Представьте школьника, который готовится к ЕГЭ по математике. Вместо того чтобы разобраться в формулах и понять логику решения задач, он просто зазубривает ответы из сборника за прошлый год. На пробном экзамене с теми же задачами он получает 100 баллов. Учитель в восторге, родители сияют. Но на реальном экзамене цифры другие, условия меняют, и мамина радость набирает, от силы, 60 баллов.
Поменяем школьника на модель машинного обучения и получим знакомую ML-спецам ситуацию — алгоритм блестяще справляется с обучающими данными и проваливает тестовые.
Разберемся, почему умные алгоритмы иногда становятся глупыми зубрилами, как вовремя заметить эту проблему и какие методы помогут привести модель в чувство.
Что такое переобучение
Переобучение (overfitting) — это ситуация, когда модель слишком сильно подстраивается под обучающие данные. Она не улавливает общую закономерность, а буквально запоминает каждый конкретный пример со всеми его случайными выбросами, шумами и погрешностями.
Цель любого обучения заключается в том, чтобы машинный алгоритм мог посмотреть на набор старых данных и сделать правильный вывод о чём-то новом, с чем он раньше не сталкивался. Переобученная модель идеально предсказывает прошлое, но оказывается бесполезной в будущем. Она строит настолько сложную внутреннюю логику, что малейшее отклонение от заученного шаблона ломает ей мозг.
Как распознать переобучение модели: основные признаки
Переобучение сложно заметить с ходу. Во время тренировки кажется, что всё идёт гладко. Но есть три признака того, что алгоритм свернул не туда.
Высокая точность на обучении, низкая — на тесте
Хрестоматийный симптом переобучения. Дата-специалисты делят данные, с которыми будет работать модель, на две выборки — обучающую и тестовую.
Если нейросеть показывает точность 99% при работе с данными, на которых она училась, но при проверке на тестовом наборе еле выжимает 60% — у вас переобучение. Модель просто заучила ответы, но не поняла сути задачи. Это самый явный и легко измеряемый признак.
Рост или стагнация уровня ошибки на тестовой выборке
Представим на оси координат отношение времени обучения (по оси X) и ошибок (по оси Y). Построим отдельные графики для обучающего и тестового наборов данных. Сначала графики нырнут вниз и будут идти рядом. У переобученной модели уровень ошибок в тестовой выборке или встанет на месте, или поползёт вверх.
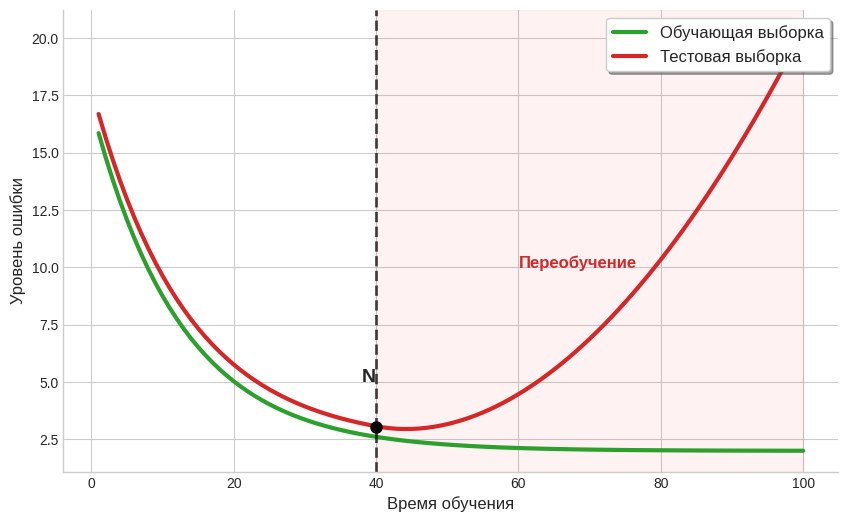
В точке N модель перестала учить полезный сигнал и начала учить шум. Всё, что происходит после этой точки расхождения — это переобучение.
Нестабильные прогнозы на новых данных
Переобученная модель становится капризной. Представьте, что вы сделали классификатор котов и собак. Переобученная нейросеть может уверенно распознать кота на уже увиденном фото, но если вы возьмёте это фото и немного измените освещённость (например, сделаете фон чуть темнее), алгоритм внезапно определит, что это собака.
Почему так происходит? Потому что переобученная модель зацепилась не за форму ушей и наличие усов, а, например, за тёмный фон, который в обучающей выборке случайно чаще встречался именно на фотографиях с собаками. Она выучила шум, а не полезный сигнал.
Полезный блок со скидкой
Если вам интересно разбираться со смартфонами, компьютерами и прочими гаджетами, и вы хотите научиться создавать софт под них с нуля или тестировать то, что сделали другие, — держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Причины возникновения переобучения нейросетей
Почему умные алгоритмы глупеют? На то есть три причины: недостаточный объём данных, избыточная сложность модели и шум в данных.
Недостаточный объём данных
Если у вас мало данных, модели слишком легко их запоминают. Допустим, вы хотите научить систему отличать спам от обычных писем и скормили ей всего 50 примеров спама. Случайно оказалось, что в 40 из них упоминается слово «Здравствуйте». Алгоритм решит, что «Здравствуйте» — главный признак спама. Ему просто не хватает разнообразия, чтобы понять, что мир сложнее, чем пара совпадений.
Избыточная сложность модели
В современных глубоких нейросетях настроены миллионы, а иногда и миллиарды параметров. Если ваша задача — предсказать цену квартиры по площади, этажу и району, то такая сложная нейросеть сама себя переиграет. Обладая кучей свободной памяти, она вместо поиска простой прямой линии проведёт запутанную кривую, которая пройдёт через все случайные выбросы цен в датасете. Слишком сложный метод для слишком простой задачи — гарантия переобучения.
Шум в данных
Данные редко бывают идеальными — какую-то часть составляет шум. Этот шум можно разделить на два типа: стохастический и детерминированный.
Стохастический шум — это обычные случайные ошибки. Например, при сборе данных оператор случайно ввёл цену квартиры 10 миллионов вместо 1 миллиона. Переобученная модель воспримет эту опечатку всерьёз и попытается выстроить вокруг неё свою логику.
Детерминированный шум — это слишком сложная концепция для модели. Если алгоритм не может осознать какую-то сложную концепцию в данных, она выглядит для него как шум. И он начинает придумывать ложные правила, чтобы хоть как-то этот шум себе объяснить. Так появляются знаменитые галлюцинации больших языковых моделей.
Чем опасно переобучение для нейросети
В учебных проектах переобучение — это просто повод похмуриться и переписать код. Но в реальной жизни переобучение нейросети стоит огромных денег, а иногда — здоровья и жизней.
Возьмём беспилотные автомобили. Если система управления машиной переобучится на тестовом полигоне, она выучит расположение конкретных деревьев, трещин на асфальте и теней от зданий на этой конкретной дороге. Выехав на реальную улицу незнакомого города, где трещины другие, а вместо деревьев — рекламные щиты, автопилот растеряется и может спровоцировать ДТП.
Другой пример — медицина. Алгоритм, предсказывающий риск развития диабета, переобучившись на данных одной конкретной больницы, может решить, что риск болезни зависит от того, каким аппаратом делали анализ, а не от уровня сахара в крови. В итоге врачи получат бесполезную систему, которая работать в других больницах просто не сможет.
Как бороться с переобучением: обзор методов
С диагнозом разобрались, теперь поговорим о лечении. У специалистов по данным есть несколько проверенных способов отучить модель зубрить и заставить её думать.
Регуляризация (L1 и L2)
Представьте, что мы вводим налог на сложность. Регуляризация примерно так и работает — мы штрафуем нейросеть, если она пытается выстроить слишком сложные и запутанные логические связи.
Представьте себе алгоритм для оценки недвижимости. Часто в данных, которые скармливают модели, помимо полезных признаков — площади, расположения и т. д. — есть информационный мусор, например, кличка соседского кота. Нейросеть не понимает смысла слов, а ищет любые совпадения. Если чисто случайно в обучающей выборке самые дорогие квартиры продавали соседи кота Барсика, переобученная модель решит: «Кота зовут Барсиком, накину миллион». Иначе говоря, присвоит этому признаку огромный математический вес. Но в реальной жизни прогноз сломается на первой же «убитой» однушке.
Регуляризация штрафует алгоритм за такие фокусы. Она бывает двух видов: L1 и L2.
L1-регуляризация работает как аудитор. Она физически обнуляет значимость мусорных признаков. Алгоритм просто вычёркивает кота из уравнения и оставляет только метраж и район.
L2-регуляризация больше похожа на демократический механизм: она не даёт ни одному признаку стать слишком весомым. Если модель решит, что цену квартиры формирует только расстояние до метро, отдав ему 95% влияния, L2 её образумит и заставит учесть ещё и этаж с ремонтом.
Увеличение объёма данных
Можно получить новые данные из старых. Этот подход особенно хорошо работает в компьютерном зрении. Если у нас есть всего 100 фотографий котов, мы можем каждую фотографию немного повернуть, отзеркалить по горизонтали, изменить яркость, обрезать края или добавить лёгкий графический шум. Из одной картинки мы получаем десять новых! Модели придётся выучить концепцию «кота», потому что зазубрить пиксели скачущей, меняющей цвет и размер картинки уже не выйдет.
В некоторых источниках это называют аугментацией данных (data augmentation). Не пугайтесь, если увидите — это все то же создание новых данных на основе старых.
Упрощение архитектуры модели
Иногда проще — значит, лучше. Если нейросеть слишком умная для ваших данных, сделайте её глупее. Порежьте число слоёв и нейронов, чтобы у алгоритма физически не хватило ресурсов на запоминание шума. Зажатый в жёсткие рамки, он будет вынужден запоминать только самые сильные и явные закономерности.
Ранняя остановка обучения
Помните график, где тренировочная ошибка падает, а валидационная начинает расти? Чтобы не дать графику тестовых данных уползти вверх, вводим правило — как только валидационная ошибка перестала падать и начала расти, останавливаем обучение. Так мы зафиксируем модель на пике способности к обобщению, не дав скатиться в зубрёжку.
Кросс-валидация
Чтобы убедиться, что наша модель действительно обобщает, а не просто удачно подогналась под конкретный тестовый кусок данных, используют кросс-валидацию.
Данные делят на несколько частей. Если данные поделили на пять частей, то и модель обучаем пять раз, и каждый раз в качестве теста используем новую часть, а обучаем на оставшихся четырёх. Если во всех пяти случаях модель показывает стабильно хороший результат, значит, она реально научилась решать задачу, а не вызубрила один удачный кусок.
Дропаут
Суть дропаута в том, что на каждой итерации обучения мы случайным образом «выключаем» определённый процент нейронов. Нейросеть больше не может полагаться на один конкретный нейрон, который зазубрил правильный ответ. Знания равномерно распределяются по всей сети, что делает её суперустойчивой к шуму и стрессу. По сути, вырубая нейроны, мы каждый раз обучаем слегка новую архитектуру сети, а итоговый результат работает как команда мастеров на все руки.

Переобучение и недообучение: в чём разница
Мы без конца ругаем переобучение, и, разумеется, за дело. Но есть и обратная сторона медали — недообучение.
Если переобученная модель — это зубрила, то недообученная — двоечник, который вообще не открывал учебник. Недообучение возникает, когда модель слишком простая для имеющихся данных. Например, вы пытаетесь описать сложную кривую продаж сезонного товара с помощью обычной прямой линии.
При недообучении алгоритм показывает неважные результаты как на тренировочной, так и на тестовой выборке. Ему просто не хватает математической гибкости, чтобы уловить логику. В машинном обучении важно найти золотую середину: баланс между недообучением и переобучением.
Почему иногда нужны переобученные модели
Может показаться, что переобучение — это то, с которым нужно бороться. Но в ИТ редко бывает что-то однозначное. Есть пара специфических сценариев, когда нам нужна именно переобученная модель.
Первый случай — полностью статичные и детерминированные среды, где новые данные никогда не выходят за рамки старых. Если вам нужна нейросеть, которая работает исключительно как продвинутая база данных, то 100% зазубривание обучающей выборки — это именно то, что вы ищете.
Второй случай — узкоспециализированные генеративные задачи. Например, алгоритмы переноса стиля. Если вы хотите, чтобы нейросеть взяла вашу фотографию и перерисовала её ровно в стиле картины Мунка «Крик», вам нужно переобучить модель на этой конкретной картине. Ей не нужно воспроизводить Ван Гога или Пикассо, зато нужно зазубрить каждый мазок только одного полотна.
Но для 99% повседневных бизнес-задач, где нужно делать предсказания в меняющемся мире, переобучение остаётся проблемой.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.