


LLM кажется простой штукой: отправил запрос, получил ответ, заплатил за токены. Поэтому первая идея оптимизации обычно звучит так: надо сделать промпт короче. Это кажется логичными потому что меньше токенов — меньше счёт.
Но в реальных AI-агентах все сложнее. Если агент делает не один запрос, а цепочку из 10, 20 или 50 шагов, появляется другой вопрос, который важнее промпта: может ли модель переиспользовать уже обработанную часть запроса? За это отвечает prefix cache — кэш начала промпта.
И вот тут появляется парадокс: короткий промпт может оказаться дороже длинного, если он каждый раз немного меняется.
Что такое prefix cache
Когда модель получает запрос, она сначала читает весь входной текст: системный промпт, описание инструментов, историю диалога, пользовательский вопрос. Этот этап называется prefill. Он нужен, чтобы модель подготовила внутренние данные для генерации ответа.
Если начало запроса повторяется много раз, провайдер или ваш inference-сервер может не считать его заново. Он берет уже подготовленные данные из кэша. Это и есть prefix cache.
Например, у вас есть корпоративный ассистент. В каждом запросе у него один и тот же большой системный промпт, одни и те же правила безопасности, одни и те же tools. Меняется только вопрос пользователя. В таком случае начало запроса можно переиспользовать.
Если кэш сработал, входные токены стоят дешевле, а ответ начинает приходить быстрее. Если не сработал — модель снова полностью читает длинный промпт.
Почему обычный прайс-лист обманывает
В прайс-листе обычно видно цену входных и выходных токенов. Но для реальной стоимости этого мало.
Нам понадобится формула — сначала просто посмотрим, потом объясним всё важное:
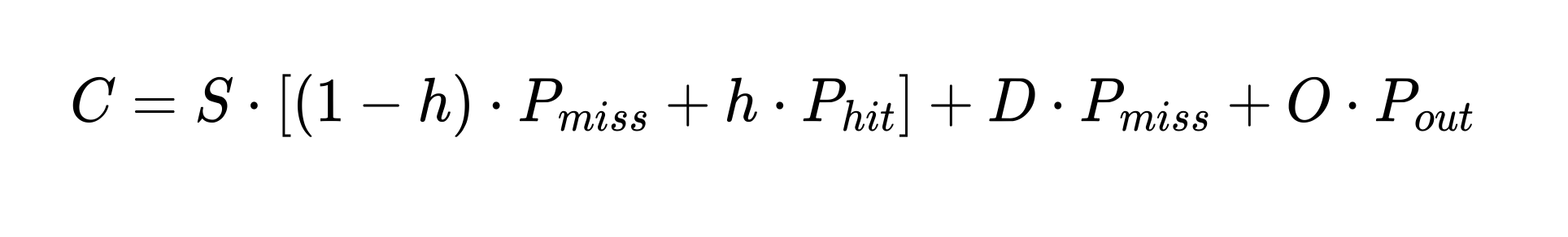
Теперь разбираем, что есть что:
- S — от слова Static, стабильная часть.
Это то, что повторяется между запросами: system prompt, tools, RAG-контекст. - D — от Dynamic, динамическая часть.
Это то, что меняется в каждом запросе: вопрос пользователя, текущее время, request ID, персональные данные. - O — от Output, ответ модели.
Это токены, которые модель сгенерировала в ответе. - h — от hit rate, доля попаданий в кэш.
Например, h = 0.9 значит, что кэш сработал в 90% случаев.
Допустим, у вас 10 000 токенов повторяющегося контекста, 200 токенов нового вопроса и 300 токенов ответа. Если кэш срабатывает в 90% случаев, вы платите гораздо меньше, чем при hit rate 30%. При этом модель, размер промпта и количество запросов могут быть теми же самыми.
Получается, что дешёвая модель не всегда дешевле в проде. Если у неё хуже работает кэш или вы неправильно собрали промпт, итоговая цена может вырасти. Сравнивать надо не цену одного миллиона токенов, а effective cost или реальный расход токенов — стоимость с учётом кэша, промахов и длины ответа.
Полезный блок со скидкой
Оптимизация LLM-систем — это не только выбор модели и сокращение промпта. Нужно понимать, как работают токены, кэш, tools, RAG и длинные агентные цепочки.
Разобраться в этом системно можно на курсах Практикума по нейросетям, разработке и AI-инженерии. Держите промокод на любую платную программу: KOD (можно просто нажать). Он даст скидку при покупке.



Как один timestamp ломает экономику
Prefix cache работает строго: у запросов должно совпадать начало. Не примерно, не по смыслу, а буквально. Если в начале появился другой символ, кэш дальше уже не используется.
Смотрите, есть классическая ошибка — положить в системный промпт текущее время:
# импортируем модуль для работы со временем
from datetime import datetime
# собираем системный промпт
system = f"Сегодня: {datetime.now()}. Ты — корпоративный ассистент."На вид всё нормально. Ассистент знает текущую дату и время. Но для кэша это катастрофа, потому что каждый запрос начинается по-новому.
Лучше оставить системный промпт стабильным, а динамику перенести дальше:
# импортируем модуль для работы со временем
from datetime import datetime
# оставляем системный промпт одинаковым для всех запросов
system = "Ты — корпоративный ассистент."
# кладем текущее время в пользовательский контекст
user_message = f"[время: {datetime.now()}] помоги ответить на вопрос пользователя"Так модель все еще получает время, но самое дорогое начало промпта остается одинаковым.
Та же проблема возникает с user_id, session_id, request_id, названием компании и любыми полями, которые меняются от запроса к запросу. Их нельзя класть в начало, если вы хотите высокий cache hit rate.
Tools тоже часть промпта
В LLM-агентах есть еще одна ловушка — tools. Это как руки модели: без tools LLM умеет только отвечать на вопросы, а tools дают ей доступ к другим сервисам, которыми она может управлять.
Как это работает: обычная LLM сама по себе умеет только читать текст и писать текст. Она не может сама открыть CRM, создать задачу или сходить в базу знаний. Но разработчик может дать ей специальные описания внешних функций, которые модель может вызвать, когда ей нужно что-то сделать. Это и есть tools.
Пример:
Ты — офисный ассистент. У тебя есть инструменты:
— найти документ в базе знаний;
— создать задачу;
— посмотреть календарь;
— отправить письмо;
— найти клиента в CRM.
Так модель получает не просто вопрос пользователя, а ещё список доступных действий. И дальше решает: ответить текстом или вызвать один из tools.
Например, пользователь пишет:
Найди последнюю переписку с клиентом Ивановым и создай задачу менеджеру.
Модель сама не знает, кто такой Иванов и где его переписка. Поэтому она может сделать цепочку:
вызвать tool search_crm, чтобы найти клиента;
вызвать tool read_messages, чтобы посмотреть переписку;
вызвать tool create_task, чтобы создать задачу;
написать пользователю: «Готово, задача создана».
То есть tool — это мост между LLM и реальной системой.
Теперь смотрите, как это связано с промптами. Разработчику кажется логичным: если у агента 30 tools, зачем отправлять все? Давайте на каждом шаге выберем 5–7 самых подходящих. Промпт станет короче. И для одного запроса это правда может быть выгодно. Но в агентном цикле такой подход часто ломает кэш.
Допустим, на первом шаге агент получил tools A, B, C. На втором — A, C, E. На третьем — B, D, F. Для человека это все тот же агент. Для prefix cache это каждый раз новый промпт, потому что список tools находится в начале запроса.
В итоге короткий промпт проигрывает длинному:
# на первом шаге агенту доступны одни инструменты
tools_step_1 = ["search", "calendar", "crm"]
# на втором шаге список изменился
tools_step_2 = ["search", "mail", "tasks"]
# для кэша это уже другое начало запроса
same_prefix = tools_step_1 == tools_step_2Решение не в том, чтобы каждый раз пересобирать список tools. Лучше держать описания инструментов стабильными, а отдельно ограничивать, какие из них можно вызвать на конкретном шаге. Например, агент всегда знает про все инструменты CRM, календаря и задач, но сейчас ему разрешено пользоваться только поиском по CRM и созданием задачи. Так начало промпта остается одинаковым, а значит, prefix cache продолжает работать.

История должна расти в конец
Главная мысль: не надо менять то, что стоит раньше растущей истории диалога. Кэш хорошо работает, когда диалог растет в режиме append-only. То есть старые сообщения остаются на месте, новые добавляются в конец.
Проблемы начинаются, когда система сжимает историю: переписывает старые сообщения, суммаризирует начало диалога, меняет системный промпт, переставляет блоки местами. Это называется summarization.
Пример плохого варианта:
# создаем новую историю вместо старой
messages = [
{"role": "system", "content": "новая версия системного промпта"},
{"role": "assistant", "content": "краткое саммари прошлых шагов"},
{"role": "user", "content": "новый вопрос"},
]Для модели это нормальный запрос. Но для кэша это почти новая сессия, потому что старое начало больше не совпадает. Более безопасный подход — не трогать начало, а добавлять новые данные в хвост:
# берем старую историю без изменений
messages = original_history.copy()
# добавляем саммари в конец, а не заменяем начало
messages.append({"role": "assistant", "content": "саммари для следующих шагов"})
# добавляем новый вопрос пользователя
messages.append({"role": "user", "content": "новый вопрос"})Это не значит, что сжатие истории в короткое резюме вредно. Иногда без этого нельзя, потому что контекст слишком большой. Но это не бесплатная оптимизация. Вы уменьшаете размер истории, но можете потерять кэш.
Почему кэш может не сработать даже с правильным промптом
Даже если промпт собран аккуратно и его начало не меняется, кэш все равно может не сработать. Обычно есть две причины: запрос попал не туда или кэш уже исчез.
Представьте, что у сервиса не один сервер с моделью, а несколько. Это делают для нагрузки: если пользователей много, запросы распределяют между разными машинами. На одной машине уже мог сохраниться кэш для вашего промпта, а на другой — еще нет. Что может произойти:
- Первый запрос ушёл на сервер №1. Он обработал длинный системный промпт и сохранил его начало в кэше.
- Второй похожий запрос должен был бы использовать этот кэш.
- Но если балансировщик отправил его на сервер №2, там такого кэша еще нет. Сервер №2 снова читает весь промпт с нуля.
Так может происходить постоянно: один запрос уходит на первый сервер, второй — на второй, третий — на третий. Промпт одинаковый, но каждый сервер прогревает свой кэш отдельно. В итоге кэш вроде бы есть, но пользы от него мало.
Поэтому в продакшене используют маршрутизацию с учетом кэша. Проще говоря, систему настраивают так, чтобы похожие запросы по возможности попадали на тот сервер, где такой промпт уже обрабатывался. Иногда для этого используют специальный ключ — например, идентификатор ассистента, версии промпта или сценария. По этому ключу система понимает: «Такие запросы лучше отправлять туда же, куда и раньше».
Вторая причина — время жизни кэша. Кэш не хранится вечно. Если похожие запросы приходят редко, сохранённое начало промпта может исчезнуть до следующего обращения. Тогда система снова будет читать промпт полностью.
Есть и другая ситуация: кэша слишком много. Например, сервис одновременно обслуживает десятки разных ассистентов, у каждого свой длинный системный промпт и свой набор инструментов. Память под кэш ограничена, поэтому старые данные начинают вытесняться новыми. Снаружи это выглядит странно: один раз кэш сработал, потом не сработал, потом снова сработал. На деле система просто не всегда успевает сохранить нужный кусок промпта.
Поэтому недостаточно один раз включить кэш. За ним нужно следить: смотреть, сколько токенов реально берется из кэша, как меняется время до первого токена ответа и не падает ли доля попаданий после деплоя, роста нагрузки или изменения числа серверов.
Если совсем коротко: хороший промпт — это только половина дела. Нужно, чтобы похожий запрос попал на нужный сервер, а сохраненный кэш не успел исчезнуть.
Минимальная проверка перед деплоем
Перед деплоем нужно дебажить LLM-систему так же, как любой другой сервис: проверить стабильность префикса, зафиксировать метрики и сравнить поведение до и после изменений.
Самый простой способ — записывать в логи короткий хэш начала промпта: системный промпт и список tools. Если хэш на каждом шаге разный, значит, система каждый раз отправляет модели немного другой префикс. В таком случае prefix cache будет работать хуже или не будет работать вообще.
# импортируем модуль для хэширования
import hashlib# импортируем модуль для стабильной json-сериализации
import json# объявляем функцию, которая считает хэш начала запроса
def prefix_hash(system_prompt, tools): # собираем только ту часть, которая должна быть стабильной
prefix = {
"system": system_prompt,
"tools": tools,
}
# превращаем объект в json с фиксированным порядком ключей
text = json.dumps(prefix, sort_keys=True, ensure_ascii=False)
# считаем sha256 от получившейся строки
digest = hashlib.sha256(text.encode("utf-8")).hexdigest()
# возвращаем короткую версию хэша для логов
return digest[:12]Что смотреть в логах:
- cached_tokens или cache_read_input_tokens.
- prefix_hash.
- Количество tools.
- TTFT — время до первого токена.
- Изменения после деплоя, A/B-теста, смены SDK или числа реплик.
Если prefix_hash меняется на каждом шаге, кэш почти наверняка ломается. Если хэш стабильный, но cached_tokens низкие, надо смотреть роутинг, TTL и вытеснение кэша.
Главное правило
В одиночном запросе короткий промпт почти всегда дешевле длинного. В агенте это уже не так.
Если агент проходит много шагов, важнее стабильность начала запроса. Большой, но стабильный блок tools может быть дешевле маленького, но плавающего списка. Длинный системный промпт может быть дешевле короткого, если короткий каждый раз пересобирается. Summarization может уменьшить контекст, но сломать кэш.
Правило простое: сначала стабилизируйте начало запроса, потом сокращайте промпт. Иначе можно случайно оптимизировать токены в одном вызове, но увеличить стоимость всей агентской сессии.
Советуем дополнительно почитать по теме:
20 AI GitHub-репозиториев для разработчика в 2026 году — подборка инструментов для локального инференса, RAG, AI-агентов и разработки из терминала: от Ollama и vLLM до Claude Code и Gemini CLI.
AI-скиллы для агентов: что это и как написать SKILL.md — как вынести повторяющиеся инструкции из диалога в отдельный навык, настроить автотриггеринг и не загружать агенту весь контекст на каждую задачу.
15 скиллов для AI-агентов: установка и как работает в 2026 — готовые навыки для Claude Code, Cursor и других агентов: как устанавливать их через терминал и подключать только тогда, когда они нужны.
ИИкономика: токены, GPU и бигтех — кто реально зарабатывает на ИИ — как токены, вычисления, дата-центры и API складываются в экономику генеративного ИИ и почему цена модели — это не только цифра в прайс-листе.
Бонус для читателей
Если вам интересно погрузиться в мир ИИ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.











