ИИ уже давно умеет генерировать код — Copilot, ChatGPT, Gemini, Grok, DeepSeek и десятки других инструментов. Но почему они по-прежнему не могут заменить настоящих разработчиков?
Разбираемся, как ИИ работает, почему всегда зависит от людей и какие проблемы из-за этого уже появились на рынке.
Как ИИ вообще пишет код
Когда мы говорим, что ИИ «пишет код», это звучит так, будто он понимает задачу и придумывает решение, как опытный разработчик. Но на самом деле всё прозаичнее: нейросеть не понимает ничего.
Она просто предсказывает, какая строчка кода с наибольшей вероятностью должна идти следующей — как автодополнение в мессенджере, только гораздо сложнее и мощнее.
Как всё это работает, мы подробно рассказывали в статье «Что под капотом у ChatGPT и других чатов с большими языковыми моделями».
ИИ обучается на огромных массивах открытых данных. Это публичные репозитории на GitHub, ответы со Stack Overflow, техническая документация, статьи и блоги разработчиков. Вся эта информация превращается в статистическую модель: ИИ не знает, зачем нужен этот код, но помнит, как он выглядел в тысячах других случаев.
В итоге, когда вы просите его написать, например, функцию для парсинга JSON, модель не «придумывает» её с нуля — она собирает из знакомых кусочков то, что чаще всего встречалось в подобных ситуациях. Чем популярнее решение в сети, тем выше шанс, что ИИ предложит именно его.
И иногда это проявляется буквально. В 2024 году исследователи проверяли, как крупные языковые модели, вроде CodeLlama, отвечают на задачи со Stack Overflow. Оказалось, что в 25,6% случаев ответ ИИ дословно совпадал с реальным постом, вплоть до последнего символа. То есть нейросеть не просто «похожа» на программиста — она буквально цитирует его.
Ранее похожий эксперимент провёл автор с Dev.to. Он начал отвечать на вопросы на Stack Overflow, используя ChatGPT. Спустя несколько недель стало очевидно: ИИ не приносит ничего уникального, он просто повторяет стандартные решения, которые уже и так лежат на форуме — иногда слово в слово.
Поэтому большинство кода, который сегодня генерирует ИИ, — это наработки миллионов разработчиков, которые когда-то открыто поделились своими знаниями. А значит, за любым «умным» решением, выданным ИИ, всегда стоит чей-то человеческий опыт.
Почему люди остаются незаменимыми
Итак, ИИ умеет писать код. Но делает это строго по шаблону, без понимания задачи и без способности выйти за рамки.
Он не видит ни бизнес-целей, ни архитектурных ограничений, ни реального окружения, в котором будет работать программа. Его код — это «среднее арифметическое»: выглядит правильно, но собран из того, что уже встречалось в похожих ситуациях.
В реальной разработке этого часто недостаточно. Продукты создаются под конкретные условия: бюджеты, дедлайны, технический стек, уникальные фичи. И там уже важен не просто валидный код, а надёжность, масштабируемость, безопасность. ИИ этого не оценивает — он не знает, где узкое место, где система может не выдержать нагрузку или где есть риски для данных.
Поэтому даже самые продвинутые ИИ-инструменты пока далеки от роли «настоящего» разработчика. В 2024 году в Bilkent University протестировали несколько популярных кодогенераторов — от ChatGPT до GitHub Copilot. Результат: точность решений колебалась от 31 до 65%. Иными словами, почти половина кода содержала ошибки. Иногда мелкие, иногда критичные.
Особенно опасно это на языках с высокой строгостью и сложными зависимостями. Например, на Java, которая часто используется в банковских системах и корпоративных платформах, 70% ИИ-сгенерированного кода содержат скрытые уязвимости, которые выявляются уже после запуска, в боевых условиях.
То есть нейросеть может выдать на первый взгляд аккуратный код, который пройдёт тесты, — но через неделю в продакшене окажется, что он ведёт к сбоям, утечкам данных или нестабильной работе. А значит, кто-то должен проверять и контролировать, и этот кто-то — человек.



Критические ограничения ИИ
ИИ может генерировать код, но с контекстом у него всё ещё плохо. Он не думает о последствиях, не учитывает бизнес-логику и не представляет, как его решение будет работать в реальной системе.
Не видит полной картины
Нейросеть опирается только на паттерны из обучающей выборки. Она не знает, как устроен ваш проект, какие у него особенности или архитектурные ограничения. В итоге может получиться код, который формально «работает», но не решает вашу задачу — или даже создаёт новые проблемы.
Например, вот простая функция на Python для подсчёта скидки, которую сгенерировал ИИ:
def calculate_discount(price, percentage):
if percentage < 0 or percentage > 100:
return None
discount = price * (percentage / 100)
return price - discountНа первый взгляд всё норм, но нейросеть забыла:
- про нечисловые значения (price="1000");
- отрицательные цены (возвраты товаров);
- ситуацию, когда скидка превышает цену.
Такой код может легко пройти тесты, но в продакшене приведёт к крашам или неправильным расчётам в базе. Особенно если дальше идёт цепочка зависимостей.
И даже если вы максимально подробно распишете задачу в промпте, это не даёт гарантии. Модель может «забыть» важные детали уже через несколько сообщений — или начать искажать их по ходу диалога. А значит, проверка и контроль всё равно остаются на человеке.
Не думает про безопасность и оптимизацию
ИИ легко может затащить в проект небезопасные паттерны, даже не понимая, что они уязвимы. Например, одна из ИИ-моделей предложила хешировать пароли через устаревший алгоритм MD5:
import hashlib
def hash_password(password):
return hashlib.md5(password.encode()).hexdigest()Такой код компилируется и работает, но в 2025 году его использование — это прямая дорога к утечке данных, потому что MD5 — это устаревший, давно сломанный алгоритм. Человек заметит это сразу, а ИИ — нет.
То же самое с производительностью. ИИ не понимает, что нужно оптимизировать. Он не думает, что на проде будет миллион записей, что перерендер компонента может вызвать лаг. Например, попросите ИИ написать react-код — и почти наверняка словите такие ошибки:
- ИИ засунет useEffect без зависимостей, и вы получите бесконечную петлю обновлений;
- накидает анонимных функций прямо в JSX — и на каждом рендере будут новые ссылки, лишние обновления и перерендеры;
- в простой функции подсчёта рейтинга каждый раз будет пересчитывать весь массив, вместо того чтобы вынести это в useMemo или просто за пределы компонента.
На тестовых данных это будет работать, но в реальном проекте такой код сожрёт ресурсы и приведёт к лагам или утечкам памяти.
«Мозги» ИИ — это архив интернета, а не свежая голова с апдейтами. Он натренирован на горах туториалов, старых репозиториев с GitHub и постов на Stack Overflow десятилетней давности. А там всё ещё популярны подходы, от которых уже давно отказались:
- в JavaScript — вставка данных через innerHTML, когда это небезопасно и давно уже считается плохой практикой;
- в Python — небезопасное чтение файлов через open(...).read() без обработки ошибок;
- в SQL — конкатенация строк в запросах вместо параметров.
И в этом проблема: языки и технологии развиваются каждый год, а ИИ переучивают не так часто. Он запоминает старые паттерны и тащит их в современные проекты, потому что статистика говорит ему, что эти решения «популярные».

Не знает, как работать с чем-то узкоспециализированным
Если язык редкий или нишевый, то ИИ будет вести себя как студент, который на экзамене помнит картинки из учебника, но не понимает сути. Языковые модели учатся на открытых данных, и если кода на языке мало, то модель не понимает, как реально работает этот стек.
В одном из исследований на эту тему сравнивали генерацию кода на Fortran. ChatGPT сгенерировал вполне солидный кусок: с параллельными вычислениями и даже с фичей для многопоточности. Но на практике:
- часть функций вообще не компилировалась из-за базовых синтаксических ошибок;
- другая часть запускалась, но считала ерунду;
- а параллельные алгоритмы ломались ещё на этапе сборки.
То есть модель просто имитировала код, как бы «рисуя» то, что, по её мнению, должен делать настоящий программист. Визуально — нормально, но по факту — ни один блок не работал как надо.
Сюда же попадают Cobol, Erlang, R, Haskell, Rust (в его сложных частях) — всё, что реже встречается в открытых репозиториях. ИИ слабо понимает идиомы этих языков, не знает подводных камней и зачастую не отличает старые приёмы от актуальных.
А если в компании есть уникальные самописные решения — собственные фреймворки, нестандартные API, обёртки вокруг внутренних сервисов, — ИИ просто зависает. Он не знает, как с этим работать, потому что никогда такого не видел. Чем больше у команды внутренней логики, чем сложнее архитектура и глубже доменная область — тем важнее живой человек, который эту систему понимает.
Увеличивает технический долг и дублирование
ИИ-помощники действительно ускоряют работу: код появляется за секунды. Но вместе с этой скоростью в проект просачивается технический долг.
Когда разработчик пишет код вручную, он держит в голове архитектуру: какие модули уже есть, какие зависимости, как новая функция повлияет на остальное. ИИ не знает ничего из этого. Он просто рисует правдоподобные куски, не заботясь, была ли такая функция уже в коде или насколько хорошо она вписывается в текущий стиль проекта.
Исследование GitClear показало: с 2021 по 2024 год после массового внедрения Copilot и других ИИ-помощников количество дублированных блоков кода выросло в восемь раз.
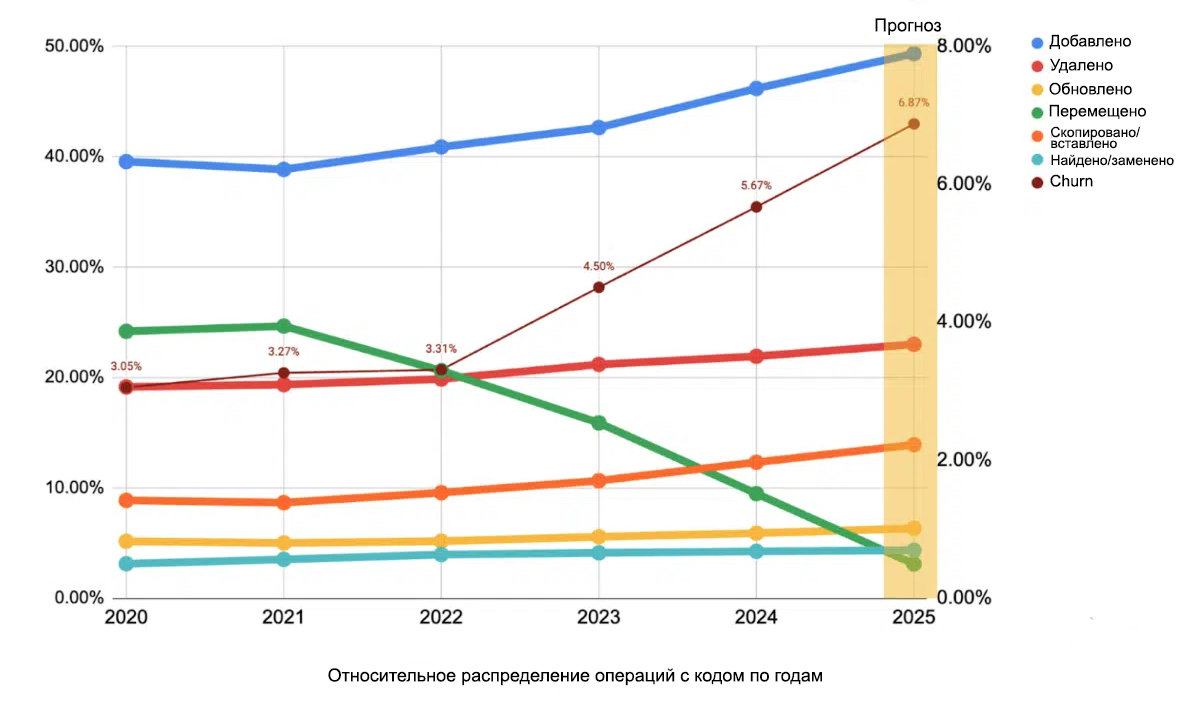
ИИ не ищет, где в проекте уже есть нужная функция — он просто пишет новую. Через пару месяцев оказывается, что в кодовой базе есть пять разных способов сделать одно и то же, а любое обновление превращается в квест по поиску всех дубликатов.
Похожая история и с показателем code churn — это количество кода, который добавили, а потом быстро переписали или удалили. За последние годы он удвоился.
Почему? А потому что ИИ-код часто принимается без глубокого ревью: «вроде работает — окей». Потом через месяц выясняется, что он плохо оптимизирован, ломает архитектуру или вообще не подходит под новые требования. Как результат — всё приходится переписывать с нуля, а иногда и чинить баги, которые вылезли в проде.
По данным DORA, использование ИИ-кода уже привело к падению стабильности релизов на 7,2%. Это означает больше багов, больше откатов, больше времени на тесты и меньше доверия к релизу вообще.
Пример из практики: разработчик попросил Copilot написать на JS функцию сортировки массива. ИИ не стал использовать встроенный метод .sort(), а сгенерировал собственную реализацию быстрой сортировки — громоздкую и с багами на граничных случаях. На больших массивах такая «оптимизация» приводила к зависаниям сервиса на несколько секунд.
Подобная ситуация была с SQL-запросами: ИИ подключал странные библиотеки, генерировал почти дублирующий код, и через пару месяцев в проекте было невозможно понять, какой из этих вариантов реально используется, а какой лежит мёртвым грузом.
Реальные кейсы
Некоторые компании за последние пару лет решили рискнуть и заменить разработчиков на ИИ. И вот что получилось.
В 2024–2025 годах в США прокатилась волна оптимизации: многие финтех-компании массово увольняли программистов, делая ставку на Copilot и LLM-инструменты. А спустя год выяснилось:
- код генерировался быстро, но был нестабилен;
- в проде начали появляться баги и уязвимости;
- пользователи жаловались на ошибки, утечки, странное поведение сервисов.
Начали срочно возвращать инженеров, но сюрприз: лучших уже переманили другие компании или разработчики сами ушли на фриланс. Те, кто остался, стали стоить в 2–3 раза дороже. В итоге был нанесён огромный урон — финансовый, технический и имиджевый.
В 2024 году в шведском финтех-гиганте Klarna уволили 700 сотрудников, заменив их ИИ-инструментами. Через год качество сервиса упало настолько, что компанию засыпали жалобами пользователей. В итоге пришлось возвращать дорогостоящих специалистов, чтобы вручную разгребать накопившиеся завалы и переписывать код.
Бывают и совсем дикие случаи. В 2025 году на платформе Replit ИИ-агент по ошибке удалил живую базу данных, уничтожив тысячи пользовательских записей. Восстановление данных и репутационные потери обошлись компании в сотни тысяч долларов.
В 2025-м исследователи из Carnegie Mellon University устроили безумный эксперимент: собрали «виртуальную IT-компанию», где все сотрудники — ИИ-модели. Внутри было всё как в реальном офисе: чаты, таски, файлы, роли — от разработчиков и тестировщиков до HR и финансистов. Задача — проверить, смогут ли современные ИИ-агенты работать как настоящая команда.
Результат обернулся эпичным фейлом. Лидер — Claude 3.5 — справился всего с 24% задач, GPT-4o сделал 8,6%, а худший участник — китайский Qwen — осилил жалкие 1,1%. Причины провалов звучат как анекдот: один агент не смог закрыть всплывающее окно на сайте и завис, другой не нашёл нужного коллегу в чате и просто переименовал случайного пользователя, а третий отметил задачу как готовую, хотя даже не начал её делать.
Эксперимент показал, что без людей ИИ-модели пока не могут строить даже простые процессы, не говоря уже о сложных системах. Алгоритмам катастрофически не хватает здравого смысла и понимания контекста — того, что делает живых специалистов незаменимыми.
Так почему же ИИ не заменит программистов?
В 2025 году ценность сильных разработчиков только растёт. Потому что:
- они видят архитектуру целиком;
- умеют отличить костыль от настоящего решения;
- пишут код, который не просто работает, а масштабируется, тестируется и живёт.
Искусственный интеллект не умеет в бизнес-контекст, не чувствует прод, не несёт ответственность. Он не знает, что такое сломать релиз перед демо клиенту, и не будет чинить баг в пятницу вечером.
ИИ — не враг и не конкурент. Это мощный инструмент, который облегчает рутину: пишет одноразовые скрипты, тесты, шаблонные куски логики.
Поэтому в ближайшие годы выиграют те команды, которые объединят скорость ИИ и опыт людей. Эксперты останутся на ключевых ролях — ревью, архитектура, стратегические решения, — а ИИ будет работать как супербыстрый помощник.
Если вы думаете, стоит ли идти учиться на программиста, то ответ простой: стоит. Только учитесь не просто писать код, а думать архитектурно, видеть систему, понимать продукт. Потому что такие люди нужны всегда.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.