


Мы уже говорили об общем принципе работы нейросетей для машинного обучения. Разберём другой — бустинг. Кто кого бустит и зачем?
Ноги бустинга растут из вопроса «можно ли с помощью нескольких слабых алгоритмов сделать один сильный?». Оказывается, что да. В этом и есть суть метода: строим серию не особо точных алгоритмов и обучаем их на ошибках друг друга.
Дерево решений
Чтобы понять бустинг, нужно сначала понять дерево решений. Вот это — очень простое дерево:
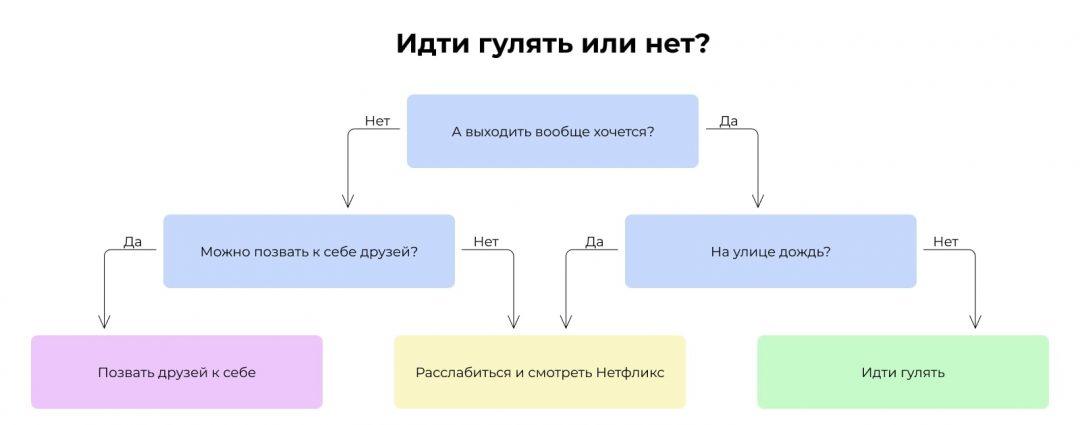
Сейчас это дерево решений, но может быть деревом предсказаний. Представьте, что в заголовке дерева написано «Выйдет ли Юзернейм гулять?» — и вы получите машину предсказаний, которая на основе данных о Юзернейме и погоде будет строить точные предсказания о Юзернейме — при условии, что мы задаём правильные вопросы.
Машина предсказания
Теперь пример сложнее. Допустим, у нас есть данные по миллиону музыкальных клипов на Ютубе. По каждому есть 100 критериев, например:
- Длится ли клип дольше трёх минут.
- Есть ли там прямая бочка.
- Этот трек в жанре «хип-хоп» или нет.
- Выпустил ли клип популярный лейбл.
- Записан ли клип во дворе на мобильный телефон.
- …
Также у нас есть данные о том, набрал ли клип больше миллиона просмотров. Мы хотим научиться предсказывать этот критерий — назовём его популярностью. То есть мы хотим получить некий алгоритм, которому на вход подаёшь 100 критериев клипа в формате да/нет, а на выходе он тебе говорит: «Этому клипу суждено стать популярным».
Первая проблема
Если мы захотим построить дерево предсказаний для этой задачи, мы столкнёмся с проблемой: мы не знаем, какие критерии ставить в начало, а какие в конец, какие запихивать в какие ветки, а какие вообще не нужны и потому не влияют.
Первый шаг решения
Чтобы построить дерево для такой задачи, мы должны будем сначала посчитать, насколько каждый критерий связан с желаемым результатом:
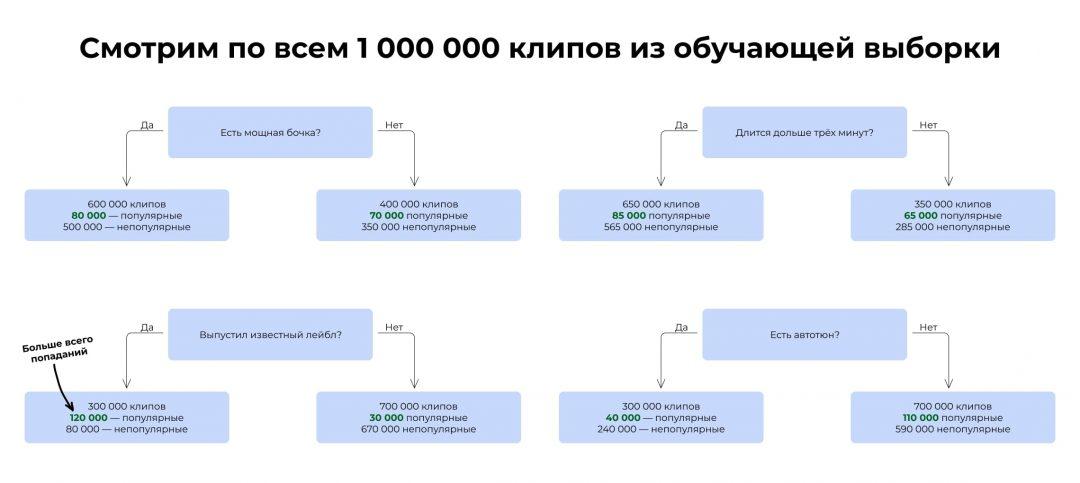
В итоге мы видим, что самая сильная связь с итоговой популярностью у критерия «Выпустил ли клип популярный лейбл». Получается, если клип выпустил лейбл, это влияет на успех сильнее, чем бочка или автотюн. Этот критерий встаёт на вершину дерева.

Затем мы смотрим, какой критерий поставить следующим. Берём те 300 000 клипов, которые выпустили лейблы, и прогоняем их по остальным критериям. Ищем тот, который даёт самую высокую итоговую точность предсказания.
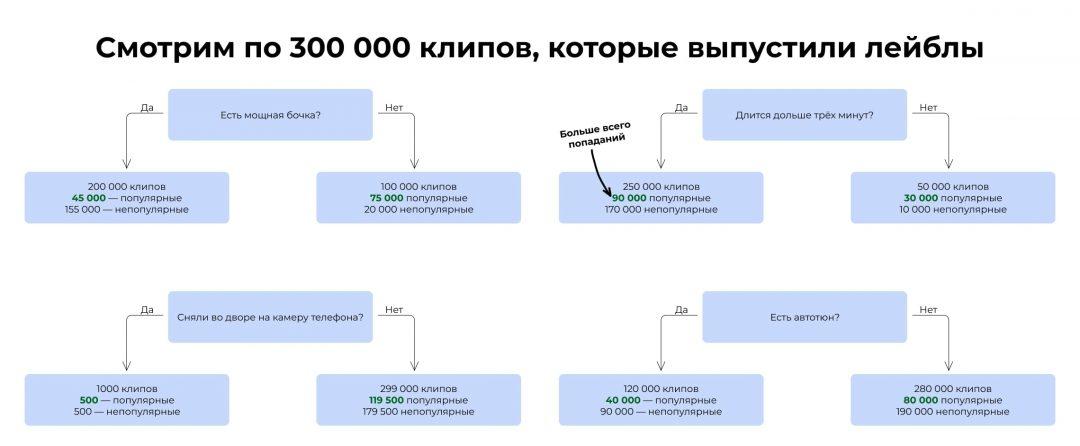
Ставим его на второе место.
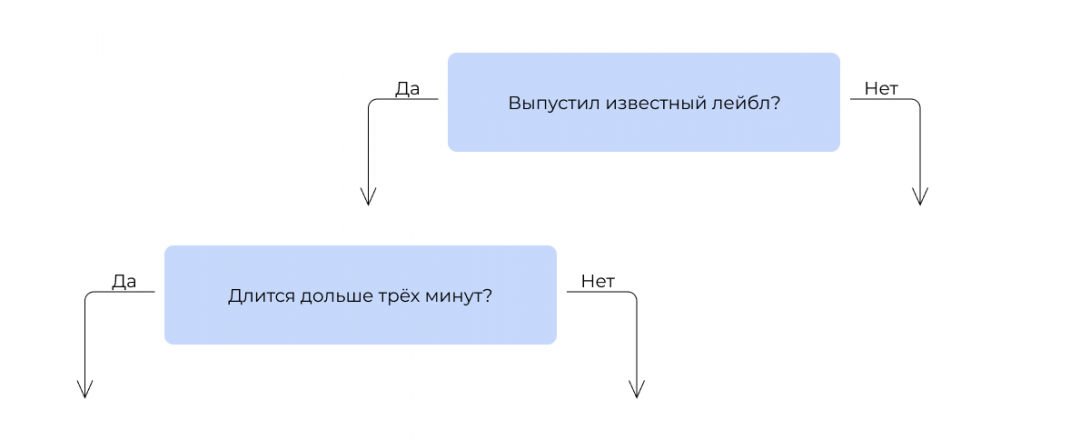
То же самое делаем для другой ветки. И так строим последовательность из остальных критериев. На практике вручную этим не занимаются: есть специальные алгоритмы, которые делают это автоматически.
Оп, у нас появилось дерево решений:
Случайный лес
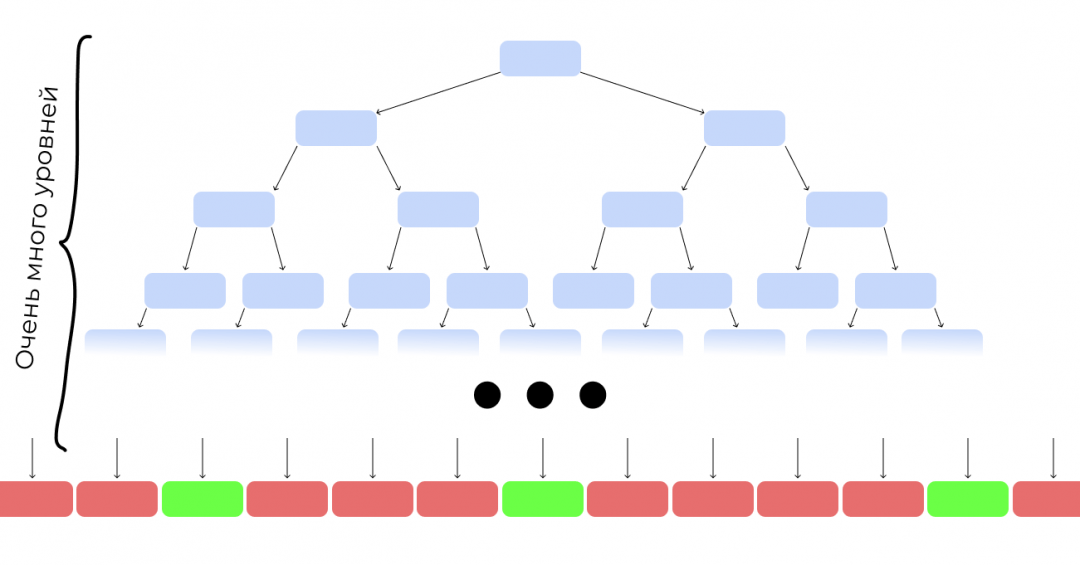
Есть проблема: построенное таким образом дерево очень сложное и, вероятно, не очень точное. Попробуем сделать не одно огромное дерево, а несколько небольших.
Возьмём случайную выборку из наших исходных данных. Не миллион клипов, а 10 000. К ним — случайный набор критериев, не все 100, а 5:

И построим дерево попроще:
Так построим ещё несколько деревьев, каждое — на своём наборе данных и своём наборе критериев:
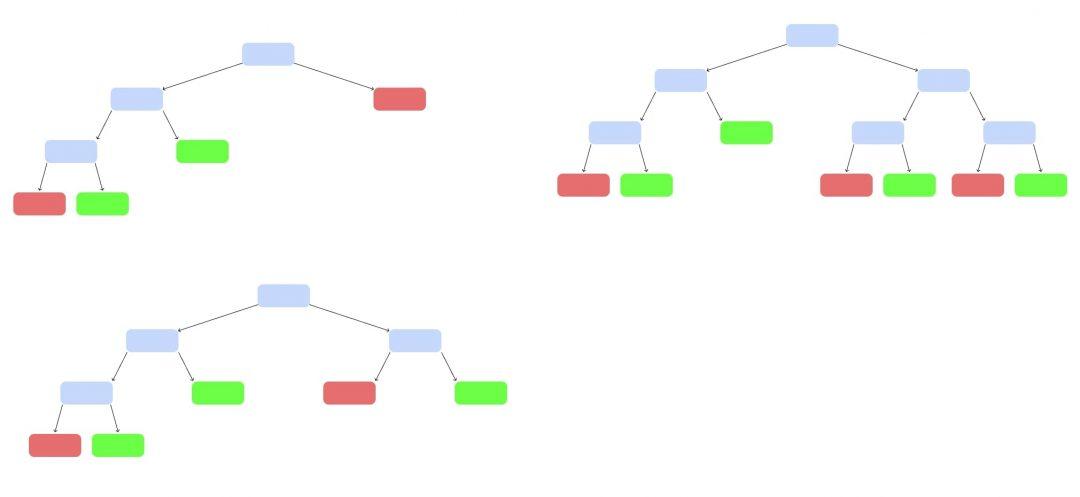
У нас появился случайный лес. Случайный — потому что мы каждый раз брали рандомный набор данных и критериев. Лес — потому что много деревьев.
Теперь запустим клип, которого не было в обучающей выборке. Каждое дерево выдаст свой вердикт, станет ли он популярным — «да» или «нет». Как голосование на выборах. Выбираем вариант, который получит больше всего голосов.
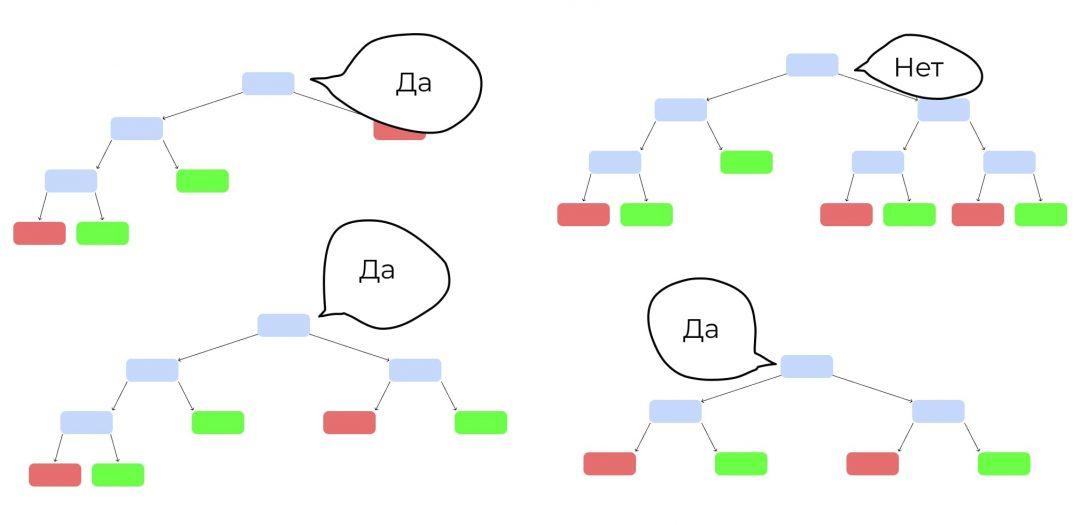
Неслучайный лес — бустинг
Теперь построим похожий лес, но набор данных будет неслучайным. Первое дерево мы построим так же, как и раньше, на случайных данных и случайных критериях. А потом прогоним через это дерево контрольную выборку: другие клипы, по которым у нас есть все данные, но которые не участвуют в обучении. Посмотрим, где дерево ошиблось:
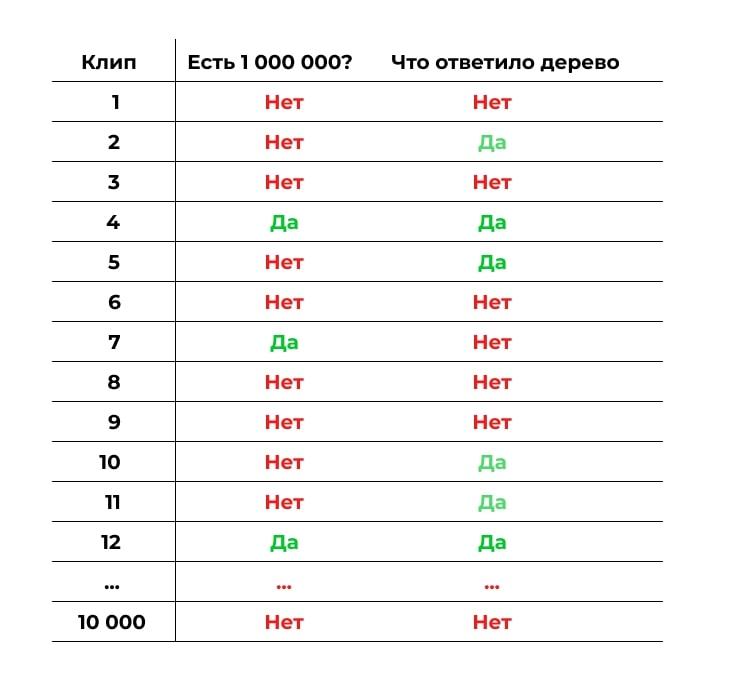
Теперь делаем следующее дерево. Обратим внимание на места, где первое дерево ошиблось. Дадим этим ошибкам больший вес при подборе данных и критериев для обучения. Задача — сделать дерево, которое исправит ошибки предыдущего.
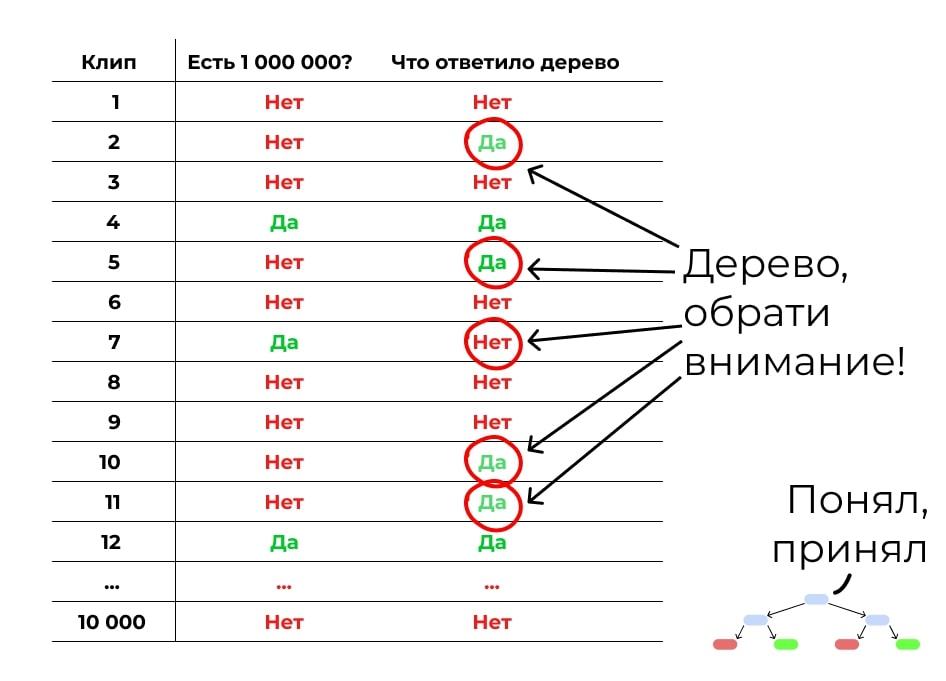
Но второе дерево наделает своих ошибок. Делаем третье, которое их исправит. Потом четвёртое. Потом пятое. Вы поняли принцип.
Делаем такие деревья, пока не достигнем желаемой точности или пока точность не начнёт падать из-за переобучения. Получается, у нас много деревьев, каждое из которых не очень сильное. Но вместе они складываются в лес, который даёт хорошую точность. Бустинг!
И где это используют?
Бустинг часто используют в задачах, когда нейронные сети не очень подходят.
Нейросети хорошо справляются с однородными данными, например изображениями или голосом. А вот если данные разного характера и с разной структурой, то бустинг справляется лучше. Например, чтобы предсказать погоду, надо учесть температуру и влажность, данные с радаров, наблюдения пользователей и другие параметры. Бустинг с этим справляется отлично.
Вот что про бустинг рассказывает Роман Халкечев, руководитель отдела аналитики в Яндекс.Еде:
«В Яндексе повсеместно используем библиотеку CatBoost. Это внутренняя разработка, которую в 2017 году выложили в open source. Она помогает решать много задач, например, ранжирование в Поиске, предсказание в Погоде, рекомендации в Музыке.
Когда я работал в Такси, с помощью CatBoost мы решали такую задачу: когда пользователь только заказывает машину, в округе может не быть свободных водителей. Мы в таком случае выводим сообщение: «Нет свободных машин». Но при этом уже через несколько секунд может появиться доступный водитель.
С одной стороны, мы не хотим терять заказ. С другой — не хотим разочаровывать пользователя, который начал поиск такси, но так и не смог уехать, потому что никогда не нашлось.
С помощью CatBoost мы решили научиться предсказывать, сможем ли найти для конкретного пользователя машину после вызова. Это задача классификации — нужно отнести пользователя к одной из двух групп: «Сможем найти машину» или «Не сможем найти машину». Мы ориентировались на метрики precision и recall. Они позволяют найти баланс надёжности: не наобещать лишнего, но и не потерять заказы.
В итоге благодаря новому механизму совершается около 1% от всех поездок, а в некоторых городах и районах — до 15%».
Почитайте полное интервью с Романом, там много про аналитику и машинное обучение на практике →


















