







Если вы хотите работать аналитиком, тестировщиком или разработчиком, SQL — это то, о чём вас обязательно спросят на собеседовании. По данным hh.ru, более 80% вакансий аналитиков данных в России требуют хотя бы базового знания SQL. Хорошая новость: язык устроен логично, читается почти как английская фраза, а базу можно освоить за один вечер.
В этой статье разберём все основные группы команд, уделим особое внимание SELECT во всей его красе, объясним JOIN без страха и разберём типичные ошибки новичков.
К этой таблице прилагается файл SQL, в котором собраны все примеры из таблицы. Копируйте первый запросы и попробуйте создать ими таблицы. Выполняйте остальные запросы из статьи по мере чтения, если хотите. Не стесняйтесь пробовать и экспериментировать! Примеры работают с PostgreSQL 14+.
Что такое SQL
SQL (Structured Query Language) — это язык запросов для работы с реляционными базами данных. С его помощью вы «разговариваете» с базой: просите найти данные, добавить запись, изменить или удалить её.
Реляционная база данных — это набор связанных таблиц. Представьте Excel: каждый лист — таблица, строки — записи, столбцы — поля. SQL позволяет работать с этими таблицами через текстовые команды.
История языка началась в 1974 году в лабораториях IBM — именно там Дональд Чемберлин и Рэймонд Бойс разработали прообраз SQL для системы управления данными. С тех пор язык стандартизирован (ISO/IEC 9075) и поддерживается всеми популярными СУБД: PostgreSQL, MySQL, SQLite, MS SQL Server, Oracle.
SQL применяется везде, где есть структурированные данные: интернет-магазины хранят в нём каталоги и заказы, банки — транзакции, приложения — пользовательские профили. В реальных API данные часто приходят в формате JSON, а затем сохраняются или обрабатываются через SQL-запросы.
С какой СУБД начать? Для обучения лучше всего подходит PostgreSQL: бесплатный, мощный, широко используется в продакшене. SQLite — ещё проще в установке и идеален для экспериментов.
Виды SQL-запросов
SQL-команды делятся на четыре группы в зависимости от того, что они делают:
| Группа | Расшифровка | Назначение | Основные команды |
| DDL | Data Definition Language | Создание и изменение структуры базы | CREATE, ALTER, DROP, TRUNCATE |
| DML | Data Manipulation Language | Работа с данными внутри таблиц | SELECT, INSERT, UPDATE, DELETE |
| DCL | Data Control Language | Управление правами доступа | GRANT, REVOKE |
| TCL | Transaction Control Language | Управление транзакциями | BEGIN, COMMIT, ROLLBACK |
Большинство повседневных задач решается командами DML. DDL нужен при проектировании базы. DCL и TCL — при работе с многопользовательскими системами.
DDL — команды структуры
DDL-команды определяют, как устроена ваша база: какие таблицы существуют, какие в них столбцы и какого типа данные они хранят. Эти команды меняют саму структуру, а не содержимое.
CREATE TABLE
Самая важная DDL-команда — создаёт новую таблицу.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
department VARCHAR(50),
salary DECIMAL(10,2),
hired_at DATE,
is_active BOOLEAN DEFAULT TRUE
);Разберём, что здесь происходит. После CREATE TABLE указывается имя таблицы. Внутри скобок — список столбцов: имя, тип данных и необязательные ограничения.
Основные типы данных SQL, которые встретятся чаще всего:
INT— целое число (возраст, количество, идентификатор)VARCHAR(n)— строка до n символов (имя, адрес, email)TEXT— длинный текст без ограниченийDECIMAL(p,s)— дробное число с точностью (цены, координаты)DATE— дата в формате YYYY-MM-DDBOOLEAN— истина или ложь
PRIMARY KEY означает, что столбец — уникальный идентификатор каждой строки. NOT NULL запрещает пустые значения. DEFAULT задаёт значение по умолчанию.
ALTER TABLE и DROP
ALTER TABLE позволяет изменить уже существующую таблицу без потери данных.
–– Добавить новый столбец
ALTER TABLE employees ADD COLUMN phone VARCHAR(20);
–– Удалить столбец
ALTER TABLE employees DROP COLUMN phone;
–– Переименовать столбец
ALTER TABLE employees RENAME COLUMN name TO full_name;
DROP TABLE удаляет таблицу целиком — вместе со всеми данными, навсегда.
DROP TABLE employees;
DROP TABLE необратима. Прежде чем выполнять её в рабочей базе, убедитесь, что у вас есть резервная копия.
TRUNCATE TABLE оставляет структуру таблицы нетронутой, но удаляет все строки — быстрее, чем DELETE без WHERE:
TRUNCATE TABLE employees;
DML — работа с данными
DML — это сердце SQL. Именно эти команды используются каждый день: выбрать данные, добавить запись, обновить значение, удалить строку.
SELECT— читает данные (самая частая операция)INSERT— добавляет новые строкиUPDATE— изменяет существующие строкиDELETE— удаляет строки
Разберём каждую команду подробно, начав с SELECT — он заслуживает отдельного раздела.
Полезный блок со скидкой
Если хотите не просто писать SQL-запросы, но и понимать, как базы данных устроены изнутри, — держите промокод Практикума на любой платный курс: KOD (можно просто нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
SELECT — главный запрос
SELECT позволяет получить данные из таблицы. Полный синтаксис выглядит так:
SELECT столбцы
FROM таблица
WHERE условие_фильтрации_строк
GROUP BY столбец_группировки
HAVING условие_фильтрации_групп
ORDER BY столбец_сортировки
LIMIT количество_строк;Обязательны только SELECT и FROM. Остальные части добавляются по мере необходимости.
Простейший запрос — получить всё содержимое таблицы:
SELECT * FROM employees;
Звёздочка означает «все столбцы». Лучше перечислить нужные явно:
SELECT name, salary, department FROM employees;
Это быстрее, нагляднее и не сломается, если в таблицу добавят новый столбец.
Можно задать псевдоним через AS:
SELECT name AS employee_name, salary AS monthly_pay
FROM employees;
WHERE и операторы
WHERE фильтрует строки по условию. В результат попадают только те строки, для которых условие истинно.
–– Только сотрудники отдела разработки
SELECT * FROM employees WHERE department = ‘Development’;
–– Зарплата больше 80 000
SELECT name, salary FROM employees WHERE salary > 80000;
–– Зарплата от 50 000 до 100 000
SELECT name, salary FROM employees WHERE salary BETWEEN 50000 AND 100000;
–– Несколько конкретных отделов
SELECT * FROM employees WHERE department IN (‘Development’, ‘Design’, ‘Analytics’);
–– Имя начинается на «Ал»
SELECT * FROM employees WHERE name LIKE ‘Ал%’;
–– Сотрудники без указанного телефона
SELECT * FROM employees WHERE phone IS NULL;
Операторы сравнения: =, != (или <>), >, <, >=, <=.
Условия комбинируются через логические операторы:
–– И то и другое
SELECT * FROM employees WHERE department = ‘Development’ AND salary > 90000;
–– Одно из двух
SELECT * FROM employees WHERE department = ‘Design’ OR department = ‘Analytics’;
–– Не активные сотрудники
SELECT * FROM employees WHERE NOT is_active;
Важное про NULL: сравнение phone = NULL не работает! Для проверки на пустоту всегда используйте IS NULL или IS NOT NULL.
LIKE поддерживает два подстановочных знака: % — любое количество любых символов, _ — ровно один любой символ. Например, LIKE ‘_ван%’ найдёт «Иван», «Дван», «Эвандро».


GROUP BY и агрегатные функции
GROUP BY группирует строки с одинаковым значением в указанном столбце. Вместе с ним используются агрегатные функции, которые вычисляют итог по каждой группе:
| Функция | Что считает |
COUNT(*) | Количество строк в группе |
SUM(столбец) | Сумма значений |
AVG(столбец) | Среднее значение |
MIN(столбец) | Минимальное значение |
MAX(столбец) | Максимальное значение |
–– Сколько сотрудников в каждом отделе
SELECT department, COUNT(*) AS headcount
FROM employees
GROUP BY department;–– Средняя и максимальная зарплата по отделам
SELECT
department,
AVG(salary) AS avg_salary,
MAX(salary) AS max_salary
FROM employees
GROUP BY department;WHERE против HAVING
WHERE фильтрует строки до группировки. HAVING фильтрует группы — то есть работает после GROUP BY и может обращаться к агрегатным функциям.
–– Это не работает
SELECT department, COUNT(*) AS cnt
FROM employees
WHERE COUNT(*) > 5 -- ошибка: агрегатную функцию здесь нельзя использовать
GROUP BY department;–– Работает! HAVING для фильтрации групп
SELECT department, COUNT(*) AS cnt
FROM employees
GROUP BY department
HAVING COUNT(*) > 5; -- отделы, где больше 5 сотрудниковПравило простое: если фильтр не использует агрегатную функцию — пишите WHERE; если использует — пишите HAVING.
ORDER BY и LIMIT
ORDER BY сортирует результат по одному или нескольким столбцам.
–– По зарплате от большей к меньшей
SELECT name, salary FROM employees ORDER BY salary DESC;
–– По отделу по алфавиту, внутри отдела — по зарплате
SELECT name, department, salary
FROM employees
ORDER BY department ASC, salary DESC;ASC — по возрастанию (по умолчанию), DESC — по убыванию.
LIMIT ограничивает количество строк в результате. OFFSET пропускает первые N строк — удобно для пагинации:
–– Топ-10 по зарплате
SELECT name, salary FROM employees ORDER BY salary DESC LIMIT 10;
–– Страница 3 при размере страницы 10 (строки 21–30)
SELECT name, salary FROM employees ORDER BY id LIMIT 10 OFFSET 20;


INSERT, UPDATE, DELETE
INSERT добавляет новые строки в таблицу:
–– Одна строка
INSERT INTO employees (name, department, salary, hired_at)
VALUES ('Алексей Иванов', 'Development', 95000, '2024-03-01');–– Несколько строк сразу
INSERT INTO employees (name, department, salary, hired_at)
VALUES
('Мария Петрова', 'Design', 80000, '2024-03-15'),
('Дмитрий Козлов', 'Analytics', 70000, '2024-04-01');UPDATE изменяет значения в существующих строках:
–– Поднять зарплату конкретному сотруднику
UPDATE employees SET salary = 100000 WHERE id = 42;–– Обновить несколько столбцов сразу
UPDATE employees
SET salary = salary * 1.1, department = 'Senior Development'
WHERE department = 'Development' AND salary > 90000;DELETE удаляет строки:
–– Удалить конкретного сотрудника
DELETE FROM employees WHERE id = 42;–– Удалить всех неактивных
DELETE FROM employees WHERE is_active = FALSE;Всегда проверяйте UPDATE и DELETE перед выполнением, запустив сначала SELECT с тем же WHERE. UPDATE employees SET salary = 0 без WHERE обнулит зарплату всем сотрудникам. DELETE FROM employees без WHERE удалит все данные. Эти ошибки необратимы.
JOIN — объединение таблиц
Реальные базы данных состоят из множества связанных таблиц. JOIN позволяет объединить их в одном запросе. Этот оператор наводит ужас на многих, но на самом деле не так сложен, как кажется. Проще всего воспринять JOIN через диаграммы Венна. Прежде чем перейти к примеру посмотрите на диаграммы и постарайтесь держать их в голове при разборе примеров ниже.

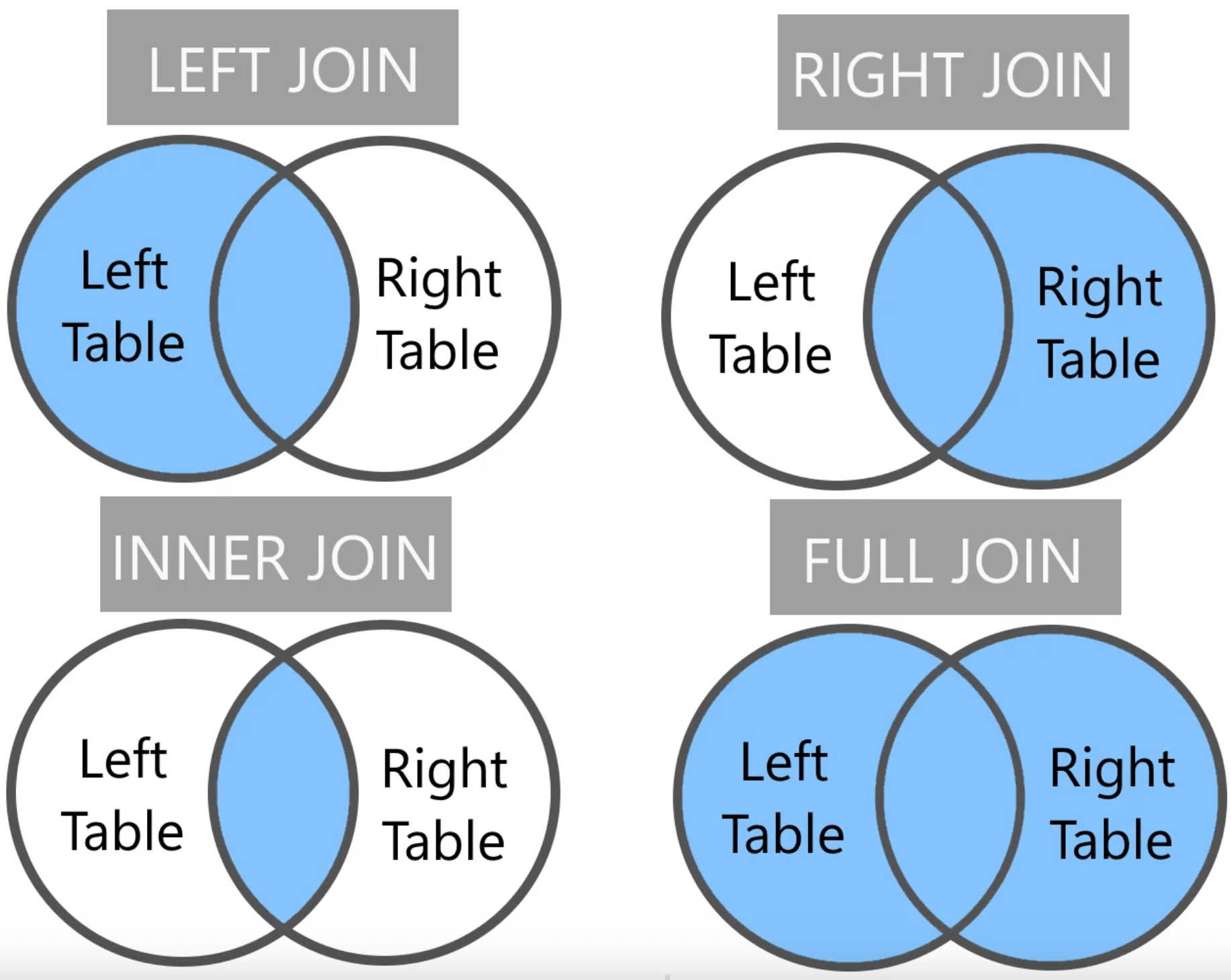
Теперь представим две таблицы: employees (сотрудники) и departments (отделы).
-- employees -- departments
-- id | name | dept_id -- id | name | budget
-- 1 | Иван | 2 -- 1 | Design | 500000
-- 2 | Мария | 1 -- 2 | Development | 900000
-- 3 | Алексей | NULL -- 3 | Analytics | 300000INNER JOIN — только строки, у которых есть соответствие в обеих таблицах:
SELECT e.name, d.name AS department, d.budget
FROM employees e
INNER JOIN departments d ON e.dept_id = d.id;
-- Алексей (dept_id = NULL) в результат не попадётLEFT JOIN — все строки из левой таблицы, плюс совпадения из правой. Если соответствия нет — поля из правой таблицы будут NULL:
SELECT e.name, d.name AS department
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.id;
-- Алексей попадёт в результат, department будет NULLRIGHT JOIN — зеркало LEFT JOIN: все строки из правой таблицы, плюс совпадения из левой. На практике используется реже — обычно проще поменять таблицы местами и написать LEFT JOIN.
FULL JOIN (или FULL OUTER JOIN) — все строки из обеих таблиц. Там, где нет соответствия, будет NULL:
SELECT e.name, d.name AS department
FROM employees e
FULL JOIN departments d ON e.dept_id = d.id;Обратите внимание на псевдонимы таблиц (e и d): они сокращают запись и делают код читаемым. Когда в нескольких таблицах есть столбцы с одинаковым именем (например, id), обязательно указывайте, из какой таблицы берётся столбец: e.id, d.id.
Подзапросы
Подзапрос — это SELECT внутри другого SQL-запроса. Он заключается в скобки и может использоваться в нескольких местах.
Подзапрос в WHERE — отфильтровать строки по результату другого запроса:
–– Сотрудники с зарплатой выше средней
SELECT name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);Подзапрос в FROM — использовать результат запроса как временную таблицу:
SELECT dept_name, avg_sal
FROM (
SELECT department AS dept_name, AVG(salary) AS avg_sal
FROM employees
GROUP BY department
) AS dept_stats
WHERE avg_sal > 70000;Подзапрос в SELECT — добавить вычисляемый столбец:
SELECT name, salary,
(SELECT AVG(salary) FROM employees) AS company_avg
FROM employees;DCL и TCL
DCL — управление правами доступа
В многопользовательских системах важно контролировать, кто что может делать.
–– Дать пользователю право читать таблицу
GRANT SELECT ON employees TO analyst_user;
–– Дать право читать и изменять
GRANT SELECT, UPDATE ON employees TO hr_manager;
–– Отозвать права
REVOKE UPDATE ON employees FROM analyst_user;
TCL — управление транзакциями
Транзакция — это набор операций, которые должны выполниться либо все вместе, либо ни одна. Классический пример: перевод денег со счёта на счёт. Нельзя, чтобы деньги списались с одного счёта, но не зачислились на другой.
BEGIN; -- начать транзакцию
UPDATE accounts SET balance = balance - 5000 WHERE id = 1;
UPDATE accounts SET balance = balance + 5000 WHERE id = 2;
COMMIT; -- зафиксировать оба изменения
-- Или, если что-то пошло не так:
ROLLBACK; -- откатить все изменения транзакцииПорядок выполнения SELECT
Здесь — главный источник путаницы у новичков. SQL-запрос пишется в одном порядке, а выполняется в другом.

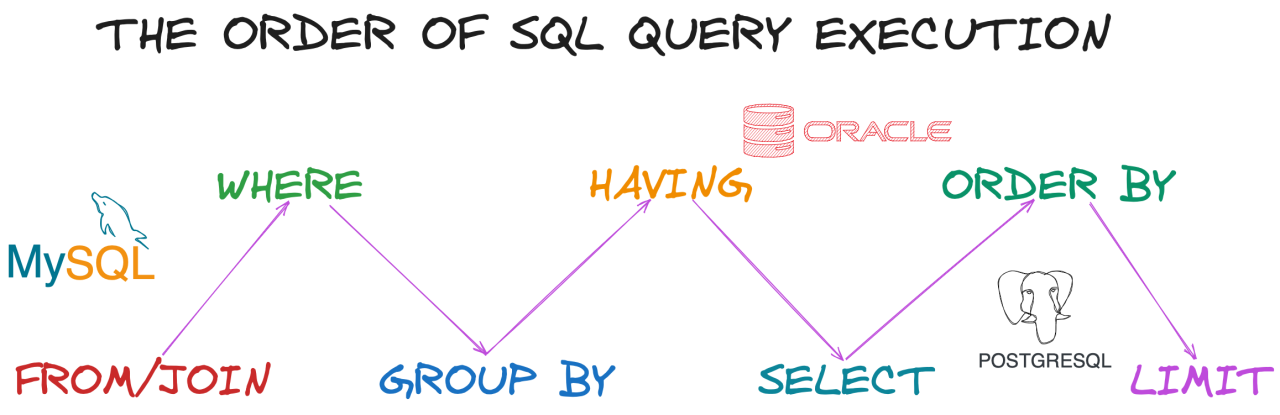
Диаграмма выше показывает логический порядок выполнения. Разберём, почему это важно практически.
Когда вы пишете SELECT name AS employee_name … WHERE name LIKE ‘А%’, псевдоним employee_name не работает в WHERE — потому что WHERE выполняется раньше SELECT, и база ещё не знает о вашем псевдониме.
По той же причине нельзя написать HAVING employee_count > 5, если псевдоним задан в SELECT. Нужно повторить агрегатную функцию: HAVING COUNT(*) > 5.
Порядок выполнения объясняет и разницу WHERE / HAVING: WHERE работает на шаге 2 (над сырыми строками), HAVING — на шаге 4 (над уже сгруппированными данными).
Типичные ошибки
1. SELECT * в production-коде
–– Плохо: тянет все столбцы, в том числе ненужные
SELECT * FROM orders;
–– Хорошо: явно указываем нужное
SELECT id, customer_id, total_amount, created_at FROM orders;
2. UPDATE и DELETE без WHERE
–– КАТАСТРОФА: обнуляет зарплату всем
UPDATE employees SET salary = 0;
–– Правильно: всегда с условием
UPDATE employees SET salary = 0 WHERE id = 99;
3. Сравнение с NULL через =
–– Неправильно: никогда не вернёт строки
SELECT * FROM employees WHERE phone = NULL;
–– Правильно
SELECT * FROM employees WHERE phone IS NULL;
4. HAVING вместо WHERE
–– Медленно: сначала группирует всё, потом фильтрует
SELECT department, COUNT(*)
FROM employees
GROUP BY department
HAVING department = 'Development';–– Быстрее: фильтрует до группировки
SELECT department, COUNT(*)
FROM employees
WHERE department = 'Development'
GROUP BY department;5. Забытые псевдонимы при JOIN
–– Ошибка: база не знает, из какой таблицы брать id
SELECT id, name FROM employees JOIN departments ON dept_id = departments.id;
–– Правильно
SELECT e.id, e.name FROM employees e JOIN departments d ON e.dept_id = d.id;
Вы не спрашивали, но мы ответим
Чем SQL отличается от NoSQL?
SQL — язык для работы с реляционными базами (таблицы, строки, связи). NoSQL — собирательное название для нереляционных баз: документных (MongoDB), ключ-значение (Redis), графовых (Neo4j). SQL гарантирует строгую структуру и транзакционность; NoSQL обычно гибче по структуре и лучше масштабируется горизонтально. Для большинства корпоративных приложений SQL — первый выбор.
Можно ли писать SQL без знания программирования?
Да. SQL — декларативный язык: вы описываете что хотите получить, а не как это сделать. Базовые запросы SELECT, INSERT, UPDATE, DELETE не требуют знания циклов, функций или переменных. Аналитики и менеджеры часто работают с SQL без навыков разработки.
В чём разница между WHERE и HAVING?
WHERE фильтрует отдельные строки — работает до группировки и не может использовать агрегатные функции (COUNT, SUM, AVG и т.д.). HAVING фильтрует группы — работает после GROUP BY и специально предназначен для условий с агрегатными функциями. Если условие не содержит агрегатную функцию — всегда пишите WHERE, это быстрее.
Что такое NULL и почему с ним нужно быть осторожным?
NULL — это не ноль и не пустая строка. Это отсутствие значения. Любое арифметическое действие с NULL даёт NULL: 5 + NULL = NULL. Любое сравнение с NULL даёт UNKNOWN (не TRUE и не FALSE): NULL = NULL — ложь. Для проверки на пустоту всегда используйте IS NULL / IS NOT NULL. Также помните, что COUNT(*) считает все строки, а COUNT(column) — только строки, где столбец не NULL.
Какую СУБД выбрать для изучения SQL?
PostgreSQL — лучший выбор для серьёзного изучения: бесплатный, соответствует стандарту SQL, широко используется в продакшене. Установить можно через официальный сайт или облачный сервис ElephantSQL без установки. MySQL — популярен в веб-разработке, чуть мягче в некоторых правилах стандарта. SQLite — нет сервера, файл базы можно открыть прямо на компьютере, идеален для первых экспериментов.
Заключение
Вы разобрали все основные группы SQL-команд: DDL для создания структуры, DML для работы с данными, DCL для управления правами и TCL для транзакций. Отдельно рассмотрели SELECT со всеми его секциями, четыре типа JOIN и подзапросы.
Следующий шаг — научиться делать запросы быстрее. Для этого изучите индексы: они ускоряют поиск по таблице так же, как оглавление ускоряет поиск в книге. Затем разберитесь с EXPLAIN ANALYZE — командой, которая показывает, как именно база выполняет ваш запрос и где теряется время.
Практикуйтесь на реальных данных: сервисы sqltutorial.org и leetcode.com (раздел Database) дают задачи с готовыми таблицами прямо в браузере — без установки чего-либо. А в современных AI-инструментах SQL тоже никуда не исчез: AI-агент может переводить запрос пользователя в SQL, идти в базу данных и возвращать готовую аналитику. Можете поэкспериментировать и с таблицами, которые мы создали в этой статье у себя на локальной машине! В любом случае, удачи в освоении SQL!
Советуем дополнительно почитать по теме:
- Бэкенд с нуля в 2026: учим Flask, Docker, Redis и ещё 7 технологий — универсальный роадмап, чтобы получить оффер от 120 000 – 180 000 ₽: что конкретно входит в цикл разработки в 2026 году, в каком порядке учить — и где вовремя остановиться.
- Как стать ML-инженером в 2026: роадмап от Python до первого оффера — путь из семи этапов с нуля до первого оффера: Python, SQL, Classic ML, Deep Learning, ML System Design и деплой модели в продакшн.
- Python-стек в 2026: что реально используют разработчики — полный стек Python-разработчика: фреймворки, базы данных, брокеры, линтеры, зависимости и инструменты, которые реально встречаются в работе.
- 17 инструментов разработчика: базовый набор для любого стека — GitHub, Docker, Postman, Codex и другие инструменты, которые помогают писать, проверять и поддерживать код в 2026 году.
- LeetCode: как пользоваться платформой и готовиться к собеседованиям — как зарегистрироваться, выбирать задачи, тренироваться по алгоритмам и решать задания из раздела Database, где как раз пригодятся SQL-запросы.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.























