


В статье про то, как устроены адреса в интернете, мы упоминали, что можно самому, без Роскомнадзора, заблокировать себе соцсети. Например, вам нужно написать диплом, сдать проект или успеть с задачей к дедлайну: тогда вы запрещаете компьютеру заходить на определённые адреса в интернете и успешно сдаёте работу. Для блокировки использовался файл hosts — в нём хранится настройка внутреннего DNS-сервиса, который говорит компьютеру, по каким адресам ходить.
Сегодня мы возьмём ту же идею с блокировкой через hosts и выведем её на новый уровень: вместо Одноклассников или Фейсбука у вас появится страница-заглушка. А чтобы было ещё интереснее, эта страница будет считать, сколько раз вы сегодня пытались отвлечься от работы. Повысим, так сказать, уровень осознанности.
Принцип работы
Напомним, как обычно ведёт себя браузер:
- Вы вводите адрес в строку браузера, и теперь ему нужно перевести адрес из букв в цифры — IP-адрес.
- Перед тем как отправить запрос на DNS-сервер, браузер заглянет в файл hosts — там написаны основные правила для всего компьютера.
- Если там прописана наша соцсеть и IP-адрес, куда нужно отправлять запросы для этой соцсети, то браузер сразу будет отправлять запросы туда.
- Если мы там напишем, что все запросы на vk.com отправлять на 127.0.0.1, то такие запросы не выйдут за пределы компьютера и уйдут на этот адрес.
- Обычно по этому адресу нет никаких страниц, но с помощью программы Apache мы скажем компьютеру, какую страницу нужно показывать, когда есть запрос на этот адрес.
- Настроим сервер, положим в него нашу страницу-заглушку. Она будет считать, сколько раз вы попытались зайти в соцсети, которые сами себе закрыли.
Первые три пункта работают и так, там нам делать нечего. Начнём сразу с записей в hosts.
Добавляем соцсети в hosts
Если вы забыли, как вносить новые записи в файл hosts — посмотрите в прошлой статье раздел «Как заблокировать себе соцсети с помощью hosts». Там есть подробная инструкция, как открыть этот файл и добавить в него что-то новое.
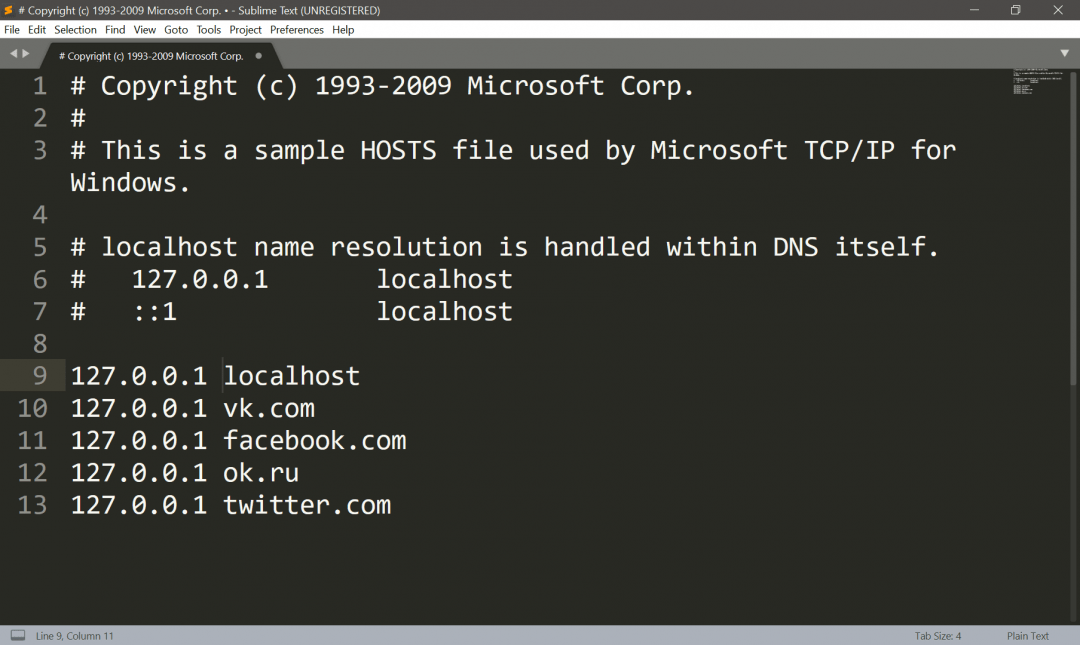
Мы будем блокировать такие сайты:
- ВКонтакте;
- Фейсбук;
- Одноклассники;
- Твиттер.
Для этого наш hosts должен выглядеть так:
Делаем страницу-заглушку со счётчиком
Логика работы страницы такая:
- запоминаем, какое сегодня число;
- при загрузке страницы смотрим, заходили на неё сегодня или нет;
- если не заходили — меняем число последнего захода на сегодняшнее;
- а если уже заходили — увеличиваем счётчик посещений и выводим нужное сообщение самому себе.
За основу возьмём наш обычный шаблон, в котором будут две важных части — сообщение для пользователя и скрипт обработки посещений.
Начнём с сообщения, которое мы сделаем заголовком в разделе <body>:
<h1 id=”hello”>Привет! Вы сегодня 1-й раз хотели зайти в эту соцсеть.</h1>
Добавим стили для заголовка:
h1{
text-align: center;
margin: 20;
font-family: Verdana, Arial, sans-serif;
font-size: 50px;
}
Смотрим, что получилось:

Теперь напишем скрипт, который будет считать, сколько раз за сегодня открывалась эта страница. Основное, что мы используем, — localstorage, именно там будем хранить всю информацию о посещениях:
// счётчик количества посещений
var counter = 0;
// запоминаем сегодняшнее число в переменную today
var date = new Date();
var today = date.getDate();
// если мы загружаем эту страницу вообще первый раз на этом компьютере и в памяти нет сохранённого значения
if (localStorage.getItem('today') == null) {
// берём сегодняшнее число и отправляем его в хранилище
today = date.getDate();
localStorage.setItem('today', today);
// заводим в хранилище ячейку counter и обнуляем его, потому что посещений ни разу не было до этого
localStorage.setItem('counter', 0);
// если в хранилище уже есть информация о прошлом посещении
} else {
// если последнее посещение было не сегодня
if (today != localStorage.getItem('today')) {
// запоминаем сегодняшнее число и обнуляем счётчик посещений
localStorage.setItem('counter', 0);
localStorage.setItem('today', today);
}
}
// если в счётчике посещений уже что-то есть…
if (localStorage.getItem('counter') !== null) {
// берём оттуда число посещений и увеличиваем его на единицу
counter = parseInt(localStorage.getItem('counter'));
counter += 1;
// выводим сообщение
document.getElementById('hello').innerHTML = 'Это уже ' + counter + '-я попытка зайти в эту соцсеть за сегодня.';
// сохраняем новое значение счётчика
localStorage.setItem('counter', counter);
// если счётчика посещений до сих пор почему-то нет в хранилище…
} else {
// отмечаем первое посещение
counter = 1;
// записываем его в хранилище
localStorage.setItem('counter', counter);
};Пару раз обновляем страницу, чтобы убедиться, что всё работает:

Сохраняем файл под именем index.html — он нам пригодится, когда будем настраивать виртуальный сервер.
<!DOCTYPE html>
<html>
<!-- служебная часть -->
<head>
<!-- заголовок страницы -->
<title>Иди работать!</title>
<!-- настраиваем служебную информацию для браузеров -->
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- задаём CSS-стили прямо здесь же, чтобы всё было в одном файле -->
<style type="text/css">
/*параметры заголовка*/
h1 {
text-align: center;
margin: 20;
font-family: Verdana, Arial, sans-serif;
font-size: 50px;
}
/*закончили со стилями*/
</style>
<!-- закрываем служебную часть страницы -->
</head>
<!-- началось содержимое страницы -->
<body>
<!-- началась видимая часть -->
<!-- заголовок страницы -->
<h1 id="hello">Привет! Вы сегодня 1-й раз хотели зайти в эту соцсеть.</h1>
<!-- закончилась видимая часть -->
<!-- пишем скрипт, который будет постоянно сохранять наш текст -->
<script>
// счётчик количества посещений
var counter = 0;
// запоминаем сегодняшнее число в переменную today
var date = new Date();
var today = date.getDate();
// если мы загружаем эту страницу вообще первый раз на этом компьютере и в памяти нет сохранённого значения
if (localStorage.getItem('today') == null) {
// берём сегодняшнее число и отправляем его в хранилище
today = date.getDate();
localStorage.setItem('today', today);
// заводим в хранилище ячейку counter и обнуляем его, потому что посещений ни разу не было до этого
localStorage.setItem('counter', 0);
// если в хранилище уже есть информация о прошлом посещении
} else {
// если последнее посещение было не сегодня
if (today != localStorage.getItem('today')) {
// запоминаем сегодняшнее число и обнуляем счётчик посещений
localStorage.setItem('counter', 0);
localStorage.setItem('today', today);
}
}
// если в счётчике посещений уже что-то есть…
if (localStorage.getItem('counter') !== null) {
// берём оттуда число посещений и увеличиваем его на единицу
counter = parseInt(localStorage.getItem('counter'));
counter += 1;
// выводим сообщение
document.getElementById('hello').innerHTML = 'Это уже ' + counter + '-я попытка зайти в эту соцсеть за сегодня.';
// сохраняем новое значение счётчика
localStorage.setItem('counter', counter);
// если счётчика посещений до сих пор почему-то нет в хранилище…
} else {
// отмечаем первое посещение
counter = 1;
// записываем его в хранилище
localStorage.setItem('counter', counter);
};
// закончился скрипт
</script>
<!-- закончилось содержимое страницы -->
</body>
<!-- конец всего HTML-документа -->
</html>Минутка занудства о протоколах
Если сейчас открыть файл index.html в браузере, он будет работать, никаких проблем. Скрипт выполняется, заголовок выводится, красота. Но посмотрите на адрес, по которому идёт запрос. Скорее всего, он будет начинаться со слова file или «Файл». Это значит, что браузер работает с локальной файловой системой, не трогая никакие интернеты. Работает файловый протокол.
А когда мы делаем запрос в интернет (например, на vk.com), у нас в адресе стоит префикс http — это означает, что мы сейчас делаем http-запрос, то есть запрос по протоколу передачи гипертекста.
Пора рассказать, что такое протоколы.
Представьте, что вы находитесь дома. Вы берёте с полки книгу и читаете её. Вы по умолчанию считаете, что все книги в доме чистые, поэтому после прочтения вы не будете мыть руки.
Теперь вы берёте книгу и идёте в парк. Домой возвращаетесь в троллейбусе. Вы зашли домой с улицы и первым делом моете руки — потому что недавно держались за грязные поручни. Вы точно так же читали книгу, но из-за особенностей транспорта теперь ведёте себя по-другому.
Как вы ведёте себя в этих двух ситуациях — это протокол. Протокол — это определённые правила, по которым вы взаимодействуете с окружающим миром: после транспорта мыть руки, на пороге снимать обувь, на работе здороваться и так далее. У компьютеров то же самое: есть протоколы для веб-страниц (http), передачи файлов (ftp), работы с почтой (imap) и так далее.
Так вот: файловый протокол, по которому вы открываете файлы с диска, — это не то же самое, что http-протокол, по которому идут запросы из браузера.
За исполнение запросов по протоколу file отвечает ваша операционная система. А за исполнение http-запросов — специальная программа, которая называется веб-сервером. Когда в компьютер прилетает http-запрос, он ищет в памяти запущенный веб-сервер и кидает запрос в него. Разбирайся, мол.
Сейчас на вашем компьютере не работает никакого веб-сервера. Если вы наберёте в браузере http://127.0.0.1, вы получите ошибку, потому что у вас в памяти нет программы, которая обрабатывает http-запросы. Адрес действителен, но ответственного по http нет, поэтому и ошибка.
Настраиваем Апач
Нам нужно, чтобы между браузером и компьютером произошёл такой диалог:
Браузер: Алло, алло! Это 127.0.0.1?
Операционная система: Вам чего?
Браузер: У меня http-запрос.
Операционная система: ожидайте, перевожу вас на http-сервер.
Http-сервер: У аппарата. Диктуйте ваш запрос.
Браузер: Запрашиваю страницу по адресу vk.com, протокол http.
Http-сервер: Ждите, исполняю…
Для этого диалога в памяти нашего компьютера должна появиться программа-сервер, которая откликается на http-запросы. Серверных программ много, мы используем самую распространённую — Apache, она же Апач. Как индейское племя.
Пользователям MacOS повезло — Апач уже встроен в операционную систему и готов к настройке. Для Windows его придётся ставить отдельно.
Разработчики Апача исходят из того, что у вас достаточно квалификации для самостоятельной сборки программы из исходного кода. Нам приятно, что о нас так думают, но мы сделаем проще — возьмём официальную сборку XAMPP от партнёров Apache Software Foundation. В комплекте с сервером идёт база данных и поддержка PHP и Perl. Сейчас они нам не нужны, но пригодятся в будущих проектах. Скачайте и установите её как обычную программу.
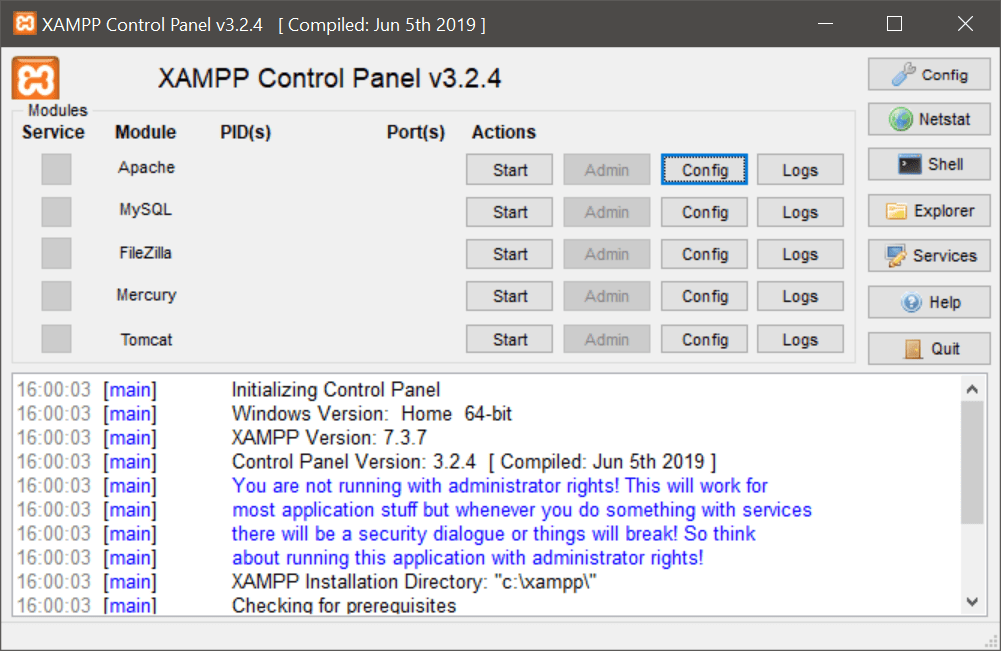
После установки попадаем в панель управления всеми модулями и нажимаем Start напротив Апача, чтобы убедиться, что всё работает как нужно:
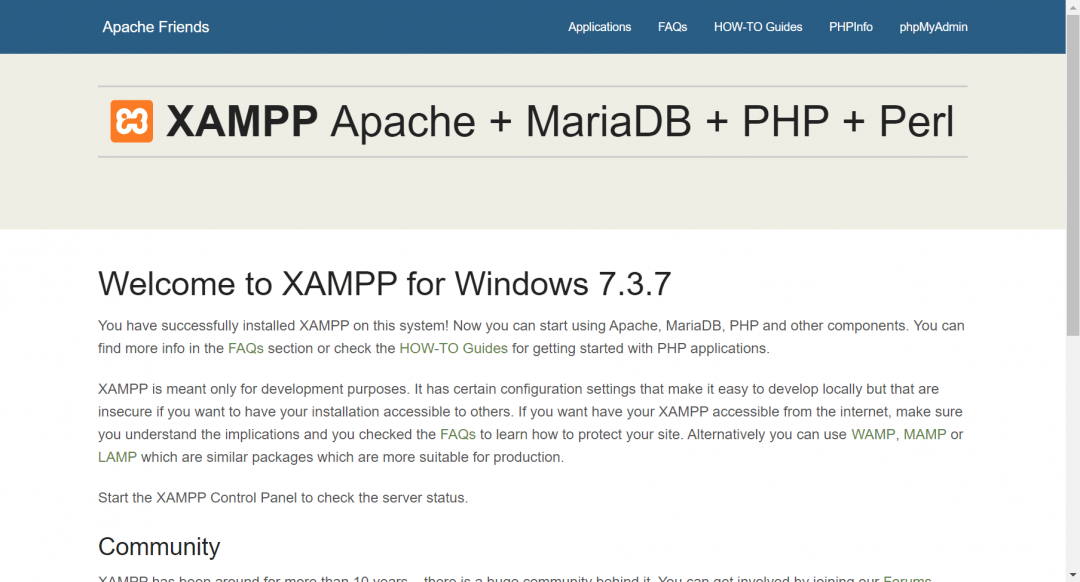
Теперь, когда мы наберём в строке браузера localhost и нажмём клавишу ввода, то увидим такую страницу. Она означает, что апач установлен и работает правильно:
Если у вас Макинтош, то вместо скачивания и установки достаточно в терминале написать команду:
sudo apachectl start
После этого по адресу localhost будет страница с текстом It works, которая говорит нам о том, что всё работает.
Указываем путь к нашей странице
Последнее, что нам осталось сделать, — научить Апач показывать нашу страницу вместо своей заглушки.
Для этого нам нужно найти путь, по которому Апач ищет файлы для отображения, и положить в эту же папку нашу страницу. Чтобы найти путь, нажимаем кнопку Config напротив Апача и выбираем первую строчку — httpd.conf:
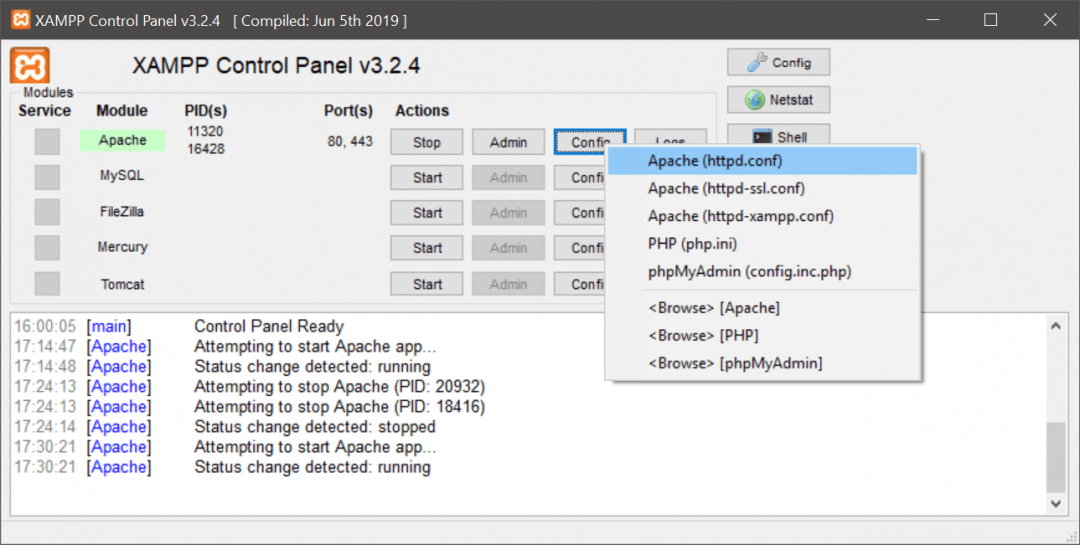
Появляется окно редактора, в котором открылся файл с настройками нашего сервера. Нужно найти строчку DocumentRoot, которая покажет нам, куда Апач обращается за веб-страницами:
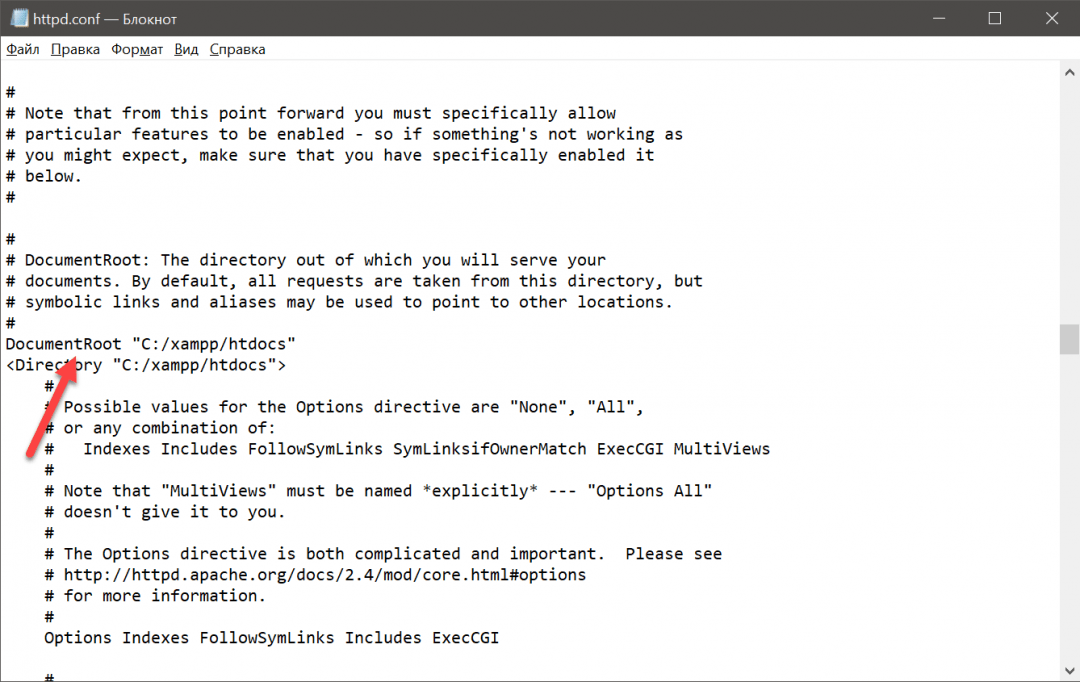
Мы видим, что Апач обращается к папке C:/xampp/htdocs. Это значит, что проще всего будет положить наш файл index.html в эту папку, а всё остальное содержимое папки — удалить, потому что оно нам не нужно.
Мы всё сделали, теперь можно спокойно работать — как только мы попробуем несколько раз зайти в Одноклассники, увидим такое:

К сожалению, с фейсбуком так не получится, и сайт покажет нам такое сообщение:
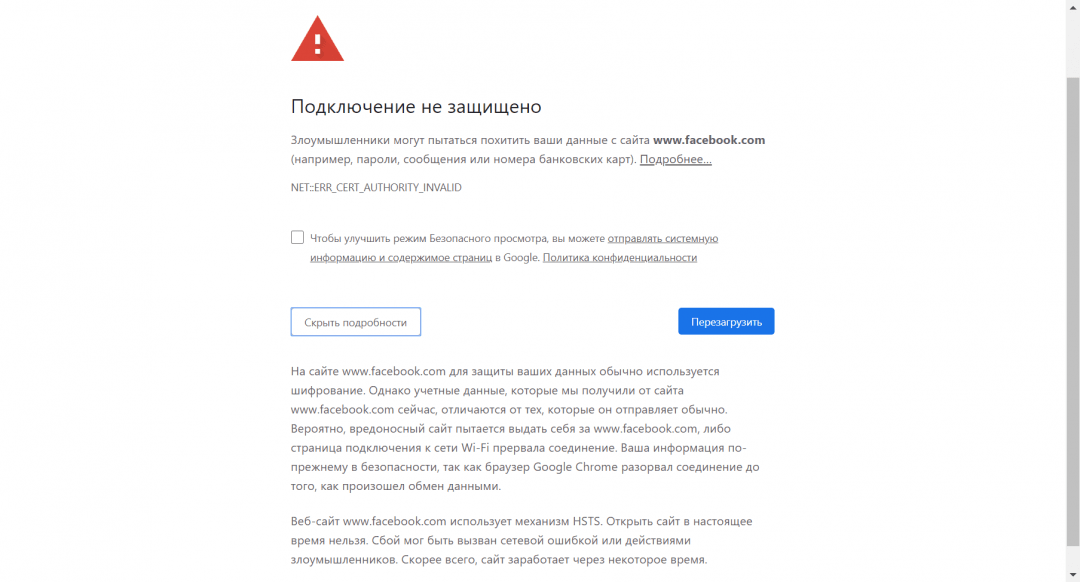
Всё дело в том, что современные браузеры используют технологию HSTS, которая отслеживает, всё ли в порядке с каналом связи от компьютера до сайта. Если HSTS видит, что что-то с каналом или настройками сети не так, то в целях безопасности он блокирует такое соединение и выводит сообщение об ошибке. Обойти штатными средствами это нельзя — сайты типа фейсбука или гугла уже вписаны в HSTS-настройки браузера и удалить их оттуда не получится.
Как сделать так, чтобы это не мешало нам показывать страницу и фильтровать трафик сильнее, чем сейчас, — расскажем в отдельной статье.








