Когда вы ищете состав «Спартака» 2005 года, поисковик не читает все тексты подряд. Он превращает ваш запрос в числовой вектор и сравнивает его с векторами всего, что есть в базе. У статей про «Спартак» числа окажутся похожими на ваши — и они выйдут в топ.
Как поисковики находят подходящие статьи под ваши запросы — и что происходит внутри до того, как вы видите результат. Разобрали векторный поиск: эмбеддинги, косинусное сходство и при чём тут RAG.
Раньше поисковики хранили слова и тексты, в которых они встречаются. Это называется обратный индекс, он прекрасно справлялся пока запросы были короткими и точными. Как только люди начали писать живым языком, система начала ломаться, потому что поисковик не понимал, что делать с запросами по типу: «хочу пойти и купить там товар, и чтобы весело мне было». Никаких ключевых слов с однозначным совпадением. Эмбеддинги решили эту проблему: теперь и запрос, и текст превращаются в числовые векторы, а поиск — это поиск ближайших чисел. Разбираем, как именно всё это работает в поисковой системе.
Зачем компьютеру числа вместо букв
Система умеет хранить текст, но работать с ним на уровне смысла — нет. Чтобы машина могла сравнивать тексты по смыслу, нужен другой формат.
Анастасия Янина — PhD по Computer Science, экс-руководитель направления LLM в Wildberries, преподаватель МФТИ — рассказала, как устроен поиск по смыслу, в авторской программе Михаила Кострецова «Репортаж на Диване».
«Вот у нас есть какая-то статья, но она написана буквами — русскими, английскими. Мы, естественно, в компьютер не можем положить текстовую строку, нам нужна какая-то числовая строка, какой-то вектор».
Такой вектор — это и есть эмбеддинг. Длинный список чисел, в котором закодирован смысл текста. Числа в этом векторе не случайные. Они подобраны так, чтобы похожие по смыслу тексты получали похожие наборы чисел — на этой близости строится весь векторный поиск.


Популярные модели возвращают векторы от 384 до 1536 чисел. Например, модель `all-MiniLM-L6-v2` кодирует любой текст в вектор из 384 чисел, `all-mpnet-base-v2` — из 768, а `text-embedding-3-small` от OpenAI — из 1536. Каждое из этих чисел фиксирует один микроаспект смысла. Именно по соотношению этих чисел поисковик понимает, что «автомобиль» и «машина» — про одно, а «ключ от замка» и «ключ к решению» — про разное.
Как работал поиск до эмбеддингов
Чтобы понять, зачем нужны эмбеддинги, полезно вспомнить, как обходились без них.
Большие поисковые компании брали всё, что есть в интернете — Википедию, новости, форумы — и индексировали.
«Какие-то признаки из них извлекают и складывают в так называемый обратный индекс. И и в нём как раз можно находить эти документы по неким ключевым словам».
Обратный индекс (в технической литературе — инвертированный индекс) — это структура данных, в которой каждому слову сопоставлен список всех документов, где оно встречается. Не «в этом тексте есть слово X», а наоборот: «слово X есть в текстах №3, №17, №204 и №891». Именно поэтому структура называется инвертированной — она перевёрнута относительно привычного направления.

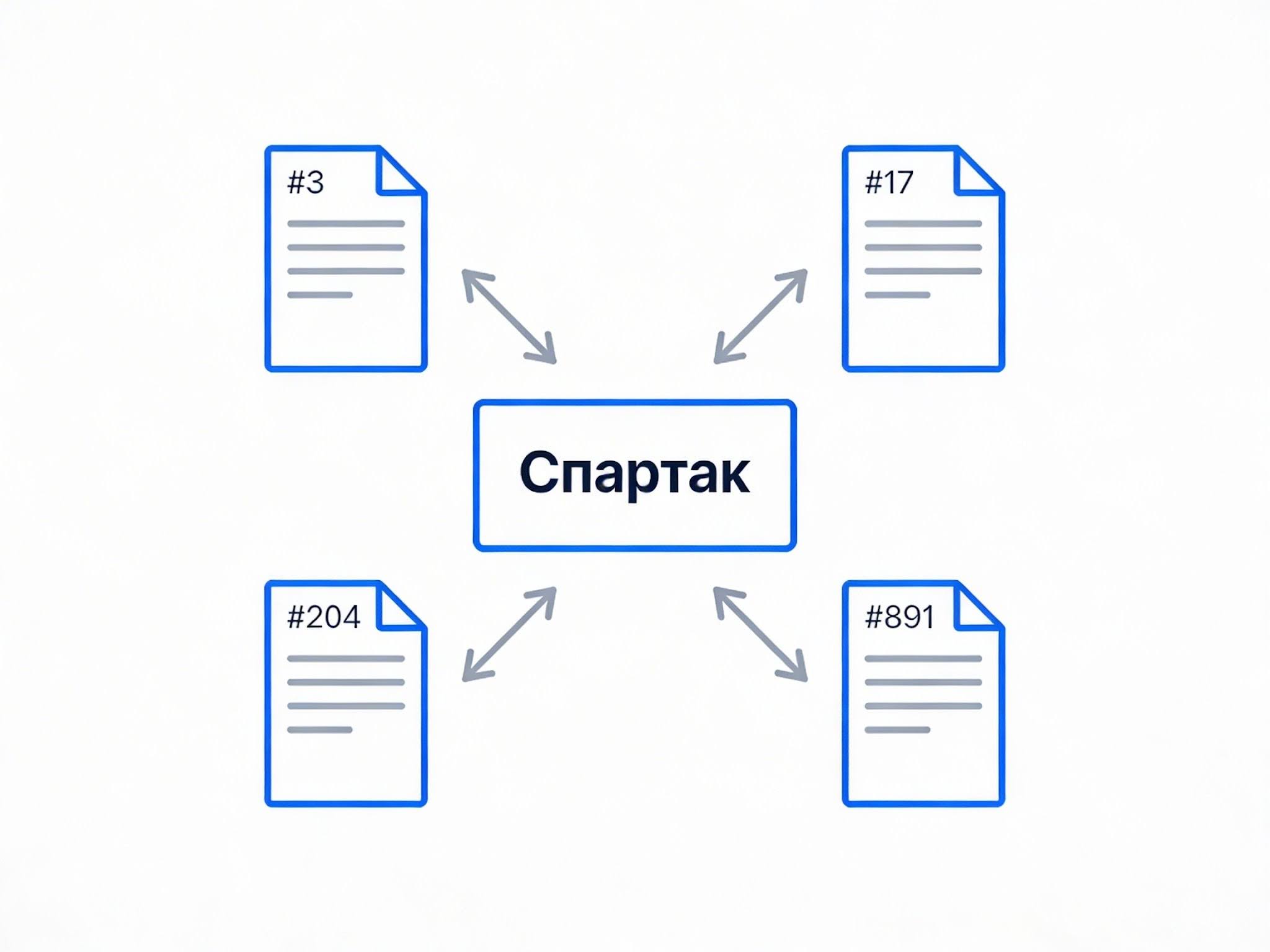
Эта технология не новая — она стала основой веб-поиска в середине 1990-х. Первая полнотекстовая поисковая система на основе краулера, WebCrawler, появилась в 1994 году. Когда в 1998 году Брин и Пейдж запустили Google, он уже работал на обратном индексе и охватывал около 24 миллионов документов. Так он продержался в поиске больше двадцати лет.
Схема простая: пользователь вводит запрос, запрос разбивается на слова, слова ищутся в индексе, возвращаются совпадающие результаты, которые дальше ранжируются по релевантности. Работает это ровно до тех пор, пока в запросе есть конкретные слова, которые могут совпасть с текстами в базе.
Но стоит написать «хочу пойти и купить там товар, и чтобы весело мне было, и чтобы все друзья обрадовались» — и схема ломается. Искать нечего: в этом запросе нет ключевых слов с однозначным совпадением, только намерение.
И ещё одна проблема, которую легко упустить: классический поиск не давал ответа. Поиск указывал направление, но фильтровать информацию приходилось самому. Если бы вы поставили запрос «как работает лекарство» — пришлось самостоятельно проходить через несколько страниц текста с историей изобретения и именами врачей, чтобы найти в конце: «один раз в день до еды».

Как пользователи учились говорить с поисковиком
Примерно десять лет люди учились формулировать запросы так, чтобы поисковик их понимал. Это был негласный договор между тремя сторонами: поисковиком, сайтами и самими пользователями.
Сайты занимались SEO — адаптировали тексты, заголовки и метаданные под алгоритмы. Пользователи в ответ учились убирать «лишние» слова: не «хочу купить цветы», а просто «цветы 8 Марта маме».
Все наконец-то сошлись на идеальной формуле запроса: короткий, с профессиональной терминологией, без лишних деталей. Пользователи при этом учились не только формулировать запросы, но и оценивать результаты — отфильтровывать мусорные сайты от полезных, не доверять первой ссылке, идти на третью страницу, если первые две не подошли. Это был целый навык, который нарабатывался годами. И он работал — в пределах своих ограничений.
Что кодирует эмбеддинг: не только слова
Задача — превратить текст в вектор так, чтобы смысл не потерялся.
«Мы хотим превратить весь текст в некий вектор, может быть длинный, многомерный — неважно. Но так, чтобы он отражал семантическую связь этого текста с другими текстами».
Что именно туда закодировать? Для поиска это не только слова.
Во-первых, лексический смысл: о чём текст. Во-вторых, поведение пользователей. «Что на этот документ много раз кликали — он популярный, а этот документ не очень популярный: на него кликают, длина клика суперкороткая, и сразу уходят. Ну, наверное, какой-то спам».
Всё это тоже можно закодировать в вектор и учитывать при ранжировании.
Придумывать, как именно это делать, не нужно. Модели, которые строят эмбеддинги, уже обучены на огромных корпусах текста. Вы подаёте текст — они возвращают вектор.
Полезный блок со скидкой
Если статья про эмбеддинги и векторный поиск зашла — это хороший знак: именно такие люди идут в ML, Data Science и разработку поисковых систем. Держите промокод Практикума на любой платный курс: KOD (можно просто на него нажать). Он даст скидку при покупке и позволит сэкономить на обучении.
Бесплатные курсы в Практикуме тоже есть — по всем специальностям и направлениям, начать можно в любой момент, карту привязывать не нужно, если что.
От Word2Vec до LLM-эмбеддингов: как менялась технология
Эмбеддинги появились не вчера. Несколько лет назад в поиске активно использовались более простые модели.
«Раньше были популярны и использовались в поиске, в том числе, всякие простые модели, типа Word2Vec и всяких надстроек над ним. А сейчас чаще берут, например, языковые модели и просто из них достают уже эмбеддинги для конкретных слов, предложений, текстов».
Word2Vec появился в 2013 году — его создала команда Томаша Миколова в Google. Идея простая: слово можно понять по окружению. Слова, которые регулярно встречаются рядом с одинаковыми другими словами, получают близкие векторы. Именно поэтому в пространстве Word2Vec работает знаменитый пример: «король» − «мужчина» + «женщина» ≈ «королева». Это как раз следствие того, что отношения между понятиями закодированы в направлениях векторов.
Проблема одна — Word2Vec учит один вектор на каждое слово — один раз и навсегда. Слово «ключ» получает один вектор, хотя в предложении «ключ от квартиры» и «ключ к успеху» это совершенно разные смыслы. Переломным моментом стал октябрь 2019 года: Google внедрил модель BERT в ядро своего поискового алгоритма для английского языка, а к декабрю — для русского и ещё более чем 70 языков. BERT впервые читал запрос целиком, а не по отдельным словам. По оценке Google, это затронуло каждый десятый поисковый запрос и стало крупнейшим изменением в поиске со времён запуска алгоритма RankBrain в 2015 году.
Именно поэтому Янина в начале карьеры занималась семантическим поиском для научных текстов: там нельзя искать по ключевым словам. Статья называется одним термином, цитирует её другим, а читатель ищет третьим. Нужен поиск по смыслу — значит, нужны хорошие эмбеддинги.
Как происходит поиск: запрос превращается в вектор
Допустим, у вас есть база индексированных текстов. Пользователь вводит запрос. Что дальше?
Запрос проходит тот же путь, что и тексты при индексации.
«Этот запрос точно так же будет превращён в некий числовой вектор, и дальше этот вектор можно будет сравнить с векторами документов, которые есть в нашей базе».
На примере «Спартака»:
«Запрос превращается, опять же, в некий эмбеддинг, числовой вектор, и начинает сравниваться со всеми документами в базе. Будет довольно очевидно для алгоритма, что вектор вашего запроса очень похож на векторы статей про “Спартак”».
После сравнения — ранжирование.
«Следующий этап — это уже ранжирование, когда мы хотим расположить документы в правильном порядке. Чтобы у пользователя на первой странице было что-то полезное, на второй — что-то менее полезное, и так далее».
Важное ограничение: если нужного текста в базе нет, поиск ничего не найдёт. Эмбеддинги не придумывают информацию — они ищут в том, что есть.
Косинусное сходство: как измеряют близость векторов
Векторы сравнивают с помощью меры близости, а самая распространённая мера — косинусное сходство.
«По некой мере близости — они могут быть очень разными на самом деле, начиная от простого косинусного расстояния и заканчивая сложными формулами — происходит поиск».
В профессиональной среде вы встретите оба термина: косинусное расстояние и косинусное сходство — это два способа выразить одно и то же. Сходство показывает, насколько векторы похожи (от 0 до 1), расстояние — насколько далеки (1 минус сходство). В поиске чаще говорят о сходстве: задача — найти самые близкие результаты, а не самые далёкие.
Представьте два вектора как стрелки из одной точки. Косинусное сходство показывает, насколько близки направления двух векторов — через косинус угла между ними.

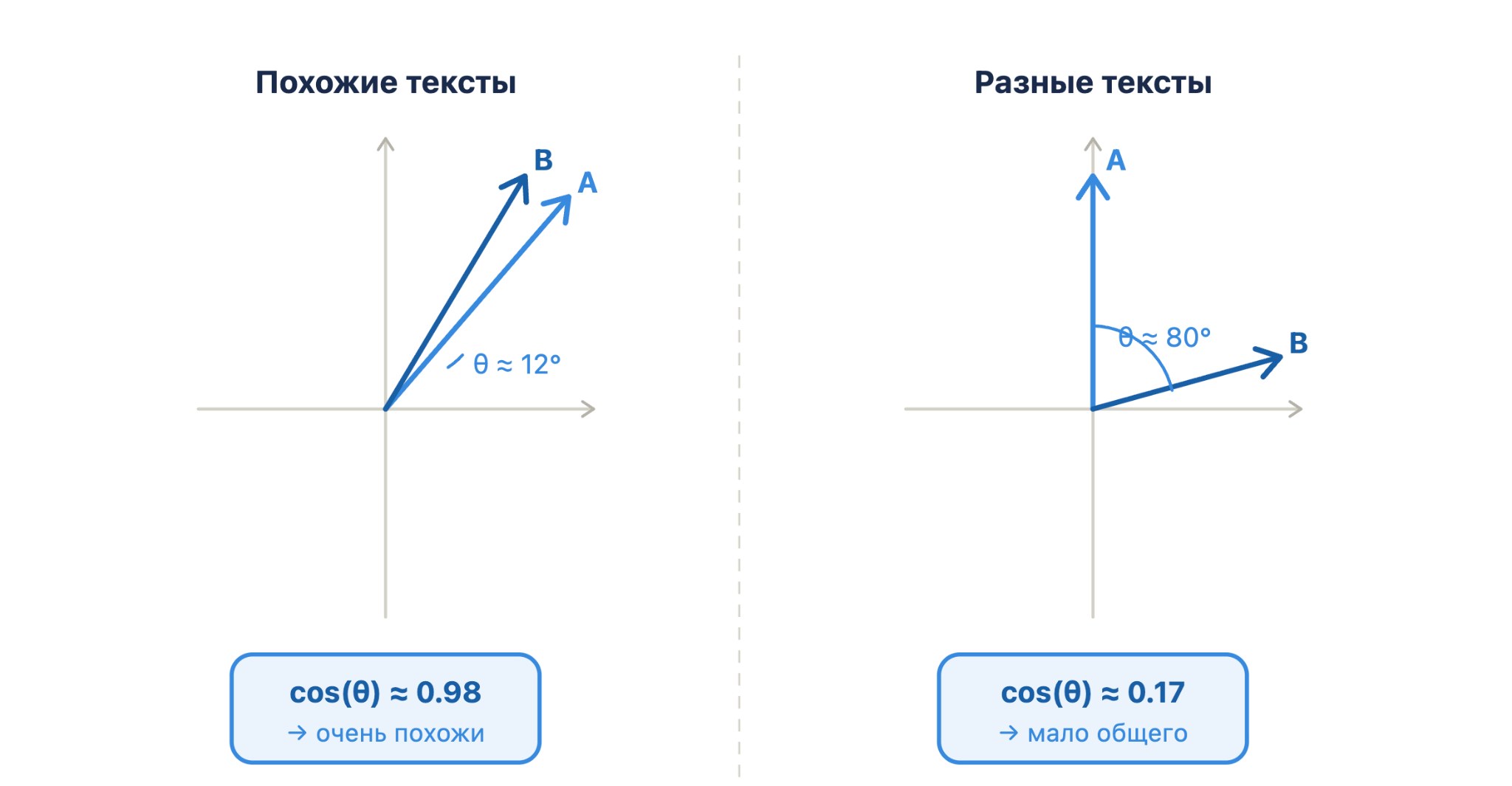
Если стрелки смотрят в одну сторону, угол маленький, тексты похожи. Если в разные — угол большой, тексты разные. Формально это записывается так:

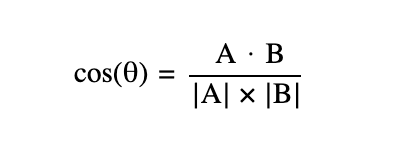
Здесь A и B — это два вектора, которые мы сравниваем (например, вектор запроса и вектор документа). A · B — скалярное произведение: сумма попарных произведений всех чисел в векторах. |A| и |B| — длины этих векторов. Деление на длины как раз убирает влияние объёма текста — остаётся только направление.
Результат варьируется от −1 до 1: на практике в текстовом поиске значения почти всегда положительные: единица означает полное совпадение направлений, ноль — отсутствие связи.
Вы можете спросить: почему бы просто не применить евклидово расстояние? Потому что длинный текст и короткий абзац об одном и том же будут далеко друг от друга по евклидовой метрике — просто потому что у одного вектора числа больше. Это то же самое, как если бы вы считали два текста разными только потому, что один написан на двадцати страницах, а другой на одной. Косинусное сходство на объём не реагирует, только на направление — именно поэтому для текстов оно подходит лучше.
В реальных системах используют и более сложные формулы. Но косинусное сходство — стандартная отправная точка, и во многих задачах его достаточно.
Что дальше: от поиска к генерации
Векторный поиск возвращает тексты. Релевантные, близкие по смыслу к запросу. Но это всё ещё просто список — не ответ.
«Модель поиска находит набор документов — например, 10 документов. А дальше QA-модель либо формулирует ответ на основе этих статей, в стиле простой языковой модели, либо находит конкретный кусок текста, который наиболее полно отвечает на вопрос».
Это и есть логика RAG — только в современном исполнении вместо отдельной QA-модели стоит большая языковая модель.
«Есть технология, которая называется Retrieval-Augmented Generation — генерация, дополненная поиском. В этом случае есть некая база, по которой мы хотим искать. Мы даём модели доступ к этой базе и говорим: “Делай свои выводы, учитывая эти документы”».
RAG как термин и метод появился в 2020 году: его предложила команда Патрика Льюиса из Facebook AI Research (сейчас *Meta), статья была принята на конференцию NeurIPS 2020. Суть — соединить поиск по базе с генерацией ответа, чтобы модель не опиралась только на то, что выучила при обучении, а работала с актуальными данными.
Схема целиком выглядит так: пользователь пишет запрос → запрос превращается в вектор → вектор сравнивается с базой → возвращаются ближайшие тексты → тексты вместе с запросом уходят в языковую модель → языковая модель формирует ответ.
Векторный поиск — первый и обязательный этап этой цепочки. Без него языковая модель работает только по своей внутренней памяти: знает много, но ничего актуального и ничего из ваших данных.
Мы прошли путь от обратного индекса, который искал точные слова, до эмбеддингов, которые ищут смысл, — и до RAG, который не просто находит документы, а формирует ответ на их основе. Каждый шаг решал одну проблему предыдущего: сначала научились понимать намерение, потом — отвечать, а не только указывать направление.
Теперь вы знаете, что происходит между вашим запросом и результатом: ваш текст превращается в числовой вектор из нескольких сотен чисел, система сравнивает его с векторами всего, что есть в базе, и возвращает те ссылки, где есть страницы, у которых числа стоят ближе всего. В этом вся прелесть изучать и работать с математикой. Именно она позволила нам найти состав «Спартака» 2005 года раньше, чем вы успели сформулировать вопрос до конца.
Кстати, вот он:

Ещё больше интересных деталей, которые не вошли в статью — послушайте или посмотрите в выпуске «Как правильно искать в интернете», подкаст «Репортаж на Диване» выходит при поддержке Яндекс Практикума. В выпуске вы узнаете:
- Как поиск работает внутри ChatGPT и чем он отличается от классического;
- В чём разница между инвертированным индексом и тем, как LLM хранит знания внутри весов;
- Почему нейросети галлюцинируют и можно ли это исправить;
- Одна и та же ли модель отвечает в Gemini и в поисковой строке Google?
Что советую ещё почитать по:
- 12 библиотек Python, которые стоит попробовать в 2026 году — разбираем 12 новых библиотек Python для работы с данными, языковыми моделями и ИИ-агентами: что такое библиотека, как подключить и какую задачу решает каждый инструмент.
- Как стать ML-инженером в 2026: роадмап от Python до оффера — data science — широкая область с четырьмя ролями внутри. Этот роадмап — про ML-инженера: человека, который берёт данные, модели и инфраструктуру и делает из этого работающий сервис в продакшне.
- 12 AI GitHub-репозиториев 2026: Ollama, n8n, Claude Code и OpenHands — за доступ к AI-инструментам сегодня платим от 20 до 200$ в месяц каждый. Инструменты из этого списка работают по-другому: те же задачи — генерация текста, RAG-пайплайны, автоматизация — но разворачиваете сами, данные остаются на вашей стороне.
Бонус для читателей
Если вам интересно погрузиться в мир ИТ и при этом немного сэкономить, держите наш промокод на курсы Практикума. Он даст вам скидку при оплате, поможет с льготной ипотекой и даст безлимит на маркетплейсах. Ладно, окей, это просто скидка, без остального, но хорошая.