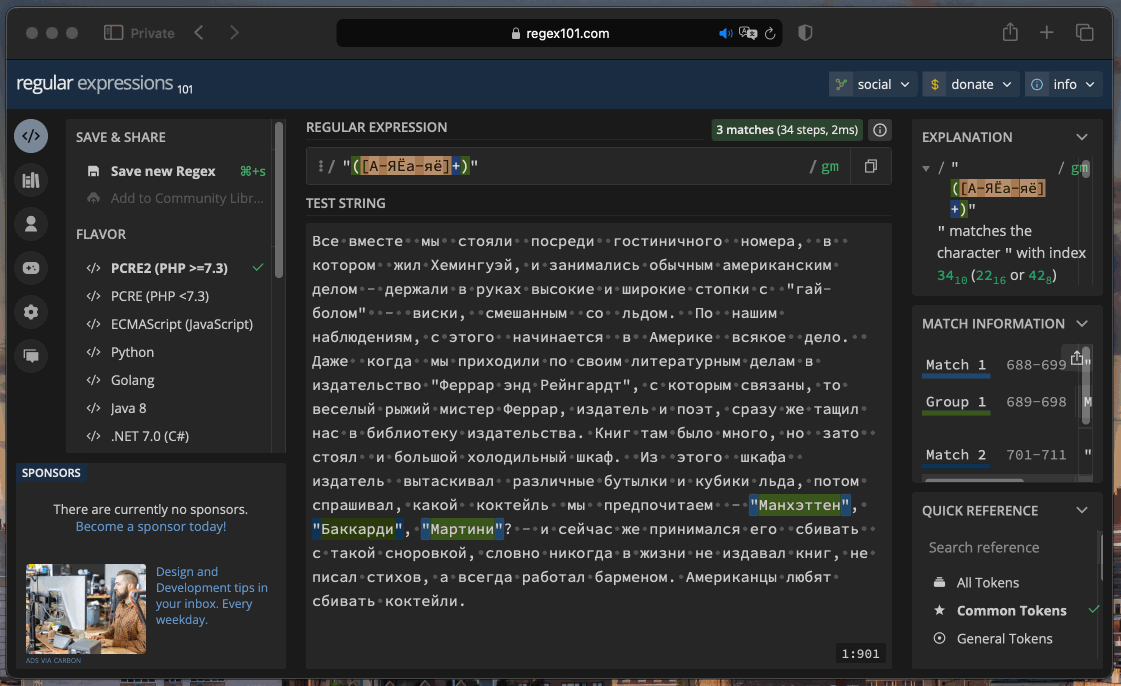
В тексте подсветились все названия из одного слова. Если бы нам понадобилось найти и остальные названия, например с пробелами, регулярное выражение было бы немного другим.
Это мощный инструмент, но разобраться в регулярных выражениях может быть сложно. Даже для такой простой задачи, как названия из одного слова в кавычках, понадобилось учесть много деталей, смотрите сами:
- " находит открывающую кавычку.
- Круглые скобки () обозначают группу символов.
[А-ЯЁа-яё]внутри круглых скобок находит диапазон русских букв. Буквы в большом и малом регистре нужно искать отдельно, букву Ё — тоже.- + означает, что символов может быть больше одного.
- " находит закрывающую кавычку.
👉 В таких выражениях легко запутаться, они трудночитаемы и могут сильно меняться в зависимости от задачи. Поэтому их применяют только когда они действительно могут принести пользу.
Модуль re в Python
Для работы с регулярными выражениями в Python используется библиотека re.
Импортирование модуля. Этот модуль встроенный, для работы его достаточно импортировать в проект. В файле скрипта пишем такую команду:
import re
Основные функции модуля работают так: нужно написать ключевое слово re и добавить нужный метод через точку.
Само регулярное выражение состоит из нескольких частей:
- В начале стоит буква
r. Она нужна, чтобы Python не обрабатывал знаки\. Благодаря этому можно использовать управляющие символы, например\d, иначе слэш в строке не прочитается. - После
rидёт строка — набор символов, из которых состоит регулярное выражение. - После регулярного выражения ставят переменную с текстом или сам текст в кавычках.
- Иногда после текста ставят ещё один параметр для более тонкой настройки — переменную-флаг.
Разберём каждый из методов на примерах.
Re.match() ищет совпадение в начале строки. Если совпадение найдено, возвращает объект типа Match, если не найдено — None. Про Match-объекты объясним ниже.
Так это выглядит в коде:
# импортируем модуль
import re
# создаём строку
string = "Привет, мир!"
# пишем регулярное выражение, ищем совпадение в начале строки
match = re.match(r'Привет', string)
# выводим на экран результат
print(match.group() if match else "Совпадений нет")Запускаем код и видим, что регулярное выражение нашло подходящий фрагмент:
Привет
Как работает:
re.match()проверяет только начало строки.- Если строка начинается с «Привет»,
group()возвращает совпадение. - Если бы слово «Привет» было не в начале,
re.match()ничего бы не нашёл.
Re.search() работает похоже, но ищет первое совпадение в любой части строки. Возвращает объект Match или None.
В примере ниже мы ищем часть строки «мир», при этом она находится в конце текста:
# импортируем модуль
import re
# создаём строку
use = "Привет, мир!"
# пишем регулярное выражение, ищем первое совпадение в строке
match = re.search(r'мир', use)
# выводим на экран результат
print(match.group() if match else "Совпадений нет")Результат в консоли:
мир
Почему так получилось: код работает точно так же, как re.match, только ищет совпадение по всему тексту.
Re.findall() возвращает все совпадения в виде списка.
Например, нам нужно извлечь из текста все числа и сохранить их в список. Понадобится такой код:
# импортируем модуль
import re
# создаём строку
used = "Цена: 120 рублей, скидка 30 рублей"
# пишем регулярное выражение, получаем все совпадения в виде списка
numbers = re.findall(r'\d+', used)
# выводим на экран результат
print(numbers)В консоли после выполнения получаем список:
['120', '30']
Что означает синтаксис:
\d+означает «одна или несколько цифр»: означает \d цифру, + — что может быть больше одного совпадения.findall()ищет все такие совпадения и возвращает список.
Re.split() разделяет строку по заданному шаблону. Такой же встроенный метод-функция есть у строк: нужно задать символ, и когда машина встречает его в тексте, то создаёт разрыв.
Для примера мы разобьём строку сразу по нескольким символам: запятой, точке с запятой и пробелу. Если Python встретит любой из этих символов в тексте, он возьмёт всё, что было до split-символа, и положит в список как новый элемент. А потом продолжит, пока не дойдёт до конца строки.
# импортируем модуль
import re
# создаём строку
text = "яблоко, банан; груша апельсин"
# пишем регулярное выражение, разделяем строку по шаблону
words = re.split(r'[,; ]+', text)
# выводим на экран результат
print(words)Запускаем и получаем список:
['яблоко', 'банан', 'груша', 'апельсин']
Как мы это сделали:
[,; ]+означает «запятая, точка с запятой или пробел». Символов может быть несколько или один.split()разрезает строку по этим разделителям.
Re.sub() заменяет найденные совпадения с регулярным выражением на указанный текст.
Это работает как замена выбранного фрагмента текста в гугл-документах или вордовских файлах:
- Вводим то, что надо заменить.
- Прописываем то, на что нужно заменить.
В коде реализовывается так:
# импортируем модуль
import re
# создаём строку
text = "Цвет: красный, цвет: синий"
# пишем регулярное выражение, заменяем совпадения на другой текст
new_text = re.sub(r'цвет', 'ИМЯ', text, flags=re.IGNORECASE)
# выводим на экран результат
print(new_text)В консоли получаем:
ИМЯ: красный, ИМЯ: синий
Почему это работает:
Re.sub()ищет в строке text все слова «цвет» и заменяет их на «ИМЯ».- Среди аргументов есть дополнительный флаг
re.IGNORECASE. Он делает поиск регистронезависимым (неважно, большие буквы или маленькие), поэтому регулярное выражение находит и «цвет», и «Цвет».
Re.compile() нужен, чтобы сохранить шаблон регулярного выражения для многократного использования.
Для примера возьмём текст, с которым мы уже работали:
text = "Цена: 120 рублей, скидка 30 рублей"
В прошлый раз мы применили регулярное выражение напрямую к этому тексту, когда использовали метод re.findall. В результате получался один список, в который сохранялись все совпадения.
В этот раз мы сначала сохраним ту же самую регулярку в переменную, а потом подключим её через цикл:
# импортируем модуль
import re
# создаём регулярное выражение и компилируем шаблон
pattern = re.compile(r'\d+')
# создаём строку
texts = ["Цена: 120 рублей", "Скидка: 30%"]
# применяем текст к шаблону: находим числа и выводим их на экран
for text in texts:
print(pattern.findall(text))Теперь после запуска каждое вхождение будет являться как отдельный список:
['120']
['30']
Работа с Match-объектами. Если re.match() или re.search() находят совпадение, они возвращают объект Match, который содержит информацию о найденном тексте.
Некоторые методы Match-объектов:
- Group() возвращает найденное совпадение с шаблоном-регуляркой.
- Start() и end() находят, где в строке начинается и заканчивается совпадение.
- Span() тоже возвращает начало и конец совпадения, но помещает их в кортеж.
Пробуем на практике:
# импортируем модуль
import re
# получаем объект Match
match = re.search(r'\d+', 'Цена: 120 рублей')
# получаем совпадение
print('match.group, найденное совпадение:', match.group())
# позиции совпадения
print('match.start, где в строке начинается и заканчивается совпадение: ', match.start(), match.end())
# начало и конец совпадения
print('match.span, диапазон индексов совпадения', match.span())Запускаем код и смотрим на результаты:
match.group, найденное совпадение: 120
match.start, где в строке начинается и заканчивается совпадение: 6 9
match.span, диапазон индексов совпадения (6, 9)


Синтаксис регулярных выражений
Регулярные выражения могут выглядеть сложно, потому что используют много разных элементов в синтаксисе. Вот основные из них.
Метасимволы — специальные символы, которые задают поведение при поиске.
| Метасимвол | Описание и пример | |
| . | Находит любой одиночный символ, кроме символа новой строки \n. a.c → находит abc, a1c, но не ac. | |
| ^ | Ищет совпадение в начале строки. ^Привет → находит "Привет, мир!", но не "Мир, привет!". | |
| $ | Ищет совпадение в конце строки. мир!$ → находит "Привет, мир!", но не "мир! Привет". | |
| \d | Любая цифра [0-9]. \d+ → в "Цена: 500$" находит 500. В этом регулярном выражении есть символ +. Это символ-квантификатор, он означает, что искомый символ должен встречаться один и более раз. | |
| \D | Любой символ, кроме цифр. \D+ → в "123abc456" находит "abc". | |
| \w | Любая буква, цифра или _ ([a-zA-Z0-9_]). \w+ → в "Привет_123!" находит "Привет_123". | |
| \W | Любой символ, кроме \w. \W+ → в "Привет, мир!" находит ", " (запятая и пробел). | |
| \s | Любой пробельный символ (пробел, \t, \n). \s+ → в "Hello world" находит " " (три пробела). | |
| \S | Любой символ, кроме пробела. \S+ → в "Hello patterns" находит "Hello" и "patterns". | |
| \b | Граница слова. \bcat\b → находит cat, но не cats, потому что cat окружён пробелами. | |
| \B | НЕ граница слова. \Bcat\B → находит scatter, но не cat, потому что cat окружён пробелами, а \B ищет только неограниченные символами вхождения. | |
Квантификаторы указывают, сколько раз должен повторяться символ или группа символов.
| Квантификатор | Описание и пример |
| * | Ноль или более раз. ba* → находит b, ba, baa, baaa и так далее. |
| + | Один или более раз. ba+ → находит ba, baa, baaa, но не b. |
| ? | Ноль или один раз. ba? → находит b или ba, но не baa. |
| {n} | Ровно n раз. a{3} → находит aaa, но не aa или aaaa. |
| {n,} | Не менее n раз. a{2,} → находит aa, aaa, aaaa и т. д. |
| {n,m} | От n до m раз. a{2,4} → находит aa, aaa или aaaa, но не a или aaaaa. |
Группировка и скобочные группы работают так: скобки используются для объединения частей выражения в одну группу.
| Символ | Описание и пример |
| () | Группировка символов. (ab)+ → находит ab, abab, ababab и любое другое количество повторяющихся символов ab. |
| (?:...) | Негруппирующие скобки, которые не запоминают совпадения. (?:ab)+ → работает так же, как (ab)+, но без сохранения ab в памяти. |
| (?P<name>...) | Именованная группа. (?P<module>\w+) → позволяет обращаться к совпадению по имени "module". |
Жадные и ленивые квантификаторы. Жадные квантификаторы захватывают максимально возможное количество символов, а ленивые — минимальное.
| Квантификатор | Описание и пример |
| * | Жадный: a.*b → в "axbxb" находит "axbxb". |
| *? | Ленивый: a.*?b → в "axbxb" находит "axb". |
| + | Жадный: a.+b → в "axbxb" находит "axbxb". |
| +? | Ленивый: a.+?b → в "axbxb" находит "axb". |
| {n,m} | Жадный: a{2,4} → в "aaaaa" находит "aaaa". |
| {n,m}? | Ленивый: a{2,4}? → в "aaaaa" находит "aa". |
Ленивым квантификатор делает знак ?.
- Жадные
*, +, {}→ захватывают максимум возможного. - Ленивые
*?, +?, {m,n}?→ захватывают минимум возможного.
Примеры использования регулярных выражений
Вот несколько примеров, как можно применять регулярные выражения для типичных задач.
Поиск и замена
Регулярные выражения умеют находить в тексте заданные шаблоны и заменять их на другие. Это полезно для исправления опечаток и замены слов.
Заменяем слово в тексте:
# импортируем модуль
import re
# объявляем строку
text = "Жизнь не сложна, когда тебе нечего терять."
# заменяем слово "сложна" на "проста"
new_text = re.sub(r'сложна', 'проста', text)
# выводим на экран результат
print(new_text)Проверяем:
Жизнь не проста, когда тебе нечего терять.
Извлечение данных
Можно извлекать из текста даты, числа или слова, соответствующие определённому шаблону.
Например, нужно найти в тексте год:
# импортируем модуль
import re
# объявляем строку
text = "В 1926 году вышел роман 'И восходит солнце'."
# извлекаем год из текста
year = re.search(r'\b\d{4}\b', text)
# выводим на экран результат
if year:
print(year.group())Запускаем код, получаем год:
1926
Проверка формата данных
Строки можно проверять на соответствие определённому формату. Например, это можно использовать для валидации адресов электронной почты или телефонных номеров.
Для примера проверим, начинается ли предложение с заглавной буквы и заканчивается ли точкой. В реальной жизни предложение может начинаться и заканчиваться по-другому, но мы для примера сделаем так.
# импортируем модуль
import re
# объявляем строку
text = "Моя жизнь имеет тенденцию распадаться на части, когда я просыпаюсь, знаете ли."
# проверяем, начинается ли предложение с заглавной буквы и заканчивается ли точкой
if re.match(r'^[А-Я].*\.$', text):
print("Предложение имеет правильный формат.")
else:
print("Предложение имеет неправильный формат.")В консоли выводится результат проверки:
Предложение имеет правильный формат.
Разделение строк
С регулярными выражениями можно разбивать строки на части по заданному разделителю. Например, по запятым:
# импортируем модуль
import re
# объявляем строку
text = ("Париж никогда не кончается, и воспоминания каждого человека, который жил в нём, отличаются от воспоминаний любого другого.")
# делим текст на предложения по запятым
sentences = re.split(r',\s*', text)
# выводим на экран результат
print(sentences)После запуска получаем список из нескольких строк. Запятые не включены:
['Париж никогда не кончается', 'и воспоминания каждого человека', 'который жил в нём', 'отличаются от воспоминаний любого другого.']

Отладка и оптимизация регулярных выражений
Для упрощения работы с regex можно использовать флаги, а ещё регулярные выражения можно отлаживать и оптимизировать.
Флаги в регулярных выражениях позволяют изменять поведение поиска. Они упрощают написание шаблонов и делают их более гибкими. Вот основные флаги, которые часто используются:
re.IGNORECASE(илиre.I) игнорирует регистр символов при поиске.re.MULTILINE(илиre.M) даёт возможность символам^и$работать с началом и концом каждой строки, а не всего текста. Это позволяет найти большее количество вхождений.re.DOTALL(илиre.S) позволяет символу . соответствовать любому символу, включая перенос строки\n.re.VERBOSE(илиre.X) включает комментарии и пробелы регулярных выражений для улучшения читаемости.
Для применения флагов их нужно указать в скобках нужного метода после переменной, в которой хранится текст. Такой код будет искать слово «мир» независимо от регистра:
result = re.findall(r"мир", text, flags=re.IGNORECASE)
В регулярных выражениях может быть довольно сложно отлаживать и искать ошибки. Вот несколько советов, как упростить этот процесс.
- Если выражение получилось слишком сложное, разбейте его на меньшие части и тестируйте каждую отдельно.
- Регулярные выражения можно тестировать в онлайн-сервисах, например regex101.com.
- Проверьте выражение не только на идеальных данных, но и на граничных случаях. Например, пустые строки, строки с лишними пробелами или неожиданными символами.
- Добавляйте вывод промежуточных результатов в консоль.
А вот что можно применить для оптимизации и увеличения скорости работы:
- Жадные квантификаторы могут замедлять работу, особенно на больших текстах. По возможности лучше использовать ленивые.
Lookahead ((?=...))иlookbehind ((?<=...))полезны, но тоже замедляют выполнение программы. Используйте их только при необходимости.
Практические задачи
Для закрепления материала попробуйте решить несколько задач. Сначала идут сами задачи, а после них — ответы с правильным кодом.
Каждая задача направлена на какой-то один способ использования регулярных выражений.
Замена имён
Нужно заменить одно слово на другое. Можно взять любой пример, мы для решения взяли такую цитату:
Он был стариком, который рыбачил один в лодке в Гольфстриме, и вот уже восемьдесят четыре дня он не поймал ни одной рыбы.
В решении мы заменим слово «стариком» на «Сантьяго».
# импортируем модуль
import re
# объявляем строку
text = ("Он был стариком, который рыбачил один "
"в лодке в Гольфстриме, и вот уже восемьдесят "
"четыре дня он не поймал ни одной рыбы.")
# заменяем слово "стариком" на "Сантьяго"
result = re.sub(r"стариком", "Сантьяго", text)
# выводим результат
print(result)Поиск адресов
Задача похожа на поиск слов, но посложнее. Нужно научиться находить адрес в тексте. В нашей задаче мы будем искать ул. Ленина, 123, Москва, Россия 101000.
# импортируем модуль
import re
# объявляем строку
text = ("Гостиница, где мы остановились, располагалась "
"по адресу ул. Ленина, 123, Москва, Россия 101000. "
"Мы провели там несколько дней, наслаждаясь прогулками по городу.")
# создаём регулярное выражение для поиска адреса
pattern = r"ул\.\sЛенина,\s\d+,\sМосква,\sРоссия\s\d{6}"
# ищем совпадение
match = re.search(pattern, text)
# проверяем результат
if match:
print("Найденный адрес:", match.group())
else:
print("Адрес не найден.")Извлечение дат
Дата может быть в разных форматах. Например, попробуйте извлечь дату отсюда:
Осень в Мадриде была прохладной, и 15.10.2023 я сидел у окна в старом кафе на Гран-Виа, наблюдая, как дождь смывает следы летнего зноя с выцветшей мостовой.
# импортируем модуль
import re
# объявляем строку
text = ("Осень в Мадриде была прохладной, и 15.10.2023 "
"я сидел у окна в старом кафе на Гран-Виа, наблюдая, "
"как дождь смывает следы летнего зноя с выцветшей мостовой.")
# ищем дату по шаблону
date = re.search(r"\d{2}\.\d{2}\.\d{4}", text)
# выводим найденную дату
print(date.group())Проверка телефонных номеров
Напишите проверку валидности телефонного номера на соответствие формату +X-XXX-XXX-XXXX.
# импортируем модуль
import re
# объявляем строку с номером телефона
phone_number = "+7-912-345-6789"
# проверяем, соответствует ли номер шаблону
is_valid = re.match(r"^\+\d{1}-\d{3}-\d{3}-\d{4}$", phone_number)
# выводим результат проверки
print("Валиден" if is_valid else "Невалиден")




















