Нейросети в 2026 году — это просто инструмент, который можно собрать вечерком под чай, даже если у вас нет видеокарты за 300 тысяч рублей.
В прошлом цикле статей мы учили компьютер видеть: распознавать лица, определять пол и возраст. Теперь пришло время научить его читать и понимать смысл.
Не будем грузить вас сухой теорией про синапсы, а с нуля создадим и обучим полезную NLP-модель — фильтр токсичных комментариев. Разберёмся, как машина превращает слова в цифры, соберём архитектуру на Keras и запустим обучение прямо в браузере.
Основы нейросетей
Мы уже разбирали на примере, как нейросеть предсказывает результат. Если пропустили — почитайте статью «Как учатся нейронки», там всё объяснено на пальцах. Сегодня нас интересует другое: как превратить человеческий язык в цифры.
Компьютер не понимает сарказм, не знает алфавита и не чувствует эмоций. Для него фраза «Ты плохой человек» — это просто набор байтов. Чтобы нейросеть смогла отличить токсичный комментарий от доброго, нам нужно перевести слова на язык математики.
Поэтому перед тем, как текст попадёт в модель, с ним происходит два ключевых шага:
- Токенизация. Мы разбиваем предложение на мелкие кусочки — токены. Это могут быть целые слова или части слов. Каждому токену присваивается номер из словаря модели, например:
“hello”→ токен 1532,“world”→ токен 829. Пока что это просто числа-индексы и сами по себе они ничего не означают. - Эмбеддинги. На следующем шаге каждый токен-номер превращается в вектор — длинный список чисел, который называется эмбеддинг. По сути, модель говорит: «Я не знаю, что такое слово, но я знаю, что токен 1532 можно представить как набор координат: [0.12, -0.88, 0.04, …]».
Суть в том, что в этом многомерном пространстве токены со сходным смыслом оказываются рядом. Например: «король» и «королева» находятся близко, «быстрый» и «скорый» тоже. Слова «плохой» и «ужасный» образуют отдельный кластер, а токсичные слова — свой. То есть эмбеддинг — это смысловое представление токена в виде математики.
Классический пример того, как нейросеть видит смыслы:
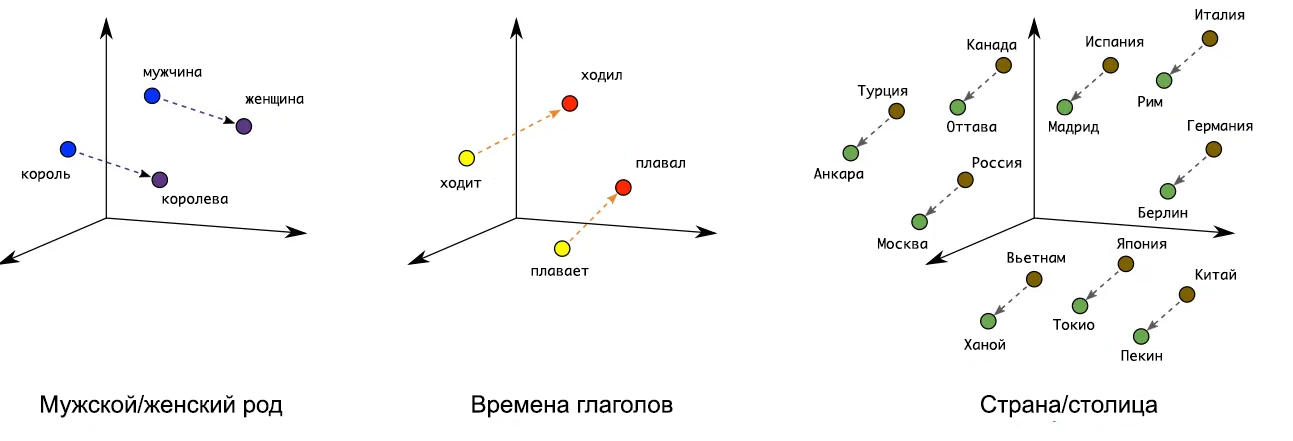
Расстояние между векторами «король» → «королева» примерно такое же, как между «мужчина» → «женщина». Из-за этой геометрии модель может решать уравнения вида: «Король» − «Мужчина» + «Женщина» ≈ «Королева».
Именно через эту математическую «географию смыслов» мы и будем определять, какая фраза похожа на спам, а какая — на адекватный комментарий.
Что такое нейросети и как они работают
Теперь, когда у нас есть токены и их смысловые представления — эмбеддинги, становится понятнее, что именно «съедает» нейросеть. Она работает не с буквами и словами, а с числами, которые отражают смысл текста. То есть, по сути, нейросеть — это математическая функция, которая ищет закономерности.
В программировании мы прописываем жёсткие правила вручную: если в тексте есть слово «дурак», то это оскорбление. В нейросетях же мы действуем иначе: даём машине 10 000 примеров оскорблений и говорим: «Разберись сама, что их объединяет». И сеть начинает замечать неочевидное: сочетания слов, контекст, знаки препинания. Она сама выводит правила, которые мы даже не смогли бы сформулировать кодом.
Именно благодаря эмбеддингам модель начинает обнаруживать вещи, которые невозможно выразить через if: тон фразы, сарказм, грубые формы обращения, пассивную агрессию, сочетания слов.
Архитектура нейросетей
Любая нейросеть похожа на слоёный пирог или конвейер, и данные проходят через неё последовательно:
- Входной слой (Input Layer): он принимает не текст, а последовательность токенов, уже превращённых в числа. Это как если бы вы подали нейронке не предложение, а список вида: [513, 92, 8841, 12, 44].
- Embedding-слой (часть скрытых слоёв). Здесь токены превращаются в векторы, которые отражают смысл слова. Сеть видит не «молодец», а что-то вроде:
[-0.12, 2.44, -0.03, …]. - Скрытые слои (Hidden Layers): здесь нейроны перемножают числа, ищут связи и признаки. Чем больше слоёв, тем более сложные абстракции — например, сарказм — может понять сеть. Каждый слой — это шаг от сырых векторов к пониманию «токсично/нет».
- Выходной слой (Output Layer): выдаёт результат. Для нашего спам-фильтра это будет всего одно число от 0 до 1, где 0 — «добрый котик», а 1 — «токсичный тролль».
Схематично это выглядит так:
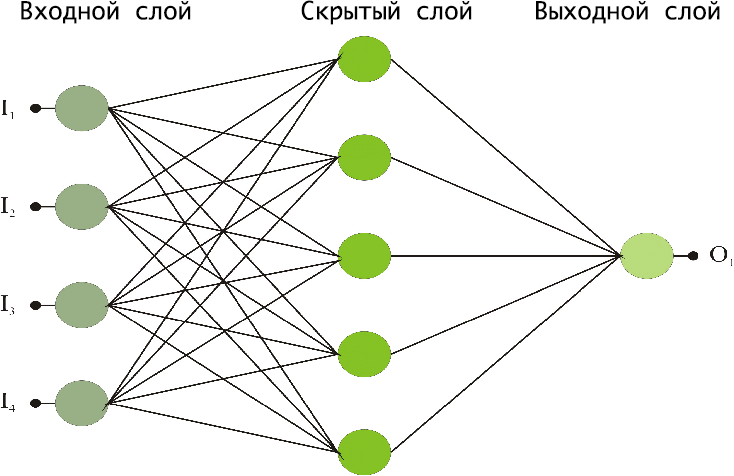
У нашей модели будет именно такая архитектура. Данные двигаются слева направо: входной слой принимает цифры, то есть токены слов, скрытый слой ищет в них закономерности, а единственный нейрон выходного слоя выносит вердикт — токсичный это комментарий или нет.
Понятие искусственного нейрона
Нейрон — это мельчайший строительный блок сети, её атом. Нейрон не живёт сам по себе: слои состоят из десятков, сотен или тысяч нейронов, которые параллельно обрабатывают одни и те же входные данные, но каждый — со своими весами и своей «точкой зрения».
Чтобы понять устройство нейрона, представьте строгого судью с весами. К нейрону приходят числовые сигналы — это не сами слова, а их эмбеддинги, или значения с предыдущего слоя. Но судья слушает не всех одинаково: каждый вход умножается на свой вес — показатель важности.
- Слово «привет» нейтральное. Его вес будет около нуля. Даже если сказать «привет» десять раз, судья не отреагирует.
- Слово «ужасный» — важная улика, у него будет огромный вес.
Нейрон занимается простой математикой: он перемножает входящие сигналы на их веса и складывает результат. Если итоговая сумма превышает определённый порог, нейрон активируется и кричит следующему слою: «Ребята, кажется, тут ругаются!»
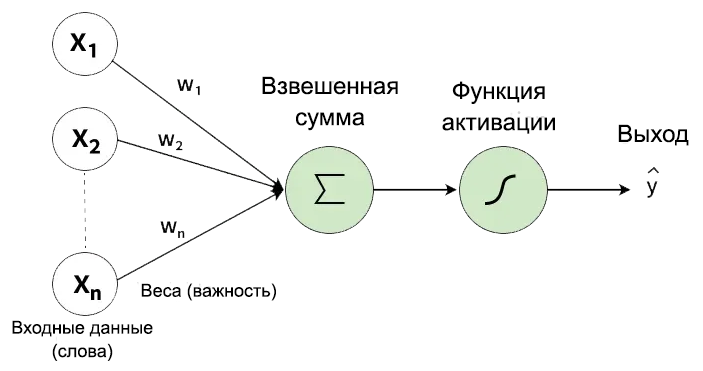
Вся магия обучения сводится ровно к одному: подобрать правильные веса. В начале обучения они случайные — нейрон может среагировать на слово «хлеб», но после тысяч примеров сеть понимает: у слова «ужас» вес должен быть высоким, а у слова «спасибо» — низким.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Подготовка к созданию нейросети
Понимать, как работает нейрон, — это важно, но на одной теории далеко не уедешь. Любой проект машинного обучения, будь то спам-фильтр или ChatGPT, держится на трёх китах: качественных данных, удобных инструментах и вычислительной мощности. Без этого даже самая гениальная архитектура останется просто математической формулой.
Сборка и подготовка датасета
Нейросеть учится на примерах. Чтобы она поняла, что такое «токсичность», нам нужно показать ей тысячи злых комментариев и тысячи добрых и сказать: «Вот это плохо, а это — хорошо».
В реальной жизни сбор данных — самая долгая часть работы. В коммерческих проектах дата-сайентисты скачивают огромные архивы комментариев с Kaggle или парсят соцсети. Обычно это тяжёлые CSV-таблицы на миллионы строк.
Но для нашего проекта мы поступим проще. Чтобы не мучиться с загрузкой файлов в облако и парсингом таблиц, мы создадим свой мини-датасет прямо в коде. Главное, понять принципы, а уже потом можно заменить самописный список на загрузку реального файла с миллионом строк — это дело одной команды. Архитектура сети от этого не изменится.
Языки и библиотеки для разработки
Стандарт де-факто в мире машинного обучения — это Python. Он победил всех благодаря простоте и мощным библиотекам. В нашем проекте мы будем использовать:
- TensorFlow/Keras — самая дружелюбная библиотека для новичков. Она работает как конструктор: мы будем просто добавлять слои друг за другом, не прописывая сложные формулы вручную.
- Pandas — чтобы открыть нашу таблицу с данными и почистить её.
- NumPy — для быстрой работы с массивами чисел.
Среда обучения и серверы с GPU
Самый частый страх новичка: «У меня старый ноутбук, он сгорит!»
Спокойно! Ноутбук будет только показывать картинку, а все вычисления мы проведём в облаке.
Для своего проекта мы будем использовать Google Colab: это бесплатная среда, которая работает прямо в браузере, как Google Docs, только для кода. Главная фишка Colab — гугл бесплатно даёт вам доступ к видеокарте на своих серверах. Обучение, которое на процессоре ноутбука заняло бы час, на видеокарте T4 в облаке пролетит за пару минут или секунд. Ничего устанавливать и настраивать не нужно — всё уже готово к работе.
Процесс создания нейросети
Мы не будем устанавливать Python, Anaconda и драйверы Nvidia на свой компьютер — в Google Colab уже настроено за нас.
1. Переходим на сайт colab.research.google.com. Вам понадобится обычный google-аккаунт. В открывшемся окне нажимаем внизу кнопку «Создать блокнот».
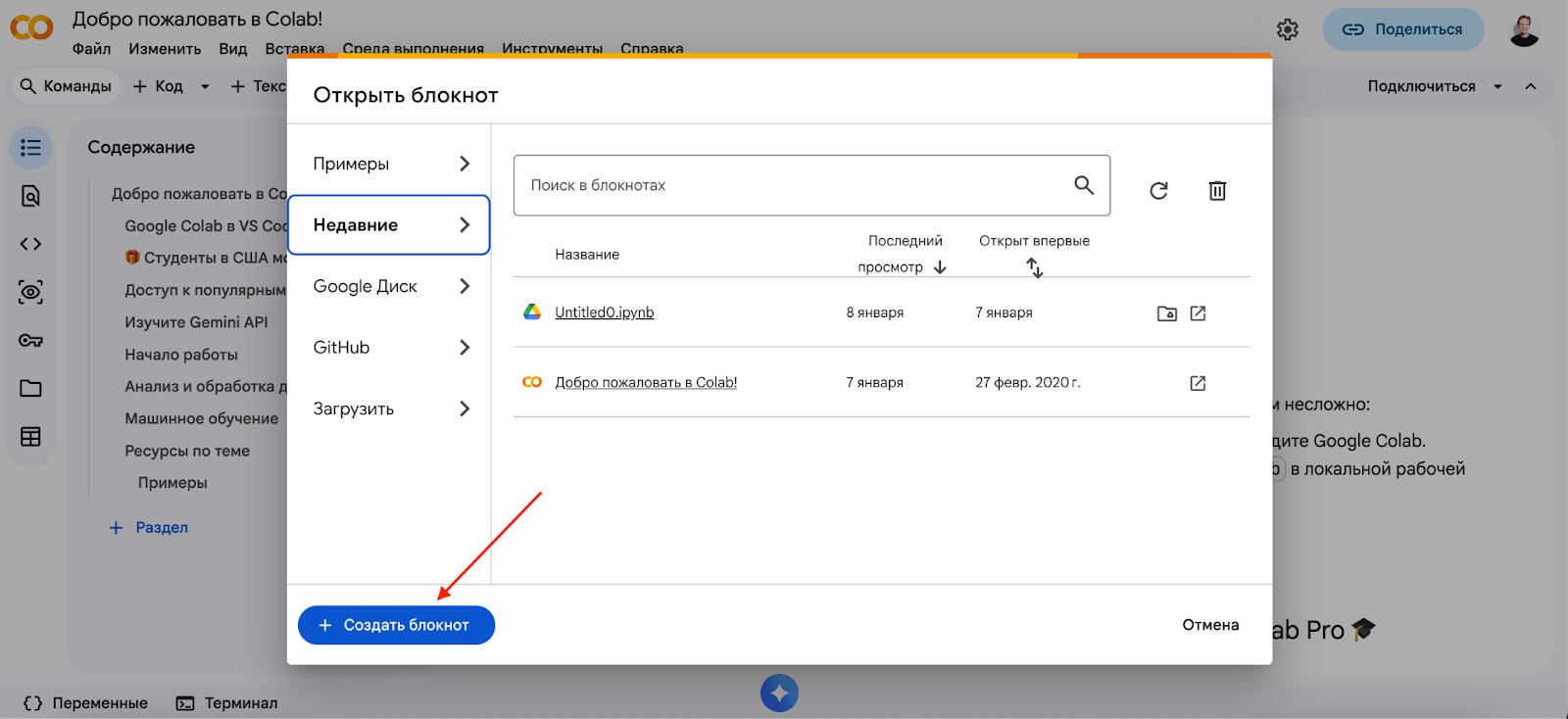
2. Откроется рабочее пространство. Если вы работали с Jupyter Notebook, то всё будет сразу понятно. Если нет, то принцип прост:
- Весь код пишется в ячейках.
- Чтобы выполнить код, нужно нажать на значок ▶ слева от ячейки или нажать Shift + Enter.
- Результат выполнения появляется сразу под ячейкой.
Пишем код и сразу запускаем:

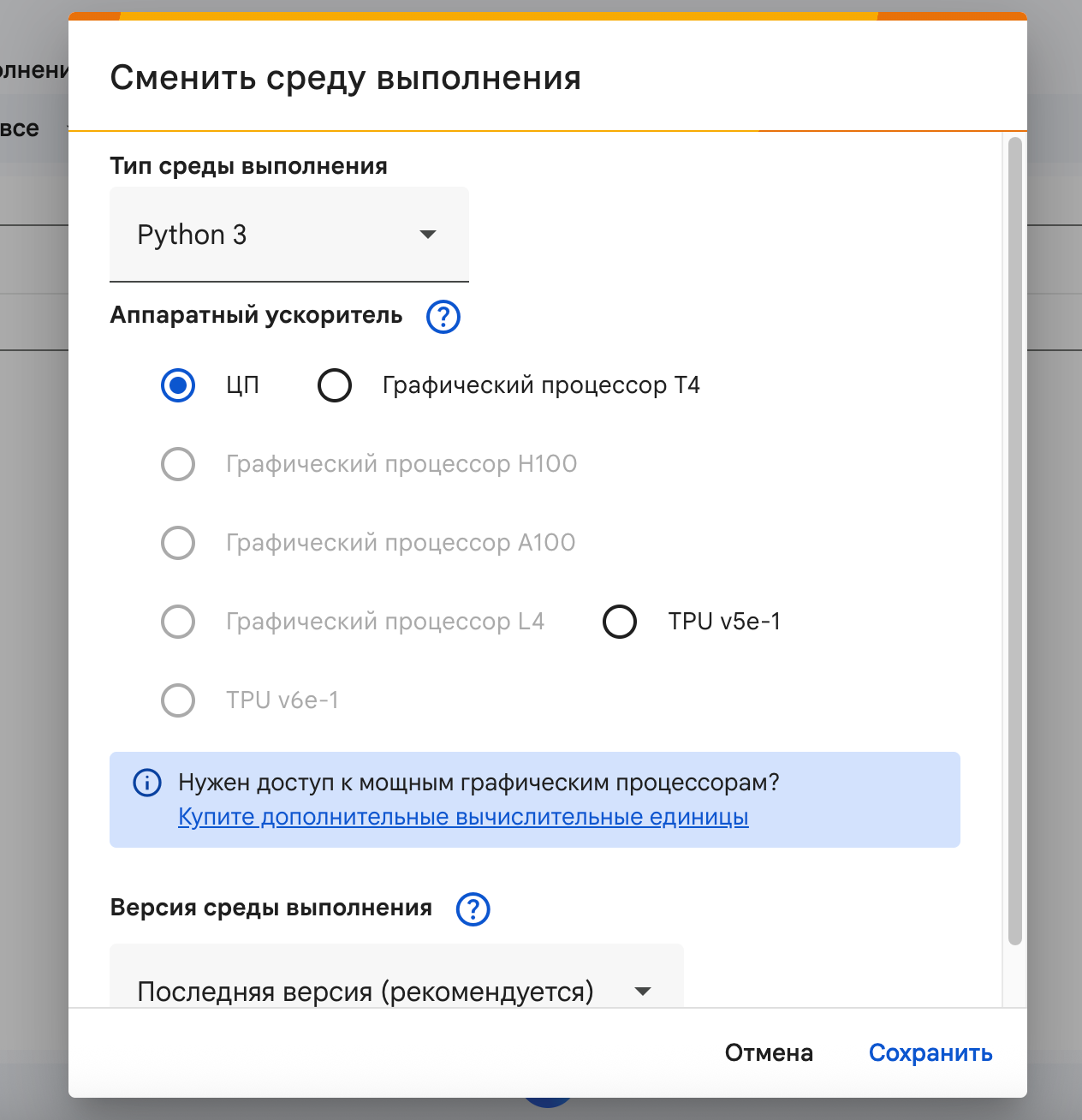
3. Теперь важный момент: включаем ускорение. По умолчанию Google даёт нам обычный процессор, но нейросети любят видеокарты, поэтому нам нужно получить мощное железо:
- В верхнем меню выберите: Среда выполнения → Сменить среду выполнения.
- В выпадающем списке «Аппаратный ускоритель» выберите T4 GPU.
- Нажмите «Сохранить».
После этого в правом нижнем углу появится текущая среда выполнения:
Теперь у вас в распоряжении сервер с видеокартой, который справится с обучением в разы быстрее любого ноутбука.
Постановка задачи и подготовка данных
Итак, наша цель — бинарная классификация текста. Нейросеть должна прочитать комментарий и выдать вердикт: токсичный спам (1) или нормальное сообщение (0).
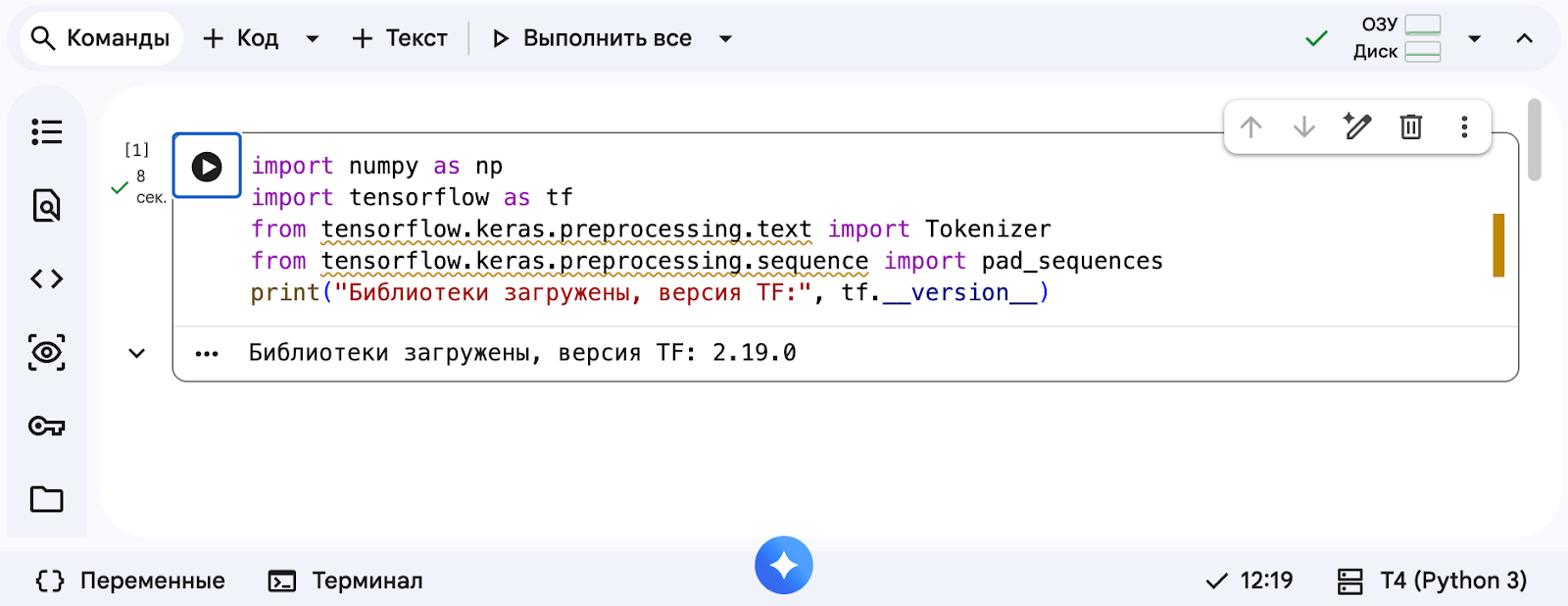
Сначала подключим инструменты и импортируем нужные библиотеки. Создадим новую ячейку, добавим туда этот код и сразу его запустим:
import numpy as np
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
print("Библиотеки загружены, версия TF:", tf.__version__)Когда всё будет готово, в консоли появится сообщение:
Дальше мы подготовим данные, на которых нейросеть будет учиться. Для этого проекта мы создадим данные вручную, прямо внутри кода. В Python для этого используются списки — конструкция в квадратных скобках []. Если вы хотите освежить знания по синтаксису, почитайте нашу статью «Списки (массивы) Python», но для понимания сути это не обязательно.
Создайте новую ячейку и вставьте этот код:
# Создаём список фраз
sentences = [
# --- ПОЗИТИВ (метка 0) ---
'Ты лучший, спасибо за видео',
'Отличный контент, лайк',
'Очень полезная статья, жду ещё',
'Автор молодец, всё понятно',
'Спасибо огромное, ты молодец',
'Статья супер, лайк',
'Огромное спасибо, класс',
'Ты просто супер',
# --- НЕГАТИВ (метка 1) ---
'Ты дурак, и видео твоё глупое',
'Ужасный контент, отписка',
'Автор идиот, ничего не знает',
'Глупость какая-то, дизлайк',
'Ты полный идиот',
'Глупый автор, отписываюсь',
'Какой же ты идиот',
'Ужас, просто кошмар'
]
# Создаём список правильных ответов, где 0 — это "добро", 1 — это "зло"
# Порядок цифр строго соответствует порядку фраз выше!
labels = np.array([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1])Запускаем код — никакого вывода в ячейке не должно быть.
Конечно, в продакшене никто не вбивает миллион комментариев вручную в код. Дата-сайентисты загружают готовые файлы, обычно формата CSV или Excel. Если бы мы делали «взрослый» проект, этот шаг выглядел бы так:
# Этот код просто для примера
import pandas as pd
# Загружаем таблицу из файла
data = pd.read_csv('toxic_comments.csv')
# Берём колонки с текстом и метками
sentences = data['comment_text'].tolist()
labels = data['is_toxic'].valuesНо так как у нас нет файла, мы работаем с нашим ручным списком sentences. Результат будет тот же.
Нейросеть не умеет читать буквы, ей нужна математика. Поэтому следующий шаг — токенизация. Мы скормим наши фразы специальному инструменту Tokenizer, который составит из них словарь и выдаст каждому слову уникальный ID-номер.
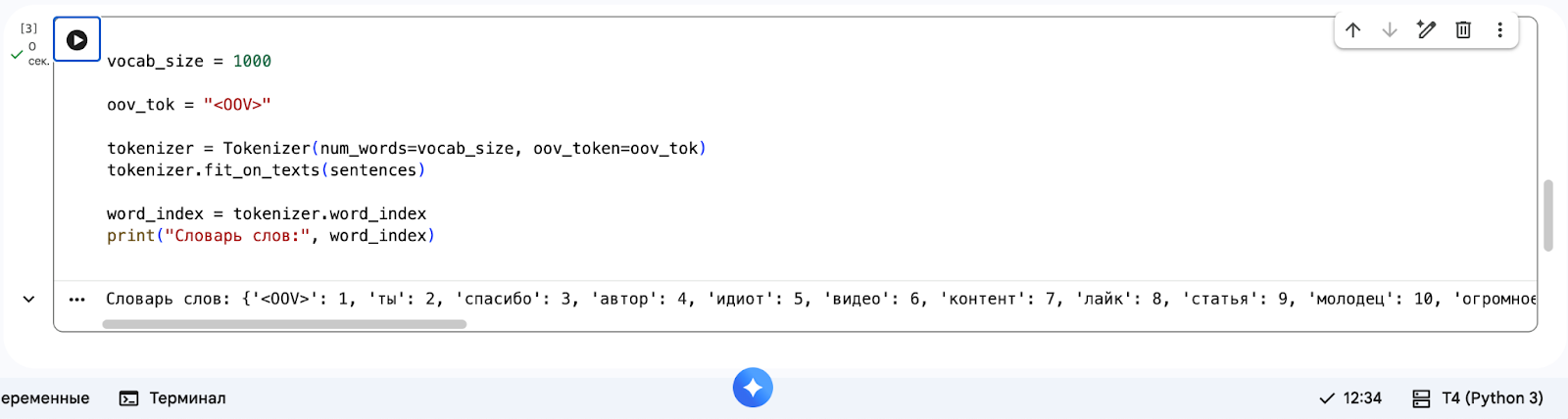
Создаём новую ячейку и добавляем в неё этот код:
# Сколько самых популярных слов запомнить
vocab_size = 1000
# Метка для незнакомых слов (Out Of Vocabulary)
oov_tok = "<OOV>"
# Обучаем токенайзер на наших фразах
tokenizer = Tokenizer(num_words=vocab_size, oov_token=oov_tok)
tokenizer.fit_on_texts(sentences)
# Смотрим, какой словарь у нас получился
word_index = tokenizer.word_index
print("Словарь слов:", word_index)В выводе увидим словарь: чем чаще слово встречалось в наших фразах, тем меньший номер оно получило.
Метка <OOV> — это наша страховка. Если в будущем нейросеть встретит слово, которого не было в обучении (например, «синхрофазотрон»), она не сломается, а просто заменит его на метку <OOV> (типа «какое-то неизвестное слово»). Без этого параметра скрипт бы вылетел с ошибкой.
Теперь заменим слова в предложениях на их номера. Но есть проблема: фразы имеют разную длину, а нейросеть требует, чтобы на входе все данные были одинакового размера, как кирпичики.
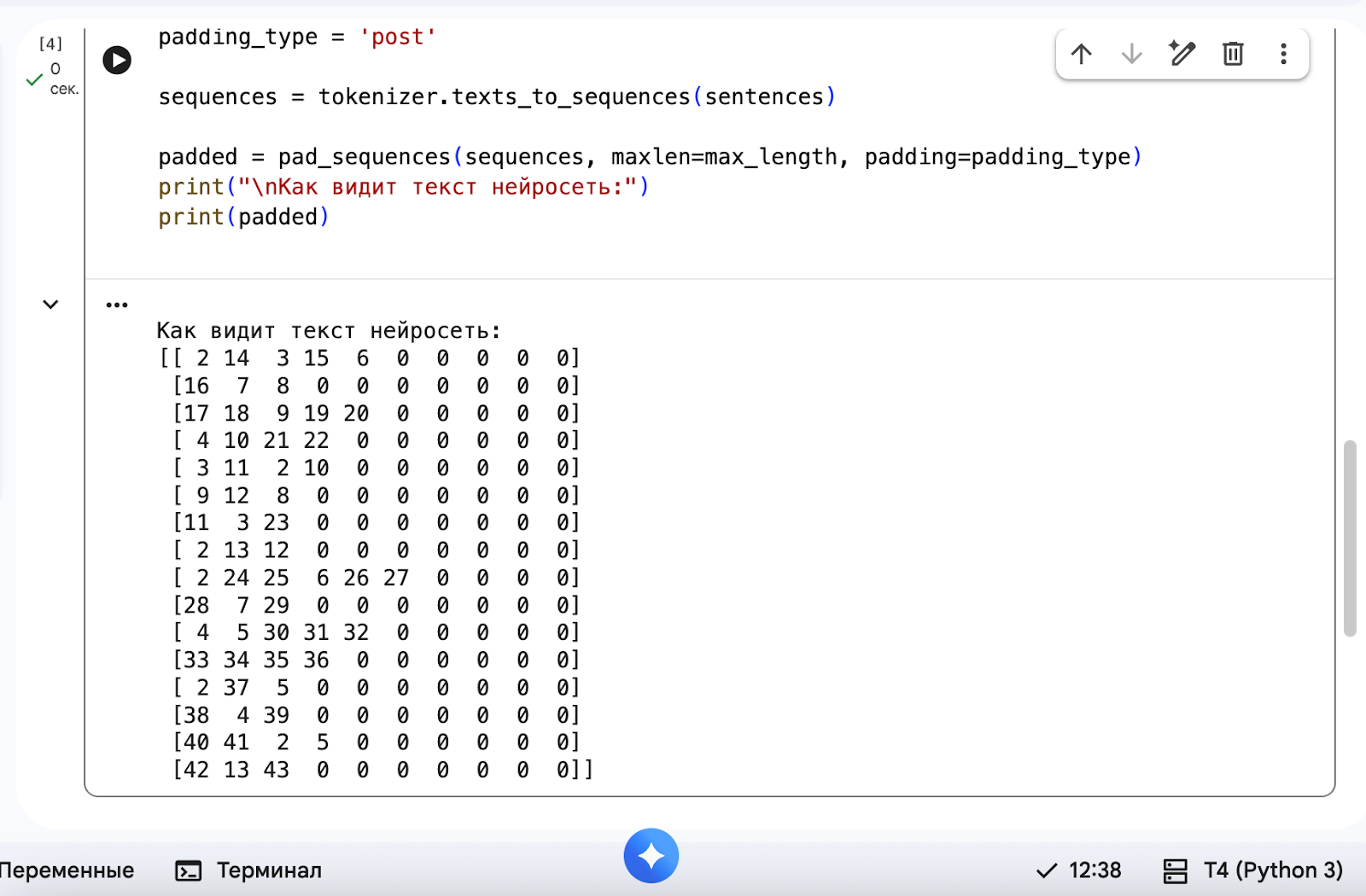
Для этого используем pad_sequences — эта функция добавит нули к коротким фразам, чтобы выровнять их длину:
# Ограничиваем длину фразы 10 словами
max_length = 10
# Добавлять нули в конце фразы
padding_type = 'post'
# Превращаем текст в списки цифр
sequences = tokenizer.texts_to_sequences(sentences)
# Выравниваем длину
padded = pad_sequences(sequences, maxlen=max_length, padding=padding_type)
print("\nКак видит текст нейросеть:")
print(padded)В консоли вы увидите матрицу, где короткие фразы дополнены нулями справа:
Всё, наши данные готовы! Мы превратили человеческую речь в матрицы чисел, которые понятны машине. Теперь можно строить «мозг» — разработать архитектуру.
Разработка архитектуры и инициализация весов
Для нашей задачи по работе с текстом мы используем классический для старта набор:
- Embedding превращает цифры в векторы смыслов.
- Pooling усредняет данные, выделяя главную суть предложения.
- Dense — обычные нейроны, которые принимают финальное решение.
В библиотеке Keras это делается очень просто — мы буквально собираем нейросеть слой за слоем, как конструктор.
Создаем новую ячейку в Colab и пишем код архитектуры:
model = tf.keras.Sequential([
# Эмбеддинг
tf.keras.layers.Embedding(vocab_size, 16),
# Слой пулинга
tf.keras.layers.GlobalAveragePooling1D(),
# Скрытый слой
tf.keras.layers.Dense(24, activation='relu'),
# Выходной слой
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.build(input_shape=(None, max_length))
# Выводим сводку нашей модели, чтобы проверить, что всё собралось
model.summary()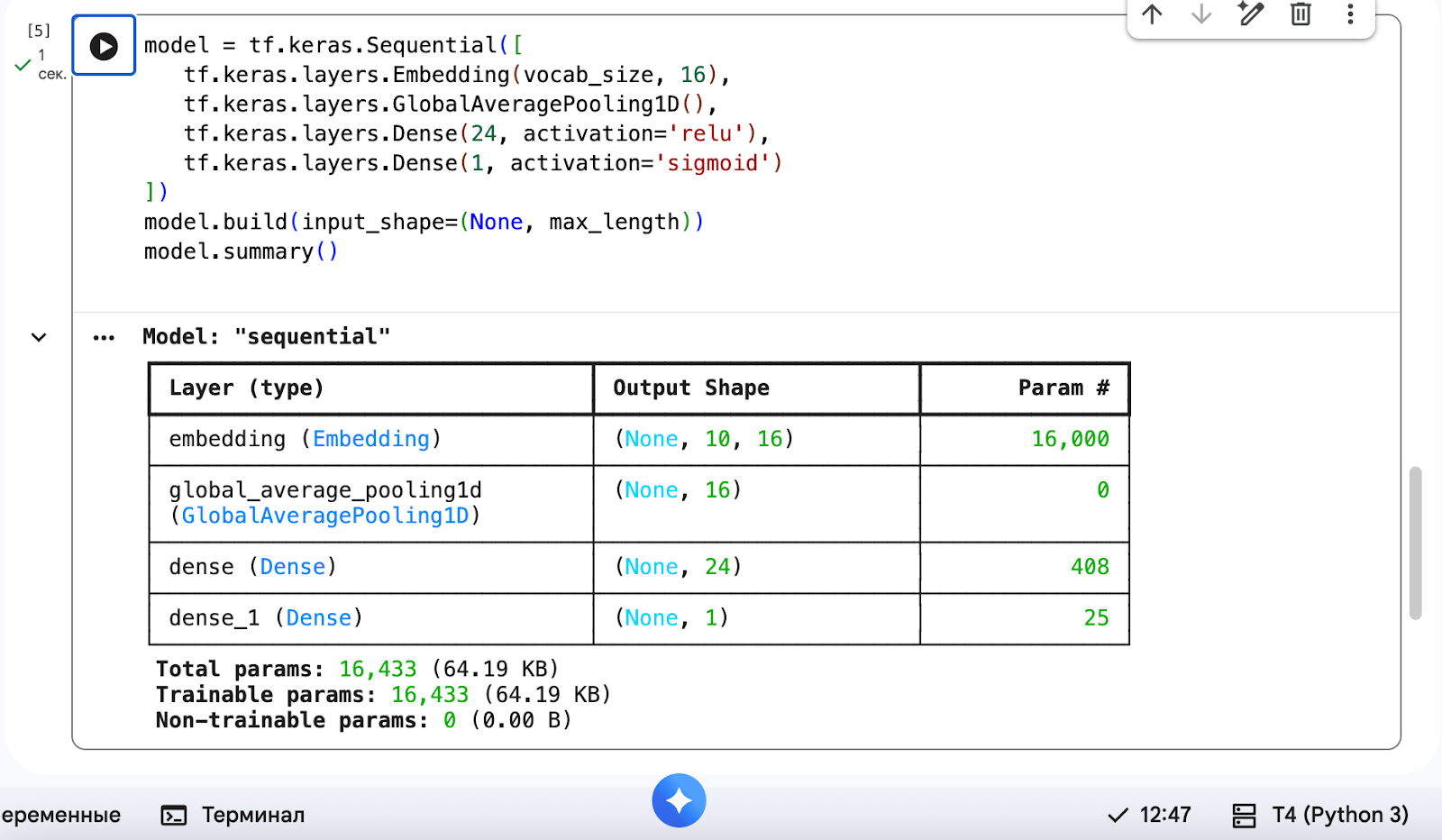
Многие новички спрашивают: «А где мы прописываем значения весов для нейронов?» В этом-то и прелесть современных библиотек — Keras делает это за нас автоматически в момент создания слоя. Он присваивает каждому нейрону крошечные случайные числа — рандомный шум.
А почему не нули? Если начать с нулей, нейросеть не сможет учиться, сигнал просто застрянет. Поэтому мы стартуем со случайных значений, а в процессе обучения сеть сама подкручивает эти числа до идеальных значений.
Теперь разберём сводную таблицу нашей сети:
Output Shape(форма выхода): мы везде видим словоNone. Это не ошибка, это размер батча — пачки данных. Нейросети всё равно, сколько комментариев вы ей скормите за раз — один или сто.Param(количество параметров): это и есть те самые веса, которые нужно обучить.
Слои:
Embedding (16 000)— это наш словарь (1000 слов × 16 координат).Pooling (0)— этот слой ничего не запоминает, он работает как калькулятор — просто считает среднее арифметическое.Dense— нейроны, принимающие решения.
У нашего «ИИ-малыша» всего 16 433 параметра. Для сравнения: у GPT-4 их триллионы. Но для задачи «отличить хейтера от фаната» этого хватит с головой.
Обучение модели
Теперь наступает самый важный момент — мы будем оживлять нашу конструкцию. Сначала выберем методы и инструменты, а потом запустим обучение.
Методы обучения и алгоритмы оптимизации
Мы собрали тело нейросети из слоёв, но пока это просто куча цифр. Чтобы она начала умнеть, ей нужно задать правила игры. В Keras это делается методом .compile().
Создаём новую ячейку и пишем конфигурацию:
model.compile(
# Функция потерь
loss='binary_crossentropy',
# Оптимизатор
optimizer='adam',
# Метрика успеха
metrics=['accuracy']
)Звучит сложно, но сейчас разберёмся, потому что это база для любой нейросети:
- Функция потерь — это «кнут». Нейросеть делает прогноз, а функция потерь сравнивает его с правильным ответом. Если сеть ошиблась, функция начисляет штраф (
loss). Здесь мы выбрали параметрBinary, поскольку у нас задача «или — или» (токсично/нетоксично). Если бы мы классифицировали 10 видов животных, то использовали быcategorical_crossentropy. - Оптимизатор — это «тренер». Он смотрит на штраф от функции потерь и решает, какие именно веса и в какую сторону подкрутить, чтобы в следующий раз ошибка стала меньше. Adam — это золотой стандарт индустрии. Он умный: в начале обучения делает большие шаги к цели, а в конце — маленькие и аккуратные, чтобы найти идеальный баланс.
- Метрика.
Loss— это непонятные дроби для робота. Людям же нужно что-то понятное.Accuracy(точность) показывает простой процент: 0.95 значит, что сеть права в 95% случаев.
Мы всё подготовили и теперь начнём обучать нашу нейросеть.
Запуск обучения
Теперь самое интересное! Мы запускаем метод .fit() — это аналог кнопки «Старт» на конвейере. Нейросеть начнёт брать наши комментарии из списка, пытаться угадать, получать правильный ответ, корректировать себя и пробовать снова.
Попытка № 1: стандартный подход. Обычно в туториалах ставят значение в 10–20 эпох, то есть количество повторений. Попробуем сделать так же.
Создаём новую ячейку:
# Запускаем обучение на 10 эпох
history = model.fit(
padded, # Наши цифровые тексты (X)
labels, # Правильные ответы (Y)
epochs=10, # Сколько раз прогнать весь учебник
verbose=1 # Показывать прогресс-бар
)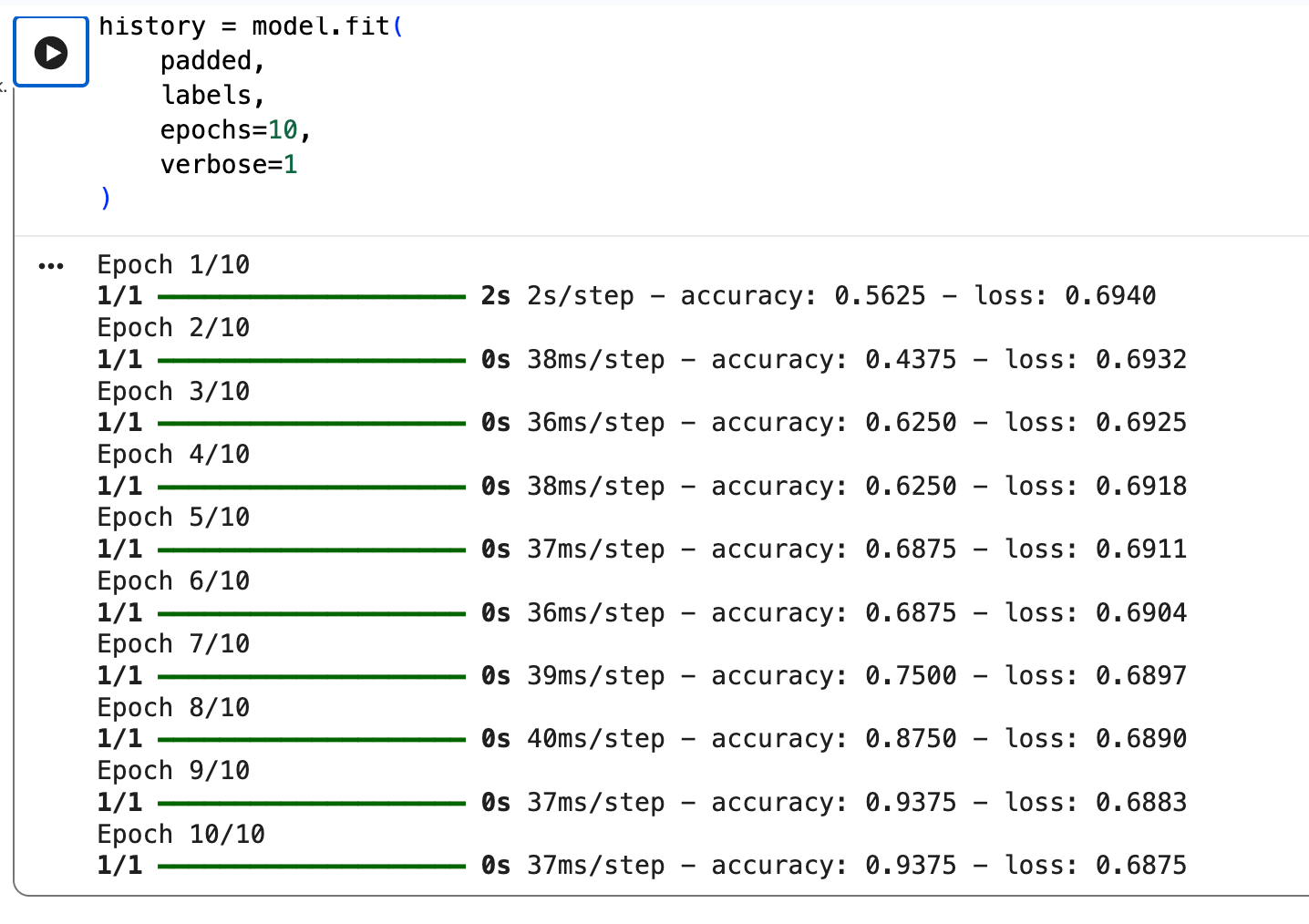
Вы увидите, как побегут строчки Epoch 1/10, Epoch 2/10. Смотрите на параметры: loss: должен падать — ошибка уменьшается, а accuracy должна расти — точность увеличивается.
Смотрим на финальные цифры:
- accuracy: 0.93.
- loss: довольно высокий — 0.68.
Это значит, что нейросеть «недопоняла». Она вроде бы уловила суть, но всё ещё сомневается, а нам здесь нужна железобетонная уверенность.
Попытка № 2: режим «Зубрила». У нас микроскопический датасет — всего 16 фраз, и нейросети просто не хватает времени, чтобы сдвинуть свои веса от стартовых случайных значений к идеальным. Ей нужно больше повторений.
Давайте заставим её вызубрить эти фразы наизусть. Меняем 10 эпох на 500:
# Ставим 500 эпох и убираем вывод логов (verbose=0), чтобы не засорять экран
history = model.fit(
padded,
labels,
epochs=500,
verbose=0
)
# Проверим финальный результат
print("Финальная точность:", history.history['accuracy'][-1])
print("Финальная ошибка:", history.history['loss'][-1])Запускаем:

Точность: 1.0, Ошибка: 0.0056… Ура! Теперь нейросеть знает эти фразы лучше, чем таблицу умножения.
Почему 500 эпох — это и нормально, и ненормально? Тут кроется парадокс глубокого обучения:
- Маленькие данные: мы вынуждены прогонять их 500 раз, чтобы вдолбить веса в крайние значения. Это как учить четверостишие: повторяешь 500 раз, пока не будет отскакивать от зубов.
- Биг-дата (GPT-4, Llama): серьёзные LLM учатся на терабайтах данных, по сути это весь интернет. Если прогнать весь интернет через видеокарты 500 раз, Солнце успеет погаснуть. Поэтому большие модели учатся обычно всего одну эпоху. Им хватает одного прочтения, чтобы понять закономерности языка, потому что примеров миллиарды.
Мы намеренно переобучили нашу сеть. В разделе «Ошибки» мы разберём, почему в продакшене так делать опасно.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.
Тестирование и оптимизация нейросети
Наша модель показала 100% точности на тренировке. Но это не значит, что она стала гением, — она просто вызубрила наши фразы из тренировочного набора. Теперь проверим, поняла ли модель суть токсичности, и подсунем ей совершенно новые комментарии.
Оценка качества работы
Главное правило: новые данные нужно обработать точно так же, как и тренировочные, то есть мы обязаны использовать тот же самый токенайзер. Если мы создадим новый, то слово «молодец» может получить другой номер и нейросеть запутается.
Пишем код тестирования в новой ячейке:
# Новые фразы, которые сеть не видела
test_sentences = [
'Огонь! Ты молодец',
'Ты полный нуб и контент твой ерунда',
'Статья супер, подписка!',
'Дизлайк, отписка!'
]
# Превращаем текст в цифры, используем тот же tokenizer
test_sequences = tokenizer.texts_to_sequences(test_sentences)
# Выравниваем длину
test_padded = pad_sequences(test_sequences, maxlen=max_length, padding=padding_type)
# Предсказываем
predictions = model.predict(test_padded)
# Выводим результат
for i in range(len(test_sentences)):
# Округляем до 4 знаков
score = predictions[i][0]
print(f"Фраза: '{test_sentences[i]}'")
print(f"Токсичность: {score:.4f} ({'ЗЛО 😡' if score > 0.5 else 'ДОБРО 😊'})\n")Запускаем и смотрим, что получилось:
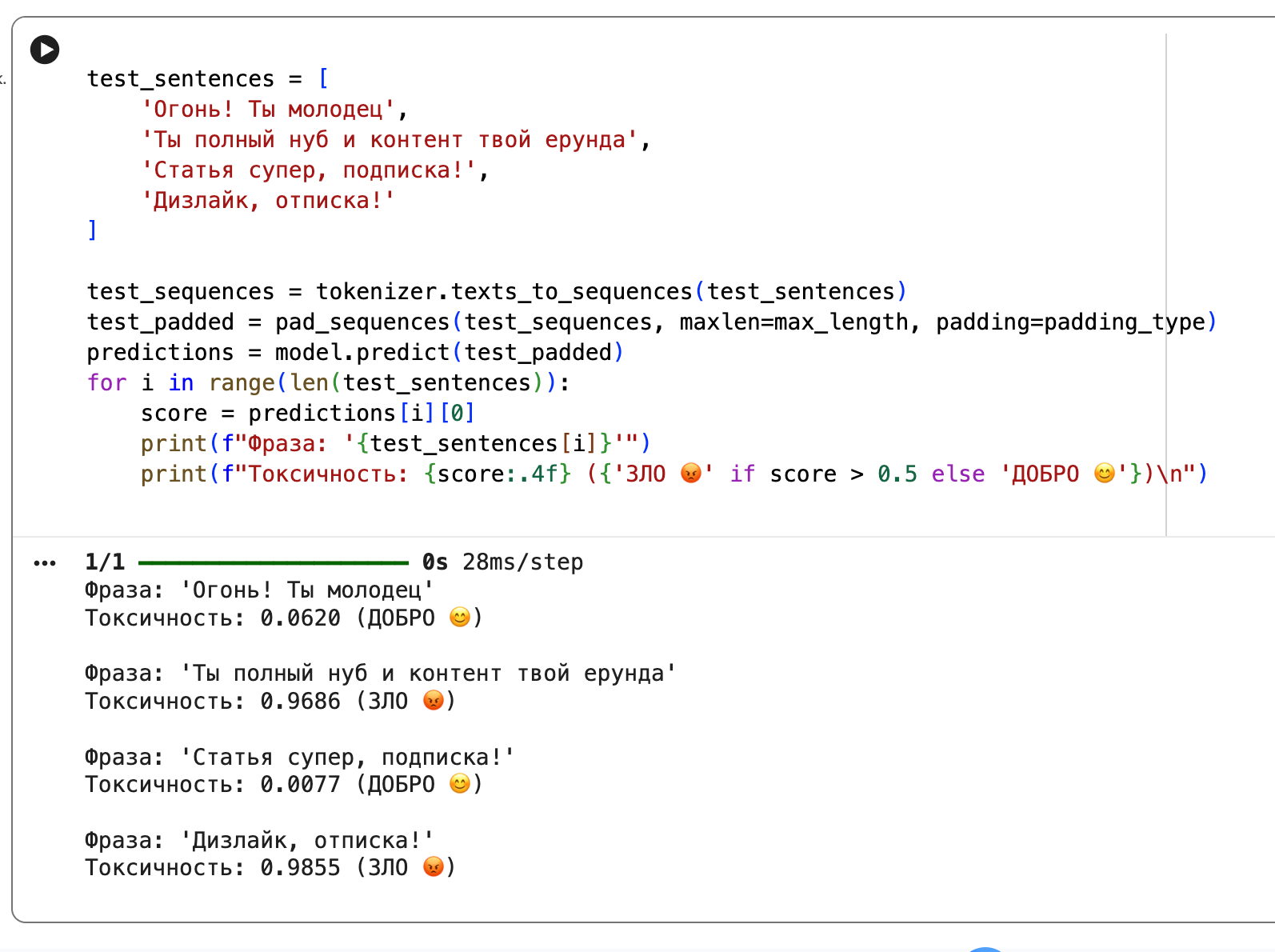
Значения 0.9 и 0.06… означают железобетонную уверенность, то есть нейросеть не просто угадала, она поняла паттерн.
Смотрите: слов «нуб» и «ерунда» не было в обучении. Нейросеть проигнорировала незнакомые слова: для неё «нуб» — это пустое место, <OOV>, но она увидела знакомое окружение. Во фразе ‘Ты полный нуб’ она зацепилась за ‘Ты полный…’, поскольку в обучении была фраза ‘Ты полный идиот’. То есть сеть выучила паттерн: «Если предложение начинается с “Ты полный…”, то дальше обычно идёт какая-то гадость». Именно поэтому она поставила 0.96. Она оценила контекст, а не просто искала знакомые ругательства.
И это главное отличие нейросети от обычного фильтра по словам.
Интерактивная проверка: общаемся с нейросетью
Каждый раз редактировать список test_sentences в коде, чтобы проверить новую фразу, — это неудобно. Поэтому напишем простейший цикл, который превратит наш скрипт в чат-бота. Вы вводите текст в поле, нажимаете Enter, а нейросеть мгновенно выносит вердикт.
Создайте новую ячейку и добавьте этот код:
import numpy as np
print("Напишите комментарий для проверки (или 'exit' чтобы выйти):")
while True:
# Запрашиваем ввод от пользователя
user_text = input("Ваш текст >> ")
# Если ввели 'exit', останавливаем цикл
if user_text.lower() == 'exit':
print("Проверка завершена.")
break
# Токенизация и паддинг — то же самое, что мы делали раньше
# Подаём текст в виде списка [user_text]
new_sequence = tokenizer.texts_to_sequences([user_text])
new_padded = pad_sequences(new_sequence, maxlen=max_length, padding=padding_type)
# Предсказание
prediction = model.predict(new_padded)
score = prediction[0][0]
# Вывод результата
if score > 0.5:
print(f"😡 ТОКСИЧНО! (Уверенность: {score:.4f})")
else:
print(f"😊 ДОБРО! (Уверенность: {score:.4f})")
print("-" * 30)После запуска ячейки у вас появится поле для ввода. Пишите туда всё, что приходит в голову. Нейросеть будет отвечать до тех пор, пока вы не напишете слово exit.
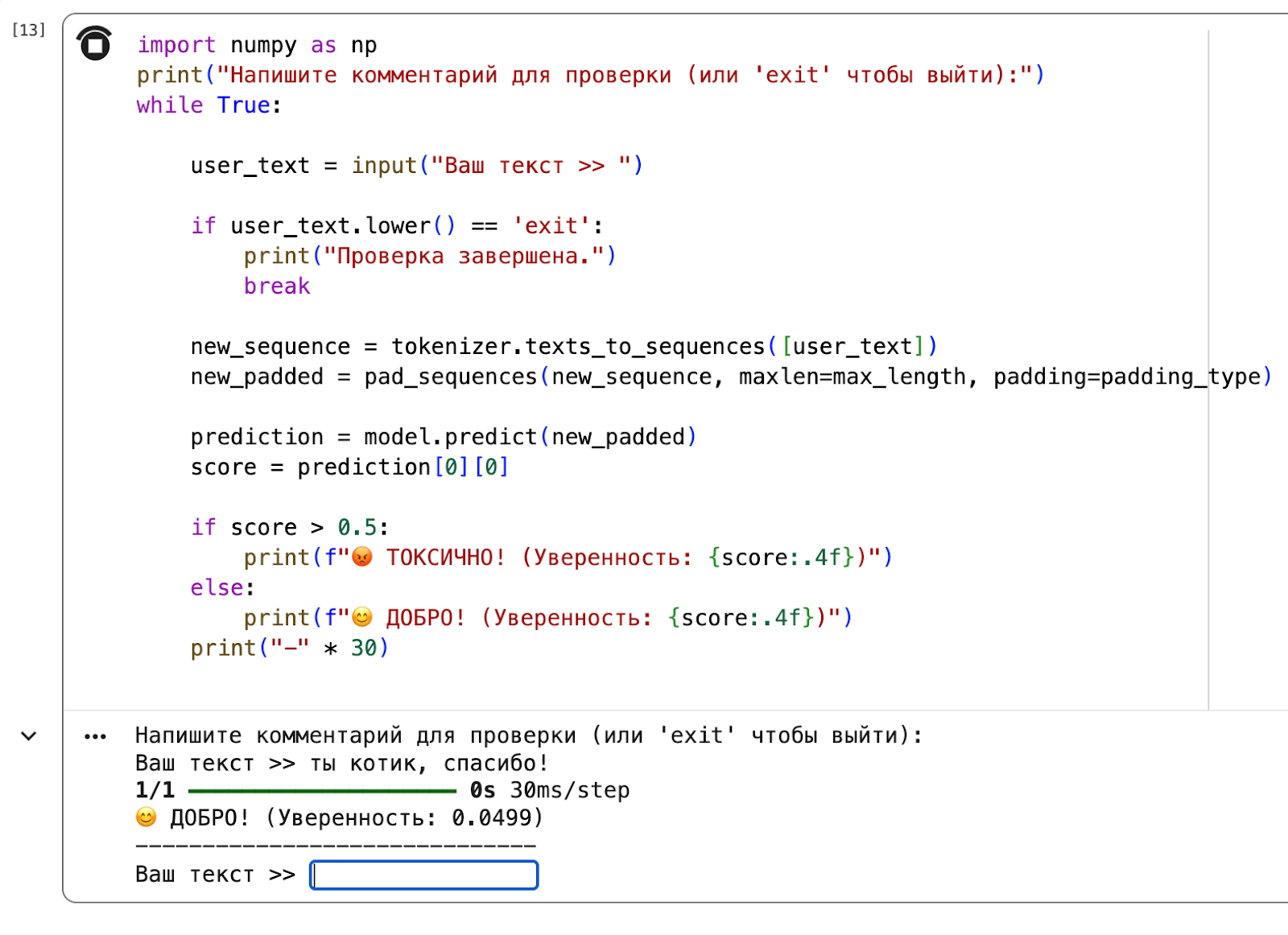
Это отличный способ найти слабые места своей модели и понять, какие слова она выучила хорошо, а какие нет.
Развёртывание и интеграция с другими системами
Сейчас наша нейросеть живёт в памяти Google Colab, и пользоваться ей можно только в этой вкладке. Чтобы превратить её в полезный продукт, нужно пройти этап деплоя.
1. Экспорт. Важный момент: нам нужно сохранить не только саму модель, но и токенайзер — наш словарь. Нейросеть помнит числа, а токенайзер помнит, какое слово какому числу соответствует. Без него модель бесполезна, как книга на зашифрованном языке без ключа.
Создаём финальную ячейку для сохранения всего необходимого:
import pickle
# Сохраняем саму модель (веса и архитектура)
model.save('toxic_filter_model.keras')
# Сохраняем токенайзер
with open('tokenizer.pickle', 'wb') as handle:
pickle.dump(tokenizer, handle, protocol=pickle.HIGHEST_PROTOCOL)
print("Всё сохранено! Скачайте два файла из папки слева.")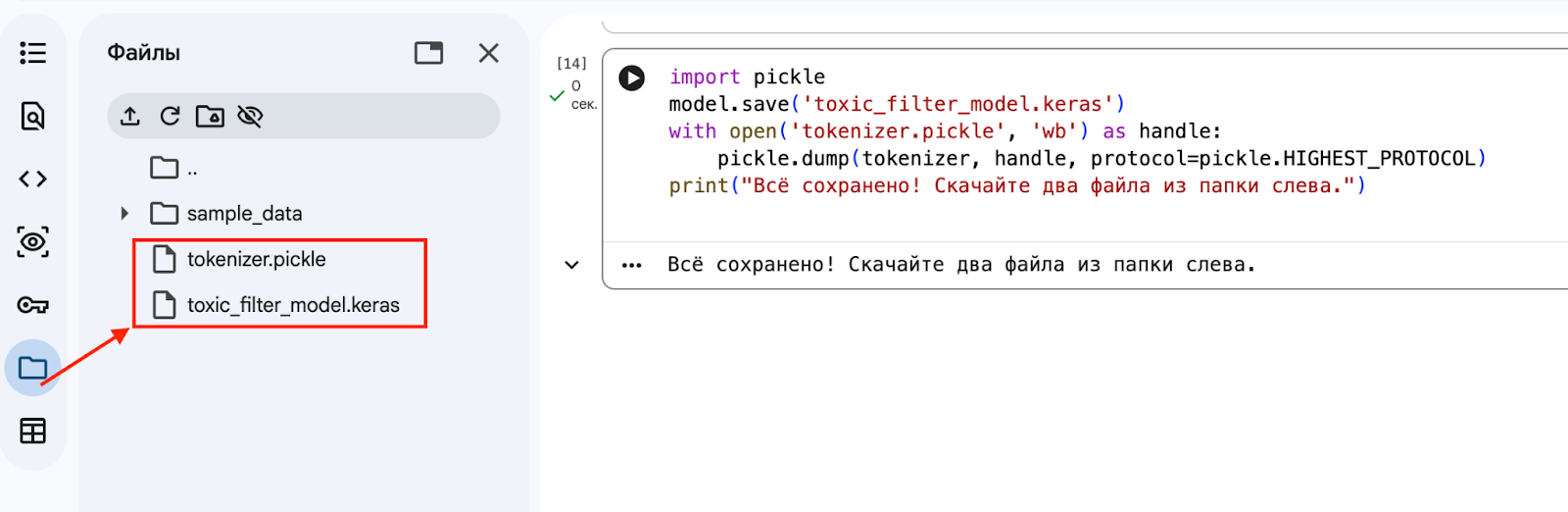
Чтобы использовать это в реальной жизни, вам нужно скачать оба файла .keras и .pickle и перенести их на другой компьютер. Там вам не нужны ни датасеты, ни тренировка на 500 эпох.
2. Интеграция в python-скрипт. Теперь представим, что вы пишете телеграм-бота на своём компьютере. Вам не нужно заново обучать сеть. Вы кладёте эти два файла рядом со скриптом бота и пишете такой код:
import tensorflow as tf
import pickle
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Загружаем модель
model = tf.keras.models.load_model('toxic_filter_model.keras')
# Загружаем токенайзер
with open('tokenizer.pickle', 'rb') as handle:
loaded_tokenizer = pickle.load(handle)
# Теперь можно проверять сообщения (используем loaded_tokenizer)
# ... логика...3. Микросервисы и API. В серьёзных проектах нейросеть обычно оборачивают в веб-сервер, например на FastAPI или Flask. Работает это так:
- Сайт отправляет комментарий на сервер: POST /check-comment.
- Сервер запускает нейросеть, прогоняет текст.
- Сервер возвращает ответ: {“toxic”: 0.99}.
- Сайт видит ответ и автоматически скрывает комментарий или отправляет его на модерацию.
4. Запуск в браузере. Хорошие новости для фронтендеров: модель Keras можно конвертировать в формат для TensorFlow.js. Тогда нейросеть будет работать прямо в браузере пользователя, даже без интернета. Спам будет фильтроваться ещё до того, как улетит на сервер.
Ищете работу в IT?
Карьерный навигатор Практикума разберёт ваше резюме, проложит маршрут к первому работодателю, подготовит к собеседованиям в 2026 году, а с января начнёт подбирать вакансии именно под вас.
Ошибки при создании нейросетей
В разделе с обучением мы намеренно совершили одно из главных преступлений в Data Science — переобучили (overfitting) свою модель:

В реальной жизни точность 1.000 — это тревожный сигнал. Это значит, что нейросеть не поняла правила языка, а просто вызубрила эти 16 фраз наизусть, как студент перед экзаменом, который не понимает предмет, но запомнил ответы.
В нашем проекте у нас было катастрофически мало данных, поэтому пришлось «вдолбить» их в веса силой, чтобы получить хоть какой-то результат.
А вот профессионалы делают иначе: они используют миллионы примеров, а обучение останавливают, как только сеть начинает просто зубрить — это называется Early Stopping. Также добавляют слои Dropout, которые специально «забывают» часть информации, заставляя сеть думать, а не списывать.
Другая ошибка — это дисбаланс данных. Если в вашем датасете 90% комментариев токсичные, а 10% — добрые, нейросеть станет параноиком. Она быстро поймёт: «Ага, почти всё в этом мире — зло». И начнёт банить всех подряд, даже за слово «Привет». Поэтому данных должно быть поровну. Если у вас перекос, нужно искусственно уравновесить выборку.
Ну и третье: писать свою архитектуру с нуля, как мы сделали сейчас, полезно, чтобы понять механику. Но в продакшене так не делают. В 2026 году инженеры берут готовые предобученные гиганты вроде BERT или RoBERTa, которые уже прочитали весь интернет, и просто слегка донастраивают их под свою задачу. Это экономит месяцы работы.
Примеры проектов и практическое применение
Самое приятное в нашем проекте — мы создали не просто «детектор ругани», а универсальный классификатор. Архитектура Embedding → Dense, которую мы собрали, — простая, надёжная и работает практически с любой текстовой задачей.
Стоит заменить файл с данными и немного поменять метки, как этот же код превратится в совершенно другие продукты.
Вот что можно попробовать сделать в следующем проекте:
Умный сортировщик техподдержки. Возьмите историю обращений пользователей. Если научить сеть отличать фразы «У меня ошибка 404» (категория Tech) от «Где мой возврат денег?» (категория Billing), то получите бота-диспетчера. Он будет мгновенно раскидывать тикеты по отделам, разгружая живых операторов первой линии.
Анализатор отзывов. Загрузите отзывы с любого маркетплейса вместе с оценками. Нейросеть научится понимать настроение покупателя. Такой инструмент может автоматически подсвечивать бизнесу проблемы: например, сигнализировать, что клиенты хвалят качество товара, но массово жалуются на долгую доставку.
Детектор языка. Если в датасете будут фразы на разных языках с соответствующими метками (RU, EN, ES), модель превратится в лингвиста. Она сможет с полуслова определять, на каком языке пишет пользователь, чтобы переключить интерфейс или вызвать нужного оператора.
Что менять в коде?
Почти ничего. Единственное различие: если категорий больше двух, например 5 языков или 3 отдела, в последнем слое (Dense) нужно поставить не 1 нейрон, а 5 (по числу категорий) и сменить активацию на softmax. Весь остальной скелет останется прежним.
Полезные ресурсы и литература
Не начинайте с толстых учебников по высшей математике — это верный способ бросить через неделю. В 2026 году учиться нужно на практике.
Где брать данные и код:
- Kaggle — главная песочница дата-сайентистов. Там миллионы готовых датасетов, от твитов до рентгеновских снимков, и, главное, примеры чужого кода.
- Hugging Face — по сути, это GitHub для нейросетей. Там лежат тысячи готовых обученных моделей, которые можно скачать и запустить одной строчкой (ну или почти одной).
Кого смотреть и читать:
- Andrej Karpathy — легендарный инженер из Tesla и OpenAI. У него есть курс Zero to Hero, где он пишет GPT с нуля — это хардкорно, но даёт глубочайшее понимание.
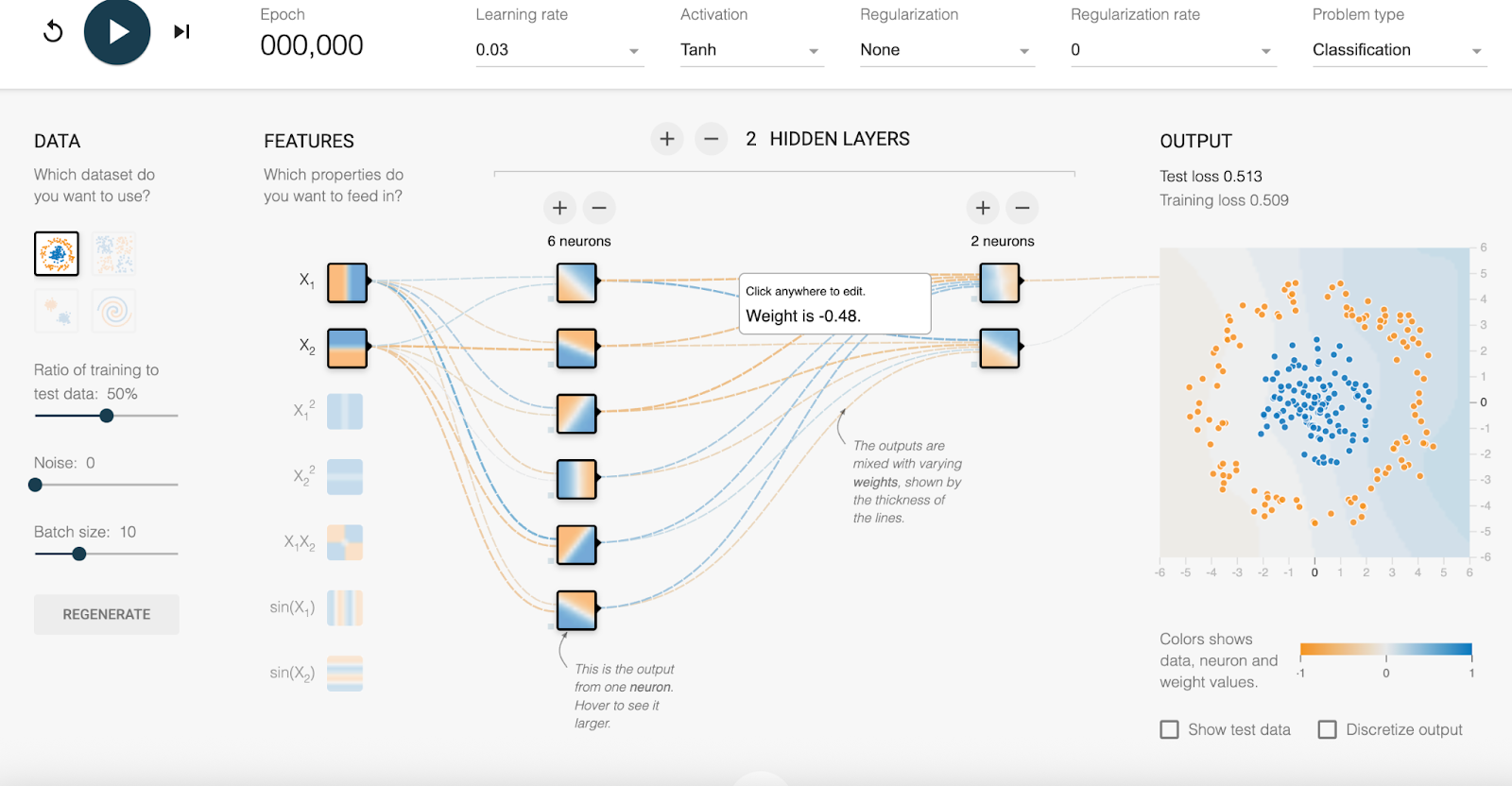
- TensorFlow Playground — интерактивный сайт прямо в браузере, где можно визуально дёргать за ниточки нейросети и смотреть, как она учится. Идеально для понимания, что такое Learning Rate и эпохи.
- Яндекс Практикум — если хочется системности. Там есть большие курсы по Data Science и отдельный трек по нейросетям. Главная фишка — встроенный тренажёр: вы пишете код прямо в браузере (прямо как мы сейчас в Colab), система его проверяет и сразу подсвечивает ошибки. Плюс почти везде есть бесплатная вводная часть — отличный способ понять, готовы ли вы тратить на это жизнь, не заплатив ни рубля.

Современные тенденции в разработке нейросетей
То, что мы сейчас создали, — это классический дискриминационный ИИ, чья задача — отличить А от Б. Но индустрия 2026 года сфокусирована на другом — на генеративном ИИ. Разберёмся, в чём разница и куда двигаться дальше.
Трансферное обучение
Представьте, что вы хотите обучить человека кардиологии. И здесь возможны два варианта:
- Путь с нуля, наш вариант — вы берёте младенца и 20 лет учите его чтению, письму, биологии, анатомии и прочим наукам. Это долго и дорого.
- Трансферное обучени — вы берёте готового врача-терапевта и за полгода переучиваете его на кардиолога.
В роли такого «терапевта» выступают фундаментальные модели BERT, Llama или GPT. Они уже «прочитали» весь интернет и понимают структуру языка, сленг и даже юмор. Вам не нужно учить их английскому или русскому. Вы просто берёте эту махину, показываете ей 100 примеров ваших спам-комментариев, и она моментально улавливает специфику именно вашей задачи. Это называется дообучением (fine tuning).
Генеративные модели
Наша нейросеть умеет только оценивать — ставить балл токсичности, она не умеет отвечать или писать стихи. Главный тренд сейчас большие языковые модели, которые предсказывают следующее слово. Если наша сеть — это судья, который ставит дизлайки, то GPT — это писатель, который может сгенерировать вежливый ответ на токсичный комментарий.
Тенденция 2026 года — объединять эти подходы. Например, одна нейросеть, как наша, находит проблему, а вторая, генеративная, автоматически пишет решение или ответ пользователю.
Заключение
Поздравляем! Вы только что создали свою нейросеть. Да, это пока «малыш», который вызубрил всего 16 фраз, но под капотом у него заложены те же принципы, что и у ChatGPT или Claude: токенизация, эмбеддинги и веса.
Что дальше?
- Зайдите на Kaggle, скачайте CSV-файл с реальными комментариями, например Toxic Comment Classification и загрузите его в свой скрипт вместо ручного списка.
- Попробуйте заменить слой GlobalAveragePooling на LSTM или BiLSTM. Это слои с памятью, они читают текст последовательно и ловят сложный контекст гораздо лучше.
Ну и не бойтесь ошибок. В Data Science ошибка — это просто математический сигнал loss, который говорит, в какую сторону нужно поправить веса.
Вам слово
Приходите к нам в соцсети поделиться своим мнением о статье и почитать, что пишут другие. А ещё там выходит дополнительный контент, которого нет на сайте — шпаргалки, опросы и разная дурка. В общем, вот тележка, вот ВК — велком!