Большинство алгоритмов машинного обучения только кажутся черными ящиками, а на деле опираются на строгую математику. Логистическая регрессия, наивный Байес и вариационные автокодировщики работают как вероятностные модели. Базовая теория вероятности для ML закладывает фундамент, без которого сложно понять поведение алгоритма и интерпретировать его результаты.
В этом гайде разберем условную вероятность, теорему Байеса, виды распределений и метод максимального правдоподобия. Все сразу с формулами и примерами кода на Python, так что можете сохранять статью и использовать в качестве шпаргалки.
Базовые понятия: событие, вероятность, случайная величина
Сперва разберемся, как именно формулы описывают случайности и какие базовые характеристики помогают оценивать разброс данных.
Событие и аксиомы вероятности
Любая вероятностная модель начинается с пространства элементарных исходов — всех возможных результатов нашего эксперимента. В машинном обучении таким экспериментом часто выступает прогноз: кликнет пользователь на баннер или нет (задача бинарной классификации).
Вся теория вероятностей держится на трёх простых аксиомах Колмогорова:
- Вероятность любого события A всегда неотрицательна:
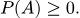
- Вероятность достоверного события (того, что произойдет хотя бы один из всех возможных исходов) равна единице:
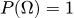
- Если события несовместны (не могут произойти одновременно, как выпадение орла и решки), вероятность их объединения равна сумме их вероятностей:
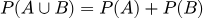
Случайная величина: математическое ожидание и дисперсия
Случайная величина принимает числовые значения в зависимости от исхода эксперимента. Две главные характеристики случайной величины:
Математическое ожидание
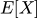
или
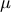
— среднее значение, вокруг которого группируются данные.
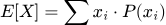
Дисперсия
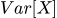
или
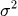
— мера разброса. Показывает, насколько сильно значения отклоняются от матожидания.
Обе характеристики вычисляются в NumPy при помощи встроенных функций:
# Импортируем библиотеку для работы с массивами
import numpy as np
# Задаем массив значений (например, оценки пользователей от 1 до 5)
data = np.array([4, 5, 3, 4, 5, 2, 4, 5, 5, 3])
# Вычисляем математическое ожидание (среднее)
mean_value = np.mean(data)
# Вычисляем дисперсию
variance_value = np.var(data)
# Выводим результаты
print(f"Математическое ожидание: {mean_value}")
print(f"Дисперсия: {variance_value}")Результат в консоли:
Математическое ожидание: 4.0
Дисперсия: 1.0Условная вероятность и независимость событий
В реальных задачах события редко происходят изолированно друг от друга. Обычно аналитиков интересует, как новая полученная информация меняет исходный прогноз и связаны ли конкретные признаки объекта между собой.
Формула условной вероятности
Алгоритмы ML постоянно используют условную вероятность. Она отвечает на вопрос: «Как изменится вероятность события A, если мы точно знаем, что событие B уже наступило?». Обозначают это как:
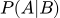
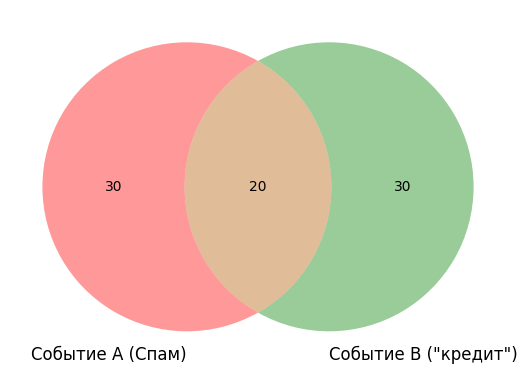
Классический пример для спам-фильтров: какова вероятность, что письмо относится к спаму — событие A, если в нём есть слово «кредит» — событие B?
Формула условной вероятности выглядит так:
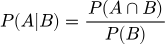
Где
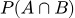
— вероятность того, что произойдут оба события вместе (письмо окажется спамом И будет содержать слово «кредит»).
Независимость и совместная вероятность
События независимы, если наступление одного не меняет вероятность другого. Тогда их совместная вероятность равна произведению вероятностей:
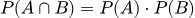
В ML часто встречается аббревиатура i.i.d. (independent and identically distributed). Большинство алгоритмов предполагают, что элементы в обучающей выборке независимы и одинаково распределены. При прогнозировании цен на квартиры модель считает, что цена одной квартиры никак не влияет на цену другой. В реальности случаются исключения, но о них поговорим в другой раз.
# Задаем вероятности независимых событий
# Вероятность того, что клиент откроет письмо
prob_open = 0.2
# Вероятность того, что клиент перейдет по ссылке, если открыл
prob_click = 0.05
# Вычисляем совместную вероятность двух независимых событий
prob_both = prob_open * prob_click
# Выводим результат
print(f"Вероятность открытия и клика: {prob_both}")Результат в консоли:
Вероятность открытия и клика: 0.010000000000000002Полезный блок со скидкой
Теория вероятности — это фундамент. Следующий шаг — научиться строить на нём реальные модели, понимать архитектуры и развиваться в сторону ML-инженера и зарабатывать больше, — держите промокод Практикума на любой платный курс: KOD (можно просто нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
Теорема Байеса и байесовский вывод
Байесовский метод — один из самых полезных инструментов в арсенале дата-саентиста. Правило помогает обновлять вероятности гипотез по мере поступления новых данных и служит основой для целого класса классификаторов.
Формула и термины
Теорема Байеса позволяет обновлять прогнозы при появлении новых данных. По структуре формула напоминает перевернутую версию условной вероятности.
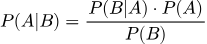
Разберём по частям:
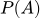
- (априорная вероятность). Убеждения до получения новых данных. Например, базовая доля спама во всем ящике (20%).
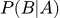
- (правдоподобие). Вероятность увидеть конкретные данные (слово «кредит») при условии, что гипотеза письмо — спам верна.
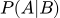
- (апостериорная вероятность). Наше новое знание. Вероятность того, что письмо — спам, при условии, что мы встретили слово «кредит».
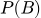
- (константа). Полная вероятность увидеть эти данные при любых условиях.
Применение в ML — наивный байесовский классификатор
Алгоритм «наивный Байес» применяет теорему для классификации. Название «наивный» связано с сильным допущением: все признаки объекта абсолютно независимы друг от друга. Несмотря на простоту, алгоритм работает потрясающе быстро и эффективно, особенно с текстами.
«Из коробки» метод доступен в scikit-learn:
# Импортируем нужные модули
import numpy as np
from sklearn.naive_bayes import GaussianNB
# Создаем синтетические данные с нормальным разбросом
# 4 объекта, 2 признака (например, количество ссылок и стоп-слов)
X_train = np.array([[-2, -2], [-1, -1], [1, 1], [2, 2]])
# Задаем классы: 0 (не спам) и 1 (спам)
y_train = np.array([0, 0, 1, 1])
# Инициализируем классификатор
model = GaussianNB()
# Обучаем модель на данных
model.fit(X_train, y_train)
# Создаем новое письмо для проверки.
# Координаты [0.2, 0.2] ближе к классу 1, но не совпадают с ним идеально.
X_test = np.array([[0.2, 0.2]])
# Предсказываем вероятности принадлежности к каждому классу
probabilities = model.predict_proba(X_test)
# Выводим вероятности
print(f"Вероятности классов [не спам, спам]: {probabilities}")Результат в консоли:
Вероятности классов [не спам, спам]: [[0.00816257 0.99183743]]Вероятностные распределения в ML
Инженерам нужно понимать вероятностные распределения, чтобы верно оценивать форму данных. Базовые функции для работы с ними в Python собраны в модуле scipy.stats (советуем заглянуть в официальную документацию scipy.stats). А в классическом справочнике NIST/SEMATECH вы найдете формулы вероятностных распределений. Если нужно шире разобраться в инструментах, посмотрите свежую подборку Python-библиотек для работы с данными.
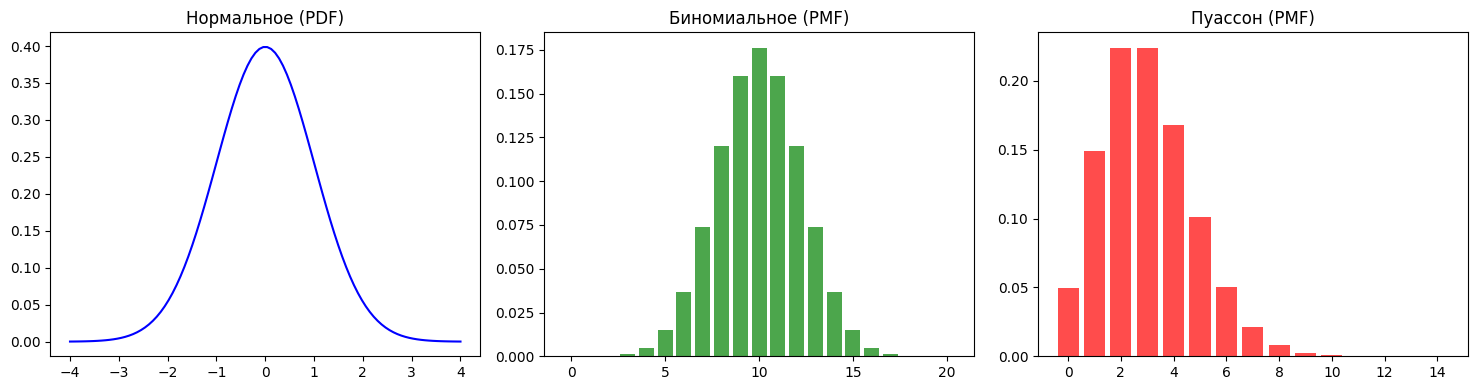
Нормальное распределение
Классический «колокол» Гаусса. Если вы используете линейную регрессию с метрикой среднеквадратичной ошибки (MSE), то неявно предполагаете нормальное распределение ошибок модели.
Формула функции плотности вероятности (PDF):
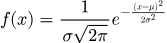
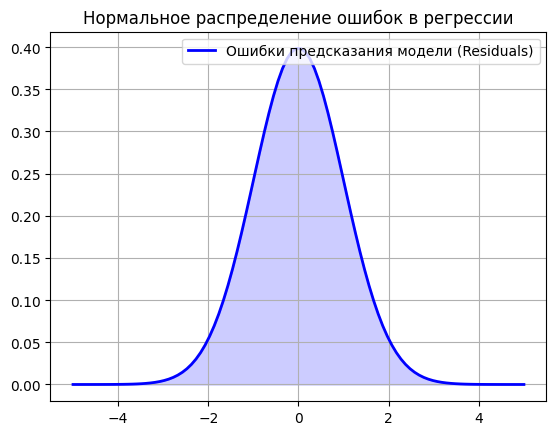
На графике показано классическое нормальное распределение, которое часто встречается при оценке качества моделей. Например, алгоритм линейной регрессии неявно предполагает, что ошибки его предсказаний распределены именно по такому «колоколу»: мелкие погрешности случаются постоянно — это высокая вероятность в центре графика, а крупные промахи крайне редки — хвосты распределения стремятся к нулю.
Распределение Бернулли, биномиальное и категориальное распределения
Распределение Бернулли описывает один эксперимент с двумя исходами — бросок монеты или выбор между кликом на баннер и игнором.
Вероятность успеха:
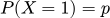
А неудачи:
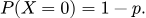
Биномиальное распределение описывает сумму нескольких независимых экспериментов Бернулли. Например, сколько раз выпадет орел, если бросить монету 10 раз.
Формула вероятности для k успехов в n испытаниях:
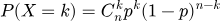
Распределение Пуассона
Распределение Пуассона стоит особняком. Оно моделирует количество случайных событий, происходящих в фиксированный промежуток времени или пространства. В машинном обучении оно идеально подходит для предсказания числа кликов по рекламе за час, количества обращений в техподдержку или числа бракованных деталей на конвейере.
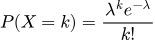
Категориальное распределение
Категориальное распределение, часто называемое мультинулли, расширяет логику Бернулли на ситуации с количеством исходов больше двух. В машинном обучении эта математическая модель описывает работу классификаторов, когда алгоритму нужно выбрать один вариант из K возможных — например, определить конкретную цифру на изображении или тематику статьи.
В отличие от схемы Бернулли с её единственным параметром p, здесь используется вектор параметров
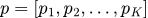
Вероятность того, что случайная величина примет значение конкретной категории k, определяется формулой:
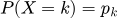
Для корректности распределения соблюдается обязательное условие — сумма вероятностей всех сценариев всегда дает единицу:
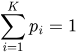
В задачах глубокого обучения такое распределение обычно формируется на выходе нейронной сети через функцию softmax. Она преобразует набор сырых чисел — логитов, в вектор вероятностей, позволяя интерпретировать результат как степень уверенности модели в каждом из доступных классов.
Метод максимального правдоподобия (MLE)
При обучении нейросетей или регрессий программы постоянно ищут оптимальные веса, но слишком точная подгонка под обучающие данные может привести к переобучению модели. Метод максимального правдоподобия дает четкий математический критерий для настройки алгоритма под конкретную обучающую выборку.
Функция правдоподобия и log-likelihood
Метод максимального правдоподобия Python-разработчики и дата-саентисты применяют (пусть и не всегда осознанно) при каждом обучении модели. Суть метода: найти такие параметры алгоритма
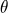
, при которых вероятность получить именно имеющиеся обучающие данные максимальна.
Функция правдоподобия
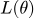
выглядит как произведение вероятностей:
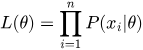
Перемножать тысячи маленьких вероятностей в компьютере чревато ошибкой — из-за машинного переполнения число превратится в ноль. Спасает математический трюк: вычисление натурального логарифма от функции правдоподобия. Логарифм произведения равен сумме логарифмов, поэтому log-likelihood выглядит так:
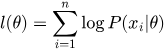
Минимизация функции потерь Log-Loss (кросс-энтропии) в ML математически эквивалентна максимизации функции log-likelihood.
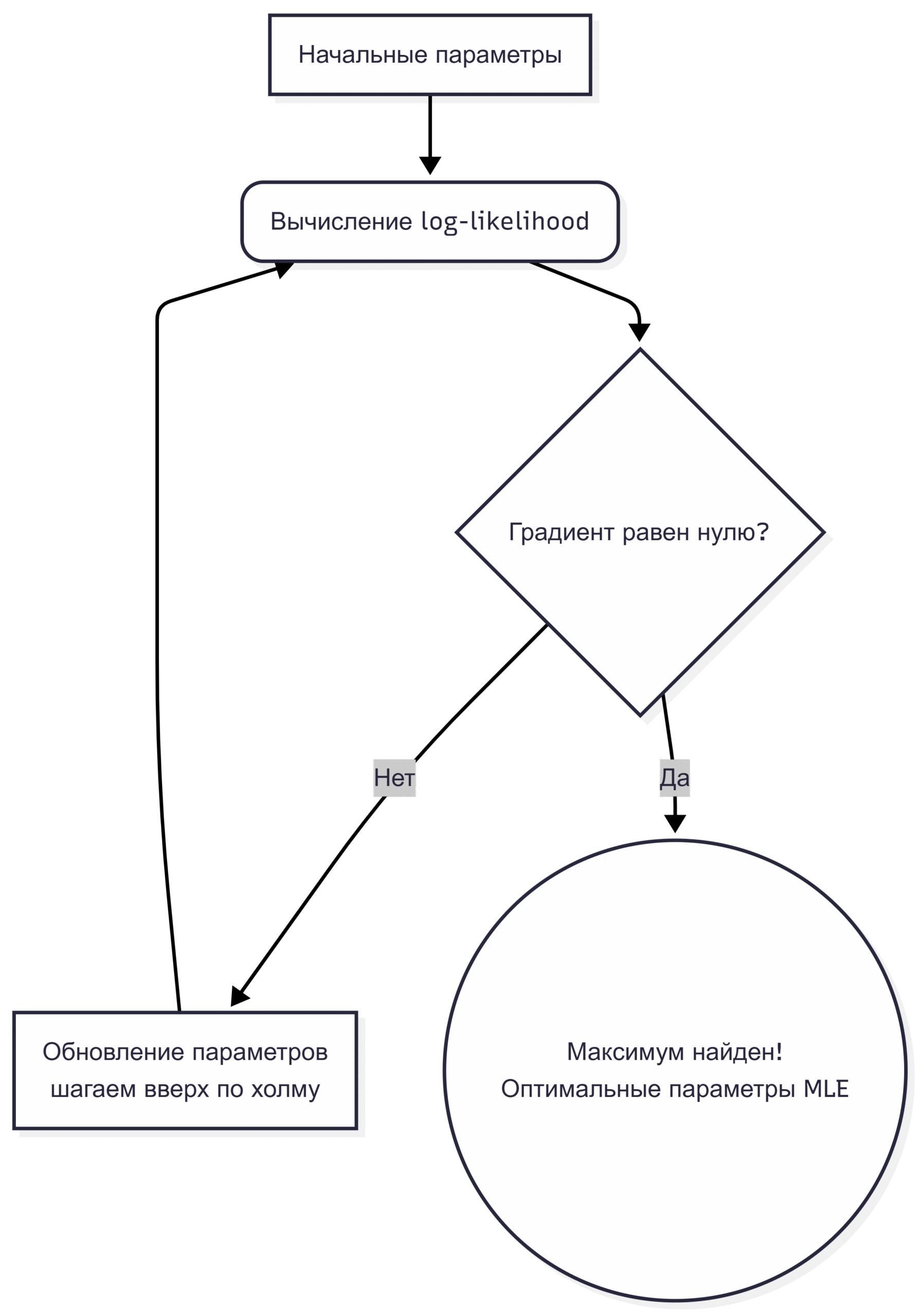
Модель вычисляет правдоподобие текущих параметров и сдвигает их в ту сторону, где вероятность получить наши обучающие данные выше. Процесс останавливается, когда алгоритм достигает локального максимума.

MLE на практике: подбор параметров нормального распределения
Посмотрим, как алгоритм находит параметры для нормального распределения — выборочное среднее и дисперсию.
# Импортируем модуль статистики
from scipy.stats import norm
import numpy as np
# Генерируем 1000 случайных чисел с известными параметрами (истинное mu=10, sigma=2)
np.random.seed(42)
true_mu, true_sigma = 10, 2
data = np.random.normal(true_mu, true_sigma, 1000)
# Используем метод fit (основанный на MLE), чтобы оценить параметры по данным
estimated_mu, estimated_sigma = norm.fit(data)
# Выводим сравнение
print(f"Истинные: mu={true_mu}, sigma={true_sigma}")
print(f"Оцененные MLE: mu={estimated_mu:.2f}, sigma={estimated_sigma:.2f}")Результат в консоли:
Истинные: mu=10, sigma=2
Оцененные MLE: mu=10.04, sigma=1.96Алгоритм отлично восстановил параметры по сырым данным.
Энтропия и KL-дивергенция
Понимание энтропии и метрик расстояния между распределениями выгодно отличает сильных инженеров от новичков. Эти инструменты помогают оценивать непредсказуемость информации и измерять разницу между реальными и предсказанными значениями.
Энтропия Шеннона
Энтропия в теории информации отражает степень непредсказуемости случайной величины или среднее количество информации, приходящееся на одно сообщение. Чем выше энтропия, тем шире распределение вероятностей по возможным исходам. В деревьях решений этот показатель выступает критерием качества разбиения узла.
Формула:
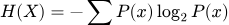
# Импортируем функцию для расчета энтропии
from scipy.stats import entropy
# Задаем вероятности честной монеты (максимальная энтропия)
fair_coin = [0.5, 0.5]
# Задаем вероятности шулерской монеты (минимальная энтропия)
biased_coin = [0.9, 0.1]
# Вычисляем энтропию с основанием логарифма 2 (в битах)
ent_fair = entropy(fair_coin, base=2)
ent_biased = entropy(biased_coin, base=2)
# Выводим результат
print(f"Энтропия честной монеты: {ent_fair:.2f}")
print(f"Энтропия шулерской монеты: {ent_biased:.2f}")Результат в консоли:
Энтропия честной монеты: 1.00
Энтропия шулерской монеты: 0.47KL-дивергенция
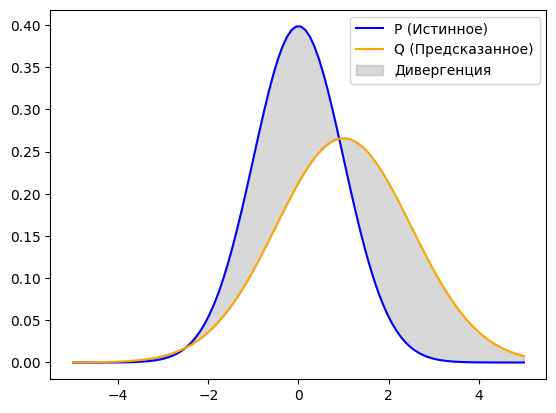
Расстояние Кульбака-Лейблера (KL-дивергенция) оценивает степень расхождения между двумя распределениями. Инструмент критически важен в продвинутом ML: например, он формирует основу функции потерь в вариационных автокодировщиках (VAE), заставляя распределение в скрытом пространстве приближаться к стандартному нормальному.
Формула KL-дивергенции от распределения Q до эталонного P
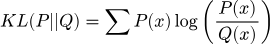
Программный расчет:
# Используем ту же функцию entropy, но с двумя аргументами (P и Q)
from scipy.stats import entropy
# Задаем два дискретных распределения вероятностей
P = [0.2, 0.5, 0.3]
Q = [0.1, 0.4, 0.5]
# Вычисляем KL-дивергенцию (по умолчанию используется натуральный логарифм)
kl_div = entropy(pk=P, qk=Q)
# Выводим результат
print(f"KL-дивергенция между P и Q: {kl_div:.4f}")Результат в консоли:
KL-дивергенция между P и Q: 0.0970Вы не спрашивали, но мы ответим
Какие разделы теории вероятности нужны для ML в первую очередь?
Базовые аксиомы, понимание случайных величин, условная вероятность, теорема Байеса и знание основных распределений. Знания из этого списка покрывают 80% повседневных задач аналитика и дата-саентиста.
Чем отличается MLE от MAP-оценивания?
Метод максимального правдоподобия (MLE) подбирает параметры, максимизирующие вероятность получения имеющихся данных. MAP выполняет аналогичную задачу, но дополнительно учитывает априорные знания. Если данных бесконечно много, результаты MLE и MAP совпадают.
Какие Python-библиотеки используются для работы с вероятностными распределениями?
Основной инструмент аналитика — scipy.stats. Библиотека содержит методы для работы с сотней распределений, генерации случайных чисел, расчета плотности вероятности и кумулятивных функций. Для базовой генерации часто хватает модуля numpy.random.
Как связаны кросс-энтропия и теорема Байеса?
Минимизация кросс-энтропии (функции потерь) эквивалентна максимизации логарифмического правдоподобия. Теорема Байеса описывает алгоритм пересчета вероятностей. Концепции пересекаются в байесовском подходе к машинному обучению, где кросс-энтропия участвует в оценке апостериорного распределения.
Теперь вы знаете, как работают условная вероятность, байесовский вывод, распределения и метод максимального правдоподобия на практике. Математика часто выглядит сложной только в формулах. Для закрепления материала скопируйте любой блок кода (например, байесовский классификатор), подставьте собственные данные, поменяйте параметры и посмотрите на изменения в консоли. Понимание принципов, на которых строится теория вероятности для ML, быстро окупается на практике при интерпретации результатов сложных алгоритмов.
Советуем дополнительно почитать по теме:
- Hugging Face: что это и как пользоваться — Hugging Face — это платформа с готовыми моделями, датасетами и библиотеками для NLP, компьютерного зрения, аудио, инференса и дообучения; в статье разбирают, как устроена экосистема и какие инструменты использовать.
- Что такое RAG-системы и как они устроены — RAG-системы работают как языковые модели, но с дополнительными библиотеками и внешней базой знаний: модель отвечает не только из памяти, а с опорой на конкретные документы и данные.
- AI-стек для разработчика: как устроен и какие задачи решает — современный AI-стек нужен, чтобы встроить модель в реальный проект с собственными данными, ограничениями, векторной базой, интерфейсом и backend-логикой.
- 20 AI GitHub-репозиториев для разработчика в 2026 году — подборка свежих репозиториев для локального запуска моделей, дообучения LLM, эмбеддингов в RAG, продакшен-инференса и работы с современными AI-инструментами.
- 15 скиллов для AI-агентов: установка и как работает в 2026 — как установить скиллы в Claude, Claude Code, Cursor и Gemini CLI и усилить уже подключённые MCP-интеграции.
Бонус для читателей
Если вам интересно погрузиться в мир ИИ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.