

В прошлый раз мы рассказывали про GIL — встроенный в Python механизм, который не допускает многопоточность, то есть параллельное выполнение множества операций с одними и теми же данными. Это сделали для того, чтобы один поток не мог испортить данные в памяти, с которыми работает другой поток: заменить их на свои, удалить или создать новые, порушив всю структуру. Сегодня разберёмся с тем, как же именно Python это делает и какие приёмы и подходы использует для этого.
Если вы только начинаете программировать на Python, эта статья может показаться вам сложной — и она действительно такая. Но если вы уже немного умеете писать код на Python и хотите разобраться, как именно компьютер работает с данными в памяти, — статья будет точно полезной.
Коротко про потоки и программы
Перед тем как начать, напомним, что происходит при запуске любой программы на компьютере.
- Каждая запущенная на компьютере программа создаёт как минимум один процесс — экземпляр этой программы, который выполняется отдельно и использует выделенные специально для него ресурсы процессора, например процессорное время, память и кэш.
- Процессы работают независимо друг от друга. Если один процесс выходит из строя или завершает свою работу, это не отражается на других процессах, потому что каждый использует какой-то свой, изолированный ресурс компьютера.
- Сами процессы делятся на потоки — части программы, каждая из которых отвечает за что-то своё (или за общее, просто работают параллельно). Потоки делят между собой одни и те же ресурсы, выделенные на один процесс. Сбой в работе одного потока сразу повлияет на работу всего процесса. Сломался один поток — сломался весь процесс.
Получается такое деление: программа → процессы → потоки.
Например, программа при запуске создаёт три процесса, которые вместе выполняют всю работу программы. Первый процесс для работы запускает три потока, второй — шесть, а третий — пятнадцать. Получается, что мы запустили всего одну программу, а для её работы компьютер создал 24 потока, которые могут работать параллельно.
Если больше одного потока начнут одновременно работать с памятью, то общая система управления памяти может сломаться: потоки начнут работать с чужими данными как со своими и будет много ошибок (или программа вообще зависнет или закроется с ошибкой).
Чтобы такого не случалось, Python использует три механизма работы с памятью:
- подсчёт ссылок;
- сборщик мусора;
- менеджер памяти.
Про эти три механизма мы и будем сегодня говорить.
Подсчёт ссылок
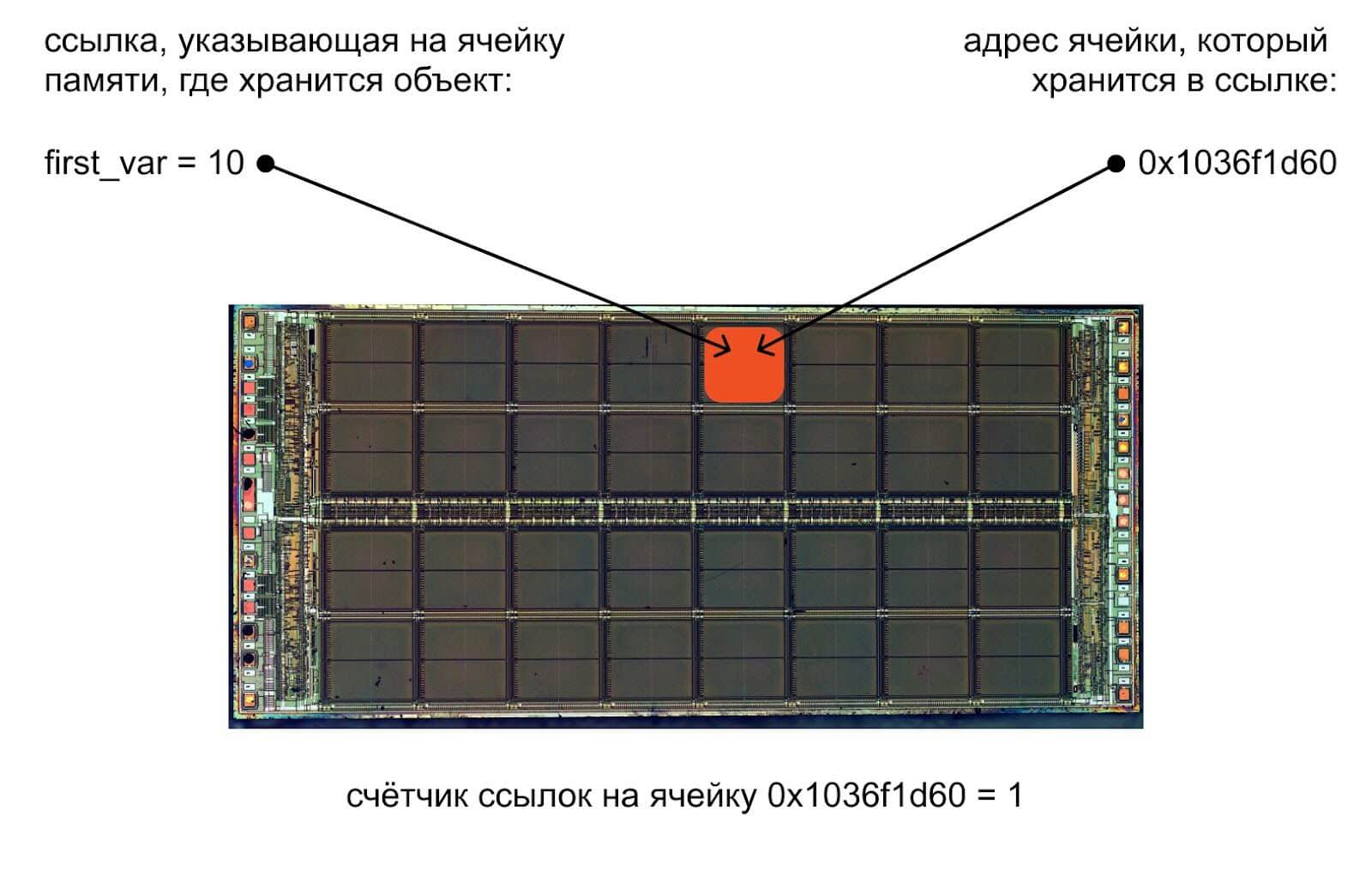
В Python все части кода являются объектами: переменные, строки, функции, коллекции. Например, мы создали переменную first_var со значением 10:
first_var = 10
При запуске кода Python посмотрит на данные, которые мы хотим поместить в переменную, и прикинет, какой тип данных для этого минимально подходит. Минимально — чтобы не создавать повышенный расход памяти. Если число помещается в самый простой целочисленный тип int — значит, выберет его. После этого Python выделит память под эти данные, запишет их туда и запомнит адрес ячейки памяти, где они хранятся.
Получается, что число 10 будет храниться не в переменной, а в какой-то ячейке памяти, а переменная будет служить ссылкой, то есть указателем, на ячейку с объектом. Когда мы захотим узнать значение этой переменной, компьютер по имени переменной найдёт у себя адрес нужной ячейки памяти, прочитает данные оттуда, переведёт их в нужный формат и после этого покажет пользователю.
Схематично это можно нарисовать так: мы взяли переменную и положили туда число 10, но на самом деле компьютер записал это число в ячейку памяти и запомнил, что эта переменная связана с адресом этой ячейки.
Как только объект создан, Python начинает отслеживать количество ссылок-указателей на него. Одна переменная — одна ссылка. Если мы создадим вторую переменную и укажем, что она равна первой, увеличится не количество объектов, а количество ссылок:
second_var = first_var
После этой строки у нас будет число 10, которое хранится по тому же адресу. Только теперь к нему привязано две ссылки:
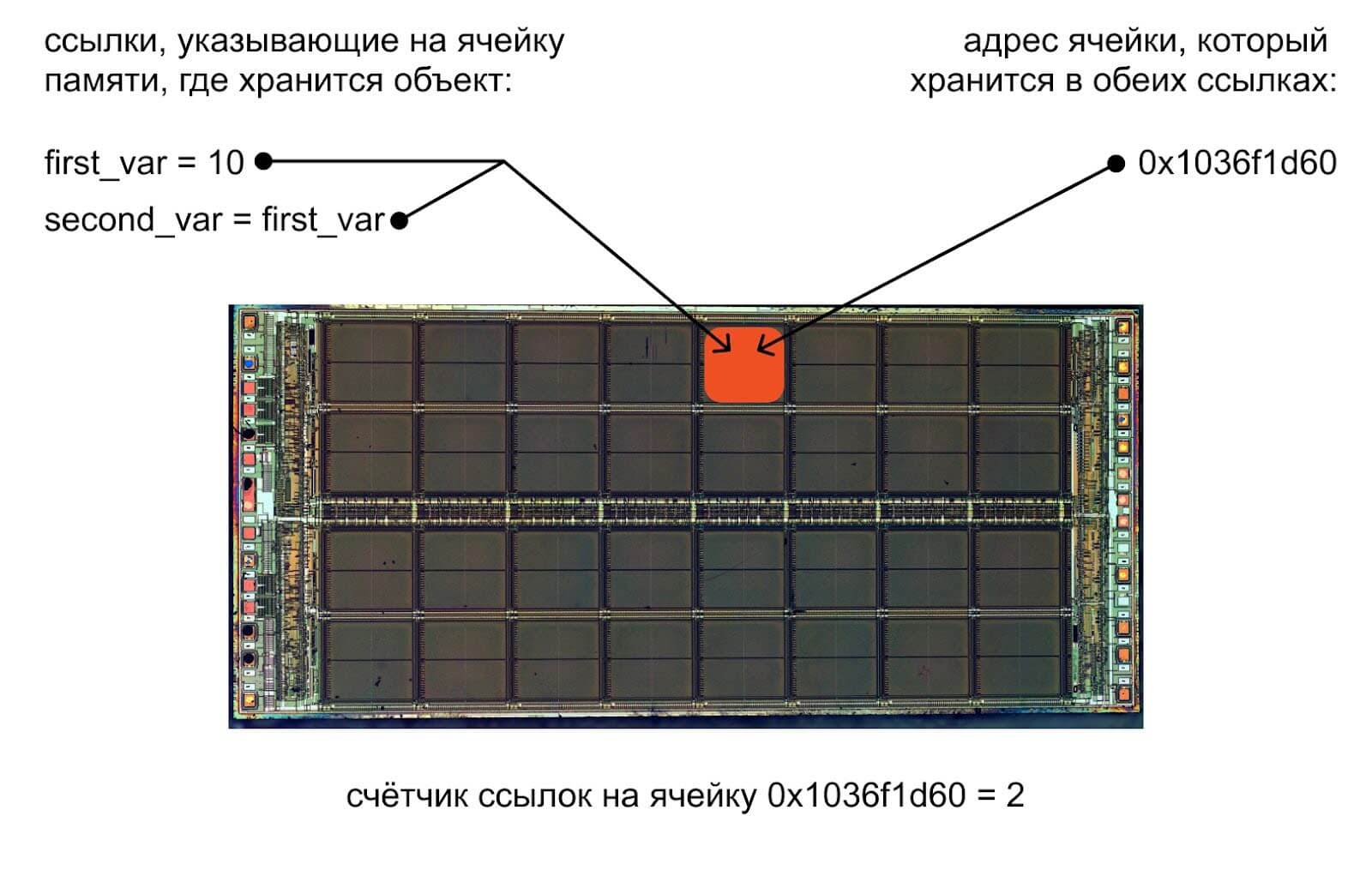
Если в первую переменную first_var положить потом другое значение, счётчик ссылок снизится до одной. Если содержимое всех переменных — ссылок на объект изменится, счётчик обнулится. В этот момент Python освободит ячейку памяти, и по её адресу можно будет хранить новый объект.
Проще говоря, если на то число 10, которое мы запомнили самым первым, больше не ссылается ни одна переменная, то Python это замечает и освобождает память, занятую этой переменной. Это значит, что в эту ячейку можно положить значение какой-то новой переменной и при этом в программе ничего не сломается.
Количество ссылок на один объект можно посмотреть с помощью функции sys.getrefcount(). В случае с нашим примером код будет таким:
sys.getrefcount(first_var)
👉 Важно учесть, что вызов этой функции временно создаёт ещё одну ссылку на объект, поэтому от возвращённого значения нужно отнять 1.
Если при работе с Python нужно вызвать библиотеку C, которая работает с указателями в памяти, можно использовать функцию ctypes(). Для этого нужно выяснить адрес объекта в памяти, а затем запросить, сколько ссылок ведёт на этот адрес:
# узнаём адрес памяти объекта first_var
print(id(first_var))
# запрашиваем количество ссылок на полученный адрес XXX
ctypes.c_long.from_address(XXX).value Делаем свой таймер на Python
Делаем свой таймер на Python Python: как сделать многопоточную программу
Python: как сделать многопоточную программу Как количество просмотров или лайков под роликом может уменьшиться у вас на глазах
Как количество просмотров или лайков под роликом может уменьшиться у вас на глазах Асинхронное программирование в Python — что это, как устроено и где применяется
Асинхронное программирование в Python — что это, как устроено и где применяется Асинхронный код на Python: синтаксис и особенности
Асинхронный код на Python: синтаксис и особенности Прокачиваем асинхронное программирование на Python: используем контекстный менеджер
Прокачиваем асинхронное программирование на Python: используем контекстный менеджерСборщик мусора
У подсчёта ссылок есть один недостаток: два объекта могут указывать друг на друга, и тогда занятые ими ячейки памяти никогда не освобождаются.
Как это может быть:
- В коде есть два шаблона объектов — класс A и класс B.
- При создании объекта любого из этих классов используется шаблон другого класса.
Вот пример с кодом. Для большинства объектов в Python адрес ячейки памяти в десятичной системе можно узнать с помощью функции id(). С некоторыми это не работает, но в нашем примере можно:
# объявляем первый класс
class A:
# объявляем конструктор для создания объекта
def __init__(self):
# при создании объявляем аргумент — переменную,
# в которой храним экземпляр класса B
self.var_a = B(self)
# выводим на экран id класса A и принадлежащего ему аргумента
print(f"A: {id(self)}, var_a: {id(self.var_a)}")
# объявляем второй класс
class B:
# объявляем конструктор для создания объекта
def __init__(self, obj):
# при создании объявляем аргумент — переменную,
# в которую передаём экземпляр класса A
self.var_b = obj
# выводим на экран id класса B и принадлежащего ему аргумента
print(f"B: {id(self)}, var_b: {id(self.var_b)}")
# создаём экземпляр класса А
var = A()При запуске скрипта будет видно, что в создании объекта одного класса используются сразу две ячейки памяти, причём оба класса ссылаются друг на друга:
B: 4515241408, var_b: 4515241456
A: 4515241456, var_a: 4515241408
Получается циклическая ссылка, которая вызывает утечку памяти. Объекты могут вообще не использоваться, а память на них всё равно выделяется — как раз из-за того, что на каждую такую ячейку есть своя ссылка, которая не даёт освободить память. Python не может удалить объект A, потому что на него ссылается объект B, — и наоборот. В итоге память забивается ненужными данными, которые никогда не используются, — это и называется утечкой памяти.
Схематично циклические ссылки выглядят так:
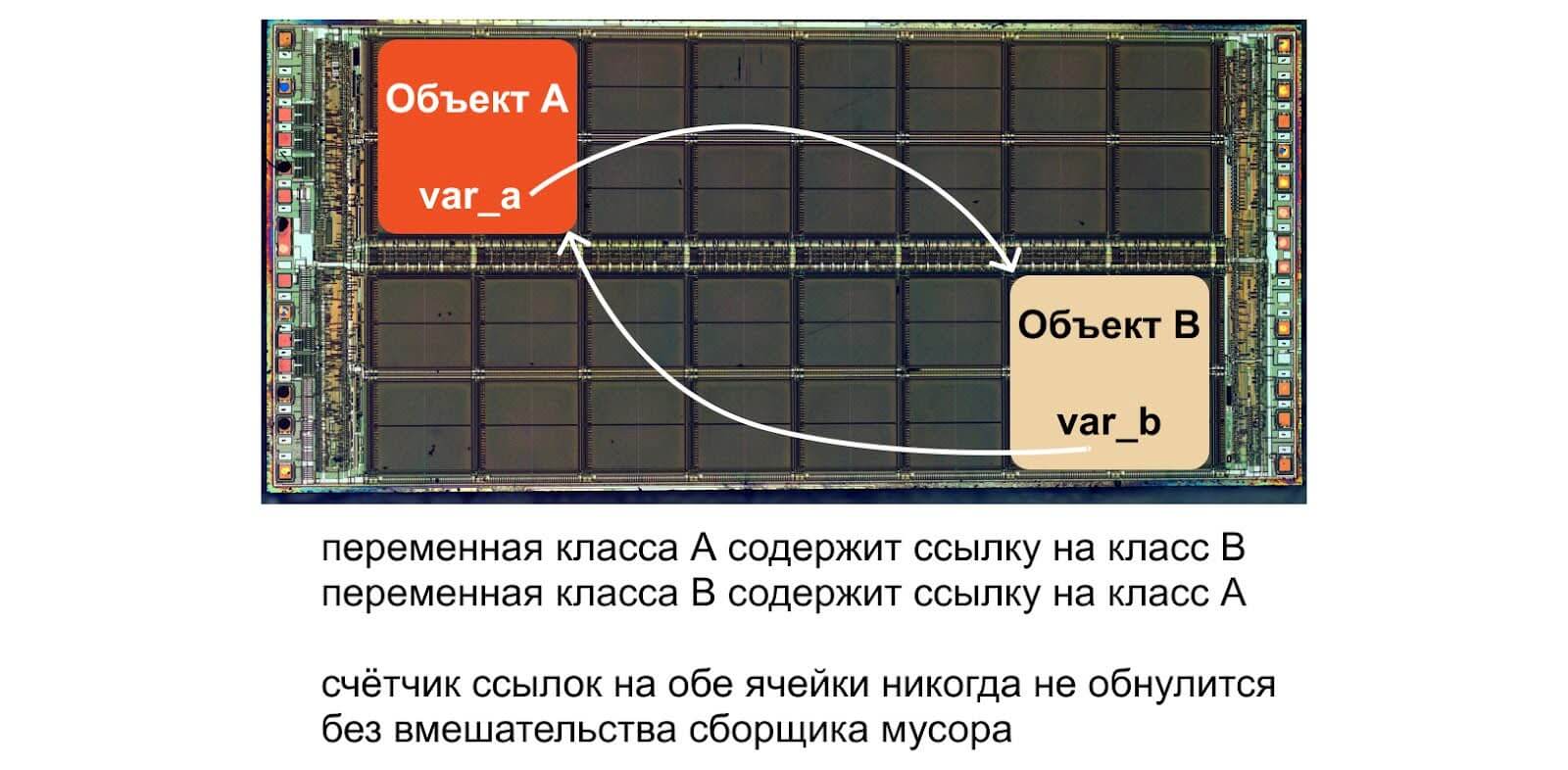
Наш пример показывает циклические ссылки в явном виде, но в реальном коде обнаружить их может быть сложно. Отслеживанием таких ссылок занимается встроенный в Python модуль Garbage Collector, или gc.
На работу сборщика мусора нужно время. Он проверяет каждый объект, и на время проверки все работавшие с объектом потоки останавливаются. Этот механизм называют Stop the world (остановка мира) — Python как бы дёргает стоп-кран, всё замораживается, и начинается поиск таких циклических ссылок (и другого ненужного мусора в памяти). Когда поиск закончен и всё почищено, мир запускается снова и потоки продолжают работать с того же места, как будто ничего не случилось.
Сборщик мусора — одна из причин, по которым не стоит использовать Python ниже версии 3.4. В более ранних версиях он не удаляет объекты, в которых есть деструктор — свой метод освобождения памяти. Если такой объект становится частью циклической ссылки, начинается утечка памяти.
Управление памятью
На каждый объект программа запрашивает у компьютера нужное количество оперативной памяти. Это может происходить один раз на этапе компиляции или динамически во время работы программы (на жаргоне — рантайм). Процесс распределения памяти часто называют аллокацией, от английского allocation.
Аллокация памяти на Python работает в двух вариантах: на уровне операционной системы и на уровне интерпретатора.
Если для работы объекта нужно больше 512 байт, запрос отправляется в системный аллокатор malloc (от слов memory allocator). Это стандартный механизм работы с памятью в операционной системе.
Системный аллокатор — универсальная технология, которая может работать с любыми процессами и объектами любого размера. Но в программах Python используется много небольших объектов, и для них придумали специальную оптимизацию: внутренний аллокатор pymalloc. Он работает только с теми данными, объём которых не превышает 512 байт памяти.
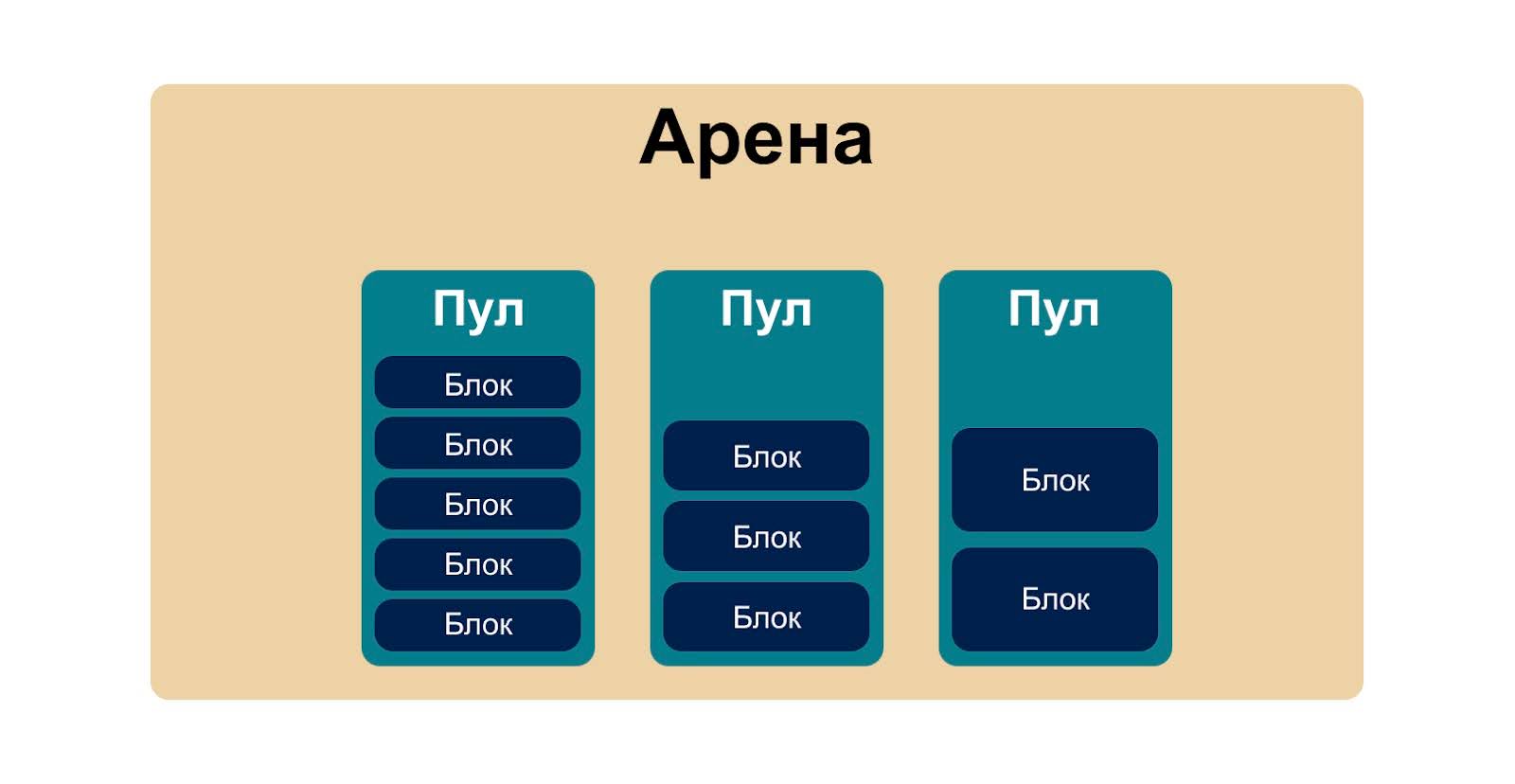
Pymalloc управляет тремя конструкциями: аренами, пулами и блоками.
- Арена — фрагмент памяти, кратный 4 килобайтам и состоящий из более мелких фрагментов — пулов.
- Пулы нужны для быстрого поиска, выделения и освобождения памяти. Пулы состоят из блоков памяти, причём в одном пуле лежат блоки только одного размера.
- Блоки — основные единицы работы pymalloc. Это ячейки памяти, кратные 8 байтам. На каждый запрос до 512 байт выделяется один из блоков. Он может быть больше нужного количества, например на запрос в 65 байт программа выдаст блок в 72 байта.
У каждого блока может быть три состояния: занятый, свободный или зарезервированный. Зарезервированный означает, что программа выделяет виртуальную память, но не физическую. Поэтому реальной нагрузки на ресурсы ещё нет, но если для работы процессу понадобятся свободные блоки, их сразу выделят, а до этого ими могут пользоваться другие программы.
Python сортирует арены по количеству занятых пулов и сначала проверяет самые заполненные. При этом компьютер постарается заполнить каждую арену под завязку, и только потом возьмёт следующий набор блоков. Так сводится к минимуму проблема фрагментации памяти: ситуация, когда на работу выделено больше физической памяти, чем требуется.
Что даёт такая система
В некоторых языках программирования мы должны вручную указывать выделенное под каждый элемент количество памяти. Нужно заранее определять тип переменной и указывать системному аллокатору её размер, потому что переменные в низкоуровневых языках — уже не просто ссылки, а ячейки памяти.
В Python это работает автоматически, поэтому мы не замечаем всей этой титанической работы, что происходит под капотом.
И что в этом всём плохого?
Все технологии работы с памятью, которые сейчас есть в Python, — непотокобезопасные. Потокам программы нельзя работать с одним объектом в памяти одновременно, потому что они могут по-разному изменить одно и то же значение. В результате программа будет работать не так, как задумали разработчики.
В некоторых языках, чтобы ограничить параллельным потокам доступ к ячейкам с важными объектами, нужно уметь работать с инструментами синхронизации. В Python многопоточность запрещена по умолчанию. За это отвечает механизм GIL, который разрешает выполнение только одного потока в любой момент. Если отключить GIL, механизмы работы с памятью перестанут работать, потому что не умеют ограничивать одновременные потоки.
Сейчас разработчики Python думают, как заменить все механизмы памяти на потокобезопасные. А там можно уже и GIL отключить, и писать более быстрые программы.
А пока этого нет — работаем с тем, что есть.











