


При работе с Big Data используют большое количество информации: вычисляют паттерны поведения, смотрят статистику продаж, обучают ML-модели. Один из вариантов представления информации, который нужен для получения результата, — датасет. Сегодня разбираем, что это такое: кто его делает, как он выглядит и как с ним работать.
Понятие и задачи датасета
Датасет — структурированный набор обработанных и разложенных по понятным категориям данных. Данные могут быть разными, поэтому датасеты тоже могут быть разными.
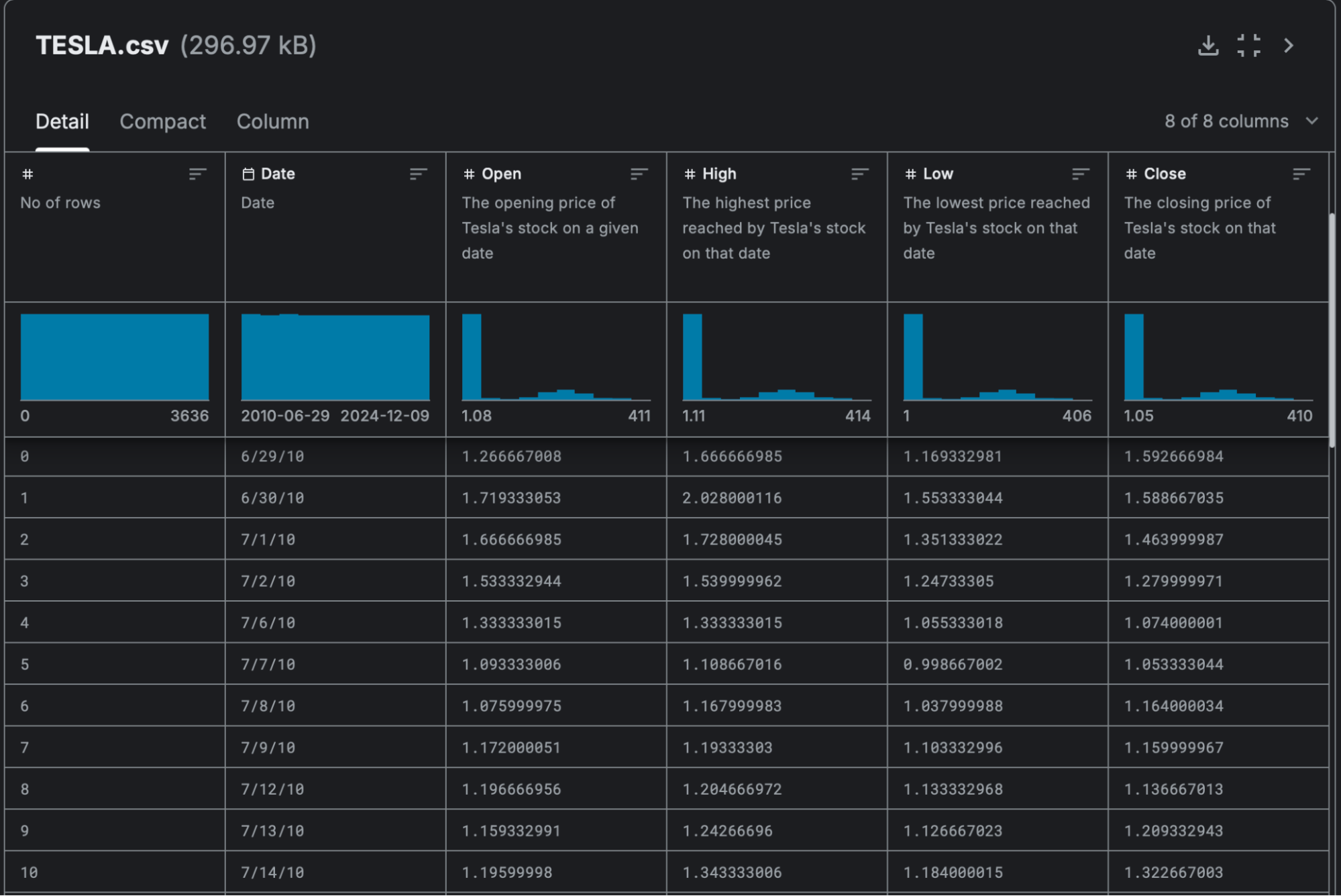
Вот пример датасета изменений курса акций компании Tesla. Тут есть несколько столбцов-категорий для разной информации:
- номер строки;
- день записи данных;
- цена открытия и закрытия акции;
- самая высокая и самая низкая цена за день.
Этот самый простой датасет выглядит как обычная эксель-таблица, пока всё привычно:
Но набор данных необязательно будет представлять собой таблицу, на самом деле он может быть любым: аудио, изображения, графики. Например, при обучении нейросети или моделей машинного обучения программе могут выдать большое количество фото размеченных картинок, чтобы она научилась определять различный тип для изображения:

У датасетов есть три основных варианта применения.
Обучение моделей машинного обучения. Программы изучают датасеты, выстраивают закономерности, учатся классифицировать каждый объект. Качество данных в датасете напрямую влияет на результаты работы модели.
Научные цели. Учёные используют наборы данных для проверки гипотез, анализа закономерностей, имитации реальных систем. В разных областях науки информация серьёзно различается, поэтому типы данных в датасетах могут быть почти любыми.
Бизнес-аналитика. Компании собирают большое количество информации, которую потом можно использовать для поиска правильных решений в бизнесе. Например, магазин может выявить ключевые запросы в разных городах или в разные праздники, чтобы понять, что интересует людей.
Типы датасетов
Есть несколько видов датасетов. Для примера мы разберём подробнее простую запись, упорядоченную и граф.
Простая запись (flat records)
Самый удобный и понятный вид данных. Они просты для понимания и обработки и используются в большинстве видов анализа. Визуально это таблица строк и столбцов. Каждый ряд или строка будет отдельной записью со своим названием, например название продукта, номер ряда в супермаркете или департамента:
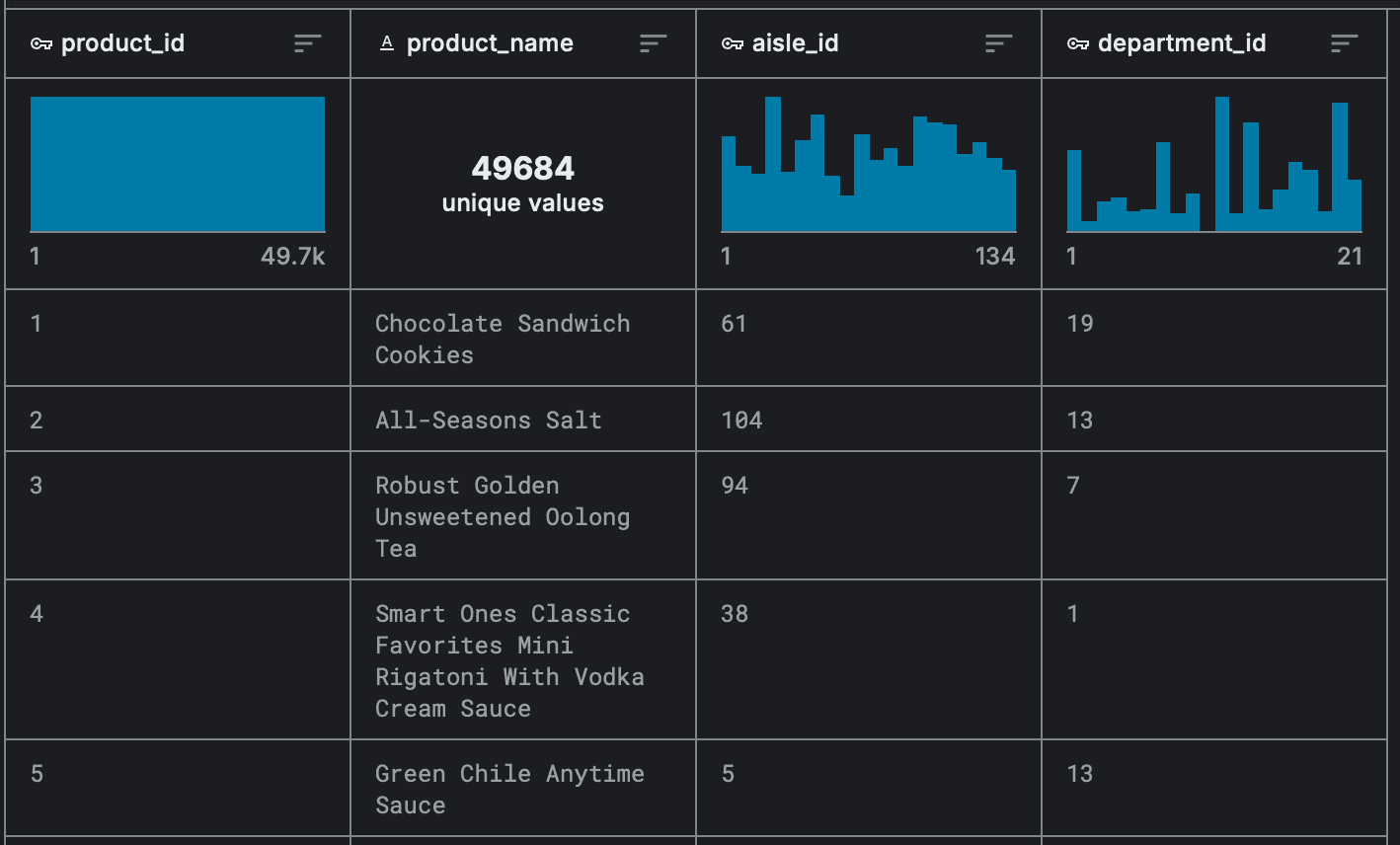
Упорядоченные записи (ordered records)
В таких датасетах данные имеют строгий порядок, и каждая запись зависит от предыдущей или следующей.
Это может быть важно для временных рядов или последовательности событий, когда анализируются колебания показателей или составляются прогнозы. Например, временные ряды количества заболевших коронавирусом в разных штатах и регионах по всему миру:
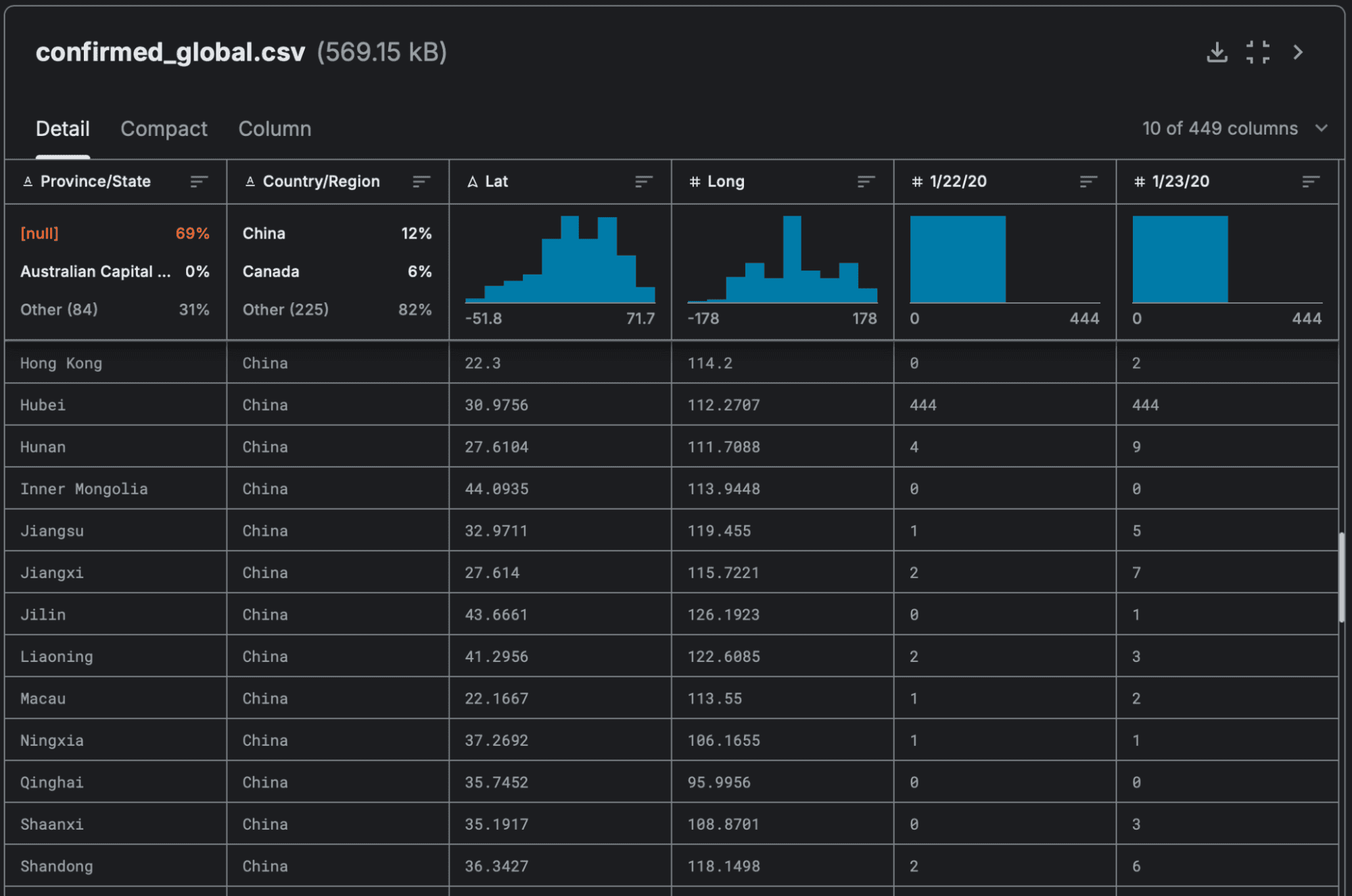
Графы (graphs)
Данные, которые выстроены в связанную систему через узлы и рёбра-связи между ними. Используются, когда между разными объектами важны связи.
Например, узлами могут быть люди, места, вещи. Рёбрами — отношения между людьми, дороги между местами, результат комбинации разных вещей между собой. В итоге связи могут выглядеть так:
- Александр дружит с Ольгой.
- Елизавета замужем за Сергеем.
- Эвелина помолвлена с Игорем.
- Анатолий влюблён в двоюродную сестру отчима племянницы своей одноклассницы Ольги.
Такие связи могут использоваться в социальных сетях для рекомендаций друзей или при оптимизации маршрута в навигаторе. Ещё это может выявлять мошеннические действия, например при аномальных связях между финансовыми транзакциями.




Свойства и характеристики датасетов
Dataset можно описать через свойства и характеристики. Свойства дают понимание внутренней структуры, а характеристики помогают оценить содержимое.
Примеры свойств датасета:
- Структура объясняет тип датасета — табличный формат, граф, временные ряды.
- Размер показывает, сколько данных содержит датасет. Пример — 10 000 строк и 15 столбцов.
- Тип данных описывает формат значений — числовой, строковый, временной. Пример — столбец «Цена» имеет числовой тип, а «Дата» — временной.
- Пропуски говорят об отсутствующих значениях. Например, в 15% случаев у пользователей нет данных о номере телефона или возрасте.
- Динамические или статические данные описывают ещё один тип информации — записи могут обновляться в реальном времени или быть постоянными. У динамических данных будет ещё одно свойство — скорость обновления.
Несколько возможных характеристик:
- Средние значения могут считаться по-разному, они показывают разные математические показатели усреднённых показателей. Это могут быть среднее арифметическое, медиана, мода значений. Например, средний возраст покупателей — 34 года.
- Диапазон показывает минимум и максимум значений. Пример — показатели ежедневных продаж колеблются от 5 000 до 50 000 рублей в день.
- Распределение данных говорит о закономерностях, если посмотреть на информацию в общем. Например, как распределяются доходы клиентов по городам и должностям на работе?
- Корреляция даёт понять связь разных типов данных друг с другом. Пример — связь расходов на рекламу и количеством новых клиентов.
Аномалии показывают неожиданные выделяющиеся значения. Если один из клиентов потратил в 30 раз больше остальных — это аномалия.

Датасеты для машинного обучения
Датасеты в машинном обучении используются, чтобы научить программу самостоятельно принимать решения. Делать это можно по-разному, вот несколько способов.
Обучение с учителем (supervised learning)
Самый простой способ натренировать модель так, как надо. Учитель в этом случае — инженер машинного обучения или дата-сайентист, который маркирует данные в датасете. Машина смотрит на эти промаркированные данные и понимает, что к чему относится. Изучив датасет, модель может распознавать похожие данные и строить связи между разными параметрами информации.
Обучение с учителем тоже делится на разные виды, например:
- Классификация, когда модель выявляет у данных определённые признаки и при работе ориентируется на них. Программа берёт входные данные, которые ей передают, и проверяет, какие выявленные признаки у этих данных есть, а каких нет. Например, если модель работает с голосом, она проверит уже выявленные звуковые характеристики и скажет, кому принадлежит голос — или какое слово он сказал.
- Регрессия относится к математике и говорит про связь одной величины с другой. Это позволяет понимать, как изменения в одном показателе сказываются на другом. Так можно строить прогнозы роста продаж после увеличения расходов на рекламу или сокращения сроков доставки.
Обучение без учителя (unsupervised learning).
Модель может учиться сама: получить датасеты и выявить какие-то правила. Программа установит свои законы распределения и разложит всё в соответствии с ними.
Обучение с частичным участием учителя (semi-supervised learning)
Вариант, когда совмещают оба подхода, описанные выше. Обучающий модель специалист может разметить часть данных в датасете, чтобы на старте было проще — а потом программа сама добавит новые закономерности.
Обучение с подкреплением (reinforcement learning). Программа учится сама, но получает обратную связь по результатам — это и есть подкрепление. Для старта у модели есть датасет и общие вводные данные для решения задачи. Правила устанавливают какие-то воздействия на модель, в зависимости от правильности или неправильности решения. Эти воздействия дают машине понять, как корректировать свои действия.
Общие критерии выбора и подготовки датасета
Чтобы решить конкретную задачу, нужно выбрать правильный датасет и подготовить его. Для этого понадобится учесть несколько факторов.
Цель использования датасета. Для разных целей понадобятся разные данные. Но не всегда это означает, что между целями и датасетом нужно искать прямую связь. Например, для продаж могут быть полезны датасеты погоды, если компания продаёт зонты, мороженое, сезонные продукты питания.
Качество данных. От качества датасета напрямую зависит финальный результат. Поэтому данные нужно проверить: есть ли в них критичные для цели пропуски? Нет ли очевидных ошибок вроде некорректных дат или отрицательной цены?
Объём датасета. Должен быть достаточным для задачи, но не избыточным. Например, для ML-моделей нужен как можно больший объём данных, чтобы модель в результате работала максимально точно. В бизнес-аналитике датасет должен быть оптимальным для обработки — это значит, что аналитик тоже должен постараться охватить много данных, но при этом понимать, сколько нужно для ответа на поставленный вопрос. Слишком большой датасет может замедлить обработку, не принеся ощутимой выгоды.
Доступ и юридические ограничения. Некоторые данные нельзя использовать вообще или можно только ограниченно. Перед использованием нужно проверить соблюдение законов конфиденциальности.
Структура и формат данных. Для работы с некоторыми датасетами нужны определённые инструменты и приложения и навыки работы с ними.
👉 После выбора датасета его нужно подготовить. Подготовка тоже включает несколько шагов.
Очистка данных означает их исправление: удаление нерелевантных, ошибочных и дублирующихся данных. Делать это вручную необязательно, анализ информации может быть машинным.
Форматирование приводит записи в датасете в стандартизированный вид. Например, все даты будут сохранены по шаблону YYYY-MM-DD, а в тексте будут только строчные буквы.
Обогащение добавляет данные, если чего-то не хватает. Можно добавить новую информацию или нужные разделы в старой.
Разделение по выборкам. Иногда один и тот же датасет используется для обучения ML-модели и её тестирования. Например, 80% датасета уходят на обучение программы, а остальные 20% — для тестирования, насколько хорошо она работает.
Создание и подготовка собственного датасета
Можно создать собственный датасет, следуя алгоритму из нескольких шагов.
- Определить цель использования датасета. Это может быть поиск ответа для бизнеса или обучение ML-модели. После понимания цели будет ясно, какая информация должна содержаться в датасете.
- Собрать данные. Это можно делать любыми способами: с использованием открытых источников, через другие сервисы, наблюдение или проведение интервью. Нужно помнить, что источник данных влияет на их качество, поэтому этот шаг стоит внимательно проанализировать.
Следующие этапы будут такими же, что при подготовке стороннего датасета.
- Очистить данные от ошибок, дублей и нерелевантной информации.
- Отформатировать данные в подходящий вид.
- Обогатить датасет недостающими данными.
- Разделить по выборкам, если необходимо.
Лучшие датасеты для анализа и машинного обучения
В открытых источниках можно найти много датасетов для разных целей. Но если вам нужна информация о конкретной компании, возможно, единственный путь получить её — собрать датасет самому, как делают исследователи данных, дата-сайентисты и другие специалисты.
Вот три ресурса, где можно поискать готовые датасеты.
Kaggle. Платформа с большой коллекцией наборов данных по различным темам: экономика, здравоохранение, спорт, технологии. Обычно датасеты Kaggle — в формате CSV или Excel.
Google Dataset Search. Поисковая система для датасетов от Google. Подходит для поиска специализированных данных из научных публикаций и государственных источников.
DataHub — коллекция общедоступных данных, включая экономику, транспорт и географию. Большинство датасетов — в формате CSV или JSON.
Встроенные датасеты
Во многих современных языках программирования есть библиотеки для работы с большими данными. А внутри библиотек есть встроенные датасеты, которые можно использовать.
Например, на Python есть фреймворк для машинного обучения Pytorch со встроенной библиотекой torchvision. Похожие технологии есть и в других языках: C++, Java, R.
Встроенные в библиотеки датасеты подходят для тех же целей, что и датасеты из открытых источников: обучение и тестирование моделей, тестирование гипотез, обучение анализу данных. Главное, чтобы датасет подходил своей цели.
Как в итоге выглядит работа с датасетом
Работа с датасетом строится по одному и тому же алгоритму.
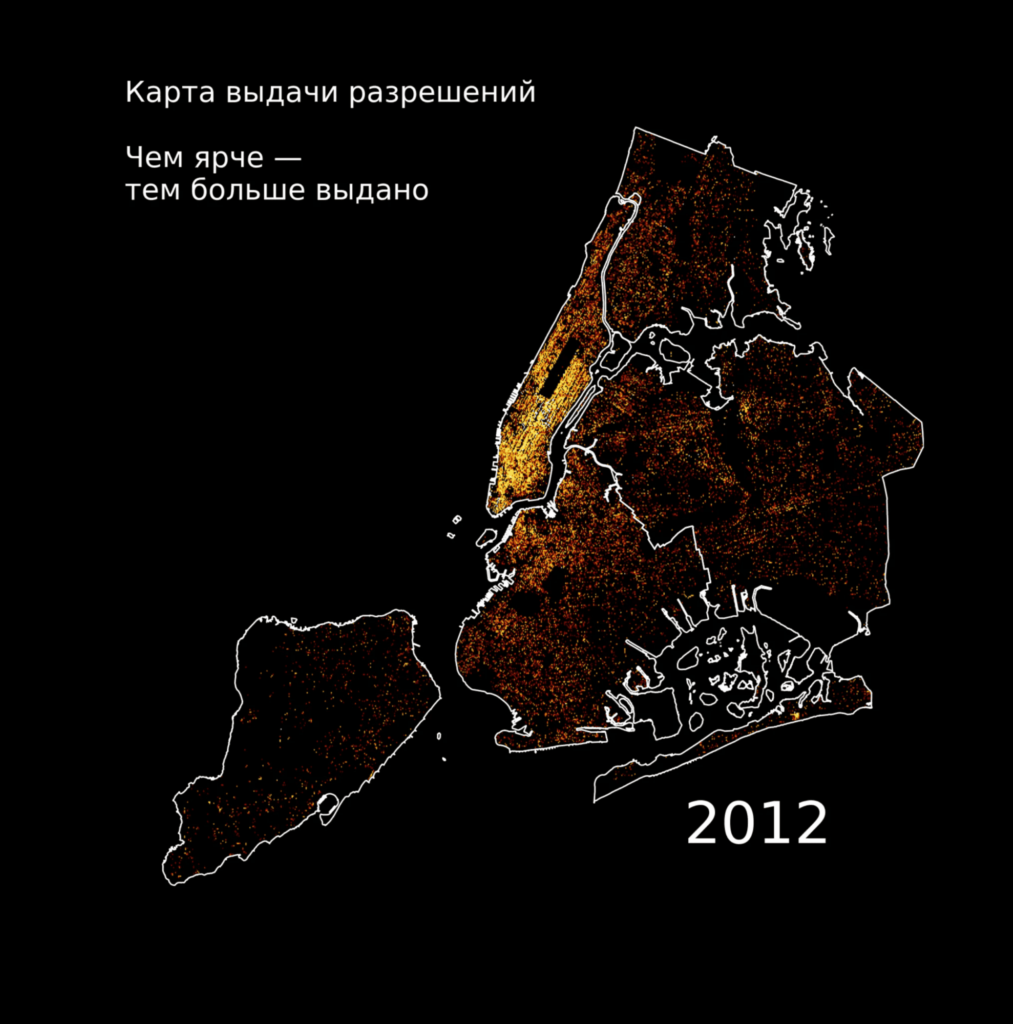
Допустим, мы хотим найти какие-то закономерности в выдаче разрешений на строительство. Потом эти данные можно как-то использовать в бизнесе — например, посмотреть, где стоит открывать магазин, потому что через 2–3 года всё вокруг будет застроено жилыми домами и появятся потенциальные клиенты.
Для этого мы:
- берём датасет из открытых источников;
- устанавливаем на компьютер Python и все дополнительные необходимые инструменты для работы с данными;
- подключаем датасет и очищаем его;
- форматируем данные;
- составляем запрос и визуализируем результаты ответа на экране.
В итоге получаем такую картину:
Почитать подробнее про работу с готовыми датасетами можно в наших статьях:
Кто делает датасеты
Созданием могут заниматься разные люди. Это могут быть организации и отдельные специалисты и любители, например:
- исследовательские организации и университеты;
- технологические компании;
- государственные организации;
- коммерческие компании;
- неофициальные сообщества программистов.
Что дальше
В следующий раз попробуем собрать свой датасет из открытых источников. Или спарсим что-нибудь весомое (легальным образом) и посмотрим, что из этого можно выжать.








