


Сегодня снова выступим в роли аналитиков данных. В качестве данных возьмём датасет рецензий с Rotten Tomatoes — сайта-агрегатора, на котором представлены обзоры фильмов и сериалов из различных изданий. Попробуем обработать эти данные и сделать какие-то выводы, заодно поучимся работать с библиотеками для анализа. Статья получилась большая, запаситесь чаем.
👉 Работать будем на Python. Если вы с ним ещё не знакомы, почитайте наш мастрид, а потом установите Python на свой компьютер за 5 минут.
Что делаем
Мы возьмём свежий датасет рецензий Rotten Tomatoes с сайта kaggle.com (тот самый сайт, где энтузиасты делятся собранной биг-датой), подключим его к нашему коду и попробуем найти закономерности и паттерны в текстах рецензий. Посмотрим, каких рецензий больше — положительных или отрицательных, кто написал больше всех и как много рецензий на самые хорошие и плохие фильмы.
После этого вспомним проект с анализом «Войны и Мира» и построим облака наиболее часто встречающихся слов из положительных и отрицательных рецензий. Если какие-то слова будут неинформативными или встречаться в обеих категориях — уберём.
Что понадобится для проекта
Чтобы анализировать данные и строить графики, понадобится несколько дополнений Python — без них он не умеет делать то, что нам нужно. Для установки пишем команду:
pip install [название библиотеки]
Например, для дополнения NumPy команда будет такой:
pip install numpy
Если у вас не получается установить дополнение с помощью команды pip, попробуйте pip3.
Самое простое — установить библиотеки из командной строки, предварительно перейдя там в папку с проектом:
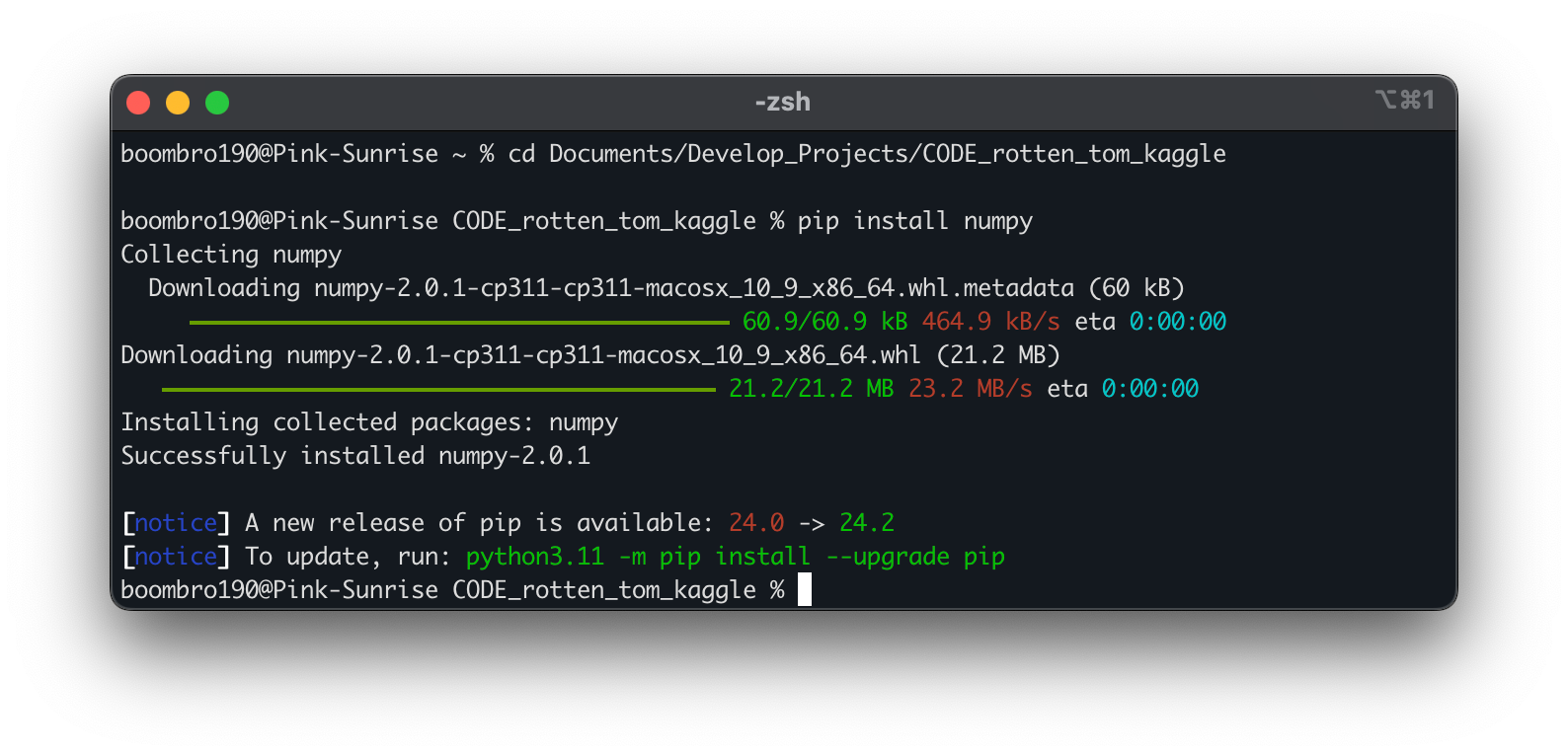
В среде разработки это можно сделать также на вкладке с командной строкой:
Разберём подробнее, какие дополнения будем использовать и что делает каждое из них.
Counter — это подкласс объекта из модуля collections, который подсчитывает неизменяемые элементы в объектах и анализирует эту частотность. Результат возвращается в виде словаря, в котором элементы представлены в виде ключей, а число их повторов — в виде значения. Например, пара 'film': '1022' означает, что слово film в выбранном наборе рецензий встречается 1022 раза. Устанавливать counter не нужно, так как он встроен в Python.
NumPy — библиотека для работы с данными и обучения нейронных сетей. Её используют для более быстрых сложных вычислений, потому что Python — интерпретируемый язык и выполняет такие операции медленнее, чем компилируемые языки. Часть NumPy написана на C и C++, поэтому работает библиотека довольно шустро.
Polars — библиотека для анализа больших данных. Это альтернатива популярной библиотеки Pandas, но за счёт того, что Polars написана на Rust, она работает быстрее и поддерживает параллельное выполнение нескольких задач.
Matplotlib — библиотека для визуализации данных и создания практически любых графиков: линейных, столбчатых, гистограмм, диаграмм и всего остального.
Seaborn — собрана на основе Matplotlib, с похожими возможностями, но более простая в работе. Они совместимы, и их можно использовать для построения одного и того же графика.
NLTK — библиотека для обработки и анализа естественного языка, то есть того, на котором говорят люди. Мы используем небольшую часть всех её возможностей: возьмём готовый список стоп-слов из разных языков и разделим тексты рецензий на токены — составные части для анализа.
Wordcloud — библиотека для создания облаков слов, где размер слов зависит от их частоты или важности.


Импортируем дополнения и загружаем датасет
Скачиваем датасет со страницы исследования. После этого нужно импортировать дополнения. Обратите внимание, что для удобства можно сразу указать сокращения для библиотек и модулей командой as:
# импортируем все зависимости
from collections import Counter
import numpy as np
import polars as pl
import seaborn as sns
import matplotlib.pyplot as plt
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from wordcloud import WordCloudТеперь загрузим датасет. Для этого объявим переменную и для проверки выведем первые 5 строк командой head:
# загружаем датасет в переменную
df = pl.read_csv('../rotten_tomatoes_movie_reviews.csv')
# проверяем, что всё загрузилось: выводим первые 5 значений
print(df.head())Если хотите вывести больше 5 строк, то в скобках после head нужно указать нужное число, например: head(10). Выводим результат на экран:
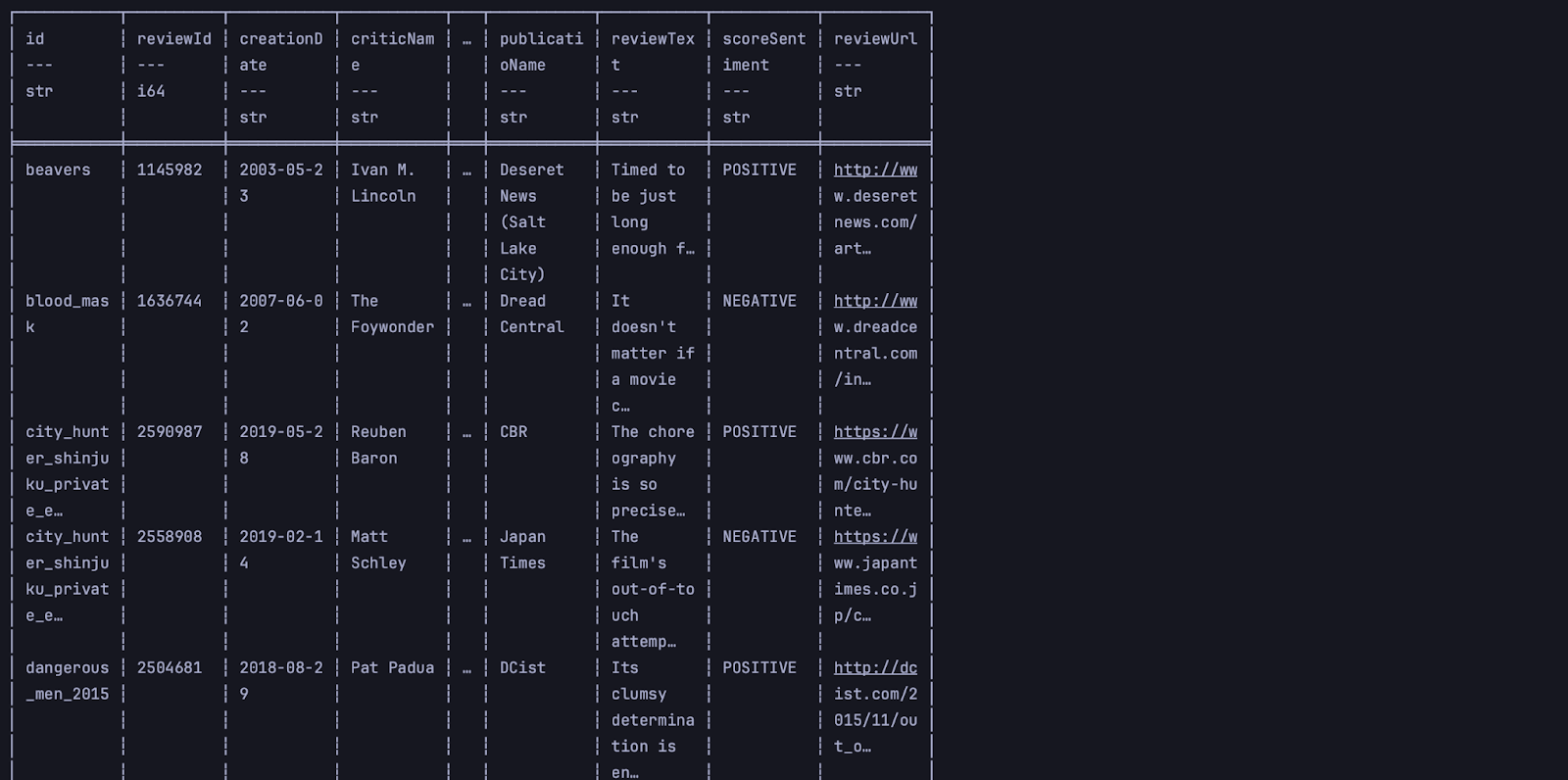
Если мы видим такую таблицу, это значит, что всё работает и мы на верном пути. Но колонки получились узкими, читать не очень удобно, поэтому для информативности добавим перед выводом настройки максимальных размеров столбцов и таблицы.
# Настройка параметров отображения
# Устанавливаем максимальную ширину столбцов
pl.Config.set_tbl_cols(30)
# Устанавливаем максимальную ширину таблицы в символах
pl.Config.set_tbl_width_chars(165)
# загружаем датасет в переменную
df = pl.read_csv('../rotten_tomatoes_movie_reviews.csv')
# проверяем, что всё загрузилось: выводим первые 5 значений
print(df.head())Совсем другое дело:

Фильтруем данные
Сейчас в таблице много полей, но нам не нужны все. Чтобы оставить только данные для исследования, напишем запрос на языке SQL и добавим фильтр. Для этого объявим переменную и напишем запрос в тройных кавычках. Оставим в таблице такие поля:
id— идентификатор рецензии;reviewText— текст отзыва;scoreSentiment— тип NEGATIVE или POSITIVE;criticName— имя написавшего рецензию критика;isTopCritic— булева переменная со значением True или False.reviewState— статус фильма согласно отзыву: rotten или fresh.
Получается такой запрос:
# задаём SQL-запрос для выборки определённых столбцов
# из датасета и выводим обновлённые данные
query = """
SELECT id, reviewText, scoreSentiment, criticName, isTopCritic, reviewState
FROM self
"""Применяем его к датасету и проверяем результат.
# применяем запрос
df = df.sql(query)
# проверяем результат
print(df.head(10))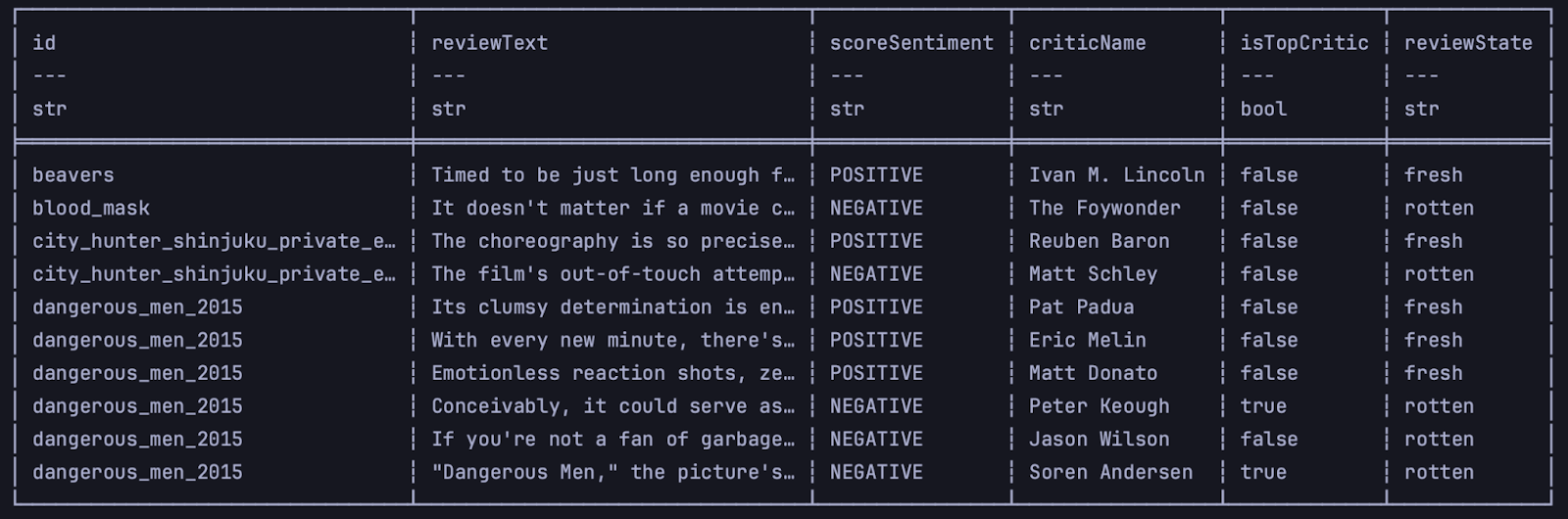
Очищаем тексты от лишних символов
Теперь нормализуем данные для более точного и быстрого анализа. Приведём все буквы к нижнему регистру с помощью метода .str.to_lowercase(). Все тексты рецензий у нас хранятся в виде строк, поэтому мы последовательно применим к каждой метод .str.replace_all(). В скобках указывается символ или часть строки, которые нужно заменить, а после него через запятую — на что заменяем.
Всё это мы положим в функцию и укажем тип передаваемого значения как DataFrame из библиотеки polars — у нас она используется под сокращением pl.
Создаём функцию и применяем к датасету:
# определяем функцию для очистки текстовых данных в столбце reviewText:
# удаляем ссылки, спецсимволы, числа и приводим текст к нижнему регистру.
def clean_data(df_cleaning: pl.DataFrame):
# метод with_columns добавляет столбцы
df_cleaning = df_cleaning.with_columns(
# очищаем все значения в столбце reviewText методом строки replace_all:
# заменяем ненужные символы на пробелы или более удобные для анализа символы
pl.col('reviewText')
.str.to_lowercase()
.str.replace_all("'s", ' is')
.str.replace_all("n't", ' not')
.str.replace_all("'m", ' am')
.str.replace_all('((www\.[^\s]+)|(https?://[^\s]+))', '')
.str.replace_all('@[^\s]+', '')
.str.replace_all(r"\d+", "")
.str.replace_all("\W", " ")
.str.replace_all('https?://\S+|www\.\S+', '')
.str.replace_all('<.*?>+', '')
.str.replace_all('\n', '')
.str.replace_all(r'#([^\s]+)', r'\1')
.str.replace_all('\.', ' ')
.str.replace_all('\"', ' ')
.str.replace_all('\w*\d\w*', '')
.str.replace_all('\!', ' ')
.str.replace_all('\-', ' ')
.str.replace_all('\:', ' ')
.str.replace_all('\)', ' ')
.str.replace_all('\,', ' ')
.str.replace_all('[\s]+', ' ')
.str.strip_chars('\'"')
)
return df_cleaning
# применяем функцию очистки данных к датасету
df = clean_data(df)Теперь на всякий случай убедимся, что в столбце reviewText у нас нет пустых рецензий. Напишем запрос и оставим только те ячейки, в которых что-то есть:
# пишем SQL-запрос для фильтра: оставляем только те строки,
# где значение в столбце reviewText не пустое — значит, рецензия есть
query = """
SELECT *
FROM self
WHERE reviewText <> ''
"""Проверяем, что датасет считывается и работает после очистки:
# применяем запрос
df = df.sql(query)
# проверяем: выводим первые 10 фильмов с рецензиями
print(df.head(10))
Показываем соотношение положительных и отрицательных рецензий
Посмотрим, каких рецензий на Rotten Tomatoes больше — хвалебных или ругательных. Для этого нужно достать значение из ячейки scoreSentiment.
В библиотеке NumPy есть функция unique, которая формирует множества — неупорядоченные неповторяющиеся коллекции элементов. В качестве аргумента мы можем указать нужный столбец и попросить вернуть количество повторений каждого значения. Чтобы получить количество, нужно указать вторым аргументом return_counts=True:
# узнаём общее количество типов рецензий
unique, count = np.unique(df['scoreSentiment'], return_counts=True)Библиотека Matplotlib строит круговые диаграммы с помощью функции plt.pie(). У неё несколько возможных настроек-аргументов, мы укажем три:
x=count— количество повторений метки Positive или Negative;labels=unique— сама метка;autopct='%.0f%%'— формат вывода значений.
Укажем название для диаграммы и выведем её на экран.
# строим круговую диаграмму для отображения распределения рецензий по scoreSentiment
# узнаём общее количество типов рецензий
unique, count = np.unique(df['scoreSentiment'], return_counts=True)
# передаём в библиотеку matplotlib массив значений
# posititve-negative и их количество на каждый фильм
plt.pie(x=count, labels=unique, autopct='%.0f%%')
# пишем название диаграммы
plt.title('Общая оценка распределения положительных и негативных рецензий')
# выводим на экран
plt.show()Смотрим, что получилось:
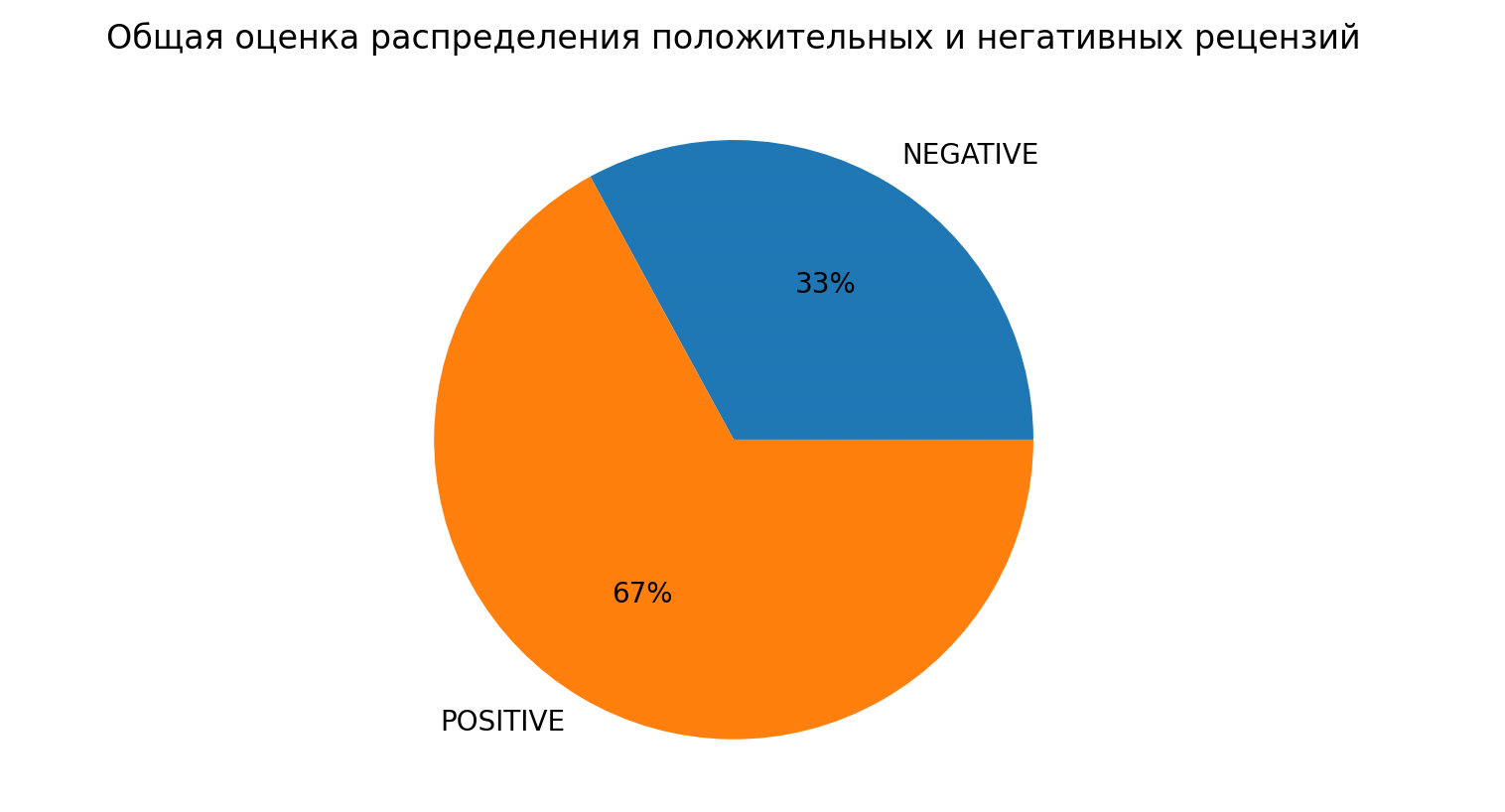
Видно, что положительных рецензий в два раза больше отрицательных.
Строим диаграмму авторов рецензий
Теперь узнаем, кто из топ-критиков написал больше всех рецензий. Сначала выберем только рецензии, где значение isTopCritic равно 1, то есть True:
# отбираем рецензии только топ-критиков
topCriticsQuery = """
SELECT *
FROM self
WHERE isTopCritic=1
"""
# применяем запрос
topCriticDf = df.sql(topCriticsQuery)Теперь посчитаем количество рецензий каждого автора и расположим их в порядке убывания:
# считаем количество рецензий каждого из топ-критиков
# и сортируем их в порядке убывания
query = """
SELECT criticName, COUNT(*) AS reviewCount
FROM self
GROUP BY criticName
ORDER BY reviewCount DESC
"""
# применяем запрос
topCriticCount = topCriticDf.sql(query)Данные для графика будем считать библиотекой seaborn методом barplot(). По оси X у нас будет количество рецензий, а по Y — имена критиков. Сам график будем строить библиотекой matplotlib. Библиотеки совместимы между собой, поэтому так можно.
Для графика берём только первые 30 позиций, то есть авторов с наибольшим количеством отзывов. Выведем график в виде строк и установим для каждой из них свой цвет:
# строим горизонтальный график для первых 30 критиков с наибольшим количеством рецензий
# устанавливаем оси: количества рецензий по x, имя критика по y
sns.barplot(x=topCriticCount['reviewCount'].head(30),
y=topCriticCount['criticName'].head(30),
# устанавливаем горизонтальную ориентацию графика
orient='h',
# устанавливаем цветовую маркировку для каждого столбца
hue=topCriticCount['criticName'].head(30)
)Подпишем оси и название графика:
# устанавливаем метку по X
plt.xlabel('Количество рецензий')
# устанавливаем метку по Y
plt.ylabel('Имя критика')
# задаём название для диаграммы
plt.title('30 топ-критиков с наибольшим количеством рецензий')Установим размеры графика в дюймах:
# задаём размер графика
plt.figure(figsize=(10, 8))Из-за того, что подписи по оси Y длинные, они могут выходить за край диаграммы. Увеличим отступ слева, чтобы всё было видно:
# увеличиваем отступ слева
plt.subplots_adjust(left=0.3)Можно рисовать график:
# рисуем график
plt.show()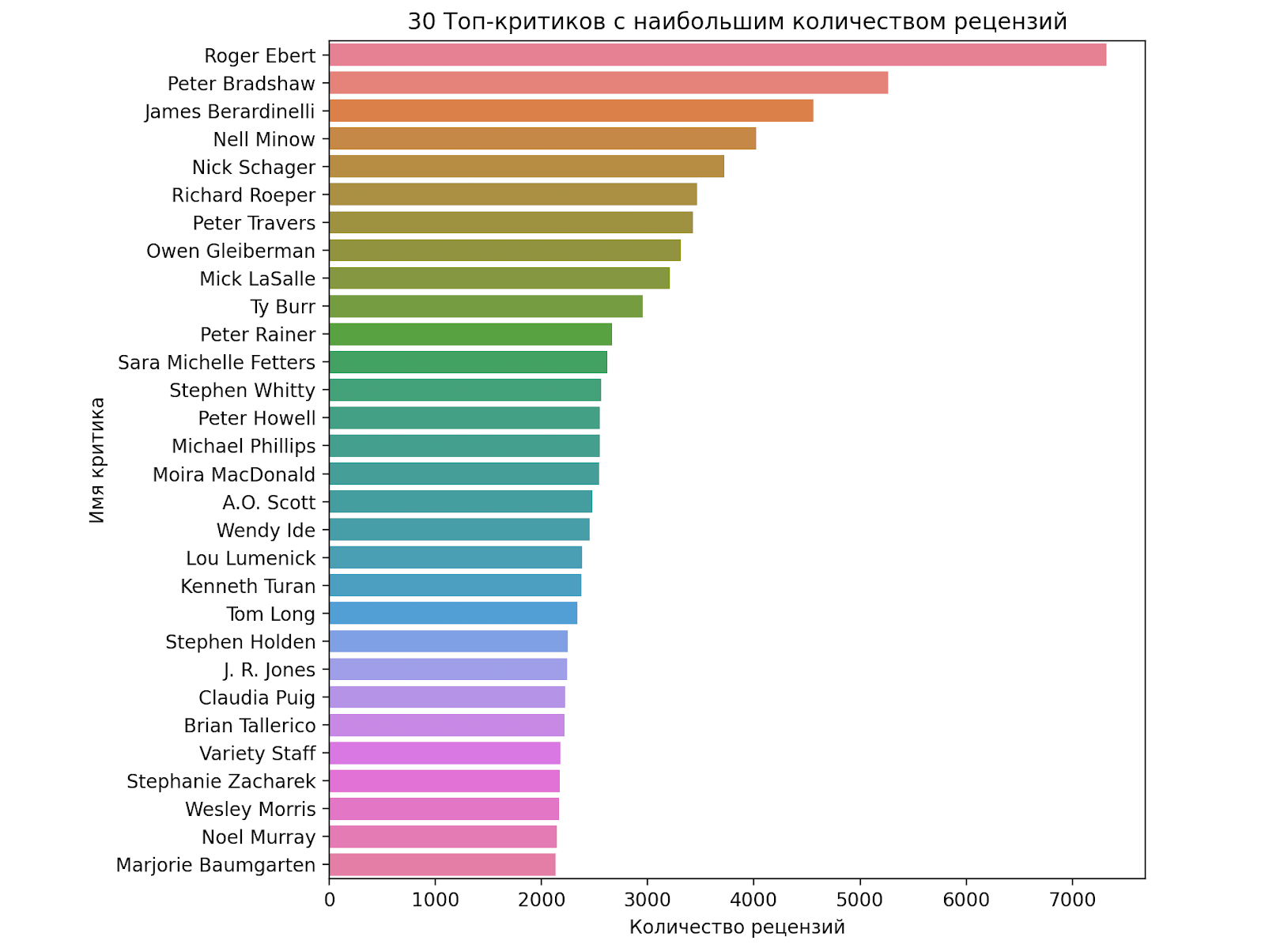
Больше всего рецензий у лауреата Пулитцеровской премии Роджера Эберта. Он начал карьеру в 1967 году, продолжал писать до своей смерти в 2013 году — и до сих пор лидирует среди критиков Rotten Tomatoes с большим отрывом.
Выводы из этого графика могут стать началом нового исследования о производительности, тайм-менеджменте и мире киножурналистики. Можно рассмотреть отдельно рецензии одного из авторов, зафиксировать их количество и характер и попробовать сравнить с событиями, которые происходили в этот момент в его жизни.
Определяем фильмы с наибольшим количеством рецензий
Потренируемся со столбчатыми диаграммами ещё немного и найдём фильмы с самым большим количеством рецензий. Возьмём по 50 фильмов сверху списка для положительных и отрицательных отзывов.
Начнём с положительных. Пишем запрос:
# задаём SQL-запрос для получения списка фильмов
# с наибольшим количеством отрицательных отзывов
query = """
SELECT id, COUNT(*) as posReviewCount
FROM self
WHERE scoreSentiment='POSITIVE'
GROUP BY id
ORDER BY posReviewCount DESC
LIMIT 50
"""Дальше делаем всё то же самое, что с графиком для критиков:
- применяем запрос;
- устанавливаем размер графика;
- располагаем значения по осям X и Y и задаём горизонтальную ориентацию;
- подписываем метки для осей и название графика;
- увеличиваем отступ слева для читаемости;
- выводим диаграмму на экран.
Между предыдущим графиком и этим будет одно различие: мы выставим одинаковый цвет столбцов для всех фильмов аргументов color='green' в методе barplot():
# применяем запрос
posNegMov = df.sql(query)
# строим столбчатый график одного цвета
# задаём размер графика
plt.figure(figsize=(10, 8))
# устанавливаем оси X и Y, ориентацию графика, цвет столбцов
sns.barplot(x=posNegMov['posReviewCount'],
y=posNegMov['id'],
orient='h',
color='green'
)
# устанавливаем метку по X
plt.xlabel('Количество положительных отзывов')
# устанавливаем метку по Y
plt.ylabel('Название фильма')
# задаём название для диаграммы
plt.title('50 фильмов с наибольшим количеством положительных рецензий')
# увеличиваем отступ слева
plt.subplots_adjust(left=0.3)
# рисуем график
plt.show()Что получилось:
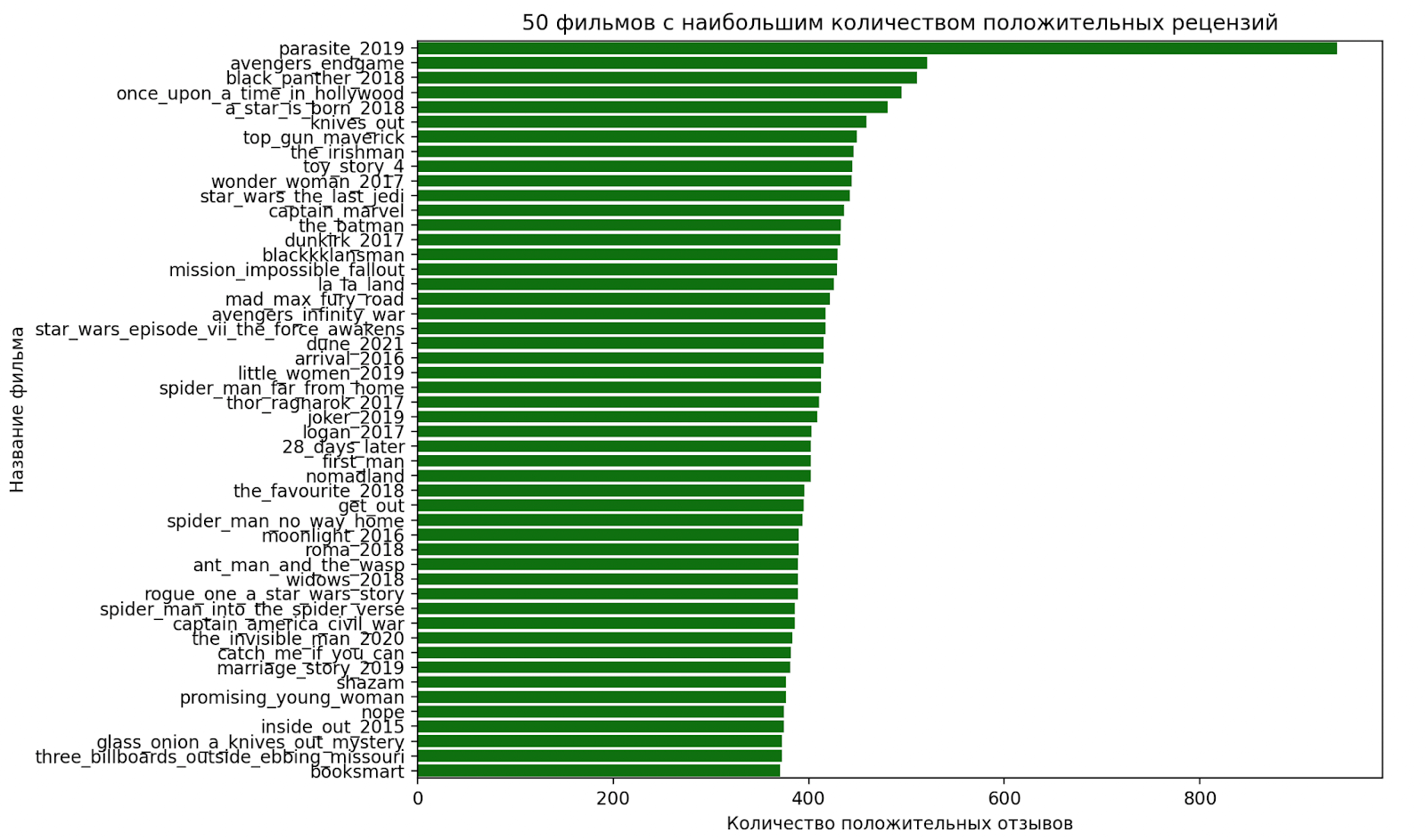
По графику видно, что больше всего положительных рецензий у фильма «Паразиты». Построим такой же график для фильмов, которые собрали больше всего отрицательных рецензий. Цвет столбцов сделаем красным:
# задаём SQL-запрос для получения списка фильмов
# с наибольшим количеством отрицательных отзывов
query = """
SELECT id, COUNT(*) as negReviewCount
FROM self
WHERE scoreSentiment='NEGATIVE'
GROUP BY id
ORDER BY negReviewCount DESC
LIMIT 50
"""
# применяем запрос
topNegMov = df.sql(query)
# строим столбчатый график одного цвета
# задаём размер графика
plt.figure(figsize=(10, 8))
# устанавливаем оси X и Y, ориентацию графика, цвет столбцов
sns.barplot(x=topNegMov['negReviewCount'],
y=topNegMov['id'],
orient='h',
color='red'
)
# устанавливаем метку по X
plt.xlabel('Количество негативных отзывов')
# устанавливаем метку по Y
plt.ylabel('Название фильма')
# задаём название для диаграммы
plt.title('50 фильмов с наибольшим количеством отрицательных рецензий')
# увеличиваем отступ слева
plt.subplots_adjust(left=0.3)
# рисуем график
plt.show()Смотрим на результат:
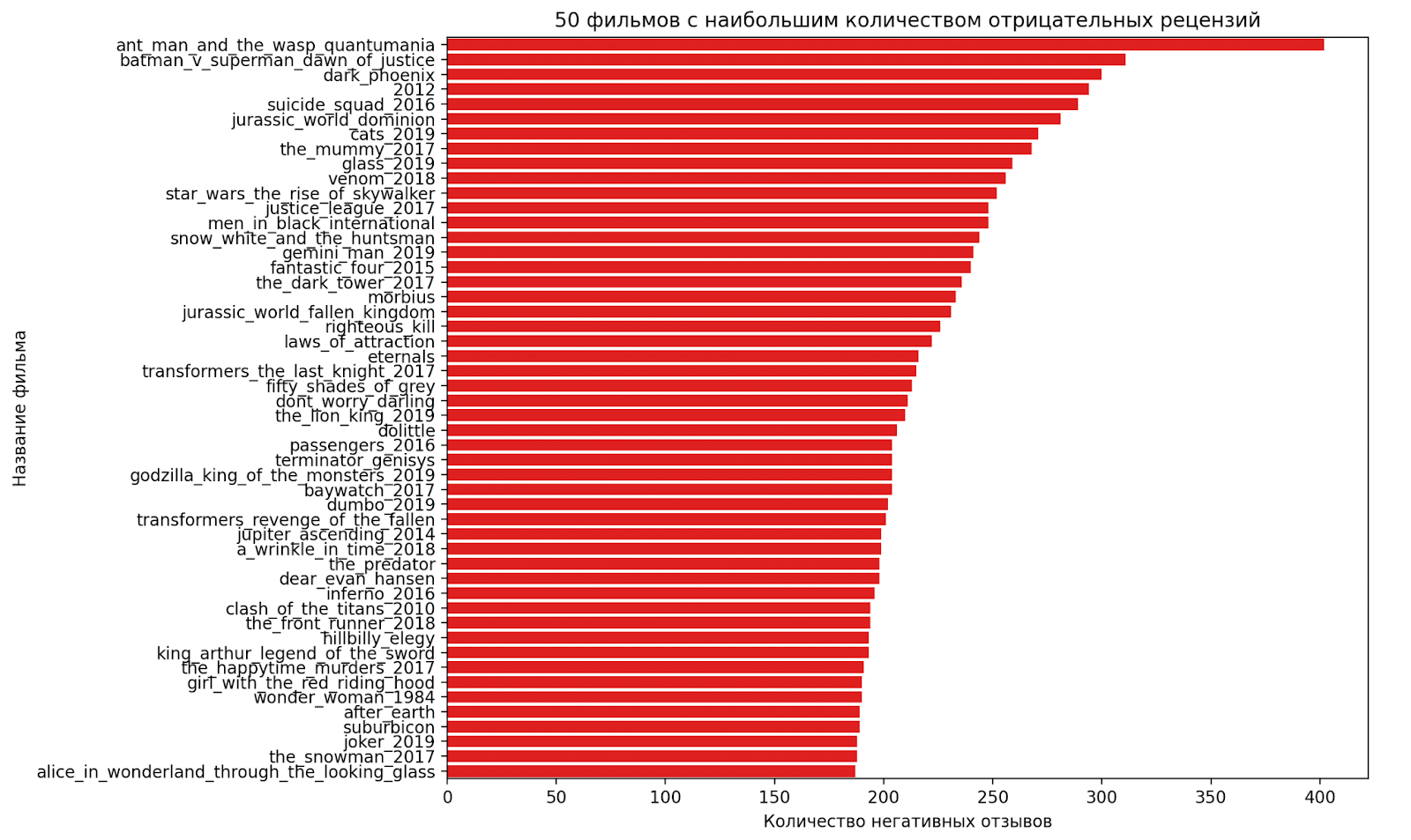
Больше всего отрицательных рецензий оставили на фильм «Человек-муравей и Оса: квантомания». Кроме этого, по графику видно, что положительных рецензий в целом пишут больше.
Полученные результаты можно развить. Например, провести дополнительную аналитику по фильму «Паразиты» и понять: почему он собрал столько рецензий? Может ли это быть связано с тем, что это первый фильм на иностранном языке, получивший «Оскар» — главную награду в киноиндустрии? Другой вариант для исследования: связано ли количество рецензий на фильм с количеством задействованных в картине актёров со звездой на «Аллее славы»?
Фильтруем данные для облака слов
Теперь посмотрим, какие слова используются чаще всего в положительных и отрицательных рецензиях.Для этого нам понадобится предварительная подготовка. В отзывах много неинформативных слов: предлогов, местоимений, причастий и так далее. Чтобы удалить эти стоп-слова, используем две зависимости из библиотеки NLTK: punkt и stopwords.
# загружаем зависимости для стоп-слов
nltk.download('punkt')
nltk.download('stopwords')Добавляем стандартные стоп-слова для английского языка:
# составляем список стоп-слов: добавляем готовые из английского словаря
stop_words_all = set(stopwords.words('english'))Теперь добавим дополнительные стоп-слова, которые не несут полезной информации в рецензиях, например «фильм», «персонаж», «обзор» и другие.
# записываем свои
custom_stop_words = {'movie', 'film', 'one', 'would', 'like', 'quite', 'enough',
'character', 'comedy', 'films', 'make', 'time', 'see', 'way',
'year', 'even', 'good', 'much', 'work', 'take', 'characters',
'still', 'review', 'feel', 'seem', 'scene', 'though', 'funny',
'scene', 'find', 'day', 'actor', 'play', 'know', 'bit', 'set',
'making', 'turn', 'want', 'feature', 'filmmaker', 'around',
'hour', 'think', 'show'}
# добавляем свои слова в набор стоп-слов
stop_words_all.update(custom_stop_words)Теперь вынесем очистку от стоп-слов в отдельную функцию и добавим к ним самые частые слова, которые встречаются в положительных и в отрицательных рецензиях одновременно. Для этого сделаем такое:
- напишем функцию, которая находит 100 самых популярных слов;
- применим эту функцию к двум группам рецензий по очереди;
- найдём пересечение двух результатов, то есть слова, которые есть и там и там;
- удалим повторы из анализа.
Для проверки текст нужно преобразовать в токены. После этого можно удалить токены стоп-слов и небуквенные символы.
# пишем функцию для очистки текста от стоп-слов
def clean_text(text, stop_words):
# токенизируем и приводим к нижнему регистру
tokens = word_tokenize(text.lower())
# удаляем стоп-слова и небуквенные символы
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words]
# возвращаем очищенный текст
return ' '.join(filtered_tokens)Чтобы подсчитать количество слов, снова воспользуемся Counter. Для получения отдельных слов текст разобьём в местах пробелов:
# пишем функцию для нахождения самых частых слов в рецензиях
def get_most_common_words(text, num_words=100):
# разбиваем текст на слова
words = text.split()
# создаём коллекцию вида: слово — количество повторений
counter = Counter(words)
# возвращаем первые 100 слов из всех переданных в функцию рецензий
return counter.most_common(num_words)На этом этапе пока ничего не рисуем.
Готовим данные для облака
Пишем запросы, которые будут проверять столбец reviewText. Один запрос будет выбирать рецензии с маркером POSITIVE, второй — с NEGATIVE:
# пишем запрос для выделения всех положительных рецензий
pos_query = """
SELECT reviewText
FROM self
WHERE scoreSentiment = 'POSITIVE'
"""
# пишем запрос для выделения всех отрицательных рецензий
neg_query = """
SELECT reviewText
FROM self
WHERE scoreSentiment = 'NEGATIVE'
"""Теперь нужно выполнить такие операции:
- применить оба запроса к датасету и получить два новых датасета;
- объединить все слова из рецензий в два списка;
- очистить эти списки от стоп-слов;
- выделить наиболее часто встречающиеся слова.
# выделяем все позитивные рецензии через запрос
pos_df = df.sql(pos_query)['reviewText']
# объединяем все слова из рецензий
all_pos_words = ' '.join(pos_df.to_list())
# очищаем текст от стоп-слов
cleaned_pos_text = clean_text(all_pos_words, stop_words_all)
# выделяем наиболее часто встречающиеся слова
pos_common_words = get_most_common_words(cleaned_pos_text)
# выделяем все негативные рецензии через запрос
neg_df = df.sql(neg_query)['reviewText']
# объединяем все слова из рецензий
all_neg_words = ' '.join(neg_df.to_list())
# очищаем текст от стоп-слов
cleaned_neg_text = clean_text(all_neg_words, stop_words_all)
# выделяем наиболее часто встречающиеся слова
neg_common_words = get_most_common_words(cleaned_neg_text)Чтобы найти самые частые пересекающиеся слова, используем множества. Все элементы в них уникальны, поэтому, если какое-то слово будет повторяться, счётчик элементов не изменится. Перебираем все слова из рецензий POSITIVE и NEGATIVE, объединяем два множества и добавляем результат к списку стоп-слов.
# преобразуем самые частые слова в множества
# позитивных и негативных часто встречающихся слов
top_pos_words = {word for word, _ in pos_common_words}
top_neg_words = {word for word, _ in neg_common_words}
# объединяем слова из обоих наборов
top_words = top_pos_words | top_neg_words
# обновляем стоп-слова
stop_words_all.update(top_words)Рисуем (наконец-то!) облако слов
На этом этапе уже можно строить облака слов в положительных и отрицательных рецензиях. Начнём с положительных. Получаем все слова хороших рецензий и удаляем из них те, что повторяются в группе плохих:
# составляем список всех слов
all_word = ' '.join(pos_df.to_list())
# очищаем от слов, которые часто встречаются в обоих типах рецензий
cleaned_text = clean_text(all_word, stop_words_all)Создаём график — пока только виртуально, ничего не показывая на экране. Задаём размеры, цветосхему, максимальный размер шрифта и запрещаем использовать сочетания из двух слов и более:
# составляем список всех слов
all_word = ' '.join(pos_df.to_list())
# очищаем от слов, которые часто встречаются в обоих типах рецензий
cleaned_text = clean_text(all_word, stop_words_all)
# строим график: задаём размер окна, цветовую палитру, максимальный размер
# шрифта, не включаем словосочетания из двух слов и передаём наш набор слов
wordcloud = WordCloud(width=800, height=500,
colormap='Blues',
max_font_size=110,
collocations=False).generate(cleaned_text)Добавим ещё несколько настроек. Задаём размер графика-облака:
plt.figure(figsize=(10, 7))
Добавляем сглаживание изображения:
plt.imshow(wordcloud, interpolation='bilinear')
Оси и метки нам не нужны. Отключаем их такой командой:
plt.axis("off")
Оставим только название графика, и можно выводить на экран:
plt.title("Самые частые слова из положительных рецензий")
Рисуем график позитивных рецензий:
plt.show()
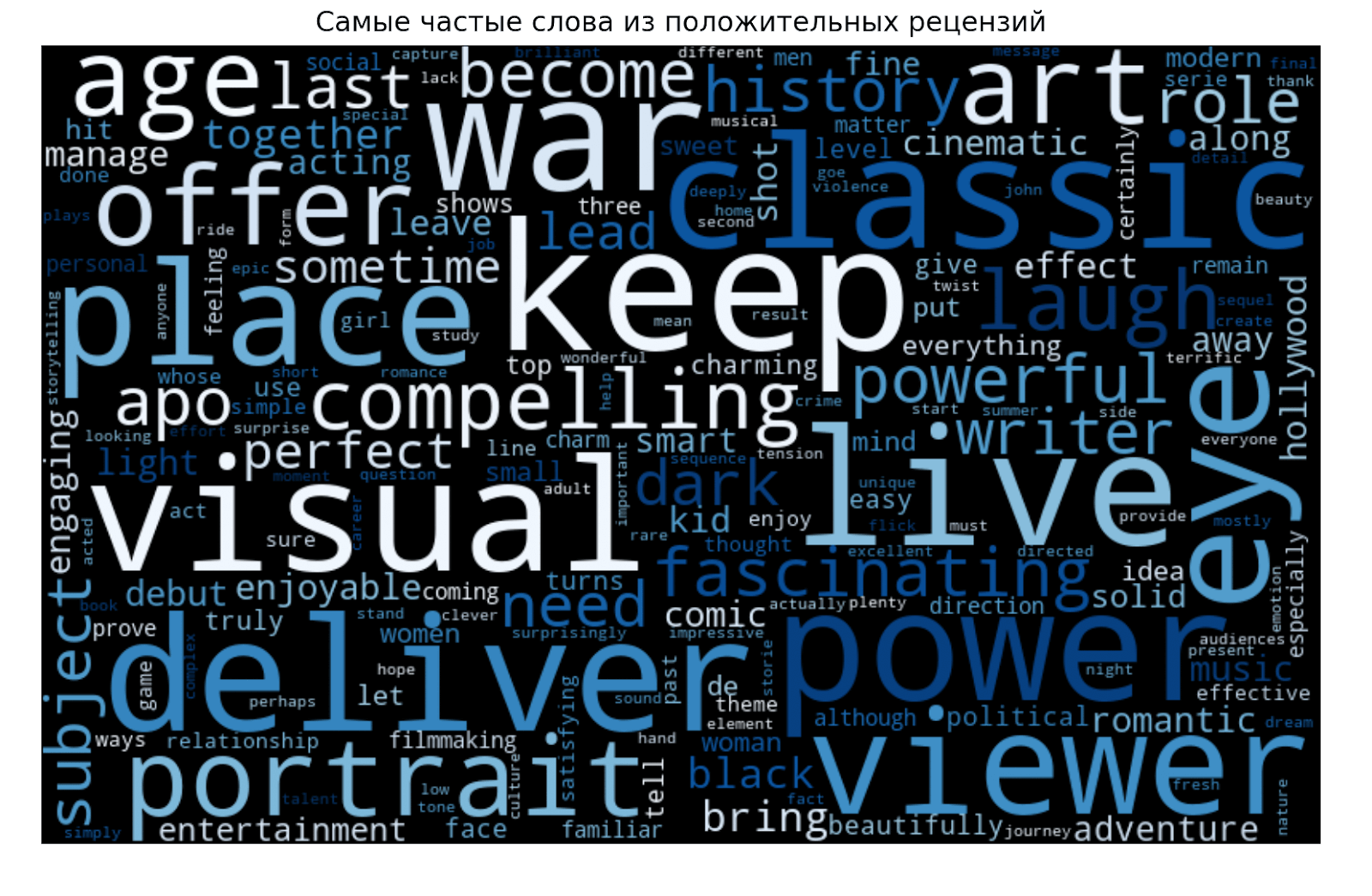
Сделаем всё то же самое для облака отрицательных рецензий:
# строим облако отрицательных рецензий
# составляем список всех слов
all_word = ' '.join(neg_df.to_list())
# очищаем от слов, которые часто встречаются в обоих типах рецензий
cleaned_text = clean_text(all_word, stop_words_all)
# строим график: задаём размер окна, цветовую палитру, максимальный размер
# шрифта, не включаем словосочетания из двух слов и передаём наш набор слов
wordcloud = WordCloud(width=800, height=500,
colormap='Oranges_r',
max_font_size=110,
collocations=False).generate(cleaned_text)
# задаём размер графика, на котором будет отображаться облако
plt.figure(figsize=(10, 7))
# добавляем сглаживание изображения
plt.imshow(wordcloud, interpolation='bilinear')
# отключаем оси и метки
plt.axis("off")
# добавляем название графика
plt.title("Самые частые слова из отрицательных рецензий")
# рисуем график негативных рецензий
plt.show()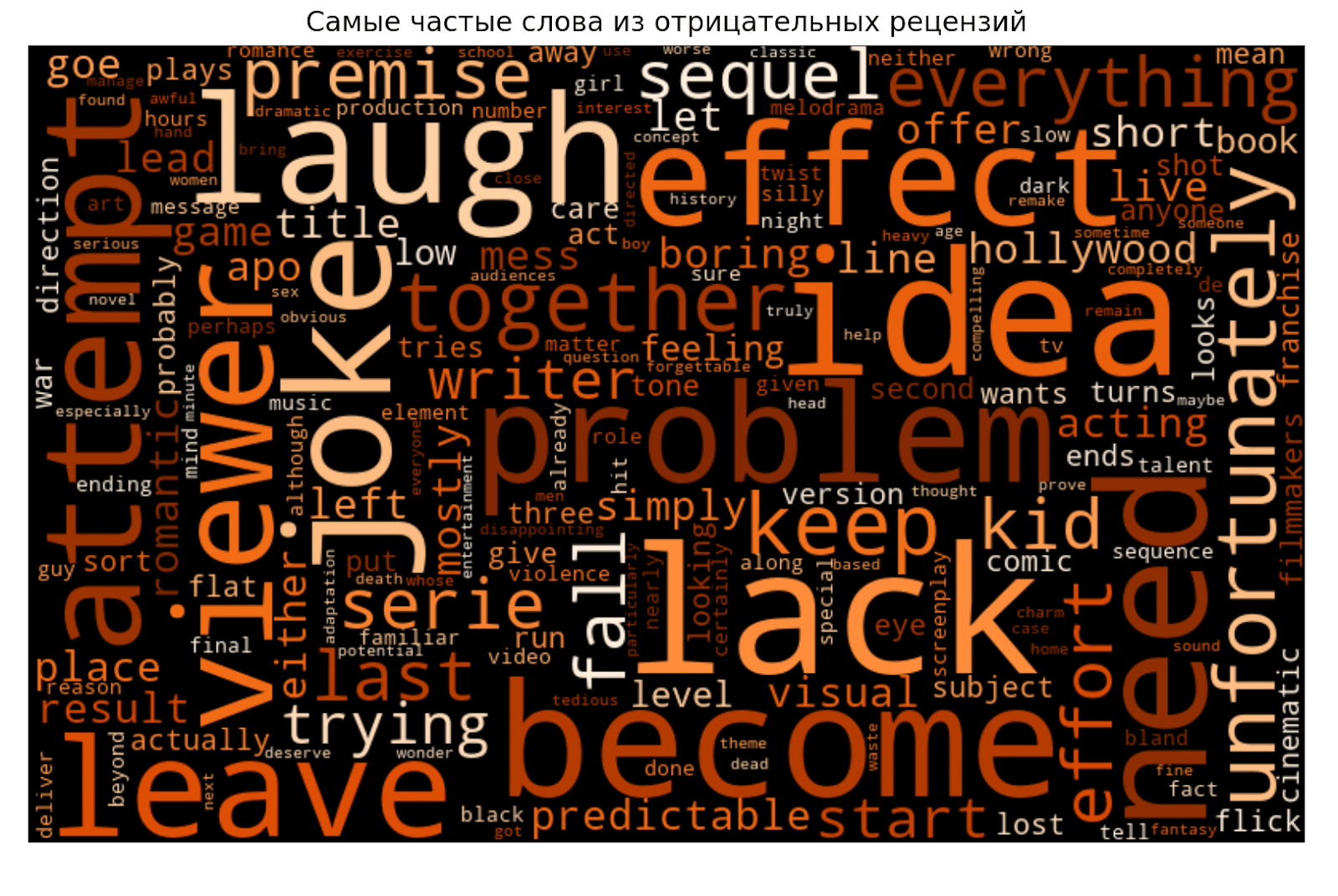
Попробуем сделать выводы из получившихся визуализаций. В положительных рецензиях преобладают слова war, classic, visual, power. Возможно, в списке часто встречаются фильмы о конфликтах с красивыми визуальными эффектами. Но какие-то уверенные выводы делать сложно, потому что среди слов в основном встречается описание ощущений.
В отрицательных рецензиях много говорят о недостатках и проблемах. Чуть реже встречается слово sequel. Но самое частое слово — laugh. Это интересно и задаёт направление для следующего исследования: проблема плохих фильмов в нехватке хороших шуток? Или авторы часто смеялись при просмотре?
Ещё видно, что даже после удаления большого количества стоп-слов остались повторы и неинформативные слова. Можно предположить, что плохие и хорошие рецензии составлены во многом из похожих слов, но в разной структуре. Но есть вариант лучше: продолжать чистить графики и попробовать найти суть.
Короче, вот тут и начинается второй этап работы аналитиков — посмотреть на результаты под разными углами и попробовать найти взаимосвязи, которые раньше до них никто не видел.
Что сделаем в следующий раз
В следующей статье про бигдату возьмём одну из идей для киноисследований и проведём более глубокий анализ с новыми интересными технологиями.
# импортируем все зависимости
from collections import Counter
import numpy as np
import polars as pl
import seaborn as sns
import matplotlib.pyplot as plt
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from wordcloud import WordCloud
# Настройка параметров отображения
# Устанавливаем число столбцов для отображения
pl.Config.set_tbl_cols(30)
pl.Config.set_tbl_width_chars(165) # Устанавливаем максимальную ширину таблицы в символах
# загружаем датасет в переменную
df = pl.read_csv('rotten_tomatoes_movie_reviews.csv')
# проверяем, что всё загрузилось: выводим первые 5 значений
print(df.head())
# задаём SQL-запрос для выборки определённых столбцов
# из датасета и выводим обновлённые данные
query = """
SELECT id, reviewText, scoreSentiment, criticName, isTopCritic, reviewState
FROM self
"""
# применяем запрос
df = df.sql(query)
# проверяем результат
print(df.head(10))
# определяем функцию для очистки текстовых данных в столбце reviewText:
# удаляем ссылки, спецсимволы, числа и приводим текст к нижнему регистру.
def clean_data(df_cleaning: pl.DataFrame):
# метод with_columns добавляет столбцы
df_cleaning = df_cleaning.with_columns(
# очищаем все значения в столбце reviewText методом строки replace_all:
# заменяем ненужные символы на пробелы или более удобные для анализа символы
pl.col('reviewText')
.str.to_lowercase()
.str.replace_all("'s", ' is')
.str.replace_all("n't", ' not')
.str.replace_all("'m", ' am')
.str.replace_all('((www\.[^\s]+)|(https?://[^\s]+))', '')
.str.replace_all('@[^\s]+', '')
.str.replace_all(r"\d+", "")
.str.replace_all("\W", " ")
.str.replace_all('https?://\S+|www\.\S+', '')
.str.replace_all('<.*?>+', '')
.str.replace_all('\n', '')
.str.replace_all(r'#([^\s]+)', r'\1')
.str.replace_all('\.', ' ')
.str.replace_all('\"', ' ')
.str.replace_all('\w*\d\w*', '')
.str.replace_all('\!', ' ')
.str.replace_all('\-', ' ')
.str.replace_all('\:', ' ')
.str.replace_all('\)', ' ')
.str.replace_all('\,', ' ')
.str.replace_all('[\s]+', ' ')
.str.strip_chars('\'"')
)
return df_cleaning
# применяем функцию очистки данных к датасету
df = clean_data(df)
# пишем SQL-запрос для фильтра: оставляем только те строки,
# где значение в столбце reviewText не пустое — значит, рецензия есть
query = """
SELECT *
FROM self
WHERE reviewText <> ''
"""
# применяем запрос
df = df.sql(query)
# проверяем: выводим первые 10 фильмов с рецензиями
print(df.head(10))
# 1 — строим круговую диаграмму для отображения распределения рецензий по scoreSentiment
# узнаём общее количество типов рецензий
unique, count = np.unique(df['scoreSentiment'], return_counts=True)
# передаём в библиотеку matplotlib массив значений
# posititve-negative и их количество на каждый фильм
plt.pie(x=count, labels=unique, autopct='%.0f%%')
# пишем название диаграммы
plt.title('Общая оценка распределения положительных и негативных рецензий')
# выводим на экран
plt.show()
# 2 — столбчатая горизонтальная диаграмма для критиков
# отбираем рецензии только топ-критиков
topCriticsQuery = """
SELECT *
FROM self
WHERE isTopCritic=1
"""
# применяем запрос
topCriticDf = df.sql(topCriticsQuery)
# считаем количество рецензий каждого из топ-критиков
# и сортируем их в порядке убывания
query = """
SELECT criticName, COUNT(*) AS reviewCount
FROM self
GROUP BY criticName
ORDER BY reviewCount DESC
"""
# применяем запрос
topCriticCount = topCriticDf.sql(query)
# задаём размер графика
plt.figure(figsize=(10, 8))
# строим горизонтальный график для первых 30 критиков с наибольшим количеством рецензий
# устанавливаем оси: количества рецензий по x, имя критика по y
sns.barplot(x=topCriticCount['reviewCount'].head(30),
y=topCriticCount['criticName'].head(30),
# устанавливаем горизонтальную ориентацию графика
orient='h',
# устанавливаем цветовую маркировку для каждого столбца
hue=topCriticCount['criticName'].head(30)
)
# устанавливаем метку по X
plt.xlabel('Количество рецензий')
# устанавливаем метку по Y
plt.ylabel('Имя критика')
# задаём название для диаграммы
plt.title('30 Топ-критиков с наибольшим количеством рецензий')
# увеличиваем отступ слева
plt.subplots_adjust(left=0.3)
# рисуем график
plt.show()
# 3.1 — столбчатая горизонтальная диаграмма для фильмов по количеству отзывов
# задаём SQL-запрос для получения списка фильмов
# с наибольшим количеством отрицательных отзывов
query = """
SELECT id, COUNT(*) as negReviewCount
FROM self
WHERE scoreSentiment='NEGATIVE'
GROUP BY id
ORDER BY negReviewCount DESC
LIMIT 50
"""
# применяем запрос
topNegMov = df.sql(query)
# строим столбчатый график одного цвета
# задаём размер графика
plt.figure(figsize=(10, 8))
# устанавливаем оси X и Y, ориентацию графика, цвет столбцов
sns.barplot(x=topNegMov['negReviewCount'],
y=topNegMov['id'],
orient='h',
color='red'
)
# устанавливаем метку по X
plt.xlabel('Количество негативных отзывов')
# устанавливаем метку по Y
plt.ylabel('Название фильма')
# задаём название для диаграммы
plt.title('50 фильмов с наибольшим количеством отрицательных рецензий')
# увеличиваем отступ слева
plt.subplots_adjust(left=0.3)
# рисуем график
plt.show()
# 3.2 — столбчатая горизонтальная диаграмма для фильмов по количеству отзывов
# задаём SQL-запрос для получения списка фильмов
# с наибольшим количеством отрицательных отзывов
query = """
SELECT id, COUNT(*) as posReviewCount
FROM self
WHERE scoreSentiment='POSITIVE'
GROUP BY id
ORDER BY posReviewCount DESC
LIMIT 50
"""
# применяем запрос
posNegMov = df.sql(query)
# строим столбчатый график одного цвета
# задаём размер графика
plt.figure(figsize=(10, 8))
# устанавливаем оси X и Y, ориентацию графика, цвет столбцов
sns.barplot(x=posNegMov['posReviewCount'],
y=posNegMov['id'],
orient='h',
color='green'
)
# устанавливаем метку по X
plt.xlabel('Количество положительных отзывов')
# устанавливаем метку по Y
plt.ylabel('Название фильма')
# задаём название для диаграммы
plt.title('50 фильмов с наибольшим количеством положительных рецензий')
# увеличиваем отступ слева
plt.subplots_adjust(left=0.3)
# рисуем график
plt.show()
# 4 — строим wordcloud по количеству слов в положительных и отрицательных рецензиях
# загружаем зависимости для стоп-сллов
nltk.download('punkt')
nltk.download('stopwords')
# составляеем список стоп-слов: добавляем готовые из английского словаря
stop_words_all = set(stopwords.words('english'))
# записываем свои
custom_stop_words = {'movie', 'film', 'one', 'would', 'like', 'quite', 'enough',
'character', 'comedy', 'films', 'make', 'time', 'see', 'way',
'year', 'even', 'good', 'much', 'work', 'take', 'characters',
'still', 'review', 'feel', 'seem', 'scene', 'though', 'funny',
'scene', 'find', 'day', 'actor', 'play', 'know', 'bit', 'set',
'making', 'turn', 'want', 'feature', 'filmmaker', 'around',
'hour', 'think', 'show'}
# добавляем свои слова в набор стоп-слов
stop_words_all.update(custom_stop_words)
# пишем функцию для очистки текста от стоп-слов
def clean_text(text, stop_words):
# токенизируем и приводим к нижнему регистру
tokens = word_tokenize(text.lower())
# удаляем стоп-слова и небуквенные символы
filtered_tokens = [word for word in tokens if word.isalpha() and word not in stop_words]
# возвращаем очищенный текст
return ' '.join(filtered_tokens)
# пишем функцию для нахождения самых частых слов в рецензиях
def get_most_common_words(text, num_words=100):
# разбиваем текст на слова
words = text.split()
# создаём коллекцию вида: слово — количество повторений
counter = Counter(words)
# возвращаем первые 100 слов из всех переданных в функцию рецензий
return counter.most_common(num_words)
# пишем запрос для выделения всех положительных рецензий
pos_query = """
SELECT reviewText
FROM self
WHERE scoreSentiment = 'POSITIVE'
"""
# пишем запрос для выделения всех отрицательных рецензий
neg_query = """
SELECT reviewText
FROM self
WHERE scoreSentiment = 'NEGATIVE'
"""
# выделяем все позитивные рецензии через запрос
pos_df = df.sql(pos_query)['reviewText']
# объединяем все слова из рецензий
all_pos_words = ' '.join(pos_df.to_list())
# очищаем текст от стоп-слов
cleaned_pos_text = clean_text(all_pos_words, stop_words_all)
# выделяем наиболее часто встречающиеся слова
pos_common_words = get_most_common_words(cleaned_pos_text)
# выделяем все негативные рецензии через запрос
neg_df = df.sql(neg_query)['reviewText']
# объединяем все слова из рецензий
all_neg_words = ' '.join(neg_df.to_list())
# очищаем текст от стоп-слов
cleaned_neg_text = clean_text(all_neg_words, stop_words_all)
# выделяем наиболее часто встречающиеся слова
neg_common_words = get_most_common_words(cleaned_neg_text)
# преобразуем самые частые слова в множества
# позитивных и негативных часто встречающихся слов
top_pos_words = {word for word, _ in pos_common_words}
top_neg_words = {word for word, _ in neg_common_words}
# объединяем слова из обоих наборов
top_words = top_pos_words | top_neg_words
# обновляем стоп-слова
stop_words_all.update(top_words)
# 5.1 строим облако положительных рецензий
# составляем список всех слов
all_word = ' '.join(pos_df.to_list())
# очищаем от слов, которые часто встречаются в обоих типах рецензий
cleaned_text = clean_text(all_word, stop_words_all)
# строим график: задаём размер окна, цветовую палитру, максимальный размер
# шрифта, не включаем словосочетания из двух слов и передаём наш набор слов
wordcloud = WordCloud(width=800, height=500,
colormap='Blues',
max_font_size=110,
collocations=False).generate(cleaned_text)
# задаём размер графика, на котром будет отображаться облако
plt.figure(figsize=(10, 7))
# добавляем сглаживание изображения
plt.imshow(wordcloud, interpolation='bilinear')
# отключаем оси и метки
plt.axis("off")
# добавляем название графика
plt.title("Самые частые слова из положительных рецензий")
# рисуем график позитивных рецензий
plt.show()
# 5.1 строим облако отрицательных рецензий
# составляем список всех слов
all_word = ' '.join(neg_df.to_list())
# очищаем от слов, которые часто встречаются в обоих типах рецензий
cleaned_text = clean_text(all_word, stop_words_all)
# строим график: задаём размер окна, цетовую палитру, максимальный размер
# шрифта, не включаем словосочетания из двух слов и передаём наш набор слов
wordcloud = WordCloud(width=800, height=500,
colormap='Oranges_r',
max_font_size=110,
collocations=False).generate(cleaned_text)
# задаём размер графика, на котром будет отображаться облако
plt.figure(figsize=(10, 7))
# добавляем сглаживание изображения
plt.imshow(wordcloud, interpolation='bilinear')
# отключаем оси и метки
plt.axis("off")
# добавляем название графика
plt.title("Самые частые слова из отрицательных рецензий")
# рисуем график негативных рецензий
plt.show()






![Что означает ошибка FileNotFoundError: [Errno 2] No such file or directory](https://thecode.media/wp-content/uploads/2024/02/1-9-720x479.png)



