








В аналитике Big Data данные для работы чаще всего хранятся в датасетах — структурированных наборах информации. Форматы этих данных могут быть разными: текстовые записи, изображения, видео. Один из самых частых вариантов — таблицы.
Сегодня рассказываем про один из самых популярных инструментов для работы с табличными данными — библиотеку Pandas на Python.
Что такое библиотека Pandas
Библиотека Pandas позволяет делать много полезных действий с данными, которые выглядят как таблицы Excel. Такие данные ещё называют «панельные», и библиотеку назвали тоже в честь них. Pandas — это сокращение от panel data.
Пример — набор данных по землетрясениям в Японии:

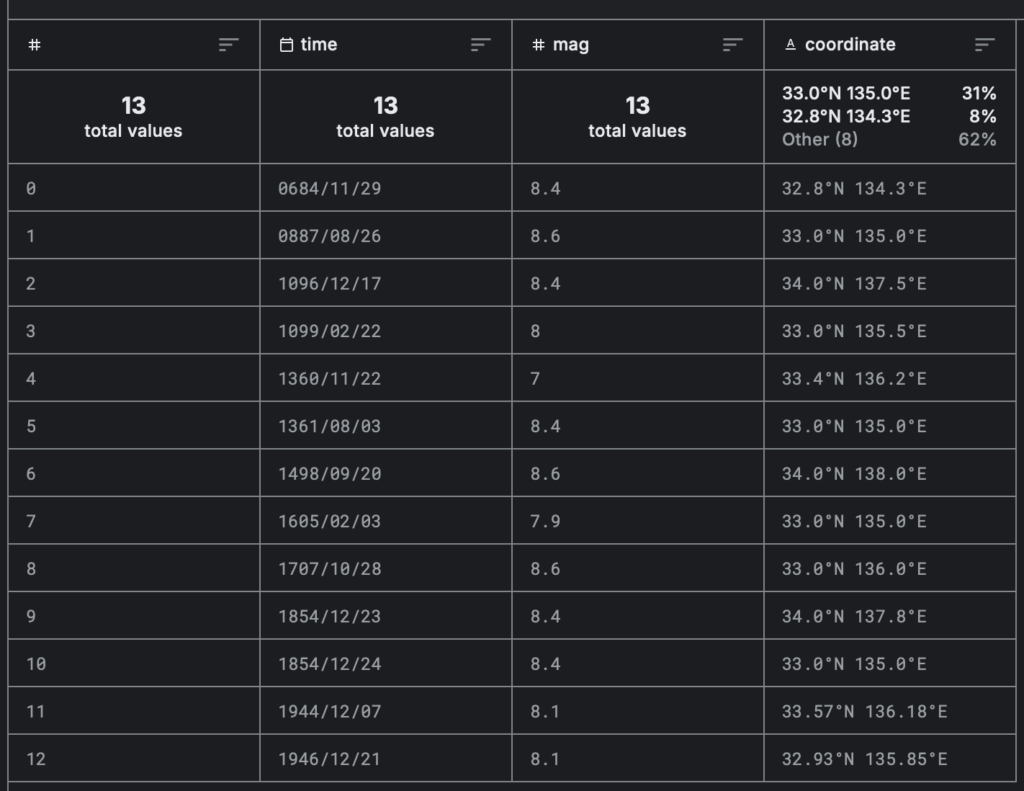
С Pandas Python получает возможность работать с информацией через уже готовые методы. Можно быстро подсчитать количество строк или уникальных значений в столбце, посмотреть общие сведения о наборе данных.
Без Pandas разработчикам пришлось бы прописывать все инструкции пошагово, используя обычный синтаксис языка Python. Библиотека объединяет целые фрагменты кода так, что их сразу можно использовать одной командой.
Область применения Pandas
В ИТ многие специалисты работают с Pandas. Вот некоторые из их профессий и то, как они используют библиотеку:
- Дата-сайентисты готовят данные для анализа и машинного обучения.
- Исследователи данных могут быстро проверять статистику экспериментов и трансформировать данные для использования в исследованиях.
- Аналитики данных собирают ключевые показатели для бизнеса и строят визуализации данных с использованием других библиотек. Например,
matplotlibиseaborn. - Инженеры машинного обучения подготавливают наборы данных для обучения моделей и их отладки перед этапом масштабирования.
- Дата-инженеры работают с небольшими объёмами данных перед их загрузкой в хранилища и тестируют процессы доставки данных до дата-сайентистов.
- Бэкенд-разработчики могут использовать Pandas при интеграции разных систем аналитики на стороне сервера.


Ключевые возможности Pandas
Pandas — это один из самых популярных инструментов для работы с данными по нескольким причинам.
Быстрая и эффективная работа с данными. Pandas построена на базе другой популярной и мощной библиотеки, NumPy. Это обеспечивает быстрые и эффективные численные операции: можно работать с миллионами строк данных без значительных задержек, что делает Pandas хорошим выбором при работе с большими датасетами.
Гибкие возможности. В библиотеке существует много функций и методов для обработки данных. Можно легко фильтровать, группировать, объединять и преобразовывать данные для конкретных задач. Это делает Pandas универсальным инструментом для аналитики.
Простая интеграция с другими библиотеками. Pandas без проблем интегрируется с популярными библиотеками Python: NumPy, SciPy и Matplotlib. Это позволяет создать более сложную и мощную аналитическую систему.
Читаемость. У Pandas чёткий и лаконичный синтаксис, который легко читать. Это делает код проще для исправления, масштабирования и поддержки.
Поддержка разных форматов. После установки можно работать с данными из разных источников, например из CSV-файлов, Excel-документов и баз данных SQL.

Установка и настройка Pandas
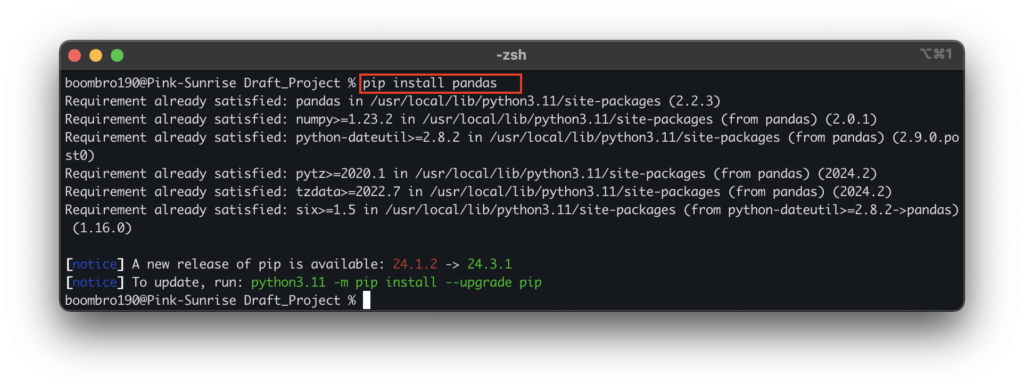
Если вы пишете Python-код в текстовом редакторе или среде разработки IDE, библиотеку нужно установить командой pip install pandas.

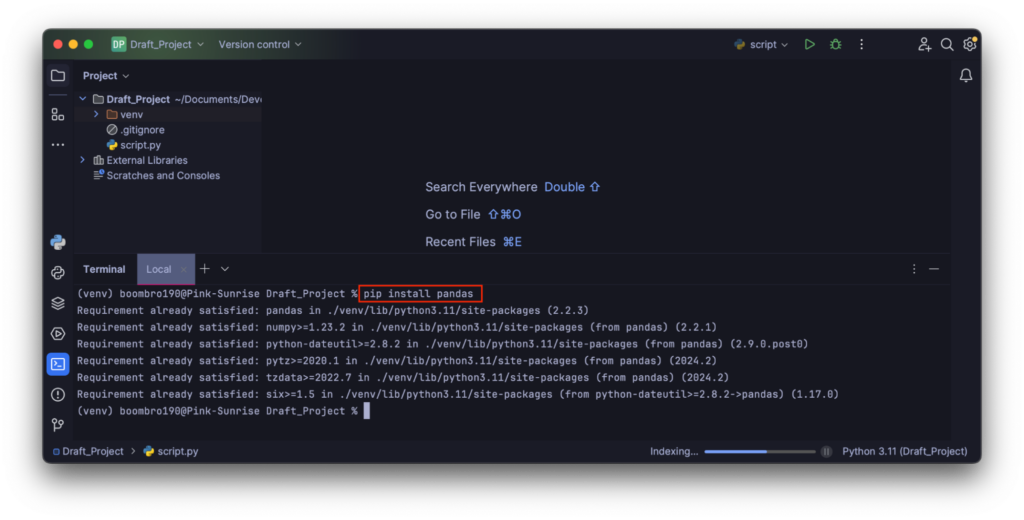
При работе в среде разработки библиотеки и другие зависимости устанавливаются на вкладке терминала:

После этого библиотеку нужно импортировать в код. Обычно это делают, используя стандартное сокращение pd:
import pandas as pd
Если работаете с большими данными, можно настроить опции Pandas, чтобы улучшить производительность. Вот несколько полезных настроек в начале работы.
- pd.set_option('display.max_rows', 100) ограничивает количество отображаемых на экране строк, в нашем примере — до 100.
- pd.set_option('display.max_columns', 20) ограничивает количество отображаемых на экране столбцов. У нас максимальное количество — 20.
- pd.set_option('display.width', 1000) устанавливает ширину таблицы на экране. Мы установили её на 1 000.
- pd.set_option('mode.chained_assignment', None) отключает предупреждения при изменении данных.
- pd.set_option('display.max_seq_item', 5) устанавливает количество отображаемых элементов в коллекциях. В примере — 5.
- pd.set_option('display.memory_usage', 'deep') показывает полное использование задействованной памяти.
Как работать с Pandas, ничего не устанавливая
Чаще всего для программирование на Pandas используют виртуальные ноутбуки, потому что это удобно и подходит для задач анализа данных.
Виртуальный ноутбук — это программа, которая работает как обычный компьютер внутри другого компьютера. Благодаря этому можно пользоваться вычислительными мощностями других машин и не устанавливать себе лишний софт. Самые популярные сервисы для работы в таком режиме — Google Colab и Jupyter Notebook.
У виртуальных ноутбуков есть ещё несколько преимуществ.
Код выполняется по фрагментам, ячейками. Можно написать часть скрипта, запустить его и сразу увидеть промежуточный результат. Так выглядит ноутбук Google Colab:

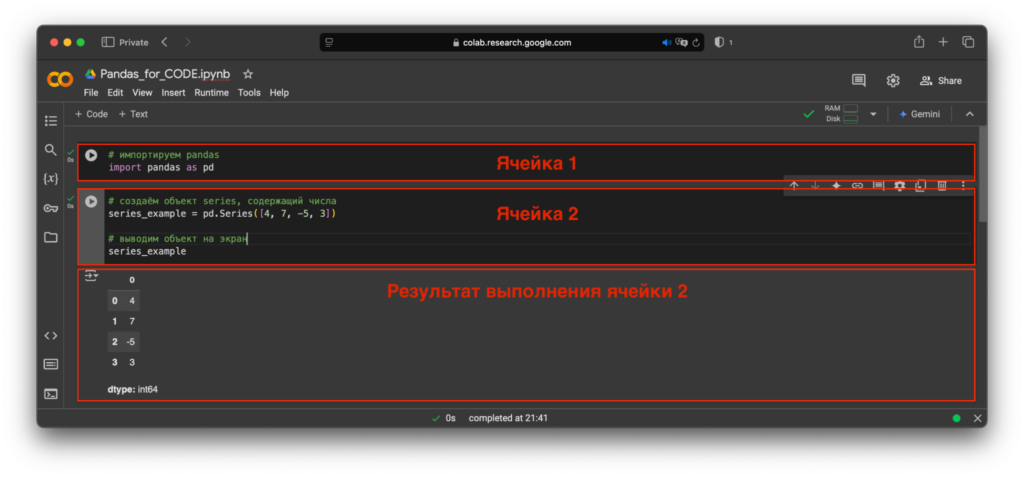
Обратите внимание, что в этом примере мы не устанавливали Pandas, а просто импортировали библиотеку и начали работать. А чтобы вывести результат на экран, не понадобился оператор print.
Визуализация. Построенные с помощью дополнительных библиотек и инструментов графики тоже отображаются прямо в ячейках.
Простота отладки. Если в коде есть ошибка, можно перезапустить только конкретную ячейку, не переписывая весь скрипт.
Удобство воспроизведения. Весь процесс можно сохранить в одном файле и запустить его позже.
Возможность совместной работы. Ноутбуками можно поделиться с коллегами в виде файлов или через онлайн-платформы.
Дистрибутив Anaconda
Ещё один вариант работы на виртуальном ноутбуке — установить специальный дистрибутив. Это пакет технологий, чаще всего объединённых общей целью. Для научных и исследовательских работ часто используется Anaconda.
Anaconda включает 1 500 библиотек, в том числе Pandas, менеджеры пакетов и виртуальной среды и графический интерфейс. После установки можно будет запустить виртуальный ноутбук на своём компьютере и работать на нём:

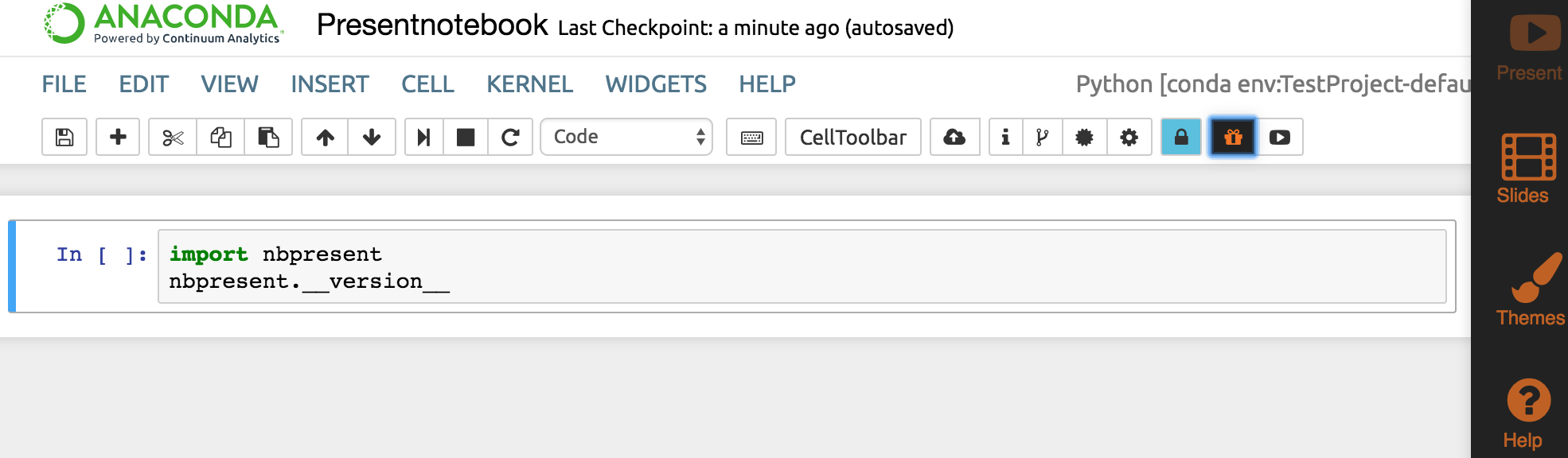
Работа через Anaconda — хороший вариант для больших проектов и новичков в анализе данных, потому что включает все необходимые зависимости и мощные инструменты. Установить этот дистрибутив можно по инструкциям для Windows, macOS и Linux на странице документации docs.anaconda.com.
Структуры данных в Pandas
В Pandas есть две основные структуры данных, с которыми можно работать: Series и DataFrame. Эти форматы лежат в основе большинства операций и будут позволять гибко работать с табличными и одномерными данными.
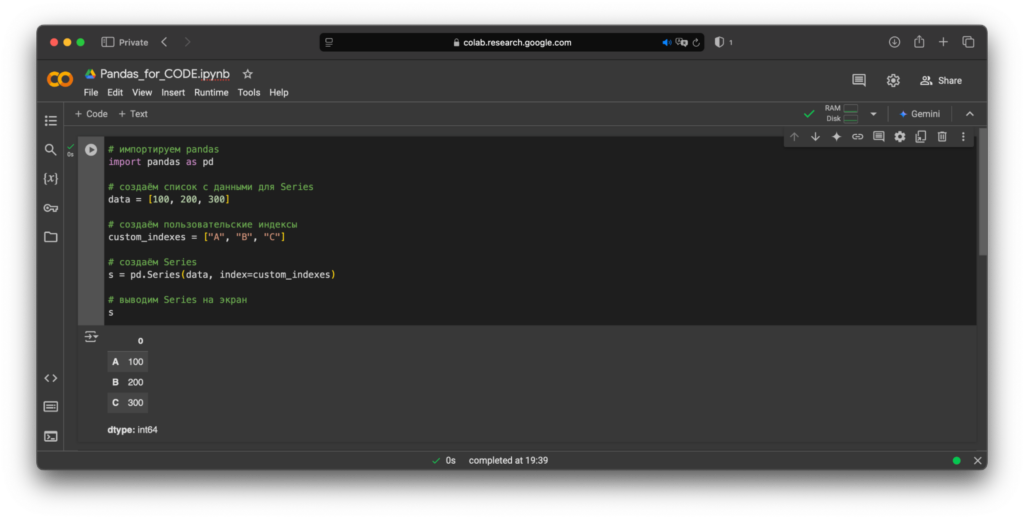
Series — одномерный массив, то есть просто список пронумерованных элементов.Создавать его можно так же, как обычный список. При этом есть возможность самим задать индексы. Определив список и индексы, можно создать объект Series командой pd.Series(), указав в скобках оба параметра через запятую. Так выглядит создание Series на виртуальном ноутбуке:
# создаём список с данными для Series
data = [100, 200, 300]
# создаём пользовательские индексы
custom_indexes = ["A", "B", "C"]
# создаём Series
s = pd.Series(data, index=custom_indexes)
# выводим Series на экран
sРезультат после запуска ячейки будет выглядеть так:



DataFrame — основной тип данных в Pandas. Большая часть работы проходит с ним. Это двумерный массив, в котором у каждого элемента есть два индекса: столбца и строки. Индексы могут быть номерами или названиями, например «Страна», «Город», «Улица», «Количество жителей», «Широта», «Долгота».
Чтобы было понятнее, посмотрим на пример. Самый простой способ создать DataFrame — через словарь. Код для виртуального ноутбука:
# импортируем Pandas
import pandas as pd
# создаём данные в виде словаря
data = {
"Name": ["Михаил", "Игорь", "Кристина"],
"Age": [39, 37, 30],
"City": ["Москва", "Токио", "Сеул"]
}
# создаём DataFrame
df = pd.DataFrame(data)
# выводим DataFrame на экран
dfРезультат:

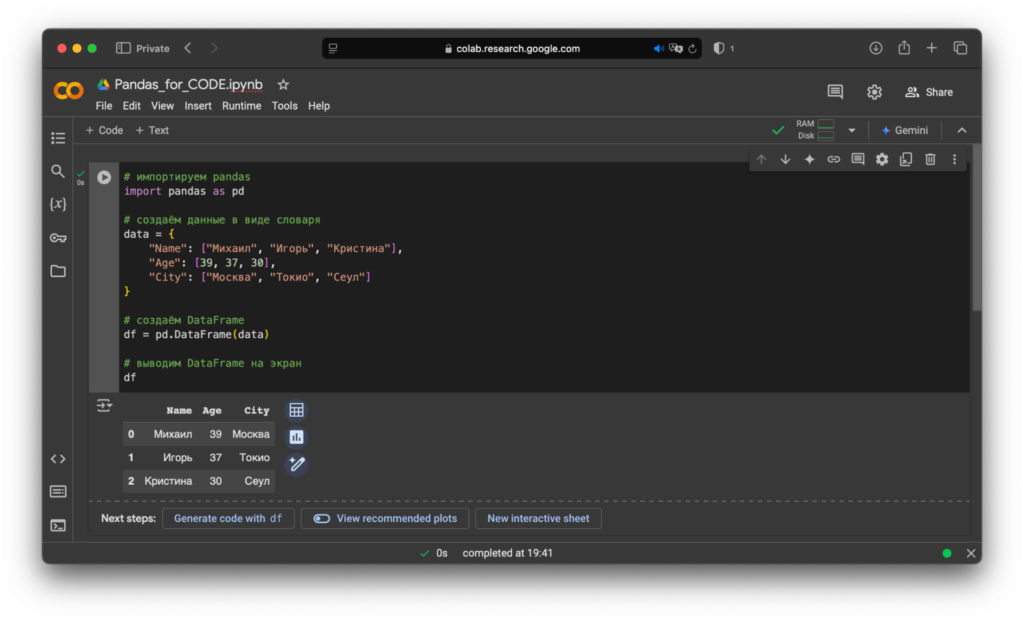
В этот раз мы не указали свои индексы для строк, поэтому Pandas проставила их автоматически: от 0 до 2.
Создать DataFrame можно и по-другому. Ниже — примеры для виртуального ноутбука.
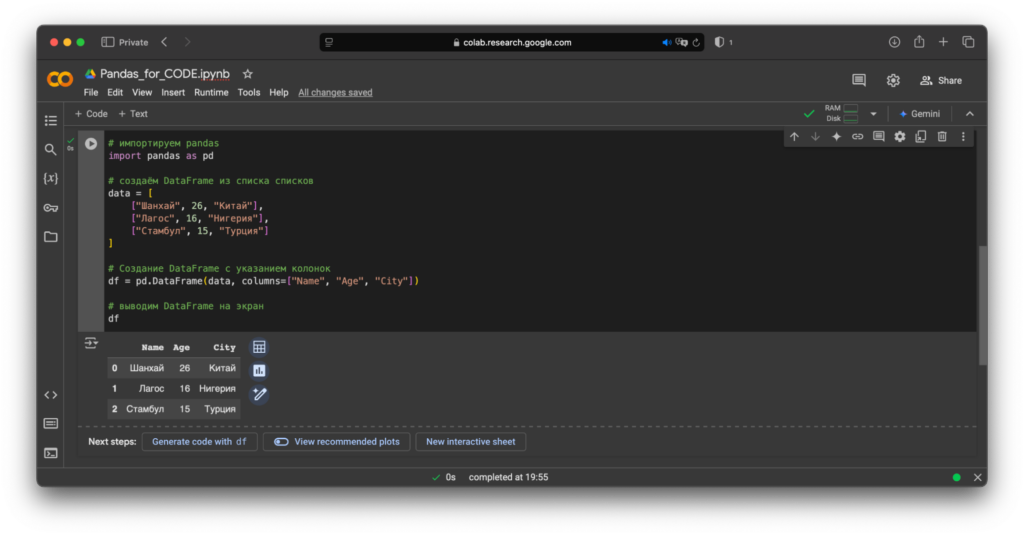
Через список списков:
# импортируем Pandas
import pandas as pd
# создаём DataFrame из списка списков
data = [
["Шанхай", 26, "Китай"],
["Лагос", 16, "Нигерия"],
["Стамбул", 15, "Турция"]
]
# Создание DataFrame с указанием колонок
df = pd.DataFrame(data, columns=["Name", "Age", "City"])
# выводим DataFrame на экран
dfСмотрим результат:

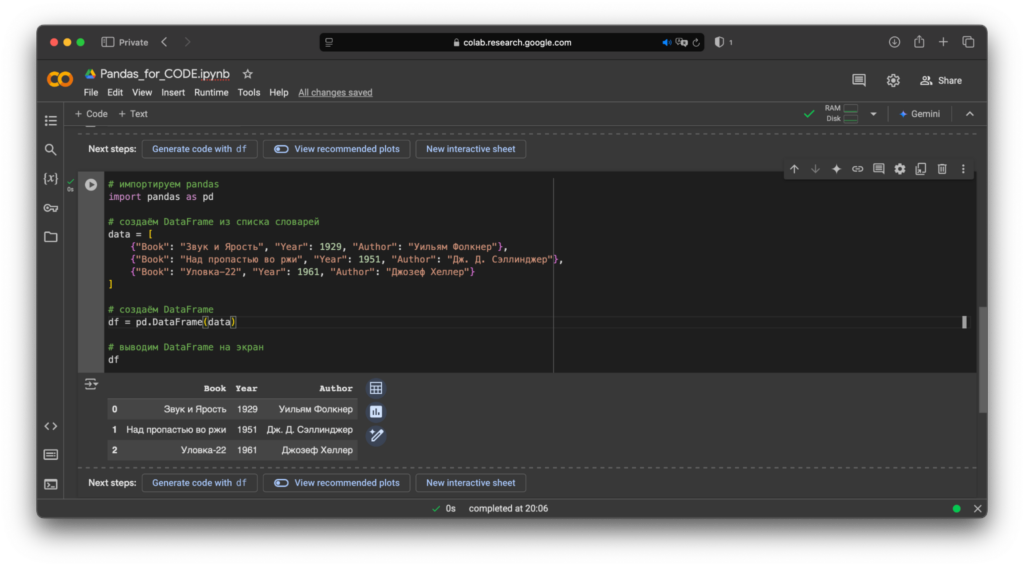
Ещё один вариант — список словарей.
# импортируем Pandas
import pandas as pd
# создаём DataFrame из списка словарей
data = [
{"Book": "Звук и Ярость", "Year": 1929, "Author": "Уильям Фолкнер"},
{"Book": "Над пропастью во ржи", "Year": 1951, "Author": "Дж. Д. Сэлинджер"},
{"Book": "Уловка-22", "Year": 1961, "Author": "Джозеф Хеллер"}
]
# создаём DataFrame
df = pd.DataFrame(data)
# выводим DataFrame на экран
dfЗапускаем ячейку кода:

Импорт и экспорт данных
Pandas поддерживает работу с разными типами данных.
Импорт данных из различных форматов:
- CSV (Comma-Separated Values). Самый популярный формат для хранения табличных данных. Этот вариант подходит для хранения больших объёмов данных в простой структуре. В CSV часто хранятся датасеты в открытых источниках — например, на kaggle.com.
- Excel. Им часто пользуются бизнес-аналитики и менеджеры, поэтому такая возможность упрощает работу.
- JSON (JavaScript Object Notation). Формат для структурированных данных, который используется при работе с API, в веб-разработке, интеграции между системами. JSON легко обрабатывается Pandas, позволяя конвертировать сложные структуры в удобные DataFrame.
- Базы данных SQL. Можно загрузить данные напрямую из баз. Прямое подключение позволяет анализировать данные в реальном времени без предварительных выгрузок.
- HTML-таблицы. С Pandas можно анализировать данные с веб-страниц, если информация на них представлена в виде таблиц — например, котировки акций, расписания, статистика.
Экспорт данных в различные форматы тоже возможен, но чаще всего используют выгрузку данных в CSV. Второй популярный вариант — Excel, при использовании дополнительной библиотеки.
Основные операции с данными
Pandas предоставляет много готовых методов работы для анализа данных, мы рассмотрим несколько основных.Для наших экспериментов мы возьмём датасет с kaggle о землетрясениях в Японии. Чтобы загрузить его в ноутбук Google Colab, нужно написать такие команды:
# импортируем Pandas в проект
import pandas as pd
# импортируем модуль для загрузки файла из Google Colab
from google.colab import files
# загружаем файл — после этой команды
# в ноутбуке появится кнопка загрузки файла
uploaded = files.upload()
# создаём объект DataFrame
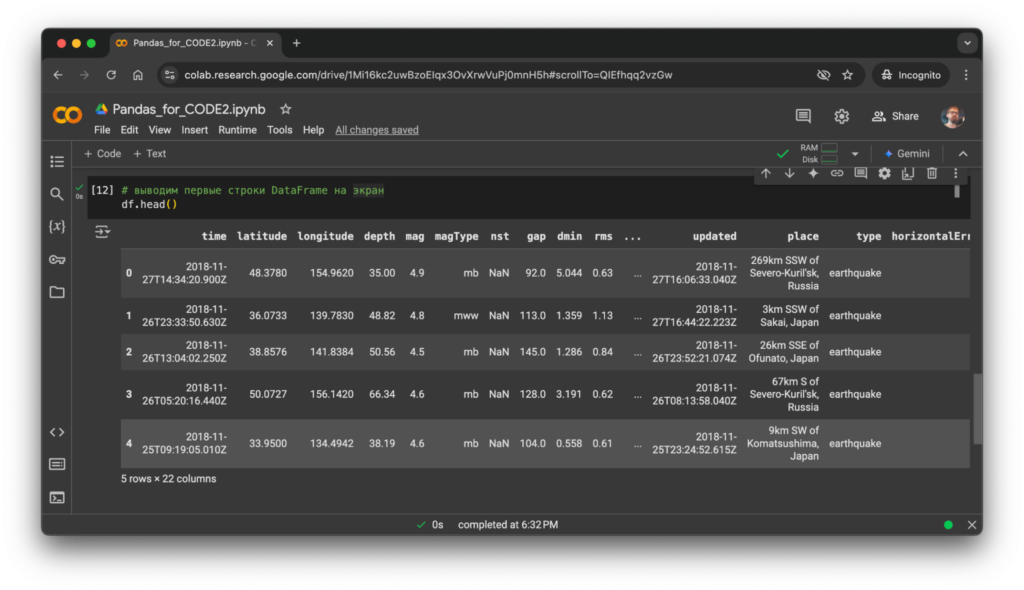
df = pd.read_csv('Japan earthquakes 2001 - 2018.csv')Просмотр и исследование данных. Это помогает понять, с какой информацией нужно работать, и определить подходящие действия для анализа.
Например, просмотр первых строк таблицы поможет увидеть структуру данных, названия столбцов и примерные значения. Анализ статистики будет предоставлять ключевые характеристики данных: средние значения, минимумы, максимумы и распределение.
Вот несколько методов, которые можно использовать.
df.head() показывает первые строки DataFrame:
# выводим первые строки DataFrame на экран
df.head()
Вывод в ноутбуке:

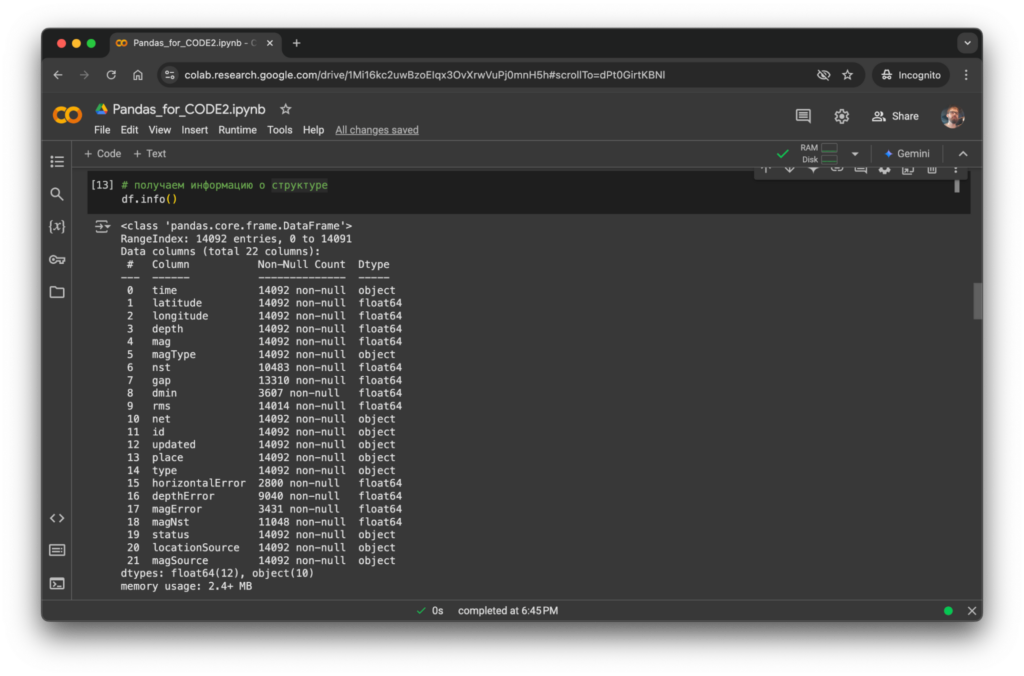
df.info() выводит информацию о структуре: количество строк и столбцов, их названия, типы данных, количество ненулевых значений по столбцам, потребление памяти.
# получаем информацию о структуре
df.info()

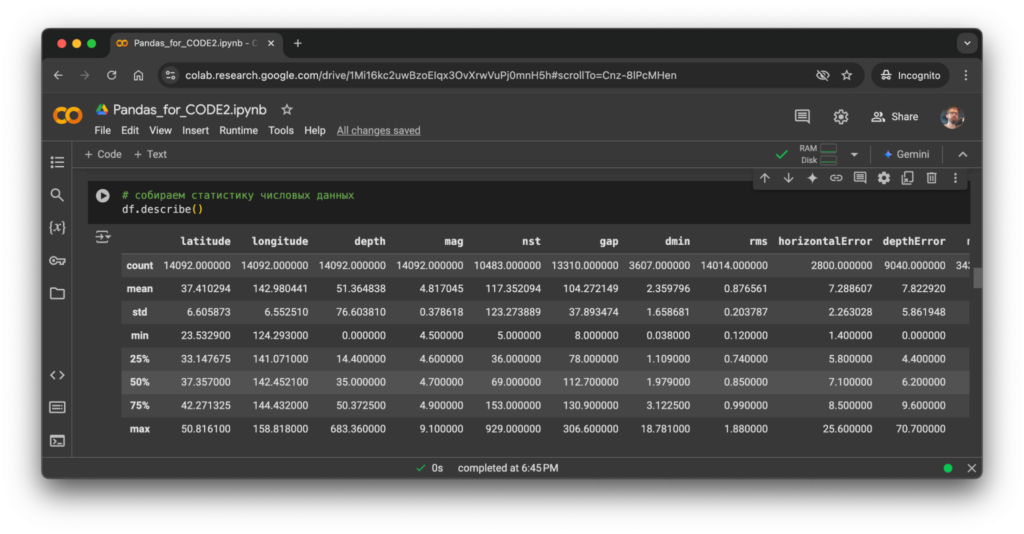
df.describe() генерирует сводную статистику по числовым (а при дополнительной настройке — и по другим) столбцам DataFrame. Это полезный инструмент для быстрого анализа. Например, можно узнать количество ненулевых значений, среднее значение, стандартное отклонение.
Команда для выполнения:
# собираем статистику числовых данных
df.describe()

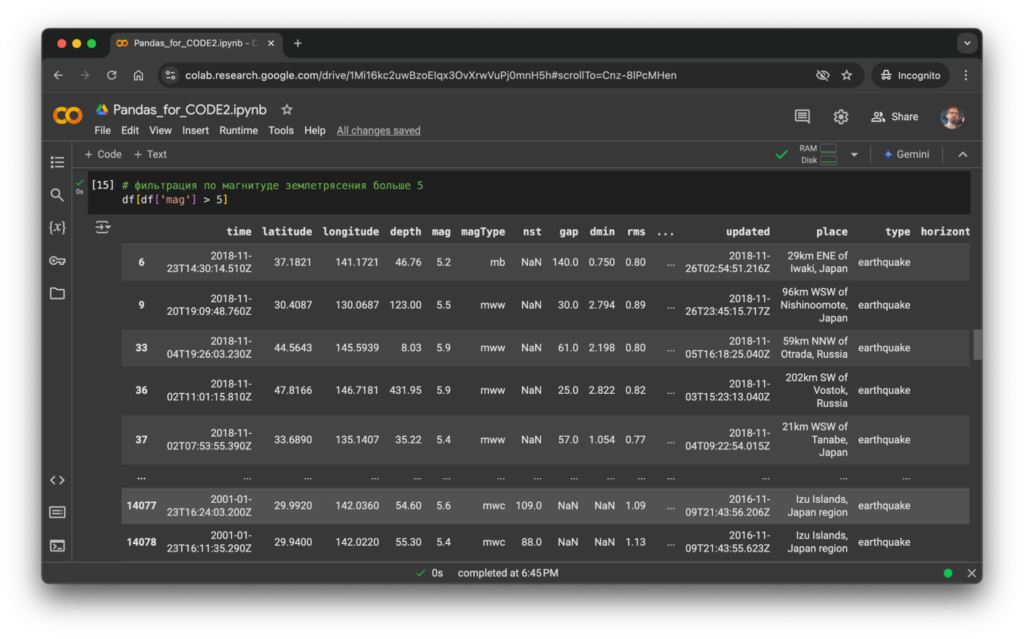
Фильтрация и выборка данных. Фильтрация помогает сосредоточиться на нужном секторе среди всей информации. Например, можно выбрать строки, где возраст больше 30. Выборка данных позволяет работать с нужными столбцами, если, например, вы хотите сконцентрироваться только на именах и оценках.
Выберем значения с магнитудой землетрясений выше установленного:
# фильтрация по магнитуде землетрясения больше 5
df[df['mag'] > 5]
После выполнения кода получаем:

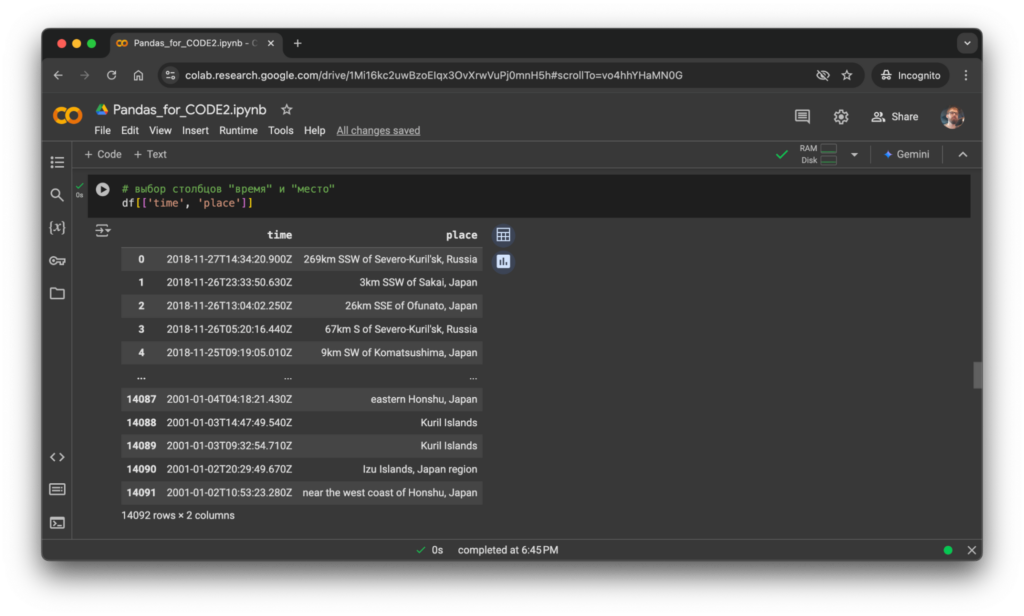
Просматриваем только нужные нам столбцы:
# выбор столбцов "время" и "место"
df[['time', 'place']]

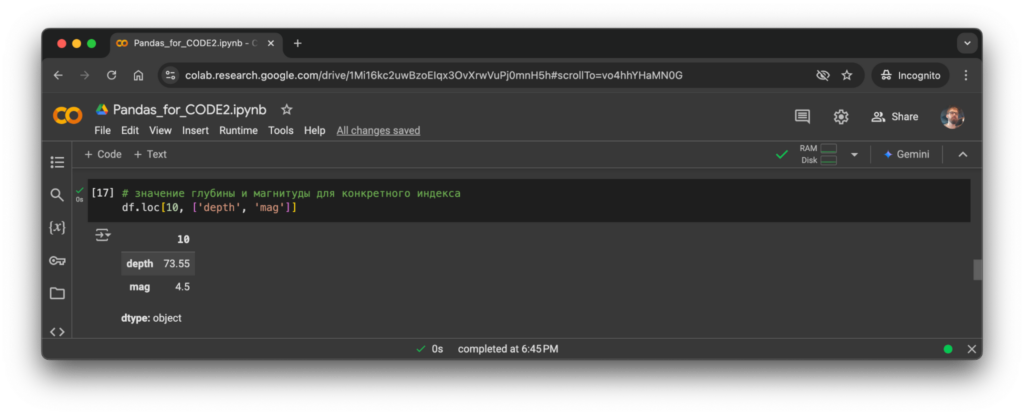
Смотрим значения для конкретной позиции в датасете:
# значение глубины и магнитуды для конкретного индекса
df.loc[10, ['depth', 'mag']]

Агрегация и группировка данных. Операции, которые помогают извлечь обобщённую информацию. Пример — сгруппировать данные по определённому критерию и рассчитать сумму и среднее по какому-то показателю.
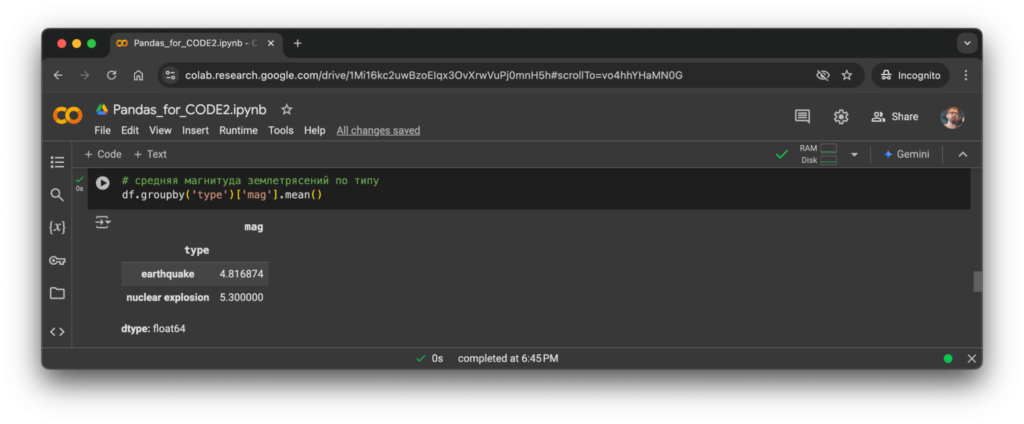
Выбираем среднюю магнитуду по каждому из представленных в таблице типов землетрясений. У нас их всего два, поэтому на выходе тоже будет только два значения:
# средняя магнитуда землетрясений по типу
df.groupby('type')['mag'].mean()
Запускаем команду:

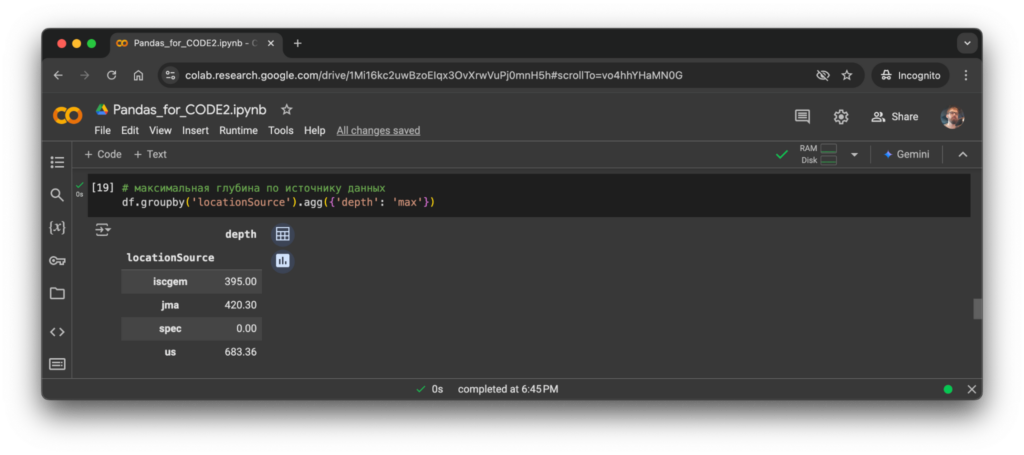
Просматриваем максимальную глубину землетрясений в километрах для каждого источника данных (это параметр locationSource):
# максимальная глубина по источнику данных
df.groupby('locationSource').agg({'depth': 'max'})

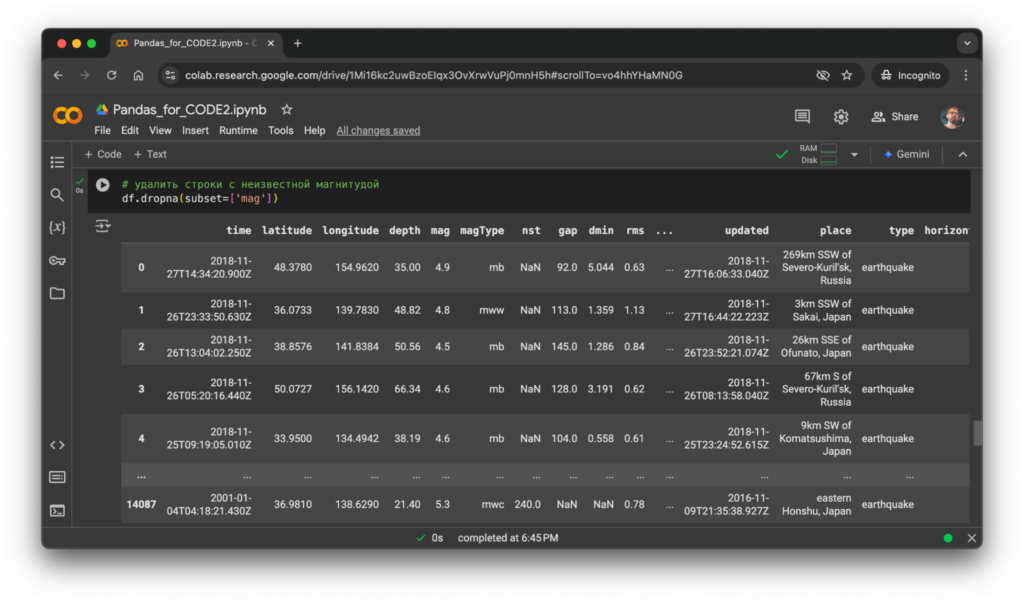
Очистка данных. Данные редко бывают идеальными, поэтому часто нужны инструменты для их очистки. Если какие-то значения пропущены, они могут быть заполнены средним арифметическим, медианой или нулями. Дубликаты можно удалить, чтобы избежать искажений в анализе.
В нашем датасете мы можем удалить строки с неизвестной амплитудой:
# удалить строки с неизвестной магнитудой
df.dropna(subset=['mag'])
Сейчас этого не видно, но DataFrame стал более очищенным:

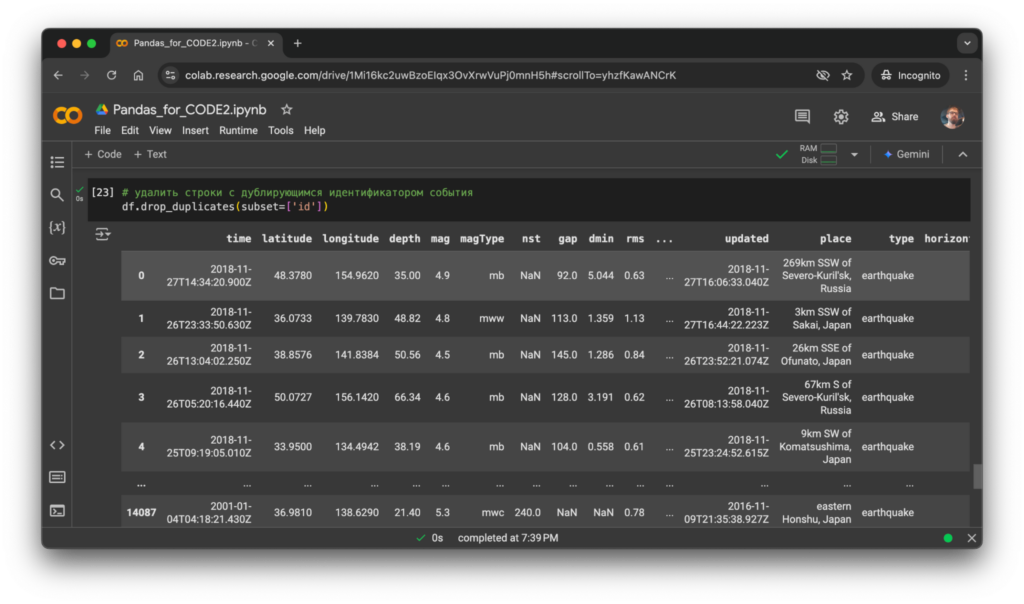
Можно вычислить повторяющиеся идентификаторы и удалить их:
# удалить строки с дублирующимся идентификатором события
df.drop_duplicates(subset=['id'])
Дублей в датафрейме больше нет:
Визуализация данных в Pandas
Графики и диаграммы помогают анализировать данные, находить зависимости и выводить результаты анализа для лучшего понимания.
Pandas интегрирована с библиотеками визуализации, например Matplotlib и Seaborn. Их можно использовать для создания различных графиков, включая гистограммы, линейные графики, диаграммы рассеяния и другие.
Для визуализации данных используется метод .plot(), который можно вызвать на объекте DataFrame или Series. Этот метод использует библиотеку Matplotlib для рисования графиков.
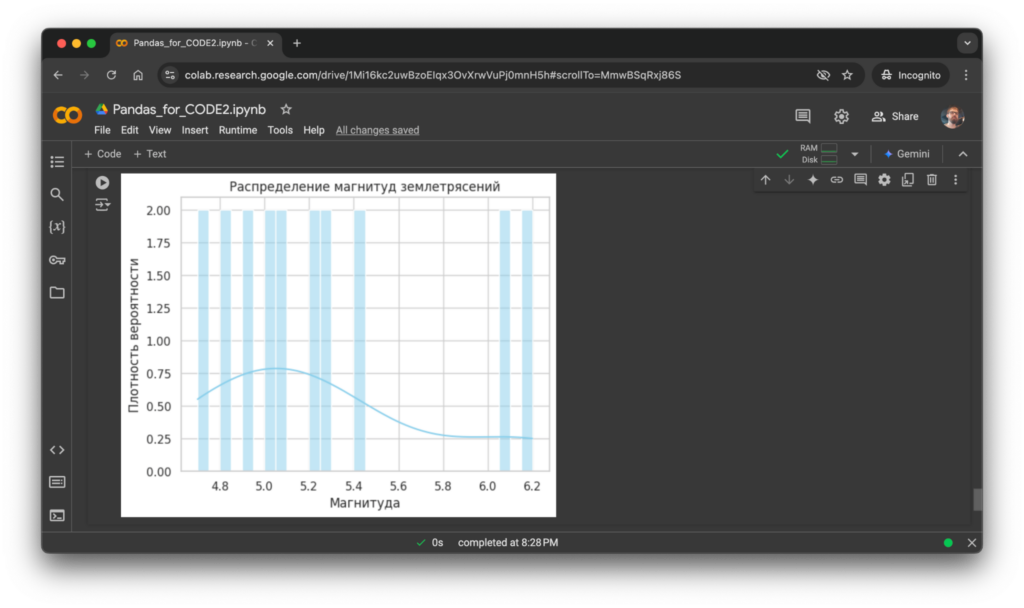
Для примера построим график с разными магнитудами землетрясений. График покажет, как часто встречаются различные уровни магнитуды в нашем датасете.
# импортируем Pandas
import pandas as pd
# импортируем библиотеки для визуализации
import seaborn as sns
import matplotlib.pyplot as plt
# извлекаем данных из столбца 'mag'
analysis = df['mag']
# создаём график
sns.set(style="whitegrid")
# задаём настройки графика
sns.histplot(analysis, kde=True, bins=30, color='skyblue', stat='density')
# указываем названия графика и осей
plt.xlabel('Магнитуда')
plt.ylabel('Плотность вероятности')
plt.title('Распределение магнитуд землетрясений')
# отрисовываем график
plt.show()После запуска кода график выглядит так:



Советы и рекомендации по работе с Pandas
Если вы только начинаете работать с этой библиотекой, вот несколько советов:
- Используйте
import pandas as pdдля удобства работы. - Настройте отображение и задайте ограничения производительности в начале работы.
- Перед началом работы с датасетом его нужно очистить от пропущенных и аномальных значений и привести к одному виду.
- Изучайте данные после изменений. Важно не просто загружать данные и манипулировать ими, но и регулярно проверять, что происходит с ними на каждом этапе.
- Структурируйте информацию правильно. Проверьте, что каждый столбец соответствует своему типу данных.
- Документируйте шаги и добавляйте комментарии к каждому шагу, чтобы понимать, что происходит с данными.
👉 Главная рекомендация — пользоваться документацией. Pandas — очень мощный инструмент, а документация содержит массу полезных примеров и рекомендаций по использованию различных функций.



















